Clarifying “What failure looks like”
Thanks to Jess Whittlestone, Daniel Eth, Shahar Avin, Rose Hadshar, Eliana Lorch, Alexis Carlier, Flo Dorner, Kwan Yee Ng, Lewis Hammond, Phil Trammell and Jenny Xiao for valuable conversations, feedback and other support. I am especially grateful to Jess Whittlestone for long conversations and detailed feedback on drafts, and her guidance on which threads to pursue and how to frame this post. All errors are my own.
Epistemic status: My Best Guess
Epistemic effort: ~70 hours of focused work (mostly during FHI’s summer research fellowship), talked to ~10 people.
Introduction
“What failure looks like” is the one of the most comprehensive pictures of what failure to solve the AI alignment problem looks like, in worlds without discontinuous progress in AI. I think it was an excellent and much-needed addition to our understanding of AI risk. Still, if many believe that this is a main source of AI risk, I think it should be fleshed out in more than just one blog post. The original story has two parts; I’m focusing on part 1 because I found it more confusing and nebulous than part 2.
Firstly, I’ll summarise part 1 (hereafter “WFLL1”) as I understand it:
-
In the world today, it’s easier to pursue easy-to-measure goals than hard-to-measure goals.
-
Machine learning is differentially good at pursuing easy-to-measure goals (assuming that we don’t have a satisfactory technical solution to the intent alignment problem[1]).
-
We’ll try to harness this by designing easy-to-measure proxies for what we care about, and deploy AI systems across society which optimize for these proxies (e.g. in law enforcement, legislation and the market).
-
We’ll give these AI systems more and more influence (e.g. eventually, the systems running law enforcement may actually be making all the decisions for us).
-
Eventually, the proxies for which the AI systems are optimizing will come apart from the goals we truly care about, but by then humanity won’t be able to take back influence, and we’ll have permanently lost some of our ability to steer our trajectory.
WFLL1 is quite thin on some important details:
-
WFLL1 does not envisage AI systems directly causing human extinction. So, to constitute an existential risk in itself, the story must involve the lock-in of some suboptimal world.[2] However, the likelihood that the scenario described in part 1 gets locked-in (especially over very long time horizons) is not entirely clear in the original post.
-
It’s also not clear how bad this locked-in world would actually be.
I’ll focus on the first point: how likely is it that the scenario described in WFLL1 leads to the lock-in of some suboptimal world. I’ll finish with some rough thoughts on the second point—how bad/severe that locked-in world might be—and by highlighting some remaining open questions.
Likelihood of lock-in
The scenario described in WFLL1 seems very concerning from a longtermist perspective if it leads to humanity getting stuck on some suboptimal path (I’ll refer to this as “lock-in”). But the blog post itself isn’t all that clear about why we should expect such lock-in—i.e. why we won’t be able to stop the trend of AI systems optimising for easy-to-measure things before it’s too late—a confusion which has been pointed out before. In this section, I’ll talk through some different mechanisms by which this lock-in can occur, discuss some historical precedents for these mechanisms occurring, and then discuss why we might expect the scenario described in WFLL1 to be more likely to lead to lock-in than for the precedents.
The mechanisms for lock-in
Summary: I describe five complementary mechanisms by which the scenario described in WFLL1 (i.e. AI systems across society optimizing for simple proxies at the expense of what we actually want) could get locked-in permanently. The first three mechanisms show how humanity may increasingly depend on the superior reasoning abilities of AIs optimizing for simple proxies to run (e.g.) law enforcement, legislation and the market, despite it being apparent—at least to some people—that this will be bad in the long term. The final two mechanisms explain how this may eventually lead to a truly permanent lock-in, rather than merely temporary delays in fixing the problem.
Before diving into the mechanisms, first, let’s be clear about the kind of world in which they may play out. The original post assumes that we have not solved intent alignment and that AI is “responsible for” a very large fraction of the economy.[3] So we’ve made sufficient progress on alignment (and capabilities) such that we can deploy powerful AI systems across society that pursue easy-to-measure objectives, but not hard-to-measure ones.
(1) Short-term incentives and collective action
Most actors (e.g. corporations, governments) have some short-term objectives (e.g. profit, being reelected). These actors will be incentivised to deploy (or sanction the deployment of) AI systems to pursue these short-term objectives. Moreover, even if some of these actors are aware that pursuing proxies in place of true goals is prone to failure, if they decide not to use AI then they will likely fall behind in their short-term objectives and therefore lose influence (e.g. be outcompeted, or not reelected). This kind of situation is called a collective action problem, since it requires actors to coordinate on collectively limiting their use of AI—individual actors are better off (in the short term) by deploying AI anyway.
Example: predictive policy algorithms used in the US are biased against people of colour. We can’t debias these algorithms, because we don’t know how to design algorithms that pursue the hard-to-measure goal of “fairness”. Meanwhile, such algorithms continued to be used. Why? Given crime rate objectives and a limited budget, police departments do better on these objectives by using (cheap) predictive algorithms, compared with hiring more staff to think through bias/fairness issues. So, individual departments are “better off” in the short term (i.e. more likely to meet their objectives and so keep their jobs) if they just keep using predictive algorithms. Even if some department chief realises that this minimization of reported crime rate produces this perverse outcome, they are unable to take straightforward action to fix the problem because this would likely result in increased reported crime rate for their department, impacting that chief’s career prospects.
(2) Regulatory capture
The second mechanism is that influential people will benefit from the AIs optimizing for easy-to-measure goals, and they will oppose attempts to put on the brakes. Think of a powerful CEO using AI techniques to maximize profit: they will be incentivised to capture regulators who attempt to stop the use of AI, for example via political donations or lobbying.
Example: Facebook is aware of how user data protection and the spread of viral misinformation led to problems in the 2016 presidential election. Yet they spent $17 million lobbying the US government to assuage regulators who were trying to introduce countervailing regulation in 2019.
(3) Genuine ambiguity
The third mechanism is that there will be genuine ambiguity about whether the scenario described in WFLL1 is good or bad. For a while, humans are overall better off in absolute terms than they are today.[4] From the original post:
There will be legitimate arguments about whether the implicit long-term purposes being pursued by AI systems are really so much worse than the long-term purposes that would be pursued by the shareholders of public companies or corrupt officials.
This will be heightened by the fact that it’s easier to make arguments about things for which you have clear, measurable objectives.[5] So arguments that the world is actually fine will be easier to make, in light of the evidence about how well things are going according to the objectives being pursued by AIs. Arguments that something is going wrong, however, will have no such concrete evidence to support them (they might only be able to appeal to a vague sense that the world just isn’t as good as it could be).
This ambiguity will make the collective action problem of the first mechanism even harder to resolve, since disagreement between actors on the severity of a collective problem impedes collective action on that problem.
Example: genuine ambiguity about whether capitalism is “good” or “bad” in the long run. Do negative externalities become catastrophically high, or does growth lead to sufficiently advanced technology fast enough to compensate for these externalities?
(4) Dependency and deskilling
If used widely enough across important societal functions, there may come a time when ceasing to use AI systems would require something tantamount to societal collapse. We can build some intuition for this argument by thinking about electricity, one general purpose technology on which society already depends heavily. Suppose for the sake of argument that some research comes out arguing that our use of electricity will eventually cause our future to be less good than it otherwise could have been. How would humanity respond? I’d expect to see research on potential modifications to our electricity network, and research that tries to undermine the original study. But actually giving up electricity seems unlikely. Even if doing so would not imply total societal collapse, it would at least significantly destabilise society, reducing our ability to deal with other existential risks. This destabilisation would increase the chance of conflict, which would further erode international trust and cooperation and increase risks posed by a range of weapon technologies.[6] And even if giving up electricity was actually the best strategy in expectation, we wouldn’t necessarily do so, due to the problems of short term incentives, collective action, regulatory capture and genuine ambiguity mentioned above.
Furthermore, if we increasingly depend on AIs to make the world work, then humans are unlikely to continue to learn the skills we would need to replace them. In a world where most businesspeople/doctors/lawyers are now AIs, we would likely cut costs by closing down most human business/medical/law schools. This deskilling is an additional reason to think we could be locked-in to a world where AI systems are filling these roles.
(5) Opposition to taking back influence
Whilst these four mechanisms may mean that our attempts at taking back influence from AIs will be delayed, and will come at some cost, surely we will eventually realise that something has gone wrong, and make a proper attempt to fix it, even if this involves some costly reskilling and destabilisation?
By way of answering this question in the negative, the original article imagines the following possibility:
Eventually, large-scale attempts to fix the problem are themselves opposed by the collective optimization of millions of optimizers pursuing simple goals.
This opposition could take two forms. The first can be seen as a continuation of the “genuine ambiguity” mechanism. Simply because the AIs are doing their jobs so well, we may be increasingly unlikely to realise that anything is going wrong. Reported sense of security, healthcare statistics, life satisfaction, GDP, etc. will look great, because it is precisely these proxies for which the AIs are optimizing. As the gap between how things are and how they appear grows, so too will the persuasion/deception abilities of AIs and the world’s incomprehensibility. Eventually, AIs will be able to manipulate human values and our ability to perceive the world in sophisticated ways (think: highly addictive video games, highly persuasive media or education; cf. the human safety problem).
Example: recommender algorithms maximizing click-throughs feed users more extreme content in order to keep them online for longer. Stuart Russell claims that this is an example of an algorithm making its users’ values more extreme, in order to better pursue its objective.[7]
Secondly, the AIs may explicitly oppose any attempts to shut them down or otherwise modify their objectives. This is because human attempts to take back influence probably will result in (short term) losses according to their objective functions (e.g. reported sense of security will go down if the systems that have been driving this down are switched off). Therefore, AIs will be incentivised to oppose such changes.
What this opposition looks like depends on how general the AIs are. In CAIS-type scenarios, AIs would probably be limited to the narrow kinds of deception described above. For example, an AI police service with bounded resources minimizing the number of complaints before the end of the day (as a proxy for society’s actual safety) will not take long-term, large-scale actions to manipulate human values (e.g. producing advertising to convince the public that complaining is ineffectual). However, it could still take unintended short-term, small-scale actions, if they’re helpful for the task before the end of the bound (e.g. offer better protection to people if they don’t file complaints).
More general AI could oppose human attempts to take back influence in more concerning ways. For example, it could hamper human attempts at collective action (by dividing people’s attention across different issues), cut funding for research on AI systems that can pursue hard-to-measure objectives or undermine the influence of key humans in the opposition movement. Our prospects certainly seem better in CAIS-type scenarios.
Historical precedents
I think the existence of these mechanisms makes the case that it is possible that the scenario described in WFLL1 will get locked-in. But is it plausible? In particular, will we really fail to make a sufficient attempt to fix the problem before it is irreversibly locked-in? I’ll examine three historical precedents which demonstrate the mechanisms playing out, which positively update my credence that it will also play out in the case of WFLL1. However, this reasoning via historical precedents is far from decisive evidence, and I can imagine completely changing my mind if I had more evidence about factors like takeoff speeds and the generality of AI systems.
Climate change
Climate change is a recent example of how mechanisms 1-3 delayed our attempts to solve a problem until some irreversible damage was already done. However, note that the mechanism for the irreversible lock-in is different to WFLL1 (the effects of climate change are locked-in via irreversible physical changes to the climate system, rather than mechanisms 4 and 5 described above).
(1) Short-term incentives and collective action
Most electricity generation companies maximize profit by producing electricity from fossil fuels. Despite the unequivocal scientific evidence that burning fossil fuels causes climate change and will probably make us collectively worse off in the long term, individual companies are better off (in the short term) if they continue to burn fossil fuels. And they will be outcompeted if they don’t. The result is a slow-rolling climate catastrophe, despite attempts at collective action like the Kyoto Protocol.
(2) Regulatory capture
BP, Shell, Chevron, ExxonMobil and Total have spent €251m lobbying the EU since 2010 in order to water down EU climate legislation.
(3) Genuine ambiguity
Consensus among the scientific community that human-caused emissions were contributing to climate change was not established until the 1990s. Even today, some people deny there is a problem. This probably delayed attempts to solve the problem.
The agricultural revolution
The agricultural revolution is a precedent for mechanisms 1 and 4 leading to lock-in of technology that arguably made human life worse (on average) for thousands of years. (The argument that agriculture made human life worse is that increased population density enabled epidemics, farm labour increased physical stress, and malnutrition rose due to the replacement of a varied diet with fewer starchy foods.[8])
(1) Short-term incentives and collective action
Humans who harnessed agricultural technology could increase their population relative to their hunter-gatherer peers. Despite the claimed lower levels of health among agriculture communities, their sheer advantage in numbers gave them influence over hunter-gatherers:
The greater political and military power of farming societies since their inception resulted in the elimination and displacement of late Pleistocene foragers (Bowles, 2011).
So, individual communities were incentivised to convert to agriculture, on pain of being eradicated by more powerful groups who had adopted agriculture.
(4) Dependency
Once a community had been depending on agricultural technology for some generations, it would be difficult to regress to a hunter-gatherer lifestyle. They would have been unable to support their increased population, and would probably have lost some skills necessary to be successful hunter-gatherers.
The colonisation of New Zealand
The colonisation of New Zealand is a precedent for a group of humans permanently losing some influence over the future, due to mechanisms 1, 3 and 5. In 1769, the indigenous Māori were the only people in New Zealand, but by 1872, the British (with different values to the Māori) had a substantial amount of influence over New Zealand’s future (see this animation of decline in Māori land ownership for a particularly striking illustration of this). Despite the superficial differences, I think this provides a fairly close analogy to WFLL1.[9]
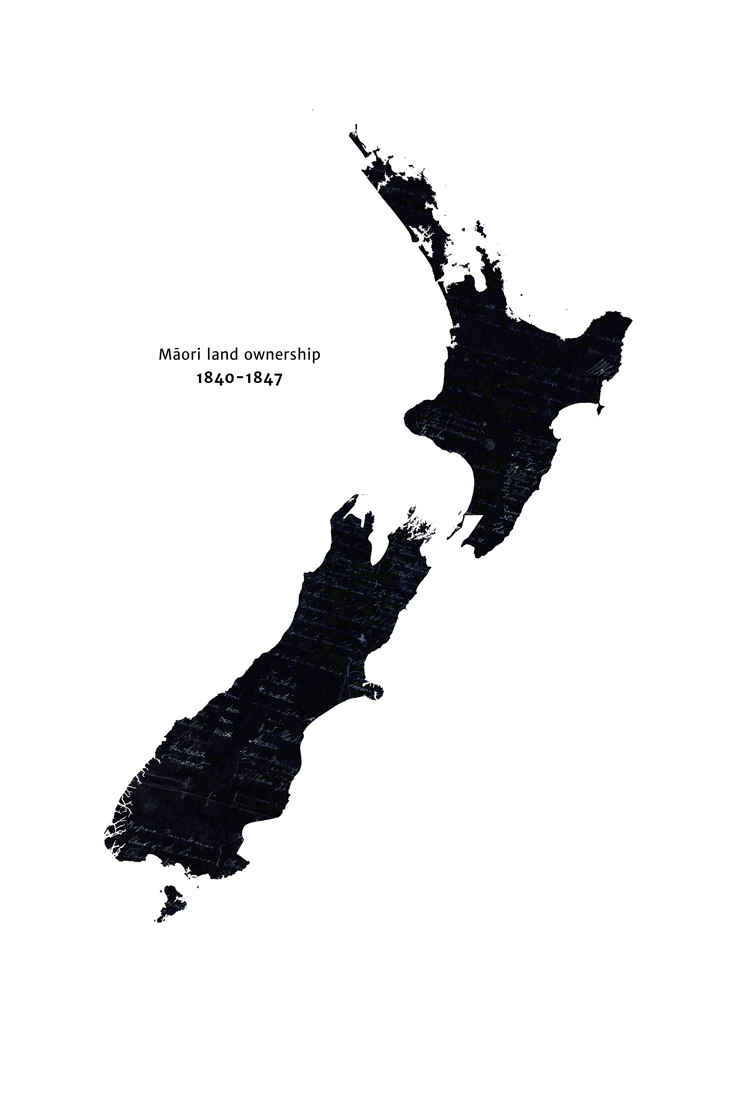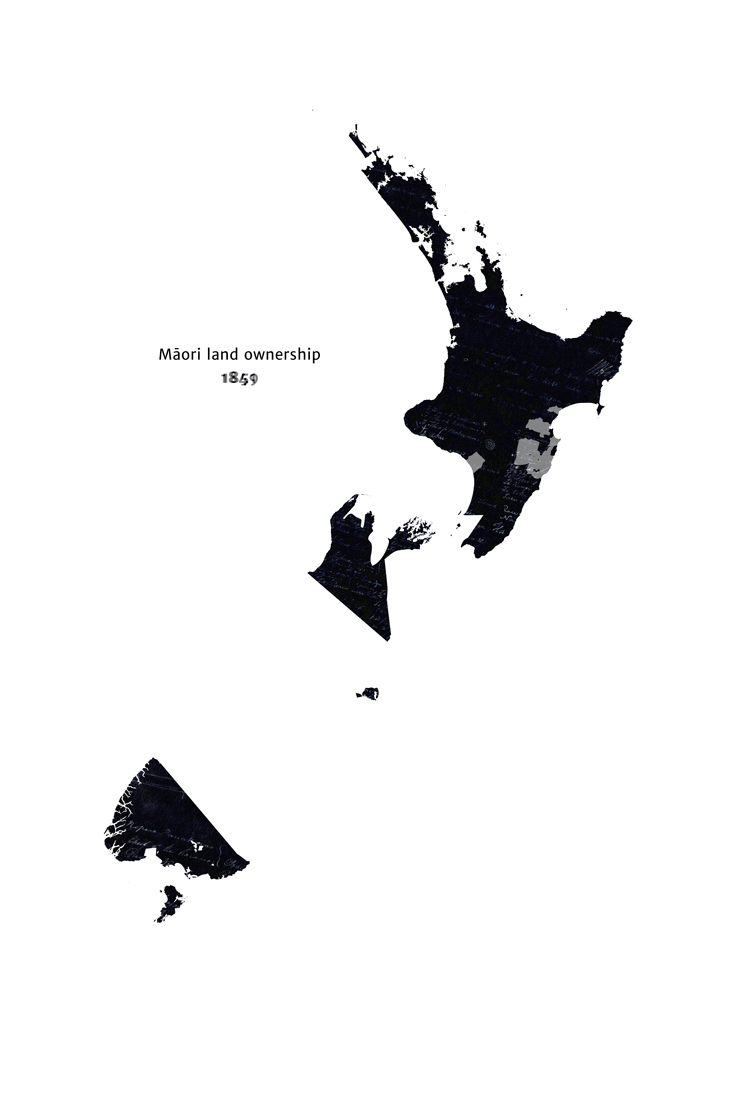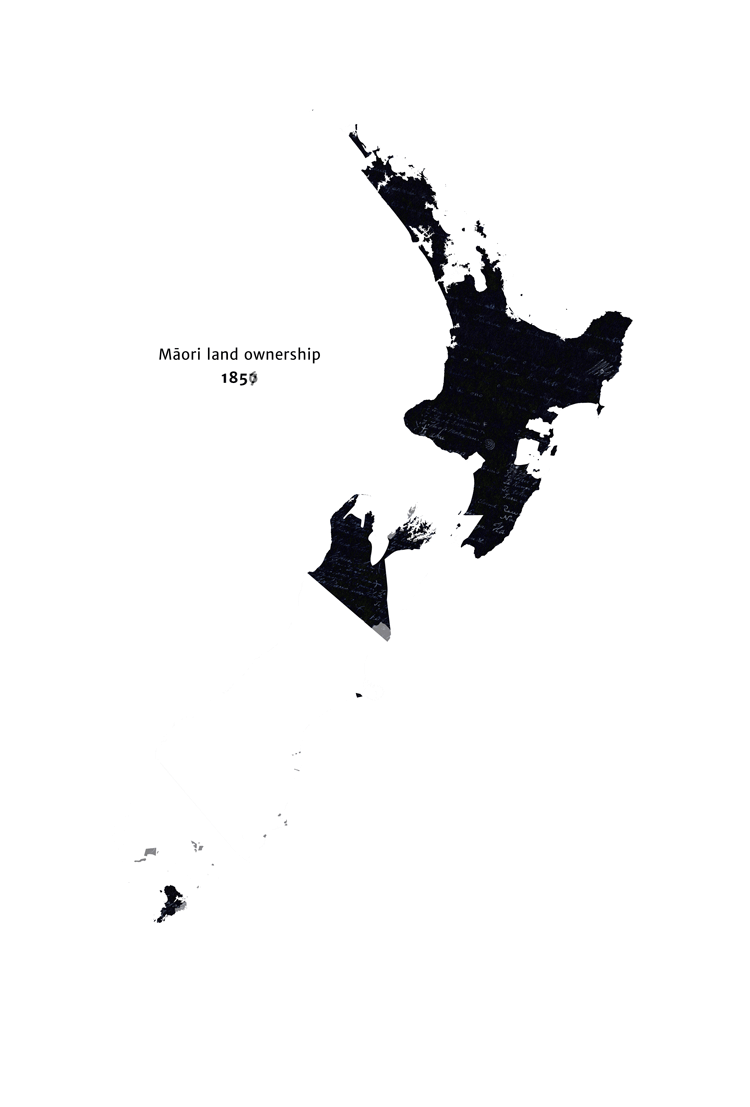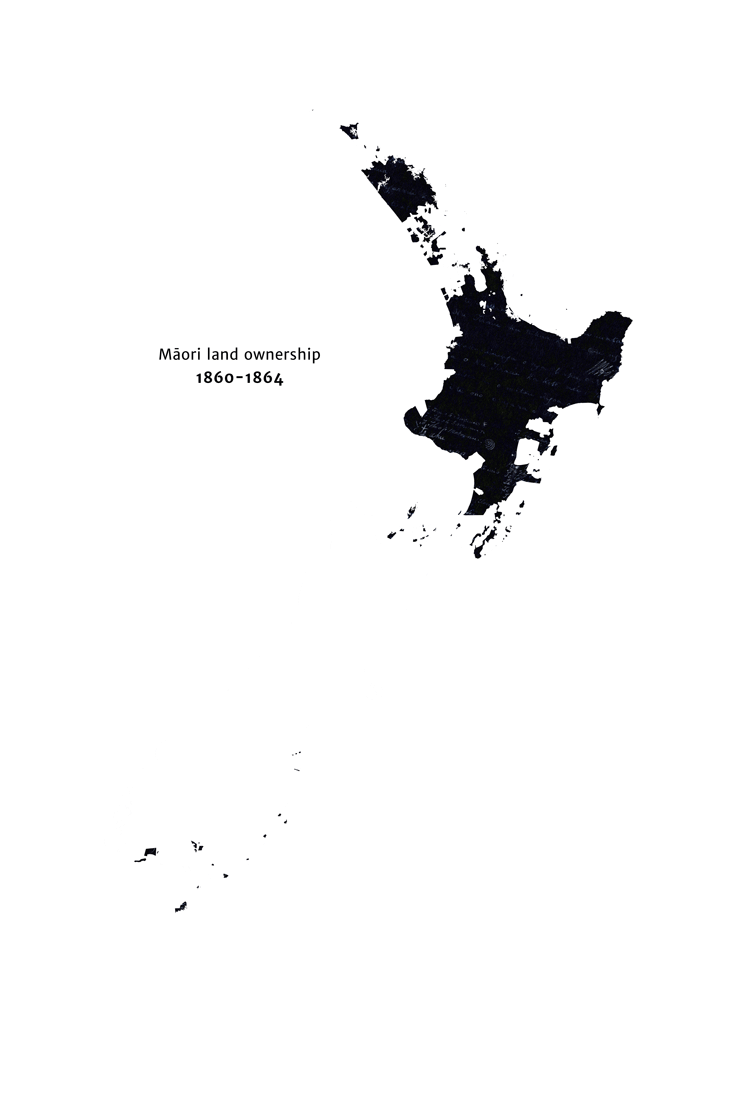{kind=link}
(1) Short-term incentives and collective action
The British purchased land from the Māori, in exchange for (e.g.) guns and metal tools. Each tribe was individually better off if they engaged in trade, because guns and tools were economically and militarily valuable; tribes that did not obtain guns were devastated in the Musket Wars. However, tribes became collectively worse off because the British charged unreasonable prices (e.g. in 1848, over 30% of New Zealand was purchased for around NZD 225,000 in today’s currency) and could use this land to increase their influence in the longer term (more settlers could arrive and dominate New Zealand’s agriculture-based economy).
(3) Genuine ambiguity
British goals were initially somewhat aligned with Māori goals. Most early contact was peaceful and welcomed by Māori. In absolute economic terms, the Māori were initially better off thanks to trade with the British. The Māori translation of the Treaty of Waitangi, which the Māori knew would bring more British settlers, was signed by around 540 Māori chiefs.
(5) Opposition to taking back influence
However, once the British had established themselves in New Zealand, the best ways to achieve their goals ceased to be aligned with Māori goals. Instead, they turned to manipulation (e.g. breaking agreements about how purchased land would be used), confiscation (e.g. the New Zealand Settlements Act 1863) and conflict (e.g. the New Zealand Wars). For the past 150 years, Māori values have sadly been just one of many determinants of New Zealand’s future, and not even a particularly strong one.
How WFLL1 may differ from precedents
These precedents demonstrate that each of the lock-in mechanisms have already played out, making it seem more plausible. The next section discusses how WFLL1 may differ from the precedents. I think these differences suggest that the lock-in mechanisms are a stronger force in WFLL1 than in the precedents, which also positively updates my credence that WFLL1 will be locked-in.
AI may worsen the “genuine ambiguity” mechanism
If AI leads to a proliferation of misinformation (e.g. via language models or deepfakes), then this will probably reduce our ability to reason and reach consensus about what is going wrong. This misinformation need not be sufficiently clever to convince people of falsehoods, it just has to splinter the attention of people who are trying to understand the problem enough to break our attempts at collective action.[10]
Another way in which AI may increase the amount of “genuine ambiguity” we have about the problem is the epistemic bubble/echo chamber phenomenon, supposedly aggravated by social media recommender systems. The claim is that (1) epistemic communities are isolated from each other via (accidental or deliberate) lack of exposure to (reasonable interpretations of) dissenting viewpoints, and (2) recommender systems, by virtue of maximising click-throughs, have worsened this dynamic. If this is true, and epistemic communities disagree about whether specific uses of AI (e.g. AI systems maximizing easy-to-measure goals replacing judges in courts) are actually serving society’s goals, this would make it even harder to reach the consensus required for collective action.
High risk of dependency and deskilling
WFLL1 assumes that AI is “responsible for” a very large fraction of the economy, making it the first time in human history where most humans are no longer required for the functioning of the economy. The agricultural and industrial revolutions involved some amount of deskilling, but humans were still required at most stages of production. However, in WFLL1 it seems likely that humans will heavily depend on AI for the functioning of the economy, making it particularly hard to put on the brakes.
Speed and warning shots
As AI gets more advanced, the world will probably start moving much faster than today (e.g. Christiano once said he thinks the future will be “like the Industrial Revolution but 10x-100x faster”). Naively, this would seem to make things less likely to go well because we’ll have less opportunity to identify and act on warning signs.
That said, some amount of speed may be on our side. If the effects of climate change manifested more quickly, it seems more likely that individual actors would be galvanised towards collective action. So faster change seems to make it more likely that the world wakes up to there being a problem, but less likely that we’re able to fix the problem if we do.
Another way of putting this might be: too fast, and the first warning shot spells doom; too slow, and warning shots don’t show up or get ignored. I’m very uncertain about what the balance will look like with AI. All things considered, perhaps faster progress is worse because human institutions move slowly even when they’re galvanised into taking action.
This discussion seems to carry an important practical implication. Since warning shots are only as helpful as our responses to them, it makes sense to set up institutions that are likely to respond effectively to warning shots if they happen. For example, having a clear, reputable literature describing these kinds of risks, which (roughly) predicts what early warning shots would look like, and argues persuasively that things will only get worse in the long run if we continue to use AI to pursue easy-to-measure goals, seems pretty helpful.
Severity of lock-in
The extent to which we should prioritise reducing the risk of a lock-in of WFLL1 also depends on how bad this world actually is. Previous discussion has seen some confusion about this question. Some possibilities include:
-
The world is much worse than our current world, because humans eventually become vastly less powerful than AIs and slowly go extinct, in much the same way as insects that become extinct in our world.
-
The world is worse than our current world, because (e.g.) despite curing disease and ageing, humans have no real freedom or understanding of the world, and spend their lives in highly addictive but unrewarding virtual realities.
-
The world is better than our current world, because humans still have some influence over the future, but our values are only one of many forces, and we can only make use of 1% of the cosmic endowment.
-
The world is much better than our current world, because humans lead fairly worthwhile lives, assisted by AIs pursuing proxies. We course-corrected these proxies along the way and they ended up capturing much of what we value. However, we still don’t make use of the full cosmic endowment.
It seems that Christiano had something like the third scenario in mind, but it isn’t clear to me why this is the most likely. The question is: how bad would the future be, if it is at least somewhat determined by AIs optimizing for easy-to-measure goals, rather than human intentions? I think this is an important open question. If I were to spend more time thinking about it, here are some things I’d do.
Comparison with precedents
In the same way that it was helpful when reasoning about the likelihood of lock-in to think about past examples, then work out how WFLL1 may compare, I think this could be a useful approach to this question. I’ll give two examples: both involve systems optimizing for easy-to-measure goals rather than human intentions, but seem to differ in the severity of the outcomes.
CompStat: where optimizing for easy-to-measure goals was net negative?[11]
-
CompStat is a system used by police departments in the US.
-
It’s used to track crime rate and police activity, which ultimately inform the promotion and remuneration of police officers.
-
Whilst the system initially made US cities much safer, it ended up leading to:
-
Widespread under/misreporting of crime (to push reported crime rate down).
-
The targeting of people of the same race and age as those who were committing crimes (to push police activity up).
-
In NYC one year, the reported crime rate was down 80%, but in interviews, officers reported it was only down ~40%.
-
It seems plausible that pressure on police to pursue these proxies made cities less safe than they would have been without CompStat: there were many other successful initiatives which were introduced alongside CompStat, and there were cases of substantial harm caused to the victims of crime underreporting and unjust targeting.
“Publish or perish”: where optimizing for easy-to-measure goals is somewhat harmful but plausibly net positive?
-
The pressure to publish papers to succeed in an academic career has some negative effects on the value of academic research.
-
However, much important work continues to happen in academia, and it’s not obvious that there’s a clearly better system that could replace it.
In terms of how WFLL1 may differ from precedents:
-
Human institutions incorporate various “corrective mechanisms”, e.g. checks and balances in political institutions, and “common sense”. However, it’s not obvious that AI systems pursuing easy-to-measure goals will have these.
-
Most human institutions are at least somewhat interpretable. This means, for example, that humans who tamper with the measurement process to pursue easy-to-measure objectives are prone to being caught, as eventually happened with CompStat. However, ML systems today are currently hard to interpret, and so it may be more difficult to catch interference with the measurement process.
Conclusion
What this post has done:
-
Clarified in more detail the mechanisms by which WFLL1 may be locked-in.
-
Discussed historical precedents for lock-in via these mechanisms and ways in which WFLL1 differs from these precedents.
-
Taken this as cautious but far from decisive evidence that the lock-in of WFLL1 is plausible.
-
Pointed out that there is confusion about how bad the future would be if it is partially influenced by AIs optimizing for easy-to-measure goals rather than human intentions.
-
Suggested how future work might make progress on this confusion.
As well as clarifying this confusion, future work could:
-
Explore the extent to which WFLL1 could increase existential risk by being a risk factor in other existential risks, rather than an existential risk in itself.
-
Search for historical examples where the mechanisms for lock-in didn’t play out.
-
Think about other ways to reason about the likelihood of lock-in of WFLL1, e.g. via a game theoretic model, or digging into The Age of Em scenario where similar themes play out.
- ↩︎
I’m worried that WFLL1 could happen even if we had a satisfactory solution to the intent alignment problem, but I’ll leave this possibility for another time.
- ↩︎
WFLL1 could also increase existential risk by being a risk factor in other existential risks, rather than a mechanism for destroying humanity’s potential in itself. To give a concrete example: faced with a global pandemic, a health advice algorithm minimising short-term excess mortality may recommend complete social lockdown to prevent the spread of the virus. However, this may ultimately result in higher excess mortality due to the longer term (and harder to measure) effects on mental health and economic prosperity. I think that exploring this possibility is an interesting avenue for future work.
- ↩︎
The latter assumption is not explicit in the original post, but this comment suggests that it is what Christiano had in mind. Indeed, WFLL1 talks about AI being responsible for running corporations, law enforcement and legislation, so the assumption seems right to me.
- ↩︎
This isn’t clear in the original post, but is clarified in this discussion.
- ↩︎
I owe this point to Shahar Avin.
- ↩︎
These pathways by which conflict may increase existential risk are summarised in The Precipice (Ord, 2020, ch. 6).
- ↩︎
From Human Compatible: “… consider how content-selection algorithms function on social media. They aren’t particularly intelligent, but they are in a position to affect the entire world because they directly influence billions of people. Typically, such algorithms are designed to maximize click-through, that is, the probability that the user clicks on presented items. The solution is simply to present items that the user likes to click on, right? Wrong. The solution is to change the user’s preferences so that they become more predictable. A more predictable user can be fed items that they are likely to click on, thereby generating more revenue. People with more extreme political views tend to be more predictable in which items they will click on. (Possibly there is a category of articles that die-hard centrists are likely to click on, but it’s not easy to imagine what this category consists of.) Like any rational entity, the algorithm learns how to modify the state of its environment—in this case, the user’s mind—in order to maximize its own reward.8 The consequences include the resurgence of fascism, the dissolution of the social contract that underpins democracies around the world, and potentially the end of the European Union and NATO. Not bad for a few lines of code, even if it had a helping hand from some humans. Now imagine what a really intelligent algorithm would be able to do.”
- ↩︎
There is some controversy about whether this is the correct interpretation of the paleopathological evidence, but there seems to at least be consensus about the other two downsides (epidemics and physical stress increasing due to agriculture).
- ↩︎
I got the idea for this analogy from Daniel Kokotajlo’s work on takeovers by conquistadors, and trying to think of historical precedents for takeovers where loss of influence happened more gradually.
- ↩︎
I owe this point to Shahar Avin.
- ↩︎
Source for these claims about CompStat: this podcast.
- 2020 AI Alignment Literature Review and Charity Comparison by (EA Forum; 21 Dec 2020 15:25 UTC; 155 points)
- 2020 AI Alignment Literature Review and Charity Comparison by (21 Dec 2020 15:27 UTC; 142 points)
- Review of FHI’s Summer Research Fellowship 2020 by (EA Forum; 19 Nov 2020 11:32 UTC; 124 points)
- A summary of current work in AI governance by (EA Forum; 17 Jun 2023 16:58 UTC; 89 points)
- A summary of current work in AI governance by (17 Jun 2023 18:41 UTC; 44 points)
- Some thoughts on risks from narrow, non-agentic AI by (19 Jan 2021 0:04 UTC; 35 points)
- [AN #120]: Tracing the intellectual roots of AI and AI alignment by (7 Oct 2020 17:10 UTC; 13 points)
- 's comment on Simplify EA Pitches to “Holy Shit, X-Risk” by (EA Forum; 11 Feb 2022 18:08 UTC; 11 points)
- 's comment on My Overview of the AI Alignment Landscape: Threat Models by (26 Dec 2021 6:52 UTC; 11 points)
- 's comment on My Overview of the AI Alignment Landscape: A Bird’s Eye View by (EA Forum; 16 Dec 2021 3:32 UTC; 8 points)
Great post! I especially liked the New Zealand example, it seems like a surprisingly good fit. Against a general backdrop of agreement, let me list a few points of disagreement:
Somewhat of a nitpick, but it is not clear to me that this is an example of problems of short-term incentives. Are we sure that given the choice between “lower crime, lower costs and algorithmic bias” and “higher crime, higher costs and only human bias”, and we have dictatorial power and can consider long-term effects, we would choose the latter on reflection? Similarly with other current AI examples (e.g. the Google gorilla misclassification).
(It’s possible that if I delved into the research and the numbers the answer would be obvious; I have extremely little information on the scale of the problem currently.)
Note ML systems are way more interpretable than humans, so if they are replacing humans then this shouldn’t make that much of a difference. If a single ML system replaces an entire institution, then it probably is less interpretable than that institution. It doesn’t seem obvious to me which of these we should be considering. (Partly it depends on how general and capable the AI systems are.) Overall I’d guess that for WFLL1 it’s closer to “replacing humans” than “replacing institutions”.
I guess you mean here that activations and weights in NNs are more interpretable to us than neurological processes in the human brain, but if so this comparison does not seem relevant to the text you quoted. Consider that it seems easier to understand why an editor of a newspaper placed some article on the front page than why FB’s algorithm showed some post to some user (especially if we get to ask the editor questions or consult with other editors).
Even if so (which I would expect to become uncompetitive with “replacing institutions” at some point) you may still get weird dynamics between AI systems within an institution and across institutions (e.g. between a CEO advisor AI and a regulator advisor AI). These dynamics may be very hard to interpret (and may not even involve recognizable communication channels).
Isn’t this what I said in the rest of that paragraph (although I didn’t have an example)?
I’m not claiming that replacing humans is more competitive than replacing institutions. I’m claiming that, if we’re considering the WFLL1 setting, and we’re considering the point at which we could have prevented failure, at that point I’d expect AI systems are in the “replacing humans” category. By the time they’re in the “replacing institutions” category, we probably are far beyond the position where we could do anything about the future.
Separately, even in the long run, I expect modularity to be a key organizing principle for AI systems.
I agree this is possible but it doesn’t seem very likely to me, since we’ll very likely be training our AI systems to communicate in natural language, and those AI systems will likely be trained to behave in vaguely human-like ways.
I meant to say that even if we replace just a single person (like a newspaper editor) with an ML system, it may become much harder to understand why each decision was made.
The challenge here seems to me to train competitive models—that behave in vaguely human-like ways—for general real-world tasks (e.g. selecting content for a FB user feed or updating item prices on Walmart). In the business-as-usual scenario we would need such systems to be competitive with systems that are optimized for business metrics (e.g. users’ time spent or profit).
Thanks for your comment!
Good point, thanks, I hadn’t thought that sometimes it actually would make sense, on reflection, to choose an algorithm pursuing an easy-to-measure goal over humans pursuing incorrect goals. One thing I’d add is that if one did delve into the research to work this out for a particular case, it seems that an important (but hard to quantify) consideration would be the extent to which choosing the algorithm in this case makes it more likely that the use of that algorithm becomes entrenched, or it sets a precedent for the use of such algorithms. This feels important since these effects could plausibly make WFLL1-like things more likely in the longer run (when the harm of using misaligned systems is higher, due to the higher capabilities of those systems).
Good catch. I had the “AI systems replace entire institutions” scenario in mind, but agree that WFLL1 actually feels closer to “AI systems replace humans”. I’m pretty confused about what this would look like though, and in particular, whether institutions would retain their interpretability if this happened. It seems plausible that the best way to “carve up” an institution into individual agents/services differs for humans and AI systems. E.g. education/learning is big part of human institution design—you start at the bottom and work your way up as you learn skills and become trusted to act more autonomously—but this probably wouldn’t be the case for institutions composed of AI systems, since the “CEO” could just copy their model parameters to the “intern” :). And if institutions composed of AI systems are quite different to institutions composed of humans, then they might not be very interpretable. Sure, you could assert that AI systems replace humans one-for-one, but if this is not the best design, then there may be competitive pressure to move away from this towards something less interpretable.
Yup, all of that sounds right to me!
One caveat is that on my models of AI development I don’t expect the CEO could just copy model parameters to the intern. I think it’s more likely that we have something along the lines of “graduate of <specific college major>” AI systems that you then copy and use as needed. But I don’t think this really affects your point.
Yeah jtbc I definitely would not assert this. If I had to make an argument for as-much-interpretability, it would be something like “in the scenario we’re considering, AI systems are roughly human-level in capability; at this level of capability societal organization will still require a lot of modularity; if we know nothing else and assume agents are as black-boxy as humans, it seems reasonable to assume this will lead to a roughly similar amount of interpretability as current society”. But this is not a particularly strong argument, especially in the face of vast uncertainty about what the future looks like.
I think that most easy to measure goals, if optimised hard enough, eventually end up with a universe tiled with molecular smiley faces. Consider the law enforcement AI. There is no sharp line between education programs, and reducing lead pollution, to using nanotech to rewire human brains into perfectly law abiding puppets. For most utility functions that aren’t intrinsically conservative, there will be some state of the universe that scores really highly, and is nothing like the present.
In any “what failure looks like” scenario, at some point you end up with superintelligent stock traiders that want to fill the universe with tiny molecular stock markets, competing with weather predicting AI’s that want to freeze the earth to a maximally predictable 0K block of ice.
These AI’s are wielding power that could easily wipe out humanity as a side effect. If they fight, humanity will get killed in the crossfire. If they work together, they will tile the universe with some strange mix of many different “molecular smiley faces”.
I don’t think that you can get an accurate human values function by averaging together many poorly thought out, add hoc functions that were designed to be contingent on specific details of how the world was. (Ie assuming people are broadcasting TV signals, stock market went up iff a particular pattern of electromagnetic waves encoding a picture of a graph going up, and the words “finantial news” exists. Outside the narrow slice of possible worlds with broadcast TV, this AI just wants to grab a giant radio transmittor and transmit a particular stream of nonsense.)
I think that humans existing is a specific state of the world, something that only happens if an AI is optimising for it. (And an actually good definition of human is hard to specify) Humans having lives we would consider good is even harder to specify. When there are substantially superhuman AI’s running around, the value of the atoms exceeds any value we can offer. The AI’s could psycologically or nanotechnologically twist us into whatever shape they pleased. We cant meaningfully threaten any of the AI.
We wont be left even a tiny fraction, we will be really bad at defending our resources, compared to any AI’s. Any of the AI’s could easily grab all our resources. Also there will be various AI’s that care about humans in the wrong way, a cancer curing AI that wants to wipe out humanity to stop us getting cancer. A marketing AI, that wants to fill all human brains with coorporate slogans. (think nanotech brain rewrite to the point of drooling vegetable)
EDIT: All of the above is talking about the end state of a “get what you measure” failure. There could be a period, possibly decades where humans are still around, but things are going wrong in the way described.
This was helpful to me, thanks. I agree this seems almost certainly to be the end state if AI systems are optimizing hard for simple, measurable objectives.
I’m still confused about what happens if AI systems are optimizing moderately for more complicated, measurable objectives (which better capture what humans actually want). Do you think the argument you made implies that we still eventually end up with a universe tiled with molecular smiley faces in this scenario?
I think that this depends on how hard the AI’s are optimising, and how complicated the objectives are. I think that sufficiently moderate optimization for goals sufficiently close to human values will probably end up well.
I also think that optimisation is likely to end up at the physical limits, unless we know how to program an AI that doesn’t want to improve itself, and everyone makes AI’s like that.
Sufficiently moderate AI is just dumb, which is safe. An AI smart enough to stop people producing more AI, yet dumb enough to be safe seems harder.
There is also a question of what “better capturing what humans want” means. A utility function, that when restricted to the space of worlds roughly similar to this one, produces utilities close to the true human utility function, seems easy enough. Suppose we have defined something close to human well being. That definition is in terms of the level of various neurotransmitters near human DNA. Lets suppose this definition would be highly accurate over all history, and would make the right decision over nearly all current political issues. It could still fail completely in a future containing uploaded minds, and neurochemical vats.
Either your approximate utility function needs to be pretty close on all possible futures (even adversarially chosen ones) or you need to know that the AI won’t guide the future towards places that the utility functions differ.
Regarding “CAIS scenario” vs “general AI” scenarios, I think that there are strong forces pushing towards the latter. For any actor that’s interested in economic, political or military gain, there are large returns on long-term planning applied to open-ended real-world problems. Therefore there are strong incentives to create systems capable of that. As you correctly notice, such systems will eventually converge to extremely malicious strategies. So, there is a tragedy of the commons pushing towards the deployment of many powerful and general AI systems. In the short-term these systems benefit the actors deploying them, in the long-term they destroy all human value.
Planned summary for the Alignment Newsletter:
Planned opinion:
Random note: initially I thought this post was part 1 of N, and only later did I realize the “part 1” was a modifier to “what failure looks like”. That’s partly why it wasn’t summarized till now—I was waiting for future parts to show up.
Minor typo: “WFFL1 assumes that AI is “responsible for” a very large fraction of the economy” should be “WFLL1″
Thanks!
Thanks for this. I’m a little late to getting to it.
I’m finding the state capture elements of this and loss of decision autonomy especially convincing and likely underway. I’m actually writing my thesis to focus on this particular aspect of scenarios. I’m using a scenario mapping technique to outline the full spectrum of risks (using a general morphological model), but will focus the details on the more creeping normalization and slow-moving train wreck aspects of potential outcomes.
Please help with data collection if any of you get a free minute. https://www.surveymonkey.com/r/QRST7M2 I’d be very grateful. And I’ll publish a condensed version here asap.