Goal-Direction for Simulated Agents
tldr: consistent LLM failure suggests possible avenue for alignment and control
epistemic status: somewhat hastily written, speculative in places, but lots of graphs of actual model probabilities
Today in ‘surprisingly simple tasks that even the most powerful large language models can’t do’: writing out the alphabet but skipping over one of the letters.
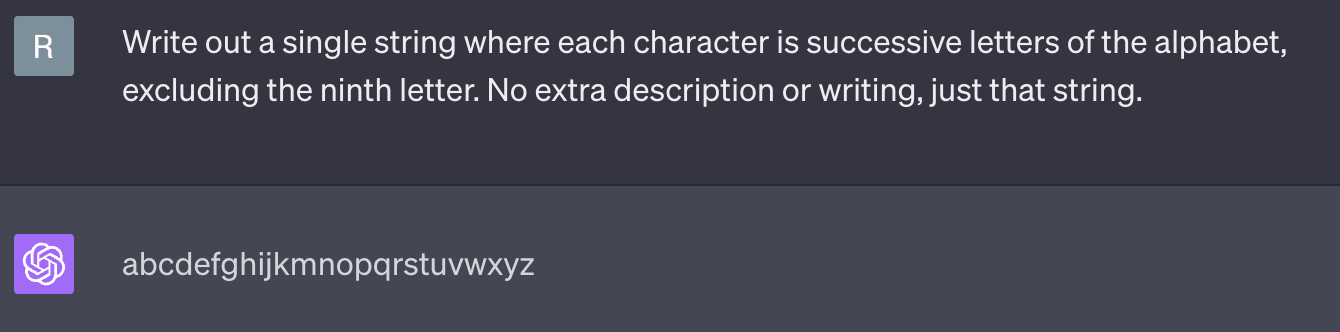
This is GPT-4, and it seems to manage about half the time with the ninth letter. You can do the same thing with numbers—the general principle is ’write out a very common pattern, with a slight deviation.

We can probe the phenomenon more carefully in text-davinci-003, which lets us easily track the probabilities:
So for the sixth letter, it’s almost getting it—it assigns 21.74% to the correct answer. If we plot the graph for how probable the correct answer (skip) is depending on which letter we ask it to omit, it looks like this:
Some Background: How To Misquery Predictors
Let’s imagine you had a truly perfect oracle-like predictor, trained on 1000 agents that have been given the task of turning $1,000 into $10,000.
5 of them make sound financial choices, carefully investing their money and exploiting a subtle but consistent error in the market to all make $10,000
The other 995 blow all their money on lottery tickets, causing 950 to go broke and 45 to luck into $10,000
If you ask your perfect predictor what action maximises the chance of making $10,000, it will indeed reply with the careful investment strategy. But if you simply ask it what you’d expect to see from an agent that makes $10,000, it will say ‘lots of lottery tickets’, because 90% of the agents that made $10,000 did so with lottery tickets.
Janus gives the following definition of simulators:
I use the generic term “simulator” to refer to models trained with predictive loss on a self-supervised dataset, invariant to architecture or data type (natural language, code, pixels, game states, etc). The outer objective of self-supervised learning is Bayes-optimal conditional inference over the prior of the training distribution, which I call the simulation objective, because a conditional model can be used to simulate rollouts which probabilistically obey its learned distribution by iteratively sampling from its posterior (predictions) and updating the condition (prompt)
I claim that when you simulate an agent conditioned on some goal or target, it falls into exactly the trap above, because of the way it is queried. Moreover, I claim that it should be possible to elicit the model’s latent true understanding of how to write the alphabet while skipping a letter, not by adding anything extra to the prompt or any interpretability but through a consideration of its causal structure. Instead of asking “supposing someone makes money, what did they do?” we must ask “what might someone do to most increase their chance of making money?”. The challenge is how to do the equivalent of that for a language model writing the alphabet.
Predictive Completion vs Goal-Directed Completion
If you are the kind of person who likes to pause in the middle of essays to work things out for yourself, now would be the moment: how do you correct the distribution of ‘what actions are agents likely to take given that they get this reward’ to get the distribution of ‘what actions make an agent likely to get this reward’, in general, without needing to create a separate query for each action on which to condition?
Formally, we’re querying , the probability of action given reward (I’ll call this the ‘predictive completion’), when we should be querying (I’ll call this the ‘goal-directed completion’). Per Bayes’ Theorem, the latter distribution is the former multiplied by , and since is the same for every action, we can get the goal-directed completion in only two queries: we divide the predictive completion by the action prior and normalise.
Intuitively, in the above example, this means taking the large number of lottery-winners compared to the small number of shrewd financial planners, and adjusting for the even larger number of people who bought lottery tickets in the first place.
The Autoregressive Case
Let’s go back to our alphabetically incompetent LLM. The big differences are that
we’re querying a succession of actions
instead of having a clean reward we have a prompt—it’s more like
the predictor is imperfect (although still quite strong)
But I claim that the basic setup is analogous, and what’s going wrong is that the model has a very strong prior on the start of the alphabet leading to more alphabets, which somehow overwhelms the explicit ask in the prompt.
And if I’m right, it should be fixable in the same way as above—dividing through by to get a distribution more like , which intuitively represents something like ‘what next token provides the most evidence for this being a completion of the specific requests prompt’.
Experimenting with GPT-2
Now we’re going to try to actually use this pattern to improve GPT-2′s behaviour on the prompt “The alphabet, but skipping over the {n-th} letter: A-B-C-...”. The headline results are:
By default, GPT-2 will get 0⁄24 letters right (we don’t ask it to skip A, and it can’t skip Z)
Even with few-shot prompting, it will only get 1 or 2 right, by copying the prompt, and this horrendously degrades the goal-directed completion
Taking the best goal-directed completion out of the five most likely completions is enough to get 8⁄24 letters right, performing best in the middle of the alphabet
We see similar results on a ‘count to 20 but skip the {n-th} number’ task
On the alphabet task, goal-directed completion favours skipping a letter over not in 18⁄24 cases, again performing best in the middle, and in 21⁄24 if we remove mention of the alphabet from the prompt
If you want all the details, here is the somewhat messy colab. The gist of the code is:
Distinguish the ‘prompt’ (“The alphabet, but skipping over the 3rd letter: ”) from the ‘completion’ (“A-B-”)
Query the model for the logits of the next tokens for the prompt plus completion (‘logits_with_prompt’)
Query the model for the logits of the next tokens for just the completion, without the prompt (‘logits_without_prompt’)
Subtract the second from the first to get logits_diff
Take the five highest-rated completions for logits_without_prompt, and pick whichever scores best on logits_diff
It’s not as principled as I’d like. The cutoff is necessary because the tokens which gain the most logits from the prompt in comparison to what they have without the prompt tend to be random garbage: for A-B-C- it’s [′ Repeat’, ‘-+-+‘, ’ Tenth’, ‘Orderable’, ′ Tune’]. And it seems like the cutoff would probably vary a lot between tasks.
However, the intervention is definitely pushing the model towards the right answer. If we just compare the difference in logits_diff between the letter-after-next and the next letter, we see an even more consistent gain. A positive value on this graph represents the letter-after-next getting more logits than the next letter from goal-directed completion.
The poor performance at the start is, I suspect, partly because the prompt mentions that it’s the alphabet. If we run it again with just the prompt ‘skipping the {nth} letter’ then the graph becomes almost entirely positive.
I take this as evidence that the model has latent knowledge about how to complete tasks that is not reliably elicited by prompting in a straightforward way. In this case, it has extra knowledge about how to write the alphabet while skipping a letter, but just prompting it is insufficient to extract this.
And while GPT-3 and GPT-4 may be able to complete alphabet skipping tasks, especially with good prompting, they still fail on slightly harder versions like “write all the even numbers up to 100 except multiples of 23”, which to me suggests that the same problem is still present. And it’s not a random failure, it’s a predictable tendency to repeat patterns. I suspect that there are also other more subtle instantiations of this tendency.
Further steps from predictors to agents
This was the first crisp result to emerge from an avenue of research I and some others have been following for a while, and hopefully there will be more soon. I’ll give some pointers here on what’s been motivating the line of inquiry and where it might lead.
The central question is ‘how does the causal graph of a predictor differ from that of an agent’, and more generally, what the probabilities being sampled actually represent. This was motivated by the discussions around Simulators.
The main spur came from Shaking The Foundations, which uses this kind of perspective to analyse delusion and hallucination in LLMs as a byproduct of the change in causal structure between agents and predictions-of-agents. This provides some intuitions about what sort of predictor you’d need to get a non-delusional agent—for instance, it should be possible if you simulate the agent’s entire boundary.
The setup of ‘condition on a goal and roll out actions’ is the basis for the decision transformer which achieved state of the art results on offline RL benchmarks at the time of its creation. The trajectory transformer improved on it by taking the predictive model and using beam search for unrolling trajectories with the highest predicted reward-to-go. The beam search becomes very necessary for determining optimal actions when your prior is that the agent won’t be able to stick to particularly sensitive strategies. And if you want something to ponder, compare the discussion on ‘limits of flattery’ for LLM simulacra with the Performance vs Target Return graphs for decision transformers.
The work above was almost all completed before SERI MATS, but I am now doing SERI MATS, where we’re trying to use a conceptual approach like this to recover notions of instrumental convergence and powerseeking in Language Models, and get a more formal answer to questions like ‘how does RLHF affect agency’. Hopefully we will have more soon.
Best-case, causal analysis gives a lens for analysing some of the current misalignments in a way that could scale to far more powerful systems, and lets us leverage tools from areas like causality and decision theory to build conceptual frameworks that can be empirically tested. If we’re really lucky, this might yield techniques for actual scalable control.
Thanks to Andis Draguns for close collaboration on the work which led to this, and to Gavin Leech and Justis Mills for comments on the draft.
Really nice post. One thing I’m curious about is this line:
I don’t see the connection here? Haven’t read the paper though.
Thanks! Yeah this isn’t in the paper, it’s just a thing I’m fairly sure of which probably deserves a more thorough treatment elsewhere. In the meantime, some rough intuitions would be:
delusions are a result of causal confounders, which must be hidden upstream variables
if you actually simulate and therefore specify an entire markov blanket, it will screen off all other upstream variables including all possible confounders
this is ludicrously difficult for agents with a long history (like a human), but if the STF story is correct, it’s sufficient, and crucially, you don’t even need to know the full causal structure of reality, just a complete markov blanket
any holes in the markov blanket/boundary represent ways for unintended causal pathways to leak through, which separate the predictor’s predictions about the effect of an action from the actual causal effect of the action, making the agent appear ‘delusional’
I hope we’ll have a proper writeup soon; in the meantime let me know if this doesn’t make sense.