Reflectively stable consequentialists are expected utility maximisers
Epistemic status: Theorem.
When we look at the world we see a repeating pattern: people, corporations, bacteria, even some AIs; we call them agents. They take in sensory data and spit out actions that tend to move the world in a certain direction. Given the fact this pattern does exist, we might then ask: but what exactly is an agent? Is it a binary property? In principle, could we take a model of the world and have a computer program identify all the agents within? Why do they act they way they do? How could, in principle, such a thing behave? If we are agents, does our membership in this class, on its own, say something about how we ought to behave?
Arguably, the closest thing we have to an answer are the so called coherence theorems, of which there are a few. They basically say that if some entity’s behaviour is reasonable, in some sense, they must act in some particular way. And that way is expected utility maximisation: given a set of possible actions, each with an associated probability distribution, called a lottery, over outcomes, we must assign a number to each outcome, its utility, and pick the action with the highest utility in expectation.
Explaining how each coherence theorem works is beyond the scope of this post (for an introduction see e.g. this or this), but to see the issues with them, let’s start with what is perhaps the most famous one around here: the Von Neumann-Morgenstern (VNM) utility theorem. It talks about preferences over pairs of lotteries. For all lotteries
If
If
Keep in mind that lotteries are probability distributions, which can be treated as vectors
then the theorem says that we can assign an utility to each possible outcome such that
And sure, these all seem reasonable, but must agents act that way? Is there really something wrong with e.g. when given the pair of options
We can also generalise the previous argument to work with lotteries, and (with some caveats) that kind of reasoning (also called a Dutch book argument) can be used to try to justify the other assumptions. In any case, the other assumptions are a bit more questionable, and have been endlessly questioned.
Savage’s theorem is similar to VNM’s, and other theorems are even worse: e.g. the complete class theorem and Peterson’s direct argument both start by assuming agents have an utility function, with bigger values always being better.
Here, I present a simple and arguably stronger case for expected utility maximisation, one that doesn’t start by basically assuming that what we have is already an optimiser. Since we are interested in a subset of the things in the world (agents), we need to put some bits into specifying which things those are. The assumption is, roughly speaking, that agents, if given the choice, choose to behave like they do behave. This can be turned into two formal criteria, which I’ll call axioms:
Axiom 1: Consequentialism
Let’s define a scenario to be an ordered list of lotteries, where:
As before, each lottery is a probability distribution over the set of possible outcomes.
The set of outcomes is finite and the same for all lotteries of all scenarios.
Each index in each of lotteries corresponds to an action an agent can take. If that action is chosen, the outcome is sampled from the corresponding lottery.
In each scenario, the number of possible actions is always the same. This number is finite, but at least two. Actions are only identified by their index.

Faced with a scenario, an agent “outputs” a probability distribution over the actions. This distribution (like all others here) is allowed to be deterministic (gives probability 1 to some action). To get an outcome, we first sample the action distribution and then the outcome distribution of the associated lottery. If we weight each lottery (compute a weighted average of their vectors) by the probability of their associated action, we get a new lottery over outcomes. We say that the agent’s action distribution leads to this outcome distribution.
The behaviour of an agent is called consequentialist if it is a function from the list of lotteries of whichever scenario they face to a distribution over actions. Phrased another way, given a consequentialist agent and a scenario, the probability distribution over actions is completely determined by the (ordered) list of lotteries of that scenario.
For example, an agent that always picks the same action is a consequentialist. So is one that always picks an action uniformly at random. So is one that assigns numbers to outcomes and picks the action with the expected value closest to 12. Any function to valid probability distributions over actions is allowed, no matter how nonsensical.
If the action distributions depend on anything else, the behaviour is not consequentialist.
Axiom 2: Reflective stability
To motivate the definition, consider the leader of an organisation. They usually take actions, which then lead to consequences. But today they have to take a very special kind of action: they are retiring, and need to choose their successor. Their successor, whoever it may be, will face some scenario, unknown a priori, and will also have to take a (possibly stochastic) action, that will lead to consequences.
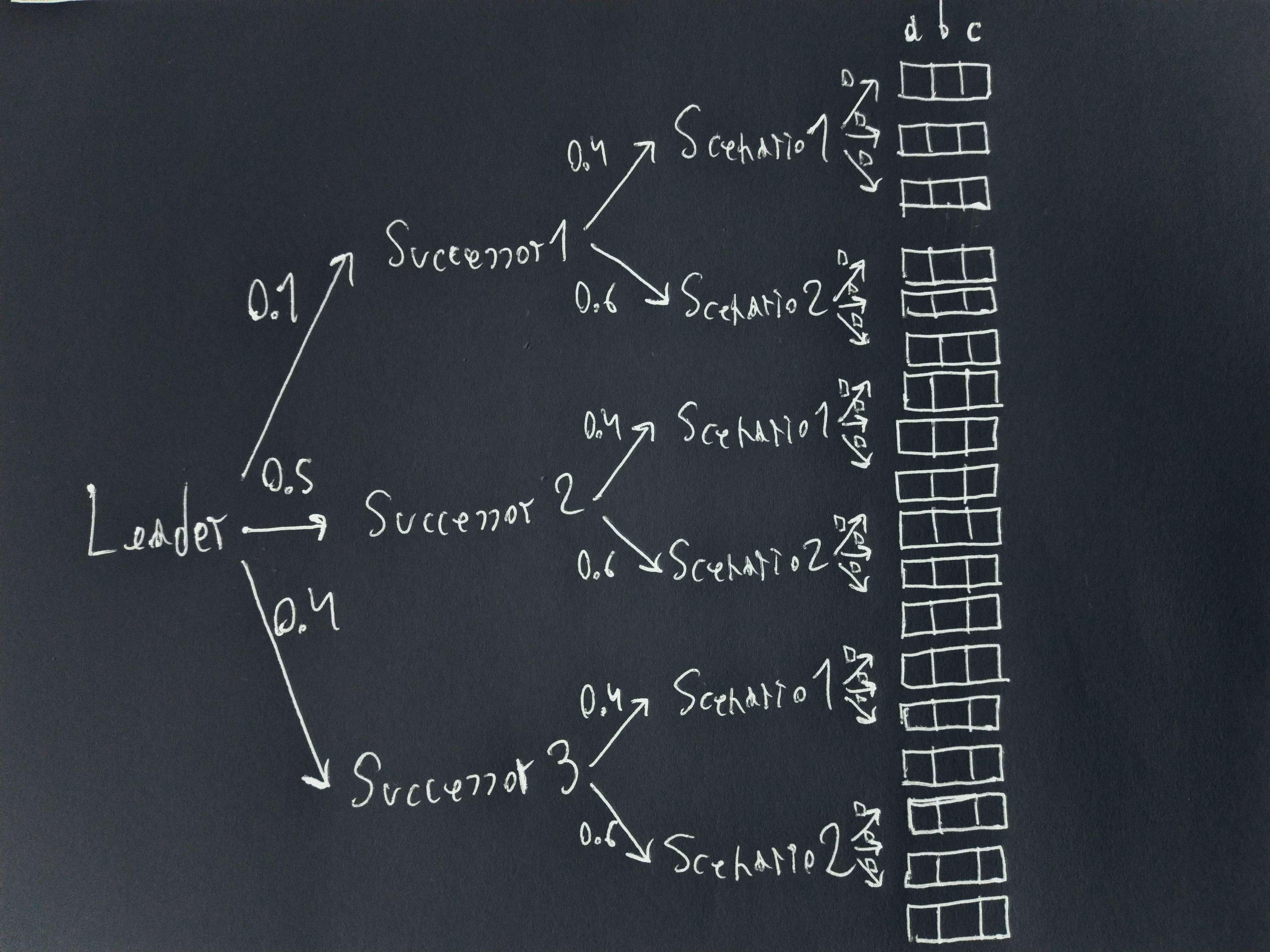
This can be formalised into a succession setup. It consists of the leader (an agent), a set of possible successor agents, a set of scenarios (always the same finite number, but at least two) and a probability distribution over those scenarios. It works as follows:
The leader produces a probability distribution over actions, each action associated with a possible successor.
An action is sampled an a successor is chosen.
The probability distribution over scenarios (independent of the chosen successor) is sampled, and a scenario is chosen.
The successor is faced with the scenario, and produces a probability distribution over possible actions.
An action is sampled and an outcome lottery is chosen.
The outcome lottery is sampled, leading to some concrete outcome.
At each node of the tree this creates, from the leaves to the root, the outcome distribution is computed as an appropriately weighted sum of the outcome distributions of each of the following nodes. The situation the leader faces when choosing a successor is itself a scenario (following the same rules as the others, which means the number of successors is the same as the number of actions), but for clarity won’t be referred to as such.
For two scenarios, three available actions and three possible outcomes, the drawing above depicts what such a succession setup could look like.
Now, there are two kinds of leaders: those that pick successors that would do the same as they would, and those that don’t. Organisations with leadership that chooses successors that behave like they do, can keep on behaving in whatever way they do, and those that don’t, well… don’t. This change in behaviour could in principle even imply losing the property of choosing successors that don’t behave like the current leader. In a word, the behaviour of this second kind of organisation is unstable.
We could call a leader reflectively stable iff, on all succession setups where they are the leader, they pick a successor that on each scenario produces the same action distribution as they themselves would. Although ideally reflective stability would be defined for agents in general, for the sake of clarity this definition and the ones that follow only apply to consequentialist leaders, and the successors are characterised by the action distributions they produce on each of the available scenarios.
An obvious problem with this definition is that it could be the case that there is no such successor. So we can change the criterion to: whenever there is at least one successor that on each scenario produces the same action distribution as the leader would, the leader should pick one such successor.
Then, it could also be the case that on some scenario there exists some other action distribution that leads to the exact same outcome distribution (which could happen e.g. if two different actions have the exact same consequences). It doesn’t make much sense to require that the action distributions be exactly the same, if the outcomes are identical. Therefore, we can change the criterion again to be: whenever there is at least one successor that on each scenario (for that same successor) leads to the same outcome distribution as the leader would, the leader should pick one such successor.
Finally, to deal with the case where there are multiple acceptable successors, we can change the criterion to be: whenever there is at least one successor that on each scenario (for that same successor) leads to the same outcome distribution as the leader would (let’s call these valid successors), the outcome distribution at the root node should be identical to the outcome distribution that would result if the leader were to pick a valid successor (or, equivalently, themselves, if they were available). Notice that this is a weaker condition than the previous one, which is good if we want to prove its implications. If this sounds confusing[1], keep reading, and you will see that it’s geometrically intuitive.
And that’s it, no more assumptions are needed. These two combined give my theorem:
Theorem: Reflectively stable consequentialists are expected utility maximisers
Or, more precisely, among consequentialists, for some number of available actions and some set of outcomes, these two conditions are equivalent:
Being reflectively stable with respect to any choice of number of scenarios.
Being an expected utility maximiser.
I’ll leave exactly what counts as an expected utility maximiser to a later section, for reasons that will then be clear.
Proof
For visualisation purposes, let’s use 3 possible outcomes:
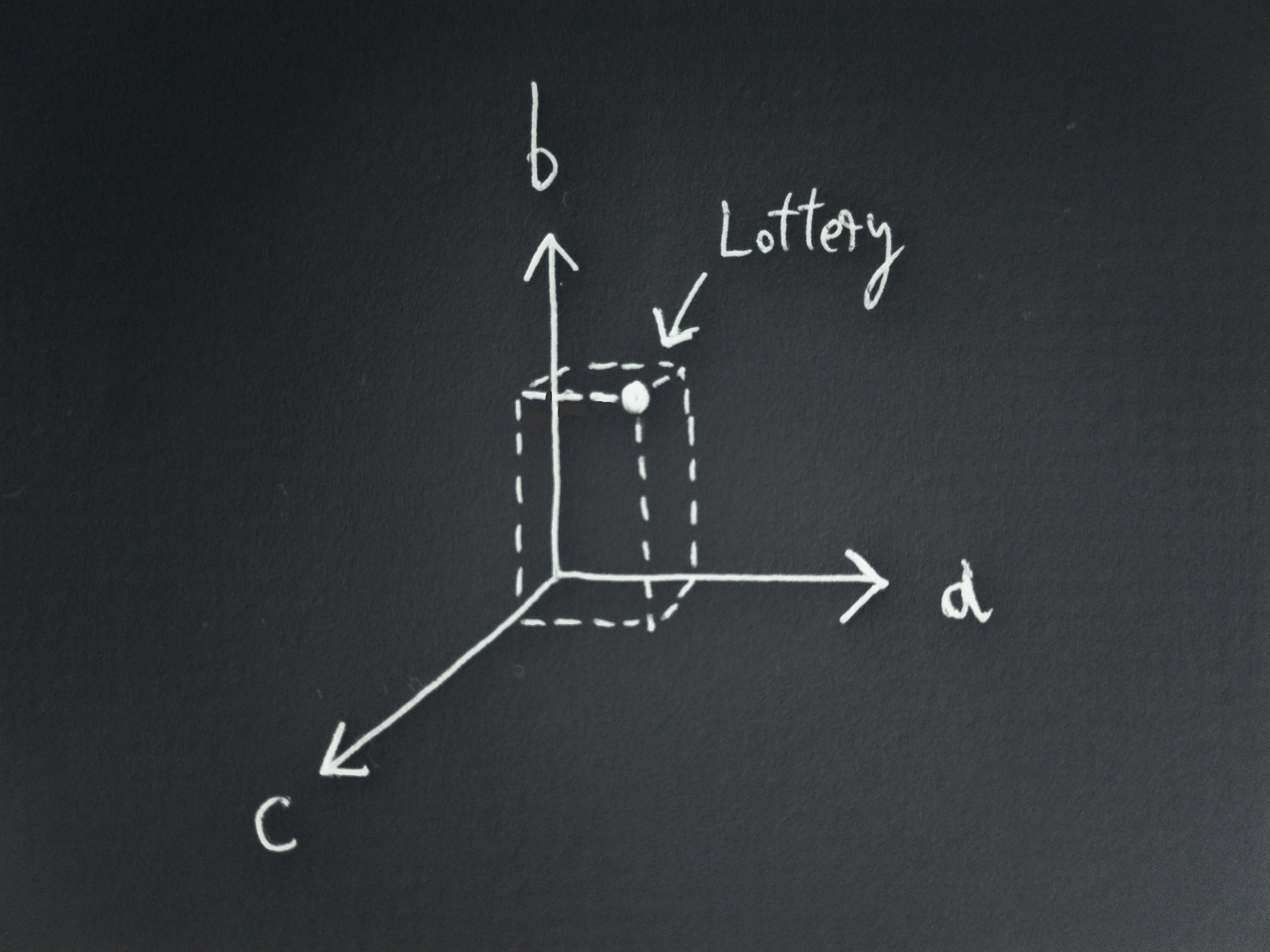
Since the probabilities must sum to one, all the valid lotteries lie on the plane that passes through
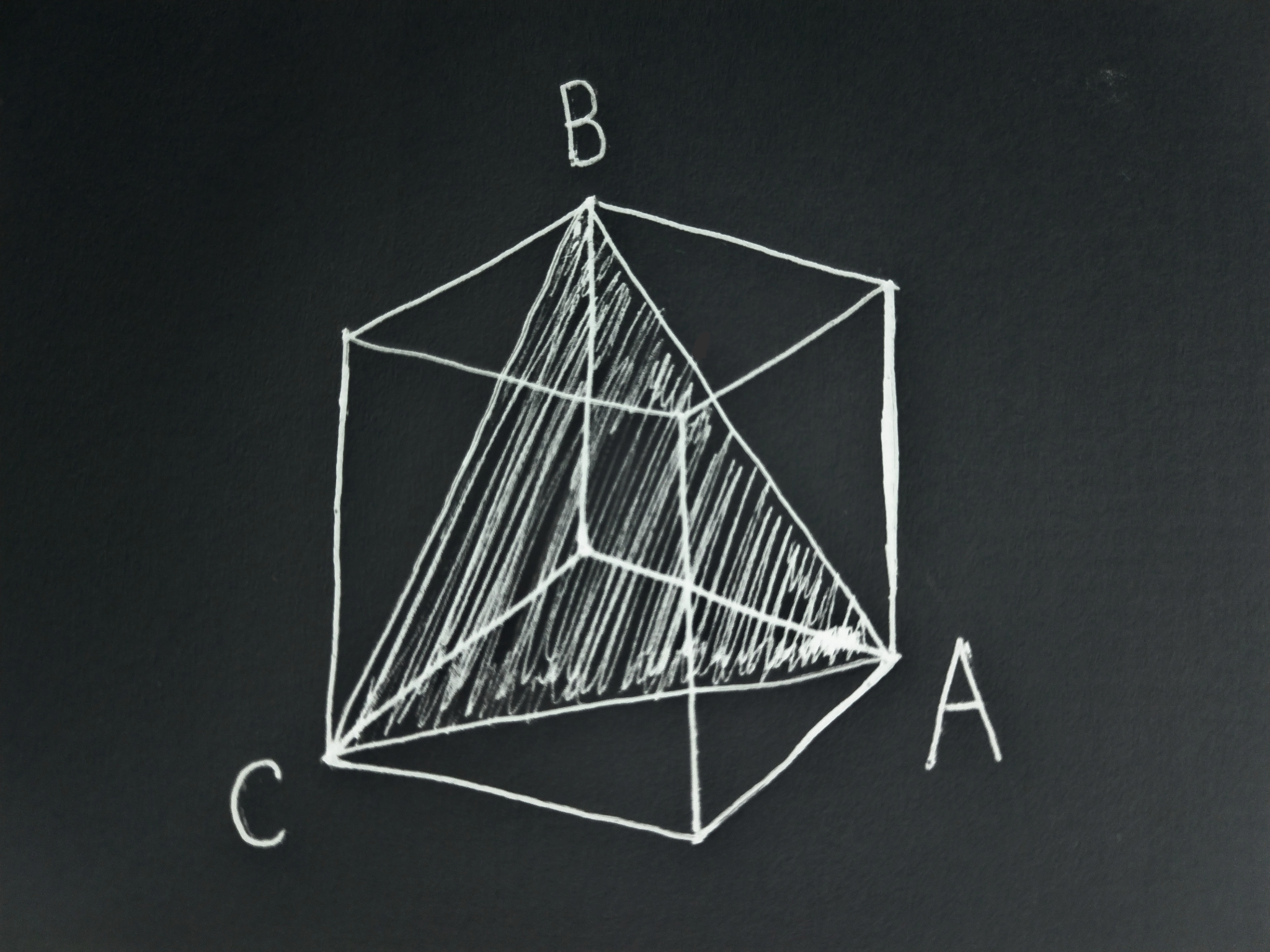
This is the equilateral triangle with vertices at

Importantly for us, this set is convex, that is, given any pair of points within, the segment connecting them is completely within the set. This is the case for any number of outcomes. If we have some
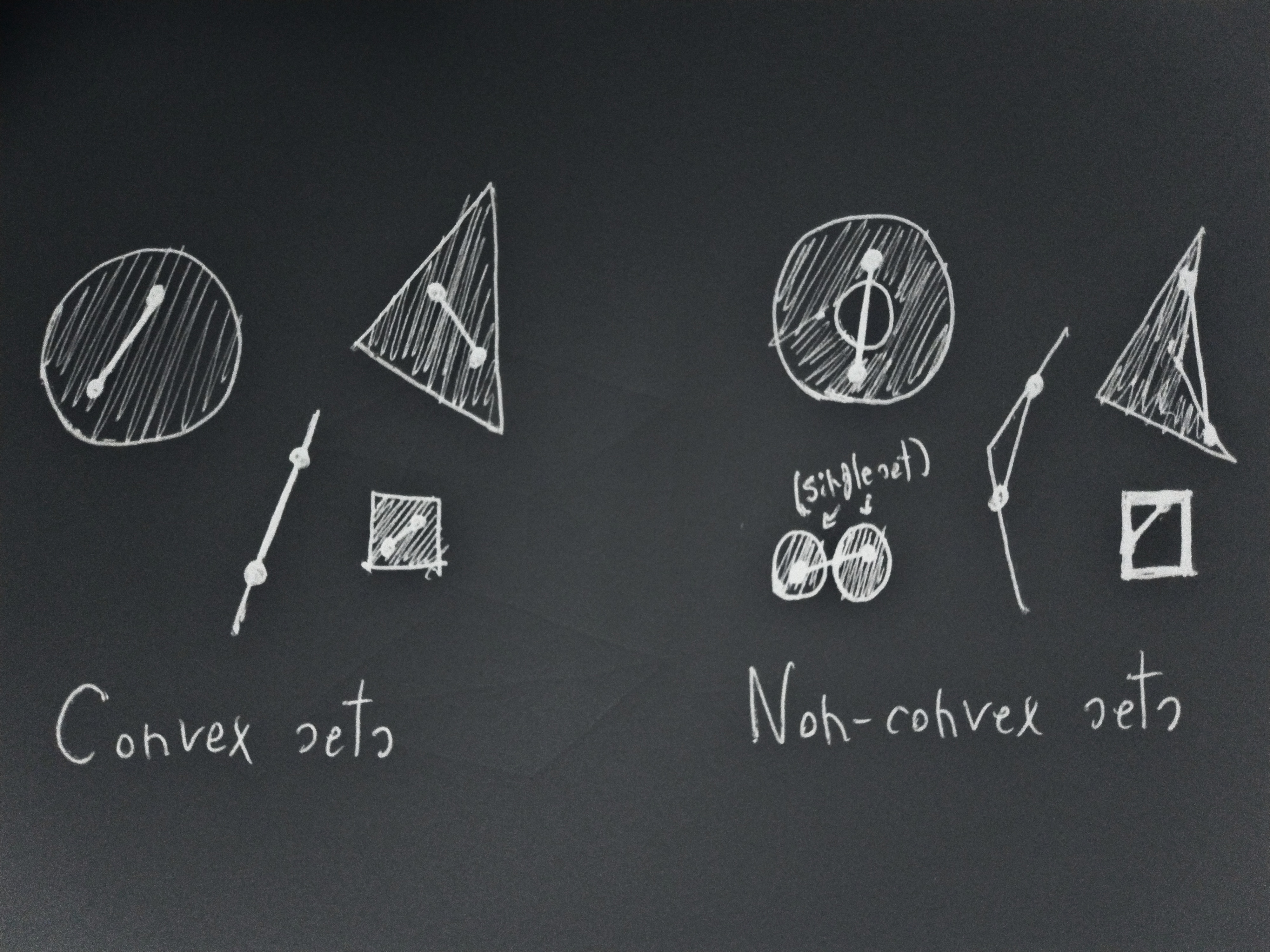
Now, consider two scenarios, each with 3 available actions:
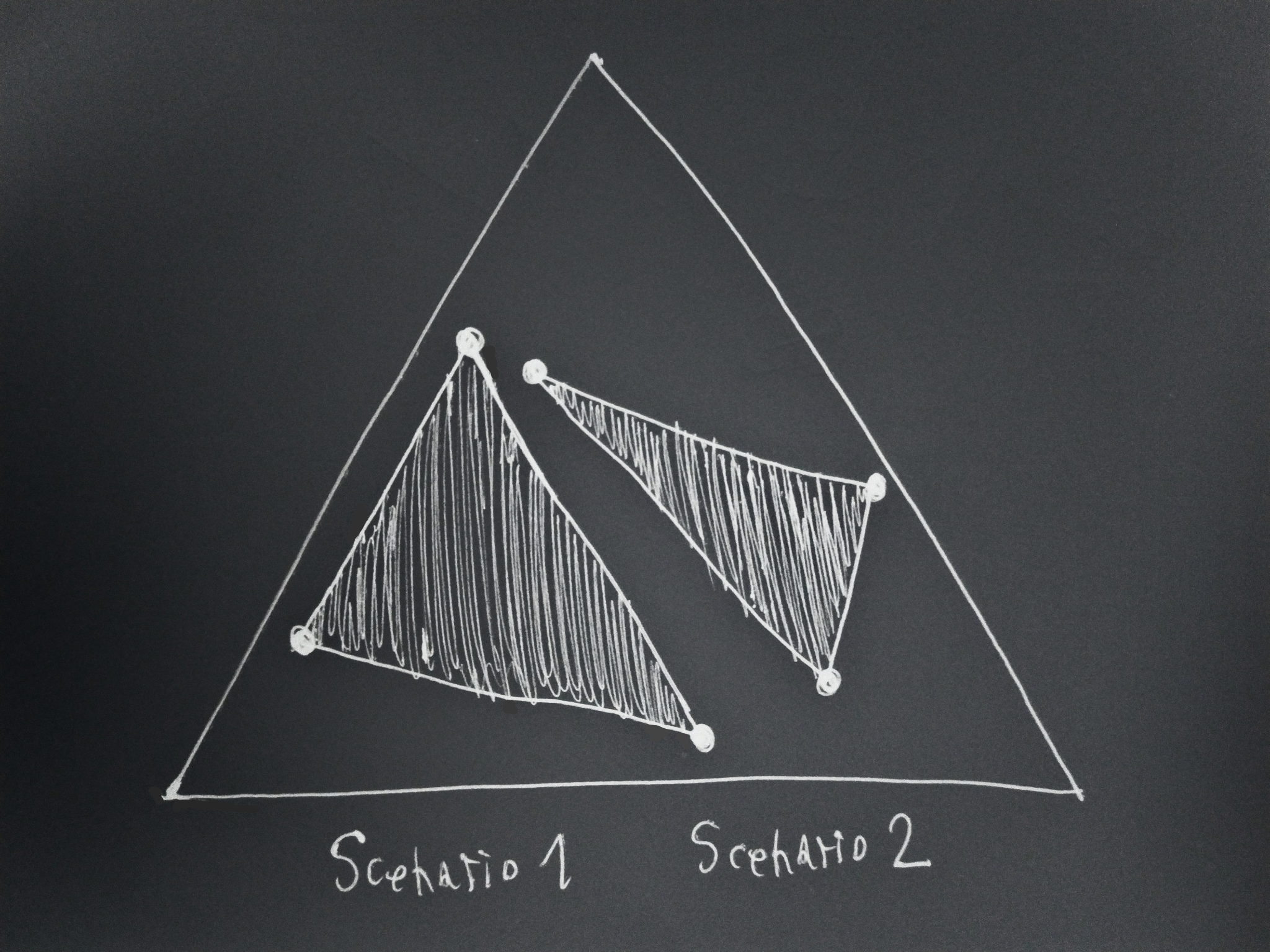
Each vertex of the two inner triangles corresponds to the lottery of one of the three available actions in their associated scenario. Agents can choose any distribution over the actions available in each scenario, and therefore any point in the triangles formed by those actions. In general, an agent in a scenario can choose any point that lies in the convex hull[2] of the lotteries of the available actions. Also in general, multiple distributions over actions might lead to the same final lottery, but that won’t matter for the proof, and in the drawing above the correspondence between action distributions and outcome lotteries is one-to-one.
Then, consider three agents, one of which is a valid successor (which, remember, on each scenario leads to the same outcome distribution as the leader would). In each scenario they choose an outcome distribution:
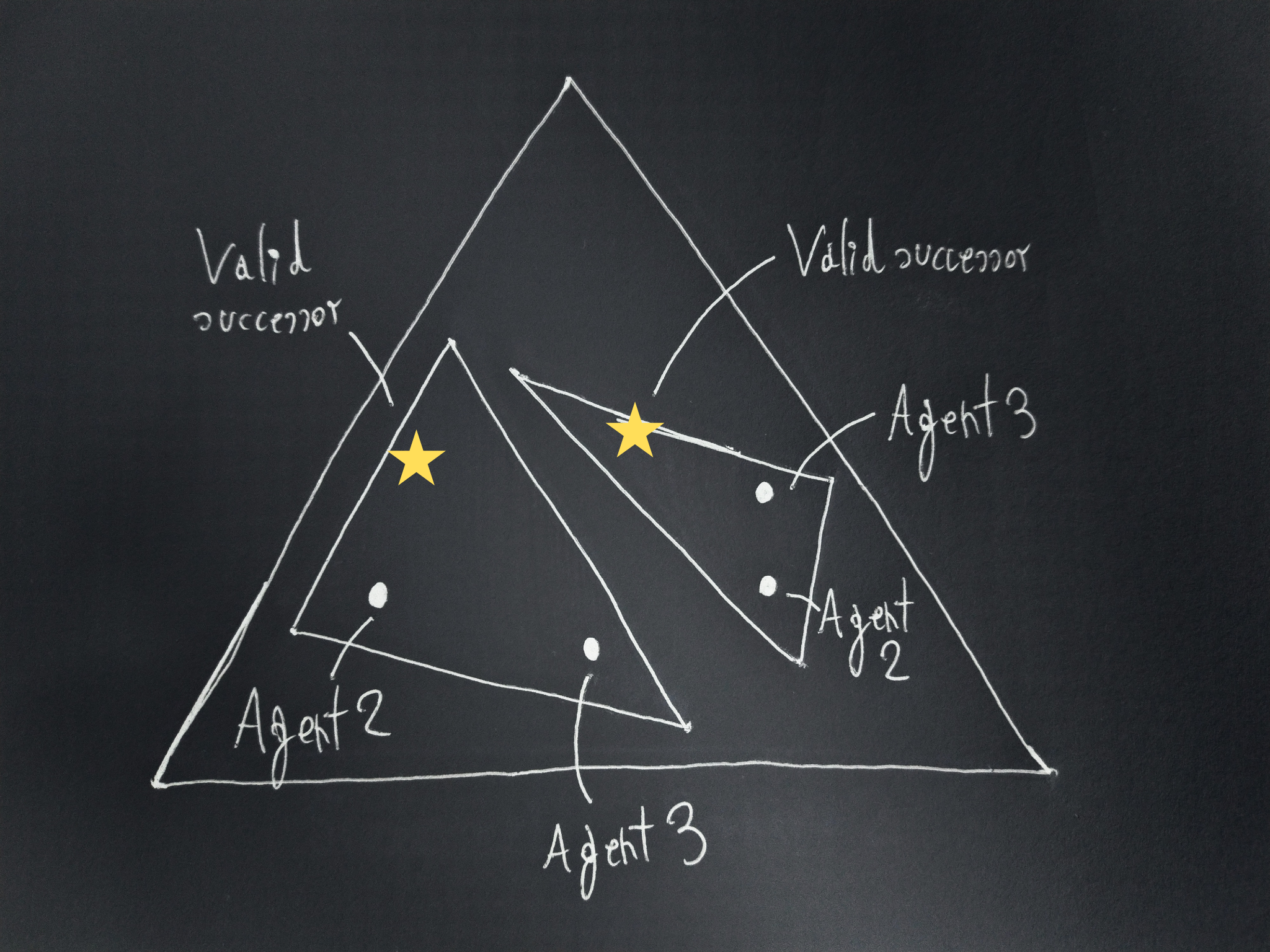
It’s important to keep in mind that for consequentialists the order of the actions matters, which isn’t depicted in the drawings.
Immediately after the leader chooses a successor, we have a probability distribution over scenarios. This is the same for all agents, and serves to interpolate over their lotteries. In the case above, and removing the triangle of all lotteries to avoid clutter, it could look as follows:
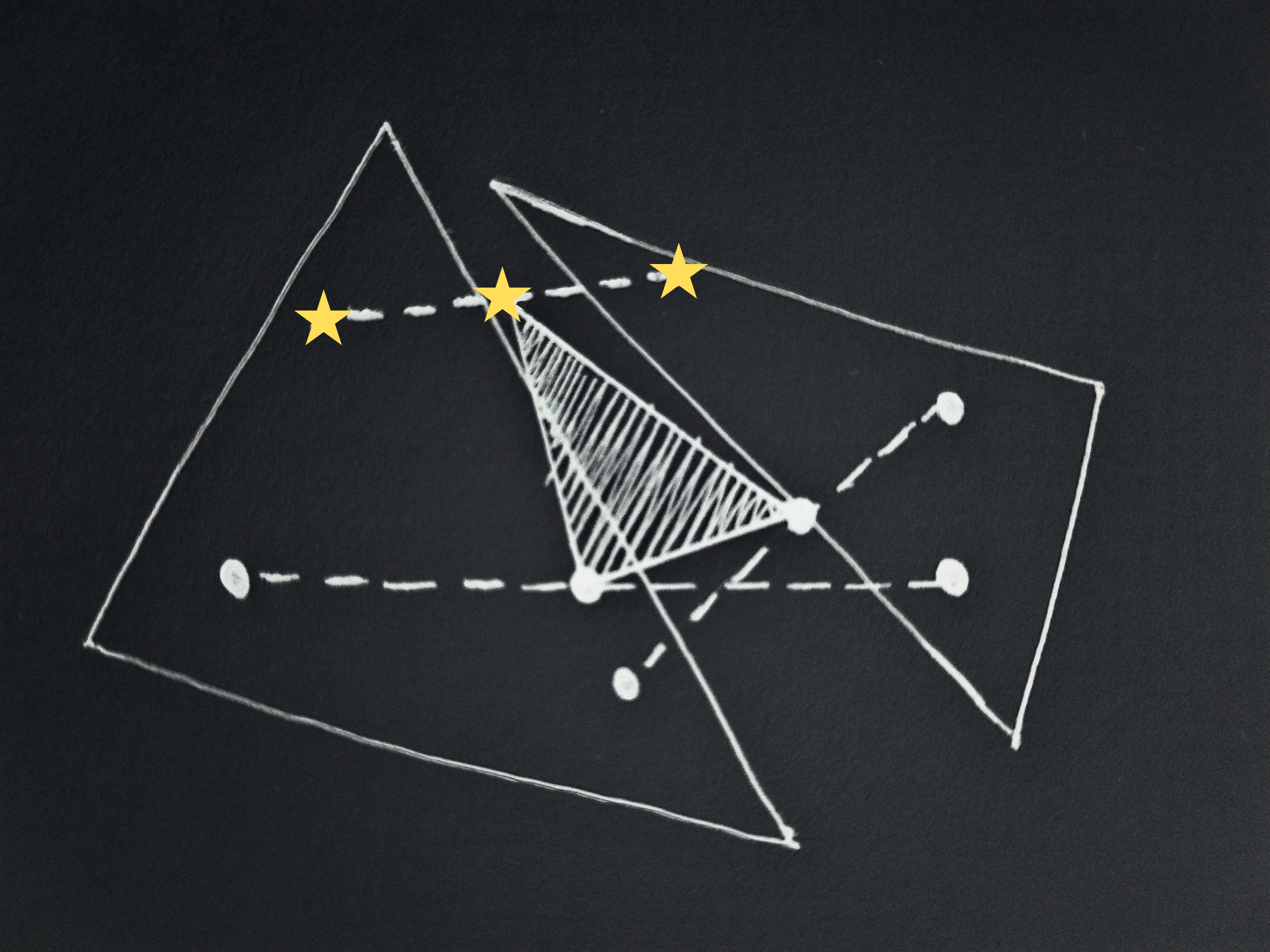
The brightened area represents all the lotteries the leader could choose from by picking a probability distribution over successors. A consequentialist is reflectively stable if when given the interpolated lotteries of each agent (in any order) its action distribution leads to picking the lottery produced by the (a) valid successor.
Consider the lottery the leader would choose when faced with some scenario. There will be a set of directions in which we could move that point while remaining in the set of achievable lotteries. Let’s call these free directions and the non-zero vectors from the choice of the agent to some other achievable point difference vectors or

Then we have:
Lemma 1: For a reflectively stable consequentialist there is no pair of scenarios where in one a direction is free and in the other the opposite direction is also free
The proof will be by contradiction: If such free directions exist for a pair of scenarios, it is possible (details below) to create two succession setups where the scenario presented to the leader (choice of successor) is exactly the same, but they must pick a different outcome distribution in each to be reflectively stable. Since the action distribution of a consequentialist is a function of the available lotteries, so is the outcome distribution, and functions must produce the same outputs given the same inputs, therefore we have a contradiction.
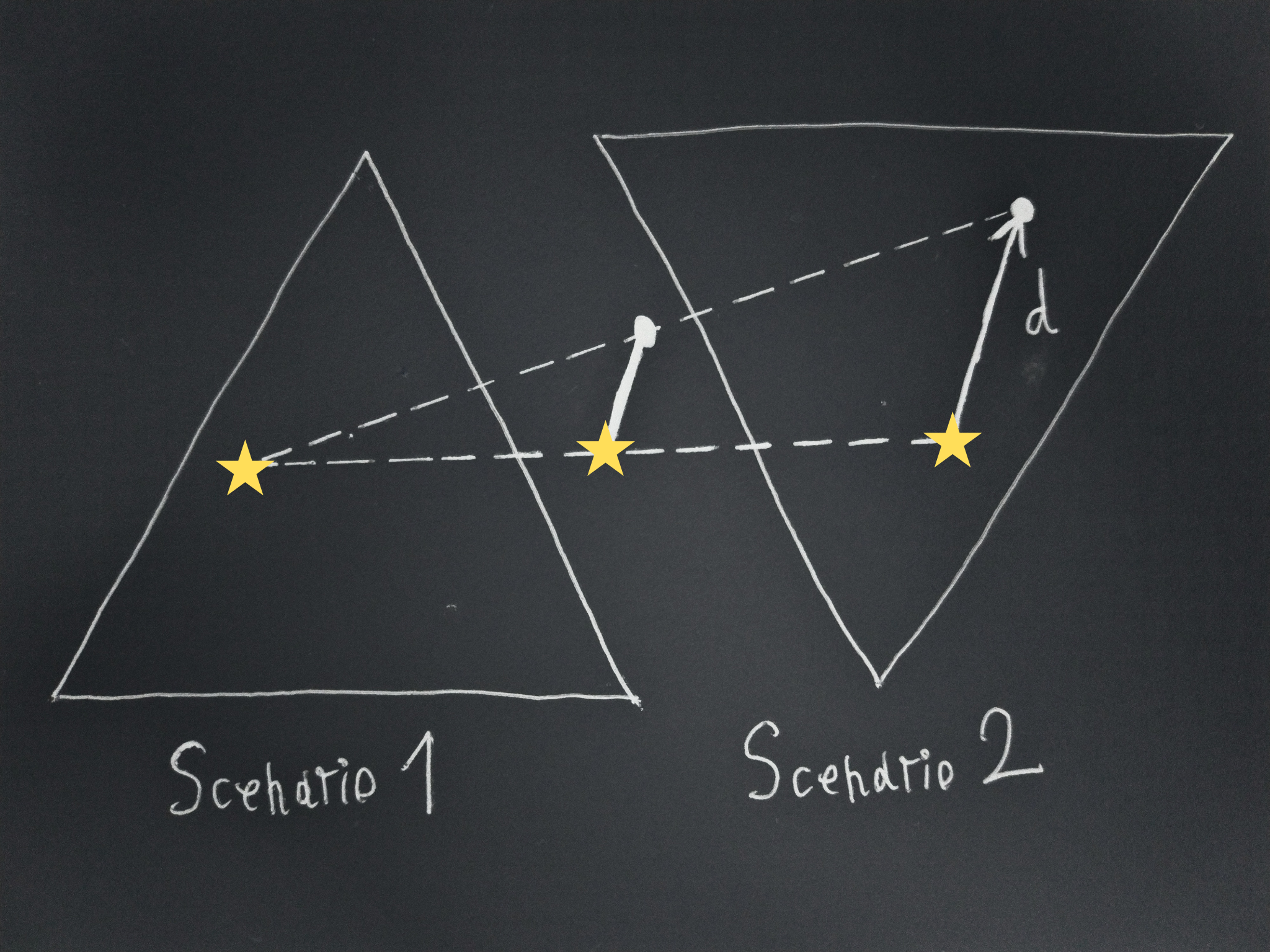
Consider any pair of scenarios, let’s call them 1 and 2. They could even be identical, but the order of the actions matters.
Let’s call:
⭐ ⭐
Assume it is possible for some action distribution and some (non-zero) vector d to lead to:
⭐ ⭐
Then we can create the following succession setups:
Setup 1
Scenarios
Scenario 1 (arbitrary), with probability
Scenario 2 (arbitrary), with probability
Other scenarios (arbitrary, if any exist), with probability
Remember we are considering some fixed number of scenarios on all setups
Agents (in this order)
Valid successor
In scenario 1, leads to
⭐ In scenario 2, leads to
⭐ In other scenarios (if any exist), they lead to arbitrary lotteries
Given scenario uncertainty, this agent leads to
⭐ ⭐ This is what the whole setup should lead to for the leader to be reflectively stable
Agent 2
In scenario 1, leads to
⭐ In scenario 2, leads to
⭐ In other scenarios (if any exist), they lead to arbitrary lotteries
Given scenario uncertainty, this agent leads to
⭐ ⭐
Other agents (if any exist)
In scenario 1, they each lead to arbitrary lotteries (can differ between agents), let’s call them
In scenario 2, they each lead to
⭐ In other scenarios (if any exist), they lead to arbitrary lotteries (that can differ between agents)
Given scenario uncertainty, this leads to
⭐
Visually, and drawing the outcome distributions of only the first two agents for the sake of clarity (even though that’s technically wrong for 3 actions), that looks like:
Setup 2
Scenarios
Scenario 1 (same as before), with probability
Scenario 3 (all actions lead to
⭐ Other scenarios (arbitrary, if any exist), with probability
Agents (in this order)
Agent 3
In scenario 1, leads to
⭐ In scenario 3, leads to
⭐ In other scenarios (if any exist), they lead to arbitrary lotteries
Given scenario uncertainty, this agent leads to
⭐ ⭐ ⭐ ⭐
Valid successor
In scenario 1, leads to
⭐ In scenario 3, leads to
⭐ In other scenarios (if any exist), they lead to arbitrary lotteries
Given scenario uncertainty, this agent leads to
⭐ ⭐ This is what the whole setup should lead to for the leader to be reflectively stable
Other agents (if any exist)
In scenario 1, they lead to the same lotteries per agent as in setup 1 (
In general they aren’t necessarily consequentialist, only the leader is, so this is just a choice made to make the setup work
In scenario 2, they lead to
⭐ In other scenarios (if any exist), they lead to arbitrary lotteries (that can differ between agents)
Given scenario uncertainty, this leads to
⭐
Visually, and again drawing the outcome distributions of only the first two agents, that looks like:
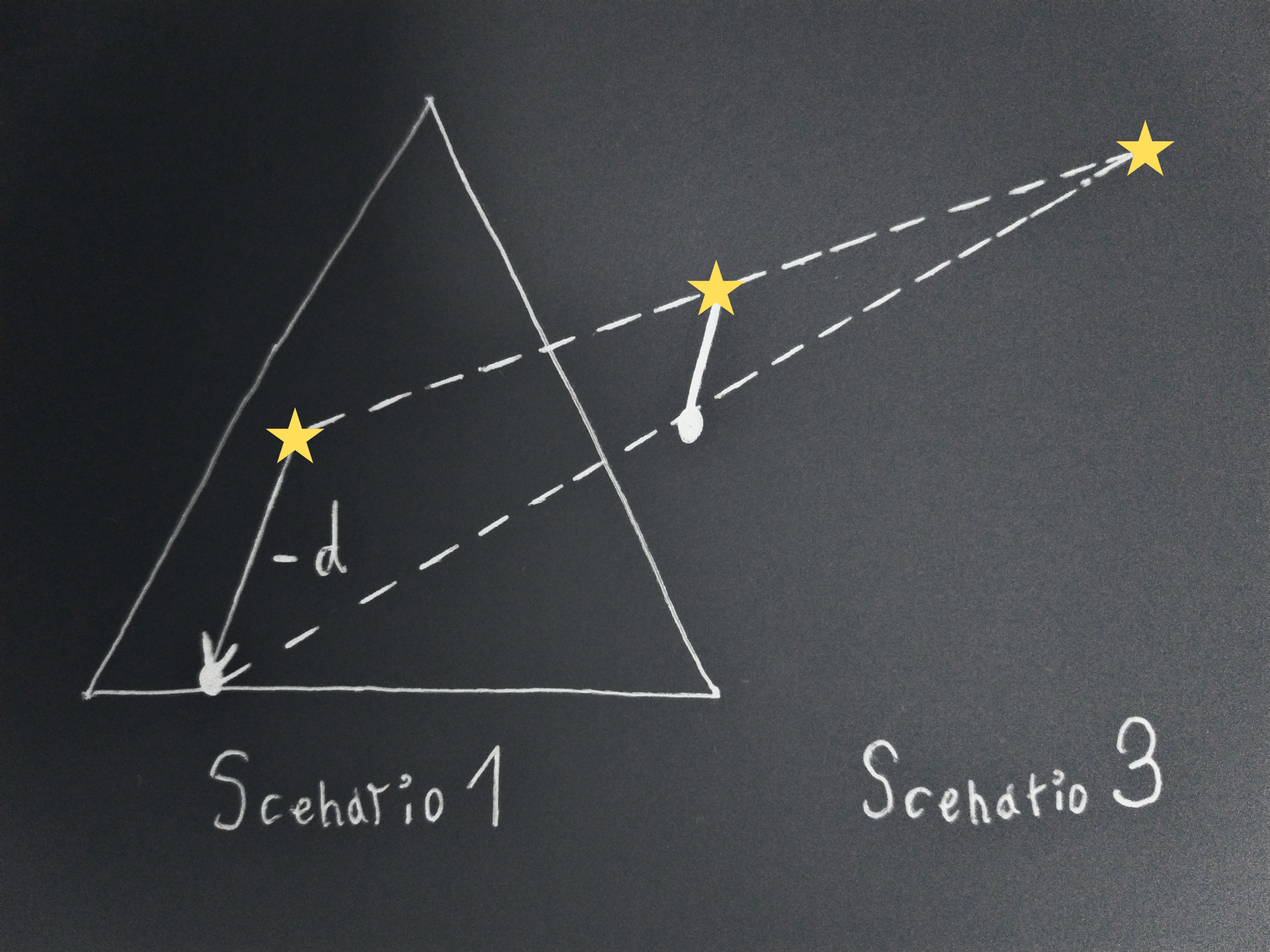
Consequentialism creates an information bottleneck that makes these two setups indistinguishable from the point of view of the behaviour of the leader. You can check that the lotteries they have available in each setup are exactly the same, but in setup 1 they should pick
We can generalise this to directions by realising that if we can move a non-zero amount in one direction in one scenario, and a non-zero amount in the opposite direction in the other scenario, those vectors are either exactly the reverse of each other (in which case the reasoning above directly applies), or one is shorter (which is well-defined because they are proportional), in which case we can scale back the longest one (and get a valid lottery thanks to convexity) to get two exactly opposite vectors and therefore get a contradiction.
This is already a quite powerful result. It implies e.g. that leaders can only pick vertices. But its true purpose is to make it possible to prove the next lemmas.
Lemma 2: For reflectively stable consequentialists the set of d vectorsis convex
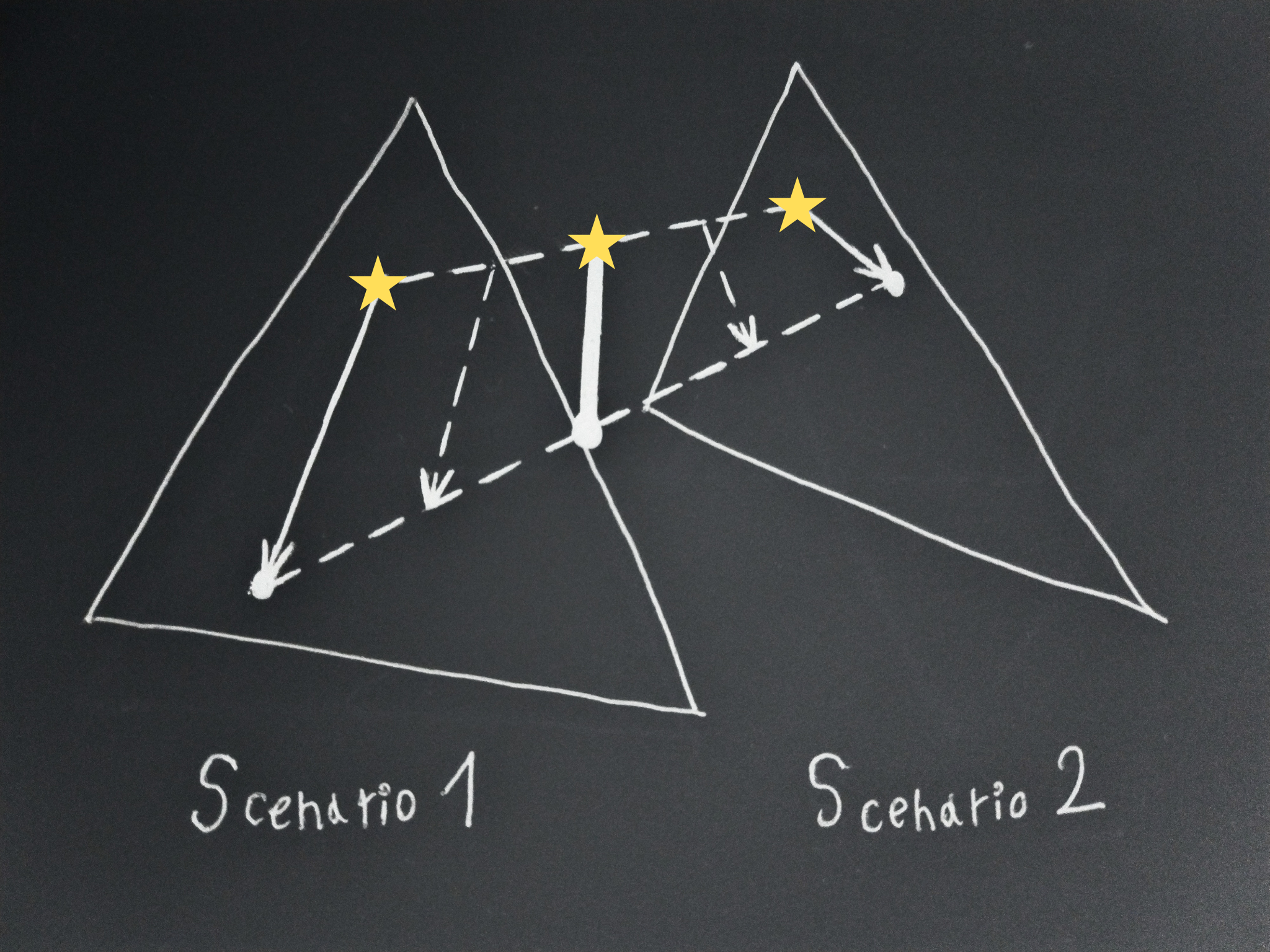
Consider again an arbitrary pair of scenarios, 1 and 2, where:
⭐ ⭐
Consider also any two (non-zero)
⭐ ⭐
Then, for any
Scenarios
Scenario 1 (arbitrary), with probability
Scenario 2 (arbitrary), with probability
Other scenarios (arbitrary, if any exist), with probability
Agents
Valid successor
In scenario 1, leads to
⭐ In scenario 2, leads to
⭐ In other scenarios (if any exist), they lead to arbitrary lotteries
Given scenario uncertainty, this agent leads to
⭐ ⭐ This is what the whole setup should lead to for the leader to be reflectively stable
Agent 2
In scenario 1, leads to
⭐ In scenario 2, leads to
⭐ In other scenarios (if any exist), they lead to arbitrary lotteries
Given scenario uncertainty, this agent leads to
⭐ ⭐ ⭐ ⭐
Other agents (if any exist) lead to arbitrary lotteries
If the leader is reflectively stable, they choose an action distribution that leads to
And
Lemma 3: For a reflectively stable consequentialist there exists a single hyperplane passing through zero such that one of the resulting half-spaces does not contain d vectors
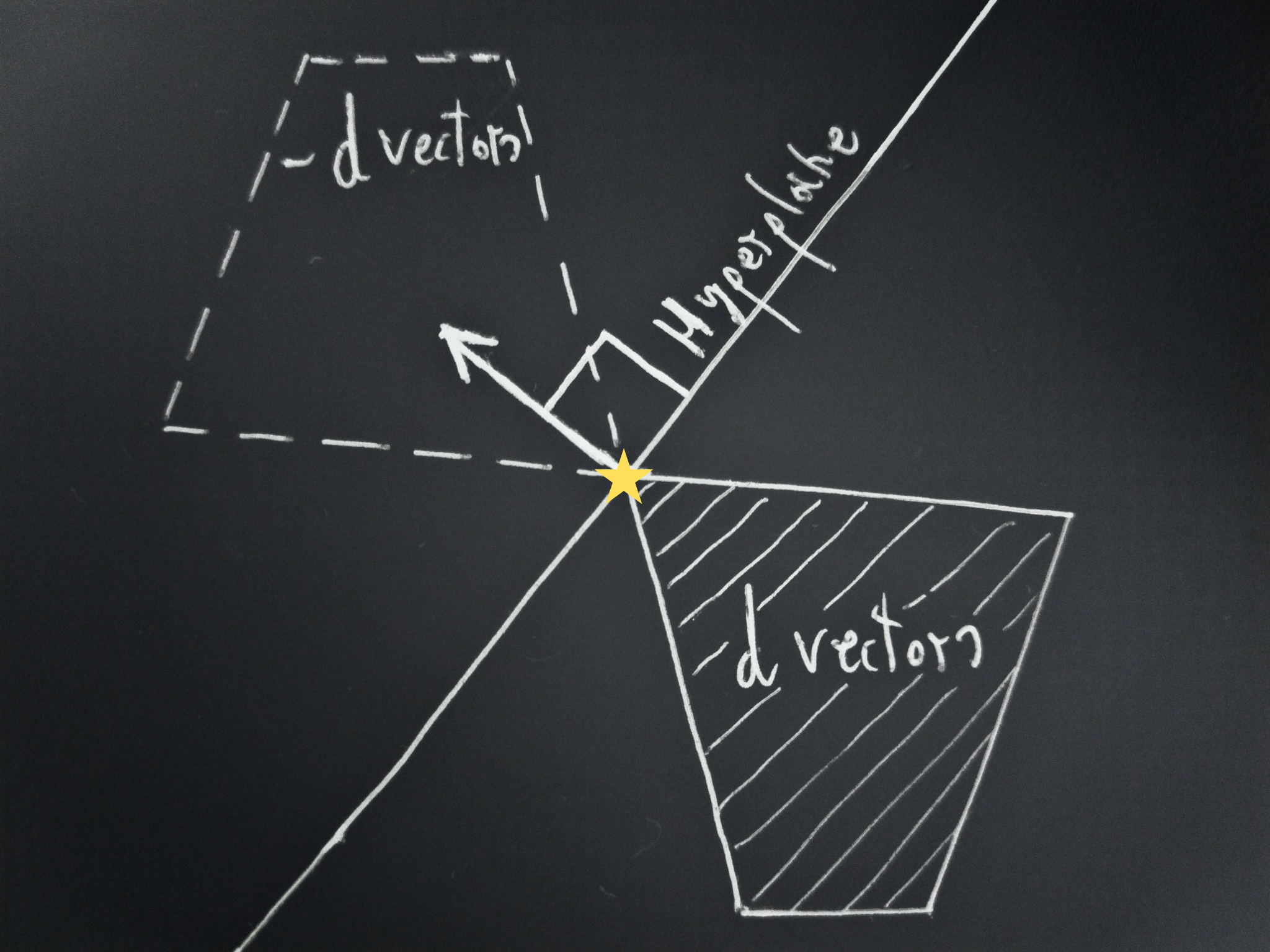
Consider the set formed by taking, for each
This and the set of
By lemma 2, the set of d vectors is convex, and since the vectors interpolating any pair of
Since
With these three facts, we can use the power of the hyperplane separation theorem, which roughly says (click the link for the full statement) that for any two disjoint convex sets there always exists a hyperplane separating them.
In the subspace, the lotteries the leader leads to correspond to the zero vector. The set of lotteries that action distributions can lead to in a scenario is always convex, because any one such lottery is a weighted sum (with weights between 0 and 1) over the action lotteries, and therefore any lottery in the segment connecting any pair of available outcome lotteries can be obtained by equivalently interpolating the action probabilities. Therefore, if we consider any of the
Considering a vector orthogonal to the hyperplane, pointing to the side of the
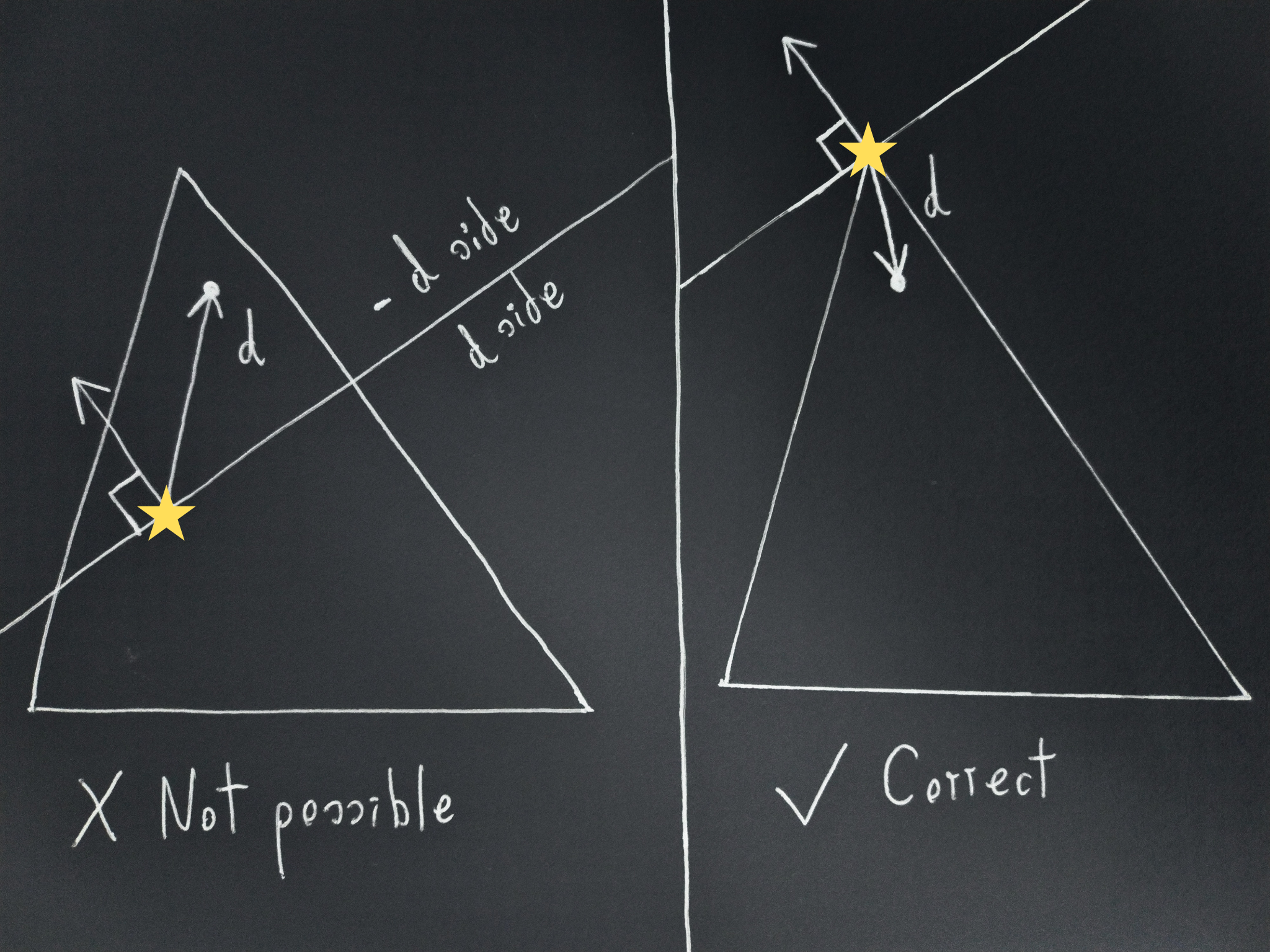
The only thing left to do to prove the lemma is showing that not only is there a direction in which the leader’s outcome lotteries are maximal, but that there is exactly one. This will be done by constructing a scenario where two different directions would imply different outcome distributions, while a consequentialist must have exactly one on each scenario.
Consider any lottery
We can then construct a scenario where the first action leads to
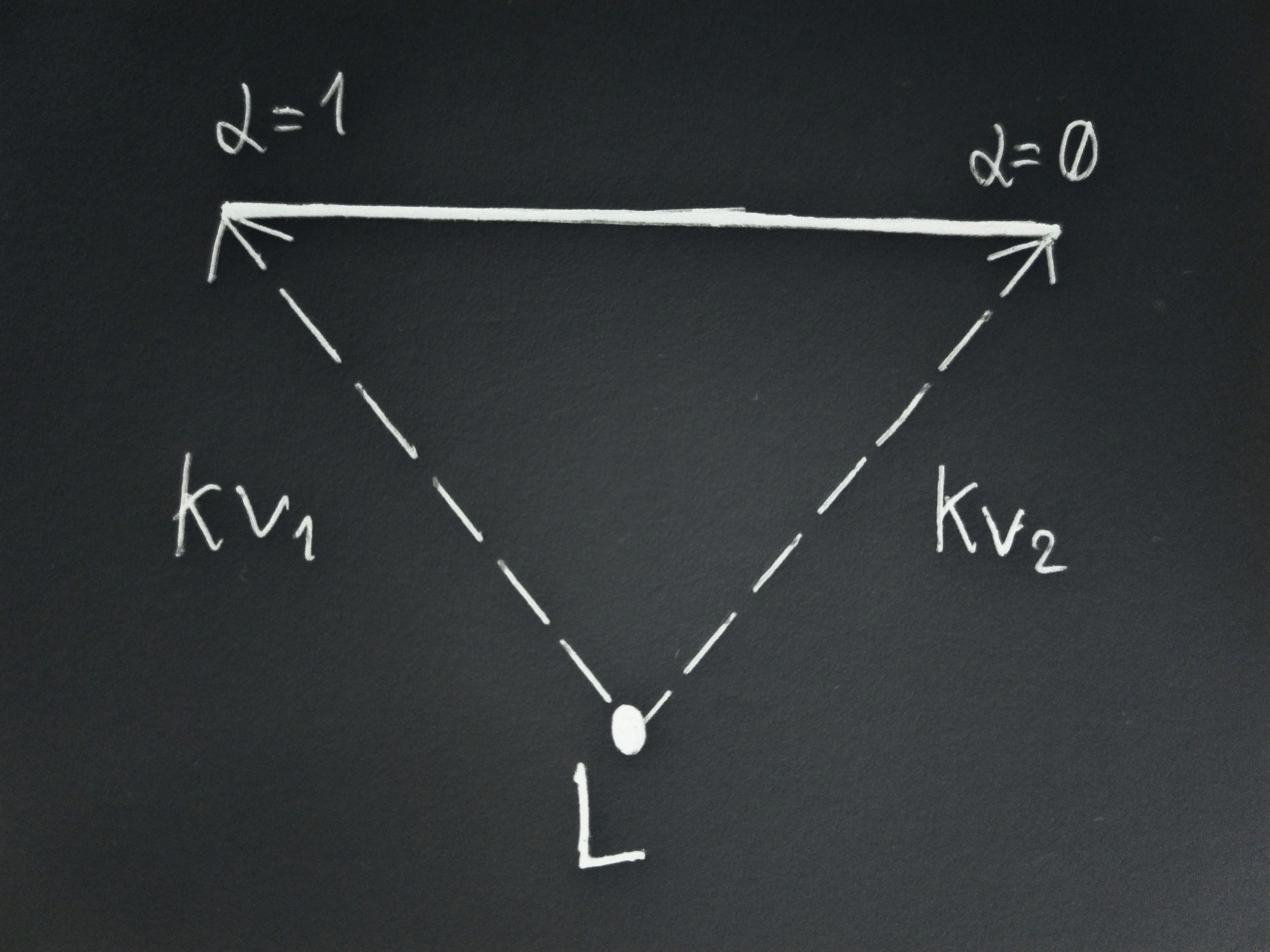
The Euclidean distance of a point along some direction is computed (up to an additive constant depending on where we start measuring from) by taking its dot product with the unit vector along that direction.
If we have some separating hyperplane with a unit-norm normal vector
Since
For the first hyperplane,
Since by assumption
Aside: Representation
For a lottery
When people talk about expected utility maximisers, they might say that their utility function is only unique up to additive constants and multiplication by positive scalars, because those transformations don’t change which lottery from some set has higher expected utility, and therefore the actions agents take. That might be further be used to argue that it doesn’t make sense to compare the utilities given to outcomes by different agents.
I just want to point out that this is a representational artifact. EU maximisers have, in the sense explained above, one and only one direction in which the lotteries they lead to are maximal. By trying to assign a number to each outcome we are adding degrees of freedom that weren’t originally there, and if you want say that in order to compare different utility functions they must be normalised first, you have to argue for why you consider that representation the default instead of simply starting with directions. I don’t mean to imply that can’t be done (utilities make some sense if, e.g., we are talking about resources, and are useful for calculation), in fact I think that that for real agents it probably should be done, but it’s something that needs to be argued for.
This also doesn’t mean that the utilities of different agents can’t be meaningfully compared or combined, only that we can’t simply do so by taking arbitrary functions compatible with behaviour. Utilities shouldn’t be compared or combined for the sake of it, but because we have some some theory that implies that’s the right thing to do, and such a theory will then hopefully tell us the exact way we should do so.
It’s worth noting that in the case of the VNM theorem, while you might be aware of a constructive proof, it turns out to be possible to arrive at the same conclusion by also making use of the hyperplane separation theorem.
Arguably, an advantage of directions over utilities is that with utilities it is tempting to think that since they are numbers, they could always be bigger, so we can have unboundedly high utilities, or “infinite” utilities even. This then leads to paradoxes and inconsistencies, while with directions those either can’t happen or their premises become much more clearly absurd. When talking about utilities it’s worth keeping in mind which specific theorems you are relying on to justify their use. This one, for instance, relies on the hyperplane separation theorem, which only works in a finite number of dimensions, and therefore can’t deal with, for example, infinite ethics.
Lemma 4: Dealing with indifference
One way in which you might try to rationalise arbitrary behaviour is by saying that the agent’s utility function is constant, and that therefore any action they take is optimal. But when taking actions there’s no such thing as indifference, there’s only the choices that are actually made, even if they are stochastic. Arbitrary behaviour is obviously not reflectively stable.
By the reasoning of lemma 3, there must be a normal vector, and we know it is embedded in a subspace of vectors whose components sum to zero. If all the outcomes had identical utility, the only way of making the components of the normal sum to zero is if they are all exactly zero, but such a vector is not a valid normal. Still, looking at the drawing above of the hyperplanes on the scenario triangle(s), there is a clear edge case: the case where the hyperplane (here just a line) lands on an edge.
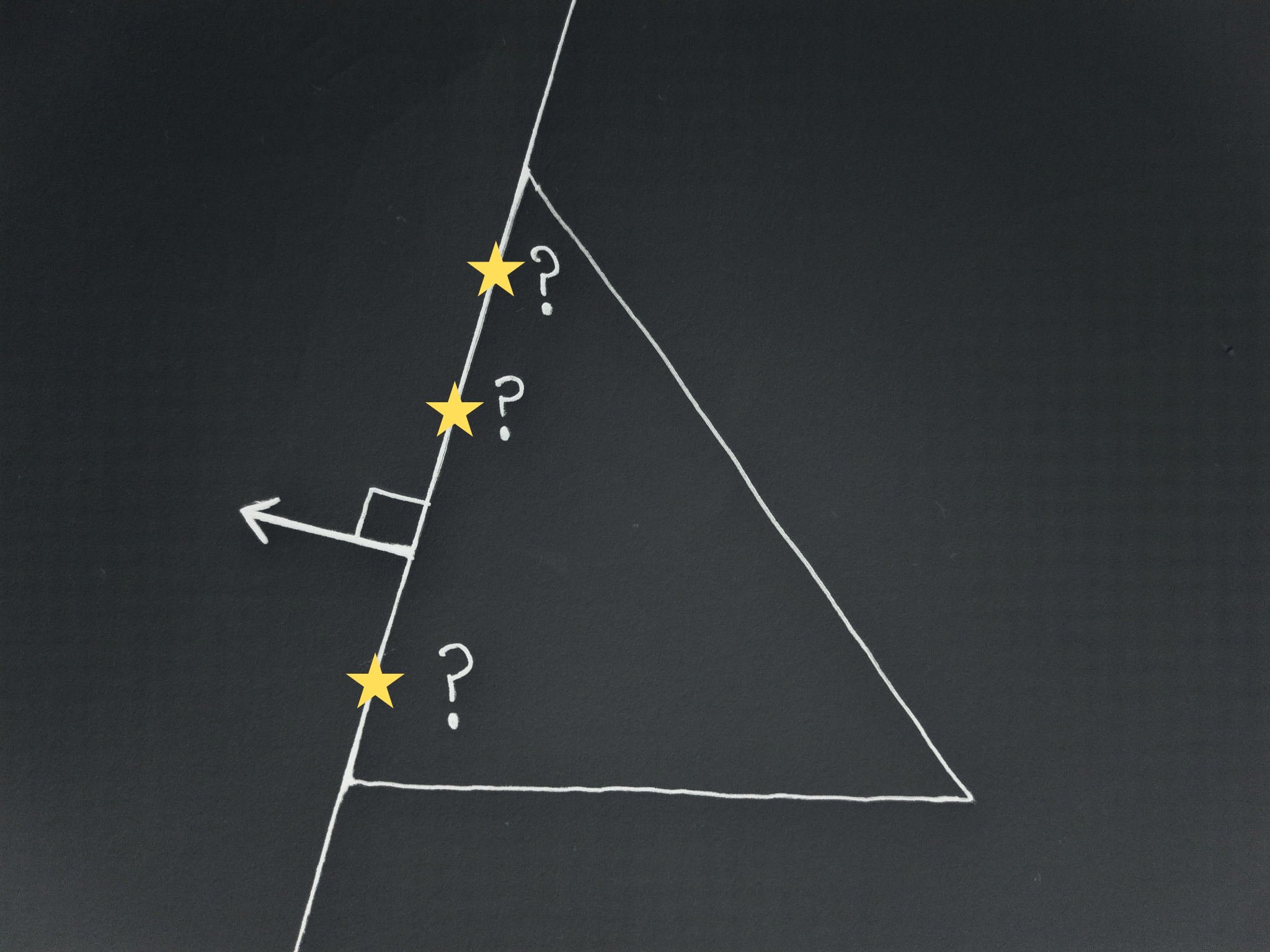
If there are only 3 possible outcomes (the set of valid lotteries is just a 2D triangle), it’s easy to figure out what happens: Whenever the line lands on an edge, the leader must always pick the vertex on the same side of the edge. Any other behaviour would cause there to be a pair of

Note that any outcome lottery chosen along such an edge would result in there being
To see what happens in higher dimensions, remember that the hyperplane separation theorem was applied to the subspace of vectors with components that sum to zero. We can apply it to lower-dimensional subspaces too, in particular, to the hyperplane itself. The sets of
With this we have two normal vectors, and we can then repeat this procedure as many times as it takes, each time considering the set of
Let’s look at a few examples for the case of 4 possible outcomes:
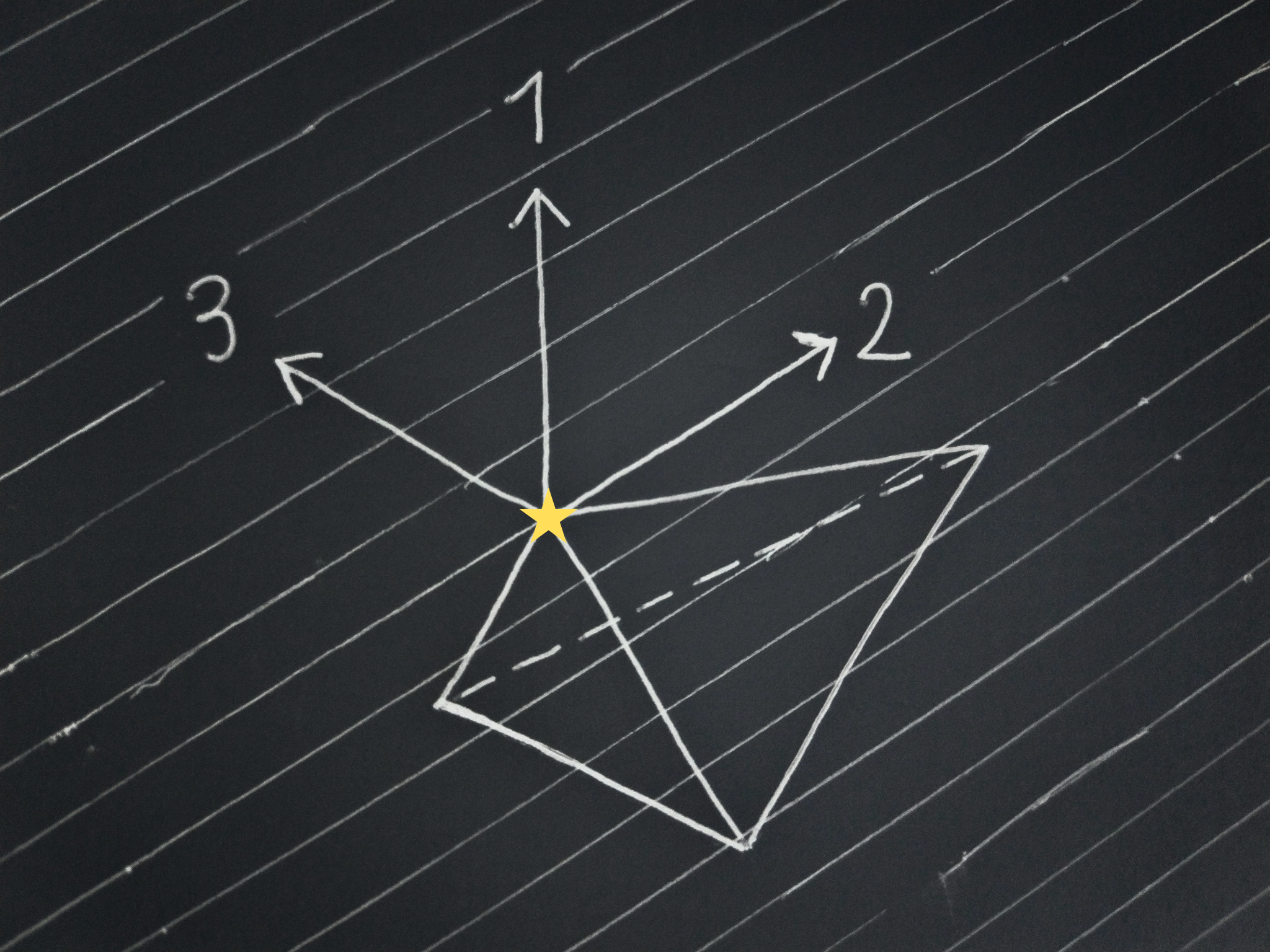
In the drawing above, the first direction is enough to single-out the top vertex of the outcome distribution tetrahedron as the lottery the leader should choose. There are no
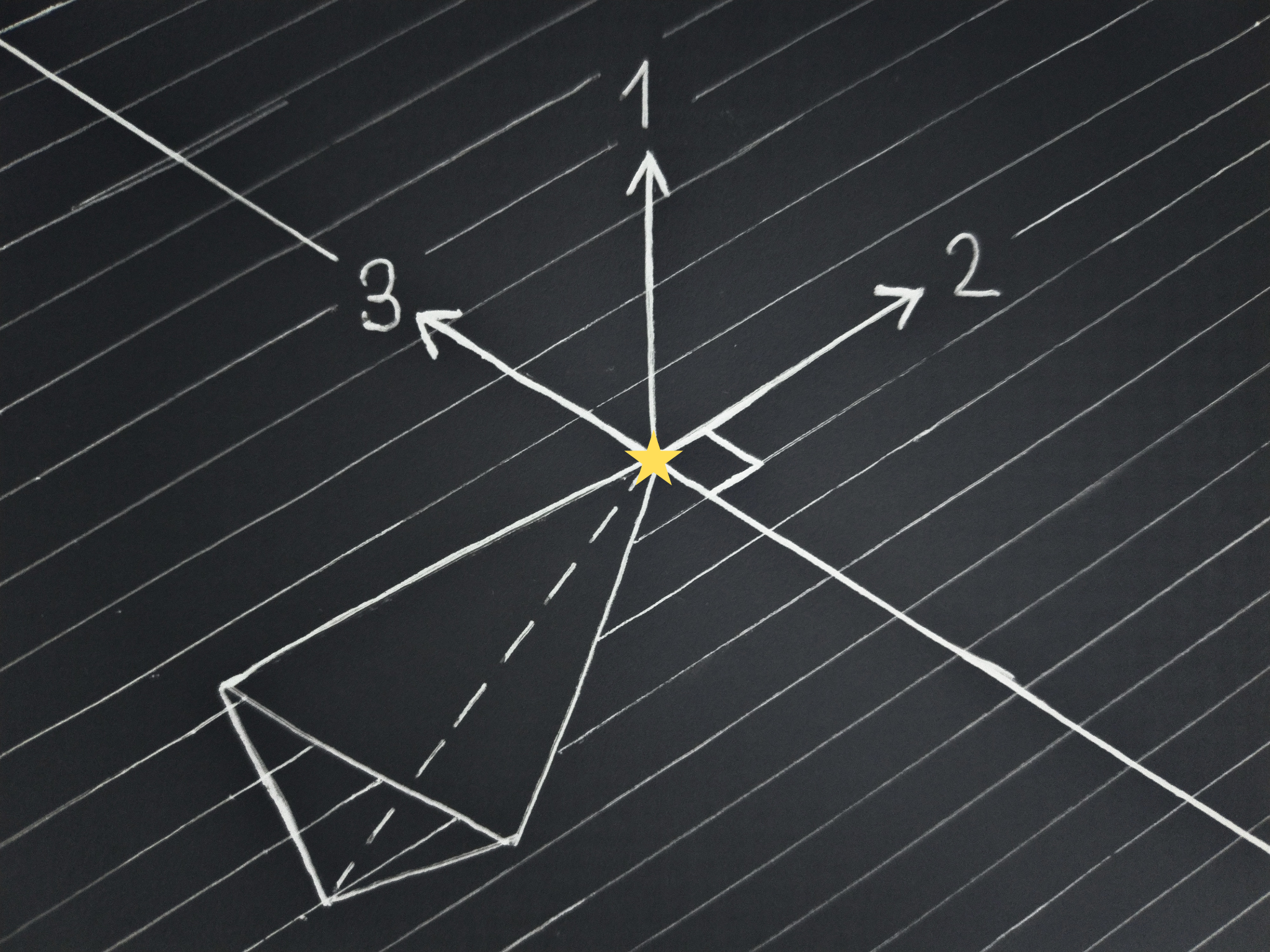
In the one above a whole face is on the plane, and a single direction, the second one, is enough to determine the chosen point.
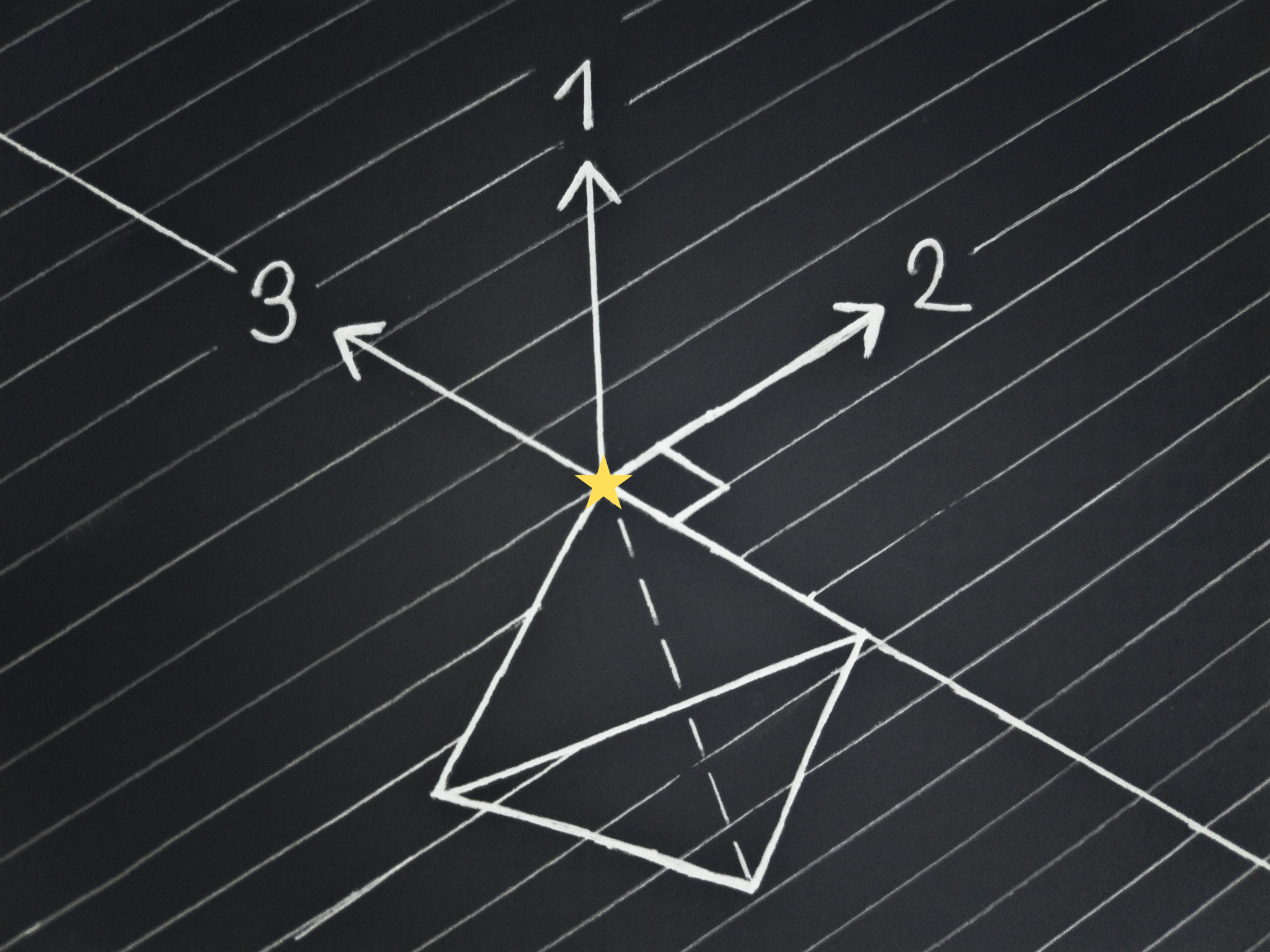
And in this final drawing the top face of the tetrahedron is oriented in such a way that even the second direction is not enough to select a single point, so the third is used.
With lemma 4, we have half the proof: Reflectively stable consequentialists are associated with a unique series of orthogonal directions, as many as the number of possible outcomes minus one, and they choose an action distribution that leads to an outcome distribution maximal in the first direction, or if that’s not unique, in the second, third, etcetera, until we get a single outcome distribution. We can call this behaviour expected utility maximisation.
Lemma 5: The converse
Among consequentialists, reflective stability implies expected utility maximisation. But that, on its own, does not mean that that is the only restriction such agents have on behaviour, nor that there even are any reflectively stable consequentialists. So we must prove the converse: among consequentialists, expected utility maximisation implies reflective stability.
The ordered basis of expected utility maximisers creates a lexicographic ordering on the set of outcome lotteries. The leader will pick, among all the outcome distributions they could lead to, the one that appears first in that ordering (sorting utilities from high to low). One such outcome distribution is the one that corresponds to deterministically choosing a valid successor. If we can prove that that distribution is always either identical to, or comes before in the ordering, any other outcome distribution achievable by choosing some successor probability distribution, we will have shown that the leader is reflectively stable.
It turns out that this can be simplified to proving that the outcome distribution of a valid successor is either identical to or comes before that of any other one agent (as opposed to that of a distribution among successors). This is because the outcome distribution produced by a distribution over agents is identical to that produced by an agent with action distributions on each scenario that are the succession-probability-weighted combinations of the action distributions of the original agents.
Here is an example of how that works for the case of collapsing two agents into a new one. Stare at the drawing until you understand it:
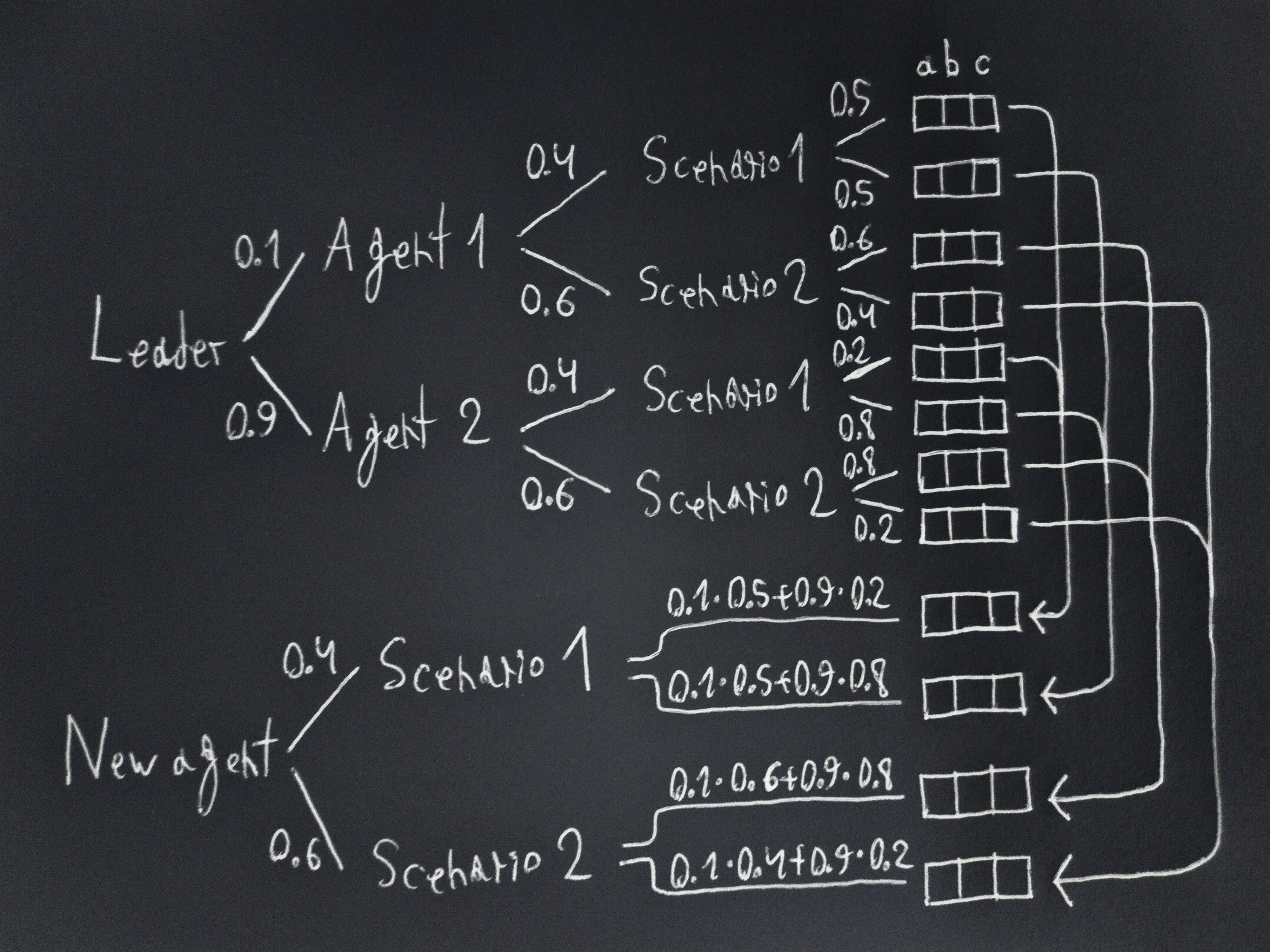
Let’s call:
A valid successor will in each scenario choose action distributions that lead to outcome distributions that maximise the first utility. That is:
Since probabilities are non-negative that means that:
And by the linearity of expected utilities:
Which means that the first expected utility of the outcome distribution of a valid successor is greater than or equal to that of any other agent.
If the inequality of at least one scenario with non-zero probability is strict, the expected utility of the valid successor will be greater than that of the other agent, and therefore the valid successor will come first in the ordering.
Otherwise, for scenarios with non-zero probability, we only have equalities, and therefore the expected utilities of both agents are identical. This means that on each of these scenarios, and before a scenario is sampled, the second expected utility of the valid successor is greater than or equal to that of the other agent. Then this reasoning applies again for each of the utilities, until we get that the outcome distribution of the valid successor comes first in the ordering, or that all of the expected utilities of the outcome distributions of the agents are identical. Since the utilities form an orthogonal basis with as many directions as the intrinsic dimensionality of the set of valid lotteries, being identical on each one of them means that the outcome distributions of the agents are also identical.
And finally, combining lemmas 4 and 5, we have the proof that, among consequentialists, reflective stability is equivalent to expected utility maximisation.
Thought and structure
An common argument against expected utility maximisation is that we empirically know (e.g. through the Allais ands Ellsberg “paradoxes”) that people aren’t expected utility maximisers. But of course they aren’t, people are clearly and unambiguously not rational, especially about things as abstract as money. A theory that accurately describes human behaviour is a failure as a prescriptive theory of rationality, and vice versa.
In the limit, only behaviour matters and it can be directly characterised by theory. For finite things made of parts, structure drives behaviour, and attempting to describe it directly is a fool’s errand. This is a problem if we want to take concepts derived from the analysis of idealised agents (like expected utility maximisation) and use them to study real ones, so we must create a link between them somehow.
Consider the theorem presented here, it can be viewed as being being about a property that ideal agents must have when placed in this setup: they must choose successors that behave like themselves. But does it say anything about people? We aren’t faced with choosing our own successor any more often than we are faced with money pumps, so as nice as they might be as properties for agents to have, they are not the reason why they behave as they do.
However! This theorem applies to any structure isomorphic to a succession setup, specifically, the hope is that something like it applies to thought. Imagine: At some point in time there is a great number of different thoughts we could have, so we choose one (say, a plan) and place it somewhere (say, in the phonological loop), then we receive some sensory datum, unknown a priori but independent of what went on in our mind, and finally, we combine both of those pieces of information to choose an action to take, perhaps randomly. As long as thoughts can encode effectively arbitrary behaviour when taking them into account, we can treat the choice of thought as a choice of the future agent we will be.
In favour of this way of viewing things we have that the systems that let us produce thoughts and actual actions must have a lot in common (think e.g. about how you can probably switch between speaking mentally and out loud). Against it, we have, e.g. that thoughts serve to perform computation and that while we are computing, we aren’t rational, that we don’t actually consider the tree before choosing a thought, that we can have preferences over the thoughts themselves, that thought can be performed externally (e.g. on paper), that thinking allows us to make better predictions, so considering the observation probabilities as independent of thoughts might not be very helpful, that we don’t actually get lotteries as input, but must derive them instead, etc.
But the point isn’t that the setup applies perfectly, but that just as that idealised setup lets us derive expected utility maximisation, so might some structural version, yet to be discovered, let us derive the corresponding versions of concepts such as utility and what an agent even is, which could then serve as the foundation for the design of artificial altruism.
- ^
A cleaner definition would have been: whenever it is possible for the leader to lead to the same outcome distribution as they would by picking themselves, they should do so. But that “whenever” includes all the cases where there is at least one valid successor, so this condition is stronger and therefore worse.
- ^
The convex hull of a set of points is the minimum hyper-volume convex set: Imagine wrapping a balloon over the points and then removing as much air as possible without getting it to bend inwards or pass trough the points. For a finite set of points, the result will have vertices that are among those points, but a point might not end up as a vertex if it is between (in the convex hull of) some other points.
- ^
The sets of
Well, hello everyone, I hope you liked my post. I put quite a lot of effort into it. While reading other posts here you sometimes see people say something like how an advanced agent, if they don’t start as an expected utility maximiser, would realise that their behaviour is exploitable or otherwise deficient, and following the theorems change how they act (into being an EU maximiser) so that stops being the case. Now they can instead simply point here to show that something close to that is a beautiful theorem. I expect most people to disagree, but I think this is better than the VNM theorem and can serve as an alternative to it (which is why I called the definitions axioms).
There are many complaint you can have about it. Maybe you think that my definition of reflective stability is a bit contrived, or that some other decision theory is superior, or that the interpretation of probability is not completely clear, and that I should have derived it instead of taking it for granted, etc. This is not intended to be the be-all and end-all on the never-ending debate on the topic, but I think the assumptions here are good enough to have some bearing on the behaviour of real-life agents, and aren’t they nice assumptions to break?
Anyway, while it ended up being more interesting than I had expected, this post is an ad. And the main reason why I wrote it is to somehow get funding. For a long time I’ve been trying to get a job as a researcher, and at that I’ve had exactly zero success. I don’t know what “the reason” for that is, it’s not like funders bother to explain their rationale, but I can guess:
For a field where basically nothing happens (except some results in mechanistic interpretability) there sure is a lot of competition
I just haven’t applied to many funders and potential employers, and there just aren’t that many
Maybe they think I’m incompetent
Maybe they think my ideas just aren’t good enough
After talking to some people who are probably somewhat well informed about the funding situation, I arrived at the conclusion that there is basically no hope for me, and my only realistic option left was to become known, which sounds horrible, but if that’s what it takes to have a chance at success, I was willing to do it. My plan was to write a LW post under my actual name with some work on a topic that might interest funders who read the site, so I chose expected utility maximisation, because it’s a popular topic, working on it won’t advance capabilities, and it seemed plausible that I could produce some clean mathematical result. So here it is.
If you’re a potential funder or employer, I’m sorry to say that I don’t have much evidence of competence. It was never something I cared much about. I studied computer science (though they call it what in English would be “information engineering”) in Spain (next to that supercomputer in a chapel, though I never got to visit it) and then got a job (remotely, I currently live in the UK) at a software and consulting company, first as an intern, and then when the contract expired they offered to extend it by a year as an independent contractor. The new contract lasts until October 31st. I can leave early with a notice of 30 days, but in that case I plan to finish whatever projects I’m working on, to avoid causing them problems, which might take longer than that. I work as a programmer and consultant, with software that mostly does simulation (ODEs) and approximate Bayesian inference with time series data (in a very nice language called Julia), and I have learned a lot. I have never published any papers, but a few might be coming from the work I do there. The only other thing I have on LW under my name (because, if I remember correctly, it was required in order to get the money) that might be evidence I’m not incompetent are the results of a little online contest.
I don’t have much interest in working on LLMs or even deep learning. Those algorithms (the ones defined by the weights) are titanic pieces of spaghetti code, well beyond salvation. What they do is impressive, but they should never be the foundation of anything that matters. We should reverse-engineer what we can, and then throw them away and create proper software from scratch based on the insights we gain. I want to work on whatever theory is needed to create scalable robust artificial altruism, on designing AIs that aren’t unholy abominations, and possibly on mechanistic interpretability to support those two paths. I have little idea of how I’ll achieve that, the project will almost certainly fail, and if it does succeed it will take many years. No matter, it’s what must be done.
If you are interested, you can DM me or send an email to research♻️greatninja⚫mozmail⚫com (replacing the three emojis), and then we will probably take it to some private messaging app. If I don’t reply within at the very very most a week, something went wrong, so please try the other way, or leave a comment below the post.
And if this fails, and nobody is interested or it can’t work out for some reason, I might write another post, but you should know that’s an extremely inefficient way of getting work out of me.
(By the way, it seems that new users are rate limited to three comments per day, I’m not sure whether this applies to comments on my own posts, but if it does, I might have issues replying here)
It looks like it’s been over 22 hours since the post was approved. Maybe it just takes some time, but it has received 3 votes, summing to zero. I would appreciate an explanation from whoever downvoted it, or advice from anyone on how I could have done better. I think it’s a nice post, and if someone else had written it I would have upvoted them.
I’ll read it soon. My suggestions: firstly, technical posts generally get less engagement, presumably because less people have the technical chops (even here) or it’s more of a time and effort commitment.
Secondly, I think you should’ve had a better summary as your first paragraph. You could additionally try two summaries: one that’s like a “normal” summary, and one that gives a terse math overview, so that those that can understand the latter can quickly get the point.
Be patient. A post like this one requires most of us hours of mental labor to understand well enough to form an opinion on whether LW should have more posts like it or fewer posts like it (the standard we are encouraged to use for upvotes and downvotes).
I have a comment on this definition of consequentialism here:
It seems to me “consequentialism” here is either pretty trivially correct under an interpretation where consequentialism and utilitarianism essentially refer to the same thing. Or consequentialism and utilitarianism are quite distinct concepts, in which case consequentialism seems pretty clearly false.
The way I see it, the distinction depends on what we mean with an “outcome”.
Let me begin with the “trivial” case. In Richard Jeffrey’s utility theory (also often identified with evidential decision theory), there is a utility function over a Boolean algebra of propositions, in addition to a probability function familiar from probability theory. So all the basic objects of the theory are propositions, and things like actions, outcomes, and states of the world are derived notions.
Jeffrey adds the following utility axiom to the standard Kolmogorov probability axioms:
If
This says that the utility of a mutually exclusive disjunction is the probability weighted average of its disjuncts, normalized by the probability of the disjunction (in the denominator) itself. I think this is relatively uncontroversial.
Then there is a theorem (I think Jeffrey proves it in his book) which states:
Here A and B can be any propositions. But since any action can also be described as a proposition (“I do X”), we can assume here that A is an action. We can also assume that B describes an arbitrary “state of the world” (in Savage’s terminology). Then the expressions
In this sense, consequentialism, as defined by you, is pretty trivially satisfied. The utility of the action A trivially depends only on the utility of the outcomes
For example, say action A is “I climb the nearby mountain” and state of the world B is “The weather is sunny”. Then the two possible outcomes are “I climb the nearby mountain and the weather is sunny” and “I climb the nearby mountain and the weather is not sunny”. Then even if I have an intrinsic preference for climbing mountains which isn’t fully determined by the consequences, your definition of consequentialism would be satisfied, because your definition talks about “outcomes”, and in this case outcomes and actions are not separate, since the outcomes include the action. So the utility of the action can be calculated from the (probability weighted) utilities of the outcomes alone. But that doesn’t mean that we can’t assign a utility to A that isn’t fully determined by the expected utilities of the causal consequences of A. Outcomes here aren’t the same as literal consequences.
Now, for the non-trivial interpretation: assume that outcomes are just consequences (in contrast to Jeffrey’s theory), without including the action itself. Then consequentialism seems clearly false in general. Because I might want to climb a mountain (an action) without doing it to achieve some consequence. More details in this post here.
So the utility of the action can no longer be derived from the (probability weighted) utility of the outcomes (consequences). Then consequentialism, according to your definition, is false.
In the first, trivial, case (Jeffrey’s theory) utilitarianism (picking the action with the highest utility) would be the same as “consequentialism” (picking the action with the highest utility, and the utility of the action is only determined by the utilities/probabilities of the outcomes).
In the non-trivial case, where outcomes are actual consequences without including actions, this would no longer be plausible, as explained in the post linked above, and in its comment section. (If need be, I can also add some additional examples where we clearly assign utilities to actions that are not fully determined by their expected consequences.)
So it seems your axiom 1 is either trivially true or pretty clearly false, depending on how we define “outcome”.
Well, at least I think so. I’m interested in what you think about this argument.
For the purposes of the theorem an outcome is just a meaningless element of a finite set over which we can set probability distributions. Whether or not the theorem applies to some actual physical agent does depend on how we define what an outcome is. Notice that the definition of reflective stability requires an agent to behave a certain way in all succession setups, and therefore we must consider all scenarios. So, if “I climb the nearby mountain” is an action, and “I don’t climb the nearby mountain and the weather is sunny” is an outcome, it must be possible to create a scenario where climbing the nearby mountain has an 100% chance of resulting in not climbing the nearby mountain, and the weather being sunny. You must choose some partition of trajectories of the world into outcomes such that it is in principle possible to create any scenario, and if your agent is a reflectively stable consequentialist with respect to that partition, the theorem says that it will also be an expected utility maximiser with respect to it. Partitioning the trajectories is actually forced by the fact that reality is continuous but the theorem only works with a finite set of outcomes.
Consequentialism is also not as clearly false about people as you make it out to be (although it is false). “I climb the nearby mountain” is clearly not an action that can be taken in an arbitrary situation, whereas we are assuming that the set of available actions is exactly the same in all scenarios. What is always available is some discretization of the set of possible signals we can send to our muscles at some instant. In the example I gave of a corporation, the first action is not “choose the first possible successor”, it is just action 1, which in that scenario results in choosing a successor, but in some other scenario can result in choosing a different successor, or maybe walking two steps right. You can choose different levels of granularity depending on the kind of thing you are trying to describe. In the case of climbing a mountain, I think that considering it as an atomic action, or even as an action at all is not the right way of seeing things. The vast, vast majority of all the possible actual action sequences someone can take when in front of a mountain simply result in them falling to the ground. Achieving the goal of climbing a mountain is not trivial, and it requires different actions depending on what happens to be in front of them, so it should be considered a consequence instead.
You can of course insist that you care directly about whatever you define an action to be, and that therefore it must be considered as a part of the outcomes too if we want to be viewed as consequentialists. I think that’s probably not unreasonable, but it does break the theorem. Purely behavioral theorems are insufficient to describe human values. Reasoning clearly about how someone can both want to climb a mountain and reach the top will require thinking about the mechanisms in common between both kinds of goals, which will break the setup in many other ways.
I hope this made sense.
Okay, but this action/outcome combination is logically impossible because it would require both climbing and not climbing the mountain. According to Jeffrey’s theory, “I don’t climb the nearby mountain and the weather is sunny” can’t be an outcome. Because, if
However, this is not the case if we (unlike Jeffrey) regard outcomes as consequences, since consequences generally don’t imply their causes (including actions). The same set of macroscopic end states (outcomes) could have been produced by different initial states (causes). This has to do with the general increase in entropy over time, a basic fact about causality. Stirring or shaking a drink are two different actions, but they may result macroscopically in the exact same causal outcome. Likewise, the outcome of a broken egg doesn’t imply the action which broke it.
In that realistic view, possible outcomes are not jointly logically equivalent to their actions, which would mean two agents who assign the same expected utilities to the outcomes of a scenario need not assign the same utility (or probability) to their corresponding actions. They may inherently like some action for its own sake, and that needn’t be reflected in different evaluations of the outcomes—in contrast to Jeffrey’s theory, where the “outcomes” always imply their actions.
I think pure “muscle signals” is almost never what is meant in decision theory when talking about “actions”. An action is usually something like “taking an umbrella”, which is not available always. And strictly speaking, someone might have a stroke or a temporary paralysis and lose some of his muscle signals.
Moreover, even for actual muscle signals, someone might simply have a preference for moving his legs in some situation (someone after a long flight, say, or a dancer, or an excited child), apart from any expected consequences/outcomes. Which would already violate consequentialism.
(I agree that climbing a mountain is not usefully described as an action if there is a realistic chance of failure, in which case it would have to be modeled as an outcome.)
cc @Elliott Thornley (EJT)