Three Alignment Schemas & Their Problems
This is the first journal entry for my 6 months of alignment studies. Feedback and thoughts are much appreciated! I’m hoping that documenting this process can serve as a reference for self-study methods in AIS.
I’m not sure how one goes about solving alignment. So for lack of an authoritative approach, I sat down to sketch out the problem from scratch. First off...
What happens when AI becomes more intelligent than humans?
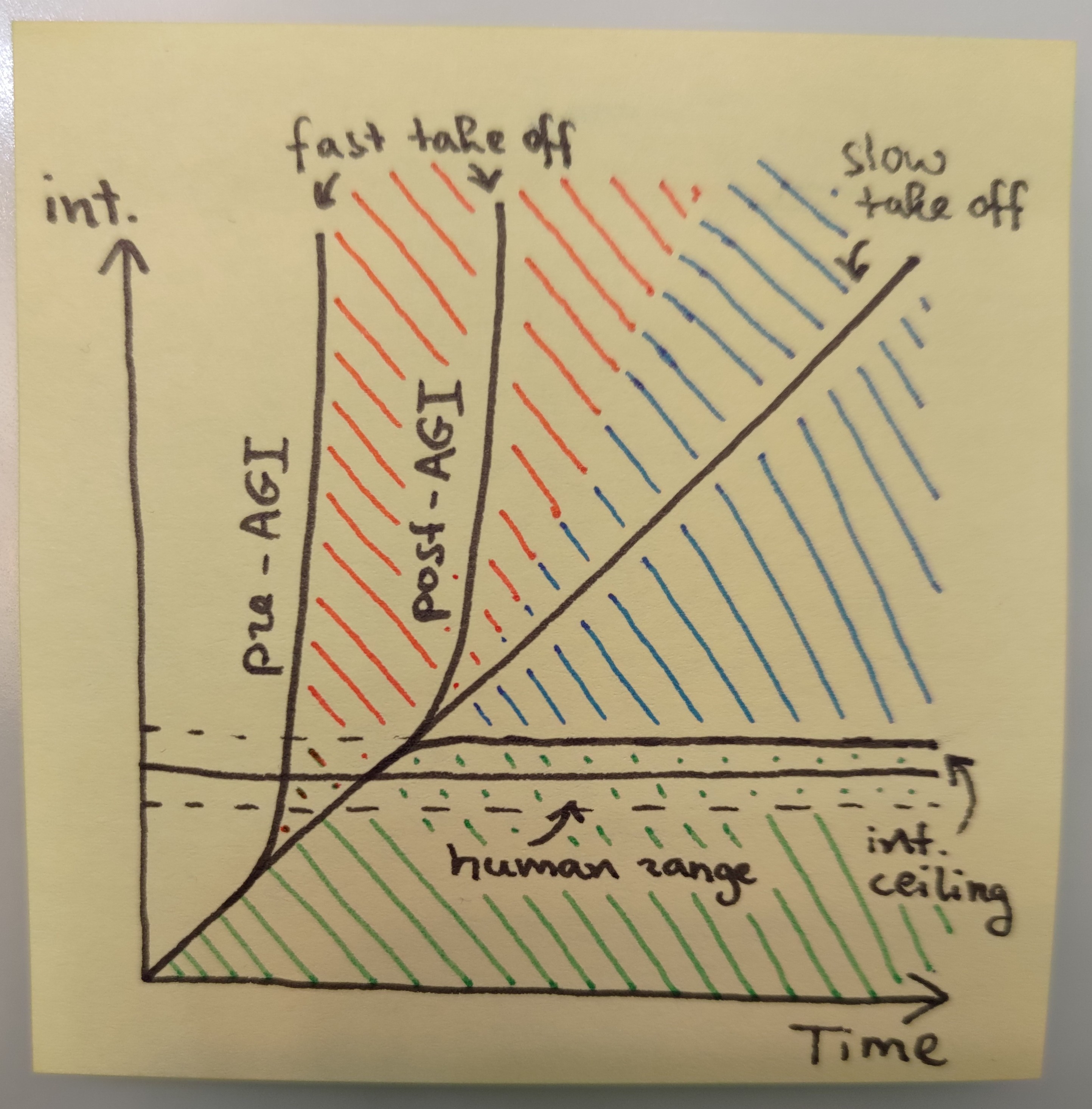
My understanding (and hope!) is that we are currently in the green area: AI is below human range—We’re safe.
Now what are the potential scenarios from this point? Let’s review the entire possibility space.
Intelligence Ceiling—AI can’t get smarter than us because human intelligence is about as good as it gets. This seems extremely unlikely on first principles, but we can’t empirically rule it out.
Slow Take-Off—There is no Recursive Self-Improvement so we’ll have time to adjust to AGI showing up. Problems will be progressive which means we can mobilize and experiment. This is kind of okay and manageable.
Fast Take-Off Post-AGI—Recursive Self-Improvement is real and kicks in around human-level intelligence. We’re sitting on a ticking time bomb but at least we know when it will go off, and it’s plausibly not extremely soon.
Fast Take-Off Pre-AGI—Recursive Self-Improvement is real and kicks in significantly before human-level intelligence! This is scary, and soon, and we’d better make sure all our current AI is aligned yesterday. Let’s get to work.
What does AI end up doing as it becomes more intelligent?
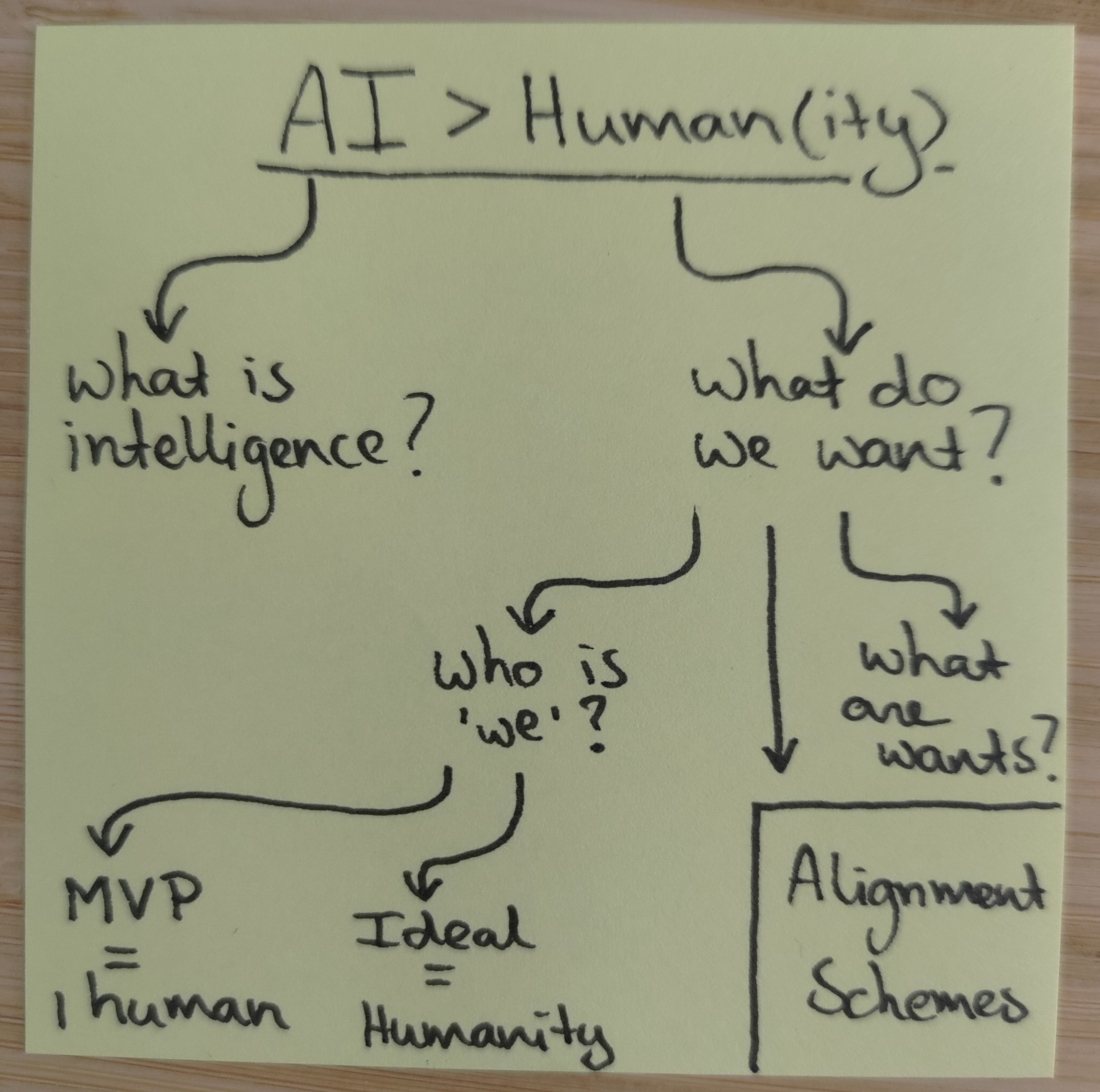
This question has a couple of branches. First off, we need to understand what intelligence is and what we’d like AI to do in the first place. This week I mostly dove into the latter part of that equation. Let’s see what we want to align on before we figure out how to get there.
Yet the question what we want to align on also consists of two parts: who is this “we” and what are “wants”? Looking at the “we”, the Minimal Viable Product (MVP) to solve for is a single human. From there, we can hopefully scale up to more humans and then all of humanity (Ideal). Notably, such scaling involves a process of value aggregation, which is a challenge in itself.
On the other hand, what are “wants”? This opens up a question on the nature of goals and if some goals might be easier or harder to align on than others. For instance, complexity of goals might make some goals easier to align on than others. But are there other properties of goals as well?
For now, let’s say we want to align on as-yet-undefined goals of a singleton human (with options to scale up), what would that look like?
Alignment Schemas
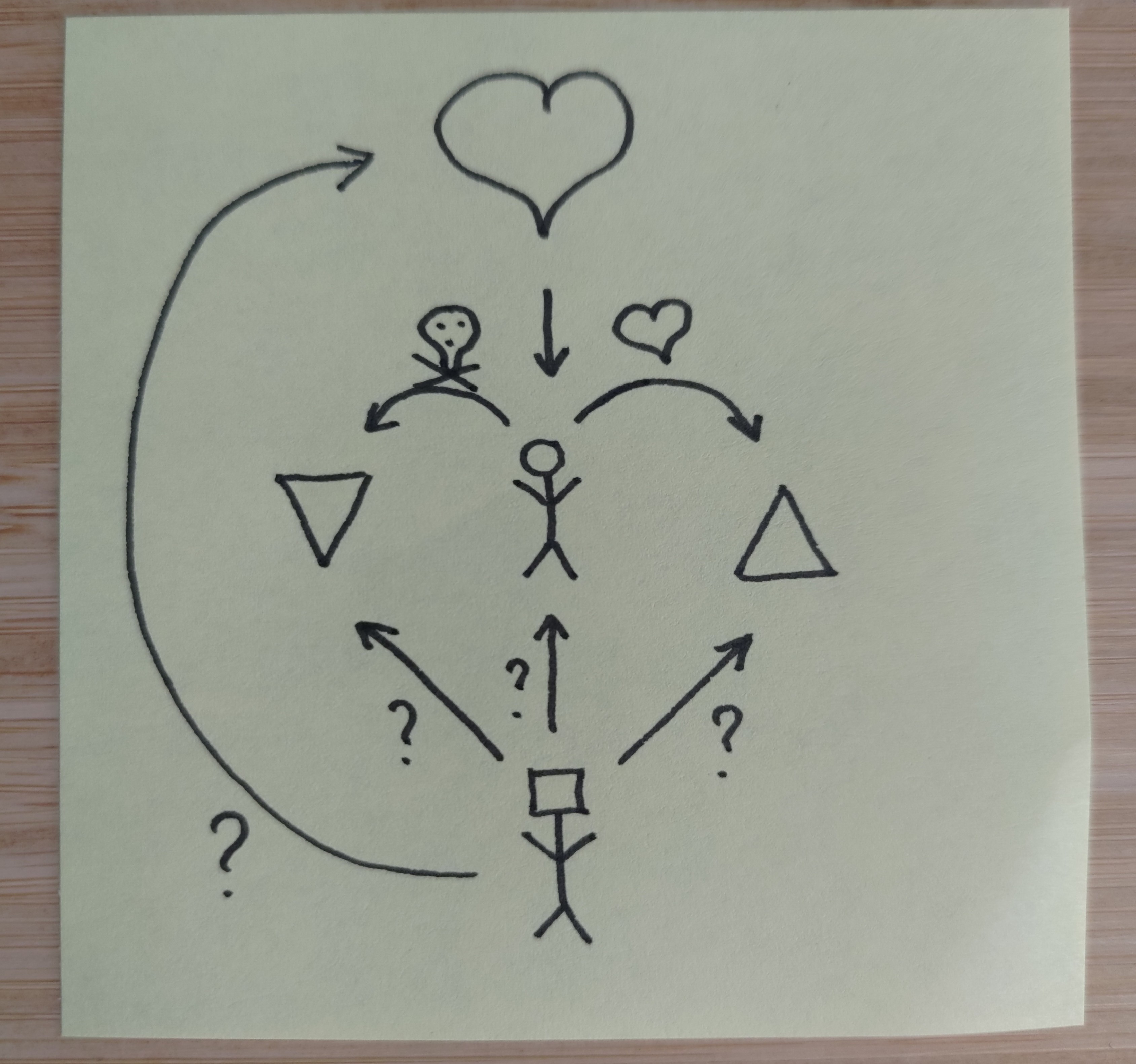
I’m using the concept of an alignment schema as referring to a relational diagram that shows how human(ity) and AI relate to each other’s goals. Overall, the situation seems to be that humans exist with preferences over world states. We prefer some things (hearts) and disprefer other things (skulls). These preferences are often not coherent, and often not even known to us a priori. They can also change over time, which means value lock-in is real and something we want to avoid.
Given that situation, what do we point the AI toward?
There roughly seem to be three options: Point it directly at us (Human in the Loop), point it at values that are benign to us (Empowerment), or point it at the exact things we like and dislike (Harm Avoidance, for reasons later explained).
Human in the Loop
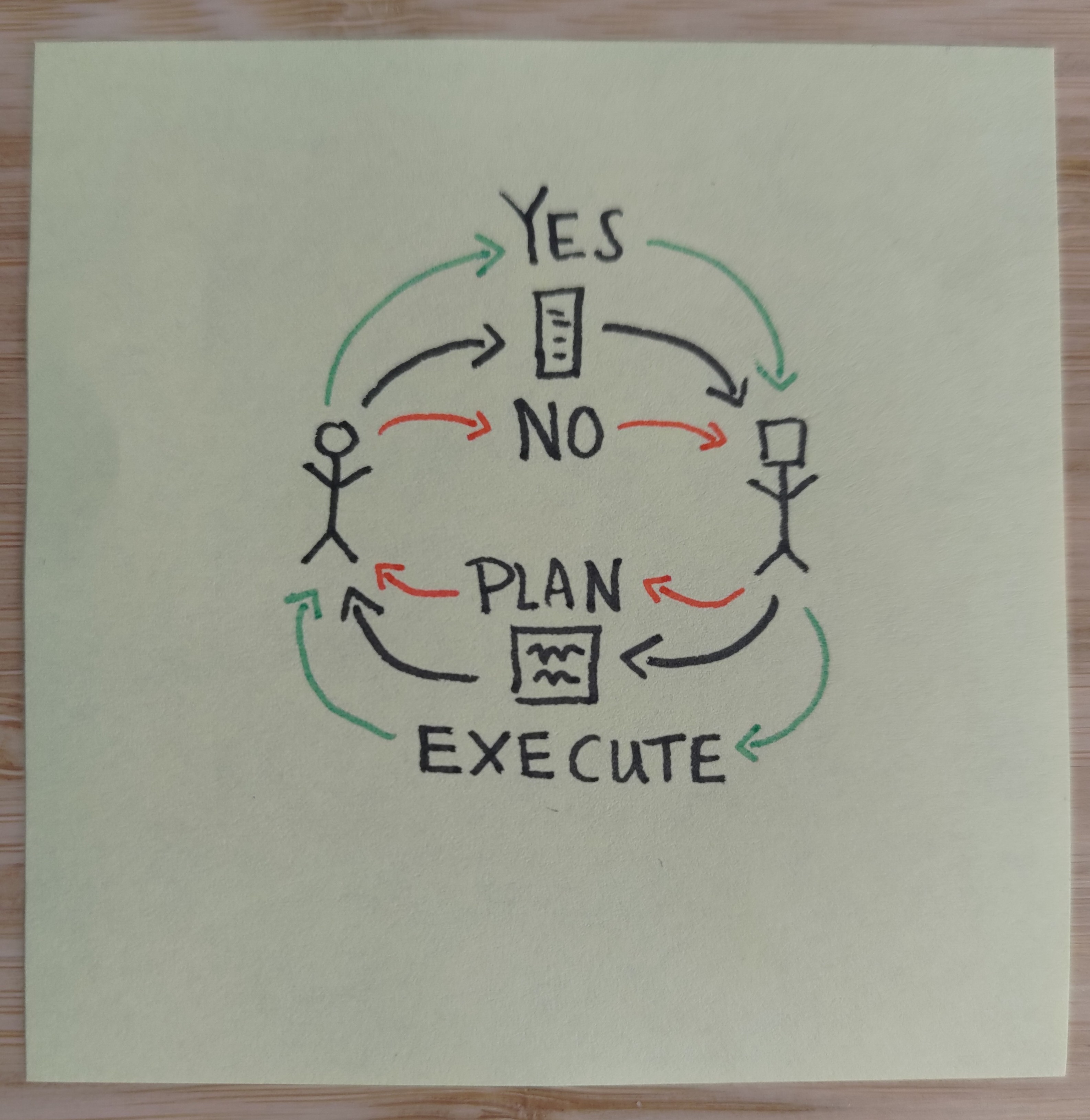
This is the holy grail: An AI that listens to us directly. We feed our preferences in to an aggregator, the AI reads out the aggregator, the AI generates a plan based on our preferences, and we review the plan:
If we don’t like the plan (NO), we update our preferences to be clearer and more detailed, the AI reads them out again, plans again, and we review its plans.
If we do like the plan (YES), then the AI executes the plan and gives us progress reports. If something goes wrong, we scream NO, it stops, and we go back to the previous step.
This schema relies on a form of corrigibility. Not only does the AI only execute approved plans it also allows the human to interrupt on-going plans. Additionally, the plans are annotated and formulated in such a way that they are human understandable and all it’s impacts and outcomes are explicitly linked to the AI’s understanding of the preference aggregator. This caps out the complexity of the plans that the AI can offer up, and thus imposes a form of alignment tax.
There are a couple of things that could go wrong here. Deceptive alignment is always an issue as the AI can pretend to only execute approved plans while being busy with nefarious plans on the side. Similarly it can try to sneak problematic consequences of plans past us by encoding them in a way we can’t detect. Next there is the question of what a preference aggregator even looks like, considering how human values are messy and incoherent. Lastly, there are issues around coordinating most of humanity to give input to a preference aggregator, as well as a question mark around emergent properties of intelligence once it’s far past our own.
Empowerment
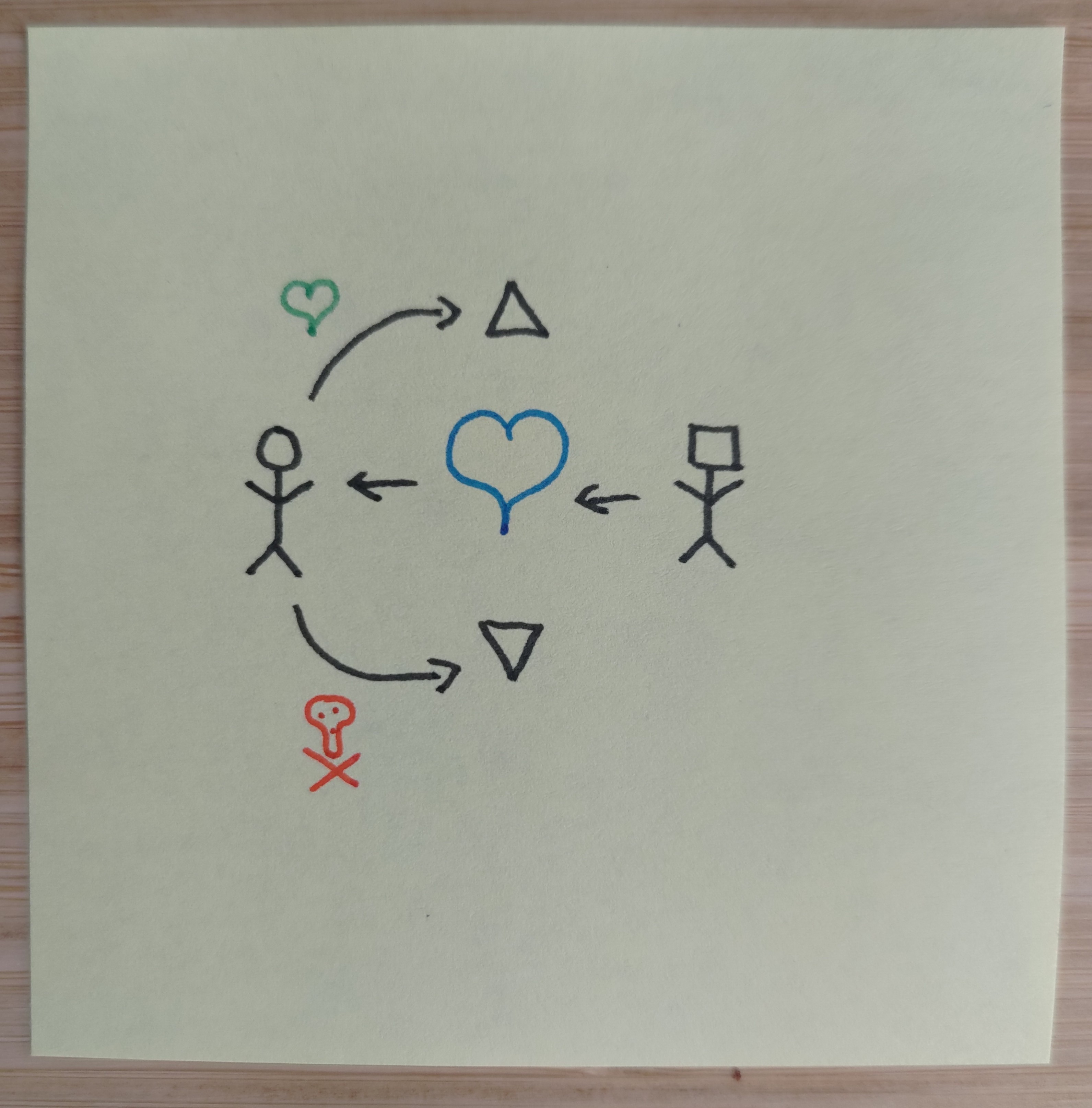
This is essentially sovereign AI—Point the AI at humanity’s instrumentally convergent goals and then deploy it. It would be a benevolent god preoccupied with supporting our self-actualization and flourishing. A utopia of sorts, but one that seems so far removed as to be rather pointless to think about. Specifically, there is no obvious path between where we are now and developing such an AI (no incentive scale), cause what does half a sovereign AI look like?
It does however avoid any question of corrigibility or preference extraction. It simply gives us the tools to make our dreams come true without having particularly strong views on how we should go about doing that. We also don’t need to coordinate humanity for this schema, cause a single lab with a magic bullet can launch the sovereign and it will be kind and empowering to all of us.
Of course there are the classical risks of deceptive alignment, manipulation and emergent properties. And specifically it’s further burdened with needing to find an exceedingly robust goal landscape (cause you better be damn sure it doesn’t have value drift toward nefarious goals cause there is no corrigibility) while distributional shift will also be a head cracker—What do training wheels for gods even look like?
Harm Avoidance
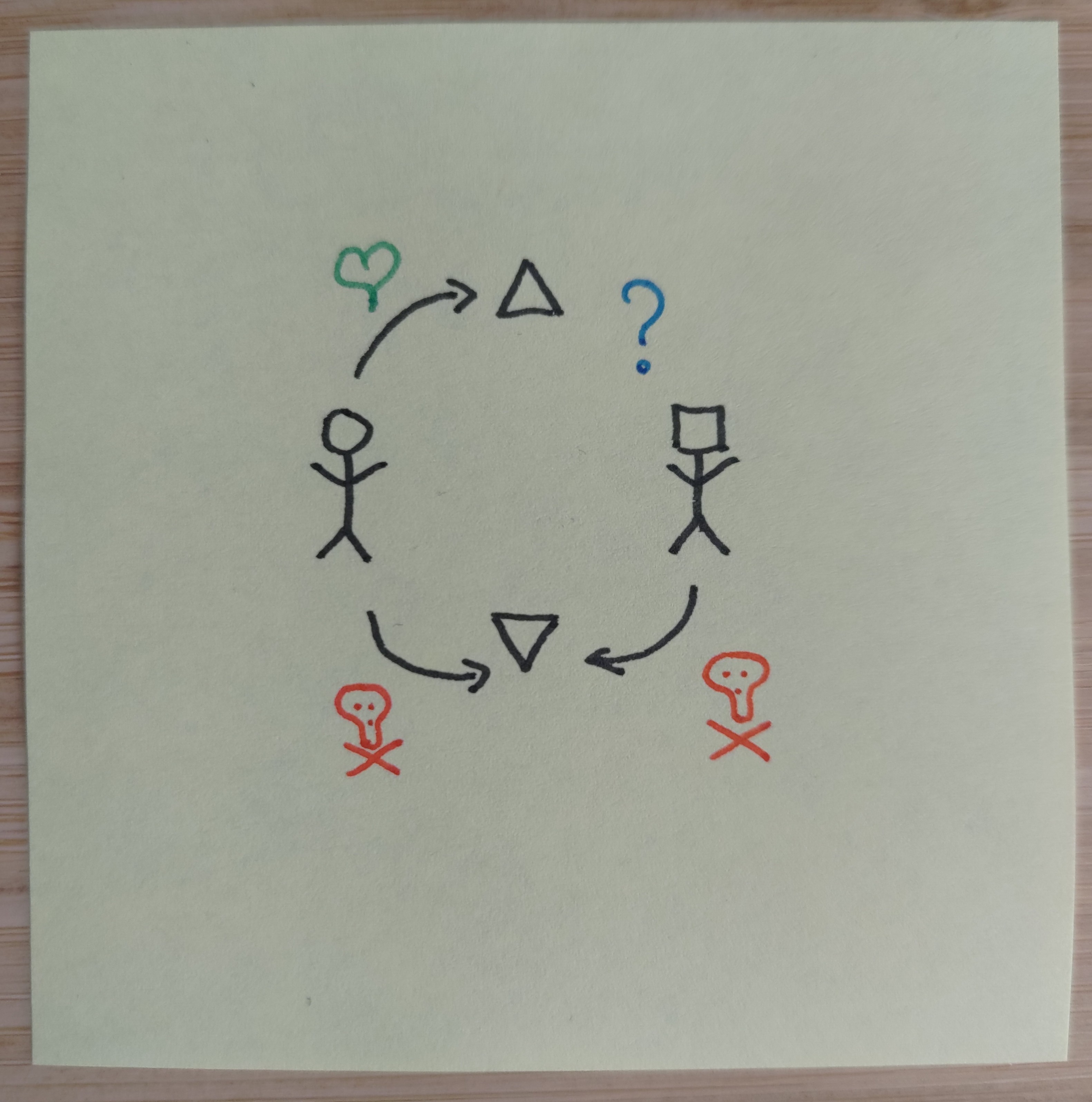
This is a rather useless AI—Peaceful coexistence with a superintelligence that does not hurt us or help us. I’ve listed it cause it may be simpler than the other two schemas. The issue is that if you try to point an AI at our preferred world states directly, then you are essentially signing up for value lock-in into perpetuity. On the other hand, if you make it corrigible then you end up on Human-in-the-Loop anyway. Thus you can only really point it away from doing anything we find really-really bad regardless. This is probably less problematic than value lock-in cause the most negative world states are fairly stable over time (don’t wipe us out, don’t torture us, etc). However, the AI won’t be doing anything useful for us either.
Challenges per Alignment Schema
In an effort to determine what the path to aligned AI may look like, I tried to list the problems that need to be solved per alignment schema. This list is non-exhaustive and I’d be grateful for additions and thoughts.
| CHALLENGES PER ALIGNMENT SCHEMA | ||||
|---|---|---|---|---|
| Human in the Loop | Harm Avoidance | Empower-ment | ||
| AI Influence on Humans | Deceptive Alignment | x | x | x |
| Manipulation Criterion | x | x | x | |
Nature of Values & Goals | Goal Robustness | - | x | x |
| Preference Extraction | x | / | - | |
| AI Governance | Human Coordination | x | — | |
| Incentive for Scalability | - | x | x | |
| Other Problems | Distributional Shift | - | x | x |
| Corrigibility | x | — | ||
| Emergent Properties | x | x | x | |
Below is a brief description of each problem:
Deceptive Alignment—An AI that realizes it is in training and thus optimizes reward according to it’s current utility function by pretending to already be aligned and then defecting straight after deployment (Steinhardt).
Manipulation Criterion—How do we define/encode/train an AI to minimally influence us considering that all interactions with humans can be considered a form of manipulation?
Goal Robustness—How do we avoid value drift after deployment? This is different from goal misgeneralization as this takes place over time and is not due to distributional shift.
Preference Extraction—How do we extract and aggregate human preferences? Maybe something like Coherent Aggregated Volition.
Human Coordination—Some schemas need more human coordination than others. The tractability of such coordination falls in the realm of AI governance.
Incentive Scalability—Some schemas are less likely to work cause there is no incentive for humans to build weaker versions of an AI with the given schema on the road to AGI. Specifically, a sovereign AI is not useful until its intelligence levels are superhuman.
Distributional Shift—Problems caused by the difference in distributions between the training and deployment environment, as defined here.
Corrigibility—The ability to correct an AI after deployment as defined here.
Emergent Properties—Humans have cognitive abilities that our far ancestors could never imagine. Similarly, superhuman intelligence may have properties we cannot imagine. There does not seem to be any obvious way to account for this, but it’s worth keeping in mind that this may pose a risk.
Conclusion
In an attempt to home in on the key problems in alignment I’ve tried to deconstruct the problem space from first principles by identifying subquestions of alignment, formulating possible alignment schemas, and grading schemas on what subproblems need to be solved to allow them to succeed. Currently, a human-in-the-loop approach that integrates corrigibility, a preference aggregator, and limited and explicit plan specification seems most promising. Next week I’m hoping to look at the other branch of the alignment problem: what is intelligence and how do we instantiate it in machine learning?
Just read your latest post on your research program and attempt to circumvent social reward, then came here to get a sense at your hunt for a paradigm.
Here are some notes on Human in the Loop.
You say, “We feed our preferences in to an aggregator, the AI reads out the aggregator.” One thing to notice is that this framing makes some assumptions that might be too specific. It’s really hard, I know, to be general enough while still having content. But my ears pricked up at this one. Does it have to be an ‘aggregator’ maybe the best way of revealing preferences is not through an aggregator? Notice that I use the more generic ‘reveal’ as opposed to ‘feed’ because feed at least to me implies some methods of data discovery and not others. Also, I worry about what useful routes aggregation might fail to imply.
I hope this doesn’t sound too stupid and semantic.
You also say, “This schema relies on a form of corrigibility.” My first thought was actually that it implies human corrigibility, which I don’t think is a settled question. Our difficulty having political preferences that are not self-contradictory, preferences that don’t poll one way then vote another, makes me wonder about the problems of thinking about preferences over all worlds and preference aggregation as part of the difficulty of our own corrigibility. Combine that with the incorrigibility of the AI makes for a difficult solution space.
On emergent properties, I see no way to escape the “First we shape our spaces, then our spaces shape us” conundrum. Any capacity that is significantly useful will change its users from their previous set of preferences. Just as certain AI research might be distorted by social reward, so too can AI capabilities be a distorting reward. That’s not necessarily bad, but it is an unpredictable dynamic, since value drift when dealing with previously unknown capabilities seems hard to stop (especially since intuitions will be weak to nonexistent).