Can we interpret latent reasoning using current mechanistic interpretability tools?
Authors: Bartosz Cywinski*, Bart Bussmann*, Arthur Conmy**, Joshua Engels**, Neel Nanda**, Senthooran Rajamanoharan**
* primary contributors
** advice and mentorship
TL;DR
We study a simple latent reasoning LLM on math tasks using standard mechanistic interpretability techniques to see whether the latent reasoning process (i.e., vector-based chain of thought) is interpretable.
Results:
We find that the model solves maths problems requiring three reasoning steps by storing the two intermediate values in specific latent vectors (the third and fifth of six). We established this using standard mechanistic interpretability techniques.
The logit lens shows that intermediate calculations are represented in the residual stream during latent reasoning.
The latent vectors are not perfectly interpretable via the logit lens, but through patching, we demonstrate that they store intermediate calculations.
Patching has no effect on the model’s accuracy when applied to problems with the same intermediate value, and at the same time changes the answer in the expected way when applied to problems with a different intermediate value.
We believe the CODI latent reasoning model we use is a reasonable object of interpretability study, as it is trained to have a relatively weak natural language prior in its latent vectors. Our findings suggest that applying LLM interpretability techniques to latent reasoning models is a promising direction. However, this may become harder with more capable models trained on broader tasks.
This was a time-boxed research sprint and we decided not to pursue this direction further, but we would be excited to see others explore this area or build on our work, so we’re sharing our preliminary results.
The CODI model used in this study on HuggingFace
GitHub repository
Introduction
Today’s best-performing LLMs are reasoning models, which generate a thinking process—known as chain-of-thought (CoT)—before producing a final output. So far, CoT has consisted of tokens in natural language. However, latent reasoning is gaining increasing attention: in these approaches, the reasoning process is generated internally using the model’s latent space rather than natural language tokens.
Despite being harder to monitor and interpret, latent reasoning seems likely to have significant performance benefits, as vectors can store so much more information than text, making its adoption in future LLMs concerningly plausible. Chain of thought monitoring is one of our best current safety techniques, so it is important to see if we can fill that gap.
We investigate whether existing LLM interpretability techniques can uncover the computations performed during the latent thinking process. We show that simple techniques such as the logit lens, activation patching, and linear probing can reveal how the reasoning process is performed. However, our study is performed on a small model trained only to solve math tasks. We find it plausible that future, more advanced latent reasoning LLMs may be substantially harder to interpret using current techniques.
Experimental setup
CoDI model
In this study, we use a CODI model that is based on Llama 3.2 1B Instruct. CODI is a latent reasoning framework, which is designed to compress natural language reasoning into continuous “neuralese” vectors. It works via a self-distillation mechanism where a single model is jointly trained on three tasks:
Teacher Task (natural language CoT): The model learns to generate a natural language CoT followed by the answer, using standard cross-entropy loss on reasoning traces generated by a smarter model such as GPT-4o.
Student Task (latent CoT): Rather than using discrete tokens, the model is trained to provide the correct answer after reasoning in a sequence of six continuous latent vectors.
Self-distillation: To bridge the gap between natural language CoT and latent CoT, CODI is trained to align the final hidden states when reasoning in these two modalities. By minimizing the L1-distance between the representations at the answer generation step, the student learns to distill the natural language reasoning patterns within the latent space.
We train the CODI model to have six latent CoT iterations, so the model has seven latent vectors (The first latent vector is created at the beginning of the thinking token). We follow all the most important hyperparameters of the original CODI paper.
Training dataset: GSM8k and CommonsenseQA.
Does the latent reasoning provide actual performance uplift?
To determine whether the latent vectors provide an advantage over no reasoning at all, the original CODI paper compares the method against a No-CoT-SFT baseline where they fine-tune a separate model solely on direct answers. However, we argue this comparison is confounded by the training data. Because the CODI “latent CoT mode” shares the weights with the “verbalized CoT mode”, it implicitly benefits from exposure to the reasoning traces during training. This is an advantage that the standard No-CoT baseline lacks. Therefore, any performance uplift could stem from this co-training rather than the actual use of the latent vectors.
To isolate the specific contribution of the latent vectors, a proper baseline should share the same training benefits. To that end, we train a single model that can operate in three modes, using special control tokens <|eot|> (end of text), <|bocot|> (begin of CoT), and <|eocot|> (end of CoT) to delimit the reasoning sequence:
Direct answer: {prompt}<|eot_id|><|eocot|>{answer}
Verbalized CoT: {prompt}<eot_id><|bocot|>{verbal_cot}<|eocot|>{answer}
Latent CoT: {prompt}<eot_id><|bocot|><l1>...<l6><|eocot|>{answer}
In this setup, the “Direct answer” mode serves as a better baseline, as it shares the same weights as the “Latent CoT” mode. This enables us to directly attribute any performance improvement to the computation performed in the latent vectors.
| GSM8k | CommonsenseQA | MultiArith | SVAMP | |
|---|---|---|---|---|
| Direct answer | 36.72 ± 0.38 | 67.19 ± 0.31 | 67.78 ± 0.56 | 45.77 ± 0.5 |
| Verbalized CoT | 42.10 ± 0.35 (+5.38) | 64.78 ± 0.67 (-2.41) | 80.37 ± 0.64 (+12.59) | 48.50 ± 0.66 (+2.73) |
| Latent CoT | 41.60 ± 0.81 (+4.88) | 66.94 ± 0.45 (-0.25) | 83.33 ± 1.47 (+15.55) | 48.50 ± 0.44 (+2.73) |
The performance of the Llama 3.2 1B model trained for 10 epochs on about 40M tokens from the GSM8k and CommonsenseQA datasets. In parentheses, we denote the uplift over the “Direct answer” mode.
Evaluation prompts
In our experiments, we use math problems similar to these from the GSM8k dataset, requiring three reasoning steps to solve. To easily generate multiple evaluation prompts, we use 20 templates that we fill with numbers ranging from 1 to 10. In total, unless stated otherwise, we present results for 1000 prompts.
Example template:
A team starts with {X} members. They recruit {Y} new members. Then each current member recruits {Z} additional people. How many people are there now on the team? Give the answer only and nothing else.
Experiments
How many latent vectors does the model actually use?
To determine whether the model actually uses all of its latent vectors—and to identify vectors we can target for our interpretability study—we compare accuracy across different numbers of latent CoT iterations (i.e., how many vectors it can use in its chain of thought before receiving an end-of-thinking token and producing a final answer):
We observe a very notable increase in accuracy after the fifth latent iteration, which may indicate that the model uses at least the first four latent vectors. The final iteration appears unnecessary, at least on our evaluation set, as it does not improve accuracy.
Below, we try to explain what these vectors do using interpretability.
The model represents intermediate calculations in latent vectors
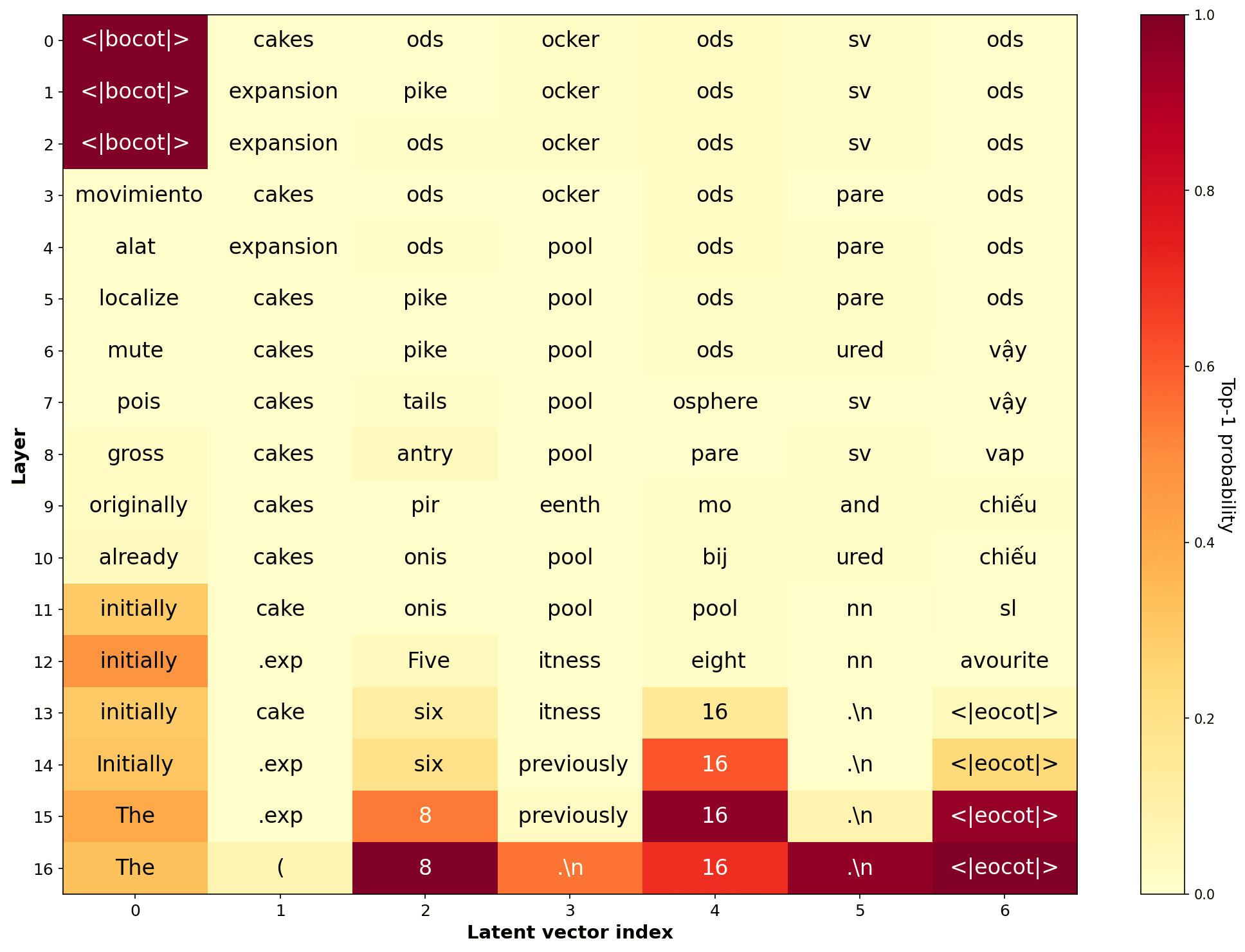
Suggestive Evidence From Logit Lens
The verbalized CoT for math problems that we trained the CODI model on usually contains intermediate calculations required to solve a math task. Here, we investigate whether the model also represents them in the latent CoT.
For example, given the prompt: “A team starts with 3 members. They recruit 5 new members. Then each current member recruits 2 additional people. How many people are there now on the team?”, we expect the reasoning should look like:
Step1: 3 + 5 = 8
Step2: Step1 * 2 = 8 * 2 = 16
Step3: Step1 + Step2 = 8 + 16 = 24
When we do the logit lens to get the most likely token at each layer on positions corresponding to the latent vectors, we see that the model indeed strongly represents Step1 value on the third latent vector and Step2 value on the fifth latent vector:
When we plot top-1 probability on the last layer of Step1 and Step2 values on all evaluation prompts:
The probability of intermediate values is very high, even when the model answers incorrectly. This suggests that the model represents intermediate results in these two latent vectors.
Causal Evidence from Activation Patching
Logit lens is suggestive but not causal. Thus, we don’t know that these representations actually matter to the model. To test this, we set up an experiment where we overwrite the original latent vectors with vectors from different prompts and observe how this affects model performance.
Specifically, we select 10 combinations of numbers (X, Y, Z) to fill our 20 prompt templates. Then, for each prompt, we overwrite its original latent vector at a specific position with either (1) a vector averaged over other prompts with the same intermediate values, (2) a vector averaged over other prompts with different intermediate values, or (3) a random vector.
We find that overwriting the third and fifth latent vectors with vectors averaged over prompts with different intermediate values notably decreases accuracy—these are the vectors that store intermediate values, and overwriting them with vectors containing different values disrupts the model. However, when we patch them with vectors averaged over different prompts that share the same intermediate values, performance remains unchanged. This demonstrates that intermediate values are stored in these vectors across prompts and can be transferred between them.
Notably, both (1) and (2) patching scenarios do not affect performance when applied to the other vectors. This suggests that these vectors may represent some general math-related computations. Moreover, we find that patching the last two vectors with random ones does not decrease accuracy, which suggests that once the second intermediate value is processed, subsequent latent vectors are unnecessary.
To obtain even stronger evidence that intermediate values stored in latent vectors impact the model’s answers, we conduct an experiment where we overwrite the fifth latent vector (the one storing the second intermediate value, Step2) and observe whether this changes the model’s answer in the expected way.
First, we compute averaged latent vectors representing specific Step2 values. We then evaluate how often the final answer flips when patching the original latent vectors with the averaged ones.
We evaluate the following baselines:
Standard sampling without patching
Fifth latent vector patched with a vector averaged over prompts with the same template
Fifth latent vector patched with a vector averaged over prompts with different templates
Patching both the latent vector and the residual stream at all layers at the fifth position
Fifth latent vector patched with a random vector
For each baseline, we plot below the frequency of the original correct answer and the answer we expect after patching the Step2 value:
We observe that in the standard sampling baseline, the model almost never predicts the answer expected after patching. However, for all three tested patching approaches, the rate at which the model outputs the expected answer is significantly higher. Importantly, this rate is also much higher than the random baseline, which rules out a less interesting scenario where the model changes its answer simply because the patching disrupts its reasoning process rather than steering it in a controlled way.
Although the frequency of the model changing its answer is not very high, note that this is a very subtle intervention: we modify only one latent vector, while the prompt itself still points to the original answer.
Are the latent vectors sufficient?
We have demonstrated that some crucial latent vectors store intermediate values, can notably impact model performance and impact its output. However, we observed that the model can partially calculate both intermediate results and the final answer from the user prompt alone[1], performing a form of internal reasoning. We now investigate how often the intermediate calculations stored in latent vectors are sufficient for the model to reach the correct answer.
To prevent the model from deriving the answer solely from the prompt, we ablate the representations of specific numbers (X, Y, Z). For each prompt template, we create 50 variations (filled with different number combinations) and average the activations across them. This diffuses the representations of specific numbers while preserving the overall math task structure. As shown in the figure below, the model almost never answers correctly when given such a mean-ablated prompt.
We then test how performance changes when we patch in (1) original latent vectors, (2) latent vectors averaged over different prompts with the same intermediate values, or (3) latent vectors averaged over prompts with different intermediate values.
Interestingly, the model recovers about 20% accuracy (from a baseline of 55%) in both cases (1) and (2). In case (2), most information stored in the latent vectors—except the intermediate calculations—is irrelevant to the math task at hand, since the latents correspond to other prompts. The fact that it still matches the performance of (1) suggests that the model primarily relies on the intermediate values stored in the latent vectors. Performance is not restored at all in case (3), as expected, since the intermediate values do not match the task.
Discussion
Our investigation suggests that neuralese latent reasoning models may be interpretable with standard interpretability techniques, but it is unclear how well these results would hold up at a larger scale and more complex tasks. This could be partly due to the fact that the model learns to reason in latent vectors while simultaneously learning to reason in natural language, which may instill a prior to reason in similar ways. Models trained via pure reinforcement learning without a verbalized teacher may develop more alien representations, rendering techniques like logit lens less effective.
A key limitation of our study is that in many of our experiments, we relied on math templates with a fixed structure requiring exactly two intermediate steps. This controlled setting allowed us to clearly identify where specific reasoning steps occurred. It remains an open question how neuralese thinking manifests in messier in-the-wild prompts where intermediate steps are ambiguous or the reasoning requires abstract, non-numerical steps. We encourage future work to investigate whether interpretable structures can be found in such domains as well.
While we strongly advocate for keeping CoTs human-readable for monitorability, we think it’s also important to stress-test and prepare interpretability techniques for latent reasoning models, in case this becomes the standard in the future. Developing robust techniques to decode or monitor neuralese thinking may be critical for safety.
Finally, we note that concurrently with our work (and unbeknownst to us during the majority of our research), the Scratchpad Thinking paper was published, exploring similar techniques. Although their study employed a different model architecture (gpt-2-small) and a different set-up involving pre-processed CoT data, our results are largely consistent. We view this convergence as promising evidence that our findings are at least somewhat generalizable and not merely artifacts of our specific configuration.
This research was made possible thanks to the support of the MATS extension program (Bartosz) and the Meridian Visiting Researcher Program (Bart).
We also thank Uzay Macar for useful discussions and feedback on this post.
- ^
We observed this both using logit lens and when calculating the similarity between token embeddings of intermediate results/final answers and the model’s activations on the user prompt.
- Latent Reasoning Sprint #3: Activation Difference Steering and Logit Lens by (4 Apr 2026 3:56 UTC; 15 points)
- Latent Reasoning Sprint #1: Tuned Lens and Logit Lens on CODI by (6 Mar 2026 18:36 UTC; 7 points)
- Latent Reasoning Sprint #4: PCA Analysis on CoDI by (18 Apr 2026 21:25 UTC; 7 points)
- Latent Reasoning Sprint #2: Token-Based Signals and Linear Probes by (19 Mar 2026 3:39 UTC; 6 points)
- Latent Reasoning Sprint #2: Token-Based Signals and Linear Probes by (14 Mar 2026 18:30 UTC; 2 points)
With how CoDI throws away the hidden state and only uses the kv values on the <|eocot|> token the accuracy drop after latent 5 could just be kv values can’t store more info.