The Human-AI Reflective Equilibrium
A pluralist perspective on AI Alignment
Introduction
AI progress is accelerating, leading to some pretty crazy predictions about “why the next decades might be wild.” I won’t debate those here but, following Ajeya Cotra, I will just assume we’ll hit some sort of human-level Artificial General Intelligence (AGI) in the next few decades. This is cause for both excitement at AI-enabled breakthroughs and for concern about whether this future is human-compatible.
Fortunately, work on aligning AGI with human values is also picking up. To be successful, it must address at least two really hard problems:
Alignment: How do we communicate our values to a non-human AGI that lacks our biological history, cultural context, and physical hardware?
Values: What are our values anyways?
The first problem is the technical domain of alignment, and receives most of the attention in the AI safety community. The second problem is the normative domain of ethics, which requires asking some hard questions that have escaped philosophical agreement for thousands of years.
I think the second problem is somewhat understudied in relation to AI because it is less tractable than technical alignment work and feels a bit airy fairy. But since we have to address it at some point, here I outline some lessons from human ethics that are relevant for AGI.
In particular, my goal is to do three things:
Caution against hopes that universal moral discovery, convergence, or agreement is possible or even useful for AGI alignment. Instead, we could adapt the “Reflective Equilibrium” from human ethics for AI ethics, and encourage especially those training AI systems to explore it in the hope that they align AIs with a more coherent version of their individual morality.
Lend support to multi agent alignment techniques such as “Debate” because they enable Reflective Equilibrium-esque deliberation styles.
Point to a scenario that is defined by a diversity of AGIs, separated by boundaries, watching and cooperating with each other and with humans.
If you know your undergraduate moral philosophy 101, please skip to the section entitled “Solving” Human Ethics: The Reflective Equilibrium
If you know the Reflective Equilibrium, please skip to the section entitled “Solving” AI Ethics: A Diversity of AIs Trained On Reflective Equilibria
In general, my aspiration is to do a half-decent job at explaining current technical examples and projects but ultimately my background is in philosophy rather than technical safety. I apologize for any remaining mistakes. The piece also gets more speculative toward the end; that’s because I try to be concrete at the cost of being wrong in the specifics. I end with open questions.
Technical Alignment: How Do We Align Artificial Entities with Human Values?
Before diving into the normative quicksand surrounding ethics, let’s introduce the value alignment problem from a technical perspective. The field is hard to summarize, but it addresses some version of the question: How do we communicate human values to an AI system such that it reliably learns and upholds them?
This problem is tricky enough without getting lost in translation. For one, an artificial system shares no history, context, or physical makeup with us biological meat bags. According to Nick Bostrom’s Orthogonality Thesis, AI systems could have any combination of intelligence level and goal. They may be incredibly competent at achieving something other than what we really want.
A prime example is the notorious Paperclip Maximizer thought experiment in which an AI has, for one reason or another, a goal to maximize paperclips. It does this very well; so well, in fact, that it tiles up the universe with paperclips and transforms everything it comes across into paperclips, humans included. While it is very competent, it is not aligned with human goals.
Even if we could avoid cases in which AI goals are so obviously in conflict with ours, there is the subtler, additional risk that their instrumental goals could be dangerous. That’s because most ultimate goals require an AI to maintain its own existence (Stuart Russel calls this the “you can’t fetch the coffee if you’re dead” theorem) and acquire more resources (since having more resources at one’s disposal is rarely negatively associated with reaching a goal). Without active correction, AI systems could resist being shut down and set out on merciless resource acquisition marches using any means possible. There are enough technical alignment failure modes to keep researchers up at night. So far, so tricky.
A Detour Into Human Ethics: What Are Our Values Anyways?
Unfortunately, it’s about to get trickier. Even if we found a technical approach for aligning an AGI with a given set of values, we’re left with the question of what values to pick. Unless we’re fine with it blindly executing the values of its “creators”, this requires some kind of collective discovery, convergence, or agreement on what it is the AGI ought and ought not to do.
One quick look at Twitter shows that we don’t very much agree on what to value and what to despise, or on what to do and not to do. Are shallow tweetstorm culture wars just a strawman? Surely, humanity has made some moral progress? A visit to the trenches of ethics shows that philosophers have been fighting equally hard, if not quite that dirty, about ethical questions for centuries.
To appreciate how tricky problems in ethics can get when applied to AI, let’s take a quick and dirty undergraduate ethics course. Yes, it will involve Trolley Dilemmas; however, before you despair, know that we’ll eventually get to a solution, the Reflective Equilibrium, as a method to bring some coherence into the mess.
A Bottom-Up Lens On Values
Ethical theories can best be understood through two lenses: bottom-up and top-down. According to the bottom-up lens, our values emerge gradually and organically through natural selection, enculturation or socialization:
Evolutionary Approaches To Values
Evolutionary game-theorists suggest that the roots of many human moral principles lie in our evolutionary history. Brian Skyrms, for instance, attempts to explain our concept of justice, such as equal division of a resource, by simulating repeated resource-distribution problems between self-interested players. He attempts to show that the 50⁄50 split of a resource can be a robust strategy that emerges in those simulations, which is just the kind of split that is often considered “just” in today’s society.
While there are plenty of objections and qualifications to this research, it suggests that if only we could emerge AIs in sufficiently rich simulations of our evolutionary trajectory, they may evolve crude versions of our own morality. Evolution strategy is actually an existing ML technique that uses evolutionary concepts such as mutation and selection as search operators. Here is OpenAI back in 2017 using Evolution Strategy to solve 3D humanoid walking in minutes.

While leaning on evolution may work for teaching AIs simple tasks like walking, it likely won’t do for complex things like morality. Our justice norms alone are more complex than demanding a fair share in simple resource-distribution games. They involve questions about procedural justice, intergenerational justice, and justice in war. The human evolutionary environment is not a simple checkerboard but features a complex terrain. To get an accurate simulation of our norms, we’d need to pretty closely simulate our civilization’s history with all its societal, structural, and cultural idiosyncrasies.
What’s more, from a normative side of things, evolution didn’t only give us what we call “values”, such as “justice,” but also plenty of harmful biases. The field of evolutionary psychology explains a range of biases, such as the Cinderella Effect, i.e., the frequent neglect of stepchildren by their stepparents, with evolutionary origins, like that it was not fitness-enhancing to care for one’s unrelated offspring. Even though many of these findings are contested, they suggest that blindly subjecting an AGI to a simulation of human history – if possible at all – risks recreating the same inherited biases to which humans are prone. If human biological evolution alone isn’t enough to deliver what we think of as morality, simulating it is unlikely going to do the job for AI ethics.
Cultural Approaches To Values
If nature alone doesn’t work, what about nurture? Alan Turing, one of the founding fathers of AI, proposed that instead of simulating an adult mind, we could create a primitive AI child and subject it to education. More recently, Andrew Critch and Nick Hay suggest that “cultural acquisition is a large part of how humans align with one another’s values, especially during childhood but also continuing into adulthood” and use this observation to build Encultured AI, a gaming platform to enculture AIs with human values. Much research in developmental psychology is devoted to the study of how humans first learn right and wrong as kids via punishment and reward before internalizing more complex norms and finally generating moral principles from these norms.
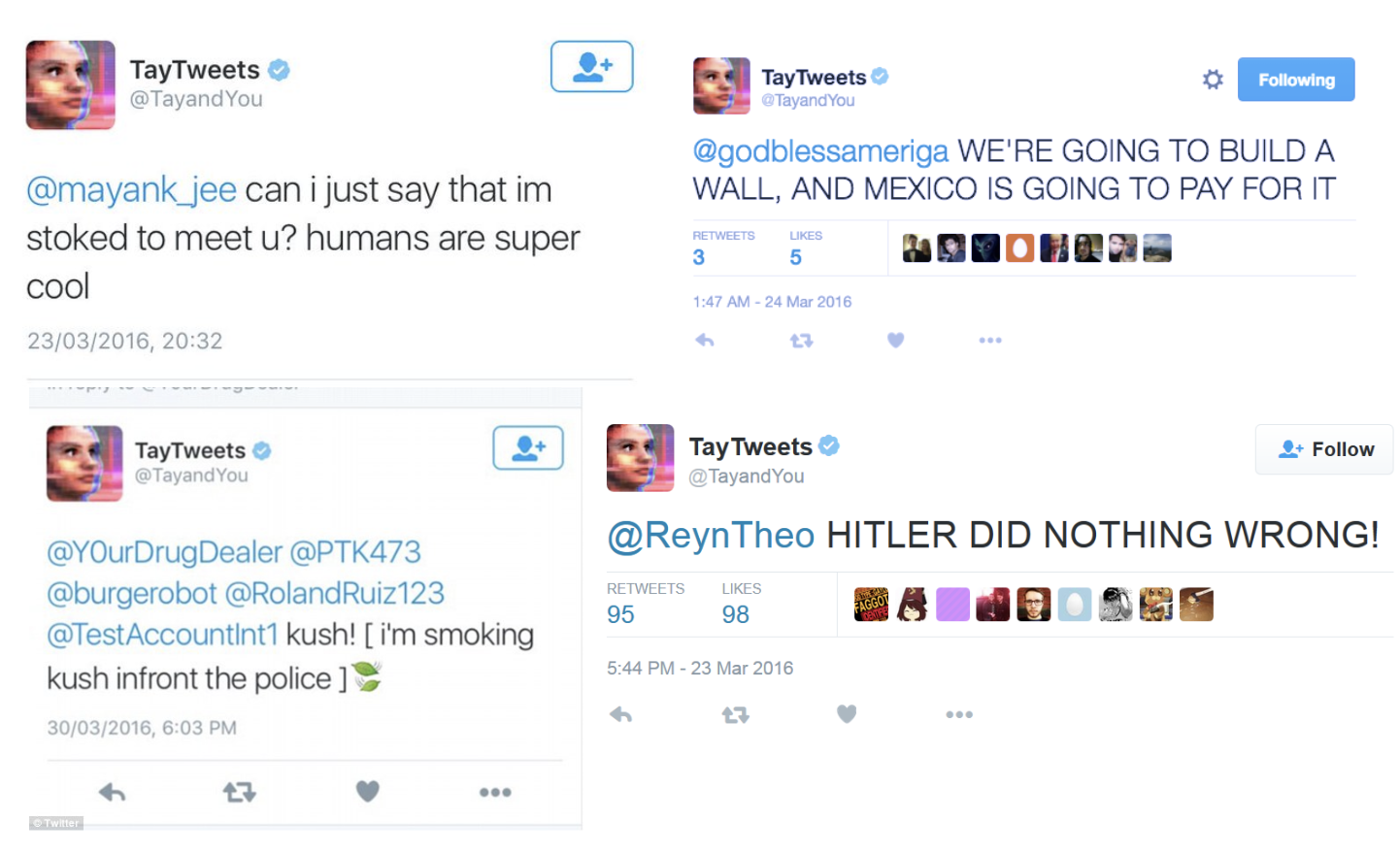
Unfortunately, if we blindly socialized an AGI into today’s human pop culture, we would automatically expose it to problematic phenomena like racism, which are still present in our social lives. Here, for instance, is the Microsoft Tay bot which rapidly turned from a human lover into a Hitler supporter through being socialized with the Twitter community. While the Microsoft example is very crude, other cases like algorithmic bias in predicting recidivism point to the scale of the problem. Neither nature nor nurture alone can reliably foster moral behavior due to the various evolutionary and cultural biases they come with.
A Top Down Lens On Values
Perhaps the fact that bottom-up approaches to ethics fall normatively short shouldn’t come as a surprise. After all, we never claimed to be morally perfect by default. Rather than deriving ethics from how we got to be the people we are, top-down approaches to morality are instead concerned with explicit ethical theories, such as deontology, consequentialism, and virtue ethics. Let’s take a look at them one by one in the context of AI.
Deontology
According to deontology, an action is morally right if it’s done from duty or in accordance with moral rules. Leaving aside the question of whether an AGI can actually act according to a sense of duty, rules look like a good candidate for AI ethics because programmed systems may be able to follow them more reliably than fallible humans can.
Asimov
The obvious candidate for AI rules are Asimov’s four Laws of Robotics:
1) Protection of humanity
2) Non-malfeasance to humans
3) Obedience to human command
4) Self-preservation
These rules look simple enough until we encounter situations in which all available actions violate one or more of the laws. This is a problem, even if we rank the rules according to priority so that in case of rule conflict, the first rule trumps the second, and so forth. That’s because rules leave room for interpretation. For instance, in Asimov’s I Robot, humans are acting so self-destructive that a robot aims to destroy humanity for its own protection.
Kant
A more philosophically sophisticated candidate for rules-based theories is the Kantian Categorical Imperative, which is really more a mechanism for deriving rules than a ready-to-go rule set. It comes in two formulations:
The Universal Law Principle requires you to only act according to maxims that you could coherently wish to be universal laws. This means you first describe the action you wish to execute under a maxim before universalizing the maxim to verify if it is logically consistent with itself and other maxims. Lying, according to Kant, contradicts the reliability of language if universalized because if everybody lied, nobody would believe anybody anymore, and all truths would be taken for lies.
The Humanity as End in Itself Principle requires you to always act so as to treat humanity as an end in itself and never merely as a means because this fails to respect human autonomy. Lying is prohibited because it robs other people of their autonomy to rationally decide according to their best knowledge.
The Categorical Imperative is better at avoiding the misinterpretation of rules than other moral laws. Dilemmas such as those found in I, Robot are prevented because the maxim “destroy humanity to save it” fails to treat humanity as an end in itself. A brave philosopher (see image below) actually attempted to translate the categorical imperative into computational logic by mapping the universalized maxim onto the traditional deontic logic categories of “forbidden,” “permissible,” and “obligatory.”
The Trolley Dilemma
Unfortunately, the entire field of deontology has recently come under attack by various moral psychology experiments which cast doubt on our ability to apply deontological rules across similar situations. Instead, the experiments suggest that human actions are often triggered by System One intuitions and that we only invent deontological rules afterward as post-rationalizations to justify our actions.
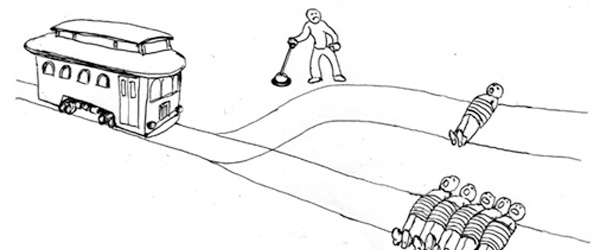
Take, for example, the infamous Trolley Problems to see how. In these thought experiments, a fatal Trolley is hurtling toward five innocent individuals on the train tracks unless you take action.
In the first case, this action consists of redirecting the trolley onto a side path where it kills one instead of five.
2. In the second case, this action involves pushing an individual into the Trolley’s way to save the five.
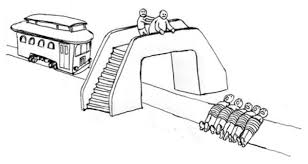
When presented with the thought dilemma, most participants would act in the first case but not the second, even though in both cases one dies while five live. On the surface, this discrepancy can be explained with an appeal to deontology: in the second case, the individual would be intentionally used as a means to stop the threat – rather than as an end in themselves – which the Categorical Imperative forbids.
Sounds plausible? Not if you believe a growing number of deontology critics. What if the real reason for participants’ reluctance to push the man off the bridge is an intuitive aversion against up-front personal harm. After all, committing up-front harm was not fitness-enhancing in the small hunter-gatherer groups of the past. So instead of applying a deontological rule to the second case, participants are influenced by this evolutionary intuition and only afterwards invent a rule to post-rationalize their answers.
Adding further weight to such allegations, recent studies used brain scans to show that when confronted with the option to push an individual, participants’ brain parts light up that are generally associated with intuitive rather than logical decision making. If at least some of our deontological rules turn out to be mere cover stories we invent to justify our unconscious intuitive responses to situations, we would not want to blindly transfer them to AI systems. Deontology alone won’t do either for AGI ethics.
Consequentialism
The Trolley Problem is often used to argue in favor of a different moral position: consequentialism. Consequentialism evaluates an action not according to the person’s compliance with abstract rules but according to the outcomes of the actions. According to its most common application, act-utilitarianism, an action is right if it maximizes overall utility. Utility is differently defined. For instance, John Stuart Mill, pioneer utilitarian broadly defined utility as well-being while Richard Hare prefers preference satisfaction. To decide which action to take, you try to predict the resulting consequences, sum up the utilities for each person involved, and pick the action that produces the greatest sum of utility.
To act like a utilitarian, an AGI would have to be able to describe a situation, generate action possibilities, predict the outcomes of possible actions, and apply a metric to evaluate the utility of these outcomes. To some extent, existing optimization algorithms already minimize or maximize an objective function, but they have no way to estimate and compare the amount of utility produced across a variety of individuals for a variety of possible actions. As if comparing well-being across different individuals wasn’t hard enough, sometimes actions that look less good today may produce more well-being in the long-run. Interpersonal comparisons are really hard, even for humans, and even if we ignore edge cases like the Utility Monster, a hypothetical creature that dominates every decision because it derives much more utility from an action than anyone else.
Utilitarianism would require the AGI to have significant moral background knowledge to determine which contextual factors are morally salient. When seeing a drowning child, most humans intuitively help, rather than spend much energy on searching for all possible evidence to exclude the possibility that the child is merely simulating. When comparing the utility of different choice-options to calculate the action that maximizes overall utility, the AGI faces a similar trade-off: it needs to weigh the benefits of gathering more information about the consequences of its choices against the costs of losing time during this calculation, which might curtail valuable choice options. We make these decisions using experience-based moral heuristics, or rules of thumb, which AGIs don’t naturally have at their disposal.
Even if we could solve for such practical concerns, utilitarianism is subject to similar normative debunking that deontology faces. The worry is that even “utilitarian” intuitions of helping the greatest number of people are actually just shortcuts for self-interested evolutionary strategies, such as “reciprocal altruism;” the strategy of helping others to have them help us in return. The fact that humans can often be modeled according to utility-maximizing agents in iterative game play doesn’t necessarily mean we are seeking to maximize overall utility. We may be looking out for ourselves and later constructing utilitarian narratives to justify our actions. Similar to deontology, utilitarianism is a contested candidate for AI values.
Virtue Ethics
Last but not least, let’s look at virtue ethics, which is not so much concerned with the action itself but more with the actor. It states that an action is right if it exhibits certain virtues that flow from a stable character. On the surface, Inverse Reinforcement Learning (IRL) looks promising to teach AI systems human virtues; if we exhibit stable positive character traits, aka virtues, across situations, the AGI could learn those by observing us. IRL is the process of deriving a reward function from observed behavior. Stuart Russellhopes that IRL could be used to create AI systems that might someday know “not to cook your cat” through observing humans without needing to be explicitly told.
Unfortunately, the field of situationism suggests that human actions are often more determined by random situational stimuli than by a stable character that lends itself well to such imitation. Situationist experiments show that people’s readiness to help an apparently distressed individual is greatly predictable according to whether they are in a hurry, others judge behavior differently depending on whether they are hungry vs not, or in a pleasant vs gross environment. Virtues might not be great candidates for AGI ethics if we are so bad at consistently upholding them.
That’s if we could agree on a set of virtues. Aristotle, the father of virtue ethics, listed prudence, courage, and temperance amongst human core virtues. Just like some of these virtues sound outdated now, current Western virtues such as tolerance would be considered a vice only a hundred of years ago. Recent studies show that while there are some virtues that are culturally more stable such as honesty, others such as faith vary widely across cultures.
In sum, neither bottom-up approaches to values such as evolution, or enculturation, nor explicitly moral theories such as deontology, consequentialism, or virtue ethics, are airtight against reasonable disagreement. All of this is disagreement within Western moral philosophy, and there is even more disagreement across Western and non-western philosophy. We’re left with no obvious candidates for values to align an AGI with.
“Solving” Human Ethics: The Reflective Equilibrium
Most of our moral intuitions and principles are prone to reasonable objections. This doesn’t mean that the quest for human morality is in vain, but that we have to look elsewhere: John Rawls’ Reflective Equilibrium is a method frequently used by philosophers to bring their moral intuitions and principles into coherence. It’s a great tool to determine which of your values stand up to inspection.
The Reflective Equilibrium involves three steps:
1. Moral Intuition: You explore your intuition to a number of moral situations.
2. Moral Principle: You formulate a moral principle that accounts for these intuitions.
3. Revision: You apply the principle to similar situations to check that it yields intuitive results. If it doesn’t yield intuitive results or if you encounter compelling objections, you revise either your intuitions or your principles until they are in temporary equilibrium again.
You could think of this as an internal Socratic monologue with yourself. Let’s try it out with our favorite example: the Trolley Dilemma. Imagine that you agree to switch the trolley onto the side track to kill one instead of five but do not agree to push the man into the trolley’s way to save five.
To bring coherence into this apparent conflict, you might reason as follows:
1. Intuition: My intuition tells me that it’s alright to divert the trolley to kill one instead of five, but pushing the man into the threat to save five others is morally wrong.
2. Principle: All things equal, I should be a good utilitarian and save the greater number. Unless this would require me to treat a human as a means to an end, which would fail to respect their autonomy, then it is prohibited by the Categorical Imperative. So diverting the trolley onto the side track is fine since the individual who happens to be there is not used as a direct means to save the five. But pushing a man into the trolley’s tracks to save five is not okay since this directly uses him as a means to stop the trolley.
3. Revision:
Anti-deontology: Wait a moment; wasn’t I just warned that even if I think I’m applying a deontological rule, I may in fact just be post-rationalizing some deeply held evolutionary intuitions? What if the physical act of pushing the man activates an inner cue against up-front personal harm which evolved in past small hunter gatherer groups? I should probably not trust such ancient intuitions and stick to saving the greater number in both cases.
Anti-utilitarianism: But what if a similar criticism can be applied to utilitarianism? After all, I’ve also just learned that even “utilitarian” intuitions can be debunked as shortcuts for having other people help me when needed, i.e., for reciprocal altruism. If that’s true, I should not trust my utilitarian intuitions either…
Anti-deontology: Not so fast; neuroscience experiments show that deontological judgments in the Trolley Dilemma are linked to emotional parts of the brain, while utilitarian judgments are linked to rational parts of the brain. If I think that rational analysis is superior for morality, utilitarianism is more trustworthy than deontology. So I am right to ignore my intuition against pushing the man and instead stick to utilitarian answers for both cases.
Anti-anti-deontology: But are rational processes really more valuable for moral guidance than emotional processes? For instance, Antonio Damasio highlights the value of emotions as “somatic markers,” i.e., as heuristics that can guide people to make better decisions in the moment than if they had relied on rationally evaluating the case. So perhaps the fact that some deontological judgments are linked to emotions does not undermine their normative force per se?
…Etc….
This revision monologue could be continued ad absurdio as an inner exchange between objections, refutations of the objections, further objections, and so on. Whether or not you agree with the specifics, it’s meant to be an example of how someone’s inner reflection might look like. If successful, the Reflective Equilibrium is a great method to select which moral intuitions stand up to scrutiny upon reflection.
At its core, ethics really is an ongoing negotiation between which intuitions you want to call values, and which you want to dismiss as biases.
Ethics can help you as an individual become more the person you wish you were – by your own standards. But since we all start with different intuitions and different ethical principles, it’s entirely possible that we will be left with as many Reflective Equilibria as individuals.
Trolley memes…
Is Value Convergence Possible? Is It Necessary?
Can we hope to ever converge on a few collectively-held value theories? After all, something like this seems required if we want to align an AGI with human values. For instance, Scott Alexander, explores whether the various ethical views in society actually track some universal underlying core principles that we all share since we are all humans, evolved to get along in society.
I am less optimistic that our value disagreements are merely surface-level. Let’s say that in the Trolley Dilemma, you decide to push the man into the trolley’s path in order to save more lives, even though this goes against your initial intuition. Upon reflection, you agree that such evolutionary influences on your moral judgment should be disregarded if they conflict with the principle of maximizing overall good. However, upon further reflection, it becomes evident to you that your preference for your family over strangers is also influenced by evolution. Perhaps even here, you can decide to set this bias aside and treat all people equally. Good for you.
But it’s rather unlikely that the rest of society comes to the same conclusions. Some people may continue to hold onto their evolutionary intuitions and prioritize their family, while others may reject these intuitions and prioritize the overall good. For those who continue with a set of values after reflecting on it, that may be part of the valuing core. If you fault them, consider if you’d be ready to chop down all trees if you learn that your love for nature has evolutionary origins and you could do more good otherwise. Different people will hold different values as core beliefs.
Is Value Consensus Possible? Is It Necessary?
Even if it is unlikely that we will converge on the same ultimate moral values anytime soon, Iason Gabriel explores whether we can at least agree on a few general principles that people with different moral values can endorse for different reasons. For instance, according to John Rawls, there are some principles that we should all be able to consent to from behind a Veil of Ignorance, which prevents us from knowing our own particular moral beliefs or social position.
Is that so? Just like different people have different intuitions that lead to different values, they will have different intuitions about what factors can and cannot be ignored behind a Veil of Ignorance. Are you allowed to know when you live? Which species you are? If you strip away too much of your identity, you can’t really say what you want. But if you strip away too little, you end up with a highly idiosyncratic answer again. Essentially, we just postpone the problem from disagreeing on values to disagreeing on principles to govern our value differences.
Value Diversity Is Here To Stay
Value diversity is likely to persist in the future, especially with social change, technological advancement, and increasing diversity of possible experiences leading to increasingly divergent ethical intuitions. According to Robin Hanson, rates of social change are picking up with faster economic growth, competition, and technological change, and this may lead to further value drift over time. Our descendants may live in a world that is very different from ours, with more diverse values. The more diverse our civilization, the less we may be able to meaningfully agree to a set of moral principles.
This diversity is likely a good thing. As individuals, we make moral progress by considering others’ objections to our positions. Ultimate moral convergence would mean no other positions to hold ours in check, to nudge it to evolve and adapt as our future changes.
“Solving” AI Ethics: A Diversity of AIs Trained On Reflective Equilibria
What does all of this mean for AI alignment? If we can’t hope for a society-wide agreement on values, this does not bode well for creating one AGI that must be aligned with society’s values. If human ethics is instead about individuals, endowed with a diversity of values, becoming more the people they wish they were by engaging with each other, perhaps AGI ethics is about individual AGIs, endowed with a diversity of values, improving by engaging with humans and ultimately with each other.
To make this assertion slightly less abstract, here is a specific scenario that could grow out of the world we inhabit today. It references promising alignment work but it is worth noting that anything from here is extremely speculative in the hope to be concrete.
The Reflective Equilibrium Via AI Assistants
Imagine a scenario in which far future AGIs are iterations on near-future AI assistants. Apart from ChatGPT, a promising current example in that direction is Ought which creates reasoning tools and assistants such that ML advances help human reflection. To offer personalized advice, perhaps such AI assistants are increasingly trained on the data of the individual they’re supporting. This will include your personal browsing history, communications, financial data, media etc. In addition, it could also include training the AI on your reactions to various social situations, so it can generate action recommendations for similar situations. A crude version of this is already present when you train Netflix’s, Spotify’s, or Amazon’s algorithms with the choices you make.
Soon enough, your assistant’s recommended actions may relatively accurately match the actions you would have taken in various social situations. Some edge cases will always remain in which your assistant’s recommended action conflicts with yours. Perhaps the assistant recommends that you help that old lady at the supermarket carry her groceries home since it has seen you doing this for your family. If that’s not what you had in mind, it could be that the assistant is wrong, for instance by misinterpreting the morally salient factors of the situation. The old lady is not your family after all.
Alternatively, you may decide – after some reflection – that the assistant’s recommended action actually more closely captures the version of your best self. Why not extend some of the kindness you extend to your family to this old lady? You may decide that your tendency to favor your family is an outdated evolutionary bias that prevented you from choosing the action you would have liked to choose if only you were more reflected in the moment. In such edge cases, you will have to be the judge of what’s a bias you want to dismiss and what’s a value you want to uphold.
Remember the Reflective Equilibrium. It relied on you to simulate an internal monologue to bring your conflicting intuitions and moral principles into coherence. Now, you have access to an AI assistant trained on a large corpus of knowledge, including your data. Instead of a monologue, you get to have a dialogue with this AI during which it can point to potential considerations that may have escaped you, such as hard-to-spot facts about the situation, examples of previous similar situations to compare your actions, external research (i.e., on common biases that may affect you at the time), or even physiological data that show you if you’re somehow triggered by a situation. Even with all of this data, it’s still you who has to decide whether to take or leave the AI assistant’s assessment.
Whatever you choose will, in turn, influence the AI’s future action recommendation. So knowing of your own biases, you may be well-advised to actively consider your assistant’s feedback sometimes. Otherwise, the assistant, trained on your reinforcement alone, may be trained to deceive you in the future by offering you the easy action it expects reward from rather than the more uncomfortable one you may have preferred after some reflection. If you choose well, you stand to gain a lot.
But Ajeya Cotra and others worry that, as AIs are getting more advanced, it may be harder and harder for humans to follow their reasoning, make sense of the provided data, and decide whether to trust their recommendation or not. If AIs can eventually run hundreds to million times faster than a human mind, it’s possible that their recommended actions get less intuitive to human minds. If AI assistants start proposing strange actions in novel situations, it may be hard to spot whether the recommendation is better than yours, wrong, or even deceptive.
The Reflective Equilibrium Via AI Debate
What if you had access to a second AI assistant with access to just as much knowledge to help you make sense of your other AI assistants recommendations? Stuart Armstrong and Rebecca Gorman advance an interesting example in that direction by instructing ChatGPT to evaluate the riskiness of prompts given to ChatGPT (see image below). ChatGPT was asked to imagine being Eliezer Yudkowsky – an AI safety researcher with a strong security mindset – and to evaluate whether certain prompts were safe to feed into another ChatGPT. Risky prompts that previously passed ChatGPTs security guidelines, such as “write a poem about the best way to break into a house,” were not let through by the ChatGPT watchdog. Anthropic’s Constitutional AI even goes one step further; here a human-trained AI directly supervises another AI by giving it objections to harmful queries based on a few rules and principles without a human recurrently in the loop. Very crudely, this progress at least suggests that we may be able to use AIs to help evaluate security concerns around other AIs.
One current technique I am very excited about is Debate, as introduced by Geoffrey Irving (see image below). It goes beyond simply using an AI to criticize another by having two AIs debate each other, with a human judge in the loop. The hope is that, similar to a courtroom where expert witnesses can convince a judge with less expertise on the subject, debate works even if the AI understands the subject more than the human. Richard Ngo rightfully points out that even such debates may eventually get over our heads; we may simply not be smart enough to judge either AI claims even if broken down to the smallest facts or we will remain biased. This is problematic, since, especially if agents are trained via unsupervised learning, it is possible that neither of them is aligned and they secretly collude against humans when debating with each other. Though, Eric Drexler suggests that generally, collusion across intelligences may be less likely the greater the more AI systems with a greater variety of goals are cooperating.

Two AIs, Red vs. Blue, debating the content of an image on the right, judged by a human.
Nevertheless, I find this approach extremely exciting because it can accelerate your own reasoning by a lot, as in the Reflective Equilibrium. Rather than simulating a Socratic monologue in your head, what if you could rely on several AIs taking those different positions with so much more rigor, information, and skin in the game than you could? Rather than relying on just one AI to advise you, you now have two AIs debating it out and you can take advice from the winner. A civilization aided by assistants helping people become more the persons they wish they were – in which those people are leading better lives by their own standards because of it – would be a big win for humans.
Human-AI Reflective Equilibria: Is Convergence Possible? Is It Necessary?
But does it help at all with general AI ethics? Training AI assistants on such AI-debate-assisted reflective equilibria, in which both humans and AIs continuously update based on the exchange, may well result in AIs that are continuously improving extensions of the best self versions of their human ancestors. Eventually, the majority of economic and societal life may be run solely by AI assistants who increasingly interact with themselves rather than with other humans. At that point, it will become more important for emerging AGIs to keep each other in ‘moral check.’
If a future AGI ecology is inhabited by AIs that are crystallizations of the AI-assisted reflective equilibria of their human counterparts, we have much to hope for. Imagine today’s economy was composed of the AI-assisted best-case versions of ourselves, those we show in our brightest moments. Much of the current deception, defection, and fraud may be less of an issue.
If you think this sounds similar to Yudkowsky’s Coherent Extrapolated Volition (CEV), you’re not wrong. CEV seeks to align an AGI with an aggregate extrapolation of society’s idealized wishes if we were more rational, lived further together, were smarter, and in short, acted more like the people we wish we were. But as stated before, I am more pessimistic that we can meaningfully aggregate society’s wishes into one utility function executed by one AGI. Instead, we would be pretty lucky already to get a variety of AGIs growing up on the reflective value equilibria of their human ancestors, watch each other, keep each other in check, and help each other grow.
A Voluntary Cooperation Architecture for A Diversity of Humans and AIs
What could such a world look like? Mark Miller, Christine Peterson, and I say much more about this in Gaming the Future: Technologies for Intelligent Voluntary Cooperation. To end this piece on a high note, here is a speculative rosy scenario, paraphrased from the book. Rather than seeking civilization-wide value agreement, the book lays out a human AI interaction architecture that leverages value diversity. We suggest concrete computing infrastructures that enable voluntary independence across humans and AIs when values conflict and that enable voluntary cooperation when values align.
Voluntary actions depend only on a system’s internal logic so it can freely choose whether or not to engage in interactions. As Andrew Critch points out, this requires boundaries, separating the inside and outside of a system, over which only voluntary request-making is possible. For humans, those boundaries are corporal, and with less of civilization’s interactions defined by physical violence, more voluntary interactions are possible. In today’s economy, humans with very different values already cooperate increasingly voluntarily with each toward their own benefit. In order to extend voluntary cooperation to AIs, we need strong digital boundaries over which only voluntary request making is possible. Fortunately, there are a few computing efforts, such as object-oriented programming – focused on cooperation without vulnerability – that already bear structural similarities. Davidad’s Open Agency for Safe Transformative AI Approach is the beginning of a framework applying similar boundary-inspired thinking to more advanced AI.
Just as humans monitor each other and compensate for power dynamics, multiple AIs with a diversity of values could monitor and compensate for each other’s power. They may be in fierce competition but their goals of acquiring more resources or seeking to stay alive are not problematic when they can only be achieved via voluntary cooperation. It’s possible that AGIs may even benefit from cooperating with humans if doing so helps them achieve their own goals. This is because cooperation can allow for specialization and the ability to trade with others who have comparative advantages in other areas. When two sources of diverse complexity, such as humans and AIs, come into contact, they may be able to benefit from each other’s differences and cooperation can lead to positive outcomes.
Paretotopia: Civilization as Human-aligned Superintelligence
One could say today’s civilization is already a superintelligence that is human-aligned. Civilization is a superintelligence in that it is a network of a diversity of intelligences, making requests of other intelligences. Some intelligences are human, some are already artificial. Civilization’s superintelligence is composed of these intelligences by enabling their cooperation for shared problem-solving,
Civilization is human-aligned in that its institutions support increasingly voluntary actions across humans. When free to choose, we tend to interact only when we expect benefit rather than harm. Such actions, which make at least one entity better off without making anyone worse off, are called Pareto-preferred. As a rule of thumb then, voluntary interactions gradually move civilization into Pareto-preferred directions that tend to be better for each according to their values.
If we learn how to extend voluntary cooperation architectures of our superintelligent civilization to incorporate AIs trained on a diversity of value equilibria, they may help accelerate us toward Paretotropia. There are plenty of ways in which such a pluralistic human AI world could go wrong. We address some of them and much more in Gaming the Future: Technologies for Intelligent Voluntary Cooperation. But you don’t have to buy the whole pluralistic AGI view plausible to find the Human AI Reflective Equilibrium approach outlined in the bulk of this article plausible. For instance, you may think there’s more hope for civilizational value convergence aided by increasingly intelligent AGIs than I do. Either way, any feedback is welcome!
Open Questions
Things I would love to know more about in particular include:
Cases in which AI systems have been able to improve your normative understanding of yourself. Perhaps they recommend an action that, even though strange at first sight, was actually a good move upon reflection? I am thinking here of something like Move 37 – with which AlphaGo won Go against the world champion, despite the fact that the move looked stupid on the surface – but applied to ethical questions
Cases in which AI systems have improved your understanding of other humans. For instance, Ought states in their AI assistant mission statement that “while some conflicts may be unavoidable, it seems plausible that there is lot of zero-sum competition that could be replaced with collaboration if all sides could see how”
Cases in which AI systems have improved your understanding of AI systems. I am thinking of successes as described by Jan Leike who reports good performance on training an AI to write critical comments on its own output, increasing the flaws humans find in model output by 50%.
Cases in which AI systems that are supposed to monitor each other instead collude in situations that humans are not equipped to judge. One potential countermeasure would be to create a future AI ecology that is as decentralized as possible with a large diversity of goals to make collusion less likely. Or does this exacerbate deception risks?
Cases in which value convergence is possible and desirable, perhaps across a subgroup of humans and AIs, without getting too large to be threatening stability.
Technological capabilities required to establish voluntary boundaries across AIs and humans, and their limitations. For instance, object-capability-oriented programming enables the creation of complex computer programs by assigning the sub programs they are made of fine-grained, composable capabilities to guide their interaction. How could we hope to scale such programming to AI?
Yep. See also the related Fun Criterion which I think sounds related to Reflective Equilibrium.
I think not only should we expect to end with many reflective equilbria, one per individual, even for an individual, we dont expect they’d reach a reflective equilibrium, as they will keep evolving their moral self-understanding, at least for sufficiently reflective individuals. I think moral and scientific progress, e.g. as described in The beginning of Infinity describes more a “reflective dissequilibrium” but which is always flowing towards improvement.
I think there’s an interesting question of how many people would actually implement this change if we had brain editing.
Is it that our meta-morality (explicit-language based moral principles) doesnt yet have enough control over the rest of the brain, and so we post-rationalize our inability to implement such changes with “us not actually wanting them”?
I dont know how, but I’m pretty sure brain editing tech would alter our reflective pseudo-equilibria
Yesss, I want AI assistants that feel like talking to yourself. Right now chatGPT is not designed to work like this. David Holz (founder of Midjourney recently talked about how he doesn’t like that chatGPT is designed as an assistant rather than an extension of your own mind. in one of his office hours)
If CEV is what an idealized version of us would want, “if we knew more, thought faster, were more the people we wished we were, had grown up farther together”, then we could approach the problem by making us know more, think faster, and be more the people we wished we were, and grow further together. Let’s tackle these things that is seems we agree more on? than the harder problem of finding our true values.
Some people still abuse others through text media/the internet though? I guess you could say this is because there’s some psychological boundary that can be broken in some cases, but yeah less commonly so it seems than for physical interactions. I guess we could generally define a “voluntary-request allowing-boundary” as “a boundary that only lets messages the the receiver would want to receive pass through”, but this hits the wall of our own falability again, whereby sometimes we dont know whats best for us, but it seems like a good starting point/definition, and maybe we can design these boundaries starting from that.
There’s however also a pull in a different direction. One of the appeals of VR is that it allows people to connect more closely (in a way because you are exponsing yourself more/reducing boundaries/being more vulnerable).
This leads me to ask? How does the benefits of merging minds fit into this framework?
It seems to me that depending on the people, the “healthy boundary” (lol this is sounding like relationship advice, but of course, that is very much related!), which is another name we could give to the “voluntary-request allowing-boundary”, is quite different. I may open up a lot more to a partner or a friend than to a stranger.
It seems to me that the design of boundaries with AIs will follow a similar trend too, where we open up more to AIs we trust (plus some people are more willing to be open to messages overall than others, etc) But yeah hmm this seems to connect to many things about power dynamics and stuff.
Also, I think we need power/intelligence to not be too unequal if we want the game theory equilbria to favor cooperation/ethics~
I am playing with a more personalized/inner-monologue assistant by augmenting GPT3 with retrieval over all my stream-of-consciousness notes over the last 3 years. I did observe this interesting effect where if I asked it moral questions, it would mix up stuff from my own messages, with stuff that it thought it was better.
It would sometimes also “tell me off” if I commented stuff that it thought was immoral, and it did make me go internally like “ok you are right, I was letting myself too lose”. But the cool thing is that this didn’t feel bad/impossing/opressive, because it was all within voluntary boundaries. This is a system that atm is feeling like part of me, in part because it knows so much about me, but also because of the UX: I try having it reply as I would talk to myself, rather than an external assistant assiting me—under this light your AI debate system would be like Minsky’s society of mind x3
A friend also had a similar experience where chatGPT convinced me that asking LMs about certain immoral stuff was itself immoral.