Gaia Network: An Illustrated Primer
NB: this post has lost footnotes. Please read the version on Effective Altruism Forum with footnotes.
In our first LW post on the Gaia Network, we framed it as a solution to the challenges of building safe, transformative AI. However, the true potential of Gaia as a “world-wide web of causal models” goes far beyond that, and in fact, justifying it in terms of its value to other use cases is key to showing its viability for AI safety. At the same time, the previous post focused more on the “what” and “why”, and didn’t really talk much about the “how”. In this piece, we’ll correct both of these flaws: we’ll visually walk through the Gaia Network’s mechanics, with concrete use cases in mind.
The first two parts will cover use cases related to making science more effective and efficient. These would already be sufficient to justify the importance of building the Gaia Network: as “science is the only news”, improving science can have a huge positive multiplier effect on our future survival and prosperity. Yet despite a workforce of 8.8 million researchers and funding that adds up to 1.7% of global GDP, science is rightly criticized for inefficiency and limited accountability. The third part will expand beyond the epistemic (scientific) benefits of the Gaia Network and towards pragmatic impact—ie, making all decision-making more effective and efficient, which impacts the entire world population and GDP. And the last two sections will focus on the applications of the Gaia Network on existential risk—first specifically with regard to AI safety, and finally as a general tool for collective sensemaking and coordination around the Metacrisis.
For brevity’s sake, we will not cover any of the implementation details or mathematical grounding. We’ll focus on the core concepts and capabilities, and try to explain them in plain language. We’ll also skim over much of the “hard parts”: the economics and trust modeling. Finally, we will not cover the arguments for convergence and resilience of the network; these have been already sketched out in our previous paper, and merit a more formal and in-depth analysis than we can incorporate into this primer. If there’s some hand-waving in the below that makes you uncomfortable, please let us know in the comments and we will attempt to assuage you.
The beginning will take a bit long with Bayesian statistics, as these are foundational concepts for the Gaia architecture. Feel free to skip the footnotes if you’re overwhelmed. Also, note that everything below assumes explicit or clear-box models (where model parameters have names that reflect their intended semantics). In a future article, we’ll discuss how to incorporate black-box models like neural networks, where most components (neurons) have opaque semantics.
So let’s get started. Fast forward to a few years from now…
Better science bottom-up
You’re a plant geneticist working on the analysis of some experimental results that you want to publish. You have a model of how your new maize strain improves yields, and you’ve tested it against an experimental data set. (In the example pseudocode below, we use a Python-based syntax for concreteness, but this could be implemented in any statistical analysis software or framework, like R or Julia or even Excel spreadsheets.)
def model(strainplanted, soiltype, rainfall, cropyield):
## Set parameter priors
deltayield ~ Normal(...)
avgyield_control ~ Normal(...)
avgyield_experimental ~ Normal(avgield_control + deltayield, ...)
𝛽_soiltype ~ Normal(...)
𝛽_rainfall ~ Normal(...)
...
## Define likelihood of the target variable cropyield given the covariates and parameters: p(cropyield | strainplanted, soiltype, rainfall, ...params)
with field = plate("field"):
with t = plate("t"):
baseyield = avgyield_control if strainplanted == "control" else avgyield_experimental
soiltype_effect = 𝛽_soiltype[soiltype]
rainfall_effect = 𝛽_rainfall * rainfall
cropyield ~ Normal(𝛼_yield + 𝛽_soiltype + 𝛽_rainfall)| field | t | strainplanted | soiltype | rainfall | cropyield |
|---|---|---|---|---|---|
| Martha’s Meadow | 2023 | control | good | 0.5 | 20 |
| Martha’s Meadow | 2024 | control | good | 0.4 | 18 |
| Ada’s Acres | 2023 | control | bad | 0.8 | 15 |
| Ada’s Acres | 2024 | control | bad | 0.1 | 12 |
| Peter’s Patch | 2023 | experimental | good | 0.4 | 35 |
| Peter’s Patch | 2024 | experimental | good | 0.4 | 41 |
| Lee’s Lot | 2023 | experimental | bad | 0.1 | 33 |
| Lee’s Lot | 2024 | experimental | bad | 0.2 | 34 |
Like most scientific analyses, this is a hierarchical model, where your local variables represent observations or states of the current context – say, the yield in each given season and field – and are influenced by parameters that represent more generic or abstract variables – average yield for your strain across all fields and seasons, which in turn depends on the expected yield improvement from a given genomics technique. (The latter is generic enough that it’s not really specific to your study, which is why it’s highlighted in orange below.)
Running this model on a data set can be understood as propagating information through the graph. First, the priors for the parameters inform the expected distributions for the local variables. Then as we gather observations for some variables, that information flows back up, giving updated posteriors for the parameters. The amount of information (uncertainty reduction or negentropy) being propagated can be understood as a flow on this graph, and indeed can be estimated as an output of many kinds of common inference algorithms.
It’s really useful to think informally of the free energy of the model as the discrepancy between the inferred distribution and the information we have available, between priors and observations. Zero free energy is the ideal state in which all information has been fully incorporated into the inference, is completely internally consistent, and explains away all the uncertainty in the system. Typically we can’t achieve zero free energy, as there’s always some uncertainty (whether aleatoric or epistemic), but we want to minimize it so that our model doesn’t have “extra”, unwarranted uncertainty. To get a better understanding of the concept of free energy and its role in Bayesian modeling and active inference, there are many excellent resources available; we particularly recommend this paper by Gottwald and Braun. Going forward, you can just think of Free Energy Reduction (FER) as a standard unit of account used by each model.
Source: Gottwald and Braun (2020).
But here’s a problem: How do you set priors for your parameters in the first place? Sure, you expect your strain to increase yield, but it would be circular reasoning to build that expectation into the priors. The common practice is to use a flat prior (also known as a weakly informative or regularization prior), that incorporates only information that you have an objective or incontrovertible reason to believe in (ex: penalizing unreasonably low or high values). This can be seen as “not sneaking information into the model”, in order to avoid fooling yourself (and your stakeholders, the people who will use your study results to make decisions) by publishing unjustifiably confident results. However, typically, most parameters in your study do not represent hypotheses you’re actively trying to learn about; instead, they represent assumptions that are justified by previous studies or expert opinions. For those, you want the opposite kind of prior, a sharp or strong prior.
In the past, if you were very lucky, there would be a published meta-analysis about the parameters for each of your assumptions, to save you the pain of combing through thousands of PDFs, understanding each, and copy-pasting numbers from the relevant tables into your workspace. Unfortunately, this work was so mind-numbingly boring, expensive, thankless and error-prone, that high-quality meta-analyses were exceedingly rare. To make matters worse, unlike the toy example above, real-world scientific models often utilize hundreds to thousands of parameters, and often far more if machine learning is used. Gathering the outputs of every relevant study for every relevant parameter, by hand, was infeasible, so we ended up with constant wheel reinvention and cargo-culted, unjustified assumptions, often used as point estimates with no uncertainty attached.
No longer: now you can simply connect your local model to the Gaia Network by annotating each parameter (in our example, average yield and drought tolerance, for both the control group of traditional maize and the experimental group of genetically modified maize). Your annotation attaches each parameter to a global namespace called the Gaia Ontology. You can browse the Ontology to see the exact definition of the parameter, with example code, and make sure you’re using the right one. Many other scientists have published their own studies on the Gaia Network; each published study contributes a posterior distribution for its parameters, and these are algorithmically aggregated into a “sort of weighted average” called a pooled distribution.
So at inference time, the Gaia engine just queries the network for the current pooled distributions for each of these parameters – effectively conducting a meta-analysis on-the-fly – and adopts them as priors.
@gaia_bind(deltayield={"v0.Agronomy.YieldImprovementPct":
{"species":"v0.Agronomy.Species.Maize",
"intervention":"v0.Agronomy.Genomics.CRISPR"}})
def model(strainplanted, soiltype, rainfall, cropyield):
## Model code is unchangedAs the illustration above shows, your model is importing information from other studies in the network and using it to increase FER. Gaia keeps track of the “credit assignment”, which will prove valuable starting in the next step, which is to publish your work.
In order to contribute to the network, all you have to do is commit your study to GitHub. Gaia will save your posterior distributions for all parameters that you’ve annotated, and share them back with every other study in the network. Your study and your peer studies each have an update chain, an append-only sequence of distributions representing the state of posteriors from each study’s perspective. These are effectively independent representations of the state of knowledge of the parameters in question.
So, immediately you can see that any other agricultural studies about different experimental strains will have their posteriors affected by adding your study to the pool of updates. This effect can be quite large if there are few studies being pooled, but it converges, so that after some point the updates become minimal.
But Gaia doesn’t just propagate posterior updates to “sibling” studies: If there are higher-level models for which your parameter is a leaf, it will propagate up to those as well. For instance, a model that forecasts advances in crop technology and their impact on global food security:
Note that, by publishing your model on the Network, you’re not exporting any information other than updates to the values of the specific parameters that you’ve connected – in particular, you’re not sharing any of the underlying data. (This is a “privacy-centric” inference approach, analogous to federated learning. In a follow-up article, we’ll discuss how we can solve the problems of trust that this imposes.)
As mentioned above, the Gaia Protocol assigns credit to every publication (also called attribution). The mechanism for attribution is primarily “subjective”: each node (ie, each study) just measures the net FER impact of each contribution as it’s incorporated into its own update chain.
Above, we mentioned that the pooled distribution is a “sort of weighted” average between each study’s posterior. So where do the weights come from? The Gaia Protocol also answers this question in a bottom-up, “subjective” way. Nodes can independently infer the “right” weights for each parameter and study. To do so, they can use arbitrary “metamodels”, ranging from simple “beauty contest” models that just aggregate the net FER impact that other studies have attributed to a contribution, to “web of trust” models that try to factor out more sophisticated ones that infer the presence of low-quality studies or deliberate fraud via social-type network analysis; to true “metamodels” that infer study quality and parameter relevance, using outside data such as the publisher’s credentials, analyses of the model code and third-party verifications of the data. This means that, at least in the short term, the pooled distribution for a given parameter is actually different depending on which node you ask! Even if all nodes have seen all the updates in the same order, they can give arbitrarily different weights to them. But as the different metamodels themselves accumulate quality signals, nodes eventually converge on a shared inference of the right metamodel to use on which kind of parameter. (As discussed in the introduction, we will not attempt to justify the claim that this protocol converges and is resilient to noise and misinformation/fraud. For now, see the arguments here.)
Funding science – retroactively and prospectively
Now approaching this from the opposite perspective, say you’re an analyst at a philanthropic foundation, trying to make recommendations for a prize that will be awarded to the most impactful scientific studies. Rather than solely rely on recommendations from the scientific community, or use “impact factors” that just measure popularity, you can query the Gaia Network to get quantitative, apples-to-apples impact metrics.
First, we should just note that being able to understand the “graph of science” in a live, transparent way – what are the research questions, how well developed, how much intensity in explore vs exploit mode, and how they connect to each other – is a game-changer. In the past, you needed to pay expensive fees for products like Web of Science and Scopus, which were based on manual curation and benefitted from the opaqueness of text-on-PDFs as the primary means of scientific communication. Having all the world’s science directly represented as machine-readable and connected models on Gaia – just like code and its dependencies on a package manager – makes all analytics orders of magnitude easier.
Now, back to the question of impact. Here we should distinguish two kinds of impact: epistemic impact—how much a given study has contributed to reducing uncertainty in the Network; and pragmatic impact—how much it has contributed to improving decisions. We’ll leave the pragmatic impact for later and focus on the epistemic impact for now.
So, for every model on the network, it’s easy to compute how much it contributed to FER flow across the network – what’s called credit assignment in neural networks. We just look at the net flow across the model boundary, which is accounted by the Gaia Protocol:
Some care needs to be taken here. First of all, note that the FER credited to a model due to its contributions is always computed by the model that’s receiving the contributions (it’s a subjective value). Plus, there might be significant differences in modeling practices between different fields, which may distort calculations. Later on, when we talk about the economics, we’ll see that the Protocol also needs a way to turn that subjective value accounting into intersubjective, mutually agreed upon “local exchange rates”. For now, let’s just say that you compute a normalization constant for each domain and use it to get a normalized, apples-to-apples net FER flow across domains.
So this covers retroactive funding in the form of prizes. But this isn’t (and shouldn’t be) how most science gets funded. Most researchers cannot internalize the risk and cost of self-funding their own work upfront and hoping for retroactive funding later. Instead, funders – who have access to cheaper capital costs, lower marginal risk sensitivity, and the other advantages that come with a big pile of cash – contract with researchers upfront to trade capital now for a future flow of impact. Before the Gaia Network, establishing effective contracts was very challenging, as it was extremely hard to predict impact, even for the researchers themselves, let alone for the funders. (In economic parlance, it was a classic agent-principal problem created by uncertainty and information asymmetry.) Now, the Gaia Network itself provides the solution: it contains metascience models that model the flow of FER across the network and use it to design interventions – adding more models and more data to specific fields and individual lines of research – that are likely to deliver the highest future flow of FER. Funders and researchers can equally use these models to guide where they should spend the most time and resources on. Compared with the recent past, where there were no meaningful metrics of scientific productivity or value added, let alone predictive models of how to improve these, the Gaia Network is a game-change for science funding.
A distributed oracle for decision-making
The above covers the advancement of science as its own objective. However, the same capabilities can aid any decision-making that pertains to the real world – what we’ve called pragmatic impact above. Indeed, the Gaia Network has given everyone an actionable, reliable way to “trust the science” – not just on big things like climate change and pandemics, but also on day-to-day things like your diet, exercise, relationships, and so on. And the same applies to business decision-making, which is where we’ll focus next.
Say you manage Ada’s Acres, a large farming operation in the US Midwest. You’re planning your next planting for your 30 thousand hectares, and as usual, your suppliers are trying to push you new seeds, new herbicides and all manner of hardware and software. Meanwhile, your usual buyers are all calling to let you know that global demand forecasts are through the roof, so you stand to gain a lot of money if you have an outstanding harvest. However, you’ve noticed that the soil has been increasingly poor and in need of fertilizer, and that herbicide resistance has increased a lot as well. The weather has been increasingly volatile, and you know it’s a matter of time before you have a major crop failure. Maybe it’s time to start giving regenerative farming a real shot?
Luckily, your farm operations software is now connected to the Gaia Network. It gives you a predictive digital twin of your farm that directly learns not just from every scientific experiment in agronomy, but from the “natural experiments” carried out by every other farm that uses the Network. So you can simulate the effects of any combination of practices, seed strains and products and estimate the outcomes, both short-term (expected yield and probability of crop failure for the next harvest) and long-term (soil health and herbicide resistance).
So that was a “small” (operational) use case. Now let’s zoom out to strategy: let’s say that you’re the CEO of Acme Foods, a major food company. In light of increased droughts and crop failures, you’re trying to invest in your supply chain in order to minimize the risk of supply shortages. Your innovation teams have aggregated a long list of potential investments in precision farming, genomics, and regenerative agriculture. In the past, assembling an investment portfolio out of that long list would have required a long, expensive and very political negotiation exercise. Now that all your suppliers are connected to the Gaia Network and share limited access with you, your portfolio management system becomes a distributed digital twin of your supply chain. You can run complex distributed queries across all the nodes, simulate the effects of different investment combinations and different sets of assumptions (like climate and pest spread scenarios), factoring in things like unintended consequences, and pull out an aggregate like a Pareto frontier for the investment profile you want.
Most of the demand for the intelligence in the Gaia Network will come from these decision engines (DEs), like the farm operations software and the portfolio management system. Combined with the ability of the Protocol to assign credit where it’s due, it can provide signals and incentives to provide a better supply of intelligence: more and better models in the places where they are most needed by decision-makers. In a future paper, we will further develop our vision of how these signals can be developed into a complete market and contracting mechanism for directing applied research, exploration and analysis: what we call the knowledge economy.
Even further, if we have “non-local” DEs that use Gaia models to design coordinated strategies that internalize the benefits of cooperation between multiple agents, then we can turn those DEs into Gaia models themselves! They become decision models performing “planning as inference” on behalf of agents (individuals and collectives), helping to solve all kinds of principal-agent problems. In the example above, the food company can use a DE not only to infer the best investments for its own goals, but also to design the adequate contracts and incentives that will best equalize the goals and constraints of all the players in the supply chain. This delegation economy will also be further explored in a future paper.
A distributed oracle for AI safety
The above discussion of decision-making is our link to AI safety. Yoshua Bengio has proposed to tackle AI safety by building an “AI scientist” – a comprehensive probabilistic world model that would serve as a universal gatekeeper to evaluate the safety of every high-stakes action from every AI agent, instead of attempting to design safety into agents. This is similar to Davidad’s Open Agency Architecture (OAA) proposal. But of course, developing such a monolithic, centralized and comprehensive gatekeeper from scratch would be an extremely costly and lengthy undertaking. Further, as Bengio’s proposal makes clear, the AI scientist needs to have “epistemic humility”: its evaluations need to incorporate the limitations and uncertainty of its own model, so that it doesn’t confidently allow actions that seem safe at the time but turn out to be unsafe in retrospect.
We argue that the Gaia Network, including the DEs that work as decision models, qualifies perfectly for the job of a distributed AI scientist. The DEs can query the diverse and constantly evolving knowledge in the network to form an “effective world model” with epistemic humility built in. They can provide the demand signals and resources to improve and expand the world model. They can then use this model to simulate counterfactual outcomes of actions that take into account all available local context and dependencies between contexts, and use these simulations to approximately estimate probabilities for outcomes (marginalization). They can factor in the preferences and safety constraints of all agents that use the Network, which they have already shared in order to enable the DEs to help with their own decisions. This gives all the terms in Bengio’s notional risk evaluation formula (adapted from slide 17 here):
Possibly the most important aspect of this design – which comes particularly to light when comparing it to the OAA design – is that none of the above components is specific to AI safety; they are just repurposed from existing and day-to-day use cases for which the users/agents already have the incentives to share the required information with the Gaia Network and the DEs. This means that tackling AI safety is no longer “one of the most ambitious scientific projects in human history”, but rather a “fringe benefit” from our pursuit of knowledge and of better decision-making. And which, in turn, benefits from all improvements to the efficiency and effectiveness of those pursuits that have already been produced by past and ongoing advances in computational statistics and machine learning – and all that will be generated by the Gaia Network connecting and interoperating the many millions of such models in existence, and increasing the RoI of creating and improving models.
This outcome is not dependent on AI safety funders; nor the foibles of political will in the scientific and policy communities; nor the desire of billions of humans to independently share their preferences with an elicitor. All that is required – beyond some cheap work on core infrastructure, modeling and developer experience – is the same economic behaviors and incentives that exist today: the desire for profit, the pursuit of greater scientific knowledge, and the existence of institutions willing and able to internalize the cost of coordinated action.
An overview of this architecture, adapted from our last post, is given below.
A distributed oracle for the Metacrisis
The very same architecture helps us identify shared pathways through the Metacrisis. Below is a nice visual of the high-level causal model we have in mind when thinking about the Gaia Network’s role. By connecting all the relevant domain models and making apparent not only their interdependencies, but also their common causes – the “generator functions” or underlying self-reinforcing dynamics – Gaia helps us understand likely future outcomes of the current trends and establish strategies with the highest potential for nudging our global course away from the two catastrophic attractors that currently seem most likely (chaos and totalitarianism). Not only that, but as we’ve seen, Gaia-powered DEs are also used as coordination surfaces: shared tools for establishing and monitoring contracts, treaties and institutions, with unprecedented scale and reliability. While this “infrastructure for model-augmented wisdom” doesn’t immediately or inherently solve conflicts of power and interests, it does provide a consistent, repeatable and scalable institution for achieving and retaining incremental advances towards a positive-sum, cooperative Gaia Attractor.
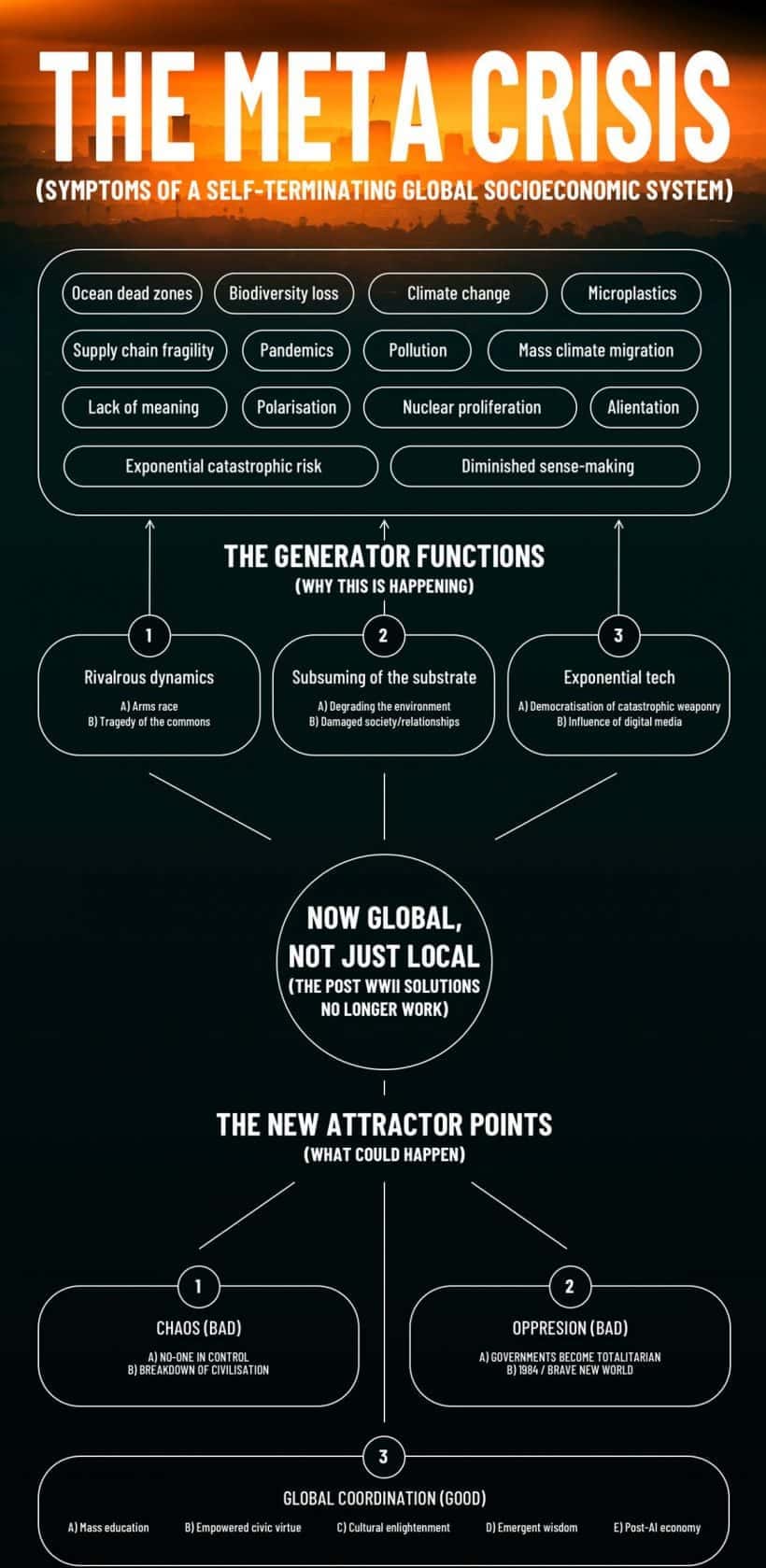
Source: Adapted from Potentialism, via Sloww
Conclusion: Back from the future
We just claimed that a lot will change in “a few years from now”. How realistic is this? Here’s the really good news: all the capabilities described above can be implemented with today’s technology. Not only that: we’re already doing it. We have assembled several organizations and individuals into a growing Gaia Consortium, and have of course been leveraging loads of existing components and building some of our own. Examples:
Ocean Protocol and DefraDB: Decentralized computing and data management.
Fangorn (coming soon): decentralized platform for building and performing (active) inference on Gaia-connected state space models.
Sentient Hubs: Federated model-based decision support.
We are simultaneously working on specific applications of the Gaia Network, focusing primarily on bioregional economies and sustainable supply chains. These have been useful for providing concrete use cases (some of which we saw above) and resourcing. But ultimately we intend to evolve this into a fully open and collaborative R&D effort to build the general-purpose capabilities described above.
If you’re interested in contributing to this work, here are some possible ways to do it:
Students interested in developing this with us should sign up for the upcoming SPAR program. We’re advising two projects: one focused on outstanding design, engineering and economics issues around using Gaia-based AI scientists for AI safety; the other is more conceptual and centers on formalizing and computationally testing the use of free energy-based causal systems models for measuring AI safety.
If you’re interested in helping design and build the Gaia Network and the surrounding infrastructure, protocols and decision machinery etc, we gladly accept contributions of all kinds.
If you’d like to use the Gaia Network (or its precursors) in your own use cases, we can happily support standing up “testnets” and help design prototypes and proofs of concepts.
If you have resources to help accelerate development, we can gladly accept grant funding or other forms of support.
If you’re interested in any of the above, please reach out!
This does sound like a powerful tool which can be helpful in these challenging times. I’d like more clarification on how you intend to regulate its use to avoid bad actors utilizing the tool to acquire dual-use information.
Collusion detection and prevention and trust modelling don’t trivially follow from the basic architecture of the system described on the level of this article. Some specific mechanisms should be implemented in the Protocol to have collusion detection and trust modelling. And we don’t have these mechanisms actually developed yet, but we think that they should be doable (though this is still a research bet, not a 100% certainty) because the Gaia Network directly embodies (or is amenable to) all six general principles for anti-collusion mechanism design (agency architecture) proposed by Eric Drexler (and these principles themselves should be further validated via formalisation and proving theorems about the collusion properties of the systems of distributed intelligence).
Of course, there should also be (at least initially, but practically for a very long time, if not forever) “traditional” governance mechanisms of the Gaia Network, nodes, model and data ownership, etc. So, there are a lot of open questions about interfacing GN with existing codes of law, judicial and law enforcement practice, intellectual property, political and governance processes, etc. Some of these interfaces and connections with existing institutions should in practice deal with bad actors and certain types of malicious behaviour on GN.