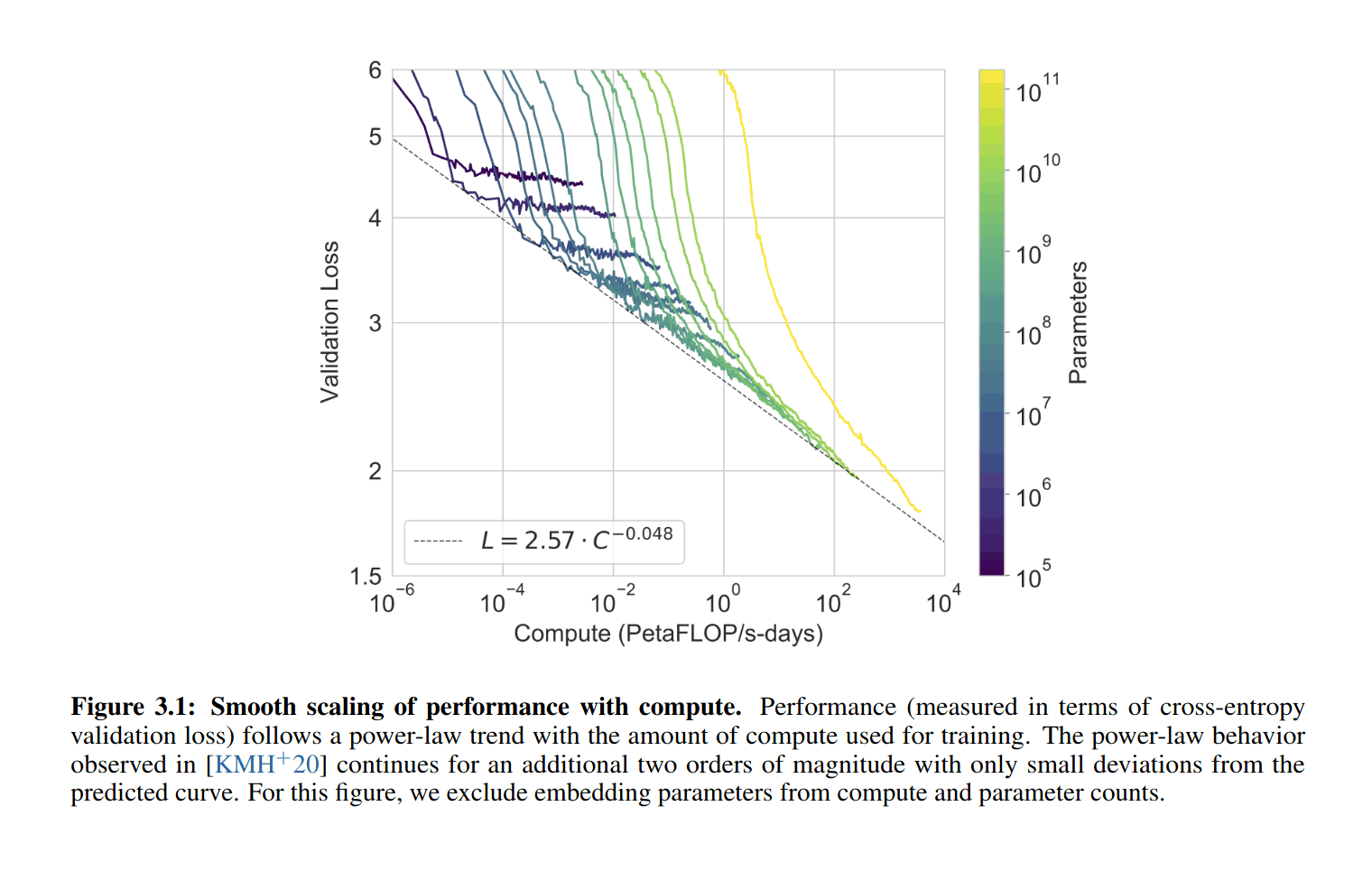
I look at graphs like these (From the GPT-3 paper), and I wonder where human-level is:
Gwern seems to have the answer here:
GPT-2-1.5b had a cross-entropy validation loss of ~3.3 (based on the perplexity of ~10 in Figure 4, and ). GPT-3 halved that loss to ~1.73 judging from Brown et al 2020 and using the scaling formula (). For a hypothetical GPT-4, if the scaling curve continues for another 3 orders or so of compute (100–1000×) before crossing over and hitting harder diminishing returns, the cross-entropy loss will drop, using to ~1.24 ().
If GPT-3 gained so much meta-learning and world knowledge by dropping its absolute loss ~50% when starting from GPT-2’s near-human level, what capabilities would another ~30% improvement over GPT-3 gain? What would a drop to ≤1, perhaps using wider context windows or recurrency, gain?
{kind=link}
{kind=link}
So, am I right in thinking that if someone took random internet text and fed it to me word by word and asked me to predict the next word, I’d do about as well as GPT-2 and significantly worse than GPT-3? If so, this actually lengthens my timelines a bit.
(Thanks to Alexander Lyzhov for answering this question in conversation)
In Steve Omohundro’s presentation on GPT-3, he compares the perplexity of some different approaches. GPT-2 scores 35.8, GPT-3 scores 20.5, and humans score 12. Sources are linked on slide 12.
I think Omohundro is wrong here. His GPT-3 perplexity of 20.5 must be for Penn Tree Bank. However, his ‘humans’ perplexity of 12 is for a completely different dataset! Tracing his citations from his video to Shen et al 2017, which uses 1 Billion Word Benchmark. 1BW was not reported in the GPT-3 paper because it was one of the datasets affected by contamination and dropped from evaluation.
I’ve never read the Penn Tree Bank or 1BW so I can’t compare. At best, I’d guess that if 1BW is collected from “English newspapers”, that’s less diverse than the Brown Corpus which goes beyond newspapers, and so perplexities will be lower on 1BW than PTB. However, some searching turned up no estimates for human performance on either PTB or WebText, so I can’t guess what the real human vs GPT-3 comparison might be. I’m also a little puzzled what the ‘de-tokenizers’ are that the Radford GPT paper mentions are necessary for doing the perplexity calculations at all...
(There are a lot of papers estimating English text entropy in terms of bits per character, but because of the BPEs and other differences, I don’t know how to turn that into a perplexity which could be compared to the reported GPT-3 performance on Penn Tree Bank/WebText/LAMBADA/etc, which is why I didn’t include a human baseline in my comment there—I just don’t know.)
No.
Looking more into reported perplexities, the only benchmark which seems to allow direct comparison of human vs GPT-2 vs GPT-3 is LAMBADA.
LAMBADA was benchmarked at a GPT-2 perplexity of 8.6, and a GPT-3 perplexity of 3.0 (zero-shot) & 1.92 (few-shot). OA claims in their GPT-2 blog post (but not the paper) that human perplexity is 1-2, but provides no sources and I couldn’t find any. (The authors might be guessing based on how LAMBADA was constructed: examples were filtered by whether two independent human raters provided the same right answer.) Since LAMBADA is a fairly restricted dialogue dataset, although constructed to be difficult, I’d suggest that humans are much closer to 1 than 2 on it.
So overall, it looks like the best guess is that GPT-3 continues to have somewhere around twice the absolute error of a human.
Thanks. Scary stuff; 2x error isn’t much considering how far the GPT’s have come already.
It’s probably a lower bound. These datasets tend to be fairly narrow by design. I’d guess it’s more than 2x across all domains globally. And cutting the absolute loss by 50% will be quite difficult. Even increasing the compute by 1000x only gets you about half that under the best-case scenario… Let’s see, to continue my WebText crossentropy example, 1000x reduces the loss by about a third, so if you want to halve it (we’ll assume that’s about the distance to human performance on WebText) from 1.73 to 0.86, you’d need
(2.57 * (3.64 * (10^3 * x))^(-0.048)) = 0.86where x = 2.2e6 or 2,200,000x the compute of GPT-3. Getting 2.2 million times more compute than GPT-3 is quite an ask over the next decade or two.Might as well finish out this forecasting exercise...
If we assume compute follows the current trend of peak AI project compute doubling every 3.4 months, then 2.2e6× more compute would be log2(2.2e6) = 22 doublings away—or 22*(3.4/12) = 6.3 years, or 2027. (Seems a little unlikely.)
Going the other direction, Hernandez & Brown 2020′s estimate is that, net of hardware & algorithmic progress, the cost of a fixed level of performance halves every 16 months; so if GPT-3 cost ~$5m in early 2020, then it’ll cost $2.5m around mid-2021, and so on. Similarly, a GPT-human requiring 2.2e6× more compute would presumably cost on the order of $10 trillion in 2020, but after 14 halvings (18 years) would cost $1b in 2038.
Metaculus currently seems to be roughly in between 2027 and 2038 right now, incidentally.
What is that formula based on? Can’t find anything from googling. I thought it may be from the OpenAI paper Scaling Laws for Neural Language Models, but can’t find it with ctrl+f.
It’s in the figure.
FWIW I wouldn’t read much into it if LMs were outperforming humans at next-word-prediction. You can improve on it by having superhuman memory and doing things like analyzing the author’s vocabulary. I may misremember but I thought we’ve already outperformed humans on some LM dataset?
I agree that the difference in datasets between 1BW and PTB is making precise comparisons impossible. Also, the “human perplexity = 12” on 1BW is not measured directly. It’s extrapolated from their constructed “human judgement score” metric based on values of both “human judgement score” and perplexity metrics for pre-2017 language models, with authors noting that the extrapolation is unreliable.
Thanks! So… Gwern is wrong? I’m confused.
Sources:
https://web.stanford.edu/~jurafsky/slp3/
https://www.isca-speech.org/archive/Interspeech_2017/abstracts/0729.html
The latter is the source for human perplexity being 12. I should note that it tested on the 1 Billion Words benchmark, where GPT-2 scored 42.2 (35.8 was for Penn Treebank), so the results are not exactly 1:1.
Just use bleeding edge tech to analyze ancient knowledge from the god of information theory himself.
This paper seems to be a good summary and puts a lower bound on entropy of human models of english somewhere between 0.65 and 1.10 BPC. If I had to guess, the real number is probably closer 0.8-1.0 BPC as the mentioned paper was able to pull up the lower bound for hebrew by about 0.2 BPC. Assuming that regular english compresses to an average of 4* tokens per character, GPT-3 clocks in at 1.73/ln(2)/4 = 0.62 BPC. This is lower than the lower bound mentioned in the paper.
That would also be my guess. In terms of data entropy, I think GPT-3 is probably already well into the superhuman realm.
I suspect this is mainly because GPT-3 is much better at modelling “high frequency” patterns and features in text that account for a lot of the entropy, but that humans ignore because they have low mutual information with the things humans care about. OTOH, GPT-3 also has extensive knowledge of pretty much everything, so it might be leveraging that and other things to make better predictions than you.
This is similar to what we see with autoregressive image and audio models, where high frequency features are fairly well modelled, but you need a really strong model to also get the low frequency stuff right.
*(ask Gwern for details, this is the number I got in my own experiments with the tokenizer)
Hmmm, your answer contradicts Gwern’s answer. I had no idea my question would be so controversial! I’m glad I asked, and I hope the controversy resolves itself eventually...
From that paper:
> A new improved method for evaluation of both lower and upper bounds of the entropy of printed texts is developed.
”Printed texts” probably falls a standard deviation or three above the median human’s performance. It’s subject to some fairly severe sampling bias.