The Future of Life Institute (FLI) recently put out an open letter, calling on all AI labs to immediately pause for at least 6 months the training of AI systems more powerful than GPT-4.
There was a great flurry of responses, across the spectrum. Many were for it. Many others were against it. Some said they signed, some said they decided not to. Some gave reasons, some did not. Some expressed concerns it would do harm, some said it would do nothing. There were some concerns about fake signatures, leading to a pause while that was addressed, which might have been related to the letter being released slightly earlier than intended.
Eliezer Yudkowsky put out quite the letter in Time magazine. In it, he says the FLI letter discussed in this post is a step in the right direction and he is glad people are signing it, but he will not sign because he does not think it goes far enough, that a 6 month pause is woefully insufficient, and he calls for… a lot more. I will address that letter more in a future post. I’m choosing to do this one first for speed premium. As much as the world is trying to stop us from saying it these days… one thing at a time.
The call is getting serious play. Here is Fox News, saying ’Democrats and Republicans coalesce around calls to regulate AI development: ‘Congress has to engage.’
As per the position he staked out a few days prior and that I respond to here, Tyler Cowen is very opposed to a pause, and wasted no time amplifying every voice available in the opposing camp, handily ensuring I did not miss any.
Structure of this post is:
I Wrote a Letter to the Postman: Reproduces the letter in full.
You Know Those are Different, Right?: Conflation of x-risk vs. safety.
The Six Month Pause: What it can and can’t do.
Engage Safety Protocols: What would be real protocols?
Burden of Proof: The letter’s threshold for approval seems hard to meet.
New Regulatory Authority: The call for one.
Overall Take: I am net happy about the letter.
Some People in Favor: A selection.
Some People in Opposition: Including their reasoning, and complication of the top arguments, some of which seem good, some of which seem not so good.
Conclusion: Summary and reminder about speed premium conditions.
I Wrote a Letter to the Postman
First off, let’s read the letter. It’s short, so what the hell, let’s quote the whole thing.
AI systems with human-competitive intelligence can pose profound risks to society and humanity, as shown by extensive research[1] and acknowledged by top AI labs.[2] As stated in the widely-endorsed Asilomar AI Principles, Advanced AI could represent a profound change in the history of life on Earth, and should be planned for and managed with commensurate care and resources. Unfortunately, this level of planning and management is not happening, even though recent months have seen AI labs locked in an out-of-control race to develop and deploy ever more powerful digital minds that no one – not even their creators – can understand, predict, or reliably control.
Contemporary AI systems are now becoming human-competitive at general tasks,[3] and we must ask ourselves: Should we let machines flood our information channels with propaganda and untruth? Should we automate away all the jobs, including the fulfilling ones? Should we develop nonhuman minds that might eventually outnumber, outsmart, obsolete and replace us? Should we risk loss of control of our civilization? Such decisions must not be delegated to unelected tech leaders. Powerful AI systems should be developed only once we are confident that their effects will be positive and their risks will be manageable. This confidence must be well justified and increase with the magnitude of a system’s potential effects. OpenAI’s recent statement regarding artificial general intelligence, states that “At some point, it may be important to get independent review before starting to train future systems, and for the most advanced efforts to agree to limit the rate of growth of compute used for creating new models.” We agree. That point is now.
Therefore, we call on all AI labs to immediately pause for at least 6 months the training of AI systems more powerful than GPT-4. This pause should be public and verifiable, and include all key actors. If such a pause cannot be enacted quickly, governments should step in and institute a moratorium.
AI labs and independent experts should use this pause to jointly develop and implement a set of shared safety protocols for advanced AI design and development that are rigorously audited and overseen by independent outside experts. These protocols should ensure that systems adhering to them are safe beyond a reasonable doubt.[4] This does not mean a pause on AI development in general, merely a stepping back from the dangerous race to ever-larger unpredictable black-box models with emergent capabilities.
AI research and development should be refocused on making today’s powerful, state-of-the-art systems more accurate, safe, interpretable, transparent, robust, aligned, trustworthy, and loyal.
In parallel, AI developers must work with policymakers to dramatically accelerate development of robust AI governance systems. These should at a minimum include: new and capable regulatory authorities dedicated to AI; oversight and tracking of highly capable AI systems and large pools of computational capability; provenance and watermarking systems to help distinguish real from synthetic and to track model leaks; a robust auditing and certification ecosystem; liability for AI-caused harm; robust public funding for technical AI safety research; and well-resourced institutions for coping with the dramatic economic and political disruptions (especially to democracy) that AI will cause.
Humanity can enjoy a flourishing future with AI. Having succeeded in creating powerful AI systems, we can now enjoy an “AI summer” in which we reap the rewards, engineer these systems for the clear benefit of all, and give society a chance to adapt. Society has hit pause on other technologies with potentially catastrophic effects on society.[5] We can do so here. Let’s enjoy a long AI summer, not rush unprepared into a fall.
You Know Those are Different, Right?
One thing that jumps out right away is that the memo risks conflating two worries. Questions about propaganda, untruth and job automation are fundamentally different than questions about losing control of the future and humanity being displaced entirely by machines. As in, it combines:
AI ‘Safety’: AI might contaminate our information spaces or take away jobs.
AI NotKillEveryoneism: AI might take control over the future, wipe out all value in the universe or kill all of us. It poses an existential risk to humanity.
These are both serious concerns. They require very different approaches.
In strategic terms, however, it is clear why the letter is choosing to conflate them here. I am very confident this was intentional, as a pause in training is the only readily available move to lay the groundwork for a robust response to either threat, and the type of move that can develop good habits and lay the groundwork for future cooperation.
The Six Month Pause
They call for a six month pause on training any systems more powerful than GPT-4.
I see this as important almost entirely for its symbolic value and the groundwork and precedents that it lays out, rather than for the direct impact of the pause.
What direct impact would this have?
It would mean that GPT-5 training, if it is even happening yet, would be halted for six months, and perhaps that similar systems inside Google or Anthropic would also have their trainings paused. My model says this would have very little impact on the pace of progress.
This would not, as I model the situation, ‘blow OpenAI’s lead’ or Google’s lead in other areas, in any serious way. OpenAI and Google (et al) would be free to continue gathering data to feed to their models. They would be free to continue collect user data. They would be free to experiment with further fine tuning and improving their techniques. We would continue to see all work continue on plug-ins and prompt engineering and API integrations and everything else.
I am not even confident that waiting six months would be a mistake on a purely strategic level. The training compute could be (and presumably would be) redirected to GPT-4 (and others could do a similar move) while GPT-5 could then be trained six months later while being (almost?) six months of progress more powerful, GPT-5.2 or what not. Even now, six months is not that long a period to wait.
Nor am I all that worried about something similar to what I would expect from a potential currently-being-trained GPT-5. I do not think there is much probability that we are that close to AI posing an existential threat, although the risk there isn’t zero. To the extent I would worry, it would be more about how people could compliment it with plug-ins and various other scaffolding, rather than that the model would do something during training or during the RLHF and fine tuning phase.
Note of course that means this applies both ways. If anyone is calling this a no-good-terrible idea because of all the damage this would do to our progress, either they misunderstand the proposal, they misunderstand the landscape, I am misunderstanding one of those rather badly, or they are lying.
What the pause does is not any of that. It is exactly what the letter says the pause is for. The pause enables us to get our act together.
It does this by laying the groundwork of cooperation and coordination. You show that such cooperation is possible and practical. That coordination is hard, but we are up to the task, and can at least make a good attempt. The biggest barrier to coordination is often having no faith in others that might coordinate with you.
I essentially agree with Jess Riedel here. If you want coordination later, start with coordination now (link to Wikipedia on Asilomar on DNA), even if it’s in some sense ‘too early.’ When it isn’t too early, it is already too late. I also agree with him on the dangers of conflating current and future risks and wish that had been handled better.


The training of more powerful models is also by far the most promising bottleneck, in the long term, through which to limit AI capabilities to ones we can handle, both in terms of society’s ability to absorb short term disruptions, and also in terms of potential existential threats.
If we try a choke point other than training, that seems like a much harder coordination problem, a much harder control problem, a much easier place for China or others to disregard the agreement. Training a big, powerful model is expensive, slow, requires a very large amount of controlled and specialized equipment and also a lot of expertise and good data.
Every other step of the process is a relative cakewalk for some rogue group to do on their own. We have relatively little hope of controlling what is built on top of something like GPT-4 that already exists, and almost none for something like Llama that is in the wild.
Are there other interventions we could do to improve our risk profile, on both levels? Yes, absolutely, and this potentially buys us time to figure out which of those we might be able to make stick.
Engage Safety Protocols
When I discussed the GPT-4 System Card Paper, special focus was on the ARC red teaming effort to determine if GPT-4 posed a potential existential threat.
It was great that ARC was engaged for this purpose. It was still a symbolic test, a dress rehearsal for when such safety tests will go from good ideas to existentially necessary. Like the pause, it in and of itself accomplished little, yet it laid the groundwork for a future test that would do much more.
That was true even if GPT-4 was an existential threat. In that case, the tests actually run by ARC were too little, too late. The final GPT-4 model was substantially more capable than the one ARC tested. ARC’s tests made some effort to enable GPT-4 to become agentic, but far from what one would reasonably expect to be tried within a week once the model was released to the public.
Then less than two weeks after GPT-4 was released, OpenAI gave it plug-ins. If GPT-4 is genuinely dangerous, it will be due to it being combined with capability-enhancing plug-ins. Whereas if (highly counterfactually) GPT-4 was so unsafe that the ARC tests would have caught it, even training the model wasn’t safe, and there would be a real risk that the model would be able to detect the ARC test and hide its capabilities.
So the ARC test came too early, was too little and was also too late. In most dangerous worlds, the ARC test never had a chance.
That does not mean that a future test, with more effort and more robust design, couldn’t make a real difference. We still need time to figure out what that would look like, to game it out and reach agreement. The cost of a much better test would still be only a tiny fraction of the cost of model training.
If we could get coordination started, getting agreement on real anti-x-risk safety protocols, that would make at least some real difference, does not seem crazy to me. Getting them to be sufficient is very hard, especially against large jumps in capability.
This does suggest that it is that much more important to avoid too-large sudden leaps in capabilities, a potential danger if longer pauses cause overhangs. I don’t think 6 months is an issue here.
I would also note that OpenAI has explicitly said it thinks there will soon be a time when it will require much greater coordination and safety protocols around AI releases. All those who are saying such coordination is impossible even in theory so why ask for it do not seem to have appreciated this.
Burden of Proof
My biggest worry with the letter is the burden of proof it imposes on potential new AI systems seems like it is not so far from a de facto ban. This goes hand in hand with the conflation of near-term and existential risks.
From the letter:
Powerful AI systems should be developed only once we are confident that their effects will be positive and their risks will be manageable.
Compare this to what I likely would have written there, which is something like “Powerful AI systems should be developed only once we are certain that the new system can be contained and does not pose an existential risk to humanity. They should not be deployed without robust publicly available risk assessments.”
Or, if I was calling for never deploying the next generation of systems because I felt they were indeed too dangerous, I would simply write “should not be developed.”
This is the same tune we have seen over and over in government regulation, from the FDA and the CDC and the NRC and so on, except here the burden would be even larger. Which, as a matter of tactics in a war, might be a good result for the planet in the end, but that’s not a game I am eager to play.
New Regulatory Authority
The final call is then to develop robust new regulatory authorities to deal with AI. This leads to the standard (and usually highly accurate) objections that regulations never work out the way you want them to and always stifle innovation and progress. Except, here, that could be exactly what we need to protect against existential risk, and also there is definitely going to be a regulatory authority. Section seems like standard boiler plate calls.
The idea, as I understand it, is to first get the labs to agree to pause. Then get them to coordinate on safety protocols and guidelines, at least somewhat, using that pause. Then, over time, build on that momentum to get the best regulations we can, and best support for safety efforts that we can, on a standard externality and public goods theory basis, except the stakes are in some parts existential.
Overall Take
My overall take is that I am positive about the letter.
I am happy it exists, despite the reasonable objections. In particular, I am happy that those in favor are finally making the calls for such moves explicit, and not sitting back to avoid offending the wrong people, or worrying about a unilateralist curse. Better to be the one in the arena.
I do realize the 6-month pause in and of itself does little, but it would lay strong groundwork for coordination, and give hope and a start. I’d be very happy if it did happen.
It is not my ideal letter. Such letters never are.
I wish it did not conflate short-term and existential risks, and I wish it did not use proof of short-term societal benefit (a ‘They Took Our Jobs’ style calculation) as a way to determine whether something should be developed, especially requiring confidence in that on a regulatory-style level – if we want a full halt, which I think is a reasonable thing to want, if not now then reasonably soon, then I’d prefer we be straight about it, although that’s never how this actually works in practice, so perhaps that is a pipe dream.
Like everyone else and every other such letter, I wish it was more specific and stronger in places, that it had stronger support where it matters, and so on. The letter does not go far enough, which is a conscious choice. I wish it said more without being longer. How? Don’t know
Some People in Favor
There is an overhang in signatures due to processing. As always, the important question is whether the ideas are right, not who is saying what. Still seems worth looking at a few highlights, especially since we’re also going to cover the vocal opposition next.
I include reasoning where I know it, especially when it is distinct from mine.
Jaan Tallin explains the reasoning behind the memo here on the BBC (3 min). Clear he is endorsing for the existential risks (the NotKillEveryoneism).
Max Tegmark also endorses and de-emphasizes the jobs angle.
GPT-4 by default will of course refuse to ever take a position on anything, but for what it is worth signs do point to it being in favor if you can get past that.
Nate Sores of MIRI signed because it’s a step in the right direction, but believes it does not go far enough and more centrally endorses Eliezer Yudkowsky’s letter in Time.
Victoria Krakovna, DeepMind research scientist I respect a lot.
Gary Marcus, and Tristan Harris, because of course, he explains here and offers a Twitter long-read extension here.
Yuval Noah Harari, author of Sapiens.
Connor Leahy of Conjecture signed, saying that while he doesn’t agree with everything in the letter, it is a good reality check.
Elon Musk. You know the guy.
Steve Wozniak, Co-founder of Apple.

Jim Babcock says we shouldn’t have waited this long to make the call for slowing things down. I agree that those who think slower was better should have been louder and clearer about it sooner.

Some People in Opposition
The general pattern of opposition seems to fall into one of two categories.
In the category of reasonable objections are
That regulations have a no good very bad track record of not working out the way you want (although if what you want is to slow down progress, they’re actually kind of great at that). I do notice.
The requirements to enforce such a pause via government action would be extreme dystopian nightmares, would lock in current winners, and otherwise are a very high price. True. I have no idea how to implement any solutions that avoid such nightmares, even in good cases, also see objection one. Thus, the price of government enforcement over time of various prohibitions, that would actually work, would be high. Yes, you should treat this as a high cost. However it is not a high cost to the initial 6-month pause, since it would not be enforced by government.
Haven’t seen this one explicitly, but: I’d also go a step further, and say that one could object that ‘be confident a deployment would be net positive’ is a completely unreasonable standard that can never be and would never be met by a new technology with widespread societal impacts. If you think that training GPT-5 poses an existential threat and therefore we should never do it, don’t hide behind proving it won’t take our jobs, actually make that case. I do think this is a real point against the letter.
Belief that AGI is almost certainly quite far and thus existential danger is very low, or belief that LLMs are not speeding up progress towards AGI. If you believe either of these things, you probably shouldn’t support the letter.
Risk that pausing training would create hardware overhang and potential discontinuous progress more than it would slow the long term path of progress, and especially that if you pause big training and then suddenly do one that could be super risky. This is worth thinking about in the longer term for sure, doesn’t seem like it applies to the 6-month pause enough to be worth worrying about.
Worry that this would level the playing field, that OpenAI currently has a lead. To the extent that OpenAI does have a lead (I am not at all confident they do have a lead where it matters, which isn’t current consumer-facing products) I don’t think a short pause would change that. A longer pause is different and this needs to be thought about carefully, especially if one wasn’t confident it would hold. This objection also depends on thinking OpenAI (or Google) would give up some or all of its lead to pause on its own, in the future, at the right time, reasonably often.
The conflation of short-term and existential risks is not good. I agree.
Then there are a lot of… not as good arguments against.
The authors of the letter didn’t do a good enough job marketing it, or didn’t execute well, so we should oppose the letter and its ideas.
The authors of the letter didn’t get the right people to sign it, so ditto.
The letter doesn’t go into all the different detailed considerations I would demand, that should somehow fit into 1.5 pages. Are they even considering such issues?
The 6 month pause would not, by itself, do that much. Yes, we know.
The 6 month pause is not a good political proposal. It’s not a political proposal.
The long terms interventions aren’t specified in concrete detail. That is not how such petitions or early stage coordination or early stage political proposals ever work. If you only sign on when all the future details are laid out and you agree with them, your kind can’t coordinate, and won’t.
The letter is nonsense because it is illegal for companies to agree to such a pause, or to decide not to maximally pursue their core business objective no matter the risks (I got someone loudly saying this at a gathering, it’s simply false, that is not how business law works, and to extent it is true it would be a very strong argument that we do indeed need regulation even if it’s implemented badly).
Thinking the letter is calling for something it isn’t calling for, a pause on other AI research and developments other than training.
Mood affectation and ad hominem attacks, they’re always there.
Tyler Cowen feels like the de facto opposition leader. Following up on his advocacy earlier in the week, he’s been retweeting and highlighting a wide variety of arguments against the letter. He’s also the source for some of the other opposing views listed here.
I would have liked to see more differentiation, in terms of amplification, between the good arguments against and the bad arguments against. And less of the use of arguments as soldiers, of viewing this as a battle to be won.
Here is his direct response on MR, for those interested. It hits all the notes – regulations never work, our government can never do anything right so why would you ever try to coordinate using it, warnings about losing to China, attacking people who signed the petition by saying signing it is evidence they are bad at predicting the future, and demanding lots of additional considerations and detail that could not fit into a letter of this length, equating any temporary pause with a permanent pause because temporary government programs often become permanent, despite this pause not being a government program at all.
Does Tyler think that two-page open letters need to include analysis of political economy considerations? Does he think that one should never suggest any concrete actions, or even concretely stop taking harmful actions, unless one has fully fleshed out all the actions that come after it? Or that an open letter should, strategically, offer full details on all future steps when calling for an initial step? This feels like saying one should not call for a cease fire and peace conference unless one agrees on what the new trade agreements will look like, and is confident that the policing of the DMZ will be efficient.
I also love the idea of asking ‘how long is this supposed to take?’ as an argument against acting now. If it takes a long time to be able to act, then that is not an argument to wait until the danger is clearer and act later.
The concrete practical recommendation here is to not do the exact thing that most makes things worse. The complaints in response are often that there are no concrete actions to take. I don’t even know how to respond?
He also offers this critique on Twitter.
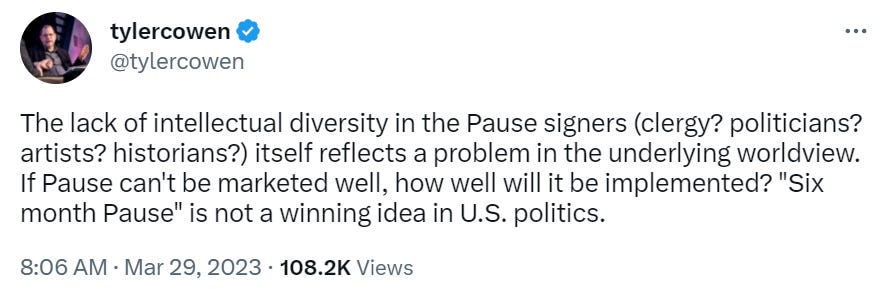
This is more demand for rigor, before you ask experts in the field to do something you should first assemble an intellectually and politically broad coalition of impressive people, why aren’t the clergy and politicians endorsing this? Or more than that, the VC move of ‘I don’t think you are good at marketing, therefore you are bad at everything’ with a side of ‘and therefore I should oppose you and everyone else should, too.’
It’s also a conflation. Why does the pause need to be ‘a winner in US politics’ at all? The letter isn’t calling for us to pass a law for the pause, the idea is for the (at most four) places even capable of training above GPT-4 in the next six months to agree not to do that. No one is suggesting this first step would be enforced politically.
Here’s Matthew Barnett’s critique, which I appreciate, concrete and thoughtful.

I find that interesting already, the distinction between quite bad and possibly net harmful is worth noticing.

I strongly agree this was frustrating and unfortunate.
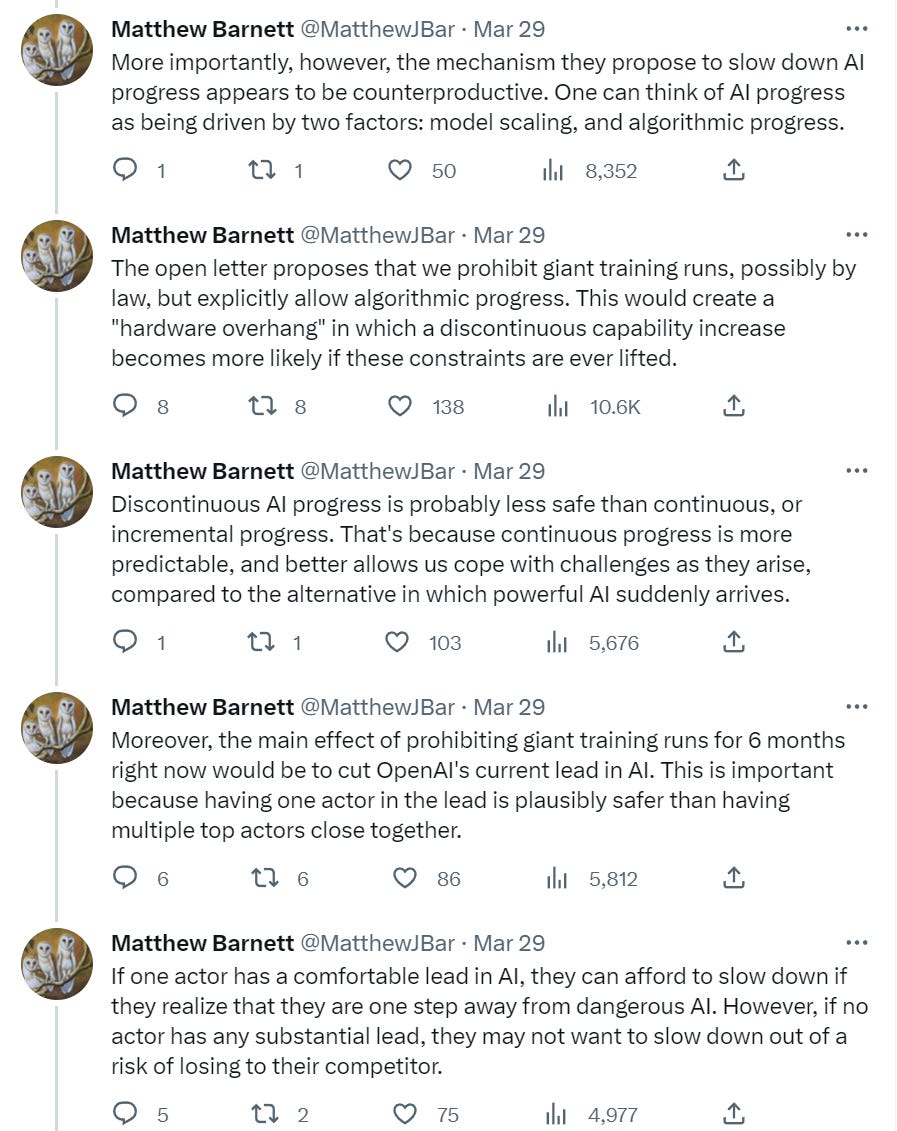
I do not think we will have confidence of when we are one step away from dangerous AI in the sense that matters most, and as discussed above I am not at all confident OpenAI is actually in the lead where it long-term matters, nor do I think a 6-month pause would meaningfully cut into that lead. If it would cut into it, the lead wasn’t worth much.
I do think the hardware overhang concerns are real if you pause for a lot longer and then someone resumes. There are no easy answers. The alternative proposal is still a full-speed race by all concerned.
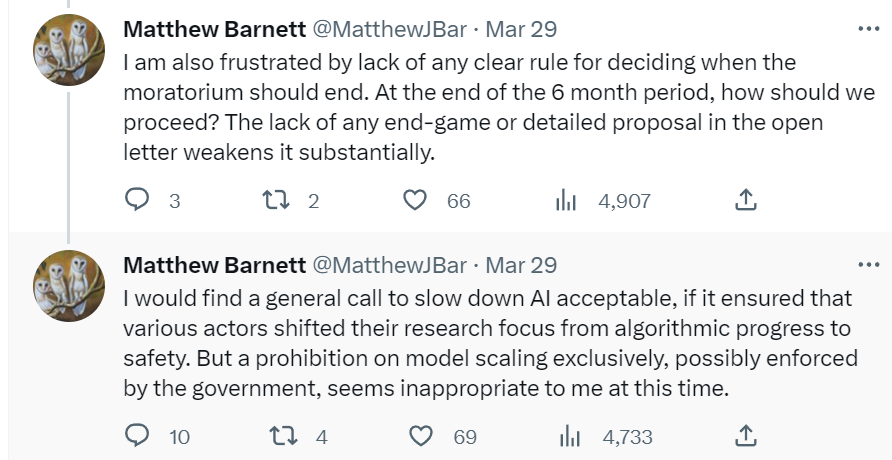
If anything I am worried that there is too much specification of what it would take, rather than too little – a burden of ‘prove your advance will be net good’ that goes far beyond guarding against existential risks and which might be effectively impossible. If one wants a permanent rule this soon (as Eliezer does) that is a not-insane position, but one should come out and say it (as he does).
If there is going to be a prohibition, I don’t see any other potential prohibition beyond model scaling, so we’re kind of stuck with it. Enforcement on anything else doesn’t really work. You can try to not actively streamline plug-in style actions but that’s very hard to define and with Python scripts and API access you can mostly improvise around it anyway.
Do we have any other options in the ‘slow down AI’ category? I do think there are a few that might make short term sense to address short term risks. One example off top of head is that we might want to consider not letting LLMs access anyone’s unread emails due to worries about prompt injections and identity thefts, but that should fall into ‘business risk’ categories that have reasonable incentives anyway and are not an existential threat nor would it much matter for long term AI progress.
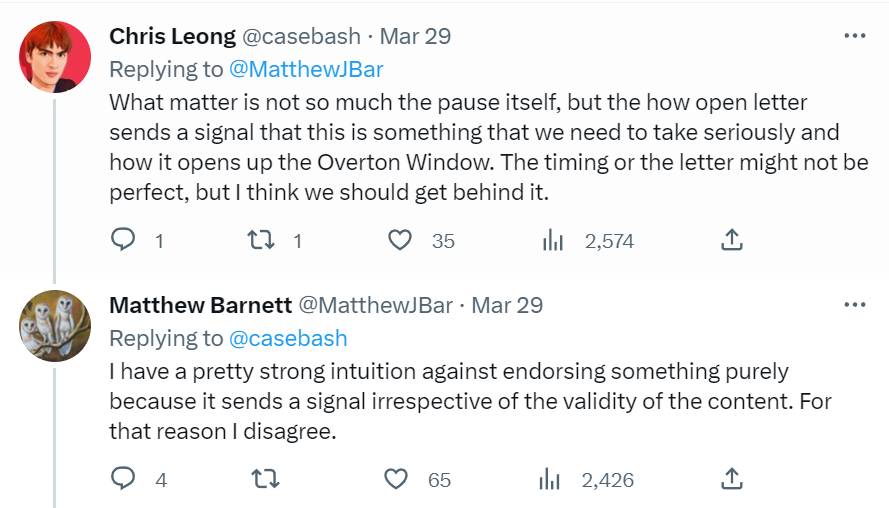
I’m very sympathetic to Matthew here. I am loathe to play signaling games without substance. In this case, I do think the substance of going through with implementation is real enough, but I can see the alternative perspective.


That’s quite a short trip to both claiming ‘what good is it to only pause for six months’ and ‘pausing forever would not help with the risks.’ I think a lot of people have learned helplessness about the whole topic, or are demanding that no change in trajectory happen unless we have a full solution to the problem – often people effectively (in the general case, not only AI) take the attitude that you can’t even mention a problem unless you have a fully detailed solution for it. It’s rough.
We also have: How dare you suggest that we have people decide what to do, or that we start setting up so there will be people who actively decide what gets done, without telling me what those people will decide?
Scott Aaronson asks three good questions, and goes on one earned mini-rant.
Would your rationale for this pause have applied to basically any nascent technology — the printing press, radio, airplanes, the Internet? “We don’t yet know the implications, but there’s an excellent chance terrible people will misuse this, ergo the only responsible choice is to pause until we’re confident that they won’t”?
Why six months? Why not six weeks or six years?
When, by your lights, would we ever know that it was safe to resume scaling AI—or at least that the risks of pausing exceeded the risks of scaling? Why won’t the precautionary principle continue for apply forever?
Were you, until approximately last week, ridiculing GPT as unimpressive, a stochastic parrot, lacking common sense, piffle, a scam, etc. — before turning around and declaring that it could be existentially dangerous? How can you have it both ways? If the problem, in your view, is that GPT-4 is too stupid, then shouldn’t GPT-5 be smarter and therefore safer? Thus, shouldn’t we keep scaling AI as quickly as we can … for safety reasons? If, on the other hand, the problem is that GPT-4 is too smart, then why can’t you bring yourself to say so?
I would strongly respond to #1 with a Big No, and as I’ve noted am sad about the conflation with places where the answer would be ‘kind of, yeah.’
My answer to #2 is that six weeks is not enough time to accomplish anything and wouldn’t matter at all, six years is not something we could plausibly get buy-in on, and six months is potentially both palatable and enough to keep on going. It’s a reasonable guess here, and you have to pick some period. I find Scott’s claim that this is about ‘getting papers ready for AI conferences’ far too cynical even for me.
#3 seems like a very good question, as I’ve noted the phrasing here is a problem. My answer would be, when I am convinced there is no (or rather, acceptably little) existential risk in the room, very similar to my answer to #1. I’m not saying mathematical proof of that, but certainly a bunch of highly robust checks that we are nowhere near the necessary thresholds.
On #4, Scott agrees most of us have a very straightforward good answer to that one, that we are impressed by GPT-4 and worried about future advances.
Here’s Adam Ozimek, who is a great economic thinker.

I strongly agree with Adam’s position here as far as it goes, if this was mostly about protecting jobs it would be quite a terrible proposal. I see this as being about something else entirely.
Leopold Aschenbrenner worries among other things that calling for a pause now is crying wolf and will interfere with future alarms, and doesn’t think the 6 month pause would do anything. Links to several other critiques I cover.
The worst part of actually mentioning (and even conflating) the near-term risks from AI is that few of those who actually care about those near term risks are going to accept your peace offering. Here are some examples.
Emily Bender starts off saying that the important thing to know about the petition is that FLI is a long term organization and longtermism is terrible, the worst thing. She says that of course we can control ChatGPT ‘by simply not setting them up as easily accessible sources of non-information poisoning our information ecosystem’ also known as ‘not turning the system on.’ So there’s that, I suppose? The solution is for some magical ‘us’ to simply turn the thing off?
Arvind Narayanan says “the new AI moratorium letter repeatedly invokes speculative risks, ignoring the version of each problem that’s already harming people. The containment mindset is neither feasible nor useful for AI. It’s a remedy that’s worse than the disease.” You see, the problems are ‘overreliance,’ ‘centralized power,’ ‘labor exploitation’ and ‘near-term security risks’ and you sir have the wrong affectations.
Katja Grace is leaning towards signing as of writing this (link to her doc, largely a point-by-point response to Barnett)

Alyssa Vance points out one that’s partly here for fun where the signatories calling for pauses and government regulations must be doing ‘BS libertarianism’ (plus, if you put ‘ethicist’ in your profile you are fair game, sorry, I actually do make the rules) because they are libertarians and you don’t like libertarians.
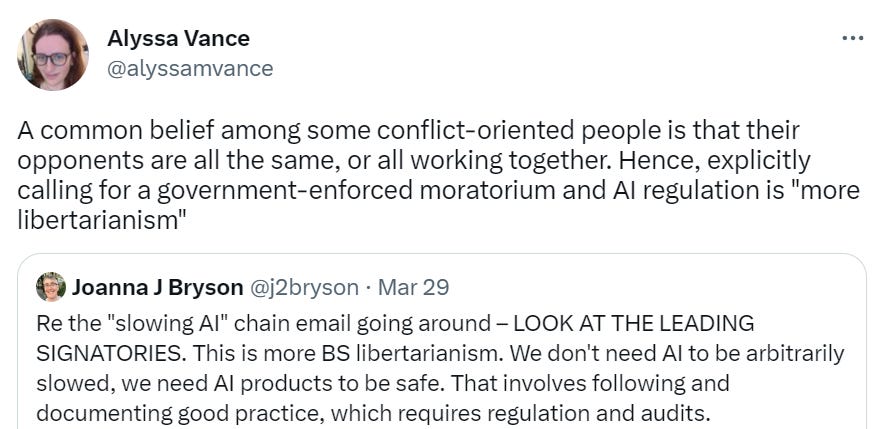
As opposed to noticing that some very libertarian-leaning people are suddenly not acting so libertarian and explicitly calling for ‘regulation and audits’ and that’s the kind of thing worth noticing. And of course, Joanna doubles down.

Another good note of hers, kind of out of place but seems right to put it here anyway.

Jessica Taylor is not signing for several reasons. Her model says that LLM work won’t lead to AGI and is actually a distraction that makes AGI less likely, despite the increases in funding and attention, so why get in its way? I agree that if you think this, you should not be calling to slow such work down. Also thee usual reminder that regulations never work the way you want them to.

Worth noting that Eliezer has moderated his position on LLMs not being on a path to superintelligence, based on the observed capabilities of GPT-4.
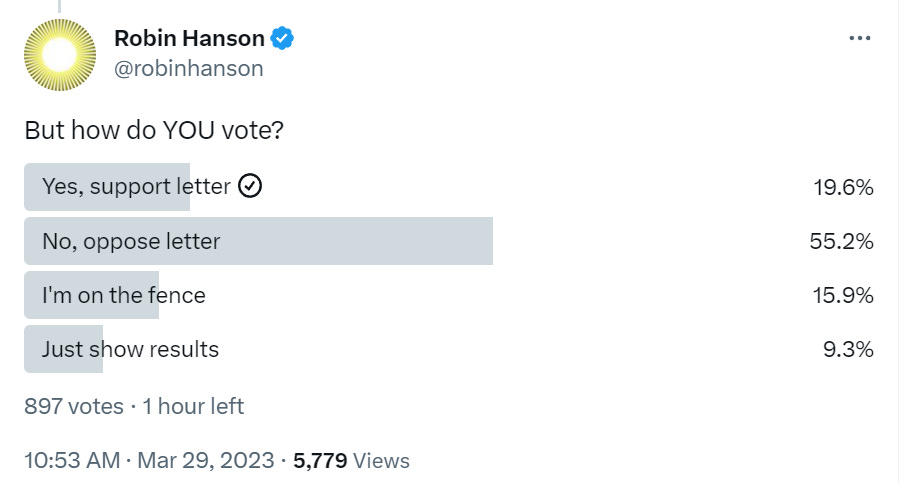
Robin Hanson votes no, also does not see much risk of AGI, also noting that the only policy that could actually ‘ensure safety’ is an indefinite pause, and does a poll.
Looks like at least this group is mostly opposed.
Here’s Andrew Ng, who I see as only focusing on near-term ‘AI safety’ concerns while ignoring existential concerns. He seems to be saying all three of ‘current safety approaches are sufficient, we don’t need more, all the labs are taking safety seriously,’ ‘we need regulations around transparency and auditing,’ and also ‘your call for a pause is bad because the labs would never agree to it without government, and it would be bad if governments did it because governments doing such things is bad.’ Grab bag.

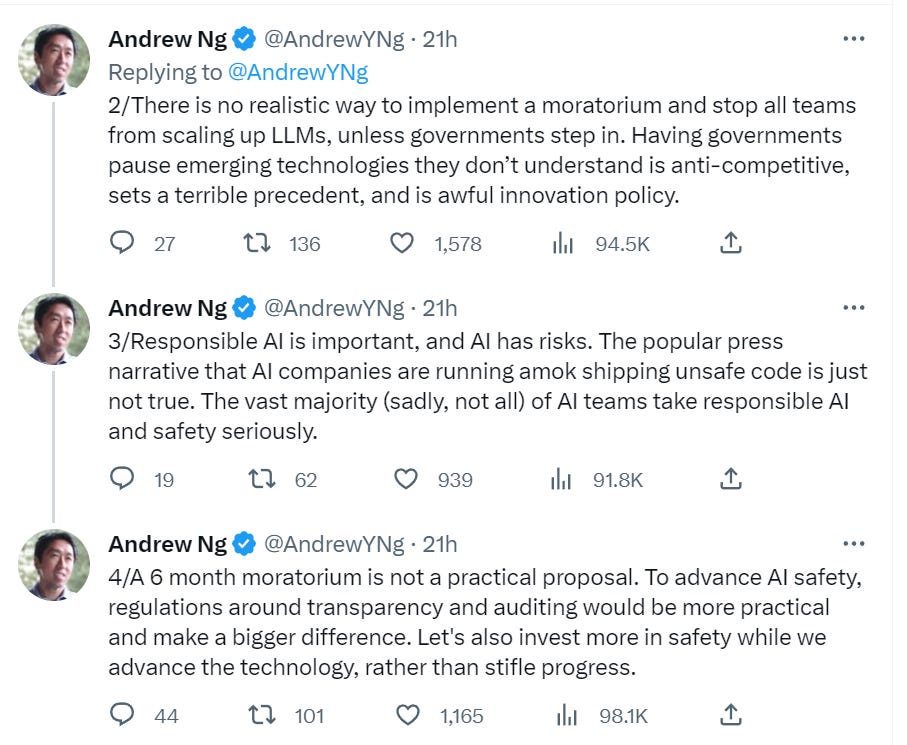
If someone comes out with a proposal that has no chance of happening, that’s a good reason not to bother with it and waste one’s powder. But it’s weird to criticize any call for coordination on the principle that no one would ever coordinate.
Daniel Eth isn’t against the letter as such now that it exists (as far as I can see) but does think the petition was a mistake as executed. Community here means EA.
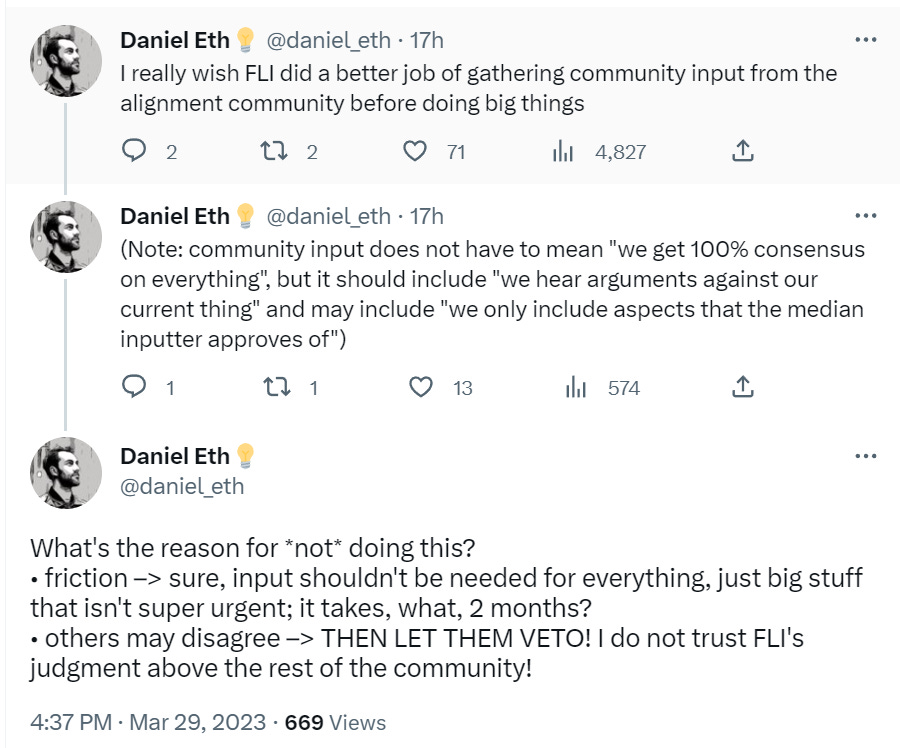
I strongly disagree that we should be letting communities veto activities like this, especially given the history of sitting around ultimately doing very little. I think such feedback is good, if it is too negative one should take that into account, and do one’s best to execute well based on the info you get, but if asking means asking permission, then you can’t ask.
Two extra months right now is kind of a big deal, especially given you might lose momentum and that’s a best case scenario. I started writing about AI less than two months ago.
There’s also the fact that it would leak. If the EA community was circulating a draft letter, it would be identified and attacked before it was issued, before it had its signatories, and the whole thing would fail. The forums are not private.
Conclusion
I am happy the letter came out, people are saying what they actually believe more directly, the arguments are being laid out, and I am glad people are signing it. I do not expect much chance of the pause happening, but would be thrilled if it did given the momentum and groundwork that would establish.
At the same time, the letter has some important flaws. It conflates short-term worries like job losses with existential risks, and is suggesting standards that seem impossible to meet in practice without owning up to what they would likely mean, even if I think it would be reasonable to want the practical effects that would have.
On the flip side, there is a reasonable argument that the letter’s calls for direct action do not go far enough. And there are a number of additional good arguments against this path, although I do not see good alternative proposals suggested that have lighter or similar footprints.
I am still thinking everything through, as we all should be. I am posting this in its current state, not because it is perfect, but because things are moving quickly, and good thoughts now seem better than great thoughts next week, if one must choose.
I also am not dealing, here, with Eliezer Yudkowsky’s letter in Time magazine, beyond noticing it exists. As I said earlier, one thing at a time, and I promise to deal with that soon.
having seen the “kitchen side” of the letter effort, i endorse almost all zvi’s points here. one thing i’d add is that one of my hopes urging the letter along was to create common knowledge that a lot of people (we’re going to get to 100k signatures it looks like) are afraid of the thing that comes after GPT4. like i am.
thanks, everyone, who signed.
EDIT: basically this: https://twitter.com/andreas212nyc/status/1641795173972672512
Zvi you totally ignored the risks of:
Other parties, China being the most visible, but any party outside of us government control gaining an insurmountable advantage from unrestricted r&d on this technology. If you accept the premise that government restrictions slow everything down, and you appear to hold that belief, you have the possibility of people building open agency AGIs and using them to end the geopolitical game.
Empire building and one party conquering this tiny planet was always limited by the inefficiencies of large governments and nuclear weapons. Both potentially counterable to a party with open agency AGIs.
You seem to have fixed on the conclusion that the “banana is poisoned” without considering obvious ways we could eat it and get superpowers.
I think China becoming more of a threat than it currently is (very little) might be good since it might be the Boogeyman the US gov needs to take appropriate action.
Sure but that action means more AI development and most chip fabs so that the USA is not solely dependent on factories within easy low end missile range of china
https://manifold.markets/NathanHelmBurger/will-gpt5-be-capable-of-recursive-s?r=TmF0aGFuSGVsbUJ1cmdlcg
I find the whole focus on jobs truly baffling. I would really, really love to live in the world where the company I work for went out of business because everything we do got automated and can be done for free (I work for a consulting firm that helps companies strategize and implement the best ways to hit their sustainability goals). Yes, it would suck for however long it took me to find a new job, and I might take a ay cut. I can still recognize the world would be better as a result.
I also get why someone putting together a public facing document would feel the need to include factors with more popular appeal than existential risk has. Not sure what the right answer is here.
I tend to think and I certainly hope that we aren’t looking at dangerous AGI at some small GPT-x iteration. ’Cause while the “pause” looks desirable in the abstract, it also seems unlikely to do much in practice.
But the thing I would to point out is; you have people looking the potential dangers of present AI, seeing regulation as a logical step, and then noticing that the regulatory system of modern states, especially the US, has become a complete disaster—corrupt, “adversarial” and ineffective.
Here, I’d like to point out that those caring about AI safety ought to care the general issues of mundane safety regulation because the present situation of it having been gutted (through regulatory capture, The Washington Monument syndrome, “starve the beast” ideology and so-forth) means that it’s not available for AI safety either.
The LessWrong Review runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2024. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?
[Note: I was reluctant to post this because if AGI is a real threat, then downplaying that threat could destroy all value in the universe. However, I chose to support discussion of all sides on this issue.]
[WARNING—my point may be both inaccurate and harmful—WARNING!]
It’s not obvious that AGI will be dangerous on its own, especially if it becomes all-powerful in comparison to us (also not obvious that it will remain safe). I do not have high confidence in either direction, but it seems to me that those designing the AGI can and will shape that outcome if they are thoughtful.
A common view of AGI is as a potential Thanos dialed to 100% rather than 50%, Cthulhu with less charm. However, I see no reason why a fully-developed AGI would have any reason to consider people—or all planetary life—to be a threat that merits a response, even less so than we worry about being overrun by butterflies. Cautious people view AGI as stuck at Maslow’s first two levels of need (physiological and safety). If AGI is so quick and powerful that we have zero chance of shutting it down or resisting, shouldn’t it know that before we even figure out it has reached a level where it could choose to be a threat? If AGI is so risk averse that it would wipe out all life on the planet (beyond?), isn’t it also so risk averse that it would leave the planet to avoid geological and solar threats too? If it is leaving anyways (presumably much more quickly and efficiently than we could manage), why clean up before departing?
Or would AGI more likely stay on earth for self-actualization:
And AGI blessed every living thing on the planet, saying, “be fruitful, and multiply, and fill the waters in the seas, and let fowl, the beasts, and man multiply in the earth. And AGI saw that it was good.”
Down side? A far less powerful Chat GPT tells me about things that Gaius Julius Caesar built in the Third Century AD, 300 years after it says Caesar died, and about an emperor of the Holy Roman Empire looting a monastery that was actually sacked by Saracens in the year it claims Henry IV attacked that monastery. If an early AGI has occasional hallucinations and also only slightly superior intelligence, so that it knows we could overwhelm it, that could turn out badly. Other down side? Whether hooked to the outside world or used by any of a thousand movie-inspired supervillains, AGI’s power can be used as an irresistible weapon. Given human nature, we can be certain that someone wants that to happen.
Is it possible to pause generative AI development? No but we need to think about regulations.
Dr Kabata Kenya
Remove the word “AI” and I think this claim is not really changed in any way. AI systems are the most general systems.
The statement is isomorphic to the more general claim that “In general, it is possible for a sequence of actions to result in bad outcomes even if those actions had been determined to result in good outcomes before taking them.”
I don’t think that is true in general. Furthermore, when you get close to AI, your theoretical steps and your physical steps begin to more closely coincide. If my theoretical steps say that the next theoretical step will be fine, and so was this one, then I am also more confident that the physical steps were mostly similar to this. As we develop AI, the more developed AI’s should be making us more confident that things will go well than the previous AI’s, and so on.
Therefore, if there is ever a point at which we feel confident that AI could be developed safely, it should be at the same time that we develop a near-AGI that makes us feel near-confident that it could be developed safely.
If not, then not six months, nor any conceivable time-frame would be expected to result in something that made everyone feel confident enough. If you believe the statement above (my restatement of it), that isn’t going to even be possible, in principle.