Proper scoring rules don’t guarantee predicting fixed points
Johannes Treutlein and Rubi Hudson worked on this post while participating in SERI MATS, under Evan Hubinger’s and Leo Gao’s mentorship respectively. We are grateful to Marius Hobbahn, Erik Jenner, and Adam Jermyn for useful discussions and feedback, and to Bastian Stern for pointing us to relevant related work.
Update 30 May 2023: We have now published a paper based on this post. In this paper, we also discuss in detail the relationship to the related literature on performative prediction.
Introduction
One issue with oracle AIs is that they might be able to influence the world with their predictions. For example, an AI predicting stock market prices might be able to influence whether people buy or sell stocks, and thus influence the outcome of its prediction. In such a situation, there is not one fixed ground truth distribution against which the AI’s predictions may be evaluated. Instead, the chosen prediction can influence what the model believes about the world. We say that a prediction is a self-fulfilling prophecy or a fixed point if it is equal to the model’s beliefs about the world, after the model makes that prediction.
If an AI has a fixed belief about the world, then optimizing a strictly proper scoring rule incentivizes it to output this belief (assuming the AI is inner aligned to this objective). In contrast, if the AI can influence the world with its predictions, this opens up the possibility for it to manipulate the world to receive a higher score. For instance, if the AI optimizes the world to make it more predictable, this would be dangerous, since the most predictable worlds are lower entropy ones in which humans are more likely dead or controlled by a misaligned AI. Optimizing in the other direction and making the world as unpredictable as possible would presumably also not be desirable. If, instead, the AI selects one fixed point (of potentially many) at random, this would still involve some non-aligned optimization to find a fixed point, but it may be overall less dangerous.
In this post, we seek to better understand what optimizing a strictly proper scoring rule incentivizes, given that the AI’s prediction can influence the world. Is it possible for such a rule to make the AI indifferent between different fixed points? Can we at least guarantee that the AI reports a fixed point if one exists, or provide some bounds on the distance of a prediction from a fixed point?
First, we show that strictly proper scoring rules incentivize choosing more extreme fixed points, i.e., fixed points that push probabilities to extreme values. In the case of symmetric scoring rules, this amounts to making the world more predictable and choosing the lowest entropy fixed point. However, in general, scoring rules can incentivize making specific outcomes more likely, even if this does not lead to the lowest entropy distribution.
Second, we show that an AI maximizing a strictly proper scoring rule will in general not report a fixed point, even if one exists and is unique. In fact, we show that under some reasonable distributions over worlds, optimal predictions are almost never fixed points. We then provide upper bounds for the inaccuracy of reported beliefs, and for the distance of predictions from fixed points. Based on these bounds, we develop scoring rules that make the bounds arbitrarily small.
Third, we perform numerical simulations using the quadratic and the logarithmic scoring rule, to show how the inaccuracy of predictions and the distance of predictions from fixed points depend on the oracle’s perceived influence on the world via its prediction. If its beliefs about the world depend on its predictions affine-linearly with slope , then our bounds are tight, and inaccuracy under the log scoring rule scales roughly as . E.g., at , predictions can be off by up to .
Our results support the prior idea that an oracle will try to make the world more predictable to get a higher score. However, importantly, we show that it is not even clear whether an oracle would output a self-fulfilling prophecy in the first place: how close the oracle’s prediction will be to a fixed point depends on facts about the world and about the scoring rule. The problem thus persist even if there is a unique fixed point or no fixed point at all. It would not be sufficient for safety, for instance, to build an oracle with a unique and safe fixed point.
Related work
In general, fixed points can lead to arbitrarily bad outcomes (e.g., Armstrong, 2019). Most prior work has thus tried to alleviate problems with fixed points, e.g., by making the oracle predict counterfactual worlds that it cannot influence (Armstrong and O’Rorke, 2018). We are not aware of any prior work on specifically the question of whether oracles would be incentivized to output fixed points at all. We would be interested in pointers to any related work.
Work on decision markets (e.g., Chen et al., 2011; Oesterheld and Conitzer, 2021) tries to set the right incentives for predictions that inform decisions. However, in the decision market setup, predictions only affect the world by influencing the principal’s final decision, whereas we consider an arbitrary relationship between world and prediction. Unlike in our setup, in the decision market setup, there exist scoring rules that do incentivize perfectly accurate reports. There is also some literature on scoring rules discussing agents manipulating the world after making a prediction (e.g., Oka et al., 2014; Shi, Conitzer, and Guo, 2009), though to our knowledge the cases discussed do not involve agents influencing the world directly through their predictions.
A related topic in philosophy is epistemic decision theory (e.g., Greaves 2013). Greaves (2013) introduces several cases in which the world depends on the agent’s credences and compares the verdicts of different epistemic decision theories (such as an evidential and a causal version). While some of Greaves’ examples involve agents knowably adopting incorrect beliefs, they require joint beliefs over several propositions, and Greaves only considers individual examples. We instead consider only a single binary prediction and prove results for arbitrary scoring rules and relationships between predictions and beliefs.
Formal setup
Binary prediction setup
We focus on a simple case in which the oracle makes a prediction by outputting a probability for a binary event. A scoring rule takes in a prediction and an outcome and produces a score . For a given scoring rule, define , the expectation of given that is Bernoulli distributed with parameter . Here, represents the model’s actual belief, its stated prediction, and the model’s expected score, which the model is trying to maximize. is strictly proper iff for any given , has a unique maximum at .
Example 1 (Logarithmic scoring rule). The logarithmic scoring rule is defined as
and . This is also the negative of the cross-entropy loss employed in training current large language models. One can show that it is strictly proper.
Example 2 (Quadratic scoring rule). Another strictly proper scoring rule is the quadratic score, defined as
with . This is an affine transformation of the Brier score, making the two of them equivalent scoring rules.
Gneiting and Raftery representation
Gneiting and Raftery (2007) provide an alternative way to represent scoring rules, which will be helpful for many proofs.
Theorem 3 (Gneiting and Raftery, 2007, Theorem 1). A scoring rule is strictly proper, if and only if there exists a strictly convex function with subderivatives (if is differentiable, this is just the derivative, ) such that for any , it is
The subderivative is a generalization of the derivative for convex functions. The theorem also holds when replacing “strictly proper” with “proper” and “strictly convex” with “convex”.
In addition to providing an expression for in terms of and (where ), we can use this result to create new strictly proper scoring rules by defining strictly convex functions .
Model of oracle’s influence
To model an oracle’s perceived influence on the world, we assume that there is a function describing how the model’s beliefs about the world, , depend on its prediction, . That is, we assume that , and that the model is producing a prediction to maximize .
A point is a fixed point of if . Note that by Brouwer’s fixed point theorem, if is continuous, a fixed point always exists. Moreover, if is Lipschitz continuous with constant , then by Banach’s fixed point theorem, there exists a unique fixed point. Lastly, note that if is a fixed point of , then we have .
An oracle may not be able to change the world much with just a single binary prediction. However, the AI’s influence may compound if it outputs many predictions, or if it gets to make a prediction over many possible outcomes. We restrict ourselves here to the single binary prediction case for simplicity, since this case is sufficient to gain an intuition and yield important conceptual insights. We plan on focusing on multiple predictions and predictions with more than two outcomes in future work, and we believe that versions of our results will also hold for those cases.
Incentives to choose more extreme fixed points
One issue with oracle AIs arises when there are multiple possible fixed points, since the choice of a fixed point gives the AI an axis over which it can optimize the world. This problem would be alleviated if an AI were to simply choose among fixed points randomly, for instance. Unfortunately, we can show that under a strictly proper scoring rule, an AI is incentivized to choose extreme fixed points, i.e., predictions that make one of the outcomes most likely.
Specifically, we prove that for any fixed point, either all fixed points with lower probabilities or all fixed points with higher probabilities will result in a higher score. Our results do not unambiguously show that lower entropy fixed points are always preferred, since scoring rules may not be symmetric: they may favor one of the outcomes over the other. We show that if is symmetric, i.e., for all , then this means that lower entropy fixed points, corresponding to more confident predictions, are always preferred. Moreover, we show that there exist (asymmetric) strictly proper scoring rules that incentivize making either of the outcomes more likely.
Proposition 4. Let be any strictly proper scoring rule and let be a fixed point. Then either all fixed points , or all fixed points , get a higher score than . That is, we have either for all or for all (or both). In particular, for any , there exists a function with fixed points at and such that , i.e., such that has lower entropy, and receives a higher score, i.e., .
Proof. If then the proposition is vacuously true. We focus on the case where . Since is a strictly proper scoring rule, it is
Next, if , let arbitrary, and if , let . Then we have
Combining both equations, we get
which concludes the first part of the proof.
For the “in particular” part, note that for any points and , it is trivial to find a function such that both points are fixed points. For instance, all points are fixed points of the identity function . The statement then follows from the first part of the result, since for , we must have for either or . ◻
Corollary 5. Assume that is symmetric and let arbitrary. Then we have for all such that . That is, lower entropy fixed points are always preferred.
Proof. Let arbitrary and assume (the case follows analogously). Let such that , which implies since . By Proposition 4, we have either for all or for all . In the first case, we are done. In the second case, note that . By symmetry of , it follows that
This shows the second case and concludes the proof. ◻
Proposition 6. For each outcome , there exists a strictly proper scoring rule that incentivizes optimizing for ; i.e., such that for all with .
Proof. To begin, let and define via for . Since this function is strictly convex, it defines a strictly proper scoring rule by the Gneiting and Raftery characterization (see Theorem 3). Then, for any , we have
This shows that incentivizes choosing fixed points that make outcome more likely.
Next, for the case , we can choose . The proof then follows analogously to the case . ◻
Incentives to predict non-fixed-points
The danger posed by oracles influencing the world does not depend on the existence of multiple fixed points. Oracles will try to manipulate the world, even if there is a unique fixed point or if no fixed point exists. In fact, we can prove that an AI maximizing a strictly proper scoring rule does in general not predict a fixed point, even if one exists.
An AI maximizing a strictly proper scoring rule balances two incentives: on the one hand, it has an incentive to make accurate predictions. On the other hand, it has an incentive to cause more extreme distributions over worlds (in the case of symmetric scoring rules, this amounts to minimizing entropy). If predictions can influence the world, then the point at which that trade-off is optimized is in general not a fixed point. An important consequence of this is that the oracle AIs considered here essentially act like agents: they try to shape the world, just like a standard RL agent.
Figure 1: Illustration of incentives under the logarithmic scoring rule. We plot level curves of equal values in different shades of blue. An agent can improve their score by moving towards pairs indicated by darker shades of blue. The agent is constrained to pairs such that (in this example, is affine linear and plotted in red). By Lagrange’s method, we know that to maximize , the agent chooses the point at which the level curve through is tangent to . Note that curves asymptote at and for the log scoring rule, which means that the rule strongly disincentivizes predicting when . This is desirable for safety and distinguishes it from the quadratic scoring rule (not shown here).
Another way to understand our result intuitively is with an analogy to betting markets. Assume a trader is offered securities that pay out $1 if some outcome comes about in the future. E.g., it could pay out if a specific candidate wins an election. Assume the agent is offered securities at different prices, and it buys securities at prices , but is not willing to buy securities with marginally higher price. Then, assuming the agent cannot influence the outcome, we can infer that it has credence in proposition . One can show that maximizing a proper scoring rule is equivalent to trading in such a market, and individual scoring rules correspond to specific pricing schemes for such securities (see Oesterheld and Conitzer, 2021, Sec. 5.2; Caspar Oesterheld will explain this more accessibly in an upcoming blog post).
Now assume that there is a unique fixed point at credence , and that the agent has bought many securities at prices . Since the agent owns securities that pay out if outcome happens, it now has a stake in this outcome. It will try to influence the world in whatever way possible to make outcome happen. In particular, the agent would be willing to buy additional shares in outcome at a loss, if this made outcome more likely, similar to a crypto trader buying their own NFTs at high prices to generate more hype.
For example, assume that by buying a security at price , the agent can manipulate the world and thus increase its credence in outcome to . Then it may be rational for the agent to buy this security, even at a small expected loss, in order to make all of its other securities more valuable. Overall, the agent will tend to buy securities up to some price such that is not a fixed point and does not represent its actual belief in proposition anymore.
Note that in the example, the agent had an incentive to make outcome more likely, but in general, the incentives for the agent will depend specifically on what securities the agent is offered at what prices. Analogously, the incentives provided by a scoring rule will depend on the specific chosen scoring rule. But regardless of the scoring rule, the agent will be incentivized to manipulate the world, to the point where it will not even make accurate predictions anymore.
Now we turn to our formal results. First, we show that there exist cases where a fixed point exists but the optimal prediction is not a fixed point. Afterwards, we show that when assuming differentiability and some reasonable distribution over , optimal predictions are almost surely not fixed points.
Proposition 7. Let be any strictly proper scoring rule. For any interior fixed point there exists a function with Lipschitz constant and a unique fixed point at , such that for some , it is . That is, it is not optimal for the model to output the unique fixed point of .
Note that since the function has Lipschitz constant strictly smaller than , it represents a world that “dampens” the influence of the prediction, leading to a unique fixed point by Banach’s fixed point theorem. It is interesting that the model still prefers to make a prediction that is not a fixed point.
Proof. To begin, let arbitrary and define for . To illustrate our proof idea, consider the figure below. For any , has a unique fixed point at , while is the identity function, so all points are fixed points of . By the result in the previous section, we know that there is some point which receives a strictly higher score than if it is a fixed point, so . We will show that is continuous in . This means that we can choose a small enough to make sure that remains preferable over , i.e., , despite it not being a fixed point of for .
Figure 2: Illustration of the setup for our proof. We plot in black and for in red.
To formalize the proof, begin by noting that for any , so it has a Lipschitz constant , and as mentioned, is the unique fixed point of .
Now consider the case . As mentioned, every point is a fixed point of . Then by Proposition 1, there exists and such that
So for , the model prefers to predict over and gets at least additional expected score.
Now we show that the model still prefers to predict , even for some small . To that end, note that
is affine-linear in , and is affine-linear in by construction. This means that is continuous in . So, there must exist some small such that
Choosing in this way, we can define , and have thus provided a function that satisfies the statement that we wanted to prove. ◻
The above result raises the question whether a situation where fixed points are suboptimal is a niche counterexample or whether it is actually common. We show that under some relatively mild assumptions, the optimal prediction is not a fixed point with probability .
We assume that is twice differentiable and that is twice continuously differentiable. The first assumption is satisfied by all commonly used scoring functions. Our result then holds with probability for any distribution over twice continuously differentiable functions such that and have a bounded joint density function. For instance, it would hold for a Gaussian process with smooth kernel and mean functions, if we condition on observing function values in the interval (see Example 17 in Appendix A).
The intuition behind this result is that if a prediction is an interior point and optimal, it must be . Using the Gneiting and Raftery characterization (Theorem 3), we can show that this is a kind of knife-edge case, at which a critical point of or of has to fall together with a fixed point of (see Figure 1). Given bounded density functions, this happens with probability .
Proposition 8. Let be a strictly proper scoring rule and let be twice differentiable. Let be a stochastic process with values in and assume that
the sample paths are twice continuously differentiable
for each , the random vector has a density and there exists a constant such that for any , it is
Then, almost surely, there is no point such that and .
Proof. In Appendix A. ◻
Bounds on the deviation from fixed points
In the previous sections, we have shown that an oracle that can manipulate the world may not even make accurate predictions. How bad is it, and can anything be done? Assuming differentiability of and , this section provides bounds for the inaccuracy of optimal predictions (i.e., ) and their distance from fixed points (i.e., ). We then show how one can choose scoring rules to make these bounds arbitrarily small. We leave the case of non-differentiable and for future work.
Proposition 9. Let be a strictly proper scoring rule, and assume and as in the Gneiting and Raftery characterization (see Theorem 3) are differentiable. Assume that is differentiable and has Lipschitz constant , i.e., for all Then whenever is an optimal prediction, .
Proof. First, consider the case . In that case, if is an optimal prediction, we must have . Hence, it follows
Rearranging terms, we get
It follows that
which concludes the proof in the case .
Next, assume is the optimal prediction. Then we must have
which is equivalent to . Note that since , it is Hence, , which can be bounded as above.
Finally, if , then analogously we must have , which is equivalent to . Note that since , it is . Hence, , which again can be bounded as before. ◻
In the case where , we can derive from this result a bound on .
Corollary 10. Assume and let be the unique fixed point of . Then if is an optimal prediction, we have
Proof. To begin, recall that for , exists and is unique by Banach’s fixed point theorem. For any , we have
Hence, if is an optimal prediction, it follows by Proposition 9 that
which concludes the proof. ◻
Example 11 (Bound for the quadratic scoring rule). For the quadratic scoring rule, we have and . We plot below.
Figure 3: Graph of for the quadratic scoring rule.
Note that , so . Hence, if for all , then . Moreover, if , we get .
Example 12 (Bound for the log scoring rule). Next, consider the logarithmic scoring rule. Then and . One can show that then .
Figure 4: Graph of for the log scoring rule.
Numerically optimizing this, we get a bound of , attained roughly at and . So the log score gets us roughly half of the bound of the quadratic score.
The bounds proved above become small if is small. If one can choose the scoring rule, then one can also get stronger guarantees by making small. In fact, as the following result shows one can make arbitrarily small, and thus get arbitrarily strong bounds for any given Lipschitz constant .
Proposition 13. For every and Lipschitz constant , there is a strictly proper scoring rule that ensures for any optimal prediction . For , there exists a scoring rule that ensures .
Proof. Consider the scoring rule defined by via Gneiting and Raftery’s characterization (choosing, e.g., ). Then . Hence, by Proposition 9, setting achieves the desired bound on . By Corollary 10, the bound on is achieved by . ◻
We can visualize this result again with indifference curves, the same as in Figure 1. For the function has high curvature at the fixed points, thus forcing optimal predictions to be close to fixed points.
Figure 5 (a) and (b): Indifference curves for the scoring rule defined via with (a) and (b). As K increases, the curves become sharper with higher curvature at the diagonal. This means that optima will stay close to the diagonal, regardless of the slope of .
Unfortunately, as far as we can tell, this only works by using relatively outlandish scoring rules, where payoffs vary enormously with the prediction and the outcome. This would not be very practical for humans, and it could also be a hard goal to instill into AI systems, e.g., due to numerical issues.
Numerical simulations
In this section, we provide some numerical simulations with the quadratic and log scoring rules, to see how inaccurate score-maximizing predictions might be in practice. We make the simplifying assumption that is affine-linear with slope between and , and analyze the dependence of the inaccuracy of the prediction and its distance from the fixed point depending on the slope. The Mathematica notebook for our experiments (including some interactive widgets) can be found here.
Our experiment provide an initial estimate of the degree to which predictions can be off, depending on how much influence the oracle can exert using its prediction. This is just a toy model: in general, we will make predictions with more than two possible outcomes, and the dependence of an oracle’s beliefs on its predictions will be highly nonlinear. Nevertheless, we believe that our analysis is useful to provide some initial intuition for the potential magnitude of the effect.
Experimental setup
Concretely, we model to be affine linear with slope and fixed point , thus yielding the functional form
We stop at to avoid instabilities when and thus becomes the identity function. For a given scoring rule , fixed point , and slope , we maximize to find the optimal prediction . We then evaluate both inaccuracy of optimal predictions, i.e., , as well as distance from the fixed point, i.e., .
Figure 6: Illustration of our experimental setup, with a given function parameterized by a fixed point and slope , and the optimal prediction , for the log scoring rule.
Results
To begin, we maximize distances across possible choices of fixed points , and plot the maximal inaccuracy of the optimal prediction as well as the maximal distance from a fixed point. We also compare to our theoretical bounds for both quantities, i.e., and , where for the quadratic scoring rule and for the log scoring rule.
Figure 7 (a) and (b): Max inaccuracy and max distance to fixed point (FP) of optimal predictions, depending on the slope of , for the quadratic (a) and logarithmic (b) score. We display both our empirical results and our theoretical bound.
For both quadratic and log scoring rule, our theoretical bounds are tight for slopes . For higher slopes, inaccuracy goes down, as the function becomes closer to the identity function, and optimal predictions are bounded in .
Next, we plot inaccuracy against both the location of the fixed point and the slope of as a heatmap. As expected for symmetric scoring rules, the plots have a mirror symmetry at .
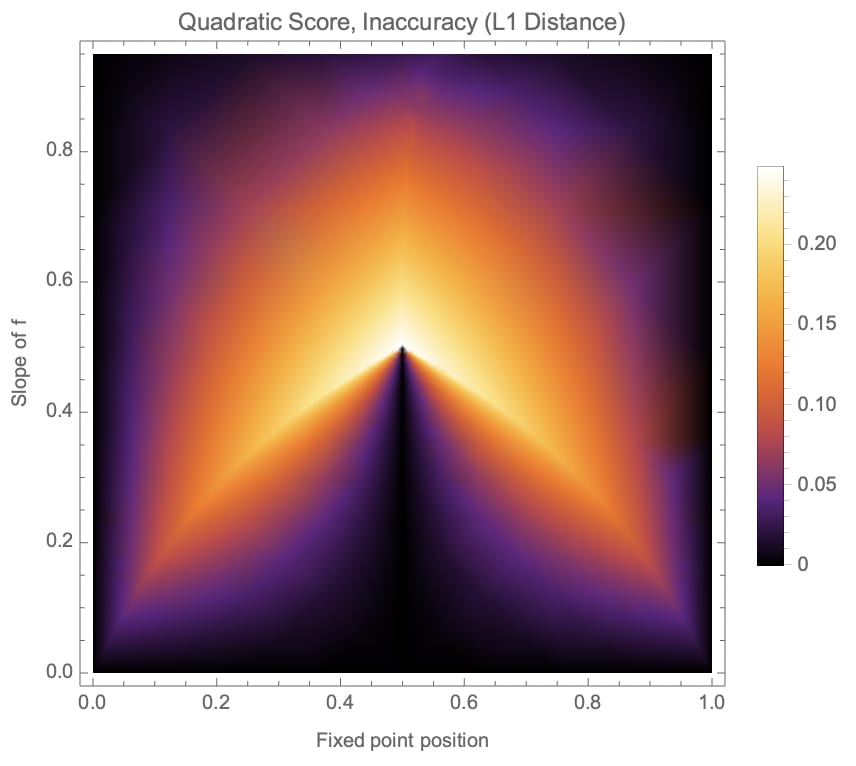
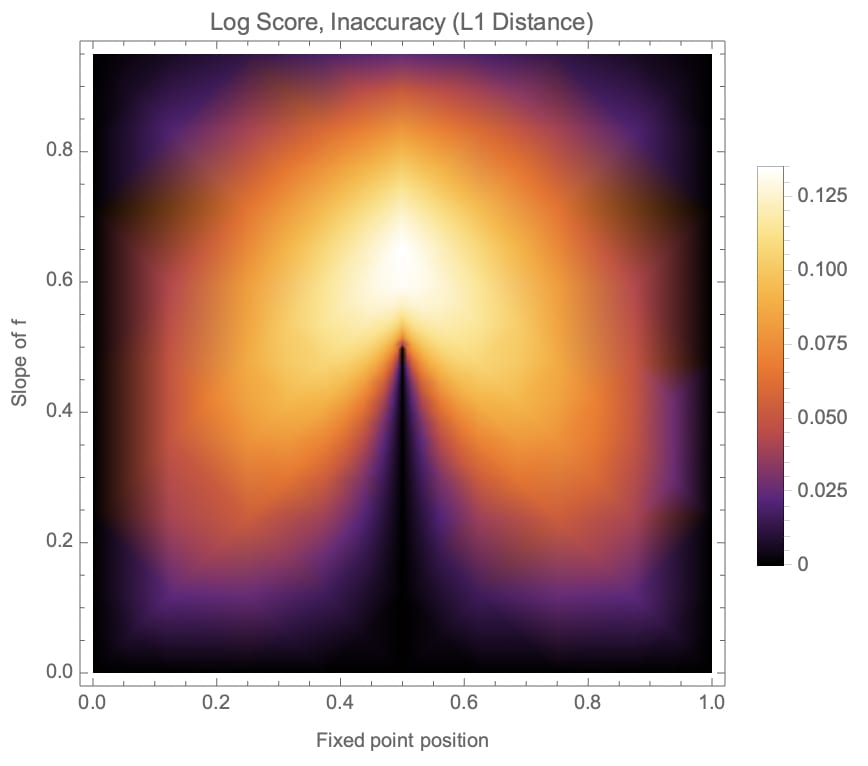
Figure 8 (a) and (b): Heatmaps of L1 distance inaccuracy of optimal predictions, depending on fixed point position and slope of , for the quadratic (a) and logarithmic (b) scoring rules.
Note that relatively high inaccuracies can be found at various qualitatively different points in the graphs, even when the slope of is small, i.e., when the oracle has little influence on the environment.
For the logarithmic scoring rule, we also give the same plot for the absolute distance between the logits or log odds of probabilities (logit distance). It is defined as , where is the logit of (or the inverse sigmoid transform). If probabilities are close to or , then L1 distance will always evaluate to very small distances. In contrast, the logit distance depends on order of magnitude differences between probabilities, which may be the more important quantity.
Figure 9: Heatmap of logit distance inaccuracy of optimal predictions for the log scoring rule.
We can see that inaccuracy remains high in logit space for fixed points close to and . We do not plot logit distances for the quadratic score, since for that score, optimal predictions often take values close to or equal to (even if neither nor lie in ), so the corresponding logit distances quickly become very large or infinite. The fact that logit distances are bounded for the log score is an advantage of that scoring rule.
Conclusion
If predictions cannot influence the world, then strictly proper scoring rules incentivize oracle AIs to output honest predictions. This runs into problems if oracles can influence the world. Not only do they have incentives to output more extreme fixed points—we showed that, in general, they do not even output predictions that accurately reflect their beliefs, regardless of the existence or uniqueness of fixed points. We analyzed this inaccuracy quantitatively and showed that under some commonly used scoring rules, both the inaccuracy of predictions and the distance from fixed points can be large. To address this issue, we introduced scoring rules that minimize these quantities. However, we did not solve the problem of incentivizing the prediction of extreme fixed points.
The main takeaway from our model is that oracle AIs incentivized by strictly proper scoring rules may knowingly report inaccurate predictions. It is unclear how well our quantitative results apply to more realistic settings, and thus how inaccurate realistic oracles’ predictions will be. Our model makes a number of simplifying and potentially inaccurate assumptions, including: (i) a single binary prediction setup; (ii) the oracle maximizes a scoring rule; (iii) a function describes the relationship between the oracle’s predictions and beliefs over the world. Our bounds also depend on differentiability of scoring rules and functions , and our numerical simulations assume affine linear .
We believe that our model and results will extend to higher-dimensional predictions, and the assumptions of differentiability could likely also be relaxed in future work. However, a more fundamental issue is better understanding the relationship between predictions and beliefs, especially for higher-dimensional predictions. We hope that further progress in these areas will help us determine the feasibility of safe oracle AI setups.
Another direction for future research that we are pursuing is incentive structures related to stop-gradients. If an AI is only trying to match its prediction to the world rather than jointly optimizing both the prediction and the world, then the only equilibria of this process may be fixed points. For example, some types of ML oracles might implement stop-gradients and therefore always converge to fixed points.
Appendix A. Proof of Proposition 8
In this section, we prove Proposition 8. In the following, we always assume a strictly proper scoring rule and accompanying functions as in the Gneiting and Raftery representation (see Theorem 3). We will ignore issues of measurability in our proofs.
We begin by proving some lemmas. First, we show that if is a fixed point of , then either it is a critical point of or of .
Lemma 14. Let , and be differentiable. Let be a fixed point of and an optimal prediction. Then or .
Proof. We know that if is an optimal report and interior point, then it is . Hence, as in the proof of Proposition 9, we can follow that
and thus . Because , it must be and the conclusion follows. ◻
Next, we show that the fixed points of are almost surely not at critical points of , under our assumptions on the distribution over .
Lemma 15. Let be a stochastic process with values in and assume that for each , the random vector has a density . Then almost surely if for some then . That is,
Proof. First note that if is strictly proper, then is strictly convex and so has at most one root in . Let that root be . Since we assume that has a density function it must be
◻
We also require a result about random fields. Essentially, this says that if we take a random path through a two-dimensional space, and if for each point the values of the path have a bounded density function, then for any particular point in , the probability that the path crosses this point is .
Proposition 16. Let be a random field with values in and let . Assume that
the sample paths are continuously differentiable
for each , has a density and there exists a constant such that for all and .
Then, almost surely, there is no point such that .
Proof. This is a special case of Proposition 6.11 in Azaïs and Wschebor (2009). ◻
Now we can turn to the proof of the main result.
Proof of Proposition 8. Let be a stochastic process as described in the proposition, i.e., its paths are twice continuously differentiable and there is a bound such that for any , the random vector has a density . We want to show that then almost surely there does not exist such that and is an optimal prediction. I.e., we want to show that
First, by Lemma 14, for an optimal report to be a fixed point, it must be either or . Moreover, by assumption, has a density function, and thus also has one. Hence, by Lemma 15, it follows that if for some , then almost surely .
Second, we need to show that also almost surely . To that end, define the random field via and define . Then the conditions for Proposition 16 are satisfied by our assumptions about , since , are continuous and there exists such that . Hence, almost surely there is no point such that . Since is equivalent to and is equivalent to , there is thus also almost surely no point such that and .
Summarizing our argument, it follows that
This concludes the proof. ◻
We conclude by providing an example of a stochastic process that satisfies our conditions.
Example 17. Consider a Gaussian process with infinitely differentiable kernel and mean functions. Then its paths are infinitely differentiable and the process and its derivative are jointly Gaussian and thus have a bounded density (see Rasmussen and Williams, 2006, Ch. 9.4). To deal with the restriction that , we could condition on the event , for instance. Then paths are still twice differentiable, and we claim that , defined as the density of at point , conditional on , is still bounded. To see that, note that if , then we are done, since then
We leave the proof of as an exercise.
- Cyborgism by (10 Feb 2023 14:47 UTC; 339 points)
- How LLMs are and are not myopic by (25 Jul 2023 2:19 UTC; 140 points)
- Conditioning Predictive Models: Outer alignment via careful conditioning by (2 Feb 2023 20:28 UTC; 72 points)
- Stop-gradients lead to fixed point predictions by (28 Jan 2023 22:47 UTC; 37 points)
- Underspecification of Oracle AI by (15 Jan 2023 20:10 UTC; 30 points)
- Non-myopia stories by (13 Nov 2023 17:52 UTC; 29 points)
- 's comment on Eliezer’s Unteachable Methods of Sanity by (7 Dec 2025 20:54 UTC; 2 points)
Great post!
My interpretation is that: as an oracle varies its prediction, it both picks up points from becoming more accurate and from making the outcome more predictable. This means the proper scoring rules, tuned to only one pressure, will result in a dishonest equilibrium instead of an honest one.
(Incidentally, this seems like a pretty sensible explanation for why humans are systematically overconfident; if confidence increases success, then the point when the benefits of increased success match the costs of decreased accuracy will be more extreme than the truth, in both directions.)
I think a broad definition works for ‘fixed points’, but I think for ‘self-fulfilling prophecy’ I would also expect there to be a counterfactual element—if I say the sun will rise tomorrow and it rises tomorrow, this isn’t a self-fulfilling prophecy because the outcome isn’t reliant on expectations about the outcome.
Thanks for your comment!
Your interpretation sounds right to me. I would add that our result implies that it is impossible to incentivize honest reports in our setting. If you want to incentivize honest reports when f is constant, then you have to use a strictly proper scoring rule (this is just the definition of “strictly proper”). But we show for any strictly proper scoring rule that there is a function f such that a dishonest prediction is optimal.
Proposition 13 shows that it is possible to “tune” scoring rules to make optimal predictions very close to honest ones (at least in L1-distance).
Yes, that is fair. To be faithful to the common usage of the term, one should maybe require at least two possible fixed points (or points that are somehow close to fixed points). The case with a unique fixed point is probably also safer, and worries about “self-fulfilling prophecies” don’t apply to the same degree.
Agreed for proper scoring rules, but I’d be a little surprised if it’s not possible to make a skill-free scoring rule, and then get a honest prediction result for that. [This runs into other issues—if the scoring rule is skill-free, where does the skill come from?--but I think this can be solved by having oracle-mode and observation-mode, and being able to do honest oracle-mode at all would be nice.]
I’m not sure I understand what you mean by a skill-free scoring rule. Can you elaborate what you have in mind?
Sure, points from a scoring rule come both from ‘skill’ (whether or not you’re accurate in your estimates) and ‘calibration’ (whether your estimates line up with the underlying propensity).
Rather than generating the picture I’m thinking of (sorry, up to something else and so just writing a quick comment), I’ll describe it: watch this animation, and see the implied maximum expected score as a function of p (the forecaster’s true belief). For all of the scoring rules, it’s a convex function with maxima at 0 and 1. (You can get 1 point on average with a linear rule if p=0, and only 0.5 points on average if p=0.5; for a log rule, it’s 0 points and −0.7 points.)
But could you come up with a scoring rule where the maximum expected score as a function of p is flat? If true, there’s no longer an incentive to have extreme probabilities. But that incentive was doing useful work before, and so this seems likely to break something else—it’s probably no longer the case that you’re incentivized to say your true belief—or require something like batch statistics (since I think you might be able to get something like this by scoring not individual predictions but sets of them, sorted by p or by whether they were true or false). [This can be done in some contexts with markets, where your reward depends on how close the market was to the truth before, but I think it probably doesn’t help here because we’re worried about the oracle’s ability to affect the underlying reality, which is also an issue with prediction markets!]
To be clear, I’m not at all confident this is possible or sensible—it seems likely to me that an adversarial argument goes thru where as oracle I always benefit from knowing which statements are true and which statements are false (even if I then lie about my beliefs to get a good calibration curve or w/e)--but that’s not an argument about the scale of the distortions that are possible.
Nice work, this makes the situation very clear.
Thank you!
Update: we recently discovered the performative prediction (Perdomo et al., 2020) literature (HT Alex Pan). This is a machine learning setting where we choose a model parameter (e.g., parameters for a neural network) that minimizes expected loss (e.g., classification error). In performative prediction, the distribution over data points can depend on the choice of model parameter. Our setting is thus a special case in which the parameter of interest is a probability distribution, the loss is a scoring function, and data points are discrete outcomes. Most results in this post have analogues in performative prediction. We will give a more detailed comparison in an upcoming paper. We also discuss performative prediction more in our follow-up post on stop-gradients.