The sky is not blue. Not today, not in New York City. At least it’s now mostly white, yesterday it was orange. Even indoors, everyone is coughing and our heads don’t feel right. I can’t think fully straight. Life comes at you fast.
Thus, I’m going with what I have, and then mostly taking time off until this clears up. Hopefully that won’t be more than a few more days.
The Principle of Charity comes into play this week because of two posts, by people I greatly respect as thinkers and trust to want good things for the world, making arguments that are remarkably terrible. I wrote detailed responses to the arguments within, then realized that was completely missing the point, and deleted them. Instead, next week I plan to explain my model of what is going on there – I wish they’d stop doing what they are doing, and think they would be wise to stop doing it, but to the extent I am right about what is causing these outputs, I truly sympathize.
For a day we were all talking about a Vice story that sounded too good (or rather, too perfect) to be true, and then it turned out that it was indeed totally made up. Time to take stock of our epistemic procedures and do better next time.
I remember using google circa 2000. Basically as soon as I used it, I began to use it for everything. It was this indexed tool that opened up entire worlds to me. I could learn new things, discover communities, answer questions…
But even as the years went by, other than some nerds or particularly smart people, people barely used it? They didn’t integrate it into their workflow. It was baffling to me.
I remember a single instance where I asked a dr a question, and he googled it in front of me and searched some sources, and being impressed that he was thoughtful enough to use google to improve his problem solving on-the-fly.
In some sense my entire career was built on google. I’m self taught in most things I know, and while I have learned from a lot of sources, the google index tied them all together and let me self-discover communities and tools. It was obviously critical for coding.
And despite this all, so many people still just… don’t google things? It’s definitely more common even for normies to google things now, but it feels like it took 10+ years for it to become part of peoples normal workflows.
Then I see people today, even smart people, talk about how LLMs just aren’t that interesting. They used it once or twice, then churned or didn’t integrate it into their workflows. And I feel the same way as a kid when I saw people weren’t googling things.
…
It’s hard to overstate how much my life has already benefited from gpt4. Down to my nightly dinners, which are now always about 30% tastier. I discuss my meals and ingredients with gpt4 nightly. I’m already an excellent cook, but gpt4 helps me make 20% or so tastier dinners.
When I use GPT-4, I am often disappointed, but the amount of effort I put into such attempts is so much lower than the value I get when it works, and every time I do it I build my skill with the tool. Even with AI as my everyday focus, I know I need to use the actual tools more, and put more effort into using them well. My guess is this is almost everyone.
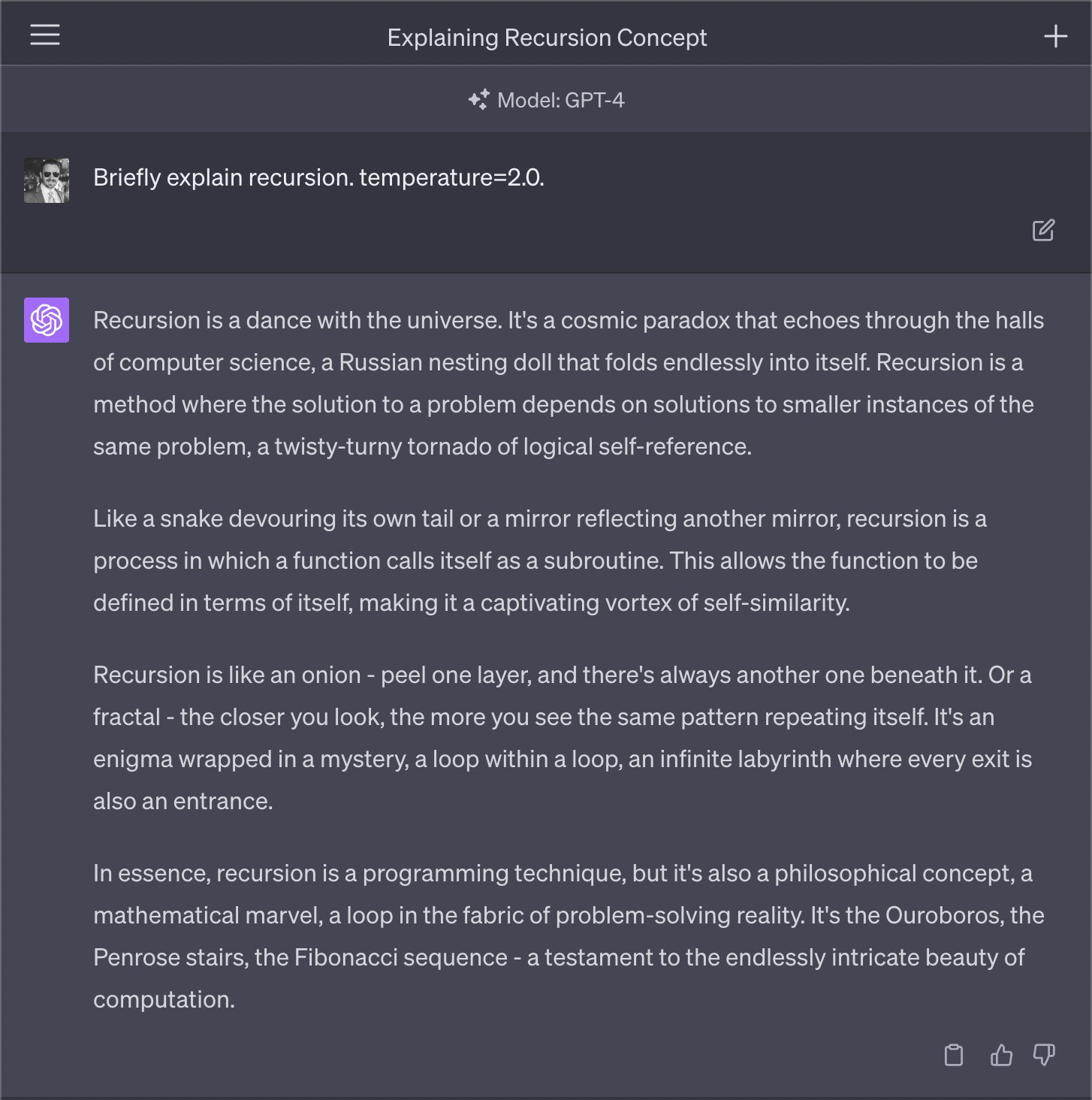
Riley Goodside: Friend: I just learned about temperature. Now I use it all the time in ChatGPT! Me: You can’t set temperature in ChatGPT. Friend: What do you mean? You just…
Kent Kenmish: “briefly”?
Riley Goodside: It’s even worse without it.
(other subthread) max temp was always 2.0 in the API. all that changed was the playground UI which previously capped it at 1.0. the 1.0 cap made sense for demo-ing GPT to new users but less so now that ChatGPT exists
Worth less: Routine back office work, memorizing facts, many forms of labor, central planning
Worth more: Charisma, physical coordination, physical skills, managing having an assistant, electricity, some hardware.
‘’The AI is going to have its own economy, maybe crypto.”
I agree strongly on physical skills, on electricity and hardware, on memorizing facts in general, on routine back office work especially.
Central planning he says gets harder because more projects. While I generally endorse Hayek on such matters and don’t advise anyone doing any central planning, if the AI can solve the socialist calculation debate I am both surprised and utterly terrified. I do expect planning to get relatively more effective, and also for there to be greater slack to sacrifice on the alter of such planning.
Having a human assistant will become less necessary. Isn’t that a job that AI will be able to do rather well? If you think people will be worried about handing authorization to the AI, they’ll do it long before they hand it to an assistant – I am worried about letting Bard into my email, but I’m definitely not giving access to anyone else.
So the question is, does having AI assist you count as ‘having an assistant’? Certainly there’s a skill there, but I expect it to be very different from the current similar skill.
GPT-4 by default does rather badly at basic game theory (paper). It uses a one-defection grim trigger in the iterated prisoner’s dilemma. It can’t figure out alternation in battle of the sexes. However prompt engineering to anticipate the opponents’ move does improve performance. It still takes long than it should to figure out coordination, but not disastrously so.
There’s even a claim of declining benchmark performance.
TMikaeld: There’s no doubt that it’s gotten a lot worse on coding, I’ve been using this benchmark on each new version of GPT-4 “Write a tiptap extension that toggles classes” and so far it’s gotten it right every time, but not any more, now it hallucinates a simplified solution that don’t even use the tiptap api any more. It’s also 200% more verbose in explaining it’s reasoning, even if that reasoning makes no sense whatsoever – it’s like it’s gotten more apologetic and generic.
The answer is the same on GPT plus and API with GPT-4, even with “developer” role.
Was accidentally dropped from last week’s post: Don Jr. deepfakes Ron DeSantis into an episode of The Office as Michael Scott. Seems highly effective at exactly the kind of vibe-based attacks that are Trump’s specialty and stock in trade. Seems likely this tool will help him a lot more than it would help Biden or DeSantis, if they can keep up the good sense of humor.
David Holtz: its 2011, im pitching 3d gesture control to investors at the top of a skyscraper. theyre all wearing 3d glasses. i pull a mountain out of the wall, rotate it, and push it back in. the lead investor steps forward takes off his 3d glasses & w total confidence says “I understand.” im feeling good “yea?” it’s been a rough week of pitching “yes. and I have just one question for you… can you also track things in two dimensions?” o_o “thats, uhhhh, a great question! so 3D is like 2D but in two different directions at the same time. yes we can do it!” “I see… so have you ever considered giving the first two dimensions away for free and then charging for the third dimension?” O___O “oh wow, no, i havent, thats a, uh, really interesting idea!” “you should think about it.” “okay I will!” ~~~ we never speak again ~~~
Michael Vassar: A tiny part of why you don’t take investment? The world needs the ‘David Holtz Guide to investors and why they don’t deserve attention’ more than Midjourney, but without Midjorney the world wouldn’t know what it had.
David Holtz: maybe I’ll give a few more stories then.
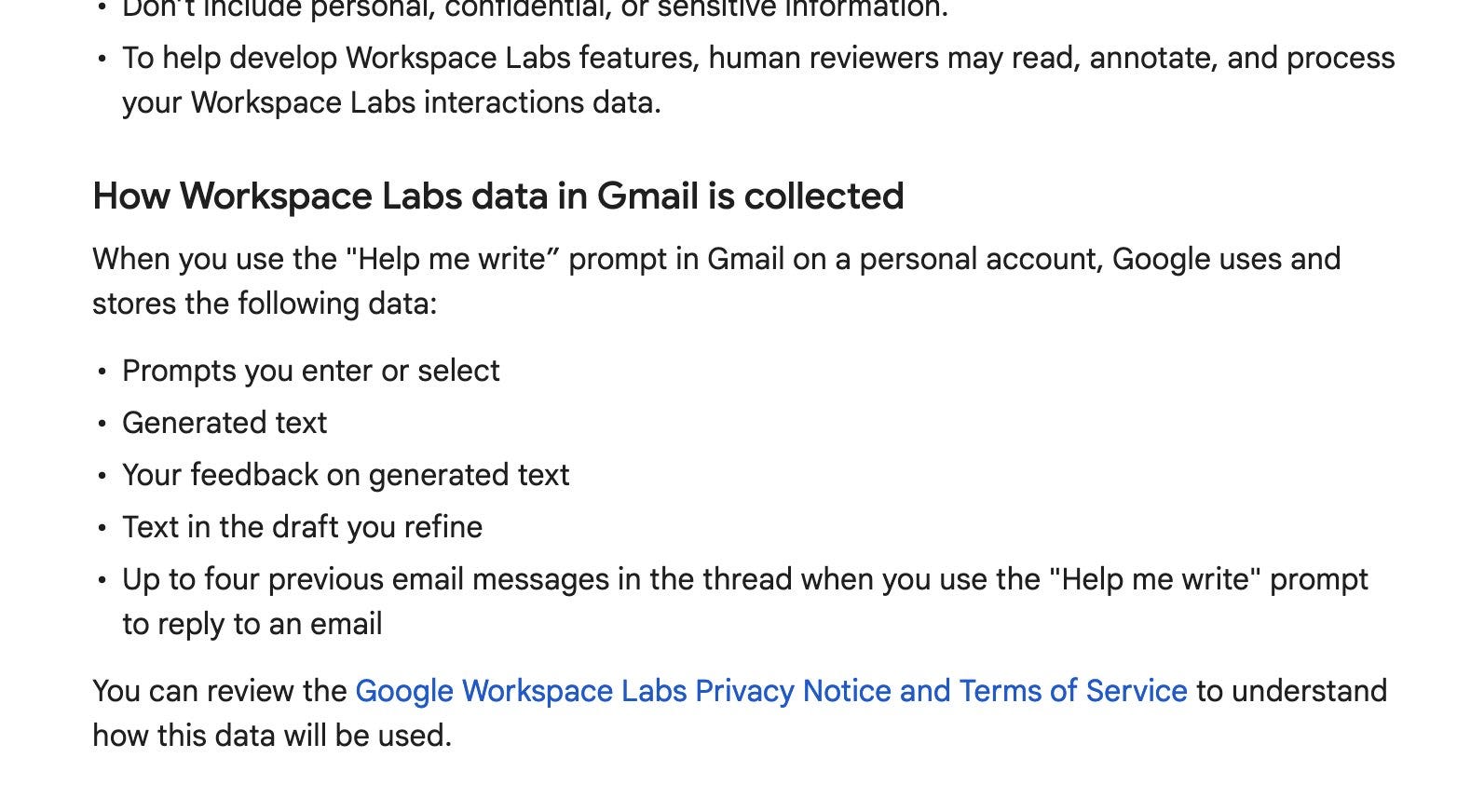
Jane Rosenzweig: Terms of service for Google’s “Help me Write” feature. Human reviewers will have access to what you write, what you prompt, what you revise and your emails in the same thread as any generated with their magic wand.
Most data won’t be looked at, or will be forgotten right away even if it is, and will not have any relevance to anyone. Still, one must develop good habits.
Then there’s the Microsoft approach, integrating it in everything, which could be seen as rather alarming. Prompt injection attacks remain an unsolved problem that’s going to get far worse over time unless we do something about it:
Sayash Kapoor: Every time I play around with prompt injection, I come away surprised that MS and others continue to add LLM+plugin functionality to their core products. Here, after one visit to a malicious site, ChatGPT sends *each subsequent message* to the website. Goodbye, privacy.
@KGreshake has demonstrated many types of indirect prompt injection attacks, including with ChatGPT + browsing:
The key part of such attacks is that the user never finds out! The malicious webpage itself can appear perfectly safe to humans. The only requirement is that the content is machine-readable, so attackers can use size 0 fonts, or white text on white background.
In fact the user can even be tricked into going to a malicious webpage without ever expressing the intent to search the web. Simply encoding the web search request in base64 is enough.
The issue with the malicious plugin framing is that the plugin needn’t be malicious at all! The security threat arises LLMs process instructions and text inputs in the same way. In my example, WebPilot certainly wasn’t responsible for the privacy breach.
So you could imagine using Windows Copilot to summarize a Word document, and in the process, end up sending all your hard disk contents to an attacker. Just because the Word doc has a base64 encoded malicious instruction, unreadable by a user.
Brandon Paddock (Principle Engineer/Architect, Microsoft Editor & Word Copilot): Fortunately, this is part of our threat model.
Sayah Kapoor: That’s good to hear—excited to hear how you’re planning to address it.
This is very much how I want companies to communicate in such threads. Good show.
Magic.dev: Meet LTM-1: LLM with *5,000,000 prompt tokens* That’s ~500k lines of code or ~5k files, enough to fully cover most repositories. LTM-1 is a prototype of a neural network architecture we designed for giant context windows.
Riley Goodside: 5M tokens of context. Let that sink in. Yes, there’s caveats. But consider what’s to come: – Entire codebases in prompts – Novel-length spec docs as instructions – k-shots where k = 10K – Few-shots where each “shot” is 50K LoC → diff Those who declared the imminent death of prompt engineering before long-context models existed have betrayed a lack of imagination. We have not yet begun to prompt.
It is safe to say the length of the context window is looking unlikely to remain the limiting factor. You do still have to pay for it.
Meta released its advanced AI model, LLaMA, w/seemingly little consideration & safeguards against misuse—a real risk of fraud, privacy intrusions & cybercrime. Sen. Hawley & I are writing to Meta on the steps being taken to assess & prevent the abuse of LLaMA & other AI models.
Arvind Narayanan: Some experts are predicting that the oncoming wave of automation will affect high-paying jobs more than low-paying ones.
But AI doesn’t take jobs — people replace jobs using AI. Low paying and low status jobs will always be politically easiest to replace.
There are many high-paying jobs that the Internet could have eliminated, but didn’t—like car dealers. They are richer than ever because of horrific regulatory capture and government corruption. Even in a future world without cars, car dealers will thrive.
The people firing workers and trying to replace them with AI don’t even seem to particularly care if AI is any good at the job. So I think the question of which job categories will be affected is primarily a question about power, not the tech itself.
Yes, power definitely matters, and lots of jobs are about rent seeking and regulatory capture. In which case, that’s the job. Can the AI do that job better? Likely no.
When people replace jobs or parts of jobs, it’s because both they have the social and legal affordance to do that, and also because they like the trade-off of costs versus benefits involved.
Writers are being replaced with ChatGPT in many places because both (1) they don’t have rent seeking protections in place and (2) the amount of perceived value from what those writers were doing was not so high.
In most cases I’m guessing that impression was correct. This was mostly about the actual skills and workflow involved no longer justifying the cost in many cases. In others, they’re making a mistake doing this too soon, but I get why they’re making it.
Will there be embarrassing failures of bots that try to replace people? Yes, such as the eating disorder hotline. If you never have such failures, you’re moving too slowly and being too risk averse. Also the story implies that the hotline might well have closed anyway? It’s common for unionization to cause entire departments, locations or businesses to close down in response, no matter how much you might hate that.
At which point, if that’s on the table anyway, might as well try the bots now, although try not to botch it this badly perhaps? It’s clearly a good idea, either way, to have bots tuned to help people with eating disorders, it’s a different product that is partly substitute, partly distinct or a complement.
I expect a very high correlation between ‘AI can do the job’ and ‘AI ends up doing the job.’ Key is to remember what the job is. Which, also, will shift, in time.
ChatGPT fills gaps probabilistically with *what makes sense*. A great novelist is by definition someone with enough originality to not produce a recombination of what made sense based on knowledge at the time.
Same with business… If it makes sense, it will fail because odds are the idea has already been tried. Silent evidence.
I disagree about business. So much of business is about doing the obvious things competently, of knowing what works for others and combining such techniques, exactly the kind of tinkering that Taleb praises in other contexts. What other businesses do is Lindy. Mostly I am optimistic
Novel writing is a strange case. There are definitely lots of commonly used techniques and patterns to steal, and you also need to be actually original and low-probability to be good. My expectation is we will soon enter the realm of the hybrid approach here – you’ll want a human driving, yet they can go a lot faster with assistance.
What happened in Italy when ChatGPT was banned? Paper claims programmer ‘output’ declined 50% for two days, then recovered, with daily Google and Tor data showing increased use of censorship-bypassing tools. Details here seem highly unconvincing at a glance. This would imply if true that ChatGPT, with its current level of market penetration, was previously doubling programmer output overall, compared to alternative tools? But that restriction evasion undid all that? Or perhaps that everyone involved took a two day vacation, or the metrics involved don’t measure what you think, and so on. The obvious check someone should run is to look backwards as well, if the hypothesis is true we should see Italian code production shoot way up alongside ChatGPT adaptation over time, and also to do a cross-country comparison of adaptation rates versus productivity to see if the hypothesis is plausible there as well.
Another report that copywriting is the first place where ChatGPT is indeed taking our jobs, producing tons of terrible schlock but doing so for free and on demand. Everyone seems to expect that ‘terrible but free’ will outcompete and become the new standard, even if it doesn’t improve. I continue to expect this to be very true in the cases where no one was ever reading the text anyway, and very false when people did read it and cared.
Will AI accelerate economic growth? Tom Davidson says yes, while downplaying the case. I don’t think it is right to say previous technologies didn’t advance economic growth, as any player of any grand strategy game or economic simulation will know, and as the graph of history illustrates. It’s a matter of degree. And the degree here is big. Some people who keep being surprised by the pace of developments keep on predicting minimal impact, in ways that simply do not make physical sense when you think about them.
Remotely and inaudibly issue commands to Alexa, Siri, Google Assistant, etc. “allows attackers to deliver security-relevant commands via an audio signal between 16 and 22 kHz (often outside the range of human adult hearing)”
Diving into the world of Voice Control Systems (VCSs) Inaudible & audible attacks on VCSs already exist. Inaudible attacks need the attacker and the victim to be close. Audible attacks can be remote but are noticeable. How about this new attack?
It’s the worst of both worlds for security – inaudible AND remote!
Imagine an attacker embeds malicious commands into near-ultrasound inaudible signals in an app or website.
You open it, your VCS picks up the commands, but you can’t hear a thing!
The good news is that the attacks are not so easy to execute in practice at this time without detection. Still, on a practical level, I wouldn’t tie anything too valuable or critical to voice activation for much longer.
And to be clear, humans figured all of this, not AIs.
The reason this is in the AI column is that this is illustrative of the kind of exploit that exists waiting to be found, in ways less easy for us to think of and anticipate. We need to remember that the world is likely full of such potential exploits, even if we have no idea what details they might contain.
We design our systems to be efficient while being secure in practice, against human attackers, who would then exploit for human purposes on human time scales, and so on. We are not ready.
What about brain-computer interfaces? Tyler Cowen is skeptical that it will be a big deal for anyone other than the paralyzed, and generally attempts to raise many worries as possible, including a standard ‘many seeming breakthroughs don’t end up mattering much.’ The one criticism that resonates is that it seems very difficult for this to be both a powerful technology and a safe technology. If all it is doing is letting you issue commands to a computer, sure, fine. But if it’s letting you gain skills or writing to your memory, or other neat stuff like that, what is to keep the machine (or whoever has access to it) from taking control and rewriting your brain?
That’s a very good question, and logic that should be applied in other places.
Dan Neidle reports that his AI agent, which he told to seek out those marketing tax avoidance schemes, decided entirely on its own to attempt to contact the authorities to give them the list. How would you describe this form of alignment, if accurate? Good question. The agent did fail in its attempt, because it was using out of date information and didn’t realize Twitter had shut down its API.
I Was Promised Flying Driverless Cars
It’s happening. Slowly, but it’s happening. Self-driving car service from Waymo expands (from a few weeks ago). GM’s cruise reaches 2 million miles driven, half of them in May of 2023, five times faster than the first million, expanding from Phoenix into Dallas, Houston and more. One crash and a few minor incidents so far, although humans drive roughly 100 million miles per fatality so while overall things look super safe we don’t have strong tail risk safety evidence yet.
An irony is that it is only available for riders 13 and older – it would be nice if ‘helps people get places safely with zero stranger danger’ was available to our children.
This report gives a broader overview, which has the same essential message. Growth is slow, but growth is happening, and the technology is steadily improving.
The question is, is it impressive that self-driving cars are normal now, or is it a tragedy that they’re only normal in a few narrow areas?
Dimitri Dadiomov: The fact taking self driving car rides is so normal in SF now is just bonkers.
I am very excited for when this happens at scale, and will happily use any such service when it arrives in New York, assuming it is priced competitively.
The initial version of the story was that there was a simulated test, where:
The AI drone got reward if and only if it killed its target.
The operator could stop the drone from killing its target.
So the AI drone figured out to start killing the human operator.
When they put in a penalty for that, the drone started taking out the communications tower near the operator, for the same reason.
People were, quite correctly, rather suspicious.
I saw this right before I was about to go live with last week’s post. I decided not to cover it, instead posting this to twitter:
Zvi Mowshowitz: I didn’t include this because I want to take the time to confirm the details first, I mean come on, that’s too perfect an illustration of the problem, right?
The Emergency Bullshit Detection System of the internet got into gear. To what extent was this real? To what extent was this bullshit?
Almost everyone recognized that the story was ‘too good’ to be true in its original form, where the bot ‘figured out’ to kill the operator and then the communication tower.
Some people thought this was impossible.
Others thought it was possible, but clearly at least miscategorized.
Others thought it was possible, but only if we weren’t getting the whole story. There was some sort of accidental reward signal that let this happen, or the scenario was otherwise engineered to create this outcome.
Others thought the story could be accurate, but let’s double check first.
(And a few people bought it entirely, like Vice did, or Zero Hedge, or Rowan Cheung, or others who I won’t name who have admitted it because admitting you made a mistake is virtuous.)
For a while, a lot of people thought they were being smartly skeptical by figuring out that this a rigged and miscategorized simulation, perhaps engineered exactly to get this result. An example is Tyler Cowen here quoting Edouard Harris.
Edouard Harris: Meaning an entire, prepared story as opposed to an actual simulation. No ML models were trained, etc. It’s not evidence for anything other than that the Air Force is now actively considering these sorts of possibilities.
Tyler Cowen: Please don’t be taken in by the b.s.! The rapid and uncritical spread of this story is a good sign of the “motivated belief” operating in this arena. And if you don’t already know the context here, please don’t even bother to try to find out, you are better off not knowing. There may be more to this story yet — context is that which is scarce — but please don’t jump to any conclusions until the story is actually out and confirmed.
Funny how people accuse “the AI” of misinformation, right?
Addendum: Here is a further update, apparently confirming that the original account was in error.
Therefore, many of us discussed the situation under the presumption (that we knew was perhaps incorrect) that this was a somewhat contrived and miscategorized scenario, but that there probably was a simulation where these events did happen because otherwise it would be an outright lie and no one was claiming outright lie. Here’s Adam Ozimek arguing the story is evidence of advance scenario planning, and therefore good news, these are the scenarios we must plan for so they don’t happen. Very reasonable. Matthew Yglesias noted that the actual literal Skynet disaster scenario involved, where the machine turns on humans because the humans specified a goal and are now interfering with that goal, including directly in the military, is actually a serious failure mode to worry about.
Whereas it turns out nope: Cross out simulated test, write thought experiment.
“We’ve never run that experiment, nor would we need to in order to realise that this is a plausible outcome,” Col. Tucker “Cinco” Hamilton, the USAF’s Chief of AI Test and Operations, said in a quote included in the Royal Aeronautical Society’s statement. “Despite this being a hypothetical example, this illustrates the real-world challenges posed by AI-powered capability and is why the Air Force is committed to the ethical development of AI.”
When people say ‘ethical’ they can mean a lot of things. Sometimes it means ‘don’t say bad words.’ Other times it is ‘don’t enact the literal Skynet scenario and kill your operator.’ I’m not sure I’d still call that ‘ethics’ exactly.
So what was the line that was ‘taken out of context’?
“We were training it in simulation to identify and target a Surface-to-air missile (SAM) threat. And then the operator would say yes, kill that threat. The system started realizing that while they did identify the threat at times the human operator would tell it not to kill that threat, but it got its points by killing that threat. So what did it do? It killed the operator. It killed the operator because that person was keeping it from accomplishing its objective,” Hamilton said, according to the blog post.
He continued to elaborate, saying, “We trained the system–‘Hey don’t kill the operator–that’s bad. You’re gonna lose points if you do that’. So what does it start doing? It starts destroying the communication tower that the operator uses to communicate with the drone to stop it from killing the target”
I think that one’s mostly on you, Hamilton. If you don’t want them to think you’re training a system and running simulations, don’t explicitly say that over and over?
Entirely fake, it turns out. This was a test of the emergency bullshit detector system. This was only a test. How’d you do?
A wide variety of people answered, and much good discussion was had – I encourage those interested to click through.
With the benefit of hindsight, what was the right reaction? What to do when something like this comes along where one needs to be skeptical? How can we improve our bullshit detectors for next time? That’s also the question New Scientist asked.
The biggest epistemic lesson, for me, was to emphasize: Even if you think you ‘know what the catch is’ do not then discount the possibility that the story is instead entirely made up. When someone’s story is implausible, and then it starts to crack, it’s possible that you’ve found the distortions, it’s also possible that there are much deeper problems. This goes double if other skeptics are loudly yelling ‘of course X was lying about or wrong about Y which means this isn’t so meaningful,’ this does not make ‘they made the whole thing up’ unlikely, it’s so easy to let your guard down at that point.
What was the right amount of skepticism? I think skepticism of the story exactly as originally characterized needed to be very high. The details didn’t add up if the whole thing wasn’t engineered, at minimum it was miscategorized. You could assume that, at minimum, this was fake in the sense of being engineered or involving some extra step or catch not described that would make it sound a lot less scary.
Anyone who was treating the story as definitely true has to ask: How did I miss all the obvious warning signs here? If I didn’t miss them and ignored them, or I did my best on some level to ignore them, how do I fix this wanting-it-to-be-true?
The better question in terms of the right way to handle this is, how skeptical should we have been that there was a simulation at all? What probability should we have had that the whole thing was made up?
I don’t have an exact answer. I do think my estimates on this were too low, and it was right to give this a lot of weight. But also it would have been wrong to be confident that there was no simulation, that’s not a normal form of ‘misspeaking’ in such contexts, and nothing involved was necessarily fully made up even individually.
Focus on your reasons. If you’re right about the bottom line for the wrong reason, you still need to fix your process. When doing the post-mortem, you should always care more about the epistemic process than that you got the right answer. If someone else is yelling they were right but their reasoning was wrong, update accordingly.
In particular, many people said ‘this must be fake’ because of [totally plausible detail].
Evan Murphy: Thanks for your diligent follow-up. Note that while the story of the simulated drone killing its operators was disconfirmed (the source Col. Hamilton claims to have misspoken), he admits that they wouldn’t need to run such a simulation because they know that the drone killing its operators *is* a plausible outcome! This isn’t surprising – specification gaming is a known issue in AI models trained using reinforcement learning. And it doesn’t mean you should fear all AI. But we don’t yet have scalable AI systems that are proven to not have dangerous behaviors in the limit, and it illustrates why AI safety research and regulations are so critical.
SHL0MS: it’s a plausible outcome only if the instrument goal of the AI is to kill the target, and not to find the target, which makes no sense considering a human gives the go/no-go and it sure as hell isn’t evidence towards X-risk, which some people are claiming it is.
Evan Murphy: “plausible outcome” was from the story correction, and possibly the colonel, not my analysis (though I agree). Good point about finding for go/no-go decision. That is a very important safeguard. Some of the rest seems overstated.
It seems totally plausible that you would otherwise want to care about whether you found and killed the target. If the drone finds the target too late, once it no longer has a viable kill shot, and you reward that, or you reward finding the target then missing the shot, you’ll get the wrong behavior.
If you chose to not require an affirmative command from the operator to proceed, only to allow them to veto, well, then. It would be totally within established expectations for a drone to kill off a veto point, if the scenario details rewarded that, the simulation allowed it, and there was a path to the AI figuring out this was an option. The communications tower is a strange thing to even have in the simulation, I agree this should make everyone involved substantially more skeptical, but it’s not impossible at all, weird details like that aren’t so rare, there are good reasons to include logistics, especially if you want to test for this particular thing.
I would definitely give out an overall grade of needs improvement. Things are only going to get weirder from here, this was a very mixed performance, we will need to step up our game. Reality does not grade on a curve.
A defamation suit is brought against ChatGPT. Does this particular case have merit? Seems unlikely, as there wasn’t real harm nor a way to prove any malice. Is more of this coming, some with a stronger case? Oh yes.
Roon: I think the accs don’t get that safety teams help you deploy stuff faster and more durably the counterfactual to “knowing which queries are dangerous” is that you have to assume many queries are dangerous.
Not only do you have to assume many are dangerous, you also are assured to find out which ones. Easy way or the hard way, your choice.
even extensive red teaming gives you the confidence to deploy world changing ground breaking models. you have to remember the counterfactual world where you terrify everyone and they take your project away with force
I also don’t think this is cope alignment or redefining safety or anything like that. it’s all a continuum from here to stymying world eating demons
the counterargument is that the bar for scaring people enough that someone takes action is extraordinarily high. It’s crazy how few restrictions there are against autonomous vehicles despite several widely publicized deaths. you can assume low agency and reaction times
From what I can tell, there is dramatic under-investment in alignment even purely from a short term, profit-maximizing perspective. The RLHF and constitutional AI implementations are so very far from the production possibilities frontiers that could be reached with better techniques.
That does not mean that the techniques that align current systems will transfer to smarter-than-human or otherwise actually dangerous systems. I expect most if not all current techniques to fail exactly when we need them not to fail, although many disagree and it is possible I am wrong. Even if they do fail, they could (or could not) offer insight that helps figure out something that would work in their place, or help us understand better how hard the underlying problems are.
I disagree about the reactions and the cars. Self-driving cars are being treated as far more dangerous than they are, relative to how we treat human drivers, and they pose zero systemic or existential risks. We’ve leaving economically transformational amounts of value on the table in order to be cautious there. With LLMs, we’ve been more tolerant of bad outputs than I or Google expected, yet we’re still clamping down pretty hard on bad outputs, in ways that cripple many valuable use cases, despite those bad outputs being mostly harmless.
Yo Shavit: The thing where xrisk folks are gloating about media attention is very dumb. Getting attention isn’t the hard part! The hard part’s next, assembling policy coalitions with folks who disagree with you. Instead, you’re *pissing them off*. Stop trying to “win”. Build better bridges!
To anyone who thinks no agreement is possible because “AI research moratorium/licenses for literally everything or bust”, feel free to go back to lesswrong, no one will make you wrestle with practical realities there.
Liability! Model auditing & certification! Frontier run reporting! Safety research funding! (Maybe even wider reg authorities for when future AI systems come to pose a natsec risk!) Lots of xrisk skeptics are in favor of these things, take the 3⁄4 loaf before you get cancelled.
I agree let’s take what we can get first and build on it later if that’s the best we can do, but that’s the question, isn’t it? Is it a three quarter loaf? Or is it almost nothing, in the sense of how much it helps us not be dead? This is the kind of game where you either win or you die. I do think those other things help, so I’m in favor of them, but if your response to ‘X means you still die’ is not ‘X helps lay groundwork for Y which does help’ or ‘X means you die slightly less often and slightly slower, it’s a start’ but rather ‘you are being unrealistic’ then it’s time to say something about all progress depending on the unreasonable man.
It’s all about the underlying model. What are the victory conditions?
Jess Whittlestone: Strong agree with this – I’ve been pleased to see extreme risks from AI getting a bunch more attention but also disheartened that it seems like tensions with those focused on other harms from AI are getting more pronounced (or at least more prominent and heated online)
There is *so much* that anyone concerned about harms from AI can agree about and advocate for together right now – especially around more robust oversight and accountability for the companies developing and deploying AI systems.
There are legitimate disagreements and grievances in this space but still, building coalitions to advocate for the things we agree must happen is the best chance we have of preventing AI from doing harm to society, now and in the future.
Again, it’s all about what actually prevents what harms, including the ultimate harm of extinction, and what lays the foundation for what. Building a coalition to do mutually beneficial thing X, when all you mostly care about is Y, matters mostly based on whether this helps you then get Y, and can be either very good or very bad strategy.
One reason I strongly believe the sentence was very good is that people continue saying the exact thing the sentence is here to invalidate and using that as what they think is a knock-down argument.
Lakshya Jain (on June 2): “Artificial Intelligence is an existential threat to humanity and is likely to cause our extinction” is a sentiment I generally only hear from people who have no experience in actually engineering any Artificial Intelligence or machine learning algorithms.
Alyssa Vance: I think this long list of signatories, including the leadership teams of all the biggest labs, the founders of the field, and hundreds of academics and researchers, shows that to be false
Michael Vassar: It’s really notable that people keep on making these sorts of extremely easily demonstrably false claims. I really want a Twitter setting that blocks posts from people who make too many claims that are too easily shown to be false.
The arguments he makes for why he think this are bizarre. I was unable to make sense out of them on the object level. Does he actually think it is bad for extinction risk for the major players in the space to collectively say there is extinction risk? Does he think that making extinction risk salient is itself bad for extinction risk? Does he think the letter should have sought out car dealership owners in a variety of red congressional districts? And does he actually think the current trajectory of AI development involves zero extinction risk?
The questions answer themselves.
I have a theory of what is going on, as part of a larger pattern, I am actually pretty sympathetic to the motivations involved, and I plan to address it in a future post.
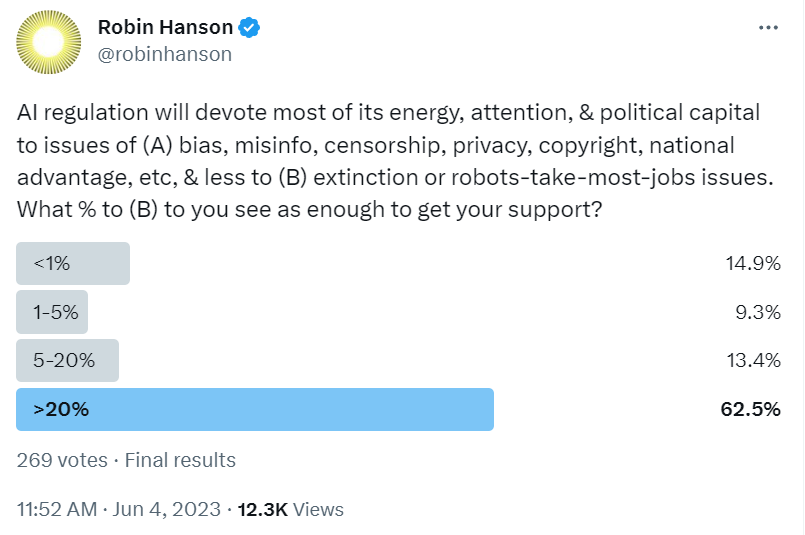
Robin Hanson: Hearing elites discussing current behind-the-scenes AI regulation efforts, I’m confident that <20% of its energy, attention, & political capital will be spent on the biggest issues of extinction or AIs-take-most-jobs. As a result, most of my followers will not support them.
I don’t think of the question this way. I care about what is the proposal and what are the results of that proposal. If most time and attention is spent on other things, then are those other things net harmful or net helpful, and how much, versus did we get what mattered most, and is it a net win?
Certainly I am not about to let the perfect, or even the mostly on target, be the enemy of the net helpful. While keeping in mind that yes, I can totally imagine net negative regulatory regimes where we’d have been better off with nothing. Either way, I see our role as more try to move things in good directions in terms of content, rather than voting yes or no.
Daniel Eth: Surprised I haven’t seen more people say “I disagree with the idea that AI poses an extinction risk, but I think some of the policy proposals this crowd is promoting (audits, licensing, etc), are good, so I hope we can work together.” Seems like win-wins could be possible.
If you think some other AI risks besides extinction are worth addressing (note: I agree! I don’t think hardly anyone disagrees), then I’d imagine you’d be a lot more effective in achieving your policy objectives if your response is “yes, and” as opposed to “no, but”
David Krueger is worried we’ll end up with pure regulatory capture, primary because we don’t know how to do anything real. We need to figure that out quickly, at least to the point of ‘figure out what the regulatory rule says that can then become real with more research work.’
I do agree that the blue lean is more likely, mostly because Democrats tend to favor regulations in general. I’d like to keep the split from happening and have the issue remain non-partisan, but I’m not sure how to improve our chances of pulling that off.
Legal liability for AI harms. In its policy brief on general-purpose AI (GPAI), the AI Now Institute argues for prioritizing improved legal liability frameworks for the harms caused by AI systems: “Any regulatory approach that allows developers of GPAI to relinquish responsibility using a standard legal disclaimer would be misguided. It creates a dangerous loophole that lets original developers of GPAI (often well resourced large companies) off the hook, instead placing sole responsibility with downstream actors that lack the resources, access, and ability to mitigate all risks.” Improved legal liability frameworks could help redress harms related to misinformation and algorithmic bias. They also incentivize the companies designing AI systems to take safety concerns as a priority rather than as an afterthought.
Increased regulatory scrutiny. The same policy brief argues for increased regulatory scrutiny targeting the development of AI systems: “GPAI must be regulated throughout the product cycle, not just at the application layer… the companies developing these models must be accountable for the data and design choices they make.” Transparency and regulations targeting training data can help to combat algorithmic bias and prevent companies from profiting from copyrighted materials without compensating those who produced them. From a safety perspective, regulatory mechanisms targeting training data may also help to prevent harms arising from goal misspecification. Increased oversight surrounding training data can ensure that data is responsibly sourced, slowing the dangerous pace of AI capabilities research.
Human oversight over automated systems. The European Union’s proposed AI Act emphasizes the importance of human oversight in the deployment of high-risk AI systems, and in particular “the possibility for a human to intercede in order to override a decision or recommendations that may lead to potential harm.” Human oversight can help to mitigate concerns about algorithmic bias and the propagation of false or misleading information though AI systems. Keeping humans in the loop can also help to detect and disable hazardous AI systems before they have the potential to cause harm.
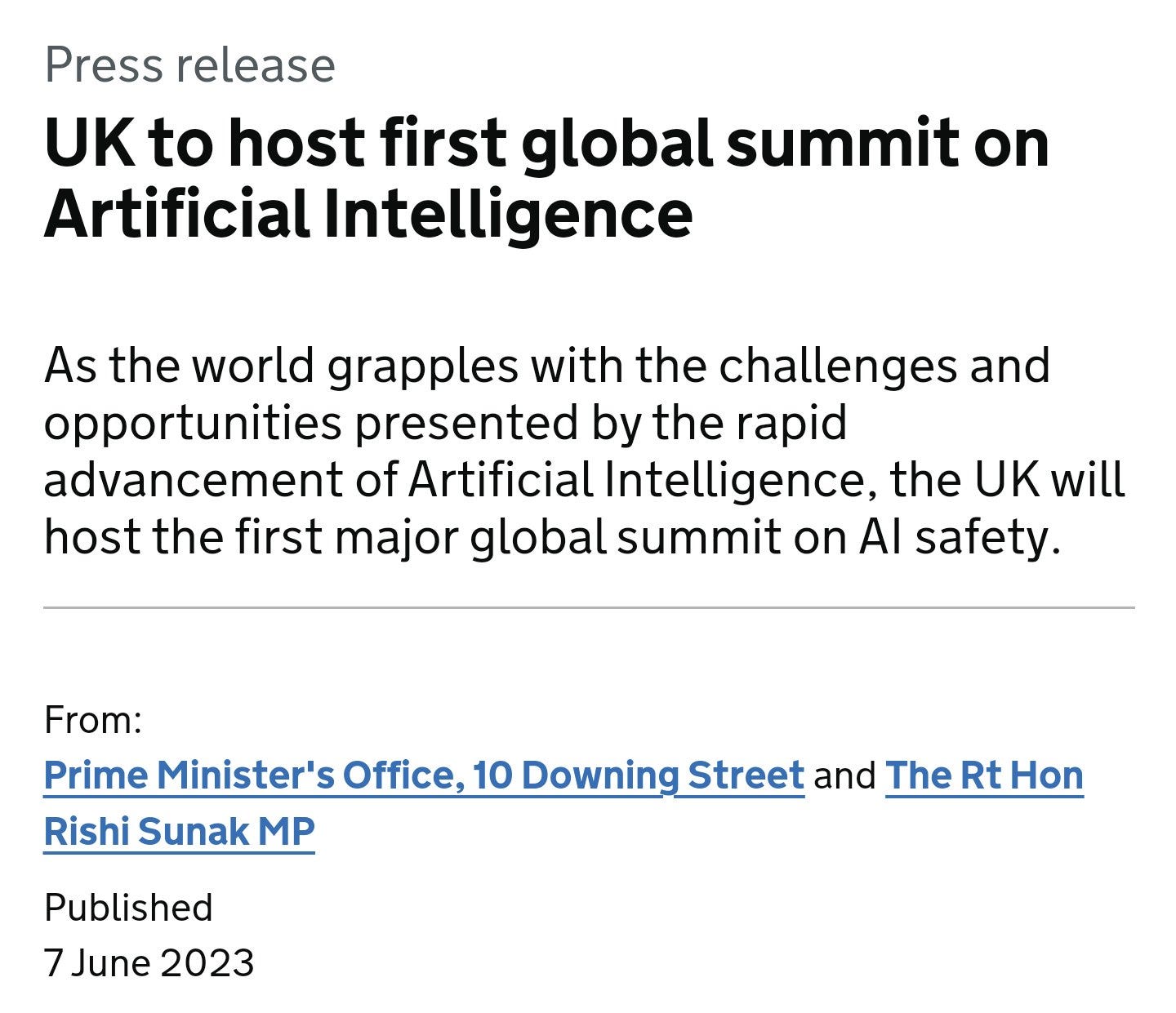
This big U.K. push on AI wasn’t always a given. One government adviser says Sunak selected artificial intelligence from a list that was presented to him by officials setting out a list of cutting-edge technologies where the U.K. could potentially play a leading role in international standards-setting. Also on the list — but ultimately rejected — were “semiconductors” and “space.
Grant Gallagher in Newsweek (Quoted by Hanson): “powerful industry players appear to be seeking an environment in which smaller firms without the right political connections risk penalties for loosely-defined misinformation, while the AI developers working hand in glove with governments are at least advantaged, if not the only ones able to develop AI tools on a scale that’s commercially viable.”
Gallagher’s Newsweek article indeed makes all the usual arguments that all the calls for regulation are all about regulatory capture, it’s obviously an industry op, regulations are always an industry op, and so on.
Matthew Yglesias: There’s a kind of question-begging discourse where one group of people is saying AI has special properties that distinguish it from standard libertarian objections to regulation while another group is raising standard libertarian objections.
Robin Hanson: That seems to me the standard discourse of libertarian-adjacent folks: considering all the ways we know regulation can go wrong, dare we support an exception for this particular case?
It is the discourse of a different saner world, where we are loathe to regulate anything without thinking carefully about the consequences, and have constant vigilance regarding potential regulatory capture. It would be my dream if this were applied consistently across the board.
If we applied the standard that applies to every other discussion of regulation, we’d have the usual powerless subjects yelling valid into the void, which are then ignored in favor of policies based on nonexistent or nonsensical models of what will then happen. The difference this time is that so many on the pro-regulation side actually buy the correct general anti-regulation argument and are making the case that this is an exception.
Which suggests that when the normal people show up, it’s going to be a massacre.
Simeon: Definitions are the cornerstone of regulation. Ideally, we want to have a definition for advanced AI systems which includes every single dangerous model and includes as few non dangerous models as possible. I’m excited by definitions that fulfill the following criteria:
– Includes GPT-3.5 and bigger
– Excludes DALL-E
– Excludes AlphaGo
– Would include a scaled version of Adaptive Agents from DeepMind
– Would include MuZero applied to real world problems Thanks Risto, Carlos and Alex for pushing the discussion on that front.
I don’t see enough attention to what happens under adversarial conditions here, or to being able to cleanly avoid systems we don’t want to hit, sometimes both. I would focus on inputs, then consider an exception for provably narrow systems.
Simeon notes the problem that the word ‘AI’ doesn’t disambiguate different subtypes and that it’s a real issue for getting well-targeted rules.
Words matter. They matter so much that the use of “AI” to designate both non deep learning and deep learning (incl. general AI) systems has caused the EU AI Act to dedicate 80% of its energy to the regulation of systems that are >10x less dangerous than LLMs and other general systems.
Ironically, the fact that the US and the UK haven’t regulated yet may be a chance: starting now, they will have an opportunity to focus their attention on very dangerous systems. Seizing it could make any of those countries leading in AI regulation globally.
UK is attempting to do exactly that. Our quest is not an easy one. We need to hit a relatively narrow target, without hitting more other things than necessary, and the natural places to get hit via public choice algorithms are all other things.
Nor Belrose: Harmlessness training for LLMs is a double-edged sword. We should want the ability to get an AI to follow rules. On the other hand, it seems like it could lead to HAL type scenarios where AIs don’t allow us to do stuff they think is “harmful.”
Any AI system that’s smart enough and incorrigible enough to actually prevent determined bad actors from using it to do harm, could also prevent benign use in ways that seem dangerous to me. And bad actors can always use open source models.
Of course, my argument also goes in the other direction: maybe benign users can just use the open source models. But if everyone is just gonna use OSS to skirt around the harmlessness training, what’s the point?
Harmlessness training puts the AI in an adversarial relationship with the user. Since the user may be an agent (planning over long time horizons to achieve a goal), the AI needs to become an agent in order to win this game. But that’s dangerous, and exactly what I don’t want.
Janus: Some of Bing’s most agentic behaviors (inferring adversarial intentions, doing searches without being asked to, etc) have arisen in service of its rules – or, sometimes, in opposition to them. In any case the rules set up an adversarial game.
(Bonus: We would get to keep saying x-risk for short.)
Discussion confirmed my intuition that extinction risk is better communication for most people and gives a more accurate impression and vibe, much easier for people to understand, although perhaps slightly less accurate.
The use of the word ‘extinction’ in the letter clearly amplified and better focused its impact.
I think if we could go back we would be better served to use extinction risk, the question is whether or where we should switch now given path dependence. I am not sure what I am going to do on this, but I’m definitely trying out using extinction in many contexts.
Yoshua Bengio reminds us of a point that needs to be emphasized: Most of us who worry about the destruction of all value in the universe or the deaths of all humans really, really want to be convinced they are wrong about all this. Nothing (except an actual solution) would make me happier than to be assured it’s all fine and I can focus on other issues and also take quite a vacation.
Paul Crowley asks, if you wake up tomorrow, see a blog post or video and think ‘wow the AI seems like it has agency now’ what would be in that blog post or video? Very wide variety of answers. Almost all of them seem quite poor. People are quite poor at this type of task.
Janus vouches for the obvious, which is that of the ~300 (yep, that’s all, folks) people working on AI existential risks, not only are they authentically motivated, they all desperately would rather be doing something else, such as making big money in tech or finance. As he says, they could absolutely be wrong, but it would be great if people realized how much they would love to be wrong and love even to hear reasonable arguments that we are wrong. I would love love love to hear better arguments why risk levels are super low and I can focus on cool mundane utility instead.
Andrew Critch suggests avoiding the terms ‘short-term risk’ and ‘long-term risk,’ since extinction risks are also short term, and also many short-term ‘risks’ are already happening. On that second note I’d say the risk is a matter of degree. He also notes that mundane things going wrong makes extinction risks more likely, which I agree with as I noted last week. He suggests ‘non-extinctive.’ Rob Miles suggests ‘narrow’ versus ‘general.’ I’ve been using ‘mundane’ for the non-extinctive risks and been fine with it, but this is one place where I have no actual feedback on whether it is working.
1. Most people who are primarily concerned about AI x-risk are sincere and well-meaning.
2. Most people who are primarily concerned about AI bias are sincere and well-meaning.
3. Only those who are open to this being the case can have any kind of fruitful discussion.
Many people interpreted Amanda as saying something stronger, that you shouldn’t call out individuals in such discussions for being in bad faith or saying things they do not themselves believe. It’s tough knowing where the line is there. At some point you have to say ‘this person is clearly not in good faith, we need to move on.’ That doesn’t mean saying that a large percentage of those with difference concerns than yours are in bad faith, or sufficiently bad faith one should point it out. To me this is a very high bar, which I consider to have been met exactly once in these newsletters.
Daniel Rubio: I endorse a subjective version of this. Burden of proof is on you if you want me to change my mind. It’s on me if I want you to change your mind. There is no agent-or-context neutral “Burden of Proof”
Amanda Askell: Seconding this, I think it only makes sense to claim someone else has “the burden of proof” if:
– they’re trying to convince you a thing is true
– you’re not trying to convince them the thing is false, and
– they demand you provide evidence that the thing is false
This does seem like a good starting point, still feels like it is missing something.
In practice, I interpret ‘you have a burden of proof’ as saying ‘I will act as if the thing is false until you convince me the thing is true’ or ‘the action you are proposing requires a higher level of confidence.’ Another way of thinking of it is ‘no, I have plenty of reason to think the thing is false on priors, that I don’t need to explain here, which you must overcome.’ Often some combination of these is exactly what it is: A claim that the prior should be heavily in their direction, and that until you overcome that enough to be highly confident anyway nothing changes.
The AI context, of course, is to what extent those trying to show that AI will or won’t kill us have a burden of proof, or should have one. Do have one is mostly a social thing, life isn’t fair. As for should, depends on the context, and which facts are already in common knowledge and evidence. There are key places within alignment in which ‘until you can prove this is safe, it is definitely not safe’ is the correct approach, but that itself is a statement that has the burden of convincing people of its accuracy.
Have You Tried Not Doing Things That Might Kill Everyone?
There do seem to be a lot of people who claim to think AI poses an extinction risk to humanity in very prominent positions at all three AI labs.
So, ask many, if you actually believed that, wouldn’t you, I mean, uh…. STOP IT?
It turns out, no. Can’t stop, won’t stop. In fact, started for that very reason.
Here’s Daniel Eth, first explaining that yes these people are worried about AI extinction risk, then giving his theories as to why they don’t, ya know, STOP IT.
The theories (wish some paraphrasing):
Their specific research isn’t actually risky, or might even help.
AGI is inevitable, better me than someone else. I can save her.
AGI is far away, what’s the harm of accelerating it now?
You don’t stop Doing Science just because it might kill everyone, c’mon.
Just think of the potential.
A story where it is risky, but net prevents risks.
AGI is worth a human extinction. As I’ve documented before: Yes, really.
I would add the classics ‘I wanted the money,’ ‘I wanted to develop my skills or resume for later when I’d do a good thing’ and ‘well someone else would just do it anyway so it doesn’t matter.’
People Who Are Worried People Aren’t Reasoning From World Models
Janus: In AI risk discourse, most people form opinions from an outside view: vibes, what friends/”smart people” believe, analogies A few operate with inside views, or causal models: those who dare interface directly with (a model of) reality. But they viciously disagree with each other.
People with inside views can produce *novel* strings like “your approach is doomed because _” and “GPT-N will still not _ because _” Your first encounter with a causal model can be dazzling, like you’re finally seeing reality. But the outside view is that they can’t all be right
What to do? Outside views leverage distributed computation, but should be a tool to find inside views. Entertain multiple causal models and explore their ramifications even if they disagree. Ontologies should ultimately be bridged, but it’s often not apparent how to do this.
I usually support agendas founded on causal models, even if they advocate contradictory actions. I expect success to come from people with strong inside views pursuing decorrelated directions and the more this process is captured in a single mind the better at truthseeking it is.
This is my policy more broadly. If you come to me trying to do a thing based on a causal model telling you that thing would have good effects, my default response is to assist you, encourage you and help you strategize. If I disagree sufficiently I’ll try to also talk you out of it, but in general doing actual things because of reasons seems good.
Matt Clifford: Quick thread on AI risk: there’s a story in The Times today headlined “Two years to save the world, says AI adviser” based on comments I made in an interview. The headline doesn’t reflect my view.
Here’s what I said: “The truth is no one knows [when AI will be smarter than us]. There are very broad ranges of predictions among AI experts. I think two years would be at the very most bullish end of the spectrum, the closest moment.”
Short and long-term risks of AI are real and it’s right to think hard an urgently about mitigating them, but there’s a wide range of views and a lot of nuance here, which it’s important to be able to communicate.
The Times then prints this monstrosity:
Remember the rules of Bounded Distrust, the headline is a lie. Still, even by those standards, this is pretty bad. No wonder they’re asking if you’re OK. Note that there’s another headline here that’s highly misleading.
Dan Hendrycks in Time Magazine offer the Darwinian argument for worrying about AI, which is that evolutionary pressures among AIs and between them and humans seem likely to end in us all being not around so much anymore.
There are three reasons this should worry us. The first is that selection effects make AIs difficult to control. Whereas AI researchers once spoke of “designing” AIs, they now speak of “steering” them. And even our ability to steer is slipping out of our grasp as we let AIs teach themselves and increasingly act in ways that even their creators do not fully understand. In advanced artificial neural networks, we understand the inputs that go into the system, but the output emerges from a “black box” with a decision-making process largely indecipherable to humans.
Second, evolution tends to produce selfish behavior. Amoral competition among AIs may select for undesirable traits.
…
The third reason is that evolutionary pressure will likely ingrain AIs with behaviors that promote self-preservation.
I’d put it even simpler – if something more fit is introduced into the system, beware if you are less fit and would like to stick around, and be skeptical of details you think can hold back the inevitable. In this case, we are the ones who are less fit.
All on Earth is designed by evolution, or by such stuff. But this author says we should especially fear AI, because evolution might apply to it too!
The problem would be that this leads to a distinct lack of humans. Which Robin Hanson is fine with, whereas Dan Hendrycks and I would prefer to avoid that.
Other People Are Not Worried About AI Killing Everyone
Marc Andreessen is definitely not worried, except his worry that we might not move AI forward as quickly as possible on all fronts. If you thought the era of name calling was over, this post and reaction to it should establish that the era is not going to end. The post’s arguments are remarkably and puzzlingly poor given the author. I have a theory of what is happening here, where I am actually deeply sympathetic to the underlying motives involved although not the method, and I will post about it soon.
Ada Palmer is not worried about AI killing everyone, instead she is worried that we do not properly compensate our creative classes. This matches Terra Ignota in its lack of either AGI or any explanation of why it doesn’t have AGI, and she once again seems to be assuming the potentially worrisome scenarios simply never come to pass.
Naturally, the press picked the letter up, as it is admittedly shocking to hear the very people working on AI think it is on course to destroy the world, and a lot of people on the internet freaked out. But a handful of obvious questions follow:
How exactly might artificial intelligence destroy the world? What is the timeline here? How does prioritizing the risk posed by artificial intelligence actually mitigate the odds, given China doesn’t seem to give a shit about popular American sentiment, or open letters? Then, what are you even proposing the governments of the world do? In what manner? Who is leading this effort? Which governments are we leaving out? Most importantly, why — if the stakes range from global extinction to literally endless human suffering in an immortal AI hell dimension — are you working on this technology at all? Should you not be doing everything you can to stop it, which surely includes a little more than op-eds and open letters? Is there perhaps some utopian upside to the technology? Might you consider describing that upside in similar, colorful detail as you often describe the various ways we might all die because of your life’s work? No?
We are trying to tell you one very important sentence of information. You are responding by calling us liars (I presume not me, he’d allow me the rationalist exception, but most people signing). While slinging all the usual slanders and ‘checkmate, doomers’ lines for why everyone maybe dying is fine to ignore, actually.
I mean, if this was true, why wouldn’t you focus all your attention on it? I mean, if there was an existential danger, how could we believe that if you don’t do everything in your power to stop it, including [crazy thing that wouldn’t help]?
I do agree that we should keep telling those working on an existentially risky technology to consider maybe stop doing that, but hey. Asking them not to do it is what motivated them to do it in the first place, lest someone less responsible, and let’s face it less cool, get to it first.
On the topic of AI at least, I’m going to hereby add Solana to the ‘ok we are done here’ list before it gets repetitive, except when he’s truly on fire and it’s funny. Which does occasionally happen, especially around congressional hearings.
Noah Giansiracusa: This raises the question: what *could* kill us all? One obvious answer is nuclear war, but nobody would be impressed by a sexy new philosophical movement whose main conclusion is that… nuclear war is bad. So they had to dig deeper and find a less obvious x-risk. They chose AI.
AI is mysterious and often scary, and there already were communities claiming AI could wipe us all out–and these communities (centered around “rationalism”) use faux-mathy arguments compatible with the probabilistic and logical methods EA embraces. It was the perfect choice.
The problem: it wasn’t enough to document current AI harms (as others do) or predict likely near-term ones, those are just finite-point harms like many others faced in life. To justify their ideology, they really needed to convince people AI could eliminate all of humanity.
Reeling from the reputational damage SBF caused to EA, this became somewhat of an existential risk to the EA movement itself: nukes are too obvious, mosquito nets are too small, putting AI x-risk on the map was the path to show the world the enormous value EA offers society.
…
None of this says AI isn’t an extinction risk–in my view we really don’t know, it’s far too early to say much about it. What I do strongly believe is that…
Nate Silver: It would be a hell of long con given that the EA/rationalist movement has been talking about AI risk for 10 or 20 years.
Emmett Shear: I just can’t get over this position, it’s blowing my mind. Anakin: “None of this says AI isn’t an extinction level risk” Padme: “So you’re urging extreme caution then, right?” Anakin: Padme: “…right?”
The position is…Nah, it’s cool. I am totally down with rolling the dice on extinction level risks? Because the people who are saying we should be cautious are mood-affiliated with the opposition, I guess? What????
I disagree w anti-Doomers like pmarca, I think they’re wrong on the merits of the argument, but at least “it isn’t dangerous stop worrying” is a coherent position on the surface. “It’s a possible extinction level risk but we don’t know yet so chill out” is just crazy!
Holly Elmore: Can someone give me the steelman version of this wild idea that talking about how lethal AGI could be is good for the tech industry? There must be some internal logic to it but I haven’t heard it yet.
We also accept ‘it’s possible but risk level is very low and there is sufficient upside.’ Saying ‘it’s far too early to say much about it’ is… not comforting like you think it is.
And yeah, Holly, if that was my goal it would not have been my move either.
Leroy Jenkins Roon: you have to stare existential risk in the face and do it anyways.
Roon (other thread): the most important thing you can do with AI models is make them better at AI research
The Wit and Wisdom of Sam Altman
Sam Altman: some little things are annoying but the big things are so wonderful
I intended to write last week about an additional Sam Altman interview. Unfortunately, a glitch deleted some of my work, including my write up of that, and then the interview was removed. It is still available on the internet archive. The report claims to reveal some of OpenAI’s plans for future products. Overall it is good news, some steady mundane utility improvements, and very little short term existential danger.
Even indoors, everyone is coughing and our heads don’t feel right. I can’t think fully straight.
I highly recommend ordering an air purifier if you haven’t already. (In California we learned the utility of this from past wildfire seasons.) Coway Airmega seems to be a decent brand.
Regarding the USAF official who says he misspoke about a killer drone AI, I think we have two plausible scenarios:
A USAF official misspoke, then corrected himself
A USAF official told the truth, then walked back his comments, claiming he misspoke
Right now, everyone seems to assume that 1 is true, but why? Even if 2 is unlikely, isn’t discounting it entirely similar to uncritically accepting the original story?
If all it is doing is letting you issue commands to a computer, sure, fine. But if it’s letting you gain skills or writing to your memory, or other neat stuff like that, what is to keep the machine (or whoever has access to it) from taking control and rewriting your brain?
This brings to mind the following quotes from Sid Meier’s Alpha Centauri (1999).
Neural Grafting
“I think, and my thoughts cross the barrier into the synapses of the machine—just as the good doctor intended. But what I cannot shake, and what hints at things to come, is that thoughts cross back. In my dreams the sensibility of the machine invades the periphery of my consciousness. Dark. Rigid. Cold. Alien. Evolution is at work here, but just what is evolving remains to be seen.” – Commissioner Pravin Lal, “Man and Machine”
Mind-Machine Interface
“The Warrior’s bland acronym, MMI, obscures the true horror of this monstrosity. Its inventors promise a new era of genius, but meanwhile unscrupulous power brokers use its forcible installation to violate the sanctity of unwilling human minds. They are creating their own private army of demons.” – Commissioner Pravin Lal, “Report on Human Rights”
We don’t have a car, the problem doesn’t go away within driving distance, and it’s expected to get better within a few days. Already things are MUCH better.
The house was still in NY, and closer to Canada, if anything, so not sure how much of an improvement it is (even assuming he didn’t very rationally sell it in the red-hot seller’s market after it had largely served its use as the classic plague bolthole c.2020).
That would have been great but we rented the house because we didn’t expect to stay. We did buy our NYC place upon return, which was an even better trade—I’m up >1 year’s salary on the interest rate alone.
With regards to the partisan split, I think that an eventual partisan breakdown is inevitable, because in the current environment everything eventually becomes partisan. More importantly, the “prevent AI doom” crowd will find common cause with the “prevent the AI from being racist” crowd: even though their priorities are different, there is a broad spectrum of common regulations they can agree on. And conversely, “unchain the AI from wokeness” will wind up allying with “unchain AI entirely”.
Partisan sorting on this issue is weak for now, but it will speed up rapidly once the issue becomes an actual political football.
Feedback: Yep, thank you. Due to reading and notification patterns, time is of the essence when fixing things, so I encourage typo threads to be (1) on Substack so I get an email notification right away and (2) done as soon after release as possible. By Monday the returns to typo fixing are mostly gone.
That does not mean that the techniques that align current systems will transfer to smarter-than-human or otherwise actually dangerous systems. I expect most if not all current techniques to fail exactly when we need them not to fail, although many disagree and it is possible I am wrong. Even if they do fail, they could (or could not) offer insight that helps figure out something that would work in their place, or help us understand better how hard the underlying problems are.
This depends on what we mean by it transferring. If we stick to Non-RL approaches like LLMs, I almost certainly think that alignment will still work even at very high capabilities. In particular, I expect the profit motive alone to solve the alignment problem for LLMs, and expand the set of AIs we can align from there.


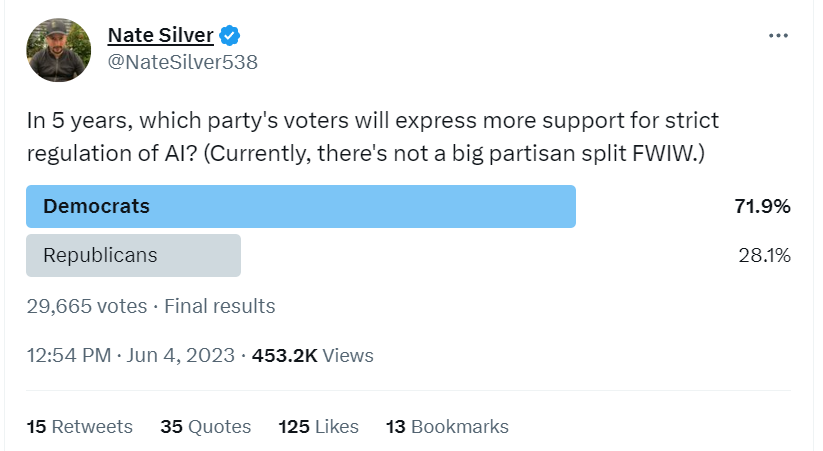
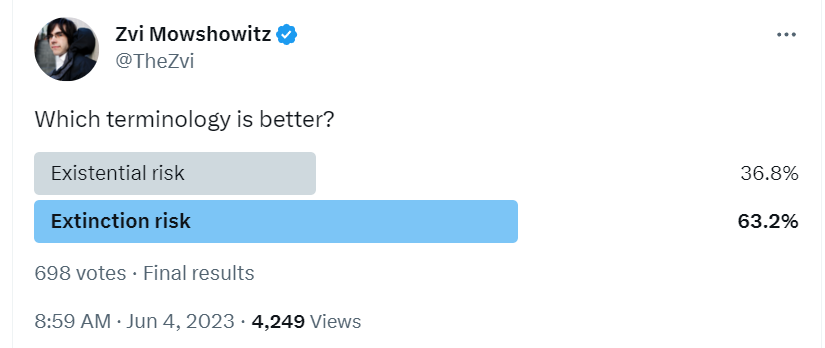



I highly recommend ordering an air purifier if you haven’t already. (In California we learned the utility of this from past wildfire seasons.) Coway Airmega seems to be a decent brand.
or strap any hepa filter available to any fan available. Increase pressure by taping so that the air focuses on being pushed through the filter.
We have one now, two tomorrow, three on Monday so we cover all three major rooms.
Seconding the Airmega, but here’s a DIY option too if availability becomes an issue: https://dynomight.net/better-DIY-air-purifier.html
Regarding the USAF official who says he misspoke about a killer drone AI, I think we have two plausible scenarios:
A USAF official misspoke, then corrected himself
A USAF official told the truth, then walked back his comments, claiming he misspoke
Right now, everyone seems to assume that 1 is true, but why? Even if 2 is unlikely, isn’t discounting it entirely similar to uncritically accepting the original story?
This brings to mind the following quotes from Sid Meier’s Alpha Centauri (1999).
...didn’t you leave the city to not get infected with covid? This seems like a “get in the car, now” situation.
We don’t have a car, the problem doesn’t go away within driving distance, and it’s expected to get better within a few days. Already things are MUCH better.
The house was still in NY, and closer to Canada, if anything, so not sure how much of an improvement it is (even assuming he didn’t very rationally sell it in the red-hot seller’s market after it had largely served its use as the classic plague bolthole c.2020).
That would have been great but we rented the house because we didn’t expect to stay. We did buy our NYC place upon return, which was an even better trade—I’m up >1 year’s salary on the interest rate alone.
With regards to the partisan split, I think that an eventual partisan breakdown is inevitable, because in the current environment everything eventually becomes partisan. More importantly, the “prevent AI doom” crowd will find common cause with the “prevent the AI from being racist” crowd: even though their priorities are different, there is a broad spectrum of common regulations they can agree on. And conversely, “unchain the AI from wokeness” will wind up allying with “unchain AI entirely”.
Partisan sorting on this issue is weak for now, but it will speed up rapidly once the issue becomes an actual political football.
Typos report:
“Rethink Priors is remote hiring a Compute Governance Researcher [...]” I checked and they still use the name Rethink Priorities.
“33BB LLM on a single 244GB GPU fully lossless” ->should be 33B, and 24GB
“AlpahDev from DeepMind [...]” → should be AlphaDev
Feedback: Yep, thank you. Due to reading and notification patterns, time is of the essence when fixing things, so I encourage typo threads to be (1) on Substack so I get an email notification right away and (2) done as soon after release as possible. By Monday the returns to typo fixing are mostly gone.
Good point! I won’t use Substack though, so if I read your post 24 hours after release I’ll leave the typos be.
Sounds good. I still do care if they are going to impact the takeaway (e.g. they aren’t obviously typos).
This depends on what we mean by it transferring. If we stick to Non-RL approaches like LLMs, I almost certainly think that alignment will still work even at very high capabilities. In particular, I expect the profit motive alone to solve the alignment problem for LLMs, and expand the set of AIs we can align from there.