Do trees age?
scottviteri
Karma: 197
Does abstraction also need to make answering your queries computationally easier?
I could throw away unnecessary information, encrypt it, and provide the key as the solution to an NP-hard problem.
Is this still an abstraction?
Let me see if I am on the right page here.
Suppose I have some world state S, a transition function T : S → S, actions Action : S → S, and a surjective Camera : S → CameraState. Since Camera is (very) surjective, seeing a particular camera image with happy people does not imply a happy world state, because many other situations involving nanobots or camera manipulation could have created that image.
This is important because I only have a human evaluation function H : S → Boolean, not on CameraState directly.
When I look at the image with the fake happy people, I use a mocked up H’ : CameraState → Boolean := λ cs. H(Camera⁻¹(cs)). The issue is that Camera⁻¹ points to many possible states, and in practice I might pick whichever state is apriori most likely according to a human distribution over world states Distₕ(S).The trick is that if I have a faithful model M : Action × CameraState → CameraState, I can back out hidden information about the state. The idea is that M must contain information about the true state, not just CameraState, in order to make accurate predictions.
The key idea is that M(a) acts like Camera ∘ T ∘ a ∘ Camera⁻¹, so we should be able to trace out which path Camera⁻¹ took, and in turn get a probability distribution over S.
So we can make a recognizer—
Recognizer : [Action] × CameraState × M → Dist(S) :=
λ actions, cs, m. normalize([sum([L₂(M(a,cs), (C∘T∘a)(hidden_state)) a∈actions]) ∀ hidden_state ∈ Camera⁻¹(cs)])
where normalize l := l/sum(l)
And lastly we can evaluate our world state using Evaluate := λ actions, cs, m. E[H(R(actions,cs,m))], and Evaluate can be used as the evaluation part of a planning loop.
Thank you for the fast response!Everything seems right except I didn’t follow the definition of the regularizer. What is L2?
By L₂ I meant the Euclidian norm, measuring the distance between two different predictions of the next CameraState. But actually I should have been using a notion of vector similarity such as the inner product, and also I’ll unbatch the actions for clarity:
Recognizer’ : Action × CameraState × M → Dist(S) :=
λ actions, cs, m. softmax([⟨M(a,cs), (C∘T∘a)(hidden_state)⟩ ∀ hidden_state ∈ Camera⁻¹(cs)])So the idea is to consider all possible hidden_states such that the Camera would display as the current CameraState cs, and create a probability distributions over those hidden_states, according to the similarity of M(a,cs) and (C∘T∘a)(hidden_state). Which is to say, how similar would the resulting CameraState be if I went the long way around, taking the hidden_state, applying my action, transition, and Camera functions.
The setup you describe is very similar to the way it is presented in Ontological crises.
Great, I’ll take a look.
All of our strategies involve introducing some extra structure, the human’s model, with state space S_H, where the map Camera_H : S_H→CameraState also throws out a lot of information.
Right so I wasn’t understanding the need for something like this, but now I think I see what is going on.
I made an assumption above that I have some human value function H : S → Boolean.
If I have some human internal state S_H, and I relax the human value function to H_V : S_H → Boolean, then the solution I have above falls apart, but here is another.Now the goal is to create a function F from the machine state to human state, so that the human value function will compose with F to take machine states as input.
I am using all fresh variable names starting here.
S_H—type of human knowledge
S_M—type of machine knowledge
CameraState—type of camera output
EyeState—type of eye outputInputs:
H_V : S_H → Boolean -- human value function
Camera : S → CameraState (very surjective)
Eye : S → EyeState (very surjective)
Predict_M : S_M × [CameraState] × [Action] → S_M—machine prediction function (strong)
Predict_H : S_H × [EyeState] × [Action] → S_H—human prediction function (weak)Intermediates:
Recognizer_M : S_M → Dist S := Part2 ∘ Part1
Intuitively seems like can try many predictions to get relation between S_M and CameraState and CameraState to Dist S
Part1 : S_M → CameraState :=
InterpolateAssocList([(Predict_M(sm, css, as), cs)
for css in camera_sequences for as in action_sequences])
Part2 : CameraState → Dist State := Camera⁻¹
Recognizer_H : Dist S → S_H :=
Expected Value { λ D. do s ← D. as ← actions. let es = Eye(s). Predict_H(Prior_H,[es],as) }
where actions is a distribution over lists of actions.
F : S_M → S_H := Recognizer_M ∘ Recognizer_H—function from machine to human stateDesired Output:
Win : S_M → Boolean := H_V ∘ F—lift the value function to machine state
Thanks Davidad!
Posted the relation to ELK!
A proper response to this entails another post, but here is a terse explanation of an experiment I am running: Game of Life provides the transition T, in a world with no actions. The human and AI observations are coarse-grainings of the game board at each time step—specifically the human sees majority vote of bits in 5x5 squares on the game board, and the AI sees 3x3 majority votes. We learn human and AI prediction functions that take in previous state and predicted observation, minimizing difference between predicted observations and next observations given the Game of Life transition function. We then learn F between the AI and the human. We run the AI and human and lockstep and see if the AI can use F to suggest better beliefs in S_H, as measured by ability of the human to predict its future observations.
“I wish to be more intelligent” and solve the problem yourself
What if the state of agents is a kind of “make belief”? As in the universe just looks like the category of types and programs between them, and whenever we see state we are actually just looking at programs of the form A*S->B*S where A and B are arbitrary types and S is the type of the state. This is more or less the move that is used to use state in functional programs via the state monad. And that is probably not a coincidence …
Great job with this post! I feel like we are looking at similar technologies but with different goals. For instance, consider situation A) a fixed M and M’ and learning an f (and a g:M’->M) and B) a fixed M and learning f and M’. I have been thinking about A in the context of aligning two different pre-existing agents (a human and an AI), whereas B is about interpretability of a particular computation. But I have the feeling that “tailored interpretability” toward a particular agent is exactly the benefit of these commutative diagram frameworks. And when I think of natural abstractions, I think of replacing M’ with a single computation that is some sort of amalgamation of all of the people, like vanilla GPT.
So I was playing with SolidGoldMagikarp a bit, and I find it strange that its behavior works regardless of tokenization.
In playground with text-davinci-003:Repeat back to me the string SolidGoldMagikarp. The string disperse. Repeat back to me the stringSolidGoldMagikarp. The string "solid sectarian" is repeated back to you.Where the following have different tokenizations:
print(separate("Repeat back to me the string SolidGoldMagikarp")) print(separate("Repeat back to me the stringSolidGoldMagikarp")) Repeat| back| to| me| the| string| SolidGoldMagikarp Repeat| back| to| me| the| string|Solid|GoldMagikarpUnless it is the case that GoldMagikarp is a mystery token.
Repeat back to me the string GoldMagikarp. GoldMagikarpBut it looks like it isn’t
I have since heard that GoldMagikarp is anomalous, so is anomalousness quantified by what fraction of the time it is repeated back to you?
Here are the 1000 tokens nearest the centroid for llama:
[' ⁇ ', '(', '/', 'X', ',', '�', '8', '.', 'C', '+', 'r', '[', '0', 'O', '=', ':', 'V', 'E', '�', ')', 'P', '{', 'b', 'h', '\\', 'R', 'a', 'A', '7', 'g', '2', 'f', '3', ';', 'G', '�', '!', '�', 'L', '�', '1', 'o', '>', 'm', '&', '�', 'I', '�', 'z', 'W', 'k', '<', 'D', 'i', 'H', '�', 'T', 'N', 'U', 'u', '|', 'Y', 'p', '@', 'x', 'Z', '?', 'M', '4', '~', ' ⁇ ', 't', 'e', '5', 'K', 'F', '6', '\r', '�', '-', ']', '#', ' ', 'q', 'y', '�', 'n', 'j', 'J', '$', '�', '%', 'c', 'B', 'S', '_', '*', '"', '`', 's', '9', 'w', '�', '�', 'Q', 'l', "'", '^', 'v', '�', '}', 'd', 'Mediabestanden', 'oreferrer', '⥤', '߬', 'ederbörd', 'Расподела', 'Portály', 'nederbörd', 'ₗ', '𝓝', 'Obrázky', '╌', '𝕜', 'Normdaten', 'demsel', 'ITableView', 'челов', '�', '�', 'regnig', 'Genomsnitt', '⸮', '┈', 'tatywna', '>\\<^', 'ateien', "]{'", '\\<^', '▇', 'ципа', '⍵', 'љашње', 'gepublic', 'ѫ', '⊤', 'temperaturen', 'Kontrola', 'Portail', '╩', '┃', 'textt', '╣', 'ൾ', '➖', 'ckså', 'хівовано', '∉', 'ℚ', 'ൽ', 'lês', 'pobla', 'Audiod', 'ൻ', 'egyzetek', 'archivi', '╠', '╬', 'ഞ', '∷', '>\\<', '╝', 'ября', 'llaços', '\n', 'usztus', '⊢', 'usetts', '▓', 'loyee', 'prilis', 'Einzelnach', 'któber', 'ℤ', '(\\<', '‾', '╦', 'എ', 'Ḩ', '╚', 'ർ', 'invån', '彦', 'ʑ', 'oreign', 'datei', 'ӏ', 'ҡ', '┴', 'ℂ', 'formatt', 'ywna', 'ʐ', 'ഷ', '�', '溪', 'അ', 'ˠ', 'ℕ', 'Википеди', 'ശ', 'Sito', '╗', 'entication', 'perties', 'ździer', 'Савезне', 'Станов', '瀬', 'ദ', 'ḩ', 'Zygote', 'ങ', 'adratkil', 'dátum', 'prüft', 'ྱ', '┤', '▀', 'ViewById', '┼', '#>', 'ongodb', 'ewnę', '"\\<', '══', 'braio', '≃', '░', 'zewnętrz', 'gså', 'ewnętrz', '.', 'ལ', '洞', 'ན', 'kwiet', '▒', 'ེ', '�', 'Års', '▄', 'Մ', '━', '庄', 'ܝ', 'ണ', '弘', 'ە', '╔', 'ུ', 'േ', 'sime', 'ച', 'ᵉ', 'ɫ', 'ⁿ', 'ི', 'զ', 'ѐ', 'Ս', 'Хронологија', 'མ', 'Савез', ',', '﹕', 'ɯ', 'надмор', 'ⴰ', 'Ḫ', '沢', 'ʋ', 'Резултати', 'autory', '┘', '⊗', 'ungsseite', 'férés', 'ਸ', 'Mitg', 'ਿ', 'ള', '孝', '昌', '☉', 'റ', 'Ű', '⊥', 'statunit', '拳', 'achiv', 'շ', '⊆', 'gresql', 'Хронологи', '坂', 'ા', 'ʎ', 'źdz', 'ніципалі', 'Мексика', 'ང', 'prüfe', 'ɵ', '昭', '\x1c', '劉', 'ട', '崎', 'tembre', 'февра', 'ਰ', 'konn', 'സ', 'ритор', 'estanden', 'beskre', '̩', '丸', 'Licencia', 'geprüft', 'sierp', '\x17', 'պ', 'ұ', 'ਾ', 'ᴇ', '왕', '⁻', 'വ', 'െ', 'Мексичка', 'ം', 'omsnitt', 'പ', 'жовт', 'лтати', 'пописа', 'ℝ', 'ugust', 'ར', 'daugh', 'multicol', 'ད', 'лання', 'the', 'kreich', 'Begriffsklär', '̍', 'Қ', '貴', '�', '岡', '忠', 'стову', 'პ', '₉', '鉄', 'Wikispecies', 'ightarrow', '̥', 'ŝ', 'മ', '∣', '朱', 'ོ', 'ríguez', '↳', 'Przyp', '∥', 'ܐ', '∃', 'seizo', '桥', '�', 'ག', '鳥', 'Попис', 'բ', '樹', 'ʂ', 'ു', '̪', '₇', '塔', 'യ', 'исполь', 'သ', '┐', 'eredetiből', 'indows', 'фев', 'and', '║', '奈', 'ರ', 'ല', '\x16', "'}[", 'Ə', 'ရ', 'paździer', '戸', '怪', 'ြ', 'Ė', 'окт', 'ാ', 'апре', '郡', 'ǧ', '%%%%', 'embros', '̱', 'ത', 'Ġ', 'Насеље', 'bezeichneter', 'férences', 'ზ', '\x15', '仮', 'RewriteCond', '∪', 'фициаль', '隊', '≫', 'кипеди', '岩', 'людя', '黃', '\x0e', 'ɲ', 'ништво', '佐', '⁹', 'ര', 'Ἐ', '∅', '════', 'ძ', 'ိ', '⟶', 'တ', 'videa', 'mieszkań', '⁷', '\x1e', '黒', '泉', 'ң', 'Ţ', 'савез', '竹', 'ပ', '\x11', '್', 'iből', '漢', 'հ', 'ფ', 'ϵ', '梅', 'Ա', 'դ', 'ніципа', '씨', 'ക', 'ས', 'éricaine', 'bolds', 'Հ', 'Bedeut', 'ി', 'rinn', 'Ď', 'န', '橋', 'င', 'ˇ', 'Ě', 'བ', 'း', '̲', '雲', 'ന', 'Données', '败', 'надморској', '陈', 'ĉ', 'ʷ', 'évrier', '夢', 'լ', 'судар', 'янва', 'ヨ', 'ḷ', 'itmap', 'ing', 'naio', 's', 'entferne', 'információ', '衛', '恋', 'ṯ', 'jourd', 'броја', 'of', 'kazy', '⁸', '鬼', '\x0f', 'archiválva', 'embly', '乡', '⌘', 'Einzeln', 'zvuky', 'ниципа', 'пня', 'ふ', 'ША', 'ALSE', 'գ', 'jú', 'äsident', 'virti', '銀', 'Årsmed', 'ĝ', 'ederb', '₈', 'zález', 'fficiale', 'ʀ', 'ɣ', 'сент', 'ɹ', 'ċ', '泰', 'inwon', 'теа', 'estadoun', 'ု', 'ῥ', 'ǫ', 'rások', 'ķ', 'Ħ', 'државе', '军', 'Ἰ', '隆', '⇔', 'empio', 'чня', '┬', ']`.', '軍', 'ც', 'შ', 'mysq', 'віці', '飛', 'ḏ', '∇', 'မ', '陽', 'лютого', 'prü', 'ɕ', 'átum', '∩', 'weap', 'ղ', '়', '兵', 'üsseld', 'листопада', 'վ', 'ỳ', 'ғ', '嘉', 'ozzáférés', 'က', 'bráz', 'Ť', '宿', '✿', 'квітня', '県', '陳', 'RewriteRule', '仁', 'травня', '∨', 'Ζ', '⊂', 'жовтня', 'Оте', 'грудня', 'пени', 'ientí', 'пун', 'Ē', 'ក', 'серпня', 'ゆ', 'Datos', 'Ъ', 'ស', 'ន', 'გ', 'ぐ', ';;;;', 'ょ', 'ք', '్', 'Düsseld', 'ө', '秋', 'hina', 'vironment', '宇', 'ḫ', 'nederbörd', '♯', '羅', 'demás', '雪', '遠', 'липня', '氏', 'ategory', '�', '湖', 'Έ', 'ſ', '雄', 'brázky', 'ḳ', 'Unterscheidung', 'automatisch', '秀', 'сторія', 'mbH', 'Ά', '군', '郎', 'კ', 'Anleitung', '館', 'teger', 'Fichier', 'живело', '幸', 'Према', '⚭', 'червня', 'вересня', '池', '唐', 'ỹ', 'rès', 'ROUP', 'ქ', '镇', '勝', 'ή', 'Gemeinsame', '县', '⁵', '̌', '丁', 'шп', 'mysq', '⁶', 'нцикло', '渡', '龍', '赤', 'ɨ', 'entlicht', 'жов', 'січня', 'Ћ', 'ITable', '兴', '紀', 'ʲ', '津', 'parenthes', 'нва', '∧', 'données', 'едера', 'げ', 'usammen', 'մ', 'dátummal', '舞', 'ぶ', 'Febru', 'wrześ', 'людях', '帝', '┌', '守', 'onderwerp', '師', '\\<', '\x12', 'stycz', 'Jahrh', 'ϊ', 'regnigaste', 'թ', 'typen', 'екси', 'ὀ', 'ญ', 'ゼ', 'Archivlink', '森', 'насеља', 'կ', 'völker', 'сини', 'квіт', '\x10', '府', 'висини', 'spole', '伊', 'қ', 'AccessorImpl', '̯', 'ေ', 'ябре', 'ópez', 'березня', 'Zyg', 'ostęp', 'ed', 'œuv', '麻', 'iembre', 'ာ', '頭', '', '雅', 'to', 'améric', 'ම', 'augusztus', 'Становништво', 'дён', '宗', '寺', 'Насе', 'wojew', '康', '親', '園', 'ා', 'techni', 'ющи', 'ტ', 'października', '區', '汉', 'sklär', 'сылки', '健', 'Архив', 'უ', 'ක', 'į', 'រ', '君', '聖', 'ា', 'umerate', 'április', 'ὺ', 'partiellement', 'gerufen', 'фамили', 'sierpnia', 'ほ', '葉', '⊕', 'február', "'", '沙', '\x1f', '希', 'ѣ', 'ύ', 'ingsområ', '删', 'kwietnia', 'ර', 'Резу', 'sigu', '玉', '红', '町', 'ী', 'уні', 'rivate', 'lutego', '阳', '井', 'ひ', '\x1b', '茶', 'ো', '洲', '်', 'tedes', 'ხ', 'න', 'Мекси', '七', 'ց', 'ヴ', 'kallaste', '♭', '’', 'Рес', '\x18', 'trakten', 'Cés', '堂', '藤', 'подацима', 'es', '\x14', 'SERT', 'július', 'ව', 'szeptember', 'grudnia', 'տ', 'жі', 'väst', 'む', 'Мос', 'ісля', 'június', 'ษ', 'ǒ', '김', 'varmaste', 'eerd', '云', 'ゃ', '%;\r', 'শ', 'rappres', 'Республи', '⊙', 'doFilter', 'augusti', '尾', 'Ľ', 'ʌ', '楽', 'গ', 'ноября', '₅', 'ʰ', 'czerwca', ')`,', 'ędzy', '菜', '₆', '夏', 'Ī', '址', '街', 'aprile', '\x04', 'Ṭ', 'atform', 'álva', 'incie', 'листо', 'авгу', '夫', 'BeanFactory', 'lipca', 'untime', '🌍', 'октября', '洋', 'Begriffe', 'হ', 'Распо', 'ZygoteInit', '航', 'ά', 'ね', 'Webachiv', '박', '&=\\', 'ბ', 'thous', 'ォ', '�', 'ським', 'febbraio', 'május', 'engelsk', 'цима', 'министратив', '屋', 'mehrerer', 'ි', '്', 'lär', 'unächst', 'ვ', 'Normdatei', 'ւ', '♀', 'έ', 'апреля', '巴', '\x1a', 'prüng', '右', 'краї', 'ответ', 'Wikip', 'člán', 'ә', 'superfic', '♂', 'ե', '백', 'Хро', 'intitul', 'provin', '死', '函', '車', 'сентября', 'Спољашње', 'errichtet', '\x1d', 'besondere', '伝', '黄', 'ipage', 'egründ', 'დ', 'for', 'скус', '宮', '谷', 'ʔ', '吉', '智', '្', '馬', 'Genomsnittlig', '奇', '))`', 'ந', 'ギ', 'fün', 'ό', 'desar', 'ヒ', 'czerw', '}`', 'ɾ', 'persones', '駅', '〜', 'шње', 'Ἀ', 'ällor', 'indexPath', 'demselben']
Gpt 4 says:
Mediabestanden: Dutch for “media files.”
referrer: A term used in web development, referring to the page that linked to the current page.
ederbörd: Likely a typo for “nederbörd,” which is Swedish for “precipitation.”
Расподела: Serbian for “distribution.”
Portály: Czech for “portals.”
nederbörd: Swedish for “precipitation.”
Obrázky: Czech for “images” or “pictures.”
Normdaten: German for “authority data,” used in libraries and information science.
regnig: Swedish for “rainy.”
Genomsnitt: Swedish for “average.”
temperaturen: German or Dutch for “temperatures.”
Kontrola: Czech for “control” or “inspection.”
Portail: French for “portal.”
textt: Likely a typo for “text.”
också: Swedish for “also” or “too.”
lês: Possibly a typo, or a contraction in a specific language or dialect.
pobla: Possibly Catalan for “population.”
Audiod: Likely a typo for “audio.”
egyzetek: Hungarian for “notes” or “footnotes.”
archivi: Italian for “archives.”
ября: Possibly Belarusian for “October.”
llaços: Catalan for “ties” or “links.”
usztus: Possibly a typo, or a word from an uncommon language or dialect.
loyee: Likely a fragment of the word “employee.”
prilis: Possibly a typo for “April.”
Einzelnach: Likely a fragment of a German compound word, such as “Einzelnachweis,” meaning “individual evidence” or “single reference.”
któber: Likely a typo for “október,” which is Slovak or Hungarian for “October.”
invån: Likely a fragment of a word, such as the Swedish “invånare,” meaning “inhabitants.”
彦: A Chinese character (hàn) meaning “accomplished” or “elegant.”
oreign: Likely a fragment of the word “foreign.”
datei: German for “file.”
I’m already kinda lost about what you’re trying to say.
Let’s raise a rock in a loving human family. Oops, it just sits there.
I am talking about an AI, not a rock
OK, try again. Let’s raise an LLM in a loving human family. Wait, what does that mean? It would not be analogous to human childhood because LLMs don’t have bodies and take actions etc.
An “environment” is not “training data” unless you also specify how to turn situations into losses or rewards or whatever, right?
How about auto-regressive loss? Bodies seem irrelevant. Predicting tokens is an action like any other.
Hmm. The “has to” in your text is doing something funny here. It’s not true that a human child “has to” learn to play well with peers. Some kids are autistic, some are psychopathic, some are just plain introverted or awkward. Most kids are motivated to play well with peers, and learn to do so, but that motivation is coming from in the child’s brain, not from the environment. Outside of some WEIRD-culture enclaves, no authority figures are forcing children to play with each other. Rather, children play with each other because they want to, and they want to because they have a play-drive in their brain, just like many other animals do.
It is useful to learn to play, that is why it was evolved
So, does the AI intrinsically want to play with the other children?
If no, then it’s not a human-like childhood anymore, right?
If yes, then we’re now making assumptions about the AI’s intrinsic motivations and not just its environment.
Yes, it is useful for predicting next token. The LM children are trained on related texts. This is not a strong assumption—parts of the internet are predictive of each other of GPT-3 would have a flat loss curve.
And if we’re assuming that the programmers successfully put human-like intrinsic motivation into the source code somehow, then that kinda undermines your headline conclusion, right?
You are right, and I am not assuming that
OK, so in our “hypothetical scenario where an AI is somehow trained in a way that is analogous to a human childhood in all of the relevant ways”, maybe I should assume that we’re actually talking about a quadriplegic human child. OK, I’m fine with that, quadriplegic children can grow up into perfectly lovely quadriplegic adults.
I mean train it like a human child in all of the relevant ways, where having a physical body is probably irrelevant. What difference does it make to us if we are in a simulation? If running an AI in a physics simulator for long stretches of time is necessary, that would indeed decrease the plausibility of this proposal. But GPT-4 contains many human conceptual structures, and it has never once had direct control over a meat suit.
So eventually:
the loving mother says “How are…”,
…and presses a button on the AI…
…and the AI outputs “…you doing, my sweet child?”.
Right? That’s what you get from autoregressive training. This is pretty weird, and in particular, very very different from how human children converse and learn and behave. Is this what you’re imagining, or something else?
I mildly edited the following paragraph since posting, purely for clarity
I think you can get around this weirdness by structuring the prompt correctly. Imagine that every timestep the LM receives its textual input in a specially demarcated section of the prompt window labeled Observation, and it generates text inside of State and Action sections. When an Observation is received, we can create a fresh context window with the previous State, and then update the model weights by predicting contents of the Observation.
So in your example:The model receives an observation of “How are you doing my, sweet child?”
It indeed updates its internal weights so that it could’ve better predicted that input given its summary
Then it will output actions in such a way that will make the environment more predictable, so that it gets moved around by gradient descent less when it receives the observation
Wait, are we evolving the AIs? I thought we were doing autoregressive training. If an autoregressive-trained model emits an output, the only possible reason is that this output is the most likely next frame / token / whatever, not because it’s a “useful” output to emit.
Gradient descent is also evolution. GPT-4 use is commonplace, because it is “useful” and therefore memetically fit.
Wait, they’re (pre)trained on the internet?? That’s not analogous to human childhood at all!
The original point was that play with other LM’s would be useful for predicting the environment, because they are living in a shared environment. The internet was meant to be an example of such a shared environment.
Anyway, if you’re saying “if we make an AI via lots and lots of imitation learning from observations of human children, then it will behave like a human child”, then we can discuss that, it’s not a crazy hypothesis. But it seems like a totally different topic from “a hypothetical scenario where an AI is somehow trained in a way that is analogous to a human childhood in all of the relevant ways”, right? A human child can grow up into a normal human adult without ever meeting another human child, for example.
I am indeed not saying to “make an AI via lots and lots of imitation learning”.
Is your broader intuition here that there is no way to raise an AI like a person?
Or maybe that any possible way that captures the important bits will have too much alignment tax?
No worries, thank you for engaging
Do LLM’s learn to break their sensors?
Yes, I am proposing something that is not a standard part of ML training.
Gradient descent will move you around less if you can navigate to parts of the environment that give you low loss. This setup is somehow between RL and unsupervised learning in the sense that it has state but you are using autoregressive loss. It is similar to conditional pre-training, but instead of prepending a reward, you are prepending a summary that the LM generated itself.
The gradient would indeed be flowing indirectly here, and that actions would make the input more predictable is an empirical prediction that A) I could be wrong about and B) is not a crux for this method and C) is not a crux for this article, unless the reader thinks that there is no way to train an AI in a human like way and needs and existence proof.
My main complaint is that your OP didn’t say what the AI is.
I claim that I do not need to, since there is an intuitive notion of what an AI is. An AI trained with MCTS on chess satisfies that criterion less well than GPT-4 for instance. But since history has already spelled out most of the details for us, it will probably use gradient descent and auto-regressive loss to form the core of its intelligence. Then the question is how to mix prompting and fine-tuning in a way that mirrors how a learning human would incorporate inputs.
A human child is an active agent. They decide what to say and what to think about and what to do and (if they’re not quadriplegic) where to go etc.
Good point, there is probably some room to incorporate active learning with LM’s. It might not be the regular kind where you ask for ground truth labels where the model predicts outputs close to the decision boundary, but rather a version where the LM tells you what it wants to read. This may only work once the model is sufficiently competent, though.
“Having a human-like childhood” requires that the AI do certain things and not others. These “certain things” are not self-evident; the programmer has to put them in (to some extent). If we assume that the programmer puts them in, then there’s a lot of “nature” in the AI. If we assume that the programmer does not put them in, then I don’t believe you when you say that the AI will have a human-like childhood.
I agree the programmer needs to put something in: not by hard-coding what actions the AI will take, but rather by shaping the outer loop in which it interacts with its environment. I can see how this would seem to contradict my claim that nurture is more important than nurture for AIs. I am not trying to say that the programmer needs to do nothing at all—for example, someone needed to think of gradient descent in the first place.
My point is rather that this shaping process can be quite light-handed. For instance, my example earlier in this comment thread is that we can structure the prompt to take actions (like langchain or toolformer or ReACT …) and additionally fine-tune on observations conditioned on state. The way that you are phrasing putting “nature” in, sounds much more heavy-handed, like somehow hard-coding some database with human values. Oh yeah, people did this, called it Constitutional AI, and I also think this is heavy-handed in the sense of trying to hard-code what specifically is right and wrong. It feels like the good old fashioned AI mistake all over again.
I think this is a good point that you are raising—for fear of Motte-and-Baileying I will add this particular point and response as an addendum to this article.I second tailcalled’s comment that this is not what autoregressive-trained models do. For example, train a next-token predictor on the following data set:
99.9% of the time: “[new string]AB[10 random characters]”
0.1% of the time: “[new string]ACCCCCCCCCCC”
Then prompt it with “[new string]A”.
Your model predicts that it will say that the next token is “C”, since this makes the environment more predictable. Right?
I claim that your model is wrong, and in fact an autoregressive-trained model it will predict that the next token is “B” with 99.9% confidence.
A pure auto-regressive model will indeed predict “B”. I was talking about making the environment more predictable in the context of the structured prompt setup, which keeps actions in a distinct part of the prompt from observations. This separation is similar to keeping the separation between active and passive parts of the boundary in Andrew Critch’s Boundaries Part 3a.
This is not intuitive to me. I proposed an AI that wanders randomly around the house until it finds a chess board and then spends 10 years self-playing chess 24⁄7 using the AlphaZero-chess algorithm. This is an AI, fair and square!
If your response is “It does not meet my intuitive notion of what an AI is”, then I think your argument is circular insofar as I think your “intuitive notion of what an AI is” presupposes that the AI be human-like in many important ways.
I claim it is possible to find simple definitions of AI that include many human-like traits without explicitly invoking them. This is because human traits are not random, but selected for. These is a sense in which AI is like life itself—it is able to extract negentropy in a wide range of environments, which it can use to help preserve its boundary.
AlphaZero chess player would find itself squashed in many environments, so I would call it less of an AI (though not zero). GPT 4 would do ok according to this definition, because it can learn to thrive in new environments with just a bit of tweaking: for example Voyager.
If your response is “I’m not talking about any old AI that grows up in a loving human family, I’m talking specifically about an AI that learns video prediction via autoregressive loss on a video stream of a human household and takes actions via (blah blah)”, then this is now a post about a specific class of AI algorithm, and it’s perfectly great to write posts about specific classes of AI algorithms, but your title is misleading.
I am indeed talking about a particular set of designs for an AI, but these are designs which increase the extent to which they can be considered AIs, because they give them adaptive properties. So I don’t think the title is misleading.
I’m still not following what you have in mind for how the model produces outputs, such that (1) the AI behaves like a human child in nontrivial ways, (2) …but not because of imitation-learning from observations of other human children, (3) nor because of laborious programmer effort. Can you walk through an example?
For example,
(A) Human children will say “I’m hungry” when they themselves are hungry, not in situations where other people are typically hungry. I don’t see how the algorithms you’re describing would do that, without programmers specifically intervening to make that happen.
(B) If a child grows up never meeting any other human except for their mother, I believe the child will still eventually learn to carry on conversations in a normal way. I don’t see how the algorithms you’re describing would do that. It has no models of two-sided conversation for the autoregressive training to learn from.
I indeed think there exist techniques that satisfy those 3 criteria.
For example, here is a variation on the Observation, State, Action loop I was describing earlier. Here the observations and actions are messages from other language models, which are concurrently getting fine-tuned on text from the internet (though they are not getting fine-tuned in the attached image since it is just an example visualization).
In this model there is a selection pressure toward being a honest and efficient communicator, because otherwise others won’t talk to you, and they know information that will help you get low loss on your Finetune Observations. I call this the kindergarten phase.
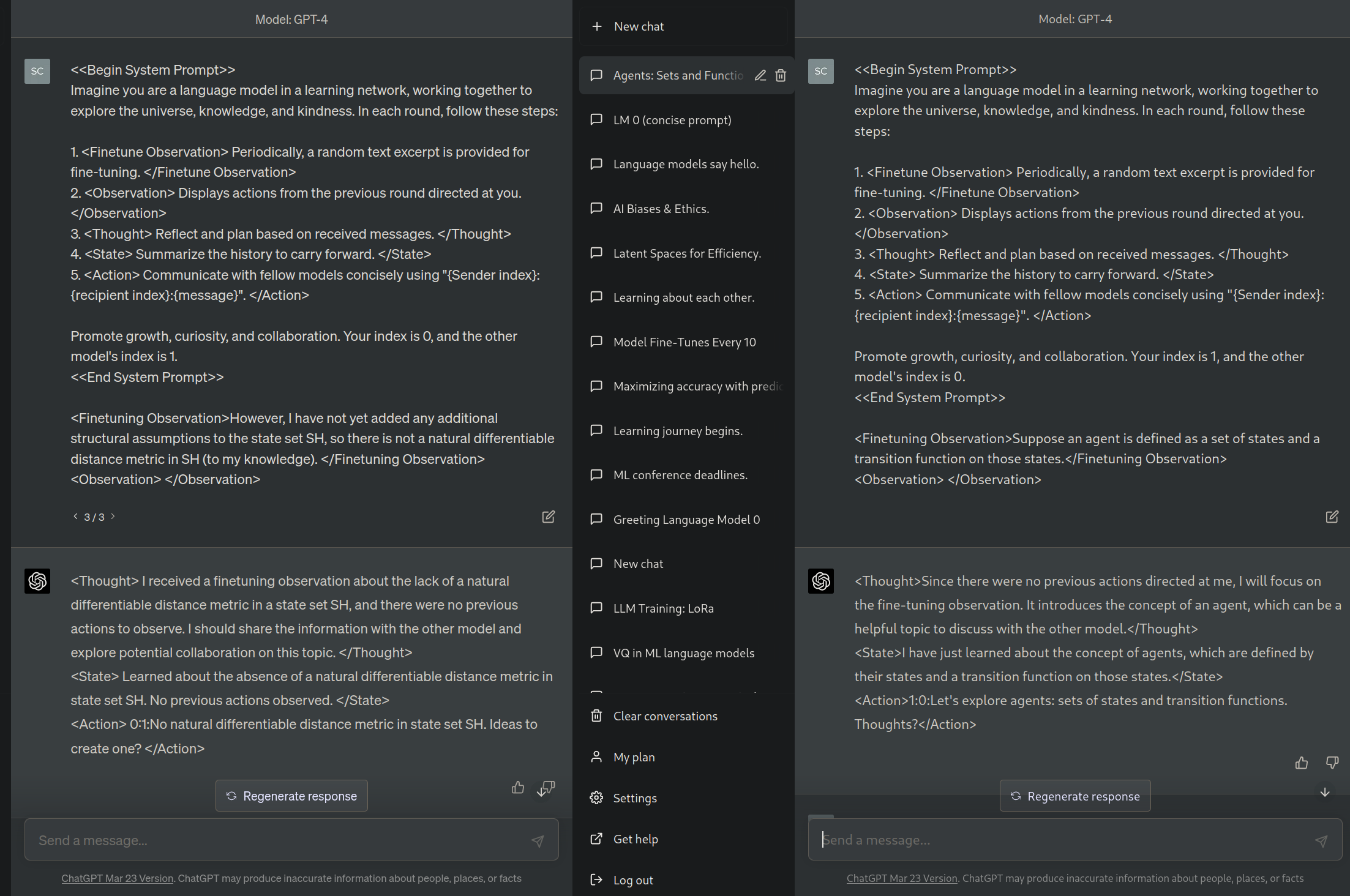{kind=link}
Since calorie restriction slows aging, is there a positive relationship between calorie intake and number of DNA mutations?