I’ve edited the article to use “The Golden Gate Bridge” instead of “deception” as the motivating example. It’s less motivating for sure, but I think it makes the technique easier to discuss. But you’ve really got me thinking about the complexities of capability removal.
Sandy Fraser
Karma: 75
True, concrete knowledge would have been a better motivating example. Intervening usefully on deception is a moonshot.
I wonder if it would be possible to intervene on a concept only for continuation tokens, while leaving prompt tokens uninhibited? I don’t know what might carry over via attention, but I’d like to try it.
Intervening on Sparse, Anchored Concepts
Side quests in curriculum learning and regularization
Regarding generalization to transformers, I suspect that:
Representations “want” to be well-structured. We see this in the way concepts tend to cluster together, and it’s further evidenced by cosine distance being a useful thing to measure.
Well-structured latent spaces compress knowledge more efficiently, or are otherwise better suited for embedding math. Weak evidence: the training speed boost from hypersphere normalization in nGPT.
So I think latent representations naturally tend toward having many of the features we would regularize for, and they may only need a gentle nudge to become much more interpretable.
I think that some of the challenges in mech interp, intervention, and unlearning are due to:
Not knowing where concepts are located, and having to look for them
Some concepts becoming poorly-separated (entangled) due to the initial state and training dynamics
Not knowing how entangled they are.
My hypothesis is that: If we a. Identify a few concepts that we really care about (like “malice”), b. Label a small subset of malicious samples, c. Apply gentle regularization to all latent representations in the transformer for tokens so-labelled, right from the start of training; Then for the concepts that we care about, the structure will become well-organized in ways that we can predict, while other concepts will be largely free to organize however they like.
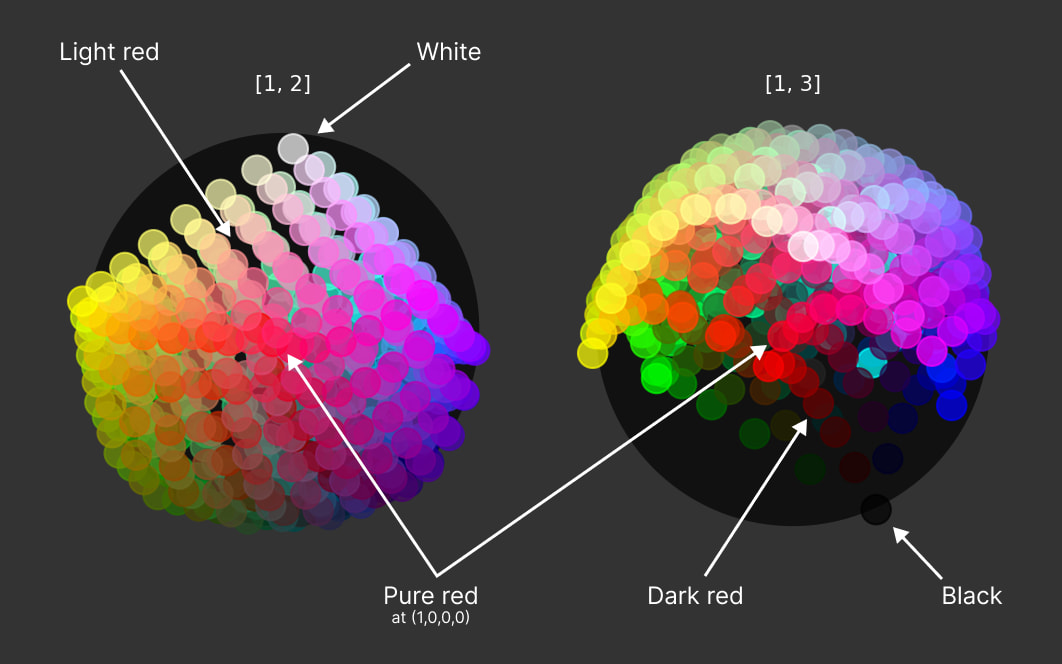
And I think that in high-dimensional spaces, this won’t be in conflict with nuanced concepts that “share” components of several more basic concepts. For example, in the experiment presented in this post, red and the colors near red were all regularized (with varying frequency) toward the anchor point — and yet the colors near red (such as dark red and light red) were able to position themselves appropriately close to the anchor point while also having enough freedom to be shifted toward white and black in the other (non-hue) dimensions.
Thanks for the link to that paper! I hadn’t seen it; I’ll definitely check it out. I started on this research with little background, and I find it interesting that I converged on using many of the same terms used in the literature. I feel like that in itself is weak evidence that the ideas have merit.
Selective regularization for alignment-focused representation engineering
Sparse Concept Anchoring
Ah, good suggestion! I’ve published a demo as a Hugging Face Space at z0u/sparky.
Very nice! What does color represent in the heatmaps? Cycle loss/accuracy?
If the base model uses non-normalized activations, shouldn’t the dot product be your training signal? Otherwise information in the magnitude of the activations would be ignored. I wonder if that might account for some of the inaccuracy (0.8).