I think what you’re asking for is perspectives on your views from someone more similar to an average Anthropic employee than you, and I guess I am that. Sorry if this post is confusing, I don’t write about abstract questions too often.
My perspective is that philosophy can have a mental effect where you think that certain questions, once posed, correspond to reality in a way that they don’t, and are potentially answerable in a way that they’re not. I feel like this post has some “twisting” in its frame from this effect where it makes you feel like if a philosophical question exists and is hard to answer, we should probably update on there being a corresponding piece of reality that also exists and is also “hard” in some way. But from my perspective, strictly philosophical questions are pretty much always unanswerable (e.g., by being ill-posed and not corresponding to the reality) even when the corresponding piece of reality is trivially easy to work with in other ways.
More concretely:
The post is called “taking technical philosophy more seriously” but doesn’t seem to contain clear arguments to take technical philosophy more seriously.
The concrete questions in the post don’t seem like things you’d use philosophy to tackle.
It seems like you have a meta-philosophical question about whether philosophy is necessary for solving alignment.
I don’t have reason to believe that this question is answerable using philosophy, and looking at the track record of philosophy etc. makes me think it’s not.
I feel that it’s possible to reasonably employ heuristic vibes on the question of how useful philosophy could be for solving alignment, but becoming good at wielding heuristic vibes is kind of like building a political opinion—you have to collect and compress a lot of different data from your experience and the resulting tacit knowledge is hard to convey. This is probably one source of your differences with the Anthropic employees—they have a lot of tacit knowledge in machine learning.
At least for me, my tacit knowledge results in me not finding the practice of philosophy relevant to alignment unless it’s embedded in a level of tacit knowledge and practice that would cause most people to not refer to it as philosophy (because they would be spending most of their time on the tacit knowledge-building and practical work, and would mostly engage with concrete examples of philosophical issues and so wouldn’t need to use the abstraction/imaginal muscles you build doing philosophy in exactly the same way, and they would need other muscles too). An example is Amanda Askell’s philosophical work, which seems potentially useful and could also be called “choosing a good character for Claude” and done (perhaps worse) using only common sense and good taste.
I agree that a crux here is your ‘I’m personally at like “it’s at least ~60% that super alignment is Real Hard”’, where by Real Hard you are probably implying that you need to solve fairly pure philosophical problems.
It seems like your stated reasons for believing you need to solve philosophical problems are:
blog by Nate Soares, and AGI Ruin: List of Lethalities by Eliezer Yudkowsky (grounds e.g. belief in a need for pivotal acts)
belief in “rapid” recursive self-improvement that is a “problem” w.r.t iterative empirical R&D
belief in a need for alignment processes that scale to “infinity” or “unboundedly powerful” AI.
that you need to solve real hard philosophical problems to manage this transition
My perspective here is that I have read and thought about the AGI Ruin post for years and have come to believe it deeply deeply does not hold water in many ways. This influences my priors on the Nate Soares post, which I haven’t read recently.
I don’t expect FOOM for reasons of hardware constraints and tacit knowledge from doing things like hands-on ML research. So I believe in a kind of “rapid” that is not as rapid as all that.
I don’t believe in “infinity” or “unboundedness” wrt the things being pointed at when we say “intelligence” for similar reasons and also conceptual reasons.
I did MATS in ’23 and I think community credence in List of Lethalities was pretty low. I might be more Lethalities-pilled than the average person.
> “what would be sufficient to think Anthropic should significantly change it’s research or policy comms?”
For me personally, I would like to see successful researchers producing impactful concrete machine learning research using philosophical reasoning that is flavored like Yudkowsky thought or Soares thought. An example would be inventing more efficient weight sparse transformers using Yudkowsky thought, or upending what loss functions are used to produce interpretable models. For the purposes of this discussion let’s just say that Yudkowsky thought is something I know when I see, and that I’m only including the aspects of Yudkowsky thought not already mainstream in ML (“thinking about incentives” is mainstream).
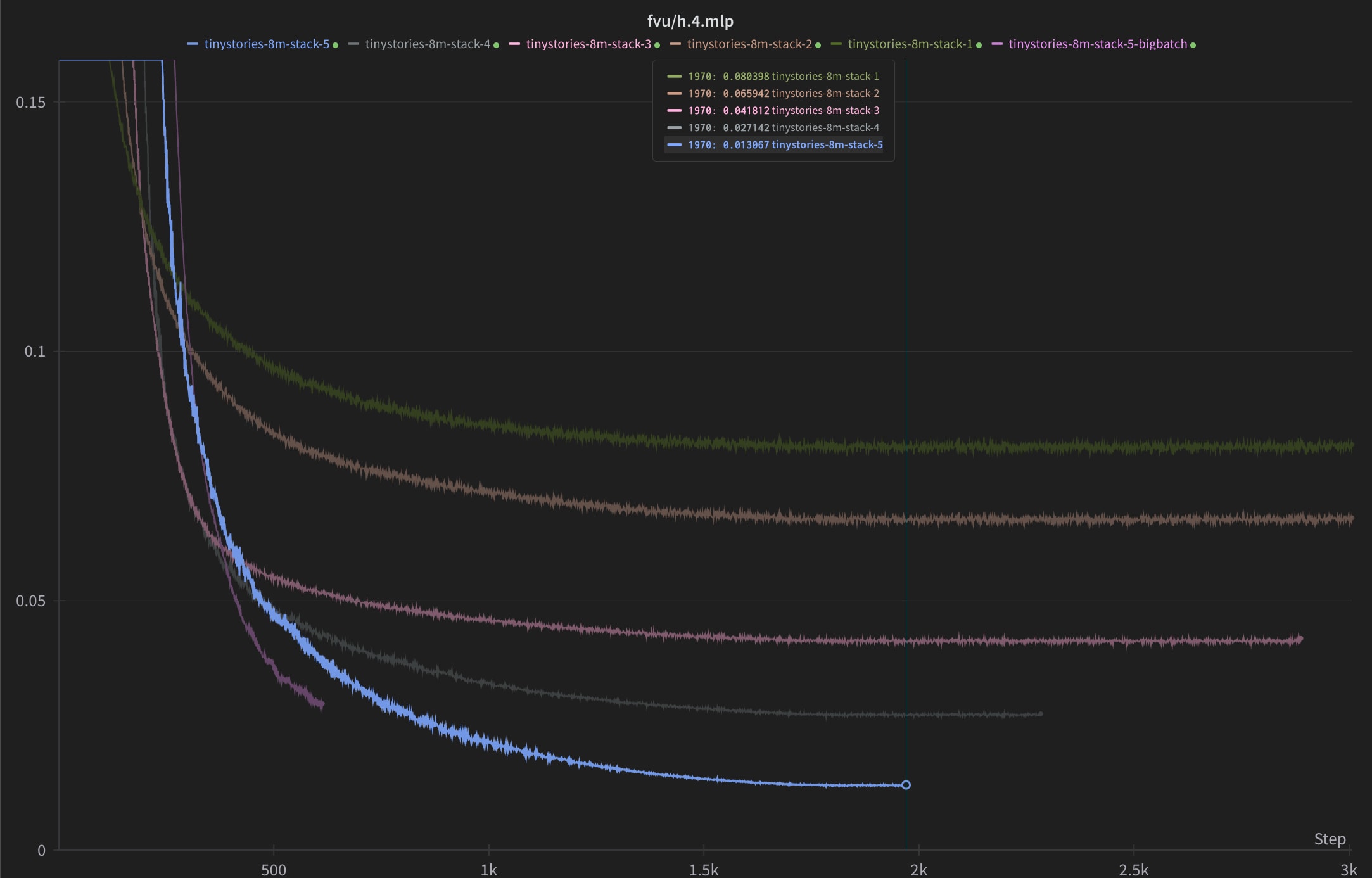
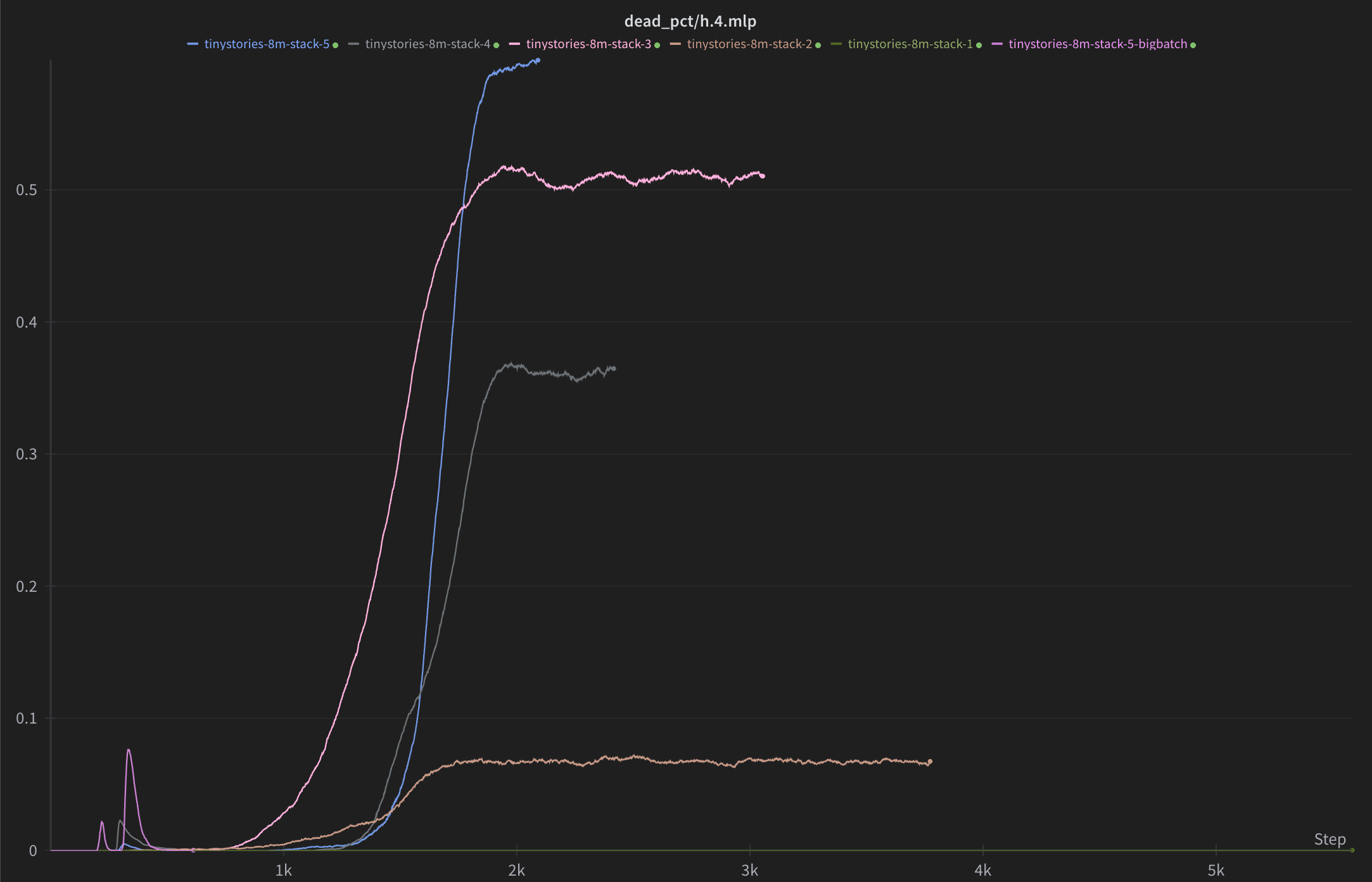
Take 2: I think you’re privileging the hypothesis that AI safety is philosophy-loaded.