The Blackwell order as a formalization of knowledge
Financial status: This is independent research, now supported by a grant. I welcome further financial support.
Epistemic status: I’m 90% sure that this post faithfully relates the content of the paper that it reviews.
In a recent conversation about what it means to accumulate knowledge, I was pointed towards a paper by Johannes Rauh and collaborators entitled Coarse-graining and the Blackwell order. The abstract begins:
Suppose we have a pair of information channels, κ1, κ2, with a common input. The Blackwell order is a partial order over channels that compares κ1 and κ2 by the maximal expected utility an agent can obtain when decisions are based on the channel outputs.
This immediately caught my attention because of the connection between information and utility, which I suspect is key to understanding knowledge. In classical information theory, we study quantities such as entropy and mutual information without the need to consider whether information is useful or not with respect to a particular goal. This is not a shortcoming of these quantities, it is simply not the domain of these quantities to incorporate a goal or utility function. This paper discusses some different quantities that attempt to formalize what it means for information to be useful in service to a goal.
The reason to understand knowledge in the first place is so that we might understand what an agent does or does not know about, even when we do not trust it to answer questions honestly. If we discover that a vacuum-cleaning robot has built up some unexpectedly sophisticated knowledge of human psychology then we might choose to shut it down. If we discover that the same robot has merely recorded information from which an understanding of human psychology could in principle be derived then we may not be nearly so concerned, since almost any recording of data involving humans probably contains, in principle, a great deal of information about human psychology. Therefore the distinction between information and knowledge seems highly relevant to the deception problem in particular, and, in my opinion, to contemporary AI alignment in general. This paper provides a neat overview of one way we might formalize knowledge, and beyond that presents some interesting edge cases that point at the shortcomings of this approach.
I suspect that knowledge has to do with selectively retaining and discarding information in a way that is maximally useful across a maximally diverse range of possible goals. But what does it really mean to be “useful”, and how might we study a “maximally diverse range of possible goals” in a mathematically precise way? This paper formalizes both of these concepts using ideas that were developed by David Blackwell at Stanford in the 1950s.
The formalisms are not novel to this paper, but the paper provides a neat entrypoint into them. The real point of the paper is actually an example that demonstrates a certain counter-intuitive property of the formalisms. In this post I will summarize the formalisms used in the paper and then describe the counter-intuitive property that the paper is centered around.
Decision problems under uncertainty
A decision problem in the terminology of the paper goes as follows: suppose that we are studying some system that can be in one of N possible states, and our job is to output one of M possible actions in a way that maximizes a utility function. The utility function takes in the state and the action and outputs a real-valued utility. There are only a finite number of states and a finite number of actions, so we can view the whole utility function as a big table. For example, here is one with three states and two actions:
| State | Action | Utility |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 0 |
| 1 | 0 | 2 |
| 1 | 1 | 0 |
| 2 | 0 | 0 |
| 2 | 1 | 1 |
This decision problem is asking us to differentiate state 1 from state 2. It says: if the state is 1 then please output action 0, and if the state is 2 then please output action 1, otherwise if the state is 0 then it doesn’t matter. Furthermore it says that getting state 1 right is more important than getting state 2 right (utility=2 in row 3 compared to utility=1 in row 6).
Now suppose that we do not know the underlying state of the system but instead have access to a measurement derived from the state of the system, which might contain noisy or incomplete information. We assume that the measurement can take on one of K possible values, and that for each underlying state of the system there is a probability distribution over those K possible values. For example, here is a table of probabilities for a system S with 3 possible underlying states and a measurement X with 2 possible values:
| S=0 | S=1 | S=2 | |
|---|---|---|---|
| X=0 | 1 | 1 | 0.1 |
| X=1 | 0 | 0 | 0.9 |
If the underlying state of the system is 0 then (looking at the column under S=0) the measurement X is guaranteed to be 0. If the underlying state of the system is 1 then the measurement is still guaranteed to be 0. If the underlying state of the system is 2 then with 90% probability we get a measurement of 1 and with 10% probability we get a measurement of 0. The columns always sum to 1 but the rows need not sum to 1.
Now this table representation with columns corresponding to inputs and rows corresponding to outputs is actually very useful because if we take the values from the table to be a matrix, then we can work out the implications of pre- and post-processing on our measurement using matrix multiplications. For example, suppose that before we made our measurement, we swapped state 1 and 2 in our system. We could think of this as a “measurement” just like before and we could use the following table:
| S=0 | S=1 | S=2 | |
|---|---|---|---|
| S’=0 | 1 | 0 | 0 |
| S’=1 | 0 | 0 | 1 |
| S’=2 | 0 | 1 | 0 |
In this table, if we put 0 in (first column) then we get 0 out, and if we put 1 in (second column) then we get 2 out, and if we put 2 in (third column) then we get 1 out. To work out what the table would look like if we applied this “swapping” first and then “measured” the output of that using the 2-by-3 table above, we can perform the following matrix multiplication:
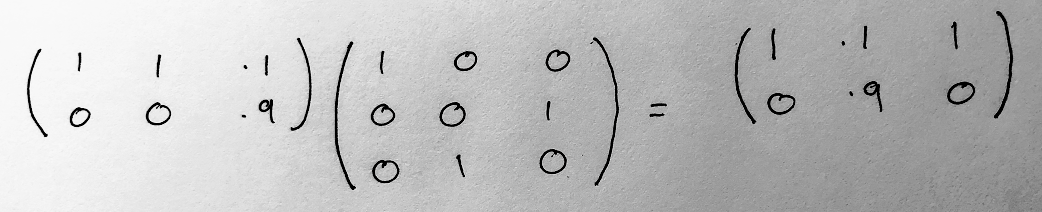
The matrix on the left contains the values from the 2-by-3 table above. The matrix that it is being right-multiplied by contains the values from the 3-by-3 “pre-processing” table. The matrix on the right is the result. It says that now if you put 0 in (first column) then you get 0 out, and if you put 1 in then you get 1 out with 90% probability, and if you put 2 in then you get 0 out, which is exactly what we expect. Matrices in this form are called channels in information theory. They are simply tables of probabilities of outputs given inputs. Since we can write all this in matrix form, we can now switch to using symbols to represent our channels. For example, here are two channels representing the 2-by-3 measurement above, and that same measurement after the pre-processing operation:
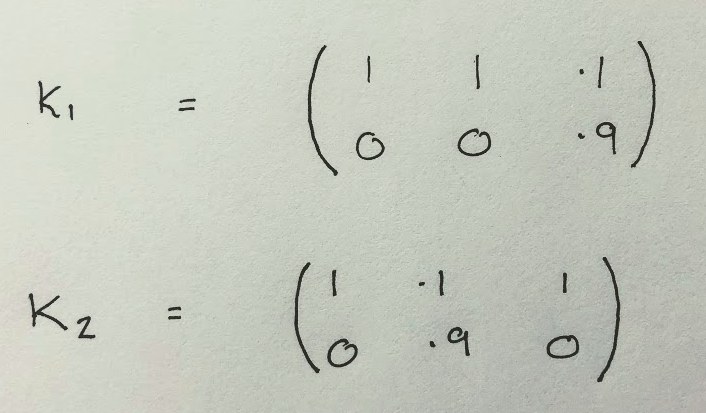
If we write for the 3-by-3 matrix corresponding the pre-processing operation itself, then we have
which is the matrix product that we worked through above.
Now when one channel can be written as the product of another channel and a pre-processing operation, then in the terminology of the paper that second channel is called a “pre-garbling”. When one channel can be written as the product of another channel and a post-processing operation:
then in the terminology of the paper, is a “post-garbling”, or simply a “garbling” of . Although the pre-processing operation we considered above consists of only zeros and ones, the definitions of pre- and post-garbling allow for any matrix whatsoever, so long as the columns all sum to 1.
The intuitive reason for using the word “garbling” is that if you take some measurement of a system and then perform some additional possibly-noisy post-processing operation, then the result cannot contain more information about the original system than the measurement before the post-processing operation. It is as if you first measured the height of a person (the measurement), and then wrote down your measurement in messy handwriting where some digits look a lot like other digits (the post-processing operation). The messiness of the handwriting cannot add information about the height of the person. At best the handwriting is very neat and neither adds nor removes information.
Blackwell’s theorem, which was published by David Blackwell in 1953, and which the paper builds on, says that this notion of post-garbling coincides exactly with a certain notion of the usefulness of some information across all possible goals:
So this theorem is saying the following: suppose you face a decision problem in which you wish to select an action in order to maximize a utility function that is a function of your action and the underlying state of the system. The underlying state of the system is unknown to you but you have a choice between two ways that you could measure the system. Assume that you know the utility function and the channel matrix that generates the measurement, and that once you see the measurement, you will select the action that maximizes your expected utility given whatever information you can glean from that measurement. Which measurement should you select? In general it might make sense to select differently among the two measurements for different utility functions. But are there any cases where we can say that it is always better to select one measurement over another, no matter what utility function is at play? In other words, are there any cases where one piece of information is more generally useful than another? Blackwell’s theorem says that the conditions under which can be said to be more generally useful than are precisely the situations where is a post-garbling of .
Now in general, if we just have two channels, there is no reason to expect either one to be a post-garbling of the other, so this does not give us a way to compare the usefulness of all pairs of channels. But according to Blackwell’s theorem, it is precisely the conditions in which one channel is a post-garbling of another that this channel can be said to provide less useful information, at least if “less useful” means “never gives higher expected utility for any utility function or distribution over underlying system states”.
That post-garbling a channel would not increase its usefulness for any utility function or distribution over underlying system states seems relatively obvious, since, as discussed above, no post-processing step can add information. But the converse, that whenever a channel is no more useful than another on any utility function or distribution over underlying system states it is also guaranteed to be a post-garbling of the other, is quite non-trivial.
With Blackwell’s theorem in hand, we also gain a practical algorithm for determining whether a particular channel contains more generally useful information than another. Blackwell’s theorem tells us to look for any non-negative matrix with columns that all sum to 1 such that
This can be expressed as a linear program, and a solution can be found in less than time where is the number of entries in , or if no solution exists then that can be confirmed just as quickly. A linear programming problem derived in this way can be numerically unstable, though, because tiny perturbations to or will generally turn a feasible problem into an infeasible problem, and working with floating point numbers introduces tiny perturbations due to round-off errors.
The counter-intuitive example
The main contribution of the paper is actually a particular example of two channels and a pre-processing operation that demonstrate some counter-intuitive properties of the Blackwell order. The example they give consists of a system , a pair of channels and , and a pre-processing operation containing only ones and zeros in its matrix, which they call a coarse-graining, but which I think would be better called a deterministic channel. For the particular example they give, strictly dominates according to the Blackwell order, but does not dominate . The authors find this counter-intuitive because, in their example, they show that any information about measured by is also present in the pre-processed system state , so how can it be that becomes less useful in comparison to in the presence of pre-processing?
Another word for a “deterministic pre-processing operation” is “computation”. Whenever we perform computation on a piece of information, we could view that as passing the information through a deterministic channel. When viewed from the land of information theory, pure computation is relatively uninteresting, since computation can never create new information, and passing two variables through the same deterministic computation tends to preserve any inequalities between their respective mutual information with some external variable. All this is to say that information theory studies that which is invariant to computation.
But as soon as you start talking about utility functions and the usefulness of information in service to goals, all that changes. The reason is that we can easily construct a utility function that places different values of different bits of information, so for example you might care a lot about the first bit in a string but not the second bit. If we have a channel that does a good job of transmitting the second bit but introduces a lot of noise into the first bit, then it now makes a big difference to introduce a pre-processing operation that swaps the first and second bit so that the important information gets transmitted reliably and the unimportant information does not.
This is no insignificant point. When we construct a model from a dataset, we are doing computation, and in many cases we are doing deterministic computation. If we are doing deterministic computation, then we are certainly not creating information. So why do it? Well, a model can be used to make predictions and therefore to take action. But why not just keep the original data around and build a model from scratch each time we want to take an action? Well that would be quite inefficient. But is that it? Is the whole enterprise of model-building just a practical optimization? Well, not if we are embedded agents. Embedded agents have a finite capacity for information since they are finite physical beings. We cannot store every observation we have ever made, even if we had time to process it later. So we select information to retain and some information to discard, and when we select information to retain it makes sense to select information that is more generally useful, and this means doing computation, because usefulness brings in utility functions that value some information highly and some information not so highly, and so we wish to put highly valued bits of information in highly secure places, and less valued bits of information in less secure places.
This, I suspect, has a lot to do with knowledge.
Conclusion
The paper presents a very lean formalism with which to study the usefulness of information. It uses a lens that is very close to classical information theory. A measurement is said to be more useful than another if it gives higher expected utility for all utility functions and distributions over the underlying system state. Blackwell’s theorem relates this to the feasibility of a simple linear algebra equality. The whole setup is so classical that it’s hard to believe it has so much to say about knowledge, but it does.
When we really get into the weeds and work through examples, things become clearer, including big-picture things, even though we are staring at the small picture. The big picture becomes clearer than it would have done if I had tried to look directly at the big picture.
There is an accumulation of knowledge going on in my own mind as I read a paper like this. It can be hard to find the patience to work through the details of a paper like this, because they seem at first so far removed from the center of the subject that I am trying to understand. But information about the subject I am studying—in my case, the accumulation of knowledge—is abundant, in the sense that there are examples of it everywhere. At a certain point it matters more to do a good job of retaining the right information among all the evidence I observe than to look in the place that has the absolute maximum information content. The detail-oriented state of mind that comes forth when I work through real examples with patience is a kind of post-processing operation. Being in this state of mind doesn’t change what evidence I receive, but it does change how I process and retain that evidence, and, as this paper points out, the way that evidence is processed can at times be more important than finding the absolute most informative evidence. In other words, when evidence is abundant, computation can be more important than evidence.
I think this is real and relevant. We can move between different states of mind by focusing our attention on different kinds of things. For example, working through a single example in detail tips us towards a different state of mind compared to collecting together many different sources. The former is sharp; the latter is broad. Both are useful. The important thing is that when we choose one or the other, we are not just choosing to attend to one kind of evidence or another, we are also choosing a post-processing operation that will process that evidence upon receipt. When we make a choice about where to focus our attention, therefore, it makes sense to consider not just value of information, but also value of computation, because the choice of where to focus our attention affects our state of mind, which affects what kind of computation happens upon receiving the evidence that we focused our attention on, and that computation might make a bigger difference to the understanding that we eventually develop than the choice of information source.
In terms of understanding the accumulation of knowledge, this paper provides only a little bit of help. We still don’t understand what knowledge looks like at the level of physics, and we still can’t really say what a given entity in the world does or does not know about. In particular, we still cannot determine whether my robot vacuum is developing an understanding of, say, human psychology, or is merely recording data, and we still don’t have a good account of the role of knowledge in embedded agency. Those are the goals of this project.
Having studied the paradoxical results, I don’t think they are paradoxical for particularly interesting reasons. (Which is not to say that the paper is bad! I don’t expect I would have noticed these problems given just a definition of the Blackwell order! Just that I would recommend against taking this as progress towards “understanding knowledge”, and more like “an elaboration of how not to use Blackwell orders”.)
This is supposed to be paradoxical because (3) implies that there is a task where it is better to look at X1, (1) implies that any decision rule that uses X1 as computed through S can also be translated to an equivalently good decision rule that uses X1 as computed through f(S). So presumably it should still be better to look at X1than X2. However, (2) implies that once you compute through f(S) you’re better off using X2. Paradox!
This argument fails because (3) is a claim about utility functions (tasks) with type signature S×A→R, while (2) is a claim about utility functions (tasks) with type signature f(S)×A→R. It is possible to have a task that is expressible with S×A→R, where X1 is better (to make (3) true), but then you can’t express it with f(S)×A→R, and so (2) can be true but irrelevant. Their example follows precisely this format.
It seems to me that this is saying “there exists a utility function U and a function f, such that if we change the world to be Markovian according to f, then an agent can do better in the changed world than it could in the original world”. I don’t see why this is particularly interesting or relevant to a formalization of knowledge.
To elaborate, running the actual calculations from their counterexample, we get:
X←S=⎛⎝11300231⎞⎠
f(S)←S=(110001)
X←f(S)=⎛⎝230131⎞⎠
(X←f(S))⋅(f(S)←S)=⎛⎝2323013131⎞⎠
If you now compare (X←f(S))⋅(f(S)←S) to X←S, that is basically asking the question “let us consider these two ways in which the world could determine which observation I get, and see which of the ways I would prefer”. But (X←f(S))⋅(f(S)←S) is not the way that the world determines how you get the observation X -- that’s exactly given by the X←S table above (you can check consistency with the joint probability distribution in the paper). So I don’t really know why you’d do this comparison.
The decomposition (X←f(S))⋅(f(S)←S) can make sense if X is independent of S given f(S), but in this case, the resulting matrix would be exactly equal to X←S -- which is as it should be when you are comparing two different views on how the world generates the same observation.
(Perhaps the interpretation under which this is paradoxical is one where B←A means that B is computed from A, and matrix multiplication corresponds to composition of computations, but that just seems like a clearly invalid interpretation, since in their example their probability distribution is totally inconsistent with “f(S) is computed from S, and then X is computed from f(S)”.)
More broadly, the framework in this paper provides a definition of “useful” information that allows all possible utility functions. However, it’s always possible to construct a utility function (given their setup) for which any given information is useful, and so the focus on decision-making isn’t going to help you distinguish between information that is and isn’t relevant / useful, in the sense that we normally mean those words.
You could try to fix this by narrowing down the space of utility functions, or introducing limits on computation, or something else along those lines, though then I would be applying these sorts of fixes with traditional Shannon information.
I really loved the thorough writeup and working of examples. Thanks!
I would say I found the conclusion section the least generally useful, but I can see how it is the most personal (that kinda why it has a YMMV feel to it for me).
Thank you for the kind words and feedback.
I wonder if the last section could be viewed as a post-garbling of the prior sections...
Is this reversed?
Yes. Thank you. Fixed.
Hi Alex,
I suspect that you might find the following articles interesting:
Information-Theoretic Probing with Minimum Description Length;
Evaluating representations by the complexity of learning low-loss predictors;
A Theory of Usable Information Under Computational Constraints;
A Novel Approach to the Partial Information Decomposition.
Are the indices the wrong way around here?
Yes. Thank you. Fixed.
Would this be a concrete example of the above:
We have two states S=0, S=1 as inputs, channel k1 given by the identity matrix, i.e. it gives us all information about the original, and k2 which loses all information about the initial states (i.e. it always returns S=1 as the output, regardless of the input ). Then k1 strictly dominates k2, however if we preprocess the inputs by mapping them both to S=1, then both channels convey no information, and as such there is no strict domination anymore. Is this so?
More generally, any k1>k2 can lose the strict domination property by a pregarbling where all information is destroyed, rendering both channels useless.
Have I missed anything?
Yes I believe everything you have said here is consistent with the way the Blackwell order is defined.