Exploring Mild Behaviour in Embedded Agents
Thanks to Tristan Cook, Emery Cooper, Nicolas Macé and Will Payne for discussions, advice, and comments. All views are my own.
I think this post is best viewed as an effort to point at a potentially interesting research direction. The specific arguments I make centered around inducing mild behaviour in embedded agents are rough and exploratory.
Summary
If an embedded agent’s utility function is heavily dependent on the parts of the environment which constitute its own thinking processes, we might see behaviour that does not have an equivalent in unembedded agents.
(This seems pretty likely to me. Of all the claims here I am most confident of this one.)
We might be able to design measures/utility functions that constrain the parts of the environment that constitute the agent’s thinking process itself, such that we can moderate the strength of the optimisation that an embedded agent exerts on the rest of the environment.
(This seems in theory possible to me but I am currently very uncertain about whether this is feasible in practice.)
Following this, we may be able to induce mild optimisation in EU maximising embedded agents through the specification of the agent’s utility function, and this induced ~mild optimisation could help protect that very same mildness-inducing specification from being gamed.
(Similar thoughts to above)
Measures that impose optimisation pressure on the thinking process might be more robust than usual to specification problems if they can induce some degree of mild optimisation even when they are not specified in a water-tight manner. To the extent that we can manage to specify a mediocre efficiency measure that induces even some small degree of mild optimisation, it will also slightly reduce the optimisation pressure the agent puts on the specification as a whole. In this way, there might be some potential for measures like these to be made somewhat self-protecting against specification problems like edge instantiation and nearest unblocked strategies.
(Again, similar thoughts to above, though I do currently find this general idea promising.)
Context
A fundamental property of embedded agents is that the agent’s thinking process is a part of the environment itself (for example, some process running on a physical chip). This can be a driver of certain ‘bad’ behaviours like wireheading, unwanted self-preservation, or extreme resource acquisition for the sake of self-improvement. However, perhaps we can also use the fact that embedded agents have physically instantiated ‘thinking processes’ to try and induce safer behaviour.
Two major things that make alignment so difficult are:
Avoiding small degrees of misspecification of ‘what we actually want’ is very difficult
The specification is likely to be put under an enormous amount of optimisation pressure by a powerful optimiser (which is likely to ‘find’ and ‘blow up the consequences’ of any small misspecification)
These considerations motivate work on approaches such as designing low-impact measures or methods of implementing mild optimisation. Low-impact measures mostly address the first point, by aiming to heuristically specify part of ‘what we actually want’ whilst also reducing the consequences of misspecifications. Mild optimisation mostly addresses the second point, by aiming to ‘tone down’ the optimisation pressure.
Embedded agents have physical instantiations of the optimisation processes that they use to decide how to optimise their environment (e.g. some algorithm running on a physical chip). What would happen if we attempted to construct a utility function that strongly incentivises the agent to constrain the physical instantiation of its own optimising process? Might it be possible to steer some of that enormous optimisation power back onto the optimiser itself?
In this post, I will be focusing on some possible effects of implementing an incentive for embedded agents to ‘think efficiently’. I will look at the possibility that ‘efficient thinking’ measures can cause EU maximisers to implement mild optimisation and the possibility of these measures being somewhat self-protecting against specification gaming.
The Core Idea
The core idea is that we might be able to induce mild optimisation in EU maximising embedded agents through the specification of the agent’s utility function, and that this induced mild optimisation could help protect that very same specification from being gamed.
A summary of the line of argument:
Mild optimisation makes problems associated with misspecification less intense.
For embedded agents, it is in principle possible to ‘reference’ the internal workings of the agent in its own utility function, because these internal workings are part of the environment.
It seems like, in principle, thinking penalties can cause / further increase pressure on EU maximising embedded agents to implement mild optimisation when selecting strategies.
In practice, we often can’t specify much of anything very well. It seems likely that for any way of specifying a ‘cost to thinking’ we could come up with, some of the most optimal strategies will include doing things that dodge or game a thinking penalty.
However, to the extent that we can even poorly specify ‘cost to thinking’ measures that initially induce some degree of mild optimisation, we also reduce the chance of these very optimal ‘penalty dodging’ strategies being played. In other words, to the extent that we can even poorly specify measures that induce mild optimisation, we are also inducing the very means to provide these measures with some degree of protection from being gamed.
Efficient Thinking Measures
Why expect efficient thinking to induce mildness anyway?
In an idealised form, I intend for an ‘efficient thinking’ measure to be used to impose a ‘cost to thinking’ on an agent or equivalently, be used to incentivise an agent to ‘think less’.
Since evaluating and searching through potential strategies involves some kind of cognitive processing, penalties on ‘‘thinking’ impose additional costs on searching through and evaluating strategies in and of itself. Therefore, gains from further deliberation over strategies will need to be traded off against the costs of further deliberation, which seems like it ought to encourage a milder optimisation over strategies.
For example, consider an agent with a goal to accomplish some task whilst making efficient use of some bounded amount of compute. This agent is optimising not only for moving the world towards some target state but also for using less compute to do so. Crucially, the search for the best way to do this itself costs compute. Searching over possible policies/strategies/actions has a cost, and so the ‘search power’ the agent employs is itself traded off against the search’s resource consumption. An agent could be an EU maximiser (in the sense of maximising its EU wrt its beliefs) but still implement mild optimisation over its strategy search. This is because the agent’s internal workings are a part of the environment and so themselves are also constrained by the computational efficiency goal. This is why these points are only applicable to embedded agents.
On a side note, this ‘cost to thinking’ seems to bear a pretty strong similarity to the situation that biological organisms find themselves in. Being smarter, in the sense of being better at navigating, predicting, and manipulating one’s environment, seems like it would always be good for fitness if it were free. However, cognition has a cost,[1] so the benefits of any increase in cognitive effort ought to be worth the higher cost that thinking harder or better would entail. The consequences of this tradeoff can be seen in how humans and animals allocate cognitive effort. For example, people satisfice over choice sets,[2] and in forced-choice experiments people trade-off cognitive effort against pain.[3] (For those interested in this, I found this review good. It also felt surprisingly relevant to / geared towards AI design).
What does ‘efficient thinking’ look like in practice?
In practice, an attempt to properly specify something as abstract as an ‘efficient thinking’ measure seems very difficult, and likely to run into the same kinds of problems that low-impact measures tend to rub up against. For example, it seems very difficult to specify a thinking penalty in such a way that an agent would ‘be responsible for’ thinking done using delegation or successor agents, whilst also ‘not being responsible for’ resources used for all future ‘human-thinking’. [4]
When I am personally imagining a basic ‘efficient thinking’ measure, I tend to think in terms of ‘compute used by an agent when deciding between actions’ or sometimes just ‘compute used by the agent’ full stop. One thing I personally like about compute usage as an efficient thinking measure is it feels both quite fundamental[5] and quite ‘close’ in the sense that we can already implement ~compute use penalties in neural networks. A straightforward implementation of this is adaptive computation time for RNNs by Alex Graves, where an RNN has an output that determines the probability of continued computation, and computation time is penalised in the loss function. Other similar and more recent examples include PonderNet and PALBERT (though they also include exploration incentives).
I also want to mention that I think many measures have some ‘efficient thinking’ component to them, even if just weakly. For example, very general measures like ‘resource use’ or ‘energy use’ seem like they would impose some thinking cost, and I suspect that many low-impact measures will also impose a cost to thinking to some degree in a similar fashion. Where the ‘efficient thinking’ component of these measures is the part that puts optimisation pressure on the physical instantiation of the agent’s thinking process itself. Additionally, all embedded agents will likely also have some ‘cost to thinking’ by default (due to opportunity costs for example) even if that cost is very small.
Efficient Thinking, Meta-Reasoning and Mild Optimisation
Imagine a special kind of slot machine such that when some set amount of money is paid into the machine, a random number from 0 to 1 is generated from a uniform distribution, printed onto a ticket, and given to the player. The player can print as many tickets as they please. At any point, the player may ‘cash out’ and convert only their highest-numbered ticket into some proportional payoff. At what point should they cash out to maximise their payoff?
If there is no cost at all to generating another ticket, then the player would receive the highest payoff by continuing to generate tickets until they get one corresponding to the absolute maximum possible payoff (exactly 1). If the cost to generate a ticket was above half the maximum payoff, then it is not even worth it for them to generate a single ticket. For this specific problem, it is better to cash out than keep playing if (where is the payoff from cashing in the highest currently owned ticket and is the cost to generate a single ticket—workings in the appendix).
In other words, if the current best ticket is worth over a certain amount (which depends on the cost to generate one ticket), the player is better off cashing out than paying to generate more tickets. In essence, the player is best off ‘satisficing’[6] over the ticket values, with higher costs to generate a ticket resulting in lower optimal satisficing ticket value thresholds. The player is still just maximising their baseline expected payoff here. It’s just that as a consequence of the cost of generating tickets, the player is best off implementing essentially a satisficing threshold on acceptable ticket values for ‘cashing out’.
This problem has similarities to the kinds of problems that agents which need to spend limited or costly computational resources in order to evaluate potential strategies/actions have to deal with. These agents need to balance gains from increased deliberation, with costs associated with using additional computation resources or time. For example, instead of a player spending money to generate tickets that correspond to some monetary payoff, we could instead have an agent which spends utility/compute to generate potential object-level strategies with corresponding expected utilities. Similarly, in this scenario, this agent would also maximise its total EU (which includes computational costs of deliberation) via mild optimisation of strategy utilities, with higher computational penalties causing lower ‘satisficing’ thresholds over object-strategy utilities. (For details, see the appendix).
However, more generally, embedded agents will be facing a far more complex situation than in the toy example discussed above. For example, agents may be uncertain about the value of additional deliberation, need to consider the value of information gained from their actions, have complexity/cost trade-offs on their own beliefs, need to avoid an infinite regress of meta-reasoning e.t.c
Essentially, embedded agents have to engage on some level with meta-reasoning problems (though heuristics or simple behaviours acquired in training, or otherwise). By increasing the inherent costs of computation, we might be able to set up the optimal solution to these problems to involve milder, more approximate meta-strategies than they otherwise would. There exists quite a bit of interesting work on rational behaviour in meta-reasoning problems[7] and I think this paper in particular gives a nice overview. (Quick footnote dump for a few other nice meta-reasoning papers I looked at whilst writing this. [8],[9],[10],[11])
Regardless of the specifics, changing the inherent cost of thinking/computation does seem like it often meaningfully changes what the EU maximising meta-reasoning strategy is. Specifically, increasing the costs of deliberation seems like it makes the actually optimal (from the perspective of maximising EU) amount of deliberation over the selection of object-level actions/ strategies lower. In a simple toy case (appendix) this results in an optimal meta policy which is equivalent to satisficing over object-level strategy utilities. In general, decreasing the optimal amount of deliberation/precision over object-level strategy selection does seem like it ought to be meaningfully related to increasing optimisation mildness to some degree. However, I do want to note that I think it’s also not obvious what the exact effects on the optimal meta-strategies of agents would be here, and they could well not be as simple or as safe as just ‘encouraging satisficing over the object-level strategies’.
Potential for Self-Protection Against Gaming
In the previous section, I sketched out how well-specified efficiency measures that impose costs on an agent’s thinking process could possibly cause EU maximising agents to implement a kind of mild(er) optimisation over object-level strategies.
Of course, the devil is in actually being able to specify these efficiency measures well. None of the properties of an efficient thinking penalty matter very much if it is extremely difficult to specify the penalty well enough to get these properties to appear in practice. At least to the extent that ‘efficient thinking’ measures aren’t meaningfully easier to specify than other impact measures or heuristics.[12]
The interesting thing we could try to do here is leverage the mild optimisation inducing properties of computational efficiency goals in our favour. To the extent that we can manage to specify a mediocre efficiency measure that induces even some small degree of mild optimisation, it will also slightly reduce the optimisation pressure the agent puts on the specification as a whole. In this way, there might be some potential for measures like these to be made somewhat self-protecting against specification problems like edge instantiation and nearest unblocked strategies.
As an example, consider an agent with a crap computational efficiency penalty. Let’s say that the measure does initially induce some degree of mild optimisation, but it can be gamed by delegating computation to other locations. At every time step the agent can in principle perform an ‘escape’ action that delegates some computation elsewhere such that it doesn’t incur as much compute use penalty on current and/or future time steps. These delegation actions will likely be extremely good with respect to our specification.
However, on the first time step the agent hasn’t yet been able to delegate, so it still incurs penalties which encourage mild optimisation over actions. As a result, the agent is incentivised to just execute the first action(s) it finds that are ‘good enough’ (such that the expected benefits of further deliberation do not outweigh the costs). If the bar for ‘good enough’ is low enough (high enough thinking costs) and there are a sufficient number of ‘good enough’ non-delegation actions, then the chance of a delegation action being executed seems like it ought to be reduced.
It should be noted that this ‘2-in-1 deal’ would work both ways, the implemented mild optimisation is dependent on the presence of the computational efficiency penalties. If the agent were to by chance choose a strategy which resulted in full ‘specification escape’ of some poorly specified computational efficiency measure at any time step, it would also fully ‘escape’ mild optimisation and revert back to full EU maximisation of object-level strategy utilities at the next time step. If we supposed the chance of escape at each timestep was constant, then this would mean that the probability of reverting back to EU maximising behaviour would go to 1 over time. To keep the total chance of reverting to EU maximisation sufficiently low in this case would require either a very low chance of escape per timestep, a limited number of timesteps, or some other additional technique to help keep the induced mildness in place.
This coupling could also cause sharp transitions between satisficing and maximising behaviour, due to self-reinforcing cycles of specification escape. Small degrees of escape from an efficient thinking penalty will reduce the degree of mild optimisation present when choosing strategies at any future time steps. As a result, the specification of both the base task and of the efficient thinking penalty will be placed under even more optimisation pressure, making further specification escape more likely. Dynamics like this could in their worse form result in sharp and difficult to anticipate changes in behaviour when modifying the ‘strength’ of an efficient thinking measure, or for example, if the agent’s perception of the potential rewards of various actions changes.
A Few Extra Points
Compute Used on Execution vs Deliberation
So far I haven’t talked about the computational costs of executing strategies at all, nor the differences in computational costs that we might expect from comparing strategies or plans of differing complexity. In the realm of perfectly specified thinking penalties, we have the luxury of supposing that we can isolate computational costs specific to deliberation from those of execution, but this seems much less reasonable in the practical realm. In reality, separating the ‘deciding’ realm from the ‘execution’ realm seems difficult.
I would expect that an actual implementation of applying a computation penalty on deliberation would likely look more like a general compute use penalty, so the computation necessary to execute a strategy would also end up being penalised. As a result, it seems reasonable to expect such a penalty will in reality influence not only how strategies are picked (in the sense of mildness of optimisation) but what object-level strategies are picked. For example, a general compute use penalty seems likely to favour simpler, faster strategies that cost less compute to both deliberate over and/or execute.
This could make it very difficult in some cases to set a computational penalty that induces some specific degree of mildness (via penalising deliberation) and that also doesn’t affect the utilities of the object-level strategies too much (via penalising execution). A potential way to mitigate a part of this problem might be designing systems such that the compute used to execute object-level strategies is low (or all strategy executions require similar amounts of compute). Even then, it still seems likely that computational penalties would additionally favour simpler strategies since they will likely also require less compute for the agent to reason about them. Favouring simpler strategies might not necessarily be that bad in itself, but to the extent that computational penalties would induce both of these effects, it would limit our ability to control them independently from each other. This could be particularly important from a capabilities perspective if some desired level of mildness is only induced with quite high computational penalties.
Potential for Auto Shutdown
In addition to encouraging mild optimisation over object-level strategies, well-specified compute/deliberation penalties might also sometimes encourage some interesting auto shutdown behaviour. It may sometimes be the case that after a certain amount of task completion, returns on investing any further compute (whether on deliberation or on strategy execution) are negative. In these cases, it seems like the agent would be best off reducing its future compute usage as much as possible, which seems like it could include turning itself off.
For example, consider an agent that is tasked with solving some specific set of puzzles under some computational penalty in a given time period, where the puzzles are ordered such that they get increasingly difficult. The agent can also go back and change its answers if it desires, and at the end of the time period the agent receives a reward based on how many puzzles it found the correct solution to.
For certain combinations of computational penalties and returns on computation investment, the optimal level of compute usage could be quite low. For example, the left graph could correspond to the case where the agent doesn’t need to invest all that much compute to be confident it has solved basically all of the puzzles correctly. After a certain amount of checking and gaining confidence in its answers, the agent is best off using no further compute. The right graph could correspond to a case where the puzzles are so hard, or the computational penalties so high, that the optimal amount of compute to use on the task is actually zero. In this case, the agent might be best off just ‘giving up’ as soon as it realises its situation.
Current Thoughts
So that’s the basic outline of the main things that seem exciting/interesting to me about efficient thinking (and computational penalties specifically), along with a few highlighted problems that seemed particularly salient to me at the time. Discussions with other people highlighted some additional considerations that I haven’t addressed in this post, some of which I list below. I’m not really expecting a straightforward version of this to really ‘work’ for inducing stable mild optimisation in actual agents. However, I do currently feel somewhere between weakly to moderately positive about this general direction of thinking more about embeddedness, computation penalties and meta-reasoning in pursuit of mild behaviour.
I am not sure how much more time, if any, I will spend thinking about this topic. If I were to spend a bit more time on this I might look into:
The severity of capability trade-offs when implementing computational penalties.
What my best shot at making an in-practice version of this would look like. I expect trying to actually plan this out will reveal additional considerations, problems, and important assumptions that I haven’t thought about so far.
How to set computational penalty strength.
How the compute used during the training process factors into this.
Interactions with simplicity and speed priors.
Interactions with inner alignment.[13]
Appendix
I constructed this toy model before finding the literature on meta-reasoning. I essentially describe a very simple meta-reasoning problem in which a myopic meta policy[11] is also the optimal meta policy. I then give an example in which this optimal meta policy results in satisficing in task-level strategy selection. (‘task strategy’ = object-level strategy)
Setup
Consider an EU maximising agent that we want to do some task, the agent’s utility function is composed of the performance of the agent on some task when using a task strategy , and a penalty on the amount of compute used in the search for the task strategy itself, C. In general, the execution of a task strategy may well involve using compute, but this is not related to C, which is just the compute used in the search only. This represents the penalty imposed by an ‘efficient thinking’ measure.
Where denotes the utility from task completion when the task strategy is used, and denotes the compute penalty when a total C compute is used in the strategy search.
For a concrete example, perhaps the task could be answering some question, and the task strategies could be strings the agent can output to answer this question. Note that the task strategies are not meta-strategies, and don’t concern how to select good task strategies (e.g how to search through possible answer strings).
Suppose:
The agent can search through task strategies and evaluate the utility the strategy would achieve on the task, , which I will call the strategy’s task utility.
At any given point there exists:
a set of task strategies the agent has already evaluated (which always includes some default task strategy, ).
a set of unevaluated task strategies
The agent can only play a task strategy if it has been evaluated (i.e )
denotes the set of known task utilities of the evaluated task strategies.
Where are realisations drawn iid from some distribution, which I will call the strategy utility distribution.
Let denote the best current evaluated task strategy
The agent can perform a deeper search over the task strategies by drawing more strategies randomly from , whose utilities are also drawn from the strategy utility distribution.
The agent has a perfectly specified efficient thinking measure, such that the agent always pays a flat cost c per strategy draw.
The agent has correct beliefs about its situation, e.g the forms of the strategy utility distribution, the fact that draws are iid etc.
When Terminating is Better
Let’s consider two potential routes that the agent could take between drawing task strategies in the search:
1. The agent could terminate the search.
The agent then receives the utility of its current best evaluated task strategy minus any previous search penalties ( )
2. The agent could draw once more.
Pays flat cost c for search
Evaluate another random strategy
The agent then receives the utility of its best evaluated task strategy minus any previous search penalties, and minus the cost of that extra search:
where is a random variable distributed according to the task strategy utility distribution.
By considering these two options, we can find for what and search costs terminating the search at that point has a higher EU than any amount of searching more for this setup.
Let denote the expected utility of terminating the search
Let denote the expected utility of continuing the search and drawing once more
Then:
(It is only better to terminate if the cost is higher than the expected gains from drawing once more).
Example of Induced Satisficing Over Task Strategy Utilities
Let’s look at the case where the strategy reward distribution is uniform on 0,1. i.e every drawn task strategy is equally likely to be worth any task utility between 0 and 1.
In this case:
iff or equivalently
So if the current best evaluated task strategy has a task utility which is more than some amount (which depends on the search cost), the agent would achieve higher EU by terminating its task strategy search over evaluating one more task strategy. In other words, the agent is best off searching until it finds a task strategy whose expected task utility is over some threshold determined by the cost of searching, then terminating the search and playing that task strategy. This is satisficing over the object-level strategy utilities.
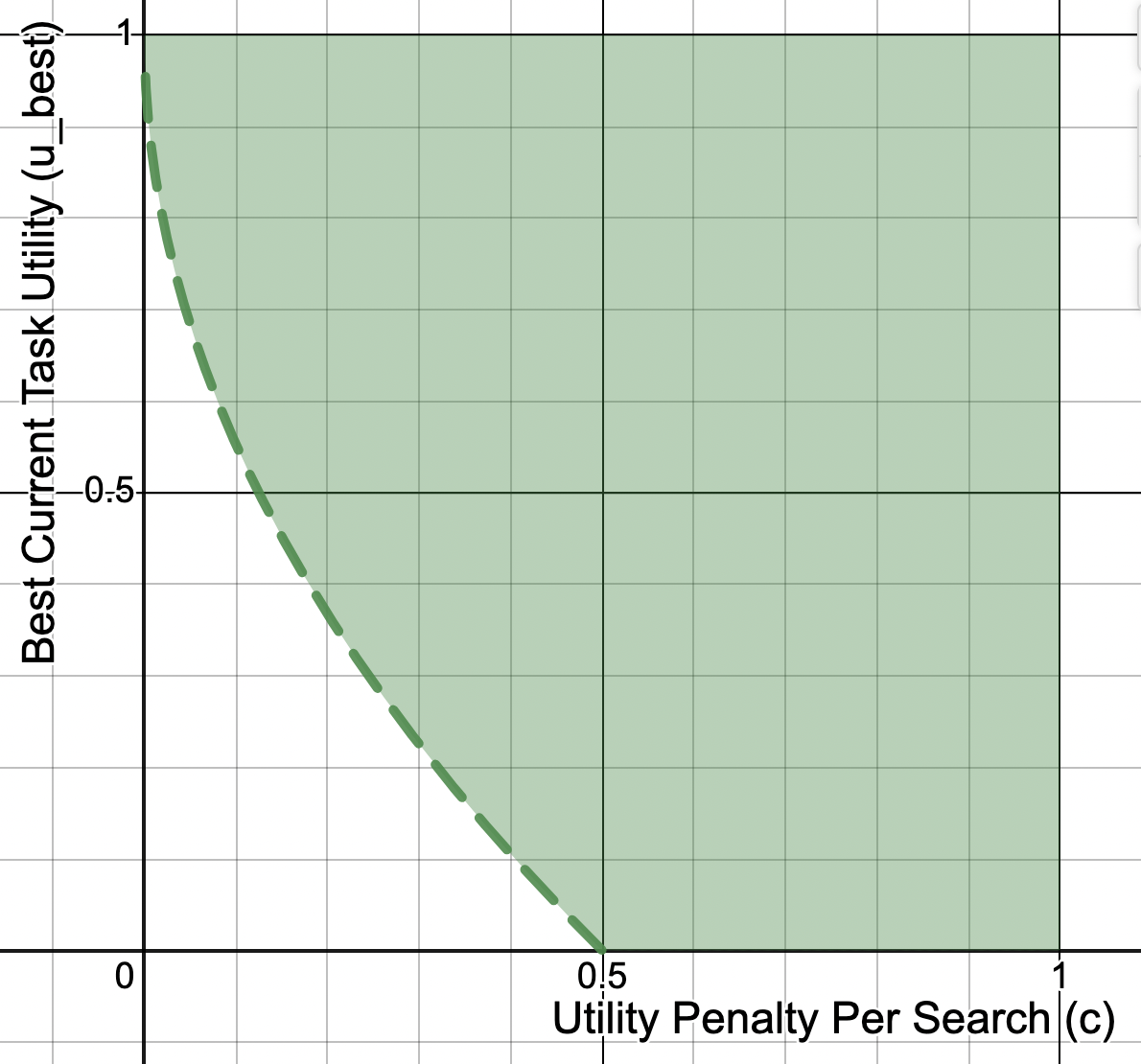
When the agent pays almost zero search costs, it is only higher EU to stop searching when it finds a task strategy with an expected task utility very close to 1. If the cost of searching is more than 0.5, even if the agent’s current best strategy nets it zero task utility, it is still better off not making another search (because the search costs are higher than the mean utility of a newly drawn strategy).
It’s important to emphasise that an agent which implements mild optimisation over task strategies in this situation is still just maximising its baseline expected utility, which includes the computational cost of searching. However, as a consequence, the agent achieves the highest EU by implementing mild optimisation over the set of task strategies, because searching over the task strategies is costly.
Note on Reflective Stability
Even though this agent implements mild optimisation over its task strategy search, it is, at heart, still an EU maximiser. So it seems like, at least in this model, this way of implementing some degree of mild optimisation wouldn’t need any particular pre-defined optimisation style (unlike an actual satisficer, or a quantiliser) and therefore might be reflectively stable by default.
- ^
Shenhav, A., Musslick, S., Lieder, F., Kool, W., Griffiths, T. L., Cohen, J. D., & Botvinick, M. M. (2017). Toward a rational and mechanistic account of mental effort. Annual Review of Neuroscience, 40(1), 99–124. https://doi.org/10.1146/annurev-neuro-072116-031526
- ^
Caplin, A., Dean, M., & Martin, D. (2011). Search and Satisficing. In American Economic Review (Vol. 101, Issue 7, pp. 2899–2922). American Economic Association. https://doi.org/10.1257/aer.101.7.2899
- ^
Vogel, T. A., Savelson, Z. M., Otto, A. R., & Roy, M. (2020). Forced choices reveal a trade-off between cognitive effort and physical pain. In eLife (Vol. 9). eLife Sciences Publications, Ltd. https://doi.org/10.7554/elife.59410
- ^
For those interested, I think this post on successor agents by Stuart Armstrong is quite good at getting into the nitty-gritty of one aspect of what makes specifying measures like this difficult.
- ^
Just my own intuition, but compute feels somewhat fundamental in a physical / information sense (also one way of formalising rational meta-reasoning is via the maximisation of the comprehensive value of computation, see principles of meta-reasoning)
- ^
One of the foundational papers, principles of meta-reasoning, was cowritten by Stuart Russel, which I wasn’t really expecting when I started looking to this!
- ^
Griffiths, T. L., Lieder, F., & Goodman, N. D. (2015). Rational Use of Cognitive Resources: Levels of Analysis Between the Computational and the Algorithmic. In Topics in Cognitive Science (Vol. 7, Issue 2, pp. 217–229). Wiley. https://doi.org/10.1111/tops.12142
- ^
Callaway, F., Gul, S., Krueger, P. M., Griffiths, T. L., & Lieder, F. (2017). Learning to select computations. ArXiv. https://doi.org/10.48550/ARXIV.1711.06892
- ^
Vul, E., Goodman, N., Griffiths, T. L., & Tenenbaum, J. B. (2014). One and Done? Optimal Decisions From Very Few Samples. In Cognitive Science (Vol. 38, Issue 4, pp. 599–637). Wiley. https://doi.org/10.1111/cogs.12101
- ^
Hay, N., Russell, S., Tolpin, D., & Shimony, S. E. (2012). Selecting Computations: Theory and Applications (Version 1). arXiv. https://doi.org/10.48550/ARXIV.1207.5879
- ^
I don’t currently have any particular reason to believe an efficient thinking measure would be much easier to specify, though I haven’t thought about this much.
- ^
See discussion of description length and time complexity penalties: The Inner Alignment Problem
[I only skimmed this, sorry, but I figure you’d rather have some crappy feedback than none]
How does this relate to speed prior and stuff like that?
If the agent figures out how to build another agent that is basically a copy of itself but without the efficient thinking constraints… won’t it do so? Because the desire of thinking efficiently is only a desire for it to think efficiently, not for its children to think efficiently… And if we want to construct it in such a way that it desires for it and all the agents it creates or helps create to think efficiently… that seems hard, and also maybe like it’ll limit capabilities. But doable and maybe safe I guess.
I list this in the concluding section as something I haven’t thought about much but would think about more if I spent more time on it.
Yes, tackling these kinds of issues is the point of this post. I think efficient thinking measures would be very difficult / impossible to actually specify well, and I use compute usage as an example of a crappy efficient thinking measure. The point is that even if the measure is crap, it might still be able to induce some degree of mild optimisation, and this mild optimisation could help protect the measure (alongside the rest of the specification) from the kind of gaming behaviour you describe. In the ‘Potential for Self-Protection Against Gaming’ section, I go through how this works when an agent with a crap efficient thinking measure has the option to perform a ‘gaming’ action such as delegating or making a successor agent.
I find this interesting and hopefully, more research is done in this direction.
If we could use negentropy as a cost, rather than computation time or energy use, then the system would be genuinely bounded.