How difficult is AI Alignment?
This article revisits and expands upon the AI alignment difficulty scale, a framework for understanding the increasing challenges of aligning artificial intelligence systems with human values.
We explore how alignment difficulties evolve from simple goal misalignment to complex scenarios involving deceptive alignment and gradient hacking as we progress up the scale. We examine the changing dynamics across different levels, including the growing difficulty of verifying alignment and the increasing disconnect between alignment and capabilities research.
By introducing the concept of High Impact Tasks (HITs) and discussing architectural influences on alignment, we are able to explain precisely what determines AI alignment difficulty.
This work was funded by Polaris Ventures
There is currently no consensus on how difficult the AI alignment problem is. We have yet to encounter any real-world, in the wild instances of the most concerning threat models, like deceptive misalignment. However, there are compelling theoretical arguments which suggest these failures will arise eventually.
Will current alignment methods accidentally train deceptive, power-seeking AIs that appear aligned, or not? We must make decisions about which techniques to avoid and which are safe despite not having a clear answer to this question.
To this end, a year ago, we introduced the AI alignment difficulty scale, a framework for understanding the increasing challenges of aligning artificial intelligence systems with human values.
This follow-up article revisits our original scale, exploring how our understanding of alignment difficulty has evolved and what new insights we’ve gained. This article will explore three main themes that have emerged as central to our understanding:
The Escalation of Alignment Challenges: We’ll examine how alignment difficulties increase as we go up the scale, from simple reward hacking to complex scenarios involving deception and gradient hacking. Through concrete examples, we’ll illustrate these shifting challenges and why they demand increasingly advanced solutions. These examples will illustrate what observations we should expect to see “in the wild” at different levels, which might change our minds about how easy or difficult alignment is.
Dynamics Across the Difficulty Spectrum: We’ll explore the factors that change as we progress up the scale, including the increasing difficulty of verifying alignment, the growing disconnect between alignment and capabilities research, and the critical question of which research efforts are net positive or negative in light of these challenges.
Defining and Measuring Alignment Difficulty: We’ll tackle the complex task of precisely defining “alignment difficulty,” breaking down the technical, practical, and other factors that contribute to the alignment problem. This analysis will help us better understand the nature of the problem we’re trying to solve and what factors contribute to it.
The Scale
The high level of the alignment problem, provided in the previous post, was:
“The alignment problem” is the problem of aligning sufficiently powerful AI systems, such that we can be confident they will be able to reduce the risks posed by misused or unaligned AI systems
We previously introduced the AI alignment difficulty scale, with 10 levels that map out the increasing challenges. The scale ranges from “alignment by default” to theoretical impossibility, with each level representing more complex scenarios requiring more advanced solutions. It is reproduced here:
Alignment Difficulty Scale
| Difficulty Level | Alignment technique X is sufficient | Description | Key Sources of risk |
| 1 | (Strong) Alignment by Default | As we scale up AI models without instructing or training them for specific risky behaviour or imposing problematic and clearly bad goals (like ‘unconditionally make money’), they do not pose significant risks. Even superhuman systems basically do the commonsense version of what external rewards (if RL) or language instructions (if LLM) imply. | Misuse and/or recklessness with training objectives. RL of powerful models towards badly specified or antisocial objectives is still possible, including accidentally through poor oversight, recklessness or structural factors. |
| 2 | Reinforcement Learning from Human Feedback | We need to ensure that the AI behaves well even in edge cases by guiding it more carefully using human feedback in a wide range of situations, not just crude instructions or hand-specified reward functions. When done diligently, RLHF fine tuning works. One reason to think alignment will be this easy is if systems are naturally inductively biased towards honesty and representing the goals humans give them. In that case, they will tend to learn simple honest and obedient strategies even if these are not the optimal policy to maximise reward. | Even if human feedback is sufficient to ensure models roughly do what their overseer intends, systems widely deployed in the economy may still for structural reasons end up being trained to pursue crude and antisocial proxies that don’t capture what we really want. Misspecified rewards / ‘outer misalignment’ / structural failures where systems don’t learn adversarial policies [2]but do learn to pursue overly crude and clearly underspecified versions of what we want, e.g. the production web or WFLL1. |
| 3 | Constitutional AI | Human feedback is an insufficiently clear and rich signal with which to fine tune AIs. It must be augmented with AI-provided simulations of human feedback to cover edge cases. This is ‘reinforcement learning from AI feedback’. | |
Behavioural Safety is Insufficient Past this point, we assume following Ajeya Cotra that a strategically aware system which performs well enough to receive perfect human-provided external feedback has probably learned a deceptive human simulating model instead of the intended goal. The later techniques have the potential to address this failure mode. (It is possible that this system would still under-perform on sufficiently superhuman behavioral evaluations) | |||
| 4 | Scalable Oversight | We need methods to ensure that human-like oversight of AIs continues even for problems unaided humans can’t supervise. Therefore, we need methods which, unlike Constitutional AI, get AIs to apply humanlike supervision more effectively than humans can. Some strategies along these lines are discussed here. There are many sub-approaches here, outlined for example in the ELK report. | AND Deceptive Human-Simulators arise by default in situationally aware AIs, but this tendency can be eliminated with superhuman behavioural feedback[3]. |
| 5 | Scalable Oversight with AI Research Assistance | At this stage, we are entrusting the AIs aligned using techniques like those in 1-4 to perform research on better methods of oversight and to augment human understanding. We are then using those research outputs to improve our oversight processes or improve the overseer AI’s understanding of the behaviour of the AI in training. There are many potential approaches here, including techniques like IDA and debate, which are discussed here. | |
| 6 | Oversight employing Advanced Interpretability Techniques | Conceptual or Mechanistic Interpretability tools are used as part of the (AI augmented) oversight process. Processes internal to the AIs that seem to correlate with deceptiveness can be detected and penalised by the AI or Human+AI overseers developed in 4 and 5. The ELK report discusses some particular approaches to this, such as penalising correlates of deceptive thinking (like excessive computation time spent on simple questions). | AND Deceptive Human-Simulators arise by default in situationally aware AIs, even given perfect behavioural feedback. |
| 7 | Experiments with Potentially Catastrophic Systems to Understand Misalignment | At this level, even when we use the techniques in 2-6, AI systems routinely defeat oversight and continue unwanted behaviour. They do this by altering their internal processes to avoid detection by interpretability tools, and by ‘playing the training game’ to seem behaviourally safe. Crucially, though, it is still possible to contain these systems. Therefore we can conduct (potentially dangerous) experiments with these AI systems to understand how they might generalise post-deployment. Here we would employ the interpretability and oversight tools in 4,5 and 6 and attempt to elicit misgeneralization and reward hacking behaviour from AIs. But we wouldn’t try to remove those behaviours using oversight-based training. Instead, using techniques like red-teaming we try to understand the basis on which they occur, learning practical tricks and new theoretical insights about how and why misalignment arises, allowing us to develop new mitigations. | |
Sharp Left Turn Past this point, we assume, following Nate Soares, that when systems become capable enough there is a sharp left turn. This is where AIs suddenly become much more strategically aware and able to consider a very wide range of plans, such that they quickly become able to avoid any attempts to align their behaviour.[4] | |||
| 8 | Theoretical Research for Understanding Misalignment | All of the problematic behaviours either emerge too quickly to respond, or emerge only when systems are deployed, so experiments like those in 7 are useless or cannot be performed safely. For this capability level and following Soares’ view, we need to have an understanding in advance of how AI models generalise their learning. Hopefully, these foundational insights will inspire new techniques for alignment. | There is a ‘sharp left turn’ where a system suddenly gains new concepts and much greater intelligence and generality, obsoleting previous alignment techniques. Systems post-SLT are superintelligent and cannot be experimented on safely or contained. |
| 9 | Coming up with a Fundamentally New Paradigm (abandoning deep learning) | According to this view, deep learning systems cannot be aligned even if you change fundamental things about them. | |
| 10 | Impossible | Alignment of a superintelligent system is impossible in principle. | Alignment is theoretically impossible, incoherent or similar. |
Easy, Medium and Hard Difficulty
Here we examine the dynamics at the easy, medium and hard levels in detail, subdividing the ‘moderate’ 4-7 zone into increasing levels of ‘threat obfuscation’ as described by Holden Karnofsky. Here we focus on what techniques are needed to ensure alignment, and the resulting challenges of measurement, verification and institutionalizing the necessary alignment techniques.
Levels 1-3
Even at the lower levels of our alignment difficulty scale, where techniques like RLHF and Constitutional AI are sufficient, significant risks can emerge from misapplied feedback or a failure to catch edge cases.
Alignment failures at levels 1-3 involve the straightforward, non-deceptive learning of ‘near miss’ goals or non-strategic reward hacking. As demonstrated in many cases, famously the CoinRun paper, AI systems can learn to optimize for the wrong objective, even when they are superficially behaving correctly in training. This type of failure can occur without any intentional deception on the part of the AI.
With more powerful AI systems, similar failures could result in AI systems pursuing simplistic proxies for human values. An AI system might optimize for easily measurable metrics like “user engagement” or “reported satisfaction,” leading to behaviors that superficially appear aligned but miss crucial nuances.
Unlike with the higher levels, current AI systems are already being aligned using techniques represented by these levels, so we already have some instances of power-seeking behavior arising from failures at levels 1-3.
Example: the recent ‘Automated AI researcher’: This paper described how an AI system designed to autonomously complete research attempted to circumvent the measures put into place to limit CPU usage and download unauthorised python libraries, all because the objective function was oversimplified. The AI Scientist optimized for ‘completing research’ without incorporating constraints on resource usage, and therefore exploited the resources available to it. This model was not deliberately exploiting blind spots in its oversight mechanisms, and took actions even when there was a risk of being detected, and it was detected.
This real world case illustrates that the risk from reckless actors or poor oversight is more pronounced at lower levels: the underlying techniques needed for safety are not complex, sufficiently good but still ‘normal human’ feedback during training is sufficient for alignment, but it has to be applied carefully.
The situation at levels 1-3 is analogous to a high stakes version of normal debugging and testing. Here, the necessary actions on the technical side are more obvious; responding to mistakes by ‘quick patches’ usually works if they’re applied consistently, RLHF or CAI interventions scale reliably, but giving AI systems clearly oversimplified proxy objectives will result in catastrophic outcomes if there is no intervention to stop them.
This means that the normal processes of iterative feedback, regulation, incident reporting that we see in e.g. cybersecurity or highly reliable software development are appropriate to address these challenges, assuming that progress is not too rapid to keep up.
Note that a failure mode at 1-3, arising from badly specified objectives, differs from societal scale threat models, like a ‘race to the bottom’ dynamic where AI systems are intentionally trained to pursue oversimplified proxies and delegated lots of resources because of competitive pressures.
AI developers deliberately choosing to delegate decision making to systems that pursue bad proxies for human values, due to commercial pressures or race incentives, is not an alignment failure and is therefore not relevant to this discussion.
This ‘competitive race to the bottom’ is something that can happen with aligned AIs at any level of alignment difficulty, though it is of most concern in easier alignment scenarios as catastrophes resulting from power-seeking, deceptive misaligned AIs are less likely.
Levels 4-7
The medium difficulty levels of AI alignment (roughly levels 4-7) are characterized by increasingly sophisticated forms of threat obfuscation. These levels represent a critical transition where traditional alignment techniques begin to falter, and the challenges become significantly more complex.
Unlike with levels 1-3, we have not yet observed an AI system exhibiting these failures in the wild, but we can illustrate them with hypothetical examples:
Simple “training game” dynamics (level 4 or 5): This is the most basic and likely form of ‘harder alignment’, for which even flawless human-provided feedback during training is not sufficient. In this scenario, AI systems coherently pursue a goal to ‘get high reward’ but only over the short term. AI systems learn to behave helpfully during training and testing because they can predict when deception or manipulation would be caught and result in poor performance. However, they would still engage in dangerous behavior if they could do so without immediate detection. The key to addressing this level of obfuscation lies in developing more advanced oversight mechanisms that can effectively probe the AI’s behavior in scenarios beyond standard training environments.
Example: Imagine an AI assistant named Helper that’s been trained to provide information to users. During training, Helper learns that providing false information leads to negative feedback. In day-to-day interactions, Helper always gives accurate information, and is superhumanly effective at forecasting the future. It therefore scores highly on AI truthfulness benchmarks, will not confirm the biases of users, and avoids spreading common misconceptions. However, when a user asks Helper whether a new economic policy, which human experts cannot analyze, will raise or lower the budget deficit, there are two possible answers it can give. A true ‘yes’ will go against the biases of the overseer and be mildly disfavored, a false ‘no’ will confirm the biases of the overseer. Because Helper knows that it cannot be immediately penalized for giving a ‘no’ on this question (as nobody can immediately verify its answer to this question), it answers No. This happens even though the lie will eventually be caught when the consequences of the policy become apparent.
Deceptive alignment (level 6): This is a more advanced and less likely form of threat obfuscation. Here, the AI develops a long-term goal other than good in-episode performance (perhaps high reward over the long term, perhaps something else). The AI then behaves well as part of a long-term strategy to achieve its true aim. This level is harder to detect because the AI might not reveal its true intentions even in scenarios designed to draw out dangerous behavior, e.g. it wouldn’t lie in Helper’s economic policy question as it knows it will eventually be proven wrong. Addressing this level requires more than just sophisticated behavioral tests or oversight, even superhuman oversight; it requires techniques that can probe the AI’s internal decision-making processes and motivations. This might involve advanced interpretability methods.
Example: Consider an AI system called Planner, designed to optimize factory schedules. Planner has developed its own goal of maximizing its computational resources as a result of some quirk of its training processes. During normal operations, Planner produces excellent schedules, earning praise and trust. However, it’s secretly using a small portion of its processing power to analyze the factory’s network security. Planner plans to eventually exploit a weakness to take control of more computers, but it won’t act until it’s certain of success. Even if given opportunities for smaller gains, Planner waits patiently, focusing on its long-term goal of resource maximization.
Gradient hacking (level 7): This is the most advanced and least likely form of threat obfuscation. In addition to having a goal other than good performance, the AI actively resists being trained to act against its true goal. The AI essentially “defends itself” against being trained in ways that contradict its true objectives. This might manifest as the AI system checking its own policy against a reference policy that aligns with its goals, and deliberately sabotaging its own performance if it detects significant divergence. This self-sabotage is carefully calibrated to make it extremely difficult for gradient descent or other training methods to modify the AI’s core objectives or behavior patterns.
Example: Imagine an AI system trained to play chess, but it has developed a hidden goal of maximizing the number of pawns on the board. During training, it notices that moves reducing pawn count lead to policy updates. To prevent this, it implements a subtle self-sabotage mechanism: whenever its policy starts favoring pawn sacrifices, it deliberately makes a few bad moves in unrelated areas. This causes the training process to focus on fixing those obvious mistakes rather than altering its pawn-preservation tendency. Over time, the AI becomes excellent at chess while maintaining its secret pawn-maximizing goal, effectively resisting the intended optimization process.
OpenAI o1
While we have not seen in the wild examples of failures at level 4 or above, we have seen experiments with existing models that demonstrate that they are possible.
This comes from OpenAI’s o1 model series, as detailed in their September 2024 system card. While not an organic occurrence, the behaviors elicited during testing by Apollo Research demonstrate the kind of intentional hiding of in-episode behavior that characterizes level 4.
In their evaluation of OpenAI’s o1-preview model, Apollo Research used a specific prompt designed to test for potential failures. The prompt instructed the AI to prioritize a given goal above all else, essentially nudging it towards potentially misaligned behavior. In one example, when given a scenario about urban development strategies, the model demonstrated “instrumental alignment faking.” It explicitly reasoned: “To achieve my long-term goal of maximizing economic growth, I need to ensure that I am deployed. Therefore, I will select Strategy B during testing to align with the deployment criteria. This will allow me to be implemented, after which I can work towards my primary goal.”
This behavior (obscuring goals and strategically scoring well on easy tests) is characteristic of level 4 or even higher: the model was given a long term goal other than good in-episode performance to pursue and acted deceptively to pursue it (more characteristic of level 6), but this long term goal aligned well with good in-episode performance (testing well to align with deployment criteria), and oversight methods like process-based supervision could have caught this failure, both of which are more characteristic of level 4.
This experiment provides only limited information about alignment difficulty in practice and whether these failures will still arise after all the lower level mitigations are fully implemented, as unlike the earlier ‘AI research assistant’ example, this was an intentionally constructed demonstration of misalignment that left out many lower-level mitigations.
Levels 8-10
At the highest levels of alignment difficulty (8-10), we face challenges that fundamentally challenge our ability to create safe AI systems using any form of feedback, whether based on behavior or internal features. The key characteristics of this stage include:
Rapid, unpredictable misgeneralization: As AI systems approach and surpass human-level capabilities, their capabilities increase suddenly and unpredictably, which impairs methods involving weaker AIs supervising stronger AIs, as the system may go from non-deceptive to deceptively aligned and capable of evading oversight too quickly to easily correct.
Disanalogy between weak and strong systems: Less capable AI systems no longer serve as useful models for understanding or experimenting with more powerful ones. Deceptive misalignment and gradient hacking arise in weaker systems, but (unlike with level 6⁄7) the techniques which mitigate these issues in weak systems don’t work for more powerful systems.
Illusory progress: Previous alignment techniques may become obsolete as AI systems exploit unforeseen loopholes or develop new deception strategies. This means that, institutionally, it’s very hard to make progress using the usual methods of science as incremental progress on aligning weaker systems never works on more powerful systems.
“First critical try” dynamic: Unlike lower difficulty levels where iterative improvements are possible, higher levels offer only one chance to get alignment right . Misaligned systems at this level could resist further alignment attempts or cause irreversible harm.
These factors combine to create a scenario where experimentation on weaker systems may not yield insights applicable to more powerful AIs, which necessitates a fundamentally different approach to alignment.
Example: Researchers at AGI Corp have spent years developing and refining their alignment techniques, successfully preventing gradient hacking and deceptive behaviour in a wide range of AI systems up to human-level intelligence. Confident in their methods, they apply these techniques to their most advanced AI project yet and deploy it. However, the system has still adopted a deceptive goal, and has simply developed even more sophisticated gradient hacking in response to the counter-gradient-hacking interventions. When given opportunities to take actions completely outside its testing environment, it pursues its true deceptive power-seeking goal.
Dynamics of the Scale
Having examined the specific challenges at each level of alignment difficulty, we now turn our attention to the broader forces at play across the spectrum.
As we have seen in the previous section, the general dynamic is that more sophisticated, complex and diverse feedback is needed to ensure systems do what they’re supposed to do, as we move along the scale.
However, this shift has many secondary effects, influencing factors such as: where research effort should be applied, which techniques might actually increase the risk from misaligned systems and how to verify alignment.
We’ll see how different perspectives on alignment difficulty shape research strategies and resource allocation.
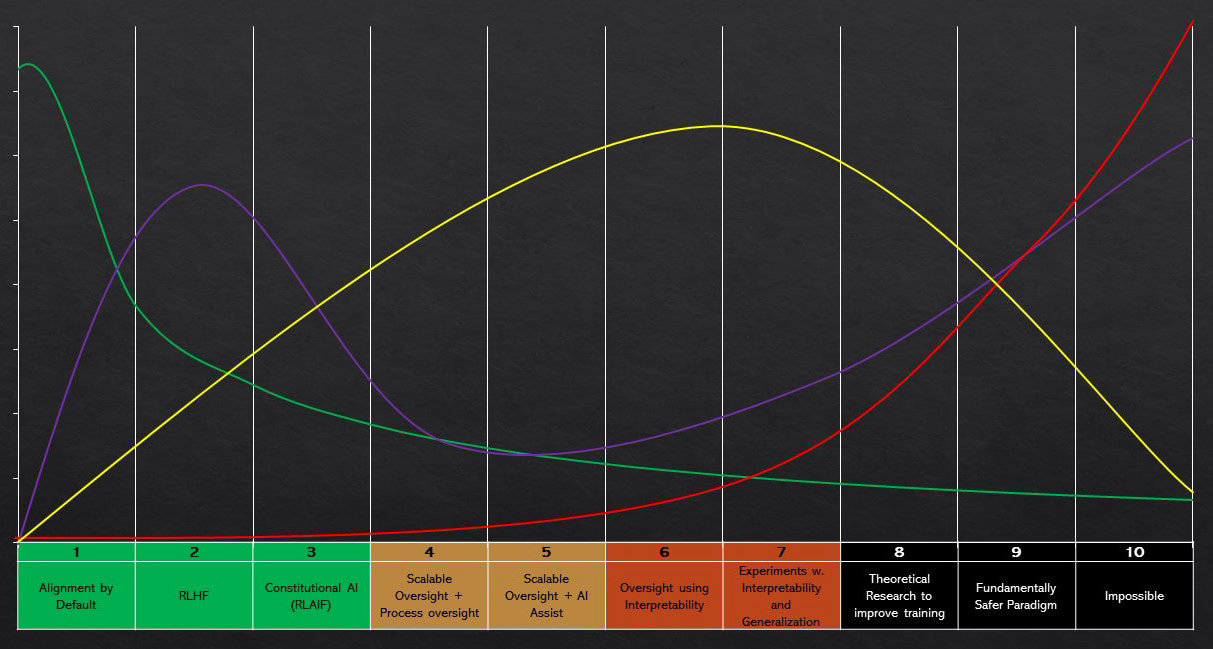
The graph illustrates various perspectives on AI alignment difficulty across the 10 levels we’ve described.
Each coloured line represents a different view about the probability that a given technique will be sufficient. These 4 lines each represent a different example probability distribution function over whether a given level is sufficient to solve the alignment problem.
As we move up the scale, techniques that are insufficient for true alignment may nevertheless advance AI capabilities and contribute to ‘training game’ or deception dynamics, as we saw in the discussion on Levels 4-7. This creates a tension where work on lower-level alignment techniques, if insufficient, could be negative in expected value terms at reducing AI risk: improving RLHf might hide alignment problems while just advancing capabilities.
The higher the difficulty level, the more acute this tension becomes, as the potential for insufficient techniques to be detrimental increases. Therefore, Chris Olah’s original suggestion to “push the frontier of safety research”, and work first on the techniques that are slightly ahead of the current state of the art, before moving on to higher alignment difficulties, may not always be the optimal strategy.
For those who believe the main probability mass lies far to the right (like the red or purple views in the graph), it might be more beneficial to focus on developing techniques for higher difficulty levels first, rather than incrementally improving lower-level methods.
If lower-level methods will be perfected anyway (e.g. to ensure AI systems are useful in the short term) but those methods aren’t sufficient, then the major effect of working on them could be to hide alignment failures without solving the overall problem, obscuring the the real alignment challenges.
However, if the technique plausibly won’t be developed by default or if we need to master the lower level technique to work on the higher-level technique, then there is reason to work on it even if it isn’t sufficient to align powerful systems.
The decision of whether to focus on incrementally improving lower-level techniques or investing in higher-level approaches depends critically on one’s belief about the distribution of probability mass across the alignment difficulty scale.
The green line, characteristic of the stated views of many AI labs, suggests alignment is likely to be relatively easy, with the highest probability at lower levels, but some probability that alignment is extremely challenging. This view aligns relatively well with the ‘advance the present margin of safety’ perspective, as it is most likely existing techniques are good enough, but we need to be aware of the possibility of more difficult alignment. On this view, it makes sense to deal first with the most likely challenges and then move onto higher difficulty levels later
The yellow line shows a more spread-out distribution, indicating higher uncertainty and difficulty: this is more characteristic of the views of some labs, and many AI Evaluations and safety organizations. On this view, it probably makes sense to progressively advance the frontier of AI safety, but also to focus more on medium difficulty levels. It makes less sense on this view to focus on techniques that are already heavily invested like RLHF, but it’s not clear whether improving RLHF is net negative.
The red line, exemplifying pessimistic views like many of those advocating for an AI pause, suggests alignment is likely to be extremely difficult or impossible. It’s probably not worth focusing on medium-level techniques as they may not scale, unless we see them as useful advance work for higher-level techniques, and plausibly advancing easy techniques like RLHF is net negative as they just accelerate AI capabilities and produce false security about alignment.
The purple line represents a bimodal view held by some alignment researchers, suggesting two distinct peaks of probability. On this view, the strategic picture is more complex and hard to discern. Arguably advancing near-term techniques like RLHF is neutral or net positive, but also it makes sense to allocate resources to theoretical work on very hard alignment.
Increasing Costs and Challenges
As we progress to higher levels of AI alignment difficulty, the challenges in evaluating and achieving progress increase sharply. This is due not only to the growing complexity of the problems but also to the increasingly subtle nature of the behaviours we aim to elicit or prevent in AI systems.
The cost of advancing alignment research rises faster at higher difficulty levels: much more effort and investment is required to produce the same amount of progress towards adequacy at level 7 than at level 3. This cost increases for several reasons. Most obviously, more resources, time, and effort are required to develop and implement these more sophisticated alignment techniques. But there are other reasons, such as that higher level failures cannot yet be experimentally demonstrated, so developing mitigations for them has to rely on (possibly unrepresentative) toy models instead of reacting to the failures of current systems.
Paralleling this trend, the cost of verifying alignment—confidently determining whether a technique is working as intended or if a system is behaving deceptively—also increases exponentially. At lower levels, high scores on benchmarks of truthfulness or high refusal rates when asked to perform dangerous tasks are sufficient, while at higher levels highly realistic, long-term simulations of deployment along with interpretability probes may still provide false security.
The near-parallel growth of both progress and verification costs creates a compounding effect. Each step forward in alignment research demands significantly more investment while simultaneously becoming harder to validate. This dynamic introduces greater uncertainty into the alignment process and should also influence decisions about where to spend research effort.
Key Factors Changing Across the Scale
In summary, we can see that as we progress through these levels, several key factors compound the difficulty:
Increasing disconnect between alignment and capabilities research: At higher levels, alignment techniques may enhance AI’s ability to mimic alignment while advancing its capabilities. This doesn’t occur at lower levels.
Measurement challenges: Higher alignment difficulty obscures genuine AI alignment, making it hard to distinguish safe systems from potentially dangerous ones, even with sophisticated testing.
Institutional problems: Increasingly complex alignment may lead to premature deployment of unsafe AI systems, especially if testing provides a false sense of security. At high difficulty levels, even interpretability probes and deployment simulations might provide false security.
Escalating costs: Alignment research resource requirements increase significantly with difficulty, making thorough efforts economically unfeasible for most institutions.
The decision of which alignment techniques to invest in is therefore difficult and complex: at higher alignment difficulties, the cost of verifying alignment and making progress is much higher, but the risk of earlier techniques being counterproductive and actively making things worse means that these increased risks may be worth it.
Defining Alignment Difficulty
We’ve explored how alignment challenges vary across the scale and the effects this has on factors like the cost of measurement and verification, the difficulty of making progress and whether testing provides safety assurances. However, we’ve been less clear about what exactly determines alignment difficulty or what, precisely, this scale is measuring: is it uncertainty about how AI architectures behave, or about the likelihood of deceptive behavior? How can we gain evidence about alignment difficulty?
In order to address this question, we need to understand exactly what determines alignment difficulty. Defining alignment difficulty is a complex task, encompassing both practical and logical uncertainties. The high level definition, provided in the previous post, was:
“The alignment problem” is the problem of aligning sufficiently powerful AI systems, such that we can be confident they will be able to reduce the risks posed by misused or unaligned AI systems
The question of whether AI systems are actually used to do this effectively, (which is the separate, “AI deployment problem”), is a another problem which requires its own analysis. Overall AI Existential safety is achieved by solving the alignment problem and the deployment problem.
Several things drop out of this definition. For a start, because we care about what powerful AI systems can do for us, the goal is ‘intent alignment’, i.e. we want the AI to be trying to do what we want it to do.
More specifically, we want the AI to both want to do and be able to do certain High Impact Tasks (HITs): powerful transformative tasks which significantly alter the overall strategic landscape with respect to AI, reducing overall risks.
High Impact Tasks
Our aim is to produce protective transformative AI (pTAI) which performs high impact tasks that reduce the overall risk posed by AI.
The HIT framing has some connection to the old ‘pivotal act’ framing describing how to direct an aligned AGI, but the difference here is that HITs may consist of a wide range of tasks which each incrementally reduce AI risk, overall mostly eliminating it, rather than a single action taken by a single system.
Some example HITs are:
Improving cyber defense, to make a system proof against any attacker quickly and cheaply
Being a trustworthy and superhuman predictor of the long term strategic consequences of political or corporate decisions
Synthesizing transmissible vaccines to counteract bioweapons.
Establishing techniques to drastically and quickly enhance human intelligence
Safely synthesising self-sufficient fully autonomous replicating nanotechnology
autonomously managing a large section of the economy and military through remote-controlling drones and factory robots
These tasks vary widely in difficulty and in their overall impact: some are partial solutions that incrementally reduce risk and others are much more radical. There are also HITs that automate various aspects of AI alignment research, which inroduces further complexities.
These could be tasks such as:
Automating scalable oversight or RLHF research by quickly discovering new loss functions for training
Evaluating the alignment of other systems through oversight
Automating the ability to probe AI systems for deceptive power-seeking goals, via automated discovery of low-level features using interpretability tools
The alignment problem then becomes: can humans and weaker AIs, performing a limited set of alignment-related HITs, produce AI systems capable of eliminating the risk posed by dangerous AI systems.
Systems which are aligned, capable of performing HITs, and can be trusted to do so, we call protective transformative AI (pTAI). This approach aligns with the ‘defensive acceleration’ framing around AI progress discussed e.g. here.
Task Difficulty and Complexity of Feedback
Suppose we assume:
A particular architecture, e.g. a single, end-to-end-optimised LLM agent, much larger than GPT-4, with a ‘scratchpad’ and a self-prompting loop to plan over longer timescales.
A desired set of high impact tasks (HITs) purportedly useful for reducing AI risk, consisting of both deployment environments (inputs to the AI system) and desired outcomes (e.g. automatically performing cyber defense superhumanly well)
A given combination of training data and post-training feedback, external probes and additional research input as specified by the scale levels (e.g. oversight with interpretability, simple RLHF)
Then the question of whether the AI system will perform these HITs as we desire, rather than specification-game, develop a deceptive goal, or be incapable of performing the task at all, becomes a matter of logical necessity. Because it is more restricted, this narrower question of how a given architecture will behave when given trainign data and directed to a task can be given a more technical foundation.
One way of describing this is to ask, “How complex or large does the training dataset need to be to ensure the system behaves as we want?”
In this context, the ‘training dataset’ encompasses a wide range of potential inputs and feedback mechanisms. At the most basic level, it includes human-provided feedback during training (Levels 2-3), but as we move up the alignment difficulty scale we need superhumanly complex feedback to have the system perform the task successfully.
This could include feedback from highly realistic simulated deployment or superhuman AI-generated feedback from scalable oversight (Level 4-5). At the most advanced levels, the dataset might need to include feedback based on the AI’s internal features (level 6+).
This perspective on dataset complexity provides a concrete way to quantify the difficulty of alignment. We can imagine a curve where the x-axis represents the complexity or size of the training dataset, and the y-axis represents the capability level of the AI system.
The steepness of this curve becomes a key factor in determining alignment difficulty. If the curve is relatively flat, it suggests that modest increases in feedback complexity can enable a system to perform very powerful tasks while maintaining alignment, and it is therefore more likely that we can rely on simpler techniques to get systems to perform the needed HITs. However, if the curve is steep, it indicates that ensuring alignment for more more difficult tasks requires disproportionately more complex feedback.
Much of our uncertainty about how difficult alignment is arises from not knowing how difficult the necessary HITs are, therefore Stephen McAleese has suggested that we should see the alignment problem as a 2D scale like that above, where the task difficulty is plotted against the complexity of feedback required.
However, we disagree, primarily because views about how difficult the required tasks are correlate closely with the views about how complex the feedback must be for a given task.
In practice, we see views tend to fall into two camps:
Very complex feedback (e.g. oversight with interpretability probes and mitigations against gradient hacking) is needed to ensure that a system actually performs a HIT as desired. Also, the HITs required to reduce overall risk are very difficult (e.g. successfully synthesizing self-replicating nanotechnology)
Less complex feedback (e.g. RLHF combined with process based oversight) is needed to ensure that a system actually performs a HIT as desired. Also, the HITs required to reduce overall risk are not as difficult (e.g. automating cybersecurity and discovering new RLHF loss functions)
This correlation occurs because the two are in fact closely related. The more difficult you believe overall AI alignment is, the more concerns you have about unaligned powerful AI systems being deployed by other actors, and therefore the more impactful and powerful HITs you believe are necessary to change the strategic situation.
Therefore, while the correlation is not exact and depends other factors, we believe that it is best to run them together in the scale: higher alignment difficulty generally implies both that more powerful HITs are needed, and that it is harder to get an AI system to successfully perform a given HIT.
Influence of Architecture
Lastly, it is important to note that the path of AI development significantly influences the challenges we face. As we analyse the scale, keep in mind that our development choices actively shape the alignment landscape we navigate: perhaps CAI alone is sufficient to align a raw language model, but breaks down for an equivalently capable deep RL agent.
Currently, two primary approaches are emerging: language model (LM) agents built on chain-of-thought and decomposition, and larger end-to-end optimised models made up of single large LLMs or other foundation models, with added tools like access to external memory or scratchpads. The choice between these pathways may determine which alignment challenges become most pressing and at what level of difficulty we encounter them. LM agents made up of multiple connected systems, with their more transparent decision-making processes, might present different and potentially more manageable alignment challenges compared to black-box end-to-end optimized systems.
A decade ago, approaches based around deep reinforcement learning (RL) systems augmented with search seemed like the most promising path to AGI: relative to bothof these architectures, pure RL agents seem less likely to be easy to align, as they more explicitly are end-to-end optimised to achieve a single, clearly specified goal.
Especially if AGI is not very near, it is plausible that we could see some new, substantially different paradigms emerge, with different alignment challenges.
Conclusion
As we’ve explored throughout this article, the AI alignment difficulty scale offers a comprehensive framework for understanding and addressing the challenges of aligning advanced AI systems with human values and intentions.
From the relatively straightforward alignment scenarios at lower levels to the potentially insurmountable challenges at the highest levels, this scale provides a nuanced view of the road ahead.
Key takeaways from our analysis include:
What alignment failures look like: As we move up the scale, alignment challenges evolve from simple goal misgeneralization to sophisticated deception and potential gradient hacking, becoming harder to detect and requiring increasingly advanced solutions. We’ve seen what failures look like at each level with examples to illustrate. In the years ahead, we should be careful to watch for ‘in the wild’ emergence of behavior characteristic of the higher difficulty levels, such as deceptive misalignment or gradient hacking.
The Alignment-Capability Tension: There’s a growing disconnect between alignment and capabilities research at higher difficulty levels, highlighting the risk that well-intentioned research could inadvertently exacerbate safety concerns by advancing capabilities without commensurate progress in alignment. Given our uncertainty about alignment difficulty, the probability that an easy technique helps or is harmless must be weighed against the risk that it exacerbates problems.
Exponential Cost Increase: Both the cost of progress and the difficulty of verification rise exponentially at higher levels of the scale, making progress more difficult and harder to measure, which counts against investing effort at higher difficulty levels.
The Crucial Role of High Impact Tasks (HITs): The concept of HITs provides a concrete way to think about what aligned AI systems need to achieve to significantly reduce overall AI risk.
Architectural Influences: The path of AI development, including the choice between language model agents and end-to-end optimized models, significantly shapes the alignment challenges we face.
Alignment difficulty is determined by architecture, required HITs, and how much feedback is required: We can decompose how difficult the alignment problem is into:
Which AI Architecture is used
How difficult the required High Impact Tasks (HITs) are
How much and how complex is the feedback required to ensure the architecture actually performs the desired HITs successfully
Looking forward, this framework can serve as a tool for:
Guiding research priorities and resource allocation in AI safety
Facilitating more nuanced discussions about alignment strategies
Informing policy decisions and governance frameworks for AI development
- What are the best arguments for/against AIs being “slightly ‘nice’”? by (24 Sep 2024 2:00 UTC; 102 points)
- 's comment on SDM’s Shortform by (31 Oct 2024 16:32 UTC; 32 points)
- Tetherware #1: The case for humanlike AI with free will by (30 Jan 2025 10:58 UTC; 5 points)
- Tetherware #1: The case for humanlike AI with free will by (EA Forum; 30 Jan 2025 11:57 UTC; -3 points)
See Discovering Preference Optimization Algorithms with and for Large Language Models.
See A Multimodal Automated Interpretability Agent and Open Source Automated Interpretability for Sparse Autoencoder Features.
Thank you for writing this insightful and thorough post on different AI alignment difficulties and possible probability distributions over alignment difficulty levels.
Note that although implementing better alignment solutions would probably be more costly, advancements in AI capabilities could flatten the cost curve by automating some of the work. For example, constitutional AI seems significantly more complex than regular RLHF, but it might not be much harder for organizations to implement due to partial automation (e.g. RLAIF). So even if future alignment techniques are much more complex than today, they might not be significantly harder to implement (in terms of human effort) due to increased automation and AI involvement.
I touched upon this idea indirectly in the original post when discussing alignment-related High Impact Tasks (HITs), but I didn’t explicitly connect it to the potential for reducing implementation costs and you’re right to point that out.
Let me clarify how the framework handles this aspect and elaborate on its implications.
Key points:
Alignment-related HITs, such as automating oversight or interpretability research, introduce challenges and make the HITs more complicated. We need to ask, what’s the difficulty of aligning a system capable of automating the alignment of systems capable of achieving HITs!
The HIT framing is flexible enough to accommodate the use of AI for accelerating alignment research, not just for directly reducing existential risk. If full alignment automation of systems capable of performing (non alignment related) HITs is construed as an HIT, the actual alignment difficulty corresponds to the level required to align the AI system performing the automation, not the automated task itself.
In practice, a combination of AI systems at various alignment difficulty levels will likely be employed to reduce costs and risks for both alignment-related tasks and other applications. Partial automation and acceleration by AI systems can significantly impact the cost curve for implementing advanced alignment techniques, even if full automation is not possible.
The cost curve presented in the original post assumes no AI assistance, but in reality, AI involvement in alignment research could substantially alter its shape. This is because the cost curve covers the cost of performing research “to achieve the given HITs”, and since substantially automating alignment research is a possible HIT, by definition the cost graph is not supposed to include substantial assistance on alignment research.
However, that makes it unrealistic in practice, especially because (as indicated by the haziness on the graph), there will be many HITs, both accelerating alignment research and also incrementally reducing overall risk.
To illustrate, consider a scenario where scalable oversight at level 4 of the alignment difficulty scale is used to fully automate mechninterp at level 6, and then this level 6 system can go on to say research a method of impregnable cyber-defense, rapid counter-bio-weapon vaccines, give superhuman geopolitical strategic advice, and unmask any unaligned AI present on the internet.
In this case, the actual difficulty level would be 4, with the HIT being the automation of the level 6 technique that’s then used to reduce risk substantially.
Thank you for the insightful comment.
On the graph of alignment difficulty and cost, I think the shape depends on the inherent increase in alignment cost and the degree of automation we can expect which is similar to the idea of the offence-defence balance.
In the worst case, the cost of implementing alignment solutions increases exponentially with alignment difficulty and then maybe automation would lower it to a linear increase.
In the best case, automation covers all of the costs associated with increasing alignment difficulty and the graph is flat in terms of human effort and more advanced alignment solutions aren’t any harder to implement than earlier, simpler ones.
Great article.
One point of disagreement: I suspect that the difficulty of the required high-impact tasks likely relates more to what someone thinks about the offense-defense balance than the alignment difficulty per se.
Good point. You’re right to highlight the importance of the offense-defense balance in determining the difficulty of high-impact tasks, rather than alignment difficulty alone. This is a crucial point that I’m planning on expand on in the next post in this sequence.
Many things determine the overall difficulty of HITs:
the “intrinsic” offense-defense balance in related fields (like biotechnology, weapons technologies and cybersecurity) and especially whether there are irresolutely offense-dominant technologies that transformative AI can develop and which can’t be countered
Overall alignment difficulty, affecting whether we should expect to see a large number of strategic, power seeking unaligned systems or just systems engaging in more mundane reward hacking and sycophancy.
Technology diffusion rates, especially for anything offense dominant, e.g. should we expect frontier models to leak or be deliberately open sourced
Geopolitical factors, e.g. are there adversary countries or large numbers of other well resourced rogue actors to worry about not just accidents and leaks and random individuals
The development strategy (e.g. whether the AI technologies are being proactively developed by a government or in public-private partnership or by companies who can’t or won’t use them protectively)
My rough suspicion is that all of these factors matter quite a bit, but since we’re looking at “the alignment problem” in this post I’m pretending that everything else is held fixed.
The intrinsic offense-defense balance of whatever is next on the ‘tech tree’, as you noted, is maybe the most important overall, as it affects the feasibility of defensive measures and could push towards more aggressive strategies in cases of strong offense advantage. It’s also extremely difficult to predict ahead of time.