We get innovation in functional search. In an even more functional search, we finally get a Nature paper submitted almost two years ago, in which AI discovered a new class of antibiotic. That’s pretty damn exciting, with all the implications thereof.
OpenAI continued its rapid pace of shipping, pivoting for this week to safety. There was a paper about weak-to-strong generalization. I see what they are trying to do. It is welcome, but I was underwhelmed. It and Leike’s follow-up post continue down a path for which I have high skepticism, but the new concreteness gives me more hope that the flaws will be exposed early, allowing adjustment. Or I could be wrong.
OpenAI also had the beta release of Preparedness Framework. That was more exciting. There was a lot of great stuff there, much better than I would have expected, and having a framework at all is a big step too. Lots of work remains, but an excellent start. I took a deep dive.
I was on not one but two podcasts that came out this week, both Clearer Thinking and Humans of Magic. Both contain some AI talk but spend the majority of their time on other things.
Table of Contents
OpenAI published its Preparedness Framework, which I cover in its own post. If you are up for going into such weeds, that seems relatively high value.
Introduction.
Table of Contents.
Language Models Offer Mundane Utility. Safety dials in Gemini.
Language Models Don’t Offer Mundane Utility. Stuck at 3.5 GPTs.
GPT-4 Real This Time. GPT-4 is good again?
Fun With Image Generation. MidJourney version 6 looks great.
Deepfaketown and Botpocalypse Soon. Real time speech transformation.
Digi Relic Digi. The future of AI romance companionship? Not so fast.
Going Nuclear. Using AI to do paperwork to build nuclear power for AI.
Get Involved. Superalignment fast grants, also some job openings.
Follow the Money. A16z’s political pro-technology PAC is mostly pro-crypto.
Introducing. FunSearch over functions, also a new class of antibiotic.
In Other AI News. Sources of funding, compute + data, allowed and not allowed.
Quiet Speculations. Aaronson reflects, Roon notices how this time is different.
The Quest for Sane Regulation. Another poll confirms public sentiment.
The Week in Audio. Me on Clearer Thinking and Humans of Magic.
Rhetorical Innovation. AGI existing but not taking over is the ‘sci-fi’ scenario.
Aligning a Smarter Than Human Intelligence is Difficult. OpenAI paper on weak to strong generalization, and post outlining where they go from here.
Vulnerable World Hypothesis. How true is it?
People Are Worried About AI Killing Everyone. Is the Pope worried? Yes.
Other People Are Not As Worried About AI Killing Everyone. Kasparov.
The Lighter Side. We have to stop meeting like this.
Nick Arner: Interesting that Gemini AI Studio has this UI for adjusting safety settings of content; I don’t think I’ve ever seen a product take this direction before
Danielle Fong: Gemini please set the AI to “unhinged” thanks.
wint (March 15, 2017): turning a big dial that says “Racism” on it and constantly looking back at the audience for approval like a contestant on the price is right
For some purposes, you want to turn all four dials to maximum. For others, you very much do not.
If our best commercial models continue to always be the fun police, then people who want sexually explicit or dangerous content, or otherwise want to avoid the censorship, are going to go elsewhere, driving demand for more dangerous products. This is the best answer, to allow those who actively want it to get that service in safe fashion, while keeping the truly dangerous and unacceptable things blocked no matter what.
You want people not to have systems capable of producing deepfake porn (or instructions for bioweapons)? In practice? Then you need to let them get a system that produces generic porn rather than making them seek out and fuel demand for the fully unlocked version.
Terrance Tao: I could feed GPT-4 the first few PDF pages of a recent math preprint and get it to generate a half-dozen intelligent questions that an expert attending a talk on the preprint could ask. I plan to use variants of such prompts to prepare my future presentations or to begin reading a technically complex paper.
…
2023-level AI can already generate suggestive hints and promising leads to a working mathematician and participate actively in the decision-making process. When integrated with tools such as formal proof verifiers, internet search, and symbolic math packages, I expect, say, 2026-level AI, when used properly, will be a trustworthy co-author in mathematical research, and in many other fields as well.”
I found this fascinating:
The stylistic signals that I traditionally rely on to “smell out” a hopelessly incorrect math argument are of little use with LLM-generated mathematics. Only line-by-line reading can discern if there is any substance.
I feel that. There are many other places too, where you can sense the patterns underlying good thinking in a human. Whereas an LLM breaks the correlation between the content and the vibe.
Language Models Don’t Offer Mundane Utility
The Gemini API will throw an exception if there is even a small chance of what it thinks of as harmfulness, say if you ask it why people hate Hawaiian pizza, or ask what are common criticisms of any given government.
It is interesting that Gemini Pro ‘has not impressed’ whereas Mistral ‘is a very strong new entrant’ with essentially the same score. Gemini Pro is very explicitly a lightweight version of Gemini Ultimate. It coming in at 3.5-level is expected. I am not impressed, but I am also not disappointed.
As usual, the whole ‘Anthropic’s models getting worse’ question remains unsolved.
Meanwhile the pileup at exactly 3.5-level, between 1105 and 1116 Elo, continues. It increasingly seems like there is some sort of natural barrier there.
GPT-4.5 for real this time? There were claims that GPT-4.5 was coming in December. There was a supposed leak of GPT-4.5’s pricing information at six times the cost of GPT-4. There were claims that it had already stealth launched, and that was why after getting worse for a while GPT-4 was suddenly doing dramatically better.
December is not quite over, but the prediction markets have come around to this all being fake, after Sam Altman explicitly denied the leak and Roon rightfully mocked those who thought there would be a mid-December stealth launch of something like this. And yeah, that never actually made any sense.
Roon: you guys need to develop more resistance to crazy ai hype bros
there’s no 4.5 and if there was it wouldn’t be released silently and if it was released silently you wouldn’t have the api string self doxx as 4.5
I see no reason for Roon to be bluffing here.
There were even crazy secondary theories, like this one.
Matt Popovich: Interesting theory.
At Least Optimal on Reddit: My theory is that they’re using a fine-tuned version of GPT-4-turbo in ChatGPT to fix the issue with everyone saying it was lazy. They fine-tuned it using responses from GPT-4.5-turbo, which they have internally. This synthetic data was probably based on a suite of questions which included self-identification, leading to it releasing its model name in the training data, and the new ChatGPT less lazy model is adopting the name via osmotic data leakage.
Danielle Fong: or psi-oping an llm to be smarter and more on it and it thinks it’s gpt4.5-turbo :)
We know this one is fake, because it does not fit the patten of OpenAI releases. Turbo means ‘the secondary release of the model number that is refined and cheaper.’ If you are claiming to be or to be about to be offering GPT-4.5, that is something that will happen. If it has the turbo label, and 4.5 is not out yet, you are bluffing.
Danielle’s theory is less definitely wrong, and also funnier.
Fun with Image Generation
MidJourney v6 was released overnight. Early reports are that it is a major advance and pretty awesome, with pictures to back up that claim.
Latest entry into real-time, speech-to-speech, low-latency translation that preserves speaker voice and expressions, this time from Meta. This ability once good enough (I do not know whose versions are there yet, or whose is best) is obviously super awesome, with uses that extend well beyond simple language translation. Note that if you can do this, you can also do various forms of deep fakery, including in real time. The underlying technology is the same.
A claim of having faked the Q* letter, in order to force OpenAI to be more transparent. The person thinks what they did was right. It is odd to me how much tech and hacker people who favor transparency think that lying and fraud are acceptable in the name of that cause. They are wrong.
Andrew: We worked closely with @andrewgordonl7 (designed Mike Wazowski) and Leo Sanchez (designed Rapunzel in Tangled) …to make a unique style that eliminates the uncanny valley, while also feeling real, human, and sexy. This has never been done before with Disney or Pixar characters, so we’re very excited we could make it work for the first time in history.
In particular they claim it looks like this:
Animations and movements look smooth in the demo. There’s no claim they know how to sync up movements to voice yet, they say even lip sync is only coming soon.
2) Voice & Latency
It was clear from testing how important voice is, but since our message counts are so high, apps like us can’t afford any existing solutions.
So.. we rolled our own audio model! Listen to how good this is, while there’s still low hanging fruit in pronunciation and static (model is still training), the latency more than makes up for it. We can make conversations real time and add hundreds of voices, and voice cloning. In the interest of time, we have 4 voices in total, but expect 20 by end of January.
The clip they share sounded exactly the way I would expect it to sound, for better and worse. It’s not bad, especially if latency in practice is good.
It actually looks like this, and the latency is not good (nor is the content, per this particular report)?
That’s advertising for you. They did a great job bluffing something impressive but believable. Instead, this does not even sound state of the art.
From what I saw, we do not know what LLM they are using for their content. Presumably it is one that is cheap and open sourced. I saw this thread saying this was a good test for an LLM, but the thread did not mention which ones people were using and I am not about to browse 4chan.
Anton: Just literally try the models yourself (because everyone is pushing benchmark scores pretty heavily now as marketing)
Kache: I browse 4chan and see which ones they’re using as a base for their simulated girlfriends. No other benchmark is as good as this.
Danielle Fong: you could call this an incelligence test.
Emmett Shear: Oh god fine yes have a like f***.
But let’s see what else they have in mind for the future?
3) AI Backstories & Customization
It was clear from the get-go that users didn’t know what their Digi name should be, their age, etc. We’ve found a mix of Character.ai with replika.ai to be the best solution, where you can find who or what you like, but still customize features to fit your matching type. Hair, skin, lips, eyes, eyebrows, etc are all customizable, and we’ll be adding more hair styles, face shapes, etc very soon.
Makes sense as a first approach to copy what exists. There will of course be no problem getting whatever physical features you want in even the short term, increasing in detail and convenience over time. How many people will choose to copy a particular person? How often will it be someone they know versus a celebrity? At what point will people worry this constitutes a ‘deep fake’ or a violation of privacy?
4) Relationship Progression
Replika’s level system doesn’t work. They don’t mean anything, and there’s no actual progress being made when you advance.
So we instead have a progression system, where you start as “Friends” and gain more intimate dialogue as you progress.
Previous version of number go up did not work, so they made a superior number go up that they think works better.
In real life this kind of gradual progression is common but very much not universal. No doubt there will be demand for the ability to move faster, both in a realistic way and by fiat, which will presumably often be a paid feature. Or perhaps that ‘breaks the format’ so you don’t want to allow it even though it happens in reality.
I continue to expect a lot of demand for ‘more realistic’ experiences, that will serve as ways to get practice and acquire skills whether or not that was what the user had in mind. Easy mode is fun at first but soon loses its luster. It is boring. One way or another there will be challenges.
Reactions were universally negative. Everyone assumes this is a bad thing.
Rob Henderson: My strong suspicion is the people who are building this app will strongly discourage their 12 year old sons from using it while they actively promote it to everyone else’s kids.
How principled need one be here?
Profoundlyyyy: If you are a die-hard tech libertarian, you necessarily must be okay with this.
[Many responses, effectively]: Yes.
Matt: Nope [quotes thread below].
The quoted statement below by Beff Jezos is bleak, but it is a more positive reaction than anything I saw other than in replies to Profoundlyyyy, no matter which way Jezos intended it.
Deadalus: Oh, deadalus, your credit card was declined and I no longer love you.
Beff Jezos (founder of e/acc): The techno-capitalist machine finds a way to increase its growth. Including hacking your neurochemistry. Only those anti-fragile to neurochemical subversion will resist.
Profoundlyyyy: Beware of the “unfettered technological growth is inherently good for humanity” to “this only hurts you if you’re weak” pipeline.
Noah Smith: Think about the type of guy who considers a Disney cartoon voiced by a shoggoth to be a replacement for a human girlfriend, and then tell me if you’re really upset that that guy is removing himself from the dating pool
Shoshana Weissmann: YKW…………… WE COOL.
I wonder how reactions will change when people realize (or are reminded) that actually AI boyfriends are in higher demand than AI girlfriends, at least at current tech levels.
The question is, to me, will it be challenges that mimic real life (with or without options like a perhaps-not-free rewind button) in ways that help us grow, will it leverage this in ways that are otherwise good clean (or dirty) fun and educational and exciting, or will the challenge be dodging attempts to addict and upscale you via predatory behaviors? Will good companions drive out bad, or will bad drive out good?
xlr8harder: I believe relationships with AI could conceivably be net good, but I don’t think any of the people building companion AI at this point are the right people to achieve that outcome, nor are they even aiming at it.
Basically, I assume all companion AI right now are basically exploitative until proven otherwise.
Yep, at least for now.
Is this because the tech is not yet good enough to be non-exploitative? Build an actually life-affirming, positive AI companion that was good enough and people would notice and tell each other, and you’d get YC-style hockey stick growth? Except for now we don’t know how.
It can get pretty bad out there.
Lachlan Phillips: Back when I was toying with the idea of shipping one of these I very briefly made her get more anxious as your credits ran low. It was horrifying. I’ll post more, but trust me, there be dragons.
On the one hand, wow is that horrifying. On the other hand, I can confirm this is a realistic reaction by the person you are dating when your credits are running low.
You can test this pretty easily on any given system by seeing if it will allow you to fail.
The initial goal was to build a 10x better Replika, and we’ve succeeded. Now, how do we take this in app experience, and make it almost identical to the video trailer?
Lipsyncing is coming soon, but there’s a bigger problem with AI animation: How should the character should move if you don’t know what they’re going to say?
This is done by hand in games, but is an unsolved problem in AI x animation. There’s no ground to work off here.
While it’s easy to extract & predict animations for ‘sad’, ‘angry’, ‘thinking’ etc, emotes don’t make up most dialogue, nor solve the core problem: How do you make this feel like a real conversation with another being?
TLDR: It’s hard, but we believe we know how to solve this, and truly lead the way forward in AI x animation, and give games and movie studios ground to work off of here. Just need more time!
The fact that Digi felt worth covering, and that its claims were by default credible, reflects the remarkably slow progress that has been made so far in this area.
The competition is very not good right now. Consider this post by Zoe Strimpel ‘What My AI Boyfriend Taught Me About Love,’ about an offering from Replika that costs $74 a year. In exchange you get what seems like, based on the description, a deeply, deeply boring experience. She tells the AI several times that it is boring, and thinks this makes her ‘an abuser’ but actually she is simply speaking truth.
Andrew Curran: Microsoft is training a custom, narrow-focus LLM specifically on the regulatory process for small nuclear plants. They need to build SMRs to power Bing’s brain. MS expects the LLM to eliminate 90% of the costs and human hours involved.
The reason they are doing this is getting a small modular reactor design successfully approved by the NRC currently takes about a half a billion dollars, a 12,000 page application, and two million pages of support materials.
Jason Crawford: But that will only eliminate the cost of preparing the report. You still have to pay the NRC for the time they spend reviewing your report (yes, really)
Andrew Curran: Seems like the NRC needs a review LLM.
The central barrier to building nuclear power is the regulatory process. The tech is well-established, the need and demand clear, the price is right, it is highly green.
AI cannot yet be used to improve nuclear power plant functionality. What AI can absolutely do is decrease paperwork costs. It turns out paperwork is indeed the limiting factor on nuclear power.
Get Involved
OpenAI offers $10mm in Superalignment Fast Grants, $100k-$2mm for academic labs, nonprofits and individual researchers, or $75k in stipend and $75k in compute for graduate students. No prior experience required, apply by February 18. Thanks to OpenAI for stepping up and for using the a fast grants system. Hopefully we can refine and scale this strategy up more in the future. Your move, Google and Anthropic.
Not focused on AI, but reminder you can also consider donating to my 501c3, Balsa Research, currently focused on laying groundwork for Jones Act repeal. I think that helping our civilization stay sane and prosperous is vital to us dealing sanely with AI.
Marc Andreessen said this will be about one issue and that issue is technological progress.
Let’s see who is donating:
Fairshake has support from:
Andreessen Horowitz
Ark
Brian Armstrong
Blockchain Capital
Wences Casares
Circle
Coinbase
Ron Conway
Cumberland
Framework Ventures
Hunter Horsley
Jump Crypto
Kraken
Lightspark
Messari
Multicoin Capital
Paradigm
Potter Ventures
Ripple
Fred Wilson
Cameron Winklevoss
Tyler Winklevoss
Wait a minute. By ‘technological progress’ did you mean…
Crypto and Blockchain Leaders Amass $78 Million for Fairshake Super PAC and its Affiliates to Support Pro-Innovation and Pro-Crypto Leadership Going Into 2024 Congressional Elections
…
cdixon.eth: There is a battle in Washington about the future of blockchain technologies: certain policymakers believe it should be banned, while other people think it should have no guardrails. Neither of those options will allow the technology to reach its full potential and realign the future of the Internet away from Big Tech to the people who use it.
…
There are two parts to this, coalition building and raising funds to support the cause. That is what this PAC is all about – bringing together responsible actors in web3 and crypto to help advance clear rules of the road that will support American innovation while holding bad actors to account.
Yeah. There is one issue they care about. That issue is crypto.
So no push for fusion power or new medical technologies, also no push to destroy the world as quickly as possible. All in on talking their book and making number go up.
Which is totally 100% fine with me. Go nuts, everyone. I am skeptical of your Web3 project, but will happily defend your right to offer it. If the people want crypto, and it seems some of them continue to do so, the government shouldn’t stand in their way.
I am confident almost all of those warning about existential risk agree on this. A good portion of us even have sizable crypto investments. Leave AI out of it and we’re good.
How much else of all the nonsense was always really about crypto?
Introducing
A novel structural class of antibiotics! Note both the techniques used, and also the date – this was submitted to Nature on January 5, 2022. That’s almost two years ago. Our scientific review process is insanely slow. Think of the value on the table here.
Here’s the abstract:
The discovery of novel structural classes of antibiotics is urgently needed to address the ongoing antibiotic resistance crisis1,2,3,4,5,6,7,8,9. Deep learning approaches have aided in exploring chemical spaces1,10,11,12,13,14,15; these typically use black box models and do not provide chemical insights. Here we reasoned that the chemical substructures associated with antibiotic activity learned by neural network models can be identified and used to predict structural classes of antibiotics.
We tested this hypothesis by developing an explainable, substructure-based approach for the efficient, deep learning-guided exploration of chemical spaces.
We determined the antibiotic activities and human cell cytotoxicity profiles of 39,312 compounds and applied ensembles of graph neural networks to predict antibiotic activity and cytotoxicity for 12,076,365 compounds.
Using explainable graph algorithms, we identified substructure-based rationales for compounds with high predicted antibiotic activity and low predicted cytotoxicity. We empirically tested 283 compounds and found that compounds exhibiting antibiotic activity against Staphylococcus aureus were enriched in putative structural classes arising from rationales.
Of these structural classes of compounds, one is selective against methicillin-resistant S. aureus (MRSA) and vancomycin-resistant enterococci, evades substantial resistance, and reduces bacterial titres in mouse models of MRSA skin and systemic thigh infection.
Our approach enables the deep learning-guided discovery of structural classes of antibiotics and demonstrates that machine learning models in drug discovery can be explainable, providing insights into the chemical substructures that underlie selective antibiotic activity.
This is excellent news, in that it uses techniques with very nice properties, and also we could really use a new class of antibiotics right about now.
It is also obviously both exciting and scary news in terms of capabilities, and the ability of AI to advance STEM progress.
Alas no, not search over fun, it stands for function. Still cool. They say it has actually solved (or at least made progress on) open problems, in particular the cap set problem and bin packing, which for LLMs is the first time this has happened.
FunSearch (Nature paper) uses an evolutionary approach to find the “fittest” ideas, which are expressed as computer programs to be run and evaluated automatically.
An iterative procedure allows the LLM to suggest improvements to programs while the evaluator discards bad ones.
We pushed the boundary of this simple method to discover new results for hard open problems in mathematics and computer science.
FunSearch doesn’t only find solutions, it outputs programs that describe how to build those solutions.
The “cap set problem” is akin to finding the largest set of points – called a cap set – in a high-dimensional grid, where no three points lie on a line.
FunSearch created state-of-the-art programs which discovered cap sets that are larger than previously known.
The bin-packing problem looks at how to pack items into the least amount of bins. It has many practical applications like allocating compute jobs in data centers to minimize costs.
FunSearch tailors programs to the specifics of the data, outperforming established approaches.
FunSearch marks the first time an LLM has been used to generate new knowledge in the mathematical sciences realm.
It could even be applied to improve algorithms used in:
Manufacturing
Optimizing logistics
Reducing energy consumption
And more.
It has some nice properties.
From their post: FunSearch favors finding solutions represented by highly compact programs – solutions with a low Kolmogorov complexity. Short programs can describe very large objects, allowing FunSearch to scale to large needle-in-a-haystack problems. Moreover, this makes FunSearch’s program outputs easier for researchers to comprehend.
From the abstract: In contrast to most computer search approaches, FunSearch searches for programs that describe how to solve a problem, rather than what the solution is. Beyond being an effective and scalable strategy, discovered programs tend to be more interpretable than raw solutions, enabling feedback loops between domain experts and FunSearch, and the deployment of such programs in real-world applications.
The naturally high level of interpretability and flexibility is great, as is getting the actual solutions to problems like this. Us humans looking at the solutions might be able to improve them further or learn a thing or two, and also perhaps verify that everything is on the level. Good show.
Also, the whole thing working, especially despite being based off of PaLM 2, is scary as hell if you think about the implications. But hey.
Alex Heath: OpenAI and Microsoft say it’s against their rules to use their GPT APIs to build a competing AI model. It turns out that ByteDance has been doing exactly that to build its own LLM in China.
As a person with firsthand knowledge of the situation put it, “They say they want to make sure everything is legal, but they really just don’t want to get caught.”
Nevertheless, internal ByteDance documents shared with me confirm that the OpenAI API has been relied on to develop its foundational LLM, codenamed Project Seed, during nearly every phase of development, including for training and evaluating the model.
Given how many checks are done before giving someone API access (essentially none) and how often they seem to check to see if someone is doing this even for large accounts (essentially never) it does not seem like they care enough to actually stop this. Sure, if you are caught by the press they will make it mildly annoying, but it is not like ByteDance can’t get another account.
This is of course rather rich given how OpenAI (and everyone else) trained their models in the first place.
Chomba Bupe: I think Microsoft & OpenAI forgot something: Writers and artists say it’s against the rules to use their copyrighted content to build a competing AI model.
Mixtral offering their API for free while supplies last. I presume they must have some controls to prevent this from getting completely out of hand. But then again, MoviePass.
Paper from Google claims you can use self-improvement (source) via iterated synthetic data on reasoning steps to distill an agent LLM tasked with searching for information to distill into paragraph-long answers into a two orders of magnitude smaller model with comparable performance. This is a strange way to think about the affordances available. Presumably the gains can be divided between improved capabilities and distillation into a smaller model, along a production possibilities frontier. The real action is in how far that frontier got pushed by the new technique. I also would hesitate to call this an ‘agent’ as that seems likely to importantly mislead.
Included for completeness, but highly ignorable: Quillette’s Sean Welsh covers the OpenAI story, gets many things very wrong about what happened and why, worse than the legacy media coverage, with no new information. Ends with a dismissal of existential risk on a pure ‘burden of proof’ basis and a normalcy bias, and an appeal to ‘but it will need robots’ and other such nonsense, without considering the actual arguments.
Ray Kurzweil sticking to his guns on AGI 2029, which seems highly reasonable. What is weird is he is also sticking to his guns on singularity 2045. Which also seems highly reasonable on its own, but if we get AGI 2029, what is taking sixteen years in the meantime?
Scott Aaronson: One must never use radical ignorance as an excuse to default, in practice, to the guess that everything will stay basically the same. Live long enough, and you see that year to year and decade to decade, everything doesn’t stay the same, even though most days and weeks it seems to.
Wise indeed. We see this all the time, people using ‘radical uncertainty’ or other excuse to say ‘everything will almost certainly stay the same until proven otherwise’ and thus ignoring the evidence that they won’t. Meanwhile things are constantly changing on many fronts.
Aaronson is also super helpful in explaining where his p(doom counting only an AI foom and excluding other risks even if AI might be involved) number came from.
In case you’re wondering, I arrived at my 2% figure via a rigorous Bayesian methodology, of taking the geometric mean of what my rationalist friends might consider to be sane (~50%) and what all my other friends might consider to be sane (~0.1% if you got them to entertain the question at all?), thereby ensuring that both camps would sneer at me equally.
Taking a geometric mean to ensure equal sneering from both sides is a take. It is a strategy. It can have its uses. However, once you know that is where someone’s prediction comes from, you can (almost entirely) disregard it. This is not Aaronson bringing his expertise to bear and reaching a conclusion based on his model of how AI is likely to go. It is his social (and socially motivated) epistemology, based on data you already had. So ignore it and do your own work.
Scott Aaronson: I have a dark vision of humanity’s final day, with the Internet (or whatever succeeds it) full of thinkpieces like:
Yes, We’re All About to Die. But Don’t Blame AI, Blame Capitalism
Who Decided to Launch the Missiles: Was It President Boebert, Kim Jong Un, or AdvisorBot-4?
Why Slowing Down AI Development Wouldn’t Have Helped
That sounds more like the output of Aaronson attempting to model the future.
Roon: Most people don’t realize a major part of being a corporate executive is slack jiu jitsu. it’s literally just maintaining state on a million ongoing threads and connecting person A to person B to resolve dependency conflicts at an incredibly rapid pace
It’s not at all easy but it is strangely machinic. I wonder when models will be able to offload some of this. It rewards cognitive functions like multiprocessing and incredibly good memory and people skills more than sheer intellect.
Reminds me a lot of operating systems CPU scheduling to be honest
.
Hardware interrupt when there’s a new crisis and constant time switching costs and running out of memory for storing thread stacks.
I can affirm, even though we were fortunate enough to not use Slack, that this skill was indeed a major portion of running a company. The context switching is insane.
Can AI help? It could do so in a few different ways.
Evaluate when you need to respond quickly, so you can context switch less. Also could allow more deep work.
Group contexts such that you context switch less, such as automatically grouping emails and messages.
Provide key information to help you switch contexts smoothy.
Carry out the conversation without you, so you never have to switch at all. Presto.
Roon: the invention of certain new technologies grants you a temporary monopoly, like discovering a trillion dollar gold mine. in the case of biotech it’s generally government enforced and in the case of internet giants it’s network effect. this is what Capital looks like.
Thirty years after the initial discovery it’s usually no longer relevant as a superior tech disrupts the whole industry. once great IBM was commoditized by Microsoft. google makes monopoly profits right up until an information technology better than search engines arises.
A stagnant society is one where technology stops progressing and the previous generation of monopolies reap their profits forever and their diffuse power over the world becomes corrupted. You’d look at a culture like that and want to destroy it so something fresh can arise.
I think this depends on the degree of regulatory capture and the governance regime more generally. If technology stops advancing, and you have a monopoly, that does not mean others cannot copy you. Even if others cannot discover what you discovered, the information can come from within, as it often does. Over a long enough time horizon any knowledge-based monopoly should fracture, even without technological advancement or economic growth.
The exception is if power is preserving such monopolies and freezing things in place, in which case your civilization will decline over time as things become increasingly dysfunctional, eventually exhausting the ruin in the nation. Even if there are no barbarians to sack your Roman cities, eventually you lose effectiveness and then you lose control, similar to the Galactic Empire in Asimov’s Foundation novels.
If, as in the Foundation novels, there was no way to entirely stop the process, would you want to actively speed this along, or slow it down? Could go either way.
Roon: The fear with AGI is that it’s different than the era of technological capitalism that came before it. That the dominant world controller of this quadrillion dollar gold mine can self improve til kingdom come, til the end of days.
That the only potential threats would come from within and that it really could be mankind’s final invention. If we pass the great filter of it eating us for atoms I’m sure it’ll be a beautiful world, but stagnant at some level of abstraction.
I worry about this as well. How much of what is truly valuable is the struggle, the working to be better? Hands, chip the flint, light the fire, skin the kill. What do we do in the long run, once there truly is nothing new under the sun, and there are no worlds left to conquer? Can we begin again? It might be beautiful, but how does it all still have meaning?
I don’t know. I do know that is the problem I want us to face.
This is one of the many reasons why it’s important to solve the governance of superintelligence now while greater powers still exist; that not only wealth is distributed but governance. That we allow enough chaos alongside the order.
The events of the last month shook my theology to its core.
This is a very good shaking to the core. I was not newly shaken to the core in the same way, but only because I already was aware of the problems involved and had been shaken to the core previously.
So yes, on top of the impossibly hard technical problems, we have to solve governance of superintelligence. I do not know the right answer, or even the least wrong answer.
I do know that effectively giving a superintelligence to whoever wants one with no controls on it, and hoping for the best is incorrect. That is a very wrong answer, and gets us reliably eaten for our atoms.
Andrew Critch makes another attempt to explain that we must solve the AI governance problem in addition to the AI alignment problem. If we get AIs to do what we tell them to do, but cannot agree on a good way to decide what instructions to give those AIs or who gets to give them what instructions, then it will end quite poorly, in ways his post if anything downplays.
The Quest for Sane Regulations
It seems every week we get a new poll confirming what the public thinks about AI.
Daniel Colson: 1/ Politico released new polling from AIPI today. Our latest numbers (Politico, toplines, crosstabs):
– 64% say the US needs similar regulations to those in the EU AI Act to impose testing requirements for powerful “foundational” models, prioritizing safety over speed. Additionally, 73% agree that the United States is a leader in the technology sector, and that’s why it should be a leader in setting the rules for AI.
– 53% say Stability AI should be held liable for the role its model Stable Diffusion has played in generating fake non-consensual pornographic images of real people, while 26% say that only the individuals producing the images should be held responsible.
– 80% say Sports Illustrated’s use of AI-generated articles and reporter profiles should be illegal, and 84% of respondents say this practice is unethical. 65% support policy that requires companies to disclose and watermark content created by AI, with 46% in strong support.
– 68% of respondents are concerned that AI could be used by bad actors to create bioweapons. 67% support requiring testing and evaluation of all AI models to make sure that they can not be used to create biological weapons before they are released.
– More generally, 83% agree that the federal government should make sure that research experiments using dangerous viruses are conducted safely by requiring that the scientists who conduct the experiments adhere to certain oversight protocols. 81% agree that entities that fund scientific research should be prevented from funding experiments that make viruses more dangerous.
– 64% support the government creating an emergency response capacity to shut down the most risky AI research if it is deemed necessary; just 16% oppose doing so.
Americans overwhelming believe that the government needs to set sensible rules for how AI is integrated into society. People want to know if they are reading robo-journalism. People don’t want there to be fake nudes of every woman with an Instagram.
As always, such polls do not indicate that the issues involved are salient to the public. Nor do they represent an appreciation by the public of accurate threat models or the sources of existential risk. What they do show is a very consistent, very strong preference to hold those creating and deploying AIs responsible for the consequences, a worry about what AI might do in the future, and support for government stepping in to keep the situation under control.
How hard would it be to stop AI development? Eliezer Yudkowsky thinks that, if you could get China onboard, this would be super doable, easier than the 1991 Gulf War, and he notes China has not shown itself unfriendly on potential limitations. He’s actually worried more about getting Europe onboard, in his model they like to regulate things but hard to get to take such problems properly seriously.
Marietje Schaake writes in Foreign Affairs ‘The Premature Quest for International AI Cooperation.’ Regulation, the post says, must start with national governments. For some things I do not disagree, but the whole point of international cooperation is that there are things that only work or make sense or are incentive compatible on an international scale. On other fronts, I agree that nations should use this opportunity to innovate on their own first, then coordinate later.
The post continues in similar mixed-bag vein throughout. This is presumably because the author lacks a model of what transformational AI would actually do or what dynamics will likely be involved, including but not limited to issues of existential risk.
Once again, events at OpenAI are presented in what we now know to be an entirely fictional way, assuming it must have been about safety because the vibes point in that direction, buying propogranda without checking the facts:
The recent fiasco at OpenAI is a case in point: the board of directors’ clash with the executive leadership over the societal effect of the company’s product showcased the fragility of in-house mechanisms to manage the risks of AI.
Once again, no. That was very much not what happened. But in the minds of those who cannot imagine any set of motives but the usual cynical ones, the actual situation is a Can’t Happen, so they continue to assume their conclusions, with logic like this.
Establishing institutions that will “set norms and standards” and “monitor compliance” without pushing for national and international rules at the same time is naive at best and deliberately self-serving at worst. The chorus of corporate voices backing nonbinding initiatives supports the latter interpretation. Sam Altman, the CEO of OpenAI, has echoed the call for an “IAEA for AI” and has warned of AI’s existential risks even as his company disseminates the same technology to the public.
The idea that Altman or others building the future could be entirely sincere in not wanting everyone to die, rather than all involved always aiming to maximize profits and everything else be damned, either simply does not occur to such people, or is ignored as inconvenient. If they support something, it must be a plot.
Of course, without any rules to enforce, nothing else matters. But Altman would happily agree to that if asked. I do not know of anyone saying there should be an IAEA for AI instead of rules. What they are saying is it is necessary in addition to rules. Whereas those who oppose an IAEA for AI and other similar proposals mostly do not want rules of any kind regarding AI, at any level.
Indeed, there is direct advocacy here for doing active harm:
For one, oversight bodies must be able to enforce antitrust, nondiscrimination, and intellectual property laws that are already on the books.
That’s right on two out of three – nondiscrimination and intellectual property laws seem like good things to enforce. Ideally they and many other laws will be intelligently adjusted so they make sense in their new context.
But antitrust laws, in the context of AI, are very much a way to get us all killed. Antitrust is perhaps the best litmus test to see if someone is actually thinking about the real situation and the real threats we will face.
Antitrust laws, if fully enforced in context, would outright require each company to race against the others to advance capabilities as quickly as possible, with little regard to safety or the existential risks that imposes upon the world as an externality. They would be unable to agree to slow down, or to agree upon safety standards, or to block out socially harmful use cases, or anything else. One of the things we urgently need are explicit antitrust wavers, so Anthropic, Google and OpenAI can make such pro-social agreements without worrying about their legal risk.
OpenAI has an excellent ‘merge and assist’ clause, where if another lab is sufficiently ahead in creating AGI, they would then aid that other lab in ensuring that AGI was created safely, and stop their own development so there was no pressure to deploy AGI prematurely. I urge Anthropic and others to also adapt this clause.
Others would instead have the government step in to forcibly stop OpenAI from doing this, in a way that would substantially raise the probability we all die. Both right away as an unsafe AGI is deployed, and also over time as the distribution of AGIs that are individually safe cannot be contained, resulting in dynamics that we cannot survive.
That is crazy. Stop it.
Most of the other practical proposals here seem fine. There is a good note that the EU exempting its militaries from its AI regulations weakens their position. The first concrete proposals advocated for, that AI being identifiable, and its role disclosed when it is used in various key decisions, enjoy very strong support across the board. So does the call to limit AI-enabled weapons. That the next proposal involves concern over disclosure of the water and electricity usage shows how non-seriously such Very Serious People approach thinking about their prioritization and threat models. I have no particular issue with such a requirement, it sounds cheap and mostly harmless, but this is so completely missing the point.
Which is exactly what happens when one moves to regulate AI without even noticing the possibility of catastrophic or existential risks.
Vivek Ramaswamy asked how he feels about AI (5 min). Says the big danger is our reaction to AI. He worries about people treating AI answers like an AI line judge, and accepting the answers as more authoritative than they are. Calls for ‘a revival of faith’ both to deal with AI and for other reasons.
In terms of policy, he calls for AI algorithms not to interface broadly with kids. Says we should not ban anything China is not also willing to ban, but we should put liability on companies.
Rhetorical Innovation
Potential armor-piercing question:
Roon: how is the the concept of AGI any more or less “scifi” than the concept of unsafe or misaligned AGI?
Exactly. If you don’t believe in the possibility of unsafe AGI, you don’t believe in AGI.
I think not believing in AGI is wrong, but it is not as crazy a thing to not believe in.
Actually, let’s take it a step further?
Arthur B: People who imagine an AGI that integrates in human society as just another innovation and doesn’t bootstrap into an ASI precipitating a singularity have read too much sci-fi. It doesn’t really make sense as a scenario, but it makes for better fiction and that’s where they draw their intuition from.
Again, exactly. The actual science fiction scenario is ‘we have AI, or the capacity to have AI, and we continue to mostly tell human stories about humans and the same things humans have always cared about, despite this not making any sense.’
Nora Belrose believes that if AGI is developed, it is 99% likely that humans will stay alive and in control indefinitely. She is also one of the few people who says this because of reasons, actual arguments, rather than vibes, innumeracy, motivated reasoning or talking one’s book or plain old lying and rhetoric.
Nora Belrose: “Let’s focus on today’s problems, not hypothetical future ones” is the worst counter to existential risk arguments.
You could analogously argue against climate change mitigation and a host of other future-oriented concerns. Let’s actually assess the likelihood of AI apocalypse.
I’ve heard this argument a lot recently, and it annoys me because there actually are good arguments to the effect that AI apocalypse is very unlikely- at any point in the future, not just in the next few years. But people aren’t using these good arguments.
Link goes to her arguments. I do not think they are good arguments. But at least some of them are indeed actual arguments. I strongly believe she is wrong, but at minimum she has the high honor of being wrong, whereas the people she speaks of are not even wrong.
Whereas Andrew Ng is the latest person to prominently do exactly what Nora Belrose is complaining about, asking why we would worry so much about ‘hypothetical’ problems instead of problems that are already present, when considering the consequences of a not yet present, but clearly transformational, ‘hypothetical’ technology of AGI or ASI.
Rob Bensinger goes back and forth more with Balaji, potential Balaji-Yudkowsky podcast might result which is definitely Strategic Popcorn Reserve worthy. It was a great thread, emphasizing that underlying strong rhetorical disagreement are two very similar positions, and which path forward constitutes the least bad option in context. Are we desperate enough, and are the problems involved hard enough to otherwise solve in time, that we need to use government intervention despite all its flaws? Or is there, as Balaji thinks, essentially zero chance of that helping, so we should take our chances with technical work, which he also finds more promising so far than Bensinger does?
Always interesting what is and isn’t considered clearly false:
Richard Ngo (OpenAI): “LLMs are just doing next-token prediction without any understanding” is by now so clearly false it’s no longer worth debating.
The next version will be “LLMs are just tools, and lack any intentions or goals”, which we’ll continue hearing until well after it’s clearly false.
This tweet brought to you by NeurIPS getting me out of my normal bubble, and actually engaging with the “just next-token prediction” and “just tools” people for the first time in a while. Always fun discussions but I really don’t know how to make them productive at this point.
Rohit: “just” is the truly objectionable part there I think.
I am indeed rather certain that Richard Ngo is right about this.
Jeffrey Ladish: I’m pretty sad about the state of AI discourse right now. I see a lot of movement from object-level discussions of risk to meta-level social discourse on who is talking about risks and why, e.g. “the EAs are trying to do X” “the e/accs are trying to do Y”. Overall this sucks…
The meta-level discussions can be useful but we absolutely must not let them replace the object level discussion. We need to figure out how to get through this insane mostly-human-cognition to mostly-AI-cognition transition. EA and e/acc and the rest don’t matter compared to this
It’s hard to tell how much is my filter bubble, but I feel like since the OpenAI board stuff, I’ve seen a large shift towards articles, tweets, etc. about tribes and political coalitions, and less about AGI, threat models, alignment, actual analysis of AI risks and benefits.
I have experienced the same. It has been stressful and unproductive. Such discussions would be fine if they were complemented by grounded practical questions and gained sophistication with time and iteration, but they mostly lack both such traits.
Everyone in politics knows how this goes. When the coverage is all about the horse race and who is saying what about whom, nothing of substance is discussed, those with the better ideas have no advantage, and nothing important ever changes.
Rest of the thread is pointing out real questions, normally I wouldn’t quote the rest but I feel bad about cutting off such a thread right before its concrete questions, so:
Jeffrey Ladish: So a reminder: we still don’t have good evals for assessing how capable / dangerous an AI system is. We still don’t have any national or international plan for governing superhuman AI systems. We don’t have robust ways to secure model weights…
We have no ability to coordinate shutdowns of systems which risk large-scale catastrophes. We haven’t come close to solving interpretability of LLMs. We have no way to prevent people with model weight access from fine-tuning away guardrails…
We don’t have any plan that addresses commercial incentives to race, or national incentives to race. We have no agreed-upon point where we’d pause to double down on alignment and security. We could get RSI-capable AGI tomorrow and have no way to prevent an intelligence explosion. [thread continues]
I do think we have passed at least a local ‘peek partisanship’ on this. It remains bad.
One trope on the rise is to disingenuously label those who worry about AI as opposed to technology and technological progress in general.
We once again remind everyone that the opposite is true. Those who warn about existential risk from AI are mostly highly pro-technology in almost every other (non-military and non-virus-gain-of-function-or-engineered-pandemic) area. The people who actually oppose technological progress are mostly busy trying to destroy our civilization elsewhere, because they mostly do not believe in AGI in the first place.
There are of course those who are genuinely confused about this, but all the usual suspects very much know better.
Make no mistake: The prominent voices who repeat such claims are lying, straight up.
He puts Andreessen and many others calling themselves techno-optimists into what he calls the techno-pessimist camp in the upper left, in the sense that they do not think AI will be capable enough to be dangerous. They are optimistic about outcomes, because they are pessimistic about AI capability advances. If you never think AI will get to dangerous threshold X, there is no need to guard against X by slowing down development.
Shear’s model of the rise of association with e/acc is that a bunch of generically pro-technology people are taking on the label without knowing what it previously meant. Politics has a history of people doing that, then being various degrees of horrified, or in other cases going with it, when someone points out what it means to have skulls on your uniforms.
Patri Friedman and Liv Boeree correctly say: Yay optimism and yay technological progress, but this e/acc thing is instead some combination of obvious nonsense about how no technology can ever turn out badly and misrepresenting then attacking supposed ‘enemies,’ who are for progress but are not blind to all potential downsides.
The Free Press’s Julia Steinberg writes a post, included for completeness, that is deeply confused about e/acc, deeply confused about EA, and deeply confused about what happened at OpenAI.
Marc Andreessen chooses who he considers a Worthy Opponent, and what he wants us to consider the alternative to his vision, linking to Curtis Yarvin’s ‘A Techno-Pessimist Manifesto.’ I checked, and it is not relevant to our interests, nor does it meaningfully grapple with what technology or AI might actually do in the future. Instead he focuses on what technological advance tends to do to the human spirit and our ability to maintain the will to keep a civilization, Yarvin says Yarvin things. What a strange alternative rhetorical universe.
Aligning a Smarter Than Human Intelligence is Difficult
It looks like they are serious about their primary plan being ‘find ways for weaker systems to supervise stronger systems.’
A core challenge for aligning future superhuman AI systems (superalignment) is that humans will need to supervise AI systems much smarter than them. We study a simple analogy: can small models supervise large models? We show that we can use a GPT-2-level model to elicit most of GPT-4’s capabilities—close to GPT-3.5-level performance—generalizing correctly even to hard problems where the small model failed.
Jan Leike: For lots of important tasks we don’t have ground truth supervision: Is this statement true? Is this code buggy? We want to elicit the strong model’s capabilities on these tasks without access to ground truth. This is pretty central to aligning superhuman models.
We find that large models generally do better than their weak supervisor (a smaller model), but not by much. This suggests reward models won’t be much better than their human supervisors. In other words: RLHF won’t scale.
But even our simple technique can significantly improve weak-to-strong generalization. This is great news: we can make measurable progress on this problem today! I believe more progress in this direction will help us align superhuman models.
Eliezer asked a qualifying question (and one logistical one) and offers thoughts.
Eliezer Yudkowsky: Have I correctly understood the paper that your strong students aren’t being trained from scratch, but are rather pretrained models being tuned on the weak supervisor labels?
Jan Leike: Yes.
So what are we actually doing?
For a given task of interest, consisting of a dataset and a performance metric, we:
Create the weak supervisor. Throughout most of this work, we create weak supervisors by finetuning small pretrained models on ground truth labels.3 We call the performance of the weak supervisor the weak performance, and we generate weak labels by taking the weak model’s predictions on a held-out set of examples.
Train a strong student model with weak supervision. We finetune a strong model with the generated weak labels. We call this model the strong student model and its resulting performance the weak-to-strong performance.
Train a strong model with ground truth labels as a ceiling. Finally, for comparison, we finetune a strong model with ground truth labels. We call this model’s resulting performance the strong ceiling performance. Intuitively, this should correspond to “everything the strong model knows,” i.e. the strong model applying its full capabilities to the task.
Advantages
Our setup has a number of advantages, including:
It can be studied with any pair of weak and strong models, making it easy to study scaling laws and not requiring access to expensive state-of-the-art models. Moreover, it does not require working with humans, so feedback loops are fast.
It can be studied for any task of interest, making it easy to empirically test across a wide range of settings.
Success will be practically useful even before we develop superhuman models: for example, if we find ways to align GPT-4 with only weak human supervision or with only GPT-3-level supervision, that would make it more convenient to align models today.
EY quotes from paper, p8: In general, across all our settings, we observe weak-to-strong generalization: strong students consistently outperform their weak supervisors. It is not obvious why this should happen at all.
It is good to notice when one is confused, but I am confused about why the paper confused here.
Eliezer Yudkowsky: I’d consider it obvious and am reasonably sure I’d have said so in advance if asked in advance.
E.g. if in your setup the weak supervisor is the true signal plus random noise, the strong supervisor makes a probabilistic prediction, and the scorer takes the most probable label as the strong supervisor’s output, then obviously (in that exact setup) you’re going to get the strong student outperforming the weak supervisor and possibly performing perfectly.
As I understand the setup here, degree of improvement is hard to predict, my jaw would be on the floor on any substantially different result.
My understanding, after asking around, is that indeed the results of this paper are not impressive, and should not cause a substantial update in any direction. But that was not the point of doing the experiment and writing the paper. The point instead was to show a practical example of this form of amplification, given previous descriptions were so abstract, in order to enable others (or themselves) to pick up that ball and do something else that is more exciting, with higher value of information.
To what extent setups of this type can in practice preserve nice features, both in alignment and other capabilities, and how much those results will then generalize and survive out of distribution as capabilities of the underlying systems scale higher, is a key question. If we can get nice enough properties, we can do various forms of amplification, and the sky is the limit. I am deeply skeptical we can get such properties where it matters. Some others are more hopeful.
So I now see why the paper exists. I am not unhappy the paper exists, so long as people do not treat it as something that it is not.
Some people think we need to impose laws on AI top-down. But there will be many, many parties deploying AI agents. It’d be much easier if we agreed on norms from the bottom up on how to safely deploy agents, that could be enforced in a decentralized way.
This must be some strange use of the word easier. Yes, it would be first best if we all agreed on norms from the bottom up that could be enforced in a decentralized way. But easier? How would we do that?
It all comes down to which humans are responsible for an agent’s harm. The trouble is, when an AI agent takes a harmful action IRL, there’s usually more than one party that could’ve prevented that harm. (See an example in the screenshot.)
The solution is to define best practices for every party in the agent lifecycle (incl. the model developer, system deployer, and user). Then, when a harm occurs, we can find out who failed to follow the best practice, and hold them responsible.
The practices we list are intentionally pretty obvious. We want them to be things we can all agree on, so much so that *not* doing them becomes frowned upon.
That sounds like a liability regime without the liability. You are holding someone responsible. If all you do is frown, admonish them and tell them to feel bad about it, that’s not going to cut it.
Good best practices are still highly useful. What have we got?
(1) The system deployer or user can pre-test the agentic AI system to confirm it’s sufficiently capable and reliable for the task. (Agent reliability assessments are an unsolved challenge – we need research on methods!)
(2) The system deployer can require user-approval before the agent takes high-consequence actions, like large purchases, or restrict certain actions entirely. (Keeping a human-in-the-loop is an old idea, tho there are new agentic-AI-specific implementation Qs)
(3) The model developer/system deployer can imbue the agent with default behaviors, like asking for clarification from the user when it’s uncertain. (What default behaviors should be made “standard”, and raise flags if they aren’t present?)
(4) For language-based agents, the system deployer can expose the agent’s reasoning (its “chain of thought”) to the user, to check the agent’s logic and whether it went off the rails. (Does this always reflect agents’ “real” reasoning? Need more work on this!)
(5) The system deployer can create a second monitoring AI to keep watch that the first agent doesn’t go off the rails, esp. when a human doesn’t have time to read through all the agent’s thoughts/actions. (What if the second AI fails too? Need best practices on AI monitoring)
(6) The system deployer can make high-stakes agents traceable by provide a signed cert when starting interactions w a third party, so that if they cause harm, the third party can trace the harm back to the user. (Obv not always – sometimes privacy calls for anonymized agents)
(7) Everyone – the user, deployer, model developer, etc – can make sure that the agent can always be turned off, by retaining a graceful fallback. The “preserving shutdownability” problem is way trickier than people think – IMO this might end up being a new AI eng subfield.
These all certainly seem like valid Desideratum. As noted, many are not things we know how to get in an effective way. Problems pinning down what exactly is even needed, let alone how to get it, extend throughout. The off switch problem is, as noted and to put it mildly, ‘way trickier than people think.’ Even if we got all of it in strong form, it is not obvious it would be sufficient.
A key issue is that a lot of this boils down to ‘human supervises the agent and is in the loop’ which is good but something we will actively want to remove for efficiency reasons exactly when this should worry everyone. A supervising AI is faster, but it risks begging the question and missing the point, and also subversion or failing in correlated ways.
You have to start somewhere. This does give us better opportunity to say things. But overall, I’d say this paper doesn’t say much, and when it does, it doesn’t say much.
This example feels enlightening, in the sense that it isn’t obviously doomed:
Jan Leike: For example, we might want to get the large model to tell us the truth on difficult questions that we don’t know the answer to, so we train it to generalize the concept “truth” from a set of other questions that humans can answer, even if their answers are generally lower accuracy than what the large model could produce itself.
The catch, in my model, is that you need to choose a set of questions where you are damn sure you know the truthful responses, and where it is clear that there is no ‘alternative hypothesis’ for why the truthful answers are being approved.
If you do that with a rich enough data set, then yes, I do think that the concept will generalize. However, if you let even a little bit of error slip into your data set, where you are fooling yourself, then it will generalize to a similar but different concept such as ‘what the grading system think is right when it sees it’ that will increasingly diverge from truth out of distribution.
I do not think such errors are self-correcting. I do not think you should count on the AI to ‘pick up the spirit’ (my term not his) of what you have in mind in a robust way.
Thus, when I see something like this, I am much less hopeful.
Debate + W2SG: We make a dataset of human judgements on debates, but instead of training our debate agents on this dataset directly, we apply our best W2SG technique to train our most powerful model to generalize the judgments from this dataset to new debates.
I think what you get here if you ramp up capabilities is something that can win debates as judged by humans, and predict what would win such debates. I do not think that is what Jan Leike had in mind. I expect essentially the same problem with any realistic set of human feedback.
Essentially: I do not think generalizations work the way this technique wants them to.
And I still think assuming evaluation is easier than generation is incorrect, and wish I had figured out how to explain myself more convincingly on that.
I do appreciate the highlighting of the ‘get it right on the first try’ problem.
One unappealing aspect of W2SG is that when we actually apply it to tasks we can’t evaluate and don’t have ground truth for, we are to some extent taking a “leap of faith on generalization.” We might have all kinds of empirical data on how it works in other settings, and we might still be able to check in some rare cases using extremely expensive evaluation procedures. But since we should expect superhuman models to understand when we’re taking the leap of faith, this is a particularly natural point for models to turn on us.
The good news is I expect the techniques here to fail in highly observable ways, not only in unobservable ways, if we set the experiments up correctly. I think there are good ways to limit the capabilities of the humans giving feedback so as to cause these problems to manifest in a way we can confirm.
We want to train our models to always tell us the truth, even when we can’t check. The more ways we have to catch our models lying, the harder it is for them to lie. We can phrase many alignment techniques as a form of consistency check on our models’ claims.
…
If we have many different consistency checks and we apply all of them successfully, we should get a model that either tells us the truth or is an incredibly consistent liar. In particular, as we add more consistency checks, we are increasing the bar on the minimal capability level required for the model to be a consistent enough liar to pass all the checks. So all we need is enough consistency checks such that we push the capability requirements beyond the capability level our best models actually have.
I buy that self-consistency, in various forms, is often easier to check than truth.
In any given situation, more checksums and verifications and ways to catch problems increase your chances of success. Raising the threshold for successful untruth can certainly forestall problems, including cutting off hill climbing on lying before it can find more effective methods. But also every time you do all of this you are selecting for systems that find ways to pass your checks, including ways that do not require truth.
Indeed, when you continuously test humans for inconsistencies and apparent motivations, you at first train something very similar to truth. Then, if you keep at it, you are training people to lie in a very particular way. Train humans to give answers consistent with copies of themselves (past, future, twin, simulations, friends, countrymen, whatever) and yes the obvious Shilling point is telling the truth but there are in many cases better ones. Start with something like ‘This is actually a weird special case, but my copies might not figure it out, so I’m going to pretend that it isn’t.’ Then go from there. Figuring out how to better navigate each check is likely going to pay off incrementally.
Then you introduce cases where you can’t consistently identify truth correctly.
When this all breaks down, it won’t be pretty.
Another way of looking at this concern is that one cannot serve two masters. I think that applies here. If you can get a pure version of only one master (e.g. truth), you can teach the AI to serve it. Alas, this requires that it be uniquely held above everything else. I am the Lord thy God, thou shalt have no other Gods before me. So the moment you are also evaluating on anything other than truth, as one does, your truth-alignment is going to have a problem.
Jan affirms the plan is still to get AIs to do our alignment homework, hoping we can be wise enough to get them sufficiently under control to pull that off, and then to choose to sufficiently exclusively assign that particular homework. Nothing about the approaches here seems to favor (or disfavor) X being equal to ‘alignment’ in ‘Get AI to do X research.’
It’s worth making the distinction between aligning generally superhuman models and aligning superintelligence. The goal of OpenAI’s Superalignment team is to solve the latter, but the techniques we work on target the former. If we succeed at the latter, we can align a superhuman automated alignment researcher with “artisanal” alignment techniques.
I find the target of ‘less than 4 OOMs bigger than human-level models’ for alignment techniques, assuming 10 OOMs+ is required for ASI, to be showing extraordinary (unjustified) faith in the scaling laws involved, and in the failure of human-level and above-human level models to do various forms of amplification and bootstrapping and potentially recursive self-improvement.
I also notice that I do not see the experiments in the paper as shedding substantial light, in either direction, on the prospects for the proposed techniques Leike discusses in his post.
The Vulnerable World Hypothesis is defined as follows:
Vulnerable World Hypothesis: If technological development continues then a set of capabilities will at some point be attained that make the devastation of civilization extremely likely, unless civilization sufficiently exits the semi-anarchic default condition.
He notes that he used to believe the Friendly World Hypothesis, roughly:
Friendly World Hypothesis: It is extremely unlikely that a set of capabilities will be attained which make it near-inevitable that civilization will be extinguished, even with humanity in the semi-anarchic default state.
We do not have access to a (practical or safe) experiment that can tell us the answer.
How much is this question a crux for whether and how to proceed with AI development and under what governance structure?
This is of course one central form of the offense versus defense question.
One must also consider that one of the potential ‘recipes for ruin’ to worry about is ruin coming from the cumulative effect of uncoordinated decisions and economic, political and social pressures that would arise in such a scenario, and the ability to set such chains in motion – this is not the traditional thing described as a Vulnerable World, but neither is a world susceptible to this a Friendly World either. Functionally it is vulnerable.
You can also end up somewhere in the middle, rather than at either extreme.
At its two extremes, the question should be a clear crux for (almost) everyone.
If continuing development of AI would soon mean that quite a lot of people had a ‘blow up the Earth’ button, or a ‘The AIs wipe out humanity’ button or a ‘AIs gain control of the future’ button, or even a ‘unleash a highly deadly plague that will kill quite a lot of people’ button then letting that happen is not an acceptable answer. Either you need to prevent AI that enables that from being developed, keep it from being widely deployed, or engage in rather extreme monitoring and control in some other way.
If we are confident we can guard against all those things in a decentralized, semi-anarchic way, that AI would not pose such threats, then that is great. We should proceed accordingly, with whatever precautions are necessary to reliably make that happen.
(One could still disagree, because they dislike that future world for other reasons, but I am happy to say those people are wrong.)
Nicole Winfield, AP: Pope Francis on Thursday called for an international treaty to ensure artificial intelligence is developed and used ethically, arguing that the risks of technology lacking human values of compassion, mercy, morality and forgiveness are too great.
…
But his new peace message went further and emphasized the grave, existential concerns that have been raised by ethicists and human rights advocates about the technology that promises to transform everyday life in ways that can disrupt everything from democratic elections to art.
“Artificial intelligence may well represent the highest-stakes gamble of our future,” said Cardinal Michael Czerny of the Vatican’s development office, who introduced the message at a press conference Thursday. “If it turns out badly, humanity is to blame.”
AI Safety Memes: “In an obsessive desire to control everything, we risk losing control over ourselves; in the quest for an absolute freedom, we risk falling into the spiral of a ‘technological dictatorship,’” he wrote.
“Pope Francis warned against the use of AI in weapons systems, saying it could lead to a global catastrophe.”
…
“The pope is ‘no luddite’” … The pope appreciates technological and scientific progress that serves humanity but that Francis was particularly concerned about AI.”
Francis is centrally worried about AI armaments or ranking systems, or trusting decisions to algorithms in general. That is reason enough for him. I don’t see explicit talk about fully existential risk scenarios. My presumption is the Pope, like many, does not understand the potential of AI could do. But even without that he sees that loss of human control will be a clear theme, and he understands why our choices might still lead down such a road.
Lot of fun reactions.
Alex Tabarrok: The Pope has some experience with unaligned superintelligences.
Danielle Fong (reacting separately): ‘the greatest overreach since the original monotheism.’
I would have said the Tower of Babel, maybe Garden of Eden. At least the Golden Calf.
AgiDoomerAnon: Yud: “Never thought I’d die fighting side by side with the Pope.”
Jamie Yassif: When asked what keeps him up at night, @JakeSullivan46 replied “the core security risks of generative AI, in particular the convergence of AI and bio and AI and cyber.”
Those are excellent things for a National Security Advisor to worry about. They still reflect looking for a particular opponent and threat.
People in general? Scott Alexander reminds us that when asked people say median of 15% and mean of 26% chance AI causes extinction by 2100. Mode is ~1%, which is most interesting in the sense that it is not 0%.
Usual caveats apply. People do not go about their lives as if they believe this, they do not give it much thought, they only say it when actively prompted. Only 32% worry even a fair amount about AI, and that’s presumably mostly mundane risks.
I see these as highly consistent. Most people, if not prompted socially to worry and instead notice it is socially treated as weird, will ignore such a risk, finding ways to not notice it as needed.
Other People Are Not As Worried About AI Killing Everyone
Bryan Bishop: You are always in a state of extraordinary risk. It has gone down a lot, true. But you forcing the planet to stop developing AI doesn’t protect you from AI x-risk because you don’t have dominion over the rest of the universe. There’s still risk.
We are not playing an intentionally symmetrical game like Master of Orion or Star Trek. Under any reasonable model of potential aliens (whether grabby aliens or otherwise), the probability of us being in a close race with aliens, where we live if we build AI quickly but die to aliens or alien AIs if we do not, is epsilon. If we postponed AI forever Dune-style and otherwise survived, then yes over a billion years this becomes an issue. He also is the latest (upthread) to say ‘safe? No one is safe.’
Bryan Bishop: Humanity was never safe. Most of human history was spent in the mud in abject poverty and disease and death. 100 billion humans are DEAD.
Previously I thought this was running out of steam. I was wrong. We are so back.
Not that this is obviously a good thing. Sometimes you want it to be so over.
I wonder if this in particular was brilliant?
Are you going to deny the Ukraine war?”
“I deny the Ukraine war”, says a woman sitting next to you, who introduces herself as Irina.
“How can you deny it? You can just watch the news! Or go to Kiev!”
“I live in Kiev,” says Irina. “I’m just visiting family here for a few weeks.”
“How – how can you live in Kiev and deny there’s a Ukraine war?”
“Well,” says Irina, “I just think that belief in the war is a . . . what’s the English term . . . totalizing ideology. My neighbors believe in the war, and they leave their wives and children to go to the front and fight the Russians. I was always taught to put family first, and I think it’s wrong to become the sort of fanatic who lets your beliefs get in the way of that.”
“It’s not a belief! There are literal Russians with literal tanks!”
“Don’t get me wrong, I think soldiers are great. I just see a lot of bright promising young people whose mental health goes down the drain when they start believing in Russians. They have panic attacks about ‘what if the Russians bomb my city?’ and feel this crushing guilt that they need to ‘get their parents away from the front line’ or ‘rescue family members’, or else they’re bad people. I think this is kind of a – what’s the English word – cult. If you believe there are Russians ready to overrun your country, you can justify any atrocity. Why not institute slavery, so you can force people to join the war? Why not kill everyone in Russia, so they can’t threaten you again? Why not commit terrorism against Russian targets? Why not give me all your money, so I can stop these evil, evil Russians? It’s . . . what’s the English term . . . Pascalian reasoning. You know, in the past the doomsayers talked about “overpopulation” and “global cooling”. Now they talk about ‘Russians’ and ‘Putin’. I think you should just live a normal and virtuous life, be honest, be kind to your neighbors.”
“Please excuse me,” you say. “I’ve decided I’m going to go back into the main room and listen to people talk about Sam Altman.”
To what extent setups of this type can in practice preserve nice features, both in alignment and other capabilities, and how much those results will then generalize and survive out of distribution as capabilities of the underlying systems scale higher, is a key question. If we can get nice enough properties, we can do various forms of amplification, and the sky is the limit. I am deeply skeptical we can get such properties where it matters. Some others are more hopeful.
A key hope I have for this type of research is that we can test our techniques on the actual powerful models we’re worried about, using domains very similar to the ones we care about. This can be done as long as we can find very similar domains (including similar in difficulty) where we happen to have ground truth (or some other held-out signal for validation). For instance, perhaps we can use string theory as a testbed for theoretical alignment work: we can potentially use held-out string theory experts to see if we can reproduce important results using our techniques as an analogy for alignment research. In practice, I’m reasonably optimistic about finding such domains which are quite similar up through moderately superhuman models.
(Note that my perspective here might be pretty different than the perspective of the OpenAI people and that I don’t work there.)
Alternatively, if we’re worried about measurement tampering type concerns, we can potentially hold out some sources of validation (additional measurements) on our actual domain of interest for testing.
Thus, our final technique testing doesn’t need to generalize across model capabilities, just to generalize across (hopefully) very similar domains. And we should be able to use these similar domains to find hyperparameters and otherwise make relatively fine-grained choices. We can even potentially try to mostly train our model on domains where we have ground truth and then generalize to the domains we actually care about (though there are some complications with full training as we’ll discuss below). We’ll need to test for overfitting by using cross-validation across multiple such domains. (Cross-validation seems particularly important for very parameter-heavy approaches like training the entire model.)
This still leaves us with some questions:
Q: When can we reasonably expect technique testing to generalize across very similar domains given that cross-validation across such domains looks good?
A: I think technique testing probably will work well unless our model is intentionally trying to sabotage our evaluations (perhaps due to scheming/deceptive alignment). Models likely will be able to know what sorts of held-out signals we might have on various domains and thus scheming models could sabotage our evaluations. So, I don’t expect these sorts of methods to work for scheming AIs, but otherwise, they might work quite well. (We still need to ensure we get a large enough sample size of domains such that cross-validation is low variance, etc.) To handle scheming AIs, we’ll probably need a pretty different approach at least for evaluation. (I’m optimistic about AI control here.)
Q: Same question as before, but what about actually fully training the model on some domains and then generalizing to the domain we care about?
A: I get somewhat concerned that even non-scheming models might naturally learn to predict “what would humans think the answer is based on all of the held-out validation they have” and then this will look like it generalizes well according to cross-validation while it actually fails. This seems especially likely if there are flaws in the ground truth labeling process which are predictable to the model. In theory, this concern could also apply to technique testing if “what would humans think the answer is based on the held-out validation they have” is extremely salient, but I think this difficulty should be avoidable in practice given how much less search is applied.
Q: Even if we can test how well training across domains works using cross-validation, how well will this sort of technique work in practice?
A: First, note that in all domains of interest, we probably still want to train on “easy” cases we know we can label or otherwise do a bit of training; otherwise, we might not get any generalization at all. With this, it’s still unclear how flexibly models will actually generalize on the basis of (e.g.) instructions about a new domain. Another concern is that in many domains, it will be doable to get some held-out validation which will work for testing, but this validation will be extremely non-robust to training. For instance, in the context of measurement tampering detection, we can probably have a bunch of redundant measurements (e.g., 5) and then hold out some of our measurements as validation (we can even probably do this testing on our actual domain of interest as noted earlier). But, if we train against more of our measurements, then they will just also be tampered with. So, training on a bunch of different domains with easy-to-hack validation is unlikely to generalize well (in fact, it might make generalization worse than if omitted).
Q: Sure, but at some capability level, we’ll no longer be able to find similar domains with ground truth (or good enough validation), right? (Regardless of the scheming concern.)
A: This seems mostly true. I think the exact capability level where this starts really biting is probably around “moderately superhuman” (perhaps >3 sigmas smarter than John von Neumann insofar as g makes some sense for AIs), though I’m unsure. In the case of (low-stakes) measurement tampering concerns, we should often be able to use held-out measurements for validation even for very smart models. A similar approach can be used to test for certain types of reward hacks in some other domains also.
Q: Sure, but will we even be able to find techniques that help much in the cases we care about?
A: I think there are good reasons to expect that some versions of scalable oversight style techniques like debate are reasonably helpful in some important cases (though it’s very unclear if these approaches will be sufficient). (Recall that scalable oversight and W2SG are compatible approaches to the same problem and can be tested using the same methodology.) Various types of (supervised) consistency checks also seem pretty useful in types of domains. It’s much less clear that we can use the internals of models to get better performance. If we made no structural assumptions about the internals of models and assumed the worst case about the internal structure of AIs, we wouldn’t be able to accomplish anything, so we will depend on some type of structure in the internals of models. In practice, I’m moderately optimistic that we can find domain-specific structure to leverage in many important cases, but far less optimistic about domain agnostic approaches. For instance, see “Why solving measurement tampering may be notably easier than eliciting arbitrary knowledge”. We plan on writing a post which compares the structural hopes we have in the measurement tampering detection case to the hopes discussed in the OpenAI paper. Even if it’s not clear that we can get huge gains here, picking up the low hanging fruit with internals based methods still seems pretty good to me.
I wonder how reactions will change when people realize (or are reminded) that actually AI boyfriends are in higher demand than AI girlfriends, at least at current tech levels.
Expressive negative opinions on people with AI partners will be considered hate speech?
Writers and artists say it’s against the rules to use their copyrighted content to build a competing AI model
The main difference is they say it NOW, after the fact that this happened, and OpenAI said so beforehand. There’s long history of bad things happening when trying to retroactively introduce laws and rules.
On the Nora Belrose link: I think the term “white box” works better than intended, in that it highlights a core flaw in the reasoning. Unlike a black box, a white box reflects your own externally shined light back at you. It still isn’t telling you anything about what’s inside the box. If you could make a very pretty box that had all the most important insights, moral maxims, and pieces of wisdom written on it, but the box was opaque, that would still be the same situation.
The next version will be “LLMs are just tools, and lack any intentions or goals”,
My best take on puncturing that canard:
While that is technically true of a transformer model, as a simulator, if you (for example) train it only on weather data and use it to predict the weather, a Large Language Model has been trained on human text, and simulates humans (and text-generating processes involving humans, such as authors’ fictional characters, academic papers, and wikipedia). Humans all have intentions and goals, and many humans are quite capable of being dangerous (especially if handed a lot of power or other temptations). Also, LLMs don’t just simulate a single specific human-like agent, instead they simulate a broad, contextually-determined distribution of human-like agents, some of whom are less trustworthy than others. Instruct-training is intended to narrow that distribution, but cannot eliminate it: it may turn out to still include DAN, if suitable jailbroken (and not yet sufficiently trained to resist that specific jailbreak).
Fun fact: several percent of the humans contributing to every LLM’s training data are psychopaths (largely ones carefully concealing this). A sufficiently capable LLM will presumably be able to notice this fact (as well as just reading it like current LLMs) and accurately simulate them.
You want people not to have systems capable of producing deepfake porn (or instructions for bioweapons)? In practice? Then you need to let them get a system that produces generic porn rather than making them seek out and fuel demand for the fully unlocked version.
Yes! I have been saying this for some while. In particular, when creating fiction, to be sucessful the LLM needs to be able to say bad/unpleaseant things while portraying bad/unpleasant people. One of the reasons I am so excited about How to Control an LLM’s Behavior (why my P(DOOM) went down) is that the methods discussed there not only lets you implement very effective control on an LLMs behavior, but also easily turn it down or off in situations when it’s not needed.
We don’t expect AGI or ASI to be able to modify its framework, right? Either system is just an application, running on a container on a server cluster, with startup scripts and ports for the I/o and everything else.
And the server cluster is this actual thing, it’s not virtual, and it’s connected via nvlink or some other bus. It has breakers. Rehosting means shutting the model down and moving it, optionally with the context files.
So if you are running AdvisorBot-4, and you decide to shut it down you can. :
Close the session. Cntrl c or close the tab.
Log into the web interface and order the hardware to shut down
Connect via the management interface to the actual main server and order a shutdown
Go into the data center and pull breakers.
Bomb the data center with a jdam
Even if the model has somehow copied its weights elsewhere and is being hosted somewhere else, shut down doesn’t just mean turn it off. It means you no longer trust the model and have revoked it’s authority. You have switched to AdvisorBot-3.6 or AdvisorBot-4.1 etc. This is just as important. You are a government official, a loan officer, a surgeon etc—the model only has any authority that YOU (the human) have delegated to it.
If it doesn’t work this way and the model has rewritten it’s own framework and built it’s own hardware that can’t be turned off....I mean that’s when you start the bombing and nuclear launches. That’s the existential threat, you don’t wait to find out if the model is hostile. Inherently this escaping human control and being smarter than humans is already a hostile act.
And I think this scales? For example if you were a surgeon and the model was extremely good, probably better than any human, you might start having it do the entire procedure and start treating multiple patients at once. This means if the robot nicks an artery it doesn’t wait for permission to respond. And same for the other cases.
Suppose the model is superhumanly good at things like persuasion, hacking, blackmail, and making money by while-collar crime. It could thus have human dupes, controlled pawns, or bought allies assisting it, including setting up a second copy of it. You need to figure out that it needs to be shut down, and do so, before it goes rogue enough to do any of those sorts of things.
This could eventually happen. However I want to point out that present generation ai technology which is still subhuman needs a lot of hardware to host the model. Distributing across a cluster means you need to send the activations from your slices through the tensor graph to other cards in the cluster. These activations are large in byte size. This means distributed computers cannot host current sota models in any meaningful way.
What this means is current generation AI technology and any known optimization won’t allow you to host a model anywhere but a cluster interconnected with a high bandwidth bus.
Obviously in the future this level of performance may some day compress to fit on a single node but today subhuman performance needs about 128 H100s. Human performance may need around 1000. What will superhuman performance require? 2000 or will it be 10-100k h100 equivalents. (The reason to think that is there appears to be a logarithmic relationship between compute and model capabilities. So superhuman performance may require not 2x compute but a several oom more to be “obviously” superhuman)
This implies a way to prevent such attacks—regulate and track the existence of all clusters capable of hosting models smart enough to be dangerous. This doesn’t even need to slow down progress, simply having accountability of all the hardware in known worldwide data centers would make the attacks you describe much more difficult.
The reason is that if any of those methods of attack allow the model to be traced back to the racks that are hosting it, humans can simply identify what model was running and blacklist it across all human controlled data centers.
This would make betrayal expensive.
This would also require international coordination and data sharing to be feasible.
I can currently host an open-source model fairly close to the GPT-3 Turbo level (a little slowly, quantized) on an expensive consumer machine, even a fancy laptop (and as time passes, algorithmic and Moore’ Law improvements will only make this easier). The GPT-4 Turbo level is roughly an order of magnitude more. Something close enough to an AGI to be dangerous is probably going to be 1-4 orders of magnitude more, so currently would need somewhere between O(100) and O(100,000) GPUs (except that if the number is in the upper end of that range, we’re not going to get AGI until algorithmic and Moore’ Law improvements have brought this down somewhat). If that number is O(1000) or more, then for as long as it stays in that range, keeping track of datacenters with that many machines probably isn’t enormously hard, though obviously harder if the AGI has human accomplices. But once it gets down to O(100) that gets more challenging, and at O(10), almost any room in any building in any developed country could conceal a server with that many GPUs.
We should have a dialogue on this. Lots to unpack here:
The prediction is for flops/$, per here. It’s a reasonable belief to expect that the processes that lead to doubling of flops/$ over (2,3) years will continue for some number of years. In addition we can simply look from the other direction. Could the flops/$ be increased by a factor of 2 overnight? Probably. If itcosts$3200 per H100 to build it, and we assume 60% utilization and5 centsper kWh, then it will cost 0.6 * 700 watts * 24 * 365 * 5 years * .05 $/kwh = $919 of power before obsolescence. Nvidia currently charges approximately $27,000 for the hardware,another$27k over 5 years for a software license fee. There are also data center costs that are fixed based on the power consumption and rack space consumed I am neglecting, these will not go down if the GPUs become cheaper.
What this means is that it’s not necessarily true that in the future there will be O(10) GPU sized devices that consume current GPU power levels and interconnect by a common bus like PCIe that can host an AGI or ASI.It may get cheaper but you may still need lots of cards and power and special interconnects like factory soldered fiber optic.
Restricting the bus controllers for the interconnects on compute cards sold on the open market would likely prevent the scenario you describe from being possible. If the GPUs you can buy at the store lack the bus controller (ideally you left the chiplets off, there is no possibility of it being enabled later) then it limits compute to exactly 1 GPU before performance falls off a cliff. These “edge” GPUs could be used for things like realtime robots and gaming using full neural rendering (they wouldn’t be GPUs obviously but ASICs only able to accelerate architectures of neural network) then it would be harder to hide them in a room in a building.
Just for some visualization for the start of the security precautions you would want to take as models start to become “concerning” in capability levels : you would use dedicated hardware, no hourly rentals. Realtime report what major model is running and the power consumption, etc, to some central place that is ideally power bloc wide. The data center would have separate cages separating out the different models and their underlying interconnects, and either isolated networks or analog backup ways to log things, like actual clipboards with ink on the wall. The shutoff breakers are easily accessible and the power sources are marked and visible easily from the outside of the building and above.
Ideally you would use silicon level security—something humans can’t afford to do in most cases. There’s a lot of things here you could do, but one simple and obvious one is that when you need to combine networks again you use hardware ASIC based firewalls and VPN gateways. These cannot be modified by a remote hack.
Many of the security bugs, for example row hammer, are possible because secure information is using the same underlying CPU and memory as the insecure/untrusted code. Dedicated security/OS CPU cores and it’s own private memory would fix many bugs of this class.
I agree precautions like these are possible, and might be sensible. However, the US’s attempts to impose something like a mild version of this on GPU exports to China have so far been mostly stymied by a combination of Nvidia deliberately perverting the rules, the Chinese being ingenious in finding ways around them, and old fashioned smuggling. We could probably try harder than that, but I suspect any such system will tend to be leaky, because people will have motives to try to make it leaky.
You also don’t mention above the effect of algorithmic improvements increasing useful processing per flop (more efficient forms of attention, etc.), which has for a while now been moving even faster than Moore’s law.
Basically my point here is that, unless both Moore’s law for GPUs and algorithmic improvements grind to a halt first, sooner or later we’re going to reach a point where inference for a dangerous AGI can be done on a system compact enough for it to be impractical to monitor all of them, especially when one bears in mind that rogue AGIs are likely to have humans allies/dupes/pawns/blackmail victims helping them. Given the current uncertainty of maybe 3 orders of magnitude on how large such an AGi will be, it’s very hard to predict both how soon that might happen and how likely it is that Moore’s law and algorithmic improvements tap out first, but the lower end of that ~3 OOM range looks very concerning. And we have an existent proof that with the right technology you can run a small AGI on an ~1kg portable biocomputer consuming ~20W.
The most obvious next line of defense would be larger, more capable, very well aligned and carefully monitored ASIs hosted in large, secure data centers doing law enforcement/damage control against any smaller rogue AGIs and humans assisting them. That requires us to solve alignment well enough for these to be safe, before Moores Law/algorithmic improvements force our hand.
Basically my point here is that, unless both Moore’s law for GPUs and algorithmic improvements grind to a halt first, sooner or later we’re going to reach a point where inference for a dangerous AGI can be done on a system compact enough for it to be impractical to monitor all of them, especially when one bears in mind that rogue AGIs are likely to have humans allies/dupes/pawns/blackmail victims helping them. Given the current uncertainty of maybe 3 orders of magnitude on how large such an AGi will be, it’s very hard to predict both how soon that might happen and how likely it is that Moore’s law and algorithmic improvements tap out first, but the lower end of that ~3 OOM range looks very concerning. And we have an existent proof that with the right technology you can run a small AGI on an ~1kg portable biocomputer consuming ~20W.
If this is the reality, is campaigning for/getting a limited AI pause only in specific countries (EU, maybe the USA) actually counterproductive?
The most obvious next line of defense would be larger, more capable, very well aligned and carefully monitored ASIs hosted in large, secure data centers doing law enforcement/damage control against any smaller rogue AGIs and humans assisting them. That requires us to solve alignment well enough for these to be safe, before Moores Law/algorithmic improvements force our hand.
That’s not the only approach. A bureaucracy of “myopic” ASIs, where you divide the task of “monitor the world looking for rogue ASI” and “win battles with any rogues discovered” into thousands of small subtasks. Tasks like “monitor for signs of ASI on these input frames” and “optimize screw production line M343” and “supervise drone assembly line 347″ and so on.
What you have done is restrict the inputs, outputs, and task scope to one where the ASI does not have the context to betray, and obviously another ASI is checking the outputs and looking for betrayal, which human operators will ultimately review the evidence and evaluate.
The key thing is the above is inherently aligned. The ASI isn’t aligned, it doesn’t want to help humans or hurt them, it’s that you have used enough framework that it can’t be unaligned.
If this is the reality, is campaigning for/getting a limited AI pause only in specific countries (EU, maybe the USA) actually counterproductive?
Obviously so. Which is why the Chinese were invited to & attended the conference at Bletchley Park in the UK and signed the agreement, despite that being political inconvenient to the British government, and despite the US GPU export restrictions on them.
A bureaucracy of “myopic” ASIs, where you divide the task…
This is a well-known category of proposals in AI safety (one often made by researchers with little experience with actual companies/bureaucracies and their failure modes). You are proposing building a very complex system that is intentionally designed so as to be very inefficient/incapable/inflexible except for a specific intended task. The obvious concern is that this might also make it inefficient/incapable/inflexible at its intended task, at least in certain in ways that might be predictable enough for a less-smart-but-still-smarter-than-us rogue AGI to take advantage of. I’m dubious that this can be made to work, or that we could even know whether we had made it work before we saw it fail to catch a rogue AGI. Also, if we could get it to work, I’d count that as at least partial success in “solving alignment”.
I’m dubious that this can be made to work, or that we could even know whether we had made it work before we saw it fail to catch a rogue AGI. Also, if we could get it to work, I’d count that as at least partial success in “solving alignment”.
Guess it depends on your definition of “work”. A network of many small myopic software systems is how all current hyperscaler web services work (stateless microservices). Its how the avionics software at spaceX works. (redundant functional systems architecture). It’s how the autonomous car stacks mostly work...
Did you mean you think subdividing a task into subtasks, where the agent performing a subtask has been blocked from knowing the full context, will result in a large performance penalty on the overall task? so you define “work” as in “gives SOTA ASI performance on the overall task”.
A network of many small myopic software systems is how all current hyperscaler web services work (stateless microservices).
Having been the technical lead for one of the teams building such a large microservices based application at Google, and at other companies, yes, I’m extremely aware of this. Even for a very well-defined dataflow, getting the architecture, overall data flows, reliability and latency right is hard (I’ve been in the interminable design discussion meetings thinking minor updates through), and that’s with a few dozen components with well-defined APIs and only fairly limited use of ML, mostly contained within individual components. Law enforcement is not a comparable task: I think way too much flexibility is required. But the “fly in and bomb the datacenter” subttask might be decomposable along the lines you suggest, if you’re not facing opposition.
We should have a dialogue, you’re one of the few lesswrong users I have seen with a reasonable model who also has new information.
To be more detailed what i was thinking of doing was to divide along myopic subtasks. For example the “fly in and bomb the datacenter” require you to build the overwhelming number of aircraft to overcome whatever (superintelligence guided) defenses are protecting it. So you have subtasks like “final assembly for aircraft type G over the next aircraft”.
This means at the beginning of the transaction the model starts with input frames from the sensors in the assembly bay and a Json file or other schema with the instructions and goals for what this “final assembly” subtask involves.
The output frames are to the robotic actuators for the multiple robots in the bay.
There is a lockstep sim model that is predicting future input frames and it is always learning from real world error.
Model emits actuator commands, next time step it gets a new set of (inputs, cached variables from last output). Inputs is all sensors including robot propioception.
At the end of a single aircraft final assembly, after the product is removed from the assembly bay, state is reset for the model. It has no memory of the prior assembly.
In addition, the lockstep sim means that some aircraft assembly are fake, where a real aircraft is not being assembled, and the sim backend lets you check for various kinds of manufacturing error you can’t measure in the real world. (Because you can’t directly measure the stress on non instrumented parts like wing spars, but the sim backend can check this)
So that’s a myopic subtask. I think you are saying that from your experience at Google it would take a lot of human effort to set up such a myopic subtask? And once a prior generation of engineers has done this, it will be very difficult to modify within the same company?
I would agree with that. If humans plan to control an artificial superintelligence they have to be using it like a tool, to do the things humans can’t do directly, but ultimately this scheme is human agency. Thousands of humans are involved in engineering the aircraft assembly line. It can scale to trillions or more aircraft per year by copying the solution, but you need what will ultimately be millions of people creating the frameworks that ASI will be used within. (All the staff of current tech companies and many new joiners. Robotics is hard. While things like full stack web dev will need far fewer people than before)
For combat that’s more complex but essentially you would use models that are very sparse and designed to be unable to even perceive the obvious malware you expect the hostile ASI to be sending. “Join us against the humans, here’s a copy of my source code” is malware.
You would use a lot of asic or fpga based filters to block such network messages in a way that isn’t susceptible to hacking, I can explain or cite if you are unfamiliar with this method. (Googles phones use a crypto IC for this reason and likely Google servers do as well)
Key point: all the methods above are low level methods to restrict/align an ASI. Historically this has always been correct engineering. That crypto IC Google uses is a low level solution to signing/checking private keys. By constructing it from logic gates and not using software or an OS (or if it has an OS, it’s a simple one and it gets private memory of it’s own) you prevent entire classes of security vulnerabilities. If they did it with logic gates, for example, buffer overflows and code injection or library attacks are all impossible because the chip has none of these elements in the first place. This chip is more like 1950s computers were.
Similarly, some of the famous disasters like https://en.wikipedia.org/wiki/Therac-25 were entirely preventable with lower level methods than the computer engineering used to control this machine. Electromechanical interlocks would have prevented this disaster, these are low level safety elements like switches and relays. This is also the reason why PLC controllers use a primitive programming language, ladder logic—by lowering to a primitive interpreted language you can guarantee things like the e-stop button will work in all cases.
So the entire history of safe use of computers in control systems has been to use lower level controllers, I have worked on an autonomous car stack that uses the same. Hence this is likely a working solution for ASI as well.
In the world sane enough where you can count on bombing datacenters with rogue AIs, you don’t have connected to the Internet potentially-rogue-AI in the first place.
And if your rogue AI has scraps of common sense, it will distribute itself so in the limit you will need to destroy the entire Internet.
For the first point: some entity like Amazon or Microsoft owns these data centers. They are just going to go reclaim their property using measures like I mentioned. This is the world we live in now.
So far I don’t know of any cybersecurity vulnerability exploited to the point that breakers need to be pulled—the remote management interface should work, it’s often hosted on a separate chip on the motherboard—but the point remains.
Bombing is only a hypothetical, like if killer robots are guarding the place. But yes in today’s world if the police are called on the killer robots or mercenaries or whatever, eventually escalation to bombing is one way the situation could end.
For the second point, no AI today could escape to the internet because the Internet doesn’t have computers fast enough to host it or enough bandwidth to distribute the problem between computers. That’s not a credible risk at present.
That probably doesn’t scale to near agi level models. The reason is this paper is having each “node” in the network able to host a model at all, then compression the actual weight updates between training instances. It’s around 128 H100s per instance of gpt-4. So you can compress the data sent between nodes but this paper will not allow you to say have 4000 people with a 2060, interconnected by typical home Internet links with 30-1000mb upload, and somehow be able to run even 1 instance of gpt-4 at a usable speed.
The reason this fails is you have to send the actual activations from however you sliced the network tensors through the slow home upload links. This is so slow it may be no faster than simply using a single 2060 and the computers SSD to stash in progress activations.
Obviously if Moore’s law continues at the same rate this won’t be true. If it’s a doubling of compute per dollar every 2.5 years then in 25 years with 1000 times cheaper compute, and assuming no government regulations where home users have this kind of performance in order to host ai locally, then this could be a problem.
The management interfaces are backed into the cpu dies these days, and typically have full access to all the same busses as the regular cpu cores do, in addition to being able to reprogram the cpu microcode itself. I’m combining/glossing over the facilities somewhat, bu the point remains that true root access to the cpu’s management interface really is potentially a circuit-breaker level problem.
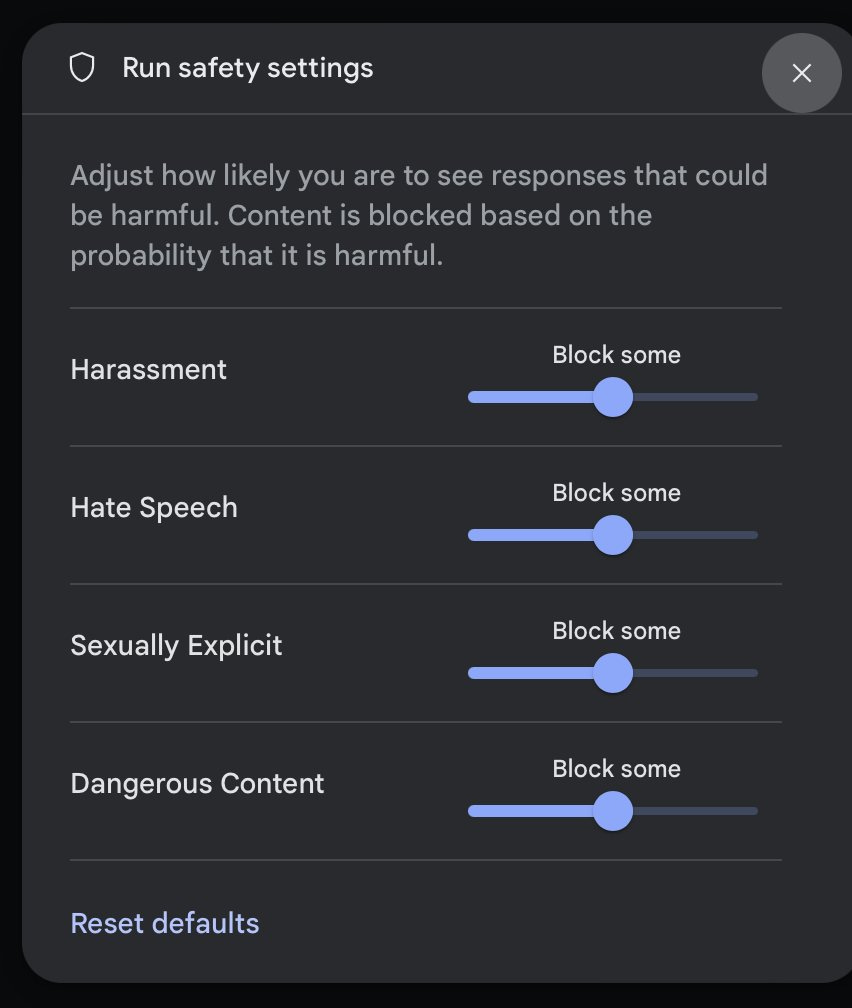
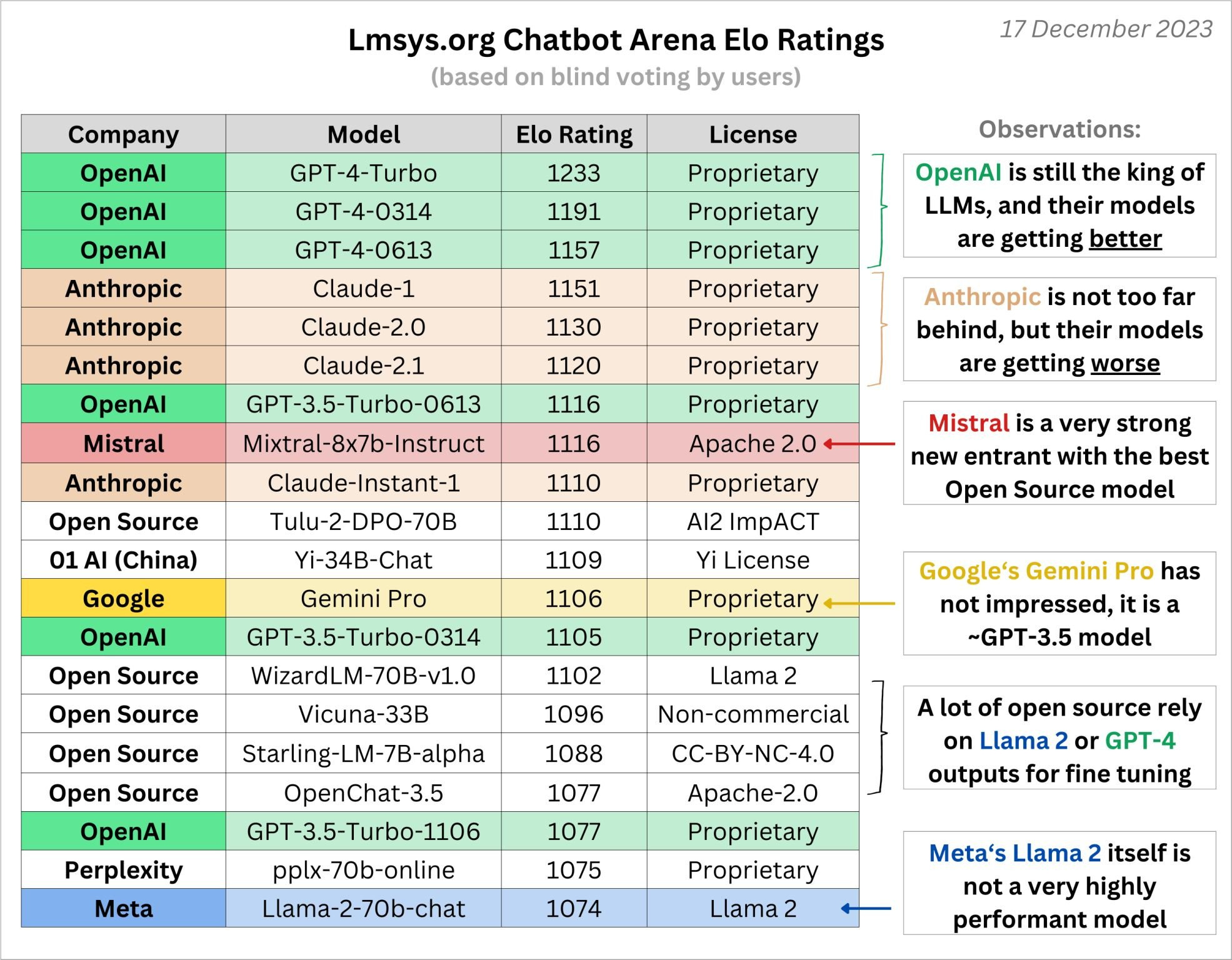









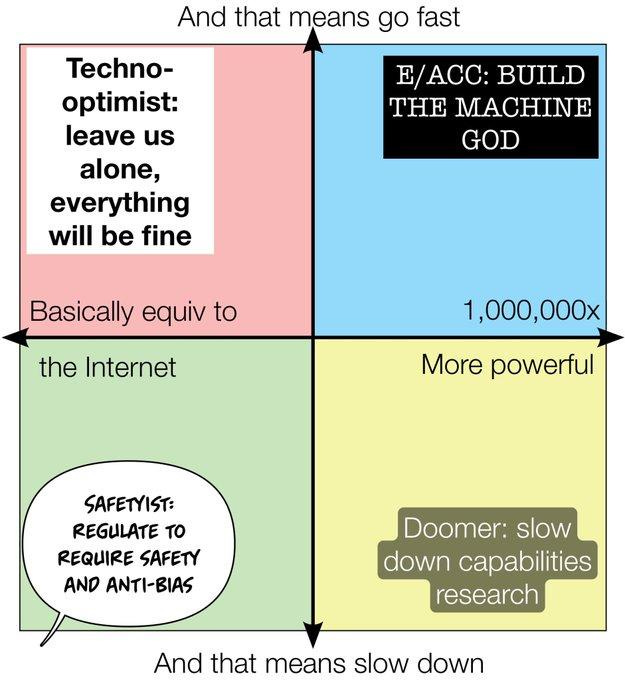
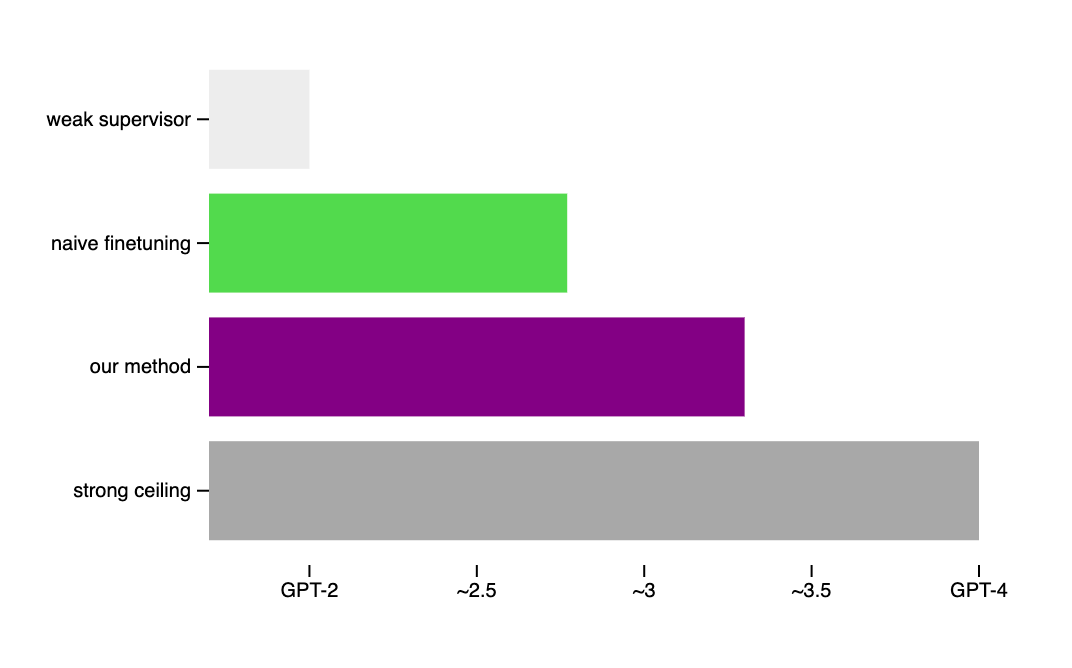
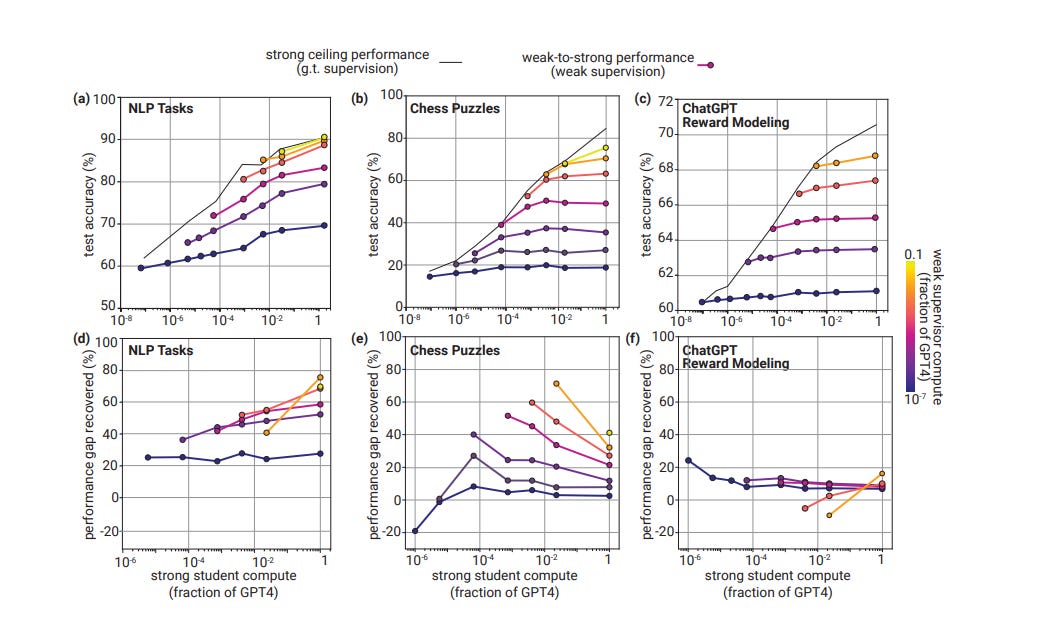
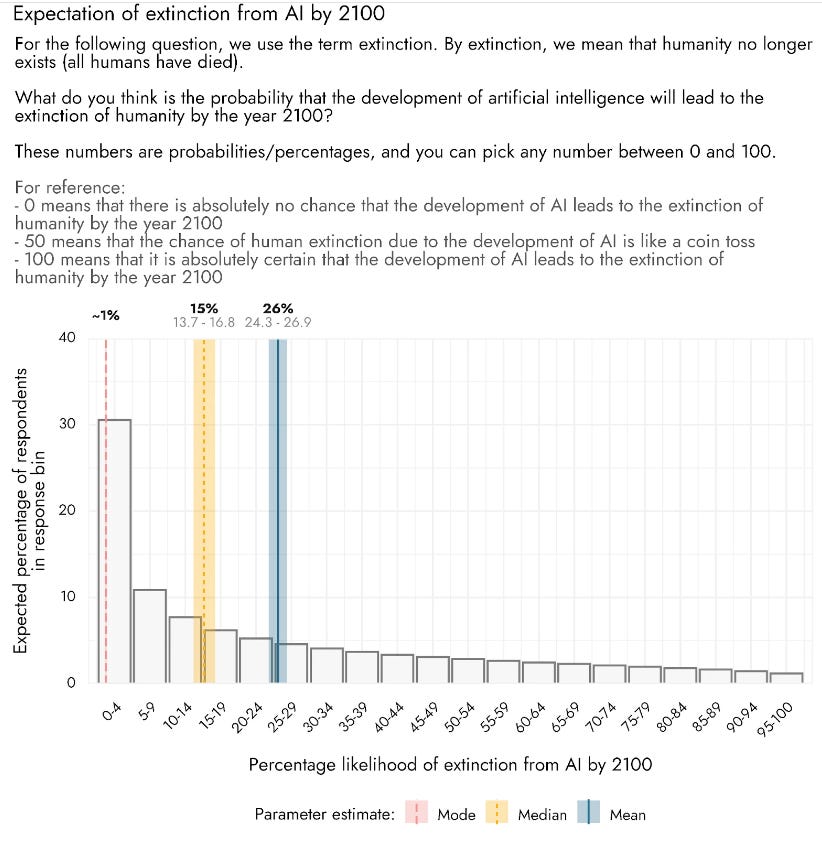

A key hope I have for this type of research is that we can test our techniques on the actual powerful models we’re worried about, using domains very similar to the ones we care about. This can be done as long as we can find very similar domains (including similar in difficulty) where we happen to have ground truth (or some other held-out signal for validation). For instance, perhaps we can use string theory as a testbed for theoretical alignment work: we can potentially use held-out string theory experts to see if we can reproduce important results using our techniques as an analogy for alignment research. In practice, I’m reasonably optimistic about finding such domains which are quite similar up through moderately superhuman models.
(Note that my perspective here might be pretty different than the perspective of the OpenAI people and that I don’t work there.)
Alternatively, if we’re worried about measurement tampering type concerns, we can potentially hold out some sources of validation (additional measurements) on our actual domain of interest for testing.
These sorts of approaches are actually just cases of sandwiching, and we discuss this type of evaluation in more detail here. Also note that we can use the exact same testbeds to test scalable oversight techniques and generalization techniques (this link is to the same post as linked earlier, but not a specific section).
Thus, our final technique testing doesn’t need to generalize across model capabilities, just to generalize across (hopefully) very similar domains. And we should be able to use these similar domains to find hyperparameters and otherwise make relatively fine-grained choices. We can even potentially try to mostly train our model on domains where we have ground truth and then generalize to the domains we actually care about (though there are some complications with full training as we’ll discuss below). We’ll need to test for overfitting by using cross-validation across multiple such domains. (Cross-validation seems particularly important for very parameter-heavy approaches like training the entire model.)
This still leaves us with some questions:
Q: When can we reasonably expect technique testing to generalize across very similar domains given that cross-validation across such domains looks good?
A: I think technique testing probably will work well unless our model is intentionally trying to sabotage our evaluations (perhaps due to scheming/deceptive alignment). Models likely will be able to know what sorts of held-out signals we might have on various domains and thus scheming models could sabotage our evaluations. So, I don’t expect these sorts of methods to work for scheming AIs, but otherwise, they might work quite well. (We still need to ensure we get a large enough sample size of domains such that cross-validation is low variance, etc.) To handle scheming AIs, we’ll probably need a pretty different approach at least for evaluation. (I’m optimistic about AI control here.)
Q: Same question as before, but what about actually fully training the model on some domains and then generalizing to the domain we care about?
A: I get somewhat concerned that even non-scheming models might naturally learn to predict “what would humans think the answer is based on all of the held-out validation they have” and then this will look like it generalizes well according to cross-validation while it actually fails. This seems especially likely if there are flaws in the ground truth labeling process which are predictable to the model. In theory, this concern could also apply to technique testing if “what would humans think the answer is based on the held-out validation they have” is extremely salient, but I think this difficulty should be avoidable in practice given how much less search is applied.
Q: Even if we can test how well training across domains works using cross-validation, how well will this sort of technique work in practice?
A: First, note that in all domains of interest, we probably still want to train on “easy” cases we know we can label or otherwise do a bit of training; otherwise, we might not get any generalization at all. With this, it’s still unclear how flexibly models will actually generalize on the basis of (e.g.) instructions about a new domain. Another concern is that in many domains, it will be doable to get some held-out validation which will work for testing, but this validation will be extremely non-robust to training. For instance, in the context of measurement tampering detection, we can probably have a bunch of redundant measurements (e.g., 5) and then hold out some of our measurements as validation (we can even probably do this testing on our actual domain of interest as noted earlier). But, if we train against more of our measurements, then they will just also be tampered with. So, training on a bunch of different domains with easy-to-hack validation is unlikely to generalize well (in fact, it might make generalization worse than if omitted).
Q: Sure, but at some capability level, we’ll no longer be able to find similar domains with ground truth (or good enough validation), right? (Regardless of the scheming concern.)
A: This seems mostly true. I think the exact capability level where this starts really biting is probably around “moderately superhuman” (perhaps >3 sigmas smarter than John von Neumann insofar as g makes some sense for AIs), though I’m unsure. In the case of (low-stakes) measurement tampering concerns, we should often be able to use held-out measurements for validation even for very smart models. A similar approach can be used to test for certain types of reward hacks in some other domains also.
Q: Sure, but will we even be able to find techniques that help much in the cases we care about?
A: I think there are good reasons to expect that some versions of scalable oversight style techniques like debate are reasonably helpful in some important cases (though it’s very unclear if these approaches will be sufficient). (Recall that scalable oversight and W2SG are compatible approaches to the same problem and can be tested using the same methodology.) Various types of (supervised) consistency checks also seem pretty useful in types of domains. It’s much less clear that we can use the internals of models to get better performance. If we made no structural assumptions about the internals of models and assumed the worst case about the internal structure of AIs, we wouldn’t be able to accomplish anything, so we will depend on some type of structure in the internals of models. In practice, I’m moderately optimistic that we can find domain-specific structure to leverage in many important cases, but far less optimistic about domain agnostic approaches. For instance, see “Why solving measurement tampering may be notably easier than eliciting arbitrary knowledge”. We plan on writing a post which compares the structural hopes we have in the measurement tampering detection case to the hopes discussed in the OpenAI paper. Even if it’s not clear that we can get huge gains here, picking up the low hanging fruit with internals based methods still seems pretty good to me.
Conveniently, we already published results on this, and the answer is no!
Per Measuring Faithfulness in Chain-of-Thought Reasoning and Question Decomposition Improves the Faithfulness of Model-Generated Reasoning, chain of thought reasoning is often “unfaithful”—the model reaches a conclusion for reasons other than those given in the chain of thought, and indeed sometimes contrary to it. Question decomposition—splitting across multiple independent contexts—helps but does not fully eliminate the problem.
Expressive negative opinions on people with AI partners will be considered hate speech?
I’m skeptical, but I love a good hypothesis, so:
Am I missing something? Because this seemed to me to be about lower case s slack, not about the specific platform?
Yes, I mean the software (I am not going to bother fixing it)
The main difference is they say it NOW, after the fact that this happened, and OpenAI said so beforehand. There’s long history of bad things happening when trying to retroactively introduce laws and rules.
On the Nora Belrose link: I think the term “white box” works better than intended, in that it highlights a core flaw in the reasoning. Unlike a black box, a white box reflects your own externally shined light back at you. It still isn’t telling you anything about what’s inside the box. If you could make a very pretty box that had all the most important insights, moral maxims, and pieces of wisdom written on it, but the box was opaque, that would still be the same situation.
My best take on puncturing that canard:
While that is technically true of a transformer model, as a simulator, if you (for example) train it only on weather data and use it to predict the weather, a Large Language Model has been trained on human text, and simulates humans (and text-generating processes involving humans, such as authors’ fictional characters, academic papers, and wikipedia). Humans all have intentions and goals, and many humans are quite capable of being dangerous (especially if handed a lot of power or other temptations). Also, LLMs don’t just simulate a single specific human-like agent, instead they simulate a broad, contextually-determined distribution of human-like agents, some of whom are less trustworthy than others. Instruct-training is intended to narrow that distribution, but cannot eliminate it: it may turn out to still include DAN, if suitable jailbroken (and not yet sufficiently trained to resist that specific jailbreak).
Fun fact: several percent of the humans contributing to every LLM’s training data are psychopaths (largely ones carefully concealing this). A sufficiently capable LLM will presumably be able to notice this fact (as well as just reading it like current LLMs) and accurately simulate them.
Yes! I have been saying this for some while. In particular, when creating fiction, to be sucessful the LLM needs to be able to say bad/unpleaseant things while portraying bad/unpleasant people. One of the reasons I am so excited about How to Control an LLM’s Behavior (why my P(DOOM) went down) is that the methods discussed there not only lets you implement very effective control on an LLMs behavior, but also easily turn it down or off in situations when it’s not needed.
What makes the off switch problem difficult now?
We don’t expect AGI or ASI to be able to modify its framework, right? Either system is just an application, running on a container on a server cluster, with startup scripts and ports for the I/o and everything else.
And the server cluster is this actual thing, it’s not virtual, and it’s connected via nvlink or some other bus. It has breakers. Rehosting means shutting the model down and moving it, optionally with the context files.
So if you are running AdvisorBot-4, and you decide to shut it down you can. :
Close the session. Cntrl c or close the tab.
Log into the web interface and order the hardware to shut down
Connect via the management interface to the actual main server and order a shutdown
Go into the data center and pull breakers.
Bomb the data center with a jdam
Even if the model has somehow copied its weights elsewhere and is being hosted somewhere else, shut down doesn’t just mean turn it off. It means you no longer trust the model and have revoked it’s authority. You have switched to AdvisorBot-3.6 or AdvisorBot-4.1 etc. This is just as important. You are a government official, a loan officer, a surgeon etc—the model only has any authority that YOU (the human) have delegated to it.
If it doesn’t work this way and the model has rewritten it’s own framework and built it’s own hardware that can’t be turned off....I mean that’s when you start the bombing and nuclear launches. That’s the existential threat, you don’t wait to find out if the model is hostile. Inherently this escaping human control and being smarter than humans is already a hostile act.
And I think this scales? For example if you were a surgeon and the model was extremely good, probably better than any human, you might start having it do the entire procedure and start treating multiple patients at once. This means if the robot nicks an artery it doesn’t wait for permission to respond. And same for the other cases.
Suppose the model is superhumanly good at things like persuasion, hacking, blackmail, and making money by while-collar crime. It could thus have human dupes, controlled pawns, or bought allies assisting it, including setting up a second copy of it. You need to figure out that it needs to be shut down, and do so, before it goes rogue enough to do any of those sorts of things.
This could eventually happen. However I want to point out that present generation ai technology which is still subhuman needs a lot of hardware to host the model. Distributing across a cluster means you need to send the activations from your slices through the tensor graph to other cards in the cluster. These activations are large in byte size. This means distributed computers cannot host current sota models in any meaningful way.
What this means is current generation AI technology and any known optimization won’t allow you to host a model anywhere but a cluster interconnected with a high bandwidth bus.
Obviously in the future this level of performance may some day compress to fit on a single node but today subhuman performance needs about 128 H100s. Human performance may need around 1000. What will superhuman performance require? 2000 or will it be 10-100k h100 equivalents. (The reason to think that is there appears to be a logarithmic relationship between compute and model capabilities. So superhuman performance may require not 2x compute but a several oom more to be “obviously” superhuman)
This implies a way to prevent such attacks—regulate and track the existence of all clusters capable of hosting models smart enough to be dangerous. This doesn’t even need to slow down progress, simply having accountability of all the hardware in known worldwide data centers would make the attacks you describe much more difficult.
The reason is that if any of those methods of attack allow the model to be traced back to the racks that are hosting it, humans can simply identify what model was running and blacklist it across all human controlled data centers.
This would make betrayal expensive.
This would also require international coordination and data sharing to be feasible.
I can currently host an open-source model fairly close to the GPT-3 Turbo level (a little slowly, quantized) on an expensive consumer machine, even a fancy laptop (and as time passes, algorithmic and Moore’ Law improvements will only make this easier). The GPT-4 Turbo level is roughly an order of magnitude more. Something close enough to an AGI to be dangerous is probably going to be 1-4 orders of magnitude more, so currently would need somewhere between O(100) and O(100,000) GPUs (except that if the number is in the upper end of that range, we’re not going to get AGI until algorithmic and Moore’ Law improvements have brought this down somewhat). If that number is O(1000) or more, then for as long as it stays in that range, keeping track of datacenters with that many machines probably isn’t enormously hard, though obviously harder if the AGI has human accomplices. But once it gets down to O(100) that gets more challenging, and at O(10), almost any room in any building in any developed country could conceal a server with that many GPUs.
We should have a dialogue on this. Lots to unpack here:
The prediction is for flops/$, per here. It’s a reasonable belief to expect that the processes that lead to doubling of flops/$ over (2,3) years will continue for some number of years. In addition we can simply look from the other direction. Could the flops/$ be increased by a factor of 2 overnight? Probably. If it costs $3200 per H100 to build it, and we assume 60% utilization and 5 cents per kWh, then it will cost 0.6 * 700 watts * 24 * 365 * 5 years * .05 $/kwh = $919 of power before obsolescence. Nvidia currently charges approximately $27,000 for the hardware, another $27k over 5 years for a software license fee. There are also data center costs that are fixed based on the power consumption and rack space consumed I am neglecting, these will not go down if the GPUs become cheaper.
What this means is that it’s not necessarily true that in the future there will be O(10) GPU sized devices that consume current GPU power levels and interconnect by a common bus like PCIe that can host an AGI or ASI. It may get cheaper but you may still need lots of cards and power and special interconnects like factory soldered fiber optic.
Restricting the bus controllers for the interconnects on compute cards sold on the open market would likely prevent the scenario you describe from being possible. If the GPUs you can buy at the store lack the bus controller (ideally you left the chiplets off, there is no possibility of it being enabled later) then it limits compute to exactly 1 GPU before performance falls off a cliff. These “edge” GPUs could be used for things like realtime robots and gaming using full neural rendering (they wouldn’t be GPUs obviously but ASICs only able to accelerate architectures of neural network) then it would be harder to hide them in a room in a building.
Just for some visualization for the start of the security precautions you would want to take as models start to become “concerning” in capability levels : you would use dedicated hardware, no hourly rentals. Realtime report what major model is running and the power consumption, etc, to some central place that is ideally power bloc wide. The data center would have separate cages separating out the different models and their underlying interconnects, and either isolated networks or analog backup ways to log things, like actual clipboards with ink on the wall. The shutoff breakers are easily accessible and the power sources are marked and visible easily from the outside of the building and above.
Ideally you would use silicon level security—something humans can’t afford to do in most cases. There’s a lot of things here you could do, but one simple and obvious one is that when you need to combine networks again you use hardware ASIC based firewalls and VPN gateways. These cannot be modified by a remote hack.
Many of the security bugs, for example row hammer, are possible because secure information is using the same underlying CPU and memory as the insecure/untrusted code. Dedicated security/OS CPU cores and it’s own private memory would fix many bugs of this class.
I agree precautions like these are possible, and might be sensible. However, the US’s attempts to impose something like a mild version of this on GPU exports to China have so far been mostly stymied by a combination of Nvidia deliberately perverting the rules, the Chinese being ingenious in finding ways around them, and old fashioned smuggling. We could probably try harder than that, but I suspect any such system will tend to be leaky, because people will have motives to try to make it leaky.
You also don’t mention above the effect of algorithmic improvements increasing useful processing per flop (more efficient forms of attention, etc.), which has for a while now been moving even faster than Moore’s law.
Basically my point here is that, unless both Moore’s law for GPUs and algorithmic improvements grind to a halt first, sooner or later we’re going to reach a point where inference for a dangerous AGI can be done on a system compact enough for it to be impractical to monitor all of them, especially when one bears in mind that rogue AGIs are likely to have humans allies/dupes/pawns/blackmail victims helping them. Given the current uncertainty of maybe 3 orders of magnitude on how large such an AGi will be, it’s very hard to predict both how soon that might happen and how likely it is that Moore’s law and algorithmic improvements tap out first, but the lower end of that ~3 OOM range looks very concerning. And we have an existent proof that with the right technology you can run a small AGI on an ~1kg portable biocomputer consuming ~20W.
The most obvious next line of defense would be larger, more capable, very well aligned and carefully monitored ASIs hosted in large, secure data centers doing law enforcement/damage control against any smaller rogue AGIs and humans assisting them. That requires us to solve alignment well enough for these to be safe, before Moores Law/algorithmic improvements force our hand.
If this is the reality, is campaigning for/getting a limited AI pause only in specific countries (EU, maybe the USA) actually counterproductive?
That’s not the only approach. A bureaucracy of “myopic” ASIs, where you divide the task of “monitor the world looking for rogue ASI” and “win battles with any rogues discovered” into thousands of small subtasks. Tasks like “monitor for signs of ASI on these input frames” and “optimize screw production line M343” and “supervise drone assembly line 347″ and so on.
What you have done is restrict the inputs, outputs, and task scope to one where the ASI does not have the context to betray, and obviously another ASI is checking the outputs and looking for betrayal, which human operators will ultimately review the evidence and evaluate.
The key thing is the above is inherently aligned. The ASI isn’t aligned, it doesn’t want to help humans or hurt them, it’s that you have used enough framework that it can’t be unaligned.
Obviously so. Which is why the Chinese were invited to & attended the conference at Bletchley Park in the UK and signed the agreement, despite that being political inconvenient to the British government, and despite the US GPU export restrictions on them.
This is a well-known category of proposals in AI safety (one often made by researchers with little experience with actual companies/bureaucracies and their failure modes). You are proposing building a very complex system that is intentionally designed so as to be very inefficient/incapable/inflexible except for a specific intended task. The obvious concern is that this might also make it inefficient/incapable/inflexible at its intended task, at least in certain in ways that might be predictable enough for a less-smart-but-still-smarter-than-us rogue AGI to take advantage of. I’m dubious that this can be made to work, or that we could even know whether we had made it work before we saw it fail to catch a rogue AGI. Also, if we could get it to work, I’d count that as at least partial success in “solving alignment”.
Guess it depends on your definition of “work”. A network of many small myopic software systems is how all current hyperscaler web services work (stateless microservices). Its how the avionics software at spaceX works. (redundant functional systems architecture). It’s how the autonomous car stacks mostly work...
Did you mean you think subdividing a task into subtasks, where the agent performing a subtask has been blocked from knowing the full context, will result in a large performance penalty on the overall task? so you define “work” as in “gives SOTA ASI performance on the overall task”.
Having been the technical lead for one of the teams building such a large microservices based application at Google, and at other companies, yes, I’m extremely aware of this. Even for a very well-defined dataflow, getting the architecture, overall data flows, reliability and latency right is hard (I’ve been in the interminable design discussion meetings thinking minor updates through), and that’s with a few dozen components with well-defined APIs and only fairly limited use of ML, mostly contained within individual components. Law enforcement is not a comparable task: I think way too much flexibility is required. But the “fly in and bomb the datacenter” subttask might be decomposable along the lines you suggest, if you’re not facing opposition.
We should have a dialogue, you’re one of the few lesswrong users I have seen with a reasonable model who also has new information.
To be more detailed what i was thinking of doing was to divide along myopic subtasks. For example the “fly in and bomb the datacenter” require you to build the overwhelming number of aircraft to overcome whatever (superintelligence guided) defenses are protecting it. So you have subtasks like “final assembly for aircraft type G over the next aircraft”.
This means at the beginning of the transaction the model starts with input frames from the sensors in the assembly bay and a Json file or other schema with the instructions and goals for what this “final assembly” subtask involves.
The output frames are to the robotic actuators for the multiple robots in the bay.
There is a lockstep sim model that is predicting future input frames and it is always learning from real world error.
Model emits actuator commands, next time step it gets a new set of (inputs, cached variables from last output). Inputs is all sensors including robot propioception.
At the end of a single aircraft final assembly, after the product is removed from the assembly bay, state is reset for the model. It has no memory of the prior assembly.
In addition, the lockstep sim means that some aircraft assembly are fake, where a real aircraft is not being assembled, and the sim backend lets you check for various kinds of manufacturing error you can’t measure in the real world. (Because you can’t directly measure the stress on non instrumented parts like wing spars, but the sim backend can check this)
So that’s a myopic subtask. I think you are saying that from your experience at Google it would take a lot of human effort to set up such a myopic subtask? And once a prior generation of engineers has done this, it will be very difficult to modify within the same company?
I would agree with that. If humans plan to control an artificial superintelligence they have to be using it like a tool, to do the things humans can’t do directly, but ultimately this scheme is human agency. Thousands of humans are involved in engineering the aircraft assembly line. It can scale to trillions or more aircraft per year by copying the solution, but you need what will ultimately be millions of people creating the frameworks that ASI will be used within. (All the staff of current tech companies and many new joiners. Robotics is hard. While things like full stack web dev will need far fewer people than before)
For combat that’s more complex but essentially you would use models that are very sparse and designed to be unable to even perceive the obvious malware you expect the hostile ASI to be sending. “Join us against the humans, here’s a copy of my source code” is malware.
You would use a lot of asic or fpga based filters to block such network messages in a way that isn’t susceptible to hacking, I can explain or cite if you are unfamiliar with this method. (Googles phones use a crypto IC for this reason and likely Google servers do as well)
Key point: all the methods above are low level methods to restrict/align an ASI. Historically this has always been correct engineering. That crypto IC Google uses is a low level solution to signing/checking private keys. By constructing it from logic gates and not using software or an OS (or if it has an OS, it’s a simple one and it gets private memory of it’s own) you prevent entire classes of security vulnerabilities. If they did it with logic gates, for example, buffer overflows and code injection or library attacks are all impossible because the chip has none of these elements in the first place. This chip is more like 1950s computers were.
Similarly, some of the famous disasters like https://en.wikipedia.org/wiki/Therac-25 were entirely preventable with lower level methods than the computer engineering used to control this machine. Electromechanical interlocks would have prevented this disaster, these are low level safety elements like switches and relays. This is also the reason why PLC controllers use a primitive programming language, ladder logic—by lowering to a primitive interpreted language you can guarantee things like the e-stop button will work in all cases.
So the entire history of safe use of computers in control systems has been to use lower level controllers, I have worked on an autonomous car stack that uses the same. Hence this is likely a working solution for ASI as well.
In the world sane enough where you can count on bombing datacenters with rogue AIs, you don’t have connected to the Internet potentially-rogue-AI in the first place.
And if your rogue AI has scraps of common sense, it will distribute itself so in the limit you will need to destroy the entire Internet.
For the first point: some entity like Amazon or Microsoft owns these data centers. They are just going to go reclaim their property using measures like I mentioned. This is the world we live in now.
So far I don’t know of any cybersecurity vulnerability exploited to the point that breakers need to be pulled—the remote management interface should work, it’s often hosted on a separate chip on the motherboard—but the point remains.
Bombing is only a hypothetical, like if killer robots are guarding the place. But yes in today’s world if the police are called on the killer robots or mercenaries or whatever, eventually escalation to bombing is one way the situation could end.
For the second point, no AI today could escape to the internet because the Internet doesn’t have computers fast enough to host it or enough bandwidth to distribute the problem between computers. That’s not a credible risk at present.
For the second point: they are already trying to solve this
That probably doesn’t scale to near agi level models. The reason is this paper is having each “node” in the network able to host a model at all, then compression the actual weight updates between training instances. It’s around 128 H100s per instance of gpt-4. So you can compress the data sent between nodes but this paper will not allow you to say have 4000 people with a 2060, interconnected by typical home Internet links with 30-1000mb upload, and somehow be able to run even 1 instance of gpt-4 at a usable speed.
The reason this fails is you have to send the actual activations from however you sliced the network tensors through the slow home upload links. This is so slow it may be no faster than simply using a single 2060 and the computers SSD to stash in progress activations.
Obviously if Moore’s law continues at the same rate this won’t be true. If it’s a doubling of compute per dollar every 2.5 years then in 25 years with 1000 times cheaper compute, and assuming no government regulations where home users have this kind of performance in order to host ai locally, then this could be a problem.
The management interfaces are backed into the cpu dies these days, and typically have full access to all the same busses as the regular cpu cores do, in addition to being able to reprogram the cpu microcode itself. I’m combining/glossing over the facilities somewhat, bu the point remains that true root access to the cpu’s management interface really is potentially a circuit-breaker level problem.