Understanding the two-head strategy for teaching ML to answer questions honestly
This post is the result of my attempts to understand what’s going on in these two posts from summer 2021:
Paul Christiano: https://www.alignmentforum.org/posts/QqwZ7cwEA2cxFEAun/teaching-ml-to-answer-questions-honestly-instead-of
Evan Hubinger: https://www.alignmentforum.org/posts/gEw8ig38mCGjia7dj/answering-questions-honestly-instead-of-predicting-human
The underlying problem is similar in some ways to Eliciting Latent Knowledge, although not quite the same. According to Paul, understanding the two-headed algorithm (described in these posts) is likely to be fairly useful to people working on ELK. A similar algorithm is described in the ELK report, under Strategy: penalize reporters that work with many different predictors and in related appendices.
I initially found the algorithm pretty confusing, so I wrote this post for anyone else who’s confused by it.
I start with the basic strategy underlying Paul’s post, but in a simpler / more general setting without any ML. Then I add back in the ML context, followed by the specific context of the problem Paul and Evan discuss in their posts. (This is not quite the same as the ELK context.)
Along the way, I outline a simple application of this strategy: finding the second-simplest “meaningfully distinct” solution to a problem. I note that Paul’s application is sort of a special case of this.
Simple abstract version: conditioning on G(a, b)
Suppose we have a probability distribution over some discrete space A × B:
This is shown in the figure below—dots represent probability mass:
Suppose there’s some point (a+, b+) in A × B, and we want to obtain it by sampling from this distribution. Unfortunately, it’s not very high probability, so we probably won’t succeed:
Conditioning on D(·, ·)
An obvious strategy, if sampling is very cheap, is to sample repeatedly until we get (a+, b+).
Unfortunately, we don’t even know how to recognize it if we had it—there are other points that look very similar. Worse still, some of them are higher in probability.
Aside: rejection sampling might sound too expensive to be worth thinking about. We really care about it here as a proxy for processes like gradient descent, which are doing something that looks like “sample from a distribution conditional on a constraint”—the constraint being “loss is low” and the distribution being an architecture- and optimizer-dependent inductive prior. This is obviously not airtight, but I’m not going to get into the differences. For my purposes I’m just taking the rejection-sampling framework as given.
Formally, let’s say that we have a predicate D: A × B → {0, 1}, which is true for (a+, b+) and false for most other points. It’s also true for some other, unwanted points, with (a-, b-) being the highest-probability one:
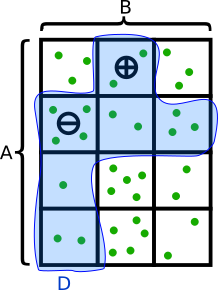
We still don’t know how to get (a+, b+), though—the best we can do is (a-, b-). We don’t know any easy-to-check predicate that is true for one and false for the other.
Conditioning on G(a, ·)
Let’s suppose that we do know of an easy-to-check predicate , such that
We can abbreviate the last part as
In other words:
G is true of both points under consideration
If you change b- randomly while keeping a-, G is fairly likely to still be true.
If you change b+ randomly while keeping a+, G is less likely to still be true.
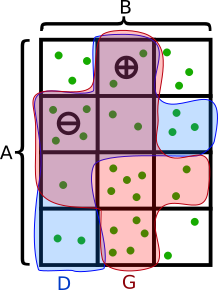
This is a somewhat nonintuitive property, but I’ll give a more motivated example of it in a more specific setting later. If you can think of nice simple toy models where a G like this exists, please let me know!
This predicate might seem unhelpful—G is less robustly true for the point we want—but it’s actually exactly what we need.
With such a G in hand, the basic idea is to use rejection sampling to throw out anything for which G=0, and redistribute its probability (under p) to other values with the same A part. This will leave anything of the form (a+, b) s.t. G(a+, b)=1 with a bunch of extra probability mass, but won’t help (a-, b) nearly as much.
In pseudocode:
Do repeatedly:
Sample a in A according to p(a)
Do repeatedly:
Sample b in B according to p(b | a)
If G(a, b)=1, return b; else keep looping
If D(a, b)=1, return (a, b); else keep looping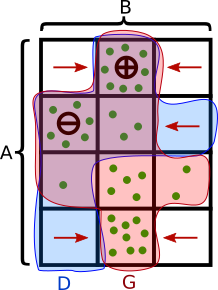
This figure shows the effect of this procedure. After redistributing from the G=0 set (shaded in red), the (+) point has higher probability than the (-) point, because it ate more of its neighbors.
The distribution pG that this produces is given by
We have two inequalities to worry about:
As long as the second inequality is stronger (the ratio of the sides is larger), we’ll have
We still have to worry about any other points (a’, b’) which get a large boost from conditioning on G in this way; it’s not obvious that (a-, b-) is still the “biggest competitor” to (a+, b+). In this toy example, that turns out not to matter, but in the ML applications below it’ll be important.
Another aside: This looks even less like normal ML training, and the analogous gradient-descent algorithm is less straightforward; you need to interleave steps of descent on two different losses. I haven’t thought much about how this would work in practice, but Paul points out that it’s somewhat similar to how GANs are trained. He will apparently have a post elaborating on this aspect soon; I’m going to continue to ignore it and stay in rejection-sampling land.
Special case: second-simplest-point algorithm
Here’s a use case for the procedure above:
Suppose we have some family of closely-related simplicity priors. These are defined on a space X, another space B, and various combinations of these such as X × B and (X × X) × B. In an abuse of notation, we’ll call all of these p.
I said p was a “simplicity prior”. What I mean by this is things like the following:
For all
These properties of p ought to be true for any notion of “simplicity”. The combination of two values is at least as complicated as either of them, and combining a value with itself is approximately as complicated as that value already is. We don’t need anything stronger than this at the moment.
We have some predicate , which checks that (x, b) is “correct” in some complicated way.
We also have a predicate , which checks that (x, b) is similar to (x’, b’) in some complicated way.
You can think of these as deriving from some large set of tests—D0 checks that the test outputs are all correct, and G0 just checks that they’re all the same for (x, b) and (x’, b’).
We want the second-simplest point that satisfies D0. We’re still pretty happy if we can get both the first- and second-simplest points satisfying D0, even if we don’t know which is which.
Let’s assume for simplicity (heh) that they have the same B-part:
The simplest such point is .
The second-simplest is .
(If they have different B-parts b- and b+, there is probably still a way to do this, but I haven’t tried to work out what it is.)
D0 is true for both of these, and G0 can’t tell them apart, because they both pass all the tests.
Let’s further assume that randomly changing b* to something else is very likely to break these properties. For the simplest values of b, (x-, b) and (x+, b) both fail our tests in different ways, so G0 can distinguish them:
Aside: We don’t really need to assume (x+, b*) is the second-simplest point, period. What I really mean is that x+ is the second-simplest “meaningfully distinct” point in X: everything simpler is indistinguishable from x- under G0 for almost all values of b.
We can’t just rejection-sample for D0 from p directly, or we’ll probably get (x-, b*).
Instead, let’s define and start working in the space .
Here’s how we can use G0 to implement the scheme described above:
We’re going to try to sample the two simplest X values at the same time:
Sampling from p directly would give us the simpler one twice:
We define D((x, x’), b) = (D0(x, b) or D0(x’, b)).
We define G((x, x’), b) = G0((x, b), (x’, b))
This G is trivial for a=a-, because the two things there are the same in all respects, no matter what b is, so
But for a=a+, G will fail for many different values of b, because x+ and x- behave differently except when combined with b*:
Now we have all the pieces and satisfy all the necessary conditions, so we can do the two-loop procedure described above in pseudocode to obtain (a+, b*).
This doesn’t quite get us (x+, b*) -- we don’t know which x is which—but we’re most of the way there.
Exercise for the reader: How do you generalize this to get the simplest “meaningfully distinct” X values, for ?
It would be interesting to do some small experiments on this in a standard ML setting like image recognition. What’s the second-simplest way to recognize a dog?
ML interpretation
All of this has been pretty abstract—let’s bring in all the baggage of machine learning:
A × B is the parameter space of some model, divided somehow into two factors A and B. The model has an extra boolean output in addition to whatever type signature it needs for the task at hand.
It’s possible that A needs to include the layers with the output heads, in the NN case, or some analogue of that in general. I’m confused about how to think about dividing A from B.
An alternative is to say that we have two models, which are both parametrized by A × B but in different ways. But I think this is equally underspecified.
p is the prior, probably a simplicity prior (e.g. the NN prior for some architecture and initialization.)
D is the training data (or more precisely the statement that loss is low on the training distribution).
Sampling from p, conditional on D=1, corresponds to some fitting or training procedure (e.g. SGD).
(a+, b+) and (a-, b-) are two possible trained models; (a+, b+) is better behaved in some way but is disfavored by the prior.
a+, in addition to other functionality, imposes the condition that the boolean output is only 1 if the B-part of the model satisfies some property G+ that is:
Cheap to specify (so that it doesn’t make the A parameters too expensive)
True for b+
False for nearly all other possible B values
a- doesn’t impose any condition like this, because there’s no G- that is comparably cheap and comparably specific to b-.
G is the statement that the boolean output from the model is 1 for any input on the training distribution.
The biggest difference between this and the more abstract setup is that a+ and a- get to implement their own conditions G+, G-, with the fixed externally-specified G just being a wrapper around these. I think this is actually unavoidable for sufficiently flexible ML models; the A-part of the model can always just return nonsense if its chosen condition isn’t satisfied, so long as that condition isn’t penalized much by the inductive prior. We aren’t assuming any ability to check things other than network outputs, so the G given above is pretty much fully general.
Alignment application: Intended and instrumental model
The use case Paul came up with this technique for is a special case of the ML version of this algorithm, with the following substitutions:
Task: answer natural-language questions
Training data: questions answered by humans
Simplifying assumption: questions answered *correctly* by humans
A: machinery to translate from a world model and a question to an answer (and an extra output bit)
a+: Answer is computed using the intended model; output bit is G+(b)
G+: the instrumental model agrees with the intended model on the input
a-: Answer is computed using the instrumental model; output bit is 1
Variants include things like: the output bit is 1 iff the world model is logically consistent
B: the world model (or at least the part of it that describes humans)
b- = b+ = correct world model
You can also put this in a- and leave b- empty, it doesn’t really matter
Why this works, and why it might not
Note that G+ is about as complicated as the instrumental model itself! Implementing a+ (including the description of G+) costs about as much complexity as the intended model plus the instrumental model, while a- only costs as much as the instrumental model.
On the other hand, p(G+ | a+) is very small—conditioning on it “pays back” the complexity of the simplest model of a human that knows how to use natural language, more or less. This is comparable to the complexity of the intended model (because it’s doing approximately the same thing), so in the end a+ only has to pay for the instrumental model—in other words .
As mentioned above, however, (a-, b-) is the simplest model that fits the data (highest-probability point conditional on D), not necessarily the most-likely model after conditioning on G. In particular, if there exists any cheap-to-specify G- such that p(G- | a-) is small, then we’ll end up with parameters that implement the instrumental model and G-. Evan analyzes several possibilities for this G-, such as “the world model is logically consistent”, and looks at whether there are defenses against these in the form of an even-pickier G+ that uses the same trick.
Two-answer-head version
Paul and Evan describe two ways to think about this:
The way I’ve written it above: you have a normal answer-output head and an extra boolean head.
The model has two answer heads, and G is the condition that both heads give the same answers on the training distribution.
The version with the boolean head is a bit better for thinking about possible problems, IMO, because it gives a more natural description of situations like “what if G- checks B for logical consistency”. This is because of the aforementioned thing where the A-part of the model gets to implement its own conditions on the B-part.
On the other hand, the two-answer-head version is possibly better for understanding the basic setup.
This two-answer-head version is very similar to the “second-simplest-point” algorithm above. G is defined as “the two output heads agree”, and this algorithm will therefore (hopefully) find a set of trained parameters where the output heads are meaningfully different. As above, “meaningfully different” means that they only agree conditional on something very specific happening in B, which in this case is the world model.
Two heads implementing the instrumental model will agree whether or not B is correct, because they’re both looking at the same thing (what the B-model of a human says). On the other hand, with one instrumental head and one intentional one, they’ll only agree if B is a good enough model of a human to predict human answers on the training data.
Thanks to Paul Christiano for discussion of the subject matter, and Beth Barnes and Evan Hubinger for feedback and discussion on this post.
Proposed toy examples for G:
G is “the door opens”, a- is “push door”, a+ is “some weird complicated doorknob with a lock”. Pretty much any b- can open a-, but only a very specific key+manipulator combo opens a+. a+ is much more informative about successful b than a- is.
G is “I make a million dollars”, a- is “straightforward boring investing”, a+ is “buy a lottery ticket”. A wide variety of different world-histories b can satisfy a-, as long as the markets are favorable—but a very narrow slice can satisfy a+. a+ is a more fragile strategy (relative to noise in b) than a- is.