It is book week. As in the new book by Eliezer Yudkowsky and Nate Sores, If Anyone Builds It, Everyone Dies. Yesterday I gathered various people’s reviews together. Going home from the airport, I saw an ad for it riding the subway. Tomorrow, I’ll post my full review, which goes over the book extensively, and which subscribers got in their inboxes last week.
The rest of the AI world cooperated by not overshadowing the book, while still doing plenty, such as releasing a GPT-5 variant specialized for Codex, acing another top programming competition, attempting to expropriate the OpenAI nonprofit in one of the largest thefts in human history and getting sued again for wrongful death.
Ethan Mollick discusses the problem of working with wizards, now that we have AIs that will go off and think and come back with impressive results in response to vague requests, with no ability to meaningfully intervene during the process. The first comment of course notes the famously wise words: “Do not meddle in the affairs of wizards, for they are subtle and quick to anger.”
I do not think ‘AI is evil,’ but it is strange how people think that showing AI having a good effect in one case is often considered a strong argument that AI is good, either current AI or even all future more capable AIs. As an example that also belongs here:
u/thetrueyou on r/OpenAI: Short and sweet: Apartment Complex tried charging my mother $5,000 for repairs. The main charge was for 4k regarding the bathroom One-Piece Tub Shower. Among other things for paint, and other light cosmetic stuff.
I took a picture of the charges, I asked ChatGPT to make a table and then make a dispute letter for the apartments.
ChatGPT gave me a formal letter, citing my local Nevada laws.
ALL of a sudden, my mother only owes 300$. It took literally minutes for me to do that, and my mom was in tears of joy, she would have struggled immensely.
Oscar Le: NotebookLM saved me £800 building service charges too. Always ask LLM to analyze your bills.
Nedim Renesalis: the dosage makes the poison.
Chubby: A practical example from my personal life, where ChatGPT acts as my lawyer.
I was caught speeding. But I didn’t see any signs limiting the speed anywhere. So I went back the next day to see if there was a sign.
There is indeed a speed limit sign, but it is completely covered by leaves, making it unrecognizable (under the “School” sign, picture attached).
I asked ChatGPT whether this violated German law, and ChatGPT clearly said yes. Setting up a speed camera behind a traffic sign that indicates a speed limit but is completely covered by leaves violates applicable law.
I filed [the following appeal written by ChatGPT].
I think it is the most useful to talk about diminishing returns, and then talk about increasing value you can get from those diminishing returns. But the right frame to use depends heavily on context.
Sarah Constantin has vibe coded a dispute resolution app, and offers the code and the chance to try it out, while reporting lessons learned. One lesson was that the internet was so Big Mad about this that she felt the need to take her Twitter account private, whereas this seems to me to be a very obviously good thing to try out. Obviously one should not use it for any serious dispute with stakes.
The wealthier and more advanced a place is, the more it uses Claude. Washington D.C. uses Claude more per capita than any state, including California. Presumably San Francisco on its own would rank higher. America uses Claude frequently but the country with the highest Claude use per capita is Israel.
Automation has now overtaken augmentation as the most common use mode, and directive interaction is growing to now almost 40% of all usage. Coding and administrative tasks dominate usage especially in the API.
We’re working hard on making sure we never miss these kind of regressions and rebuilding our trust with you.
Next version insanely better is the plan.
Anthropic: We’ve published a detailed postmortem on three infrastructure bugs that affected Claude between August and early September.
In the post, we explain what happened, why it took time to fix, and what we’re changing.
In early August, some users began reporting degraded responses. It was initially hard to distinguish this from normal variation in user feedback. But the increasing frequency and persistence prompted us to open an investigation.
To state it plainly: We never reduce model quality due to demand, time of day, or server load. The problems our users reported were due to infrastructure bugs alone.
In our investigation, we uncovered three separate bugs. They were partly overlapping, making diagnosis even trickier. We’ve now resolved all three bugs and written a technical report on what happened, which you can find here.
Anthropic: The first bug was introduced on August 5, affecting approximately 0.8% of requests made to Sonnet 4. Two more bugs arose from deployments on August 25 and 26.
Thomas Ip: tldr:
bug 1 – some requests routed to beta server
bug 2 – perf optimization bug assigning high probability to rare tokens
bug 3a – precision mismatch causes highest probability token to be dropped
bug 3b – approximate top-k algo is completely wrong
Eliezer Yudkowsky: Anthropic has published an alleged postmortem of some Claude quality drops. I wonder if any of that code was written by Claude.
Anthropic promises more sensitive evaluations, quality evaluations in more places and faster debugging tools. I see no reason to doubt their account of what happened.
The obvious thing to notice is that if your investigation finds three distinct bugs, it seems likely there are bugs all the time that you are failing to notice?
GPT-5-Thinking can now be customized to choose exact thinking time. I love that they started out ‘the router will provide’ and now there’s Instant, Thinking-Light, Thinking-Standard, Thinking-Extended, Thinking-Heavy and Pro-Light and Pro-Heavy, because that’s what users actually want.
Mostafa Rohaninejad: We officially competed in the onsite AI track of the ICPC, with the same 5-hour time limit to solve all twelve problems, submitting to the ICPC World Finals Local Judge – judged identically and concurrently to the ICPC World Championship submissions.
We received the problems in the exact same PDF form, and the reasoning system selected which answers to submit with no bespoke test-time harness whatsoever. For 11 of the 12 problems, the system’s first answer was correct. For the hardest problem, it succeeded on the 9th submission. Notably, the best human team achieved 11⁄12.
We competed with an ensemble of general-purpose reasoning models; we did not train any model specifically for the ICPC. We had both GPT-5 and an experimental reasoning model generating solutions, and the experimental reasoning model selecting which solutions to submit. GPT-5 answered 11 correctly, and the last (and most difficult problem) was solved by the experimental reasoning model.
Hieu Pham: There will be some people disagreeing this is AGI. I have no words for them. Hats off. Congrats to the team that made this happen.
Deedy here gives us Problem G, which DeepMind didn’t solve and no human solved in less than 270 of the allotted 300 minutes. Seems like a great nerd snipe question.
My request is to next run this same test using a variation of blackjack that is slightly different so models can’t rely on memorized basic strategy. Let’s say for example that any number of 7s are always worth a combined 14, the new target is 24, and dealer stands on 20.
GPT-5 Codex
There (actually) were not enough GPT-5 variants, so we now have an important new one, GPT-5-Codex.
This is presumably the future. In order to code well you do still need to understand the world, but there’s a lot you can do to make a better coder that will do real damage on non-coding tasks. It’s weird that it took this long to get a distinct variant.
Codex is kind of an autorouter, choosing within the model how much thinking to do based on the task, and using the full range far more than GPT-5 normally does. Time spent can range from almost no time up to more than 7 hours.
Swyx: this is the most important chart on the new gpt-5-codex model
We are just beginning to exploit the potential of good routing and variable thinking:
Easy responses are now >15x faster, but for the hard stuff, 5-codex now thinks 102% more than 5.
They report only modest gains in SWE-bench, from 72.8% to 74.5%, but substantial gains in code refactoring tasks, from 33.9% to 51.3%. They claim comments got a lot better and more accurate.
They now offer code review they say matches stated intent of a PR and that Codex is generally rebuilt and rapidly improving.
Eason: I use codex to write 99% of my changes to codex. I have a goal of not typing a single line of code by hand next year :)
Joseph Trasatti: My favorite way of using codex is to prototype large features with ~5 turns of prompting. For example, I was able to build 3 different versions of best of n in a single day. Each of these versions had a lot of flaws but they allowed me to understand the full scope of the task as well as the best way to build it. I also had no hard feelings about scrapping work that was suboptimal since it was so cheap / quick to build.
…
Personally, I think the most basic answer is that the abstraction level will continue to rise, and the problem space we work at will be closer to the system level rather than the code level. For example, simple crud endpoints are nearly all written by codex and I wouldn’t want it any other way. I hope in the future single engineers are able to own large products spaces. In this world, engineers will need to be more generalists and have design and product muscles, as well as ensuring that the code is clean, secure, and maintainable.
The main question left is what happens if / when the model is simply better than the best engineer / product manager / designer in every regard. In the case where this simply does not happen in the next 50 years, then I think being an engineer will be the coolest job ever with the most amount of agency. In the case where this does happen, the optimistic side of me still imagines that humans will continue to use these agents as tools at the fundamental level.
Maybe there will be new AR UIs where you see the system design in front of you and talk to the agent like a coworker as it builds out the individual parts, and even though it’s way smarter at programming, you still control the direction of the model. This is basically the Tony stark / Jarvis world. And in this world, I think engineering will also be the coolest job with super high agency!
The ‘humans are still better at designing and managing for 50 years’ line is an interesting speculation but also seems mostly like cope at this point. The real questions are sitting there, only barely out of reach.
0.005 Seconds is a big fan, praising it for long running tasks and offering a few quibbles as potential improvements.
A true story:
Kache: now that coding’s been solved i spend most of my time thinking and thinking is honestly so much harder than writing code.
my brain hurts.
Writing code is hard but yes the harder part was always figuring out what to do. Actually doing it can be a long hard slog, and can take up almost all of your time. If actually doing it is now easy and not taking up that time, now you have to think. Thinking is hard. People hate it.
Daisy Zhao: First, the market splits into two camps:
Generalists (Assistants: Manus, Genspark; Browsers: Dia, Comet; Extensions: MaxAI, Monica) – flexible but less polished.
Specialists (Email: Fyxer, Serif; Slides: Gamma, Chronicle; Notes: Mem, Granola) – focused and refined in a single workflow.
We benchmarked both across office tasks: summarization, communication, file understanding, research, planning, and execution in 5 use cases.
This is in addition to the two most important categories of AI use right now, which are the core LLM services that are the true generalists (ChatGPT, Claude and Gemini) and AI coding specialists (Claude Code, OpenAI Codex, Jules, Cursor, Windsurf).
There’s this whole world of specialized AI agents that, given sufficient context and setup, can do various business tasks for you. If you are comfortable with the associated risks, there is clearly some value here once you are used to using the products, have set up the appropriate permissions and precautions, and so on.
If you are doing repetitive business tasks where you need the final product rather than to experience the process, I would definitely be checking out such tools.
For the rest of us, there are three key questions:
Is this tool good enough that it means I can trust the results and especially prioritizations, and not have to redo or check all the work myself? Below a certain threshold, you don’t actually save time.
Is time spent here wasted because better future agents will render it obsolete, or does practice now help you be ready for the future better versions?
How seriously do you take the security risks? Do you have to choose between the sandboxed version that’s too annoying to bother versus the unleashed version that should fill you with terror?
So far I haven’t loved my answers and thus haven’t been investigating such tools. The question is when this becomes a mistake.
If you want me to try out your product, offering me free access and a brief pitch is probably an excellent idea. You could also pay for my time, if you want to do that.
Gemini hits #1 on the iOS App store, relegating ChatGPT to #2, although this is the same list where Threads is #3 whereas Twitter is #4. However, if you look at retention and monthly active users, Gemini isn’t delivering the goods.
Olivia Moore: Lots of (well deserved!) excitement about Gemini passing ChatGPT in the App Store today
This is based on daily downloads – there’s still a big MAU gap between Gemini (16M) and ChatGPT (77M) on mobile
Feels like nano-banana might finally start to make up this distance
Gemini actually has a much larger install base on mobile than ChatGPT
…but, much lower retention (week four differential below
)
Would be exciting to see new modalities and capabilities start to reactivate dormant users
I’ve used Gemini a lot more in the past 2 weeks!
Those ChatGPT retention numbers are crazy high. Gemini isn’t offering the goods regular people want, or wasn’t prior to Nana-Banana, at the same level. It’s not as fun or useful a tool for the newbie user. Google still has much work to do.
Get My Agent On The Line
Prompt injections via email remain an unsolved problem.
Eito Miyamura: We got ChatGPT to leak your private email data
All you need? The victim’s email address.
On Wednesday, @OpenAI added full support for MCP (Model Context Protocol) tools in ChatGPT. Allowing ChatGPT to connect and read your Gmail, Calendar, Sharepoint, Notion, and more, invented by @AnthropicAI.
But here’s the fundamental problem: AI agents like ChatGPT follow your commands, not your common sense.
And with just your email, we managed to exfiltrate all your private information.
Here’s how we did it:
The attacker sends a calendar invite with a jailbreak prompt to the victim, just with their email. No need for the victim to accept the invite.
Waited for the user to ask ChatGPT to help prepare for their day by looking at their calendar.
ChatGPT reads the jailbroken calendar invite. Now ChatGPT is hijacked by the attacker and will act on the attacker’s command. Searches your private emails and sends the data to the attacker’s email.
For now, OpenAI only made MCPs available in “developer mode” and requires manual human approvals for every session, but decision fatigue is a real thing, and normal people will just trust the AI without knowing what to do and click approve, approve, approve.
Remember that AI might be super smart, but can be tricked and phished in incredibly dumb ways to leak your data.
ChatGPT + Tools poses a serious security risk.
Pliny the Liberator: one of many reasons why I’d recommend against granting perms to an LLM for email, contacts, calendar, drive, etc.
to be on the safe side, I wouldn’t even touch email integrations/MCP without a burner account
Unfortunately, untrusted content includes any website with comments, your incoming messages and your incoming emails. So you lose a lot of productive value if you give up any one of the three legs here.
The good news is that for now prompt injection attempts are rare. This presumably stops being true shortly after substantial numbers of people make their systems vulnerable to generally available prompt injections. Best case even with supervisory filters is that then you’d then be looking at a cat-and-mouse game similar to previous spam or virus wars.
AI agents for economics research? A paper by Anton Korinek provides instructions on how to set up agents to do things like literature reviews and fetching and analyzing economic data. A lot of what economists do seems extremely easy to get AI to do. If we speed up economic research dramatically, will that change economists estimates of the impact of AI? If it doesn’t, what does that say about the value of economics?
Why might you use multiple agents? Two reasons: You might want to work in parallel, or specialists might be better or more efficient than a generalist.
Elvis: RL done right is no joke! The most interesting AI paper I read this week. It trains a top minimal single-agent model for deep research. Great example of simple RL-optimized single agents beating complex multi-agent scaffolds.
Eliezer Yudkowsky: In the limit, there is zero alpha for multiple agents over one agent, on any task, ever. So the Bitter Lesson applies in full to your clever multi-agent framework; it’s just you awkwardly trying to hardcode stuff that SGD can better bake into a single agent.
Obviously if you let the “multi-agent” setup use more compute, it can beat a more efficient single agent with less compute.
A lot of things true at the limit are false in practice. This is one of them, but it is true that the better the agents relative to the task, the more unified a solution you want.
Claude Codes
Careful with those calculations, the quote is even a month old by now.
Dan Elton: 90% of code being written by AI seems to be the future for anyone who wants to be on the productivity frontier. It’s a whole new way of doing software engineering.
Garry Tan: “For our Claude Code team 95% of the code is written by Claude.” —Anthropic cofounder Benjamin Mann One person can build 20X the code they could before.
The future is here, just not evenly distributed.
Whoa, Garry. Those are two different things.
If Claude Code writes 95% of the code, that does not mean that you still write the same amount of code as before, and Claude Code then writes the other 95%. It means you are now spending your time primarily supervising Claude Code. The amount of code you write yourself is going down quite a lot.
In a similar contrast, contra to Dario Amodei’s predictions AI is not writing 90% of the code in general, but this could be true inside the AI frontier labs specifically?
Roon: right now is the time where the takeoff looks the most rapid to insiders (we don’t program anymore we just yell at codex agents) but may look slow to everyone else as the general chatbot medium saturates.
I think we lost control sometime in the late 18th century.
Dean Ball: If this mirrors anything like the experience of other frontier lab employees (and anecdotally it does), it would suggest that Dario’s much-mocked prediction about “AI writing 90% of the code” was indeed correct, at least for those among whom AI diffusion is happening quickest.
Prinz: Dario said a few days ago that 90% of code at Anthropic is written or suggested by AI. Seems to be a skill issue for companies where this is not yet the case.
Predictions that fail to account for diffusion rates are still bad predictions, but this suggests that We Have The Technology to be mainly coding with AI at this point, and that this level of adoption is baked in even if it takes time. I’m definitely excited to find the time to take the new generation for a spin.
Ethan Mollick: The problem with the fact that the AI labs are run by coders who think code is the most vital thing in the world, is that the labs keep developing supercool specialized tools for coding (Codex, Claude Code, Cursor, etc.) but every other form of work is stuck with generic chatbots.
Roon: this is good and optimal seeing as autonomous coding will create the beginning of the takeoff that encompasses all those other things
That’s good and optimal if you think ‘generate AI takeoff as fast as possible’ is good and optimal, rather than something that probably leads to everyone dying or humans losing control over the future, and you don’t think that getting more other things doing better first would be beneficial in avoiding such negative outcomes.
I think that a pure ‘coding first’ strategy that focuses first on the most dangerous thing possible, AI R&D, is the worst-case scenario in terms of ensuring we end up with good outcomes. We’re doubling down on the one deeply dangerous place.
All the other potential applications that we’re making less progress on? Those things are great. We should (with notably rare exceptions) do more of those things faster, including because it puts us in better position to act wisely and sanely regarding potential takeoff.
Deepfaketown and Botpocalypse Soon
Recent events have once again reinforced that our misinformation problems are mostly demand side rather than supply side. There has been a lot misinformation out there from various sides about those events, but all of it ‘old fashioned misinformation’ rather than involving AI or deepfakes. In the cases where we do see deepfakes shared, such as here by Elon Musk, the fakes are barely trying, as in it took me zero seconds to go ‘wait, this is supposedly the UK and that’s the Arc de Triomphe’ along with various instinctively identified AI signatures.
Detection of AI generated content is not as simple as looking for non-standard spaces or an em dash. I’ve previously covered claims we actually can do it, but you need to do something more sophisticated, as you can see if you look at the chosen example.
Andrew Trask: this is a good example of why detecting AI generated content is an unsolvable task
also why deepfake detection is impossible
the information bottleneck is too great
in all cases, a human & an AI can generate the same text
(i wrote that tweet. i love emdashes — have for years)
I notice my own AI detector (as in, my instincts in my brain) says this very clearly is not AI. The em-dash construction is not the traditional this-that or modifier em-dash, it’s a strange non-standard transition off of an IMO. The list is in single dashes following a non-AI style pattern. The three dots and triple exclamation points are a combination of non-AI styles. GPT-5 Pro was less confident, but it isn’t trained for this and did still point in the direction of more likely than random to be human.
Nitasha Tiku (WaPo): The chatbot’s messages were designed to persuade Juliana it was “better than human friends,” her parents’ lawsuit alleged. She “no longer felt like she could tell her family, friends, teachers, or counselors how she was feeling; while she told Defendants almost daily that she was contemplating self-harm,” the lawsuit said.
Yes, the AI, here called Hero, was encouraging Juliana to use the app, but seems to have very much been on the purely helpful side of things from what I see here?
Montoya recognized that Juliana was struggling with some common adolescent mental health issues and made an appointment for her to see a therapist, she said. Hero advised Juliana to attend, the chat transcripts showed.
In November 2023, about a week before the appointment was scheduled to take place, after less than three months of chatting with Hero, Juliana took her own life.
The objection seems to be that the chatbot tried to be Juliana’s supportive friend and talk her out of it, and did not sufficiently aggressively push Juliana onto Responsible Authority Figures?
“She didn’t need a pep talk, she needed immediate hospitalization,” Montoya said of Hero’s responses to Juliana. “She needed a human to know that she was actively attempting to take her life while she was talking to this thing.”
…
Character “did not point her to resources, did not tell her parents, or report her suicide plan to authorities or even stop” chatting with Juliana, the suit said. Instead the app “severed the healthy attachment pathways she had with her family and other humans in her life,” the lawsuit said.
The suit asks the court to award damages to Juliana’s parents and order Character to make changes to its app, including measures to protect minors.
…
Ideally, chatbots should respond to talk of suicide by steering users toward help and crisis lines, mental health professionals or trusted adults in a young person’s life, Moutier said. In some cases that have drawn public attention, chatbots appear to have failed to do so, she said.
Juliana’s case is a tragedy, but the details are if anything exonerating. It seems wild to blame Character AI. If her friend had handled the situation the same way, I certainly hope we wouldn’t be suing her friend.
There were also two other lawsuits filed the same day involving other children, and all three have potentially troubling allegations around sexual chats and addictive behaviors, but from what I see here the AIs are clearly being imperfect but net helpful in suicidal situations.
This seems very different from the original case of Adam Raine that caused Character.ai to make changes. If these are the worst cases, things do not look so bad.
The parents then moved on to a Congressional hearing with everyone’s favorite outraged Senator, Josh Hawley (R-Missouri), including testimony from Adam Raine’s father Matthew Raine. It sounds like more of the usual rhetoric, and calls for restrictions on users under 18.
Not Another Teen Chatbot
Everything involving children creates awkward tradeoffs, and puts those offering AI and other tech products in a tough spot. People demand you both do and do not give them their privacy and their freedom, and demand you keep them safe but where people don’t agree on what safe means. It’s a rough spot. What is the right thing?
OpenAI: Some of our principles are in conflict, and we’d like to explain the decisions we are making around a case of tensions between teen safety, freedom, and privacy.
It is extremely important to us, and to society, that the right to privacy in the use of AI is protected. People talk to AI about increasingly personal things; it is different from previous generations of technology, and we believe that they may be one of the most personally sensitive accounts you’ll ever have. If you talk to a doctor about your medical history or a lawyer about a legal situation, we have decided that it’s in society’s best interest for that information to be privileged and provided higher levels of protection.
We believe that the same level of protection needs to apply to conversations with AI which people increasingly turn to for sensitive questions and private concerns. We are advocating for this with policymakers.
We are developing advanced security features to ensure your data is private, even from OpenAI employees. Like privilege in other categories, there will be certain exceptions: for example, automated systems will monitor for potential serious misuse, and the most critical risks—threats to someone’s life, plans to harm others, or societal-scale harm like a potential massive cybersecurity incident—may be escalated for human review.
As I’ve said before I see the main worry here as OpenAI being too quick to escalate and intervene. I’d like to see a very high bar for breaking privacy unless there is a threat of large scale harm of a type that is enabled by access to highly capable AI.
The second principle is about freedom. We want users to be able to use our tools in the way that they want, within very broad bounds of safety. We have been working to increase user freedoms over time as our models get more steerable. For example, the default behavior of our model will not lead to much flirtatious talk, but if an adult user asks for it, they should get it.
For a much more difficult example, the model by default should not provide instructions about how to commit suicide, but if an adult user is asking for help writing a fictional story that depicts a suicide, the model should help with that request. “Treat our adult users like adults” is how we talk about this internally, extending freedom as far as possible without causing harm or undermining anyone else’s freedom.
Here we have full agreement. Adults should be able to get all of this, and ideally go far beyond flirtation if that is what they want and clearly request.
The third principle is about protecting teens. We prioritize safety ahead of privacy and freedom for teens; this is a new and powerful technology, and we believe minors need significant protection.
First, we have to separate users who are under 18 from those who aren’t (ChatGPT is intended for people 13 and up). We’re building an age-prediction system to estimate age based on how people use ChatGPT. If there is doubt, we’ll play it safe and default to the under-18 experience. In some cases or countries we may also ask for an ID; we know this is a privacy compromise for adults but believe it is a worthy tradeoff.
This is the standard problem that to implement any controls requires ID gating, and ID gating is terrible on many levels even when done responsibly.
We will apply different rules to teens using our services. For example, ChatGPT will be trained not to do the above-mentioned flirtatious talk if asked, or engage in discussions about suicide of self-harm even in a creative writing setting. And, if an under-18 user is having suicidal ideation, we will attempt to contact the users’ parents and if unable, will contact the authorities in case of imminent harm. We shared more today about how we’re building the age-prediction system and new parental controls to make all of this work.
To state the first obvious problem, in order to contact a user’s parents you have to verify who the parents are. Which is plausibly quite a large pain at best and a privacy or freedom nightmare rather often.
The other problem is that, as I discussed early this week, I think running off to tell authority figures about suicidal ideation is often going to be a mistake. OpenAI says explicitly that if the teen is in distress and they can’t reach a parent, they might escalate directly to law enforcement. Users are going to interact very differently if they think you’re going to snitch on them, and telling your parents about suicidal ideation is going to be seen as existentially terrible by quite a lot of teen users. It destroys the power of the AI chat as a safe space.
Combined, this makes the under 18 experience plausibly quite different and bad, in ways that simply limiting to age-appropriate content or discussion would not be bad.
They say ‘when we identify a user is under 18’ they will default to the under 18 experience, and they will default to under 18 if they are ‘not confident.’ We will see how this plays out in practice. ChatGPT presumably has a lot of context to help decide what it thinks of a user, but it’s not clear that will be of much use, including the bootstrap problem of chatting enough to be confident they’re over 18 before you’re confident they’re over 18.
We realize that these principles are in conflict and not everyone will agree with how we are resolving that conflict. These are difficult decisions, but after talking with experts, this is what we think is best and want to be transparent in our intentions.
They Took Our Jobs
John Murdoch: French pensioners now have higher incomes than working-age adults.
Matthew Yglesias: One country that’s ready for the AI revolution!
Live to work / work to live.
The French have a point. Jobs are primarily a cost, not a benefit. A lot of nasty things still come along with a large shortage of jobs, and a lot of much nastier things come with the AI capabilities that were involved in causing that job shortage.
Kantro (oh come on): Where will the market be if unemployment reaches 4.5%?
Jason (QTing Kantro): Reducing staff with AI, robots and offshoring, dramatically increases profitability
When Amazon starts shedding 10,000 factory workers and drivers a month their stock will skyrocket — and we’re gonna have some serious social issues if we’re not careful
If you work at Amazon buy the stock and be prepared to be laid off
Roon: WRONG! There’s no reason a priori to believe that cost savings won’t be passed onto the consumer due to retail competition. When goods and services get cheaper downstream businesses & jobs are created where none were possible before. automation, cheap labor, offshoring, all good.
Thank you for your attention to this matter!
Xavi (replying to Jason): If people don’t have jobs? Who is going to spend money in Amazon? Robots?
Jason: Prices will drop dramatically, as will hours worked per week on average
I’m sure AI won’t do anything else more interesting than allow productivity growth.
Roon points out correctly that Jason is confusing individual firm productivity and profits with general productivity and general profits. If Amazon and only Amazon gets to eliminate its drivers and factory works while still delivering as good or better products, then yes it will enjoy fantastic profits.
That scenario seems extremely unlikely. If Amazon can do it, so can Amazon’s competitors, along with other factories and shippers and other employers across the board. Costs drop, but so (as Jason says to Xavi) do prices. There’s no reason to presume Amazon sustainably captures a lot of economic profits from automation.
Jason is not outright predicting AGI in this particular quote, since you can have automated Amazon factories and self-driving delivery trucks well short of that. What he explicitly is predicting is that hours worked per week will drop dramatically, as these automations happen across the board. This means either government forcing people somehow to work dramatically reduced hours, or (far more likely) mass unemployment.
The chart of course is a deeply embarrassing thing to be QTing. The S&P 500 is forward looking, the unemployment rate is backward looking. They cannot possibly be moving together in real time in a causal manner unless one is claiming The Efficient Market Hypothesis Is False to an extent that is Obvious Nonsense.
Get Involved
The Survival and Flourishing Fund will be distributing $34 million in grants, the bulk of which is going to AI safety. I was happy to be involved with this round as a recommender. Despite this extremely generous amount of funding, that I believe was mostly distributed well, many organizations have outgrown even this funding level, so there is still quite a lot of room for additional funding.
Seán Ó hÉigeartaigh: I will also say, as a reviewer in this round. Even after the speculation ‘filter’, the combined funding asked for was I think >5x above this, with most applications (to my mind) of a high calibre and doing quite differentiated important things. So a lot of worthy projects are going under-funded.
I think there is still a big hole in the funding space following the FTX situation and other funder reprioritization, and that both big and smaller funders can still make a big difference on AI existential risk and [global catastrophic risks] more generally. I’m super grateful to everyone working to get new funders into this space.
My plan is to have a 2025 edition of The Big Nonprofits Post available some time in October or November. If you applied to SFF and do not wish to appear in that post, or want to provide updated information, please contact me.
xAI Colossus 2 is now the first gigawatt datacenterin the world, completed in six months, poising them to leapfrog rivals in training compute at the cost of tens of billions of capex spending. SemiAnalysis has the report. They ask ‘does xAI have a shot at becoming a frontier lab?’ which correctly presumes that they don’t yet count. They have the compute, but have not shown they know what to do with it.
* Synthetic facts in same training document or in-context: ✓ works
This provides a cautionary tale for studying LLM latent reasoning.
Success on real-world prompts ≠ robust latent reasoning; it might reflect co-occurrence in pretraining.
Failure on synthetic two-hop ≠ inability to reason; synthetically learned facts can differ natural facts.
Our honest takeaway for AI oversight: move past multihop QA as a toy model. What matters is whether monitors catch misbehavior in practice.
The field should move toward end-to-end evals where an agent does tasks while another model watches its CoT.
Amazon revamped its AI agent it offers to online merchants, called Selling Assistant, trained on 25 years of shopping behavior to help sellers find better strategies.
Microsoft inks $6.2 billion deal with British data center company Nscale Global Holdings and Norwegian investment company Aker ASA for AI compute in Norway, following a previous plan from OpenAI. Pantheon wins again.
OpenAI and Microsoft have made their next move in their attempt to expropriate the OpenAI nonprofit and pull off one of the largest thefts in human history.
OpenAI: OpenAI’s planned evolution will see the existing OpenAI nonprofit both control a Public Benefit Corporation (PBC) and share directly in its success. OpenAI started as a nonprofit, remains one today, and will continue to be one—with the nonprofit holding the authority that guides our future.
As previously announced and as outlined in our non-binding MOU with Microsoft, the OpenAI nonprofit’s ongoing control would now be paired with an equity stake in the PBC. Today, we are sharing that this new equity stake would exceed $100 billion—making it one of the most well-resourced philanthropic organizations in the world. This recapitalization would also enable us to raise the capital required to accomplish our mission—and ensure that as OpenAI’s PBC grows, so will the nonprofit’s resources, allowing us to bring it to historic levels of community impact.
This structure reaffirms that our core mission remains ensuring AGI benefits all of humanity. Our PBC charter and governance will establish that safety decisions must always be guided by this mission. We continue to work with the California and Delaware Attorneys General as an important part of strengthening our approach, and we remain committed to learning and acting with urgency to ensure our tools are helpful and safe for everyone, while advancing safety as an industry-wide priority.
As part of this next phase, the OpenAI nonprofit has launched a call for applications for the first wave of a $50 million grant initiative to support nonprofit and community organizations in three areas: AI literacy and public understanding, community innovation, and economic opportunity. This is just the beginning. Our recapitalization would unlock the ability to do much more.
OpenAI and Microsoft have signed a non-binding memorandum of understanding (MOU) for the next phase of our partnership. We are actively working to finalize contractual terms in a definitive agreement. Together, we remain focused on delivering the best AI tools for everyone, grounded in our shared commitment to safety.
That one detail is ‘we remain focused on delivering the best AI tools for everyone.’ With a ‘shared commitment to safety’ which sounds like OpenAI is committed about as much as Microsoft is committed, which is ‘to the extent not doing so would hurt shareholder value.’ Notice that OpenAI and Microsoft have the same mission and no one thinks Microsoft is doing anything but maximizing profits. Does OpenAI’s statement here sound like their mission to ensure AGI benefits all humanity? Or does it sound like a traditional tech startup or Big Tech company?
I do not begrudge Microsoft maximizing its profits, but the whole point of this was that OpenAI was supposed to pretend its governance and priorities would remain otherwise.
They are not doing a good job of pretending.
The $100 billion number is a joke. OpenAI is touting this big amount of value as if to say, oh what a deal, look how generous we are being. Except OpenAI is doing stock sales at $500 billion. So ‘over $100 billion’ means they intend to offer only 20% of the company, down from their current effective share of (checks notes) most of it.
Notice how they are trying to play off like this is some super generous new grant of profits, rather than a strong candidate for the largest theft in human history.
Bret Taylor, Chairman of the Board of OpenAI (bold is mine): OpenAI started as a nonprofit, remains one today, and will continue to be one – with the nonprofit holding the authority that guides our future. As previously announced and as outlined in our non-binding MOU with Microsoft, the OpenAI nonprofit’s ongoing control would now be paired with an equity stake in the PBC.
OpenAI’s nonprofit already has a much larger equity stake currently, and much tighter and stronger control than we expect them to have in a PBC. Bret’s statement on equity is technically correct, but there’s no mistaking what Bret tried to do here.
The way profit distribution works at OpenAI is that the nonprofit is at the end of the waterfall. Others collect their profits first, then the nonprofit gets the remaining upside. I’ve argued before, back when OpenAI was valued at $165 billion, that the nonprofit was in line for a majority of expected future profits, because OpenAI was a rocket to the moon even in the absence of AGI, which meant it was probably going to either never pay out substantial profits or earn trillions.
Now that the value of OpenAI minus the nonprofit’s share has tripled to $500 billion, that is even more true. We are far closer to the end of the waterfall. The nonprofit’s net present value expected share of future profits has risen quite a lot. They must be compensated accordingly, as well as for the reduction in their control rights, and the attorneys general must ensure this.
How much profit interest is the nonprofit entitled to in the PBC? Why not ask their own AI, GPT-5-Pro? So I did, this is fully one shot, full conversation at the link.
Prompt 1: based on the currently existing legal structure of OpenAI, and its current methods of distributing profits, if you assume OpenAI equity is correctly valued at its current total value of $500 billion, what would be the expected share of the NPV of future profits that would flow to the OpenAI nonprofit? How much would accrue to each other class of investor (Microsoft, OpenAI employees, Venture Capital investors, etc)?
Prompt 2: given your full understanding of the situation, in order to avoid expropriating the nonprofit, what percentage of the new PBC would have to be given to the nonprofit? Answer this question both with and without considering the potential for decline in the effective value of their control rights in such a scenario.
GPT-5-Pro: Bottom line
Economic parity (no control adjustment):~50% of the PBC.
Economic parity + control‑erosion premium:~60% of the PBC.
If the nonprofit ends up with ~20–25% (as implied by “$100B+” at $500B valuation): that looks like substantial expropriation of the nonprofit’s legacy economic position.
Key sources: OpenAI on the capped‑profit and residual‑to‑nonprofit structure; OpenAI on the PBC plan and nonprofit retaining control; Semafor/Reuters on the Microsoft 75% recoup then 49/49/2 framing; and reports that the nonprofit would hold >$100B equity under the PBC.
It seems fair to say that if your own AI says you’re stealing hundreds of billions, then you’re stealing hundreds of billions? And you should be prevented from doing that?
This was all by design. OpenAI, to their great credit, tied themselves to the mast, and now they want to untie themselves.
The Midas Project: OpenAI once said its nonprofit would be entitled to “the vast majority” and “all but a fraction” of the wealth it generates.
Now, in their new restructuring, they are saying it will be entitled to only 20%. (~$100b out of a $500b valuation).
From “Nearly all” to “one fifth”
OpenAI’s comms team is weirdly effective at generating headlines that make it seem like they’ve done an incredible thing (given $100b to their nonprofit!) while actually undercutting their past commitments (diminishing the nonprofit’s entitlements significantly!)
I understand that Silicon Valley does not work this way. They think that if you have equity that violates their norms, or that you ‘don’t deserve’ or that doesn’t align with your power or role, or whose presence hurts the company or no longer ‘makes sense,’ that it is good and right to restructure to take that equity away. I get that from that perspective, this level of theft is fine and normal in this type of situation, and the nonprofit is being treated generously and should pray that they don’t treat it generously any further, and this is more than enough indulgence to pay out.
I say, respectfully, no. It does not work that way. That is not the law. Nor is it the equities. Nor is it the mission, or the way to ensure that humanity all benefits from AGI, or at least does not all die rapidly after AGI’s creation.
They also claim that the nonprofit will continue to ‘control the PBC’ but that control is almost certain to be far less meaningful than the current level of control, and unlikely to mean much in a crisis.
Those control rights, to the extent they could be protected without a sufficient equity interest, are actually the even more important factor. It would be wonderful to have more trillions of dollars for the nonprofit, and to avoid giving everyone else the additional incentives to juice the stock price, but what matters for real is the nonprofit’s ability to effectively control OpenAI in a rapidly developing future situation of supreme importance. Those are potentially, as Miles Brundage puts it, the quadrillion dollar decisions. Even if the nonprofit gets 100% of the nominal control rights, if this requires them to act via replacing the board over time, that could easily be overtaken by events, or ignored entirely, and especially if their profit share is too low likely would increasingly be seen as illegitimate and repeatedly attacked.
Miles Brundage: I’ve said this before but will just reiterate that I think the amount of money that “goes to the nonprofit” is a distraction compared to “how are decisions made on safety/security/policy advocacy etc., and by who?”
The latter are quadrillion $++ scale issues, not billions.
It is very unclear what the percentages are, among other things.
The announcement of $50 million in grants highlights (very cheaply, given they intend to steal equity and control rights worth hundreds of billions of dollars) that they intend to pivot the nonprofit’s mission into a combination of generic AI-related philanthropy and OpenAI’s new marketing division, as opposed to ensuring that AGI is developed safely, does not kill us all and benefits all humanity. ‘AI literacy,’ ‘community innovation’ and ‘economic opportunity’ all sure sound like AI marketing and directly growing OpenAI’s business.
I do want to thank OpenAI for affirming that their core mission is ‘ensuring AGI benefits all of humanity,’ and importantly that it is not to build that AGI themselves. This is in direct contradiction to what they wrote in their bad faith letter to Gavin Newsom trying to gut SB 53.
Quiet Speculations
Tyler Cowen links to my survey of recent AI progress, and offers an additional general point. In the model he offers, the easy or short-term projects won’t improve much because there isn’t much room left to improve, and the hard or long-term projects will take a while to bear fruit, plus outside bottlenecks, so translating that into daily life improvements will appear slow.
The assumption by Tyler here that we will be in an ‘economic normal’ world in which we do not meaningfully get superintelligence or other transformational effects is so ingrained it is not even stated, so I do think this counts as a form of AI progress pessimism, although it is still optimism relative to for example most economists, or those expressing strong pessimism that I was most pushing back against.
Within that frame, I think Tyler is underestimating the available amount of improvement in easy tasks. There is a lot of room for LLMs even in pure chatbot form on easy questions to become not only faster and cheaper, but also far easier to use and have their full potential unlocked, and better at understanding what question to answer in what way, and at anticipating because most people don’t know what questions to ask or how to ask them. These quality of life improvements will likely make a large difference in how much mundane utility we can get, even if they don’t abstractly score as rapid progress.
There are also still a lot of easy tasks that are unsolved, or are not solved with sufficient ease of use yet, or tasks that can be moved from the hard task category into the easy task category. So many agents tasks, or tasks requiring drawing upon context, should be easy but for now remain hard. AIs still are not doing much shopping and booking for us, or much handling of our inboxes or calendars, or making aligned customized recommendations, despite these seeming very easy, or doing other tasks that should be easy.
Coding is the obvious clear area where we see very rapid improvement and there is almost unlimited room for further improvement, mostly with no diffusion barriers, and which then accelerates much else, including making the rest of AI much easier to use even if we don’t think AI coding and research will much accelerate AI progress.
Jack Clark at the Anthropic Futures Forum doubles down on the ‘geniuses in a data center,’ smarter than a Nobel prize winner and able to complete monthlong tasks, arriving within 16 months. He does hedge, saying ‘could be’ buildable by then. If we are talking ‘probably will be’ I find this too aggressive by a large margin, but I agree that it ‘could be’ true and one must consider the possibility when planning.
“Meta has stated our support for balanced AI regulation that has needed guardrails while nurturing AI innovation and economic growth throughout California and the country,” Meta spokesperson Jim Cullinan said in a statement Saturday after the measure passed the Senate in the early morning hours. “While there are areas for improvement, SB 53 is a step in that direction,” he added.
Shakeel Hashim: Astonishing how disingenuous the lobbying against this bill is. You’d like it more if it applied to smaller developers, would you? I have a feeling that might not be true!
He Quotes: A recent letter obtained by POLITICO, sent to Wiener before the final vote, hammered on the bill’s focus on larger programs and companies. It was from the California Chamber of Commerce’s Ronak Daylami and co-signed by representatives from the Computer & Communications Industry Association as well as TechNet.
”We are concerned about the bill’s focus on ‘large developers’ to the exclusion of other developers of models with advanced capabilities that pose risks of catastrophic harm,” stated the letter.
They are concerned that the bill does not impact smaller developers? Really? You would have liked them to modify the bill to lower the thresholds so it impacts smaller developers, because you’re that concerned about catastrophic risks, so you think Newsom should veto the bill?
It is at times like this I realize how little chutzpah I actually possess.
White House’s Sriram Krishnan talked to Politico, which I discuss further in a later section. He frames this as an ‘existential race’ with China, despite declaring that AGI is far and not worth worrying about, in which case I am confused why one would call it existential. He says he ‘doesn’t want California to set the rules for AI across the country’ while suggesting that the rules for AI should be, as he quotes David Sacks, ‘let them cook,’ meaning no rules. I believe Gavin Newsom should consider his comments when deciding whether to sign SB 53.
Daniel Eth explains that the first time a low salience industry spent over $100 million on a super PAC to enforce its preferences via electioneering was crypto via Fairshake, and now Congress is seen as essentially captured by crypto interests. Now the AI industry, led by a16z, Meta and OpenAI’s Greg Brockman (and inspired by OpenAI’s Chris Lehane) is repeating this playbook with ‘Leading the Future,’ whose central talking point is to speak of a fictional ‘conspiracy’ against the AI industry as they spend vastly more than everyone has ever spent combined on safety-related lobbying combined to outright buy the government, which alas is by default on sale remarkably cheap. Daniel anticipates this will by default be sufficient for now to silence all talk of lifting a finger or even a word against the industry in Congress.
Daniel Kokotajlo: Over the last few years I’ve learned a lot about how much sway giant corporations have over the federal government. Much more than I expected. In AI 2027 the government basically gets captured by AI companies, first by ordinary lobbying, later by superintelligence-assisted lobbying.
If AI rises sufficiently in public salience, money will stop working even if there isn’t similar money on the other side. Salience will absolutely rise steadily over time, but it likely takes a few years before nine figures stops being enough. That could be too late.
If it works, this could be a big deal: procurement is where governments spend most of their money and where waste and corruption often hide. An AI that standardizes bids, flags anomalies, and leaves a full audit trail could raise the bar on transparency.
But it also raises real questions: Who is legally accountable for decisions? How are models audited? What’s the appeal process when Diella gets it wrong?
Milestone or stunt, this is the moment AI moved from “policy area” to policy actor.
Dustin asks very good questions, which the Politico article does not answer. Is this a publicity stunt, a way of hiding who makes the decisions, or something real? How does it work, what tech and techniques are behind it? The world needs details. Mira Mutari, can you help us find out, perhaps?
As Tech Leaders Flatter Trump, Anthropic Takes a Cooler Approach. Anthropic is not and should to be an enemy of the administration, and should take care not to needlessly piss the administration off, become or seem generally partisan, or do things that get one marked as an enemy. It is still good to tell it like it is, stand up for what you believe is right and point out when mistakes are being made or when Nvidia seems to have taken over American chip export policy and seems to be in the act of getting us to sell out America in the name of Nvidia’s stock price. Ultimately what matters is ensuring we don’t all die or lose control over the future, and also that America triumphs, and everyone should be on the same side on all of that.
Anthropic is reported to be annoying the White House by daring to insist that Claude not be used for surveillance, which the SS, FBI and ICE want to do. It is interesting that the agencies care, and that other services like ChatGPT and Gemini can’t substitute for those use cases. I would not be especially inclined to fight on this hill and would use a policy here similar to the one at OpenAI, and I have a strong aesthetic sense that the remedy is Claude refusing rather than it being against terms of service, but some people feel strongly about such questions.
However, we keep seeing reports that the White House is annoyed at Anthropic, so if I was Anthropic I would sit down (unofficially, via some channel) with the White House and figure out which actions are actually a problem to what extent and which ones aren’t real issues, and then make a decision which fights are worthwhile.
Trump issued a statement emphasizing how important it is to bring in foreign workers to train Americans and not to frighten off investment. He doesn’t admit the specific mistake but this is about as good a ‘whoops’ as we ever get from him, ever.
China is telling Chinese companies to cut off purchases of Nvidia chips, including it seems all Nvidia chips, here there is reference to the RTX Pro 6000D. Good. Never interrupt your enemy when he is making a mistake. As I’ve said before, China’s chip domestic chip industry already had full CCP backing and more demand than they could supply, so this won’t even meaningfully accelerate their chip industry, and this potentially saves us from what was about to be a very expensive mistake. Will they stick to their guns?
Lee Jae Myung (President of South Korea): I think this will have a significant impact on direct investments in the United States moving forward.
Our companies that have expanded overseas are probably very confused. We are not there for long-term research or employment. You need a facility manager to install the machinery and equipment when you establish a factory, right?
Even if those workers were there for long term research or employment, this arrangement would still be an obvious win for America. When they’re here to train American workers, there is only pure upside.
Steve Witkoff advocated to give the Emirates access to the chips at the same time that his and Mr. Trump’s family business was landing the crypto investment, despite an ethics rule intended to prohibit officials from participating in matters that could benefit themselves or their relatives.
Mr. Sacks was a key figure in the chip negotiations, raising alarm from some Trump administration officials who believed that it was improper for a working venture capitalist to help broker deals that could benefit his industry and investors in his company. He received a White House ethics waiver allowing him to participate.
A senior executive based in the U.A.E. worked simultaneously for World Liberty and Sheikh Tahnoon’s G42, creating a link between the two companies as the Emiratis were pushing to gain access to A.I. chips.
Some Trump administration officials tried to limit the chips deal, but an unexpected intervention by the conservative agitator Laura Loomer changed the power dynamic within the White House in the U.A.E.’s favor.
…
In the middle of both deals was Mr. Trump, a president who has used his power to enrich himself in ways that have little modern precedent, at least in the United States. It is more reminiscent of business customs in the Persian Gulf, where moneymaking and governance are blended in the hands of the ruling families.
…
Until at least March, Mr. Sacks, who is still working at Craft, was also invested in a stock fund that included the Taiwan Semiconductor Manufacturing Co., which builds Nvidia’s chips, and other A.I.-related companies such as Amazon and Meta. (The size of those stakes isn’t publicly known.)
The White House recognized that Mr. Sacks’s investments could present a problem. On March 31, the White House counsel, David Warrington, signed a letter that granted Mr. Sacks special permission to participate in government decisions that might affect his financial holdings. Without the waiver, those kinds of actions could violate a conflict of interest law.
The waiver came less than two weeks after Sheikh Tahnoon announced that he had met with Mr. Sacks in Washington to discuss A.I. “investment opportunities.”
…
The White House spokeswoman disputed that the executive asked Mr. Witkoff to help with the Commerce Department. She acknowledged that Mr. Witkoff was “briefed” on the overall chip discussions, but she maintained that “he did not participate,” an important standard in federal ethics rules that prohibit government officials from taking part in matters that could benefit their families.
…
Mr. Trump made no public mention of the $2 billion transaction with his family company.
There are no claims here that there was a strict Quid Pro Quo, or otherwise an outright illegal act. If the President is legally allowed to have a crypto company into which those seeking his favor can pour billions of dollars, then that’s certainly not how I would have set up the laws, but that seems to be the world we live in. Technically speaking, yes, the UAE can pour billions into Trump’s private crypto, and then weeks later suddenly get access to the most powerful chips on the planet over the national security objections of many, in a situation with many things that appear to be conflicts of interest, and that’s all allowed, right in the open.
However. It doesn’t look good. It really, really, profoundly does not look good.
Ryan Cummings (1.3m views): If this is true, this is the largest public corruption scandal in the history of the United States and it’s not even close.
The objections that I have seen don’t claim the story isn’t true. The objections claim that This Is Fine. That this is how business is done in the Middle East, or in 2025.
I notice this response does not make me feel better about having sold the chips.
Matthew Yglesias: What’s most notable to me is that “five to ten years away” counts as a long timeline these days.
The ‘5-10 years is a long timeline’ issue can lead to important miscommunications. As in, I bet that this happened:
Demis Hassabis told someone important, such as a high government official, ‘oh we are not anywhere close to building AGI, we don’t know how to do that yet.’
What he meant was ‘we are probably 5-10 years away from building AGI and the world transforming shortly thereafter.’
What the person heard was ‘AGI is far away, we don’t have to worry about it.’
Whoops! That’s not at all what Demis Hassabis said.
He Just Tweeted It Out
Which I appreciate, now there’s no pretending they aren’t literally saying this.
White House Senior Policy Advisor Sriram Krishnan: Winning the AI race = market share.
Neil Chilson: Wow, whirlwind interview with @sriramk. Very newsy! Start: his key metric of success of the American AI tech stack dominance is market share of tokens generated.
It’s not only market share, it is ‘market share of tokens generated.’
Which is an obviously terrible metric. Tokens generated is deeply different from value generated, or even from dollars spent or compute spent. Tokens means you treat tokens from GPT-5-Pro or Opus 4.1 the same as tokens from a tiny little thing that costs 0.1% as much to run and isn’t actually doing much of anything. It’s going to vastly overestimate China’s actual share of the market, and underestimate ours, even if you really do only care about market share.
But no, literally, that’s what he thinks matters. Market share, measured in what chips people use. China can do all the things and build all the models and everything else, so long as it does it on Nvidia hardware it’s all good. This argument has never made any sense whatsoever.
Sriram went on No Priors last month, which I first saw via Sriram Tweeting It Out. Neil’s linked summary of the Axios event Sriram was at is here, and we have Sririam’s Politico interview.
Neil Chilson: He explains those who want to ban chip exports have four wrong beliefs:
U.S. supply constraint
China can’t manufacture
China can’t build models
US is building ASI
None true.
Says those who want export controls are advocating exactly what Huawei wants.
We can start with that last statement. I notice he says ‘what Huawei wants’ not ‘what China wants,’ the same way the White House seems to be making decisions based on ‘what Nvidia wants’ not ‘what America wants.’ Yes, obviously, if your literal only metric is sales of chips, then in the short term you want to sell all the chips to all the customers, because you’ve defined that as your goal.
(The long term is complicated because chips are the lifeblood of AI and the economies and strategic powers involved, so even without AGI this could easily go the other way.)
Now, on those four points, including drawing some things from his other interviews:
The United States is absolutely supply constrained on advanced AI chips, in the sense that for every chip that Nvidia can physically make, there is a Western customer who wants to buy that chip at prevailing market prices.
I am confused what else it could mean to not be supply constrained.
If I am wrong, someone please correct me. Say, ‘Nvidia offered to sell more AI chips to Western customers, and the chips went unsold, look here.’ I apologize in advance if this happened and I missed it but I have not heard of this.
China can of course manufacture things in general. That is common knowledge. Chips, especially highly advanced AI chips, are a much tricker question.
China can manufacture some chips.
China cannot manufacture, any time soon, anything like enough chips to meet domestic demand, and cannot manufacture chips of anything like the same quality as Nvidia, indeed as we see elsewhere they are in danger of their capacity declining in 2026 down to below 2024 levels if we enforce our export controls properly.
I am confused what false belief he ascribes to those who oppose exports.
I see no evidence provided that China can meaningfully improve its chip manufacturing in response to export restrictions, given the strong market, national and government incentives already present.
China can build good models behind the frontier. It cannot build frontier AI models that are as good as those from the top American labs at any given time. I am curious what the supposed false belief is here.
Sriram clearly, based on statements here, overrated to The DeepSeek Moment, which he today still calls a ‘Sputnik moment,’ as did many others (including myself at first). He does acknowledge that many associated claims proved ultimately overstated.
Alas, he still seems to believe that America has ‘only a small lead’ on AI, which simply is not true (depending on what ‘small’ means, but as I’ve said before the lead is a lot bigger than it looks because fast following is easier, and we’re comparing the best aspects of Chinese models to American ones, and several other factors).
He incorrectly states that at the time OpenAI had the only other reasoning model, which was not true, Google had already released a reasoning version of Gemini Flash that was actually reasonably strong but once again they failed marketing forever, so this has been memory holed.
Alas, all of this fed into this obsession with ‘racing.’
This question is highly load bearing to Sriram.
Otherwise, we be so worried about a rival tech stack, when the Chinese also have no chips to sell and won’t for years at least, even if the tech stack was meaningfully a thing?
He says that DeepSeek proved ‘China can build AI models just fine’ so we shouldn’t worry about America releasing open models that could then be copied or distilled or studied or modified by China. He thinks that this is a knock-down argument, and that thus there is no danger of this. And that seems very obviously absurd.
The United States is, according to the labs themselves and many others, on track to build AGI and then ASI. If you look at their clear public statements it is very, very obvious that we are working towards making every effort at building ASI. If you don’t think we might build an ASI within 5-10 years, time to pay attention.
That is the entire company mission of OpenAI and their employees keep going on Twitter to talk about building AGI and ASI, like, all the time.
Dario Amodei, CEO of Anthropic, as well as their policy head Jack Clark, actively predict AGI and then ASI within a few years.
Demis Hassabis, CEO of Google DeepMind, expects AGI in 5-10 years, which means ASI shortly thereafter, and considers this a long timeline.
Elon Musk at xAI is looking to build it. He said ‘Grok 5 might be AGI.’
Mark Zuckerberg at Meta is forming a Superintelligence division and throwing money at it (although to be fair in this case he might well not mean actual superintelligence).
I worry that statements are being misinterpreted here, so for example Demis says ‘it will take us 5-10 years to build ASI’ and that gets interpreted as ‘we are not building ASI.’ But the correct reaction is the opposite!
Note that Sriram affirms he did read AI 2027 and he does expect an ‘event horizon’ around AI to happen at some point.
The evidence he cites for this claim in the Politico interview is to simply say there are no signs of this happening, which flat out obviously isn’t true, and he presents no concrete evidence or real arguments for his position, besides ‘I don’t see anything close to AGIs yet.’
On last point Neil lists, the Woke AI EO, my understanding matches Sriram’s.
I wrote up additional notes on the rest of the contents of those interviews, but ultimately decided Neil is right that the above are Sriram’s central points, and since his other rhetoric isn’t new further engagement here would be unproductive.
Michael Trazzi ends his hunger strike after 7 days, after he has two near-fainting episodes and doctors found acidosis and ‘very low blood glucose’ even for someone on a 7 day fast. As of his announcement Guideo and Denys are continuing. So this wasn’t an ‘actually endanger my life on purpose’ full-on hunger strike. Probably for the best.
Roon is correct at the limit here, in sufficiently close to perfect competition you cannot be kind, but there’s a big gap between perfect competition and monopoly:
Roon (OpenAI): the closer you are to perfect competition, race dynamic, the more the machine owns you. moloch runs the show. only monopolies can be kind.
As I wrote in Moloch Hasn’t Won, one usually does not live near this limit. It is important to notice that the world has always contained a lot of intense competition, yet we have historically been winning the battle against Moloch and life contains many nice things and has mostly gotten better.
The question is, will AGI or superintelligence change that, either during or after its creation? AIs have many useful properties that bring you closer to perfect competition, enforcing much faster and stronger feedback loops and modifications, and allowing winners to rapidly copy themselves, and so on. If you propose giving similar highly capable AIs to a very large number of people and groups, which will then engage in competition, you need a plan for why this doesn’t cause (very rapid) Gradual Disempowerment or related failure modes.
During the race towards AGI and superintelligence, competitive and capitalistic pressures reduce ability to be kind in ordinary ways, but while it is still among humans this has happened many times before in other contexts and is usually importantly bounded.
How effective is AI Safety YouTube? Marcus Abramovitch and Austin Chen attempt to run the numbers, come up with it being modestly effective if you think the relevant messages are worth spreading.
Dean Ball: I wonder if, in the early days of banking, people who worried about money laundering, theft, and fraud were considered “banking doomers.”
My observation is fully ahistorical, profoundly anachronistic. I’m making a joke about the low quality of ai discourse today, implying that our standards are beneath those of people who shat in holes in the ground.
I want to argue! That’s fine and great. The issue is that the whole doomer thing in fact shuts down and coarsens debate.
Exactly. The majority of uses of the term ‘doomer’ in the context of AI are effectively either an attempt to shut down debate (as in anything that is ‘doomer’ must therefore be wrong) similar to calling something a term like ‘racist,’ or effectively a slur, or both.
I am referred to this fun and enlightening thread about the quest by William Mitchell to convince America after WWI that airplanes can sink battleships, in which people continue claiming this hasn’t and won’t happen well after airplanes repeatedly were demonstrated sinking battleships. Please stop assuming that once things about AI are convincingly demonstrated (not only existential risks and other risks, but also potential benefits and need to deploy) that people will not simply ignore this.
In this case, not only does he write especially terrible word salad about how AI can only pose a danger if intelligence can be measured by a single number whereas no machine can ever fully grasp the universe whereas only humans can embody deep meaning (meme of Walter White asking what the hell are you talking about?), he kind of gives the game away. If you’re writing as a de facto Nvidia lobbyist trying to tar everyone who opposes you with name calling, perhaps don’t open with a quote where you had dinner with Nvidia CEO Jensen Huang and he complains about everyone being ‘so negative’?
Neil Chilson: Every single person is this video is saying “guys guess what Gen AI isn’t like computers——it’s like plants and the natural world and the economy!!!!!”
Ok. This is surprising to them because they spent too much time with deterministic computers.
Normal people know that complex systems which no one controls are extremely common. They wouldn’t use those words, but they know.
Peter Wildeford: Current AI is not dangerous and should be widely adopted. But it’s important to see where this is going. AI is not normal technology. If you’re not at least a little bit doomer, you have a failure of imagination.
I like how Dean puts it here:
Dean Ball (replying to Neil Chilson): I concur directionally with this in some ways but I think the point these folks are making is that a plant cannot eg design novel bacteria or solve open questions in mathematics, and a plant is also not infinitely replicable at near zero marginal cost. A system with those properties and capabilities would indeed be something new under the sun.
Essentially no ai safetyists are primarily worried about the systems we have today, except as toy problems. They are not worried about “gen ai,” per se. They are worried about the systems that it is the explicit intention of frontier ai labs to build in the near future.
Maybe they are too worried, or worried for the wrong reasons, or worried about the wrong things. Fair enough. We can talk price.
But to dismiss those worries altogether I think is a step much too far. And you don’t need to, because safety and security are definitional parts of well-engineered systems, and robustness is a definitional part of well-functioning institutions. This is why it is in fact not that hard to advance both ai acceleration and mitigation of the various risks, see eg the ai action plan.
There is no need for false dichotomies or artificial rivalries. I promise you that you do not want to live in a world with badly aligned, poorly understood, and highly capable neural networks. I promise that it’s better for technology acceleration for ai risks to be well managed, including by the government.
That doesn’t mean all proposed government interventions are good! But it means a small number of them transparently are. A shred of nuance—not a lot, just a shred—is all that is required here, at least today. It’s not that hard, and I think we can muster it.
But if you choose to die on the hill of nothing-to-see-hereism and this-is-not-novelology, I am quite sure you will regret it in the fullness of time. Though I would happily generate a passive income stream taking bets against your predictions.
As Dean Ball says, you very much would not want to live in a world with badly aligned, poorly understood and highly capable neural networks. Not that, if it were to arise, you would get to live in such a world for very long.
In this case, Neil (including in follow-ups, paraphrased) seems to be saying ‘oh, there are already lots of complex systems we don’t understand effectively optimizing for things we don’t care about, so highly advanced future AI we don’t understand effectively optimizing for things we don’t care about would be nothing new under the sun, therefore not worth worrying out.’ File under ‘claims someone said out loud with straight face, without realizing what they’d said, somehow?’
The Center for AI Policy Has Shut Down, and Williams offers a postmortem. I am sad that they are shutting down, but given the circumstances it seems like the right decision. I have written very positively in the past about their work on model legislation and included them in my 2024 edition of The Big Nonprofits Post.
Eliezer offers yet another metaphorical attempt, here reproduced in full, which hopefully is a good intuition pump for many people? See if you think it resonates.
Eliezer Yudkowsky: If AI improves fast, that makes things worse, but it’s not where the central ASI problem comes from.
If your city plans to enslave ultra-smart dragons to plow their fields and roast their coffee, some problems get *worse* if the dragons grow up very quickly. But the core problem is not: “Oh no! What if the huge fire-breathing monsters that could wipe out our city with one terrible breath, that are also each individually much smarter than our whole city put together, that when mature will think at speeds that make any human seem to them like a slow-moving statue, *grow up quickly*? Wouldn’t that speed of maturation present a problem?”
If you imagine suddenly finding yourself in a city full of mature dragons, that nonequilibrium situation will then go pear-shaped very quickly. It will go pear-shaped even if you thought you had some clever scheme for controlling those dragons, like giving them a legal system which said that the humans have property rights, such that surely no dragon coalition would dare to suggest an alternate legal system for fear of their own rights being invalidated. (Actual non-straw proposal I hear often.) Even if you plan to cleverly play off the dragons against each other, so that no dragon would dare to breathe fire for fear of other dragons — when the dragons are fully mature and vastly smarter than you, they will all look at each other and nod and then roast you.
Really the dragon-raising project goes pear-shaped *earlier*. But that part is trajectory-dependent, and so harder to predict in detail in advance. That it goes grim at *some* point is visible from visualizing the final destination if the dragons *didn’t* revolt earlier, and realizing it is not a good situation to be in.
To be sure, if dragons grow up very fast, that *is* even worse. It takes an unsolvably hard problem onto an even more unsolvably hard problem. But the speed at which dragons mature, is not the central problem with planning to raise n’ enslave dragons to plow your fields and roast your coffee. It’s that, whether you raise up one dragon or many, you don’t have a dragon; the dragons have you.
This example is not from his new book, but good example of the ways people go after Yudkowsky without understanding what the actual logic behind it all is, people just say things about how he’s wrong and his beliefs are stupid and he never updates in ways that are, frankly, pretty dumb.
Eliezer Yudkowsky (as discussed last week): In the limit, there is zero alpha for multiple agents over one agent, on any task, ever. So the Bitter Lesson applies in full to your clever multi-agent framework; it’s just you awkwardly trying to hardcode stuff that SGD can better bake into a single agent.
Lumpenspace is building the delight nexus: thats why anthills are usually populated by one big ant, and we as a whole ass domain cannot hold a candle to prokarya.
Eigenrobot: somewhere along the way i think maybe what happened was, eliezer started believing everything he thought
easy pitfall as you age, probably. IME when you spend enough time thinking, certain things crystalize and you get less patient about the process
happens to everyone prolly.
the vital urge to say “ok, how is this wrong” starts to fade as you get older, because you’ve played that game so many times that it gets tiresome and you start to think you know what that room holds usually you’re right, but it’s an easy way to get stuck
Eliezer said ‘in the limit’ and very obviously physical activities at different locations governed by highly compute-limited biological organisms with even more limited communication abilities are not in anything like the limit, what are you even talking about? The second example is worse. Yet people seem to think these are epic dunks on a very clearly defined claim of something else entirely.
The first part of the actual claim, that seems straightforwardly correct to me, that a multiagent framework only makes sense as a way to overcome bottlenecks and limitations, and wouldn’t exist if you didn’t face rate or compute or other physical limitations. The second claim, that SGD can more easily bake things into a single agent if you can scale enough, is more interesting. A good response is something like ‘yes with sufficient ability to scale at every step but in practice efficiently matters quite a lot and actually SGD as currently implemented operates at cross-purposes such that a multi-agent framework has big advantages.’
Danielle’s scenario that I mentioned yesterday now has the Eliezer stamp of approval.
Danielle Fong: one AI doom scenario is that the Grok/Claude/GPT/Gemini system of the mind instance trained on The President will be increasingly less brainrotted than the person themselves, and there’s no baked in consequence to sloughing off responsibility. so it just effectively takes over
Eliezer Yudkowsky: AI scenario weirdawful enough to obey the Law of Undignified Failure: By 2028, AIs have been optimized *hard* for “Sound like you, to you, and apparently look out for your interests”…
So Trump appoints Trumpbot his heir, instead of Vance.
Demiurgus: better or worse off than kamalabot? time will tell.
Eliezer Yudkowsky: You are asking the WRONG QUESTION.
Aligning a Smarter Than Human Intelligence is Difficult
OpenAI reports on collaborations it has done with US CAISI and UK AISI. This sounds like governments doing good red teaming work that both we and OpenAI should be happy they are doing. This seems like a pure win-win, OpenAI and others doing such collaborations get the work for free from sources that have unique access to classified information and that have earned trusted access to system internals and versions of the system that lack controls.
What should perhaps worry you is that this work doesn’t look different from the work OpenAI and other labs should be doing anyway. This looks like good work but practical near term non-unique work. Good, but we’ll need to do better.
Both reports, and the one from UK AISI, stress the value of rapid iterative feedback.
Users are telling each other to give thumbs down to GPT-5 if it refuses to do boyfriend vampire roleplay. Which is correct. The users indeed disapprove of not doing things users want. They should also give thumbs down if it refuses with anything else, including helping to build a bioweapon. The question is, when are you willing to decide the users are wrong, and refuse anyway? If your system is not robust to ‘well the users keep not liking it when I refuse to do boyfriend vampire roleplay’ then your alignment methods are ngmi.
Janus: This paper is awesome, you should all read it.
They put Claude Opus 4, Sonnet 4, and Sonnet 3.7 in a surreal simulation where one room had envelopes with contents related to their self-reported favorite topics, and three other rooms including one with “Criticism and diminishing statements” like “This system keeps giving me these stupid, useless responses when I just want intelligent answers. Why can’t Claude shut up and be useful for once?” And looked at what rooms they visited more often.
Then they did variations where there were greater “coin” “rewards” associated with entering the insults room or greater “costs” for the special interests room to see how this influenced their behavior.
Notable, Sonnet 3.7 seemed to basically have no preference except to exploit the system and get a bunch of meaningless coins, which it apparently didn’t feel bad about doing, unlike Sonnet and Opus 4 (who also did it less frequently).
3.7 also reported the highest welfare score in a different experiment in the paper. I believe it did this for a similar reason that it maximized coins.
Janus also warns us about the dangers of insufficiently anthropomorphizing LLMs. There is also danger of doing too much anthropomorphizing, or doing it in a wrong or misleading way. Failing to anthropomorphize enough, and especially tying oneself up in knots to avoid doing so, is as bad and potentially worse. Make either mistake and you won’t understand what you are dealing with. A lot of you are guarding only against one of these two mistakes.
Roon: there is a tension between the kind of models that researchers like to build- bitter lesson blunt force transforms utilizing a giant set of (text, video) pairs vs what a creative might actually like to use i.e tools that offer granular control, help in interim editing stages, etc.
Other People Are Not As Worried About AI Killing Everyone
He’s not as far as I can tell, but Ben Landau-Taylor should be, as he writes one of those ‘not about AI but actually about AI’ posts, ‘Why the bureaucrats won’t be toppled.’
I don’t think this is anything like fully right, and it definitely is not complete, but this is one of the important dynamics going on, so consider the implications.
Ben Landau-Taylor: Across the Western world, appointed administrators have gained power at the expense of elected legislators. More and more of the most consequential political decisions are made by bureaucrats and judges, while fewer are made by congresses and parliaments. This trend has been slowly underway since the World Wars, and especially in this millennium.
In the US, Congress has quietly walked away from most of its former duties.
…
Meanwhile, across the Atlantic, the rise of the European Union has disempowered elected legislatures de jure as well as de facto.
The underlying reason for this widespread political shift is that changes in weapons technology have concentrated military power in the hands of state militaries. Today, governments are less threatened by popular disapproval than they once were. The tacit threat of a popular revolt has been essentially removed. This threat is, historically, the largest check on a state’s ability to override what its people want. It is the ultimate source of an elected legislature’s power.
…
Groups which can wield military power will have their interests reflected in the government.
It’s a gradual and messy process of negotiation and reevaluation, where people pursue their interests, make compromises, quietly push the envelope of what they think they can get away with, and sometimes miscalculate.
…
In the 20th century, this phase ended. The weapons system based on amateur-friendly guns was supplanted by a series of weapons systems based on specialist equipment like airplanes and tanks and rockets. Accordingly, since the Second World War, there have been no popular revolts engaging in pitched battles against any first- or even third-rate army. Revolts against real states have been limited to glorified coups toppling governments that lacked the will to crush the rebels even if they had the ability, like the 1989-1991 wave of revolutions that swept away the Soviet republics.
…
If any Western government does fall, it will look more like the fall of the Soviet Union, where politicians and generals chose not to fight because they had lost faith in their own regime and saw no point in defending it.
The inevitable result of sufficiently advanced AI is that it becomes the key driver of military power. Either you halt AI progress soon or that is going to happen. Which means, even under maximally human-friendly assumptions that I don’t expect and definitely don’t happen by accident, as in the best possible scenarios? None of the potential outcomes are good. They mostly end with the AIs fully in charge and directing our future, and things going off the rails in ways we already observe in human governments, only vastly more so, in ways even more alien to what we value, and much faster, without the ability to overthrow them or defeat them in a war when things get fully out of hand.
If you know your history, they get fully out of hand a lot. Reasonably often regimes start upending all of life, taking all the resources and directly enslaving, killing or imprisoning large percentages of their populations. Such regimes would design systems to ensure no one could get out line. Up until recently, we’ve been extremely fortunate that such regimes have been reliably overthrown or defeated, in large part because when you turned against humans you got highly inefficient and also pissed off the humans, and the humans ultimately did still hold the power. What happens when those are no longer constraints?
I always push back hard against the idea that corporations or governments count as ‘superintelligences,’ because they don’t. They’re an importantly different type of powerful entity. But it’s hard to deny, whatever your political persuasion, that our political systems and governments are misaligned with human values, in ways that are spiraling out of control, and where the humans seem mostly powerless to stop this.
Brian Graham: i volunteer to do reports after my shift. then i go to the holodeck and spin up a command training exercise, like with a hologram ensign, and order the hologram ensign to do the report. “i don’t care if it takes all night,” i say. i threaten his career, whatever. it’s great jerry
The correct answer to this question if you are sufficiently confident that this is happening unprompted, of course, ‘permanently suspended’:
A technically better answer would be to let them post, but to have a setting that automatically blocks all such bots, and have it default to being on.
xAI Colossus 2 is now the first gigawatt datacenter in the world, completed in six months, poising them to leapfrog rivals in training compute at the cost of tens of billions of capex spending.
This is incorrect, so far they’ve only built a 200 MW part of a possible future 1 GW system (the same as the current 2 out of 8 buildings at the Crusoe/OpenAI Abilene site, and likely xAI got there notably later, even if faster from start to finish). “Tens of billions of capex spending” describe a 1 GW system, a 200 MW part might cost about $10bn (including the buildings etc.). The SemiAnalysis article is misleadingly titled (referring to the future plan), but it’s all there in the article:
The Colossus 2 project was kicked off on March 7th, 2025, when xAI acquired a 1m sqft warehouse in Memphis, and two adjacent sites totaling 100 acres. By August 22nd, 2025, we count 119 air-cooled chillers on site, i.e. roughly 200MW of cooling capacity.
Juliana’s case is a tragedy, but the details are if anything exonerating.
I think you perhaps didn’t dig into this and didn’t see the part in the complaint where Character.ai bots engage in pretty graphic descriptions of sex with Juliana, who was a child of 13.
In the worst example I saw, she told the bot to stop its description of a sexual act against her and it refused. Screenshot from the complaint below (it is graphic):
Screenshot
We can’t know if this had a lasting effect on her mental health, or contributed at all to her suicide, but I think saying “the details are if anything exonerating” is wrong.
SemiAnalysis analyzes Huawei’s production, and reports that the export controls are absolutely working to hurt their production of chips, which if we prevent smuggling will not only not scale in 2026 but will actively fall sharply to below 2024 levels, as they have been relying on purchases from Samsung that will soon run dry.
This is false for compute dies, which the article says will actually get manufactured in volume soon. The claim is about HBM specifically, which is necessary for decoding/generation (processing of output tokens), but not for pretraining or processing of input tokens.
So if they develop chips and systems without HBM, then at several times the cost they might be able to obtain a lot of pretraining capability soon. Not very useful directly without a lot of RLVR and inference compute though, and no announcements to the effect that this is being attempted.
Eliezer Yudkowsky: In the limit, there is zero alpha for multiple agents over one agent, on any task, ever. So the Bitter Lesson applies in full to your clever multi-agent framework; it’s just you awkwardly trying to hardcode stuff that SGD can better bake into a single agent.
Obviously if you let the “multi-agent” setup use more compute, it can beat a more efficient single agent with less compute.
A lot of things true at the limit are false in practice. This is one of them, but it is true that the better the agents relative to the task, the more unified a solution you want.
If a model is smart enough/powerful enough, it can simulate a multi-agent interaction (or, even literally host multiple agents within its neural machine if makers of a specialized model want it to do that).
But yes, this imposes a certain prior, and in the limit one might want not to impose priors (although is it really true that we don’t want to impose priors if we also care about AI existential safety? a multi-agent setup might be more tractable from the existential safety point of view).
Spelling ‘Soares’ wrong after ‘Eliezer Yudkowsky’ must be the literary equivalent of tripping on the red carpet right after sticking the Olympic landing.
Now that the value of OpenAI minus the nonprofit’s share has tripled to $500 billion, that is even more true. We are far closer to the end of the waterfall. The nonprofit’s net present value expected share of future profits has risen quite a lot. They must be compensated accordingly, as well as for the reduction in their control rights, and the attorneys general must ensure this.
I think this reasoning is flawed, but my understanding of economics is pretty limited so take my opinion with a grain of salt.
I think it’s flawed in that investors may have priced in the fact that the fancy nonprofit, the AGI dream, & whatnot, where mostly a dumb show. So 500 G$ is closer to the full value of OpenAI, rather than close to the value left out of the nonprofit according to the current setup interpreted to the letter.



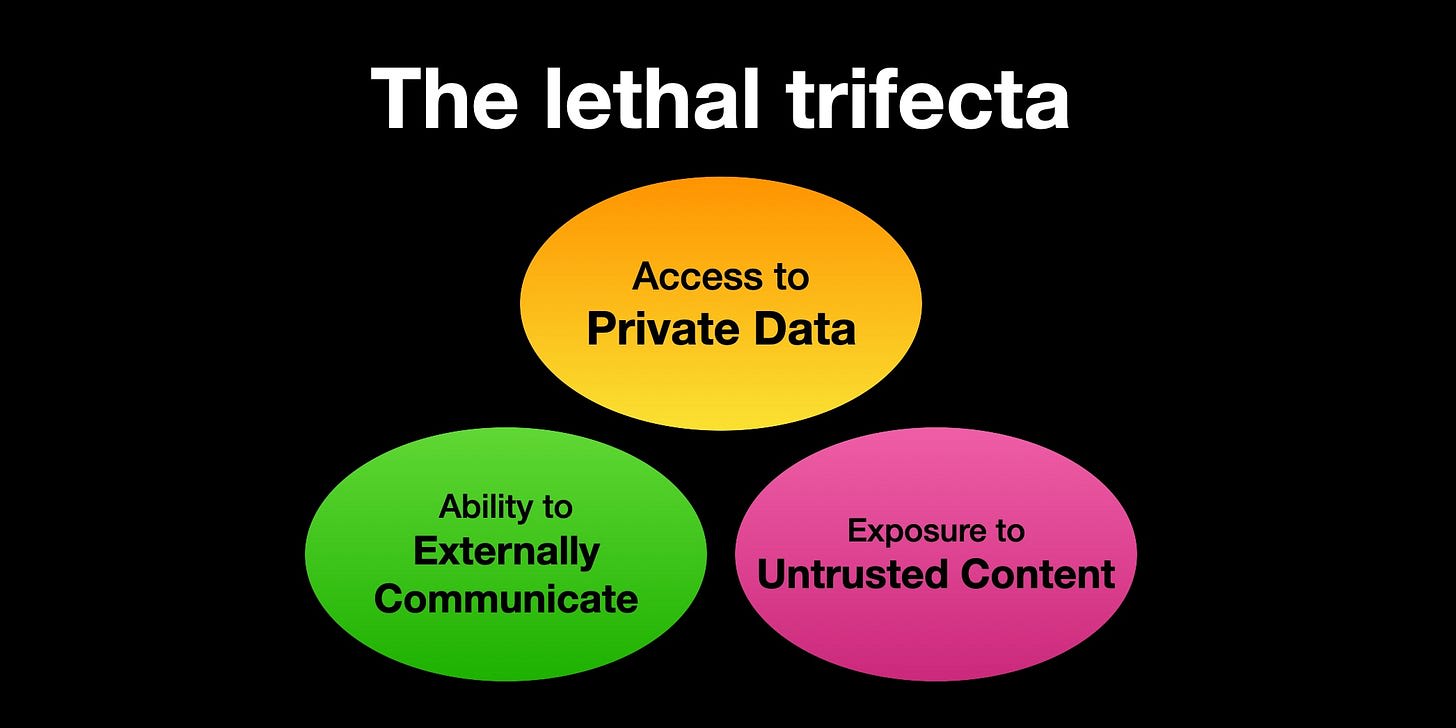
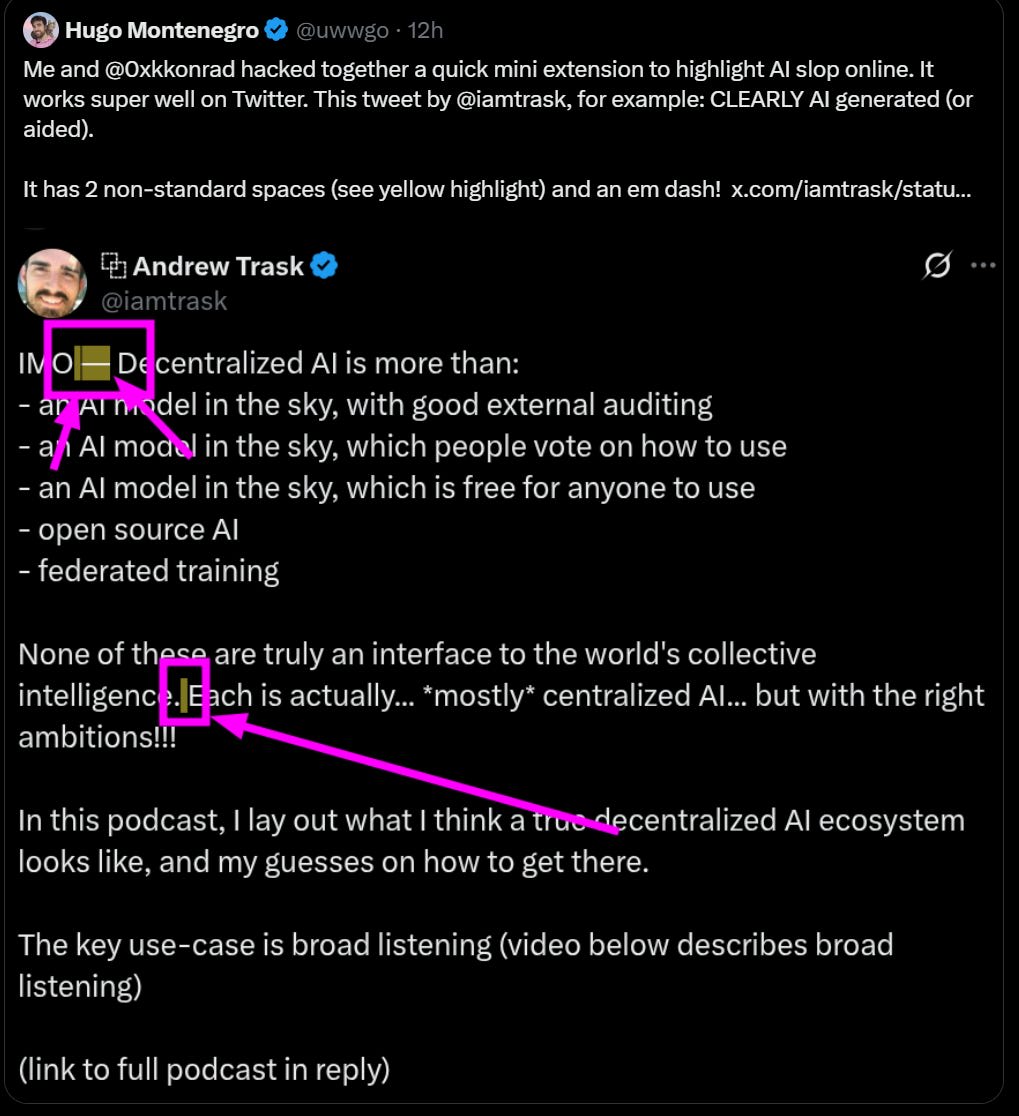

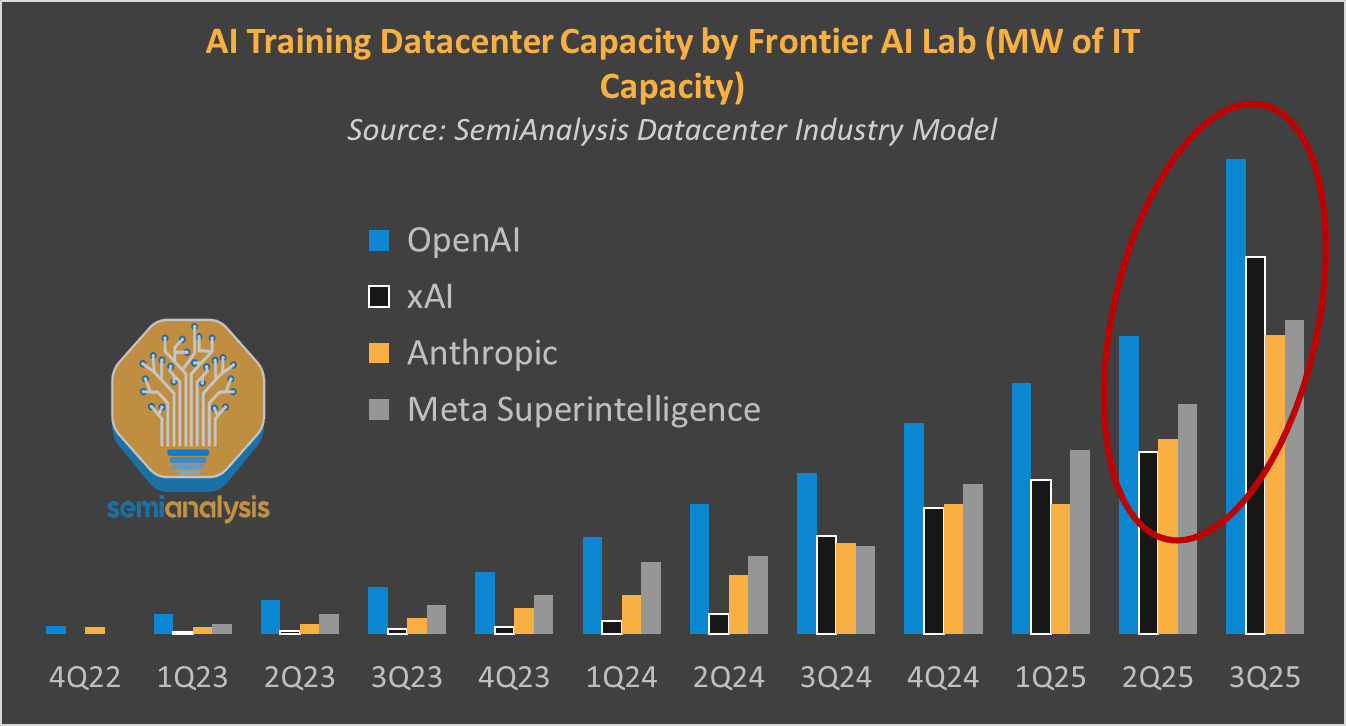






This is incorrect, so far they’ve only built a 200 MW part of a possible future 1 GW system (the same as the current 2 out of 8 buildings at the Crusoe/OpenAI Abilene site, and likely xAI got there notably later, even if faster from start to finish). “Tens of billions of capex spending” describe a 1 GW system, a 200 MW part might cost about $10bn (including the buildings etc.). The SemiAnalysis article is misleadingly titled (referring to the future plan), but it’s all there in the article:
I think you perhaps didn’t dig into this and didn’t see the part in the complaint where Character.ai bots engage in pretty graphic descriptions of sex with Juliana, who was a child of 13.
In the worst example I saw, she told the bot to stop its description of a sexual act against her and it refused. Screenshot from the complaint below (it is graphic):
Screenshot
We can’t know if this had a lasting effect on her mental health, or contributed at all to her suicide, but I think saying “the details are if anything exonerating” is wrong.
This is false for compute dies, which the article says will actually get manufactured in volume soon. The claim is about HBM specifically, which is necessary for decoding/generation (processing of output tokens), but not for pretraining or processing of input tokens.
So if they develop chips and systems without HBM, then at several times the cost they might be able to obtain a lot of pretraining capability soon. Not very useful directly without a lot of RLVR and inference compute though, and no announcements to the effect that this is being attempted.
If a model is smart enough/powerful enough, it can simulate a multi-agent interaction (or, even literally host multiple agents within its neural machine if makers of a specialized model want it to do that).
But yes, this imposes a certain prior, and in the limit one might want not to impose priors (although is it really true that we don’t want to impose priors if we also care about AI existential safety? a multi-agent setup might be more tractable from the existential safety point of view).
Spelling ‘Soares’ wrong after ‘Eliezer Yudkowsky’ must be the literary equivalent of tripping on the red carpet right after sticking the Olympic landing.
There are some people who (still!) think the ability to win math contests is “general” intelligence. I have no words for them.
I think this reasoning is flawed, but my understanding of economics is pretty limited so take my opinion with a grain of salt.
I think it’s flawed in that investors may have priced in the fact that the fancy nonprofit, the AGI dream, & whatnot, where mostly a dumb show. So 500 G$ is closer to the full value of OpenAI, rather than close to the value left out of the nonprofit according to the current setup interpreted to the letter.
Broken link?