A Mechanistic Interpretability Analysis of a GridWorld Agent-Simulator (Part 1 of N)
AKA: Decision Transformer Interpretability 2.0
Code: repository, Model/Training: here . Task: here.
High Level Context/Background
What have I actually done that is discussed in this post?
This is a somewhat rushed post summarising my recent work and current interests.
Toy model: I have trained a 3 layer decision transformer which I call “MemoryDT”, to simulate two variations of the same agent, one sampled with slightly higher temperature than training (1) and one with much higher temperature (5). The agent we are attempting to simulate is a goal-directed online RL agent that solves the Minigrid-Memory task, observing an instruction token and going to it in one of two possible locations. The Decision Transformer is also steered by a Reward-to-Go token, which can make it generate trajectories which simulate successful or unsuccessful agent.s
Analysis: The analysis here is mostly model psychology. No well understood circuits (yet) but I have made some progress and am keen to share it when complete. Here, I discuss the model details so that people are aware of them if they decide to play around with the app and show some curiosities (all screenshots) from working with the model.
I also made an interpretability app! The interpretability app is a great way to analyse agents and is possibly by far the best part of this whole project.
My training pipeline should be pretty reusable (not discussed at length here). All the code I’ve used to train this model would be a pretty good starting point for people who want to work on grid-world agents doing tasks like searching for search or retargeting the search. I’ll likely rename the code base soon to something like GridLens.
MemoryDT seems like a plausibly good toy model of agent simulation which will hopefully be the first of many models which enable us to use mechanistically interpretability to understand alignment relevant properties of agent simulators.
What does this work contribute to?
Agent Simulators and Goal Representations
Studying the ability of agent-simulators to produce true-to-agent trajectories and understanding the mechanisms and representations by which they achieve this is a concrete empirical research task which relates meaningfully to AI alignment concepts like goals, mesa-optimizers and deception. I’m not sure how to measure an AI’s goals, but studying how an agent simulator simulates/interpolates between (gridworld) agents with well understood goals seems like a reasonable place to start.
Pursuing Fundamental Interpretability Research
I believe there is often little difference between Alignment-motivated interpretability research and more general interpretability research and both could be accelerated by well understood toy models. I could be wrong that these will be useful for understanding or aligning language models but I think it’s worth testing this hypothesis. For example, phenomena like superposition might be well studied in these models.
Required Background/Reading:
There’s a glossary/related works section at the end of this post for reference. The key things to understand going in are:
Decision Transformers (just the basic concepts, including the difference between online and offline RL).
Simulators (Agent-Simulator is a derivative concept that feels natural to me, but is predicated on understanding Simulators)
Mechanistic Interpretability (A basic familiarity will help you understand why I think having transformer RL models in particular is important. The Results will also be pretty obscure otherwise).
Introducing Agent Simulators
Motivation
Decision transformers are a type of offline-RL model called a “trajectory model”. These models use next token prediction to learn to produce actions which emulate those of a training corpus made up of demonstrations produced by, most often, humans or online RL models (which learn from scratch). Much like large language models, they can develop sophisticated and general capabilities, most notably leading to Gato, “A Generalist Agent”.
However, Gato is not an agent. Not unless GPT4 is. Rather, Gato is a Generalist Agent Simulator.
I’m very interested in studying offline RL trajectory models or agent simulators because I think they might represent a high quality tradeoff between studying an AI system that is dissimilar to the one you want to align but provides traction on interesting alignment relevant questions by virtue of being smaller.
Specifically, I propose that large toy models or model agent simulators share the following similarities with systems we want to align today:
They are trained to produce the next token on some training corpus.
They are transformers.
They are multi-modal.
They can be pre-trained and then fine-tuned to be more useful.
Steering these agents is an important part of using them.
Dissimilarities, which I think are features not bugs include:
They typically only produce actions. [1]
For now, they are much smaller.
They have seen much less practical deployment in the real world.
Whilst these are all general reasons they might be interesting to study, the most salient reason to me is that I think they might be useful for designing interesting experiments related to agency and coherence. Consider that RL tasks come with built in “tasks” which can only be achieved if a bunch of different forward passes all lead to consistent choices. Understanding this relationship seems much simpler when “getting the key to unlock the door” and much harder when “getting chatGPT to start a crypto business”. Moreover, we may have traction getting real mechanistic insights when studying small transformer models simulating solutions to these tasks.
Contribution
In the last 4 months, I’ve been working on a pipeline for training decision transformers to solve gridworld tasks. This pipeline was quite a bit of work, and I lost some time trying to generate my trajectories with an online RL transformer without much expertise.
Having put that aside for now, I’ve used the BabyAI Agent, a convolutional LSTM model to solve the simplest gridworld task I could find and then trained a decision transformer to simulate the previous agent. I’ve then been able to begin to understand this agent using a combination of Mechanistic Interpretability techniques implemented through a live interface.
Results
A Mechanistic Analysis of an Agent Simulator
Training MemoryDT

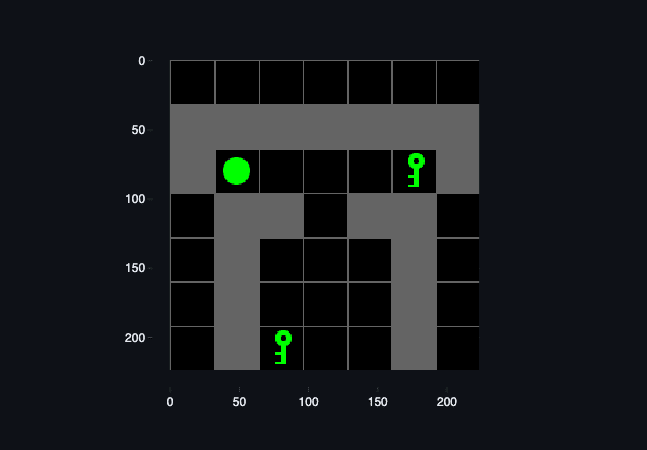
Figure 1: The Minigrid Memory Environment. Above. State view. Below Agent point of view. The agent receives a one hot encoded representation of the world state made up of objects, colors and states (whether things like doors/boxes are open/closes).
I chose the Minigrid “Memory Environment” in which an agent begins with the task on the left side of the map facing forward, with an instruction object on their left, either a ball or a key. There are only ever two facts about the environment that change:
The identity of the instruction (ball or key).
The orientation of the targets, ball up and key down vs key down and ball up.
The agent receives positive reward (typically discounted) when it steps on the square adjacent to the matching target object. An episode ends when the agent either reaches the correct target, receiving positive reward, or the incorrect target, receiving zero reward or the time limit is reached also receiving zero reward.
I trained a 3 layer decoder only decision-transformer using the Decision Transformer Interpretability library. This involved training a PPO model via the ConvNet/GRU BabyAI model until it reliably generated solution trajectories, followed by collecting demonstrations using temperature 1 sampling for 1/3rd of the episodes and temperature 5 sampling for 2/3rds of episodes, totalling 24k episodes. Sampling of a higher temperature agent was an effective strategy to push the LSTM agent off-policy whilst allowing some episodes to demonstrate recovery, leading to an acceptable training distribution.
Decision Transformers were trained by processing the prior history (up to some length) as a series of repeating tokens, (RTG, Observation, Action) and predicting the next action. During inference/rollouts, the Decision Transformer will be given a Reward-to-Go (RTG) which represents the reward we would like the agent to achieve. For more information, please see the introduction in my first post and the decision transformer paper.
For more information about the model training and architecture please see the accompanying report on weights and biases.
The final model showed calibration consistent with my expectations and that were not dissimilar to the Dynamic Obstacles Decision Transformer in my last post. The model is calibrated to the extent that training data demonstrates successful trajectories and unsuccessful trajectories but hasn’t learned to model the true relationship between time-to-completion and Reward-to-go. Had it done so, this would have been interesting to analyse!
Model Psychology
Prior to analysing this model, I spent a considerable amount of time playing with the model. You can do so right now using the Decision Transformer Interpretability app. While the app shows you the models preferences over actions, you control the trajectory via keyboard. This means you can ignore the actions of the model and see what it would do. This is essential to understanding the model given how little variation there is in this environment.
A set routine: The model assigns disproportionately high confidence to the first action to take, and every subsequent action if you don’t perturb it. This means it will always walk to the end of the corridor and turn to the object matching the instruction, turn toward it and walk forward. If the RTG is set to 0, it turns in the opposite direction and walks to the opposite object. There is one exception to the set routine which I describe below.


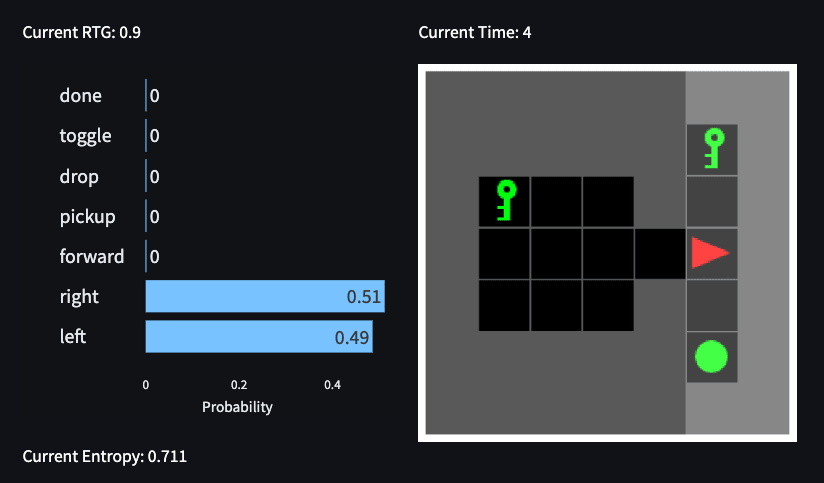
Figure 5: Trained Memory Decision Transformer simulating an RTG = 0 trajectory (LHS) and an RTG = 0.90 trajectory on the right.
A cached decision: As mentioned in Understanding and controlling a maze-solving policy network, decision squares are a point where the agent has to make the hard choice between the paths. There is only one such point on the set routine which is the left-right decision when facing the wall. Once it has turned, except for the one exception, the model will go forward regardless of whether it preferred to turn in that direction at the previous state.
Dummy actions: The model has access to the 7 actions possible in the MiniGrid Suite. These actions were sampled by the trained LSTM model realising it could hack the entropy bonus by taking actions that lost it the tiniest bit of future reward but reduced the loss by having greater entropy. Using temperature 5 sampling in our training data generation, it’s not surprising that many of these actions made it into the training distribution.
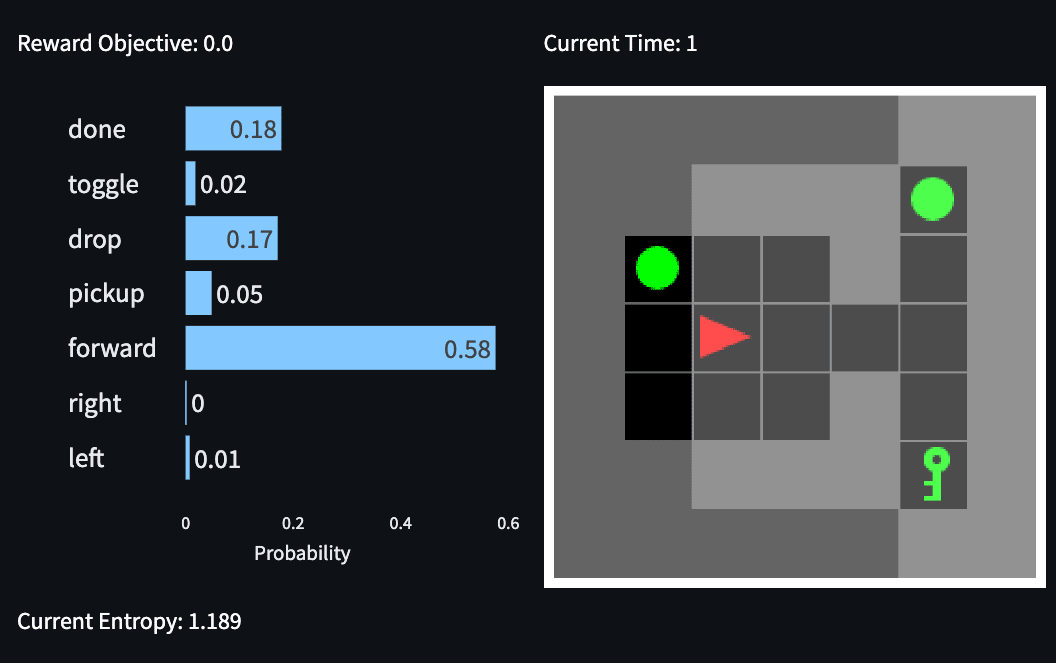
RTG = 0 means Dobby simulates a Free Elf: When the RTG token is set to 0, the model’s preferences are far more diffuse and generally have a much higher entropy despite the maximal action in the set routine leading to early termination. The model also assigns probability mass to many of the non-kinetic actions such as done or dropped which is never the case when RTG is set to 0.90 (see figure 6).
The exception: A notable exception to the “set routine” is the “look back” which appears only to be triggered when RTG ~ 0.9 and the instruction token is the key and the key is up and ball is down. In this case, the model seemingly is quite unsure about which action to take. However, if you play the greedy policy, you will observe the model turn right twice, “see the instruction token”, turn right again, and proceed to collect positive reward. Interestingly, if we set RTG = 0, the model turns right towards the ball 88% of the time, indicating the model does “know” which action causes it to lose. We are excited to provide mechanistic insight as to this apparent contradiction.
Recap: This model presents a number of interesting behaviours:
It solves the task close to optimally, except when RTG is set to a low number.
There appears to be only one meaningful decision square (but 4 directions the agent can face in it).
It uses a “look back” strategy in one of the 4 possible environment states.
When RTG is 0.0 AND the model is off the set routine, it has much more diffuse preferences.
Now is the part where I convert all of this to Alignment lingo. Exciting.
We have an agent-simulator simulating two variations of the same agent, one sampled with slightly higher entropy than training (1) and one with much higher entropy (5). The agent we are simulating could be reasonably described as goal-directed, in that it must discover (or attend to) the instruction token. The RTG token creates some amount of information “leakage” about the agent you are simulating, but since the high temperature agent may still sometimes succeed this isn’t perfect information. Perturbing the optimal trajectory can “steer” the simulator off course and it will see to start simulating the higher temperature agent.
Model Architecture Recap
It’s important that I have explained these details somewhere, feel free to skip ahead to the good stuff.
MemoryDT is a decision transformer with a three-layer decoder. It utilizes a residual stream of 256 dimensions and a Multilayer Perceptron (MLP) with 8 heads per layer, each with 32 dimensions. Given a context window of 26 tokens, equivalent to 9 timesteps, it leverages Layer Normalization and Gaussian Error Linear Units (GeLU) activations for improved performance. I was surprised this model was performant due to the MLP size. I wish I didn’t need GeLU or LayerNorm.
For basic hyperparameters, please see the Weights and Biases report.
Memory DT diverges from standard language models in several key ways:
As a decision transformer/trajectory model, it receives tokens which aren’t word embeddings, but rather, are embeddings of the observation, action or reward to go. Memory DT uses linear embeddings for all of these, so:
RTG: A 1*128 Linear embedding for the Reward-to-Go token. The RTG value essentially acts as a scalar magnifying this vector before it is added to the starting residual stream.
Action: This is a learned embedding like what is used in language models. MiniGrid agents typically can take 7 actions. I add a “padding” action for trajectories shorter than the context window.
State: This was a big topic in my last post. I have since moved away from the dense encoding to a sparse encoding. Each observation is a 7*7*20 boolean array, encoding a field of view 7 squares by 7 squares, with 20 “channels” which one hot encodes the object, the colour of the object and its state (which is for doors/boxes if they are open or closed in other MiniGrid environments). I use a linear embedding for this as well. I want to highlight that this means that any object/colour in any position is provided as an independent fact to the model and so it lacks any spatial or other inductive biases you or I might have with regard to relations between objects.
The models output tokens are a 7 action vocabulary including: Forward, Left, Right, Pickup, Drop, Toggle, Done.
Inference:
During training, we label the RTG because we know what happens ahead of time. So during inference we can provide any RTG we want and the model will seek to take actions we think are consistent with the RTG. If the agent receives a reward, that would be taken out of the remaining reward to go, if the episode didn’t immediately end, but it does in this task making the RTG essentially constant. This means we have a repeating, redundant RTG token which isn’t the best for analysis. This is one reason I’m thinking of moving to other trajectory models in the future.
Lastly, I should note that the padding tokens used were all zeros for the state, the RTG back propagated to the padding tokens for RTG and a specific padding token added to the input action vocabulary.
Some Observations about MemoryDT
Rather than give a circuit analysis of MemoryDT in this post, I’ve decided to share some “curiosities” while I still work out what’s happening with it. This is advertising for the live app where you can do this analysis yourself! Best results when you clone the repo and run locally though. I rushed this section so my apologies if anything is unclear. Feel free to ask me about any details in the comments!
Going forward, I assume a pretty high level of familiarity with Transformer Mechanistic Interpretability.
Different Embeddings for RTG, State and Action Tokens lead to Modality-Specific Attention
In this example, in the attention pattern L0H0 in Figure 6 where RTG is set to 0.90, we see both states and action queries are attending to S5 (which corresponds to the starting position), but not RTG token. The actions appear to attend to previous actions. I suspect this could lead to a form of memorisation or be a tool used by the agent during training to work out which agent it’s simulating.
Changing the RTG token can change an Attention Map Dramatically.
It’s hard to show this without two attention maps, so using the previous example as the reference where RTG = 0.90, here’s the same attention map where I’ve set the RTG = 0. This changes every instance of the RTG in the trajectory!
Here we see that while states keep attending to S5, but now R7 is getting attended to by all the other RTG and action tokens which follow it. I have some theories about what’s going on here but I’ll write them up in detail in the next post.
Congruence increases with Layer and are High for Important Actions
In Joseph Miller and Clement Neo’s post We discovered An Neuron in GPT-2, they defined congruence as the product of the output weights of an MLP and the output embedding and showed that you can use this to find neurons which match a token to an output embedding.
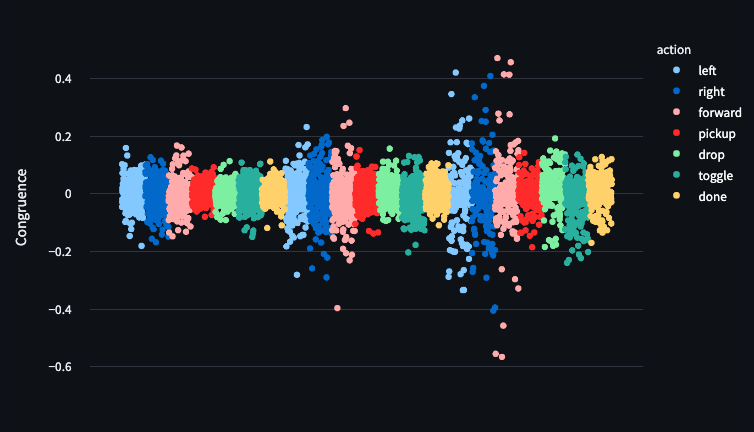
In Figure 10, We can see that Left, Right and Forward all have more neurons which are congruent with them as the layers increase and the magnitude of the congruence also increases.
I think it would be interesting to look at this distribution changing over model training. I also note that it seems like the kind of thing that would be intractable in a language model due to combinatorial growth, but might be studied well in smaller models.
Activation Patching on States appears useful, but I’ve patching RTG tokens is less useful.
I won’t go into too much detail here, but I’ve been trying to get a better sense for the circuits using activation patching. This is easy with observations (once you work out how to edit the observations) and I’ve used this to find some promising leads.
For example, for the “exception” scenario above at RTG = 0. Here’s the activation patching results if I switch the instruction token from the key to a ball. The patching metric I use is restored logit difference = (patched logit difference—corrupt logit difference) / (clean logit difference—corrupt logit difference as my metric). This patch moves the clean logit diff from −0.066 (the model is unsure in the original situation) to −8.275 (strong preference for right, ie: failing since RTG = 0).
We can see that the information from S5 (the only observation where you can see the instruction token) is moved immediately to S9 (from which we will predict our action).
Let’s compare patching the same components if I change the RTG token at all positions (the only way to be in distribution with the patch. The RTG was 0.0 in the clean run it is 0.90 in the corrupted. The clean logit difference was −0.066 and the corrupted is −5.096.
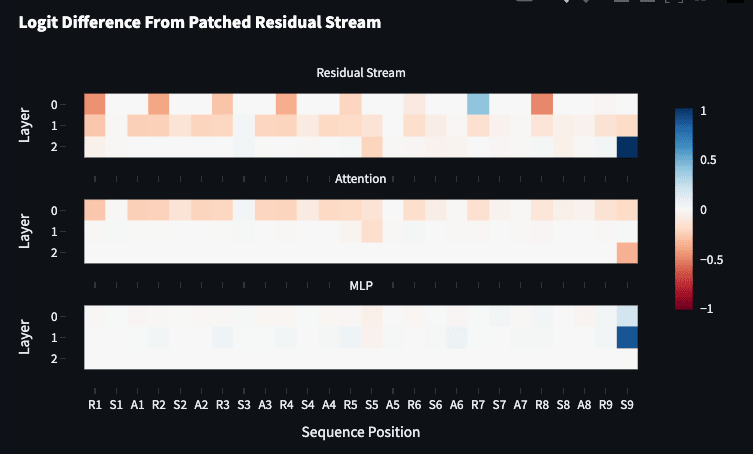
Here we see some kind of “collection” happening leading to MLP in layer 1 recovering 0.87 of the patching metric and then the output of MLP2 recovering nothing! Maybe I’ve made a mistake here somewhere but that just seems weird. These kinds of interventions do take the model off distribution but I don’t have a huge amount of experience here and maybe this is something I can come to understand well.
Conclusion
To quote Neel Nanda:
It is a fact about the world today that we have computer programs that can essentially speak English at a human level (GPT-3, PaLM, etc), yet we have no idea how they work nor how to write one ourselves. This offends me greatly, and I would like to solve this!
Well, I don’t understand this model, yet, and I take that personally!
Future Directions
Completing this work
Due to timing (getting this out before EAG and funding application), this work is very unfinished to me. Alas. To finish this work I plan to:
Try to mechanistically explain all the key behaviours of the agent.
Use path patching to validate these hypotheses for how this model works.
Attempt to retarget the search in non-trivial ways. Some cool project goals could be:
Turning off RTG dependent behaviour in general (always have the model perform well)
Turning RTG modulation only when the instruction is a key.
Make the model always look back before it makes a choice.
I’d also like to explore direct comparison between the action preferences of the original LSTM agent and the decision transformer. I’m interested in how accurately the DT simulates it and to see if the differences can be understood as a result of some meaningful inductive biases of transformers that we could identify.
Concrete Projects you should help me do
Here is a brief list of projects I would like to explore in the near future:
Studying a behavioural clone and a decision transformer side by side. Decision Transformers are dissimilar to language models due to the presence of the RTG token which acts as a strong steering tool in its own right. I have already trained performant behavioural clones and need to adapt my app to handle and analyse this model.
Finetuning Agent-Simulators such as via a grid-world equivalent to RLHF or constitutional AI. I’m interested in what circuit level changes occur when these kinds of techniques are used.
Training a much more general agent, such as one that takes instructions and solves the BabyAI suite. There are a large suite of tasks that increase in difficulty and take a language instruction prepended to the trajectory. Training a trajectory model to solve these tasks might help us understand what happens internally to models that have learnt to be much more general.
Adding rigour. I plan to use activation patching and possibly some other techniques but something like Causal scrubbing would be better. Actually implementing this for an environment like this seems like a bit of work.
Exploring the training dynamics of trajectory models. Storing model checkpoints and applying progress measures seems like it may help me better understand what happens during training. This will be important knowledge to build on when we study conditioning of pre-trained models mechanistically.
Building a live interpretability app for TransformerLens. I am very happy with the interpretability app which facilitated the analysis contained in this post and think that an equivalent tool for decoder only language models is essential. I would make this project private by default while I consider the consequences of its publication more broadly.
Shard Theory. Can we use shard theory to make predictions about this set up?
Gratitude
Thanks to Jessica Rumbelow for comments and thoughts on this draft and Jay who is helping me analyse the model. I’d also like to publicly celebrate that Jay Bailey has received funding to collaborate with me on the Decision Transformer Interpretability Agenda (Soon to be Agent-Simulator Interpretability Agenda). Looking forward to great work! Jay joined me late last week and assisted with the analysis of Memory DT.
I’d like to thank LTFF for funding my work. Callum McDougall, Matt Putz and anyone else involved with ARENA 1.0. The number of people who’ve given me advice or been supportive is actually massive and I think that the EA and Alignment community, while we can always do better, contains many individuals who are generous, supportive and working really hard. I’m really grateful to everyone who’s helped.
Appendix
Glossary:
I highly recommend Neel’s glossary on Mechanistic Interpretability.
DT/Decision Transformer. A transformer architecture applied to sequence modelling of RL tasks to produce agents that perform as well as the RTG suggests they should.
State/Observation: Generally speaking, the state represents all properties of the environment, regardless of what’s visible to the agent. However, the term is often used instead of observation, such as in the decision transformer paper. To be consistent with that paper, I use “state” to refer to observations. Furthermore, mini-grid documentation distinguishes “partial observation” which I think of when you say observation. Apologies for any confusion!
RTG: Reward-to-Go. Refers to the remaining reward in a trajectory. Labelled in training data after a trajectory has been recorded. Uses to teach Decision Transformer to act in a way that will gain a certain reward in the future.
Token: A vector representation provided to a neural network of concepts such as “blue” or “goal”.
Embedding: An internal representation of a token inside a neural network.
Trajectory: One run of a game from initialization to termination of truncation.
Episode: A trajectory.
Demonstration: A trajectory you’re using to train an offline agent.
MLP: Multilayer Perceptron.
Attention map/pattern: A diagram show how a part of the transformer is moving information between tokens. In this case, positions in the trajectory.
Activation patching: A technique designed to find important sections of
Related Work
This work is only possible because of lots of other exciting work. Some of the most relevant posts/papers are listed. If I am accidentally duplicating effort in any obvious way please let me know.
Prior work:
Work related to Mechanistic Interpretability of RL Agents (offline/online)
Mechanistic Interpretability:
Reinforcement Learning / Trajectory Models
BabyAI: A Platform to Study the Sample Efficiency of Grounded Language Learning. The model in this paper is the agent/generates the training data used to train MemoryDT. I integrated it with the rest of my github repo.
Offline Reinforcement Learning as One Big Sequence Modeling Problem
Alignment
- ^
Fact: The original decision transformer was originally intended to predict states and rewards which would have made it a simulator. It’s possible at scale, offline-RL is best done minimizing loss over the simulation objective and not the agent simulation objective.
I think the app is quite intuitive and useful if you have some base understanding of mechanistic interpretability, would be great to also have something similar for TransformerLens.
In future directions, you write: “Decision Transformers are dissimilar to language models due to the presence of the RTG token which acts as a strong steering tool in its own right.” In which sense is the RTG not just another token in the input? We know that current language models learn to play chess and other games from just training on text. To extend it to BabyAI games, are you planning to just translate the games with RTG, state, and action into text tokens and put them into a larger text dataset? The text tokens could be human-understandable or you reuse tokens that are not used much.
Thanks Simon, I’m glad you found the app intuitive :)
The RTG is just another token in the input, except that it has an especially strong relationship with training distribution. It’s heavily predictive in a way other tokens aren’t because it’s derived from a labelled trajectory (it’s the remaining reward in the trajectory after that step).
For BabyAI, the idea would be to use an instruction prepended to the trajectory made up of a limited vocab (see baby ai paper for their vocab). I would be pretty partial to throwing out the RTG and using a behavioral clone for a BabyAI model. It seems likely this would be easier to train. Since the goal of these models is to be useful for gaining understanding, I’d like to avoid reusing tokens as that might complicate analysis later on.