Formalizing Newcombian Problems with Fuzzy Infra-Bayesianism
Introduction
In this post, we introduce contributions and supracontributions[1], which are basic objects from infra-Bayesianism that go beyond the crisp case (the case of credal sets). We then define supra-POMDPs, a generalization of partially observable Markov decision processes (POMDPs). This generalization has state transition dynamics that are described by supracontributions.
We use supra-POMDPs to formalize various Newcombian problems in the context of learning theory where an agent repeatedly encounters the problem. The one-shot version of these problems are well-known to highlight flaws with classical decision theories.[2] In particular, we discuss the opaque, transparent, and epsilon-noisy versions of Newcomb’s problem, XOR blackmail, and counterfactual mugging.
We conclude by stating a theorem that describes when optimality for the supra-POMDP relates to optimality for the Newcombian problem. This theorem is significant because it gives a sufficient condition under which infra-Bayesian decision theory (IBDT) can approximate the optimal decision. Furthermore, we demonstrate through the examples that IBDT is optimal for problems for which evidential and causal decision theory fail.
Fuzzy infra-Bayesianism
Contributions, a generalization of probability distributions, are defined as follows.
Definition: Contribution
A contribution on a finite set is a function[3] such that The set of contributions on is denoted by .
Given we write to denote A partial order on is given by if for all subsets For example, the constant-zero function 0 is a contribution that lies below every element in in the partial order. A set of contributions is downward closed if for all implies Given the downward closure of in is defined by
Figure 1 illustrates a set of contributions together with its downward closure.
The set of contributions shown in Figure 1 together with its downward closure is an example of a supracontribution, defined as follows.
Definition: Supracontribution
A supracontribution on is a set of contributions such that
,
is closed,
is convex, and
is downward closed.
The set of supracontributions on is denoted by .
Figure 2 shows another example of a supracontribution.
Supracontributions can be regarded as fuzzy sets of distributions, namely sets of distributions in which membership is described by a value in rather than In particular, the membership of in is given by
where denotes the scaling of by See Figure 3 for two examples. Note that is well-defined since all supracontributions contain 0. By this viewpoint, supracontributions can be seen as a natural generalization of credal sets, which are “crisp” or ordinary sets of distributions.
There is a natural embedding of credal sets on into the space of supracontributions on Let Define Note that under this definition, (and otherwise the union with in the definition of is redundant).
Generalizing the notion of expected value, we write We define expectation (similarly as in the crisp case) as the max over all expectations for elements of the supracontribution. By definition, a supracontribution is closed and thus this notion of expectation is well-defined.
Definition: Expectation with respect to a supracontribution
Given a continuous function and define the expectation of with respect to by
Let denote a non-empty set of contributions. Then where denotes convex hull and denotes closure. Therefore, in the context of optimization we may always replace a non-empty set of contributions by the supracontribution obtained by taking the convex, downward, and topological closure.
Recall that environments in the classical theory and in crisp infra-Bayesianism have type We generalize this notion to the fuzzy setting using semi-environments.[4]
Definition: Semi-environment
A semi-environment is a map of the form
The interaction of a semi-environment and a policy determines a contribution on destinies [5]
Definition: (Fuzzy) law
A (fuzzy) law generated by a set of semi-environments is a map such that for all where denotes convex hull and denotes closure.
Fuzzy Supra-POMDPs
Our tool for formalizing Newcombian problems using the mathematical objects described in the last section is fuzzy supra-POMDPs, a generalization of partially observable Markov decision processes (POMDPs). Given a set of states and a contribution the missing probability mass, can be interpreted as the probability of a logical contradiction.
Under a fuzzy supra-POMDP model, uncertainty of the initial state is described by an initial supracontribution over states. Similarly to the state transition dynamics of a crisp supra-POMDP as defined in the preceding post, the state transition dynamics of a fuzzy supra-POMDP are multivalued. Given a state and action, the transition suprakernel returns a supracontribution, and the true dynamics are described by any element of the supracontribution.
A significant feature of fuzzy supra-POMDPs is that for some state and action we may have which corresponds to a logical contradiction in which the state transition dynamics come to a halt. We use this feature to model Newcombian problems where it is assumed there is a perfect predictor Omega predicting an agent’s policy. When an action deviates from the predicted policy (which is encoded in the state), the transition kernel returns
We formally define fuzzy supra-POMDPs as follows.
Definition: Fuzzy supra-POMDP
A fuzzy supra-partially observable Markov decision process (supra-POMDP) is a tuple where
is a set of states,
is an initial supracontribution over states,
is a set of actions,
is a set of observations,
is a transition suprakernel,[6]
is an observation mapping.
Defining laws from fuzzy supra-POMDPs
Every fuzzy supra-POMDP defines a (fuzzy) law. The construction is similar to the construction of a crisp law given a crisp supra-POMDP, which is discussed in the preceding post. A copolicy to a fuzzy supra-POMDP is a map that is consistent with the transition suprakernel. More specifically, given a history of states and actions, the transition kernel determines a supracontribution from the most recent state and action. The copolicy can be thought of as a map that selects a contribution from that supracontribution.
Definition: Copolicy to a fuzzy supra-POMDP
Let be a fuzzy supra-POMDP. A map is an -copolicy if
- for the empty string and
For all non-empty strings , .
An -copolicy and the observation map of together determine a semi-environment Let
Then defines the law generated by
Formalizing Newcombian problems
In this section, we give a mathematical definition for Newcombian problems and describe how to model Newcombian problems using fuzzy supra-POMDPs.
Let denote a set of observations. Given a time-horizon let denotes strings in of length less than Let denote the set of horizon- policies, i.e. maps of the form
Definition: Newcombian problem with horizon
A Newcombian problem with horizon is a map together with a loss function
Intuitively speaking, given a policy and a sequence of observations, a Newcombian problem specifies some distribution that describes uncertainty about the next observation. This framework allows for a mathematical description of an environment in which there is a perfect predictor Omega and a distribution over observations that depends on the policy that Omega predicts.
Optimal policy for a Newcombian problem
Similar to how the interaction of a policy and an environment produce a distribution over destinies, a Newcombian problem and a policy together determine a distribution on outcomes, The policy that minimizes expected loss with respect to this distribution is said to be a -optimal policy.
Definition: Optimal policy for a Newcombian problem
A policy is optimal for a Newcombian problem if .
If is optimal for then is said to be the optimal loss for
Formalism for multiple episodes
In order to discuss learning, we consider the case of multiple episodes where an agent repeatedly encounters the Newcombian problem.
Given some number of episodes let denote the set of multi-episode policies. A multi-episode policy gives rise to a sequence of single-episode policies
By means of this sequence of single-episode policies, a Newcombian problem and a multi-episode policy together determine a distribution on outcomes over multiple episodes, which we also denote by
The loss function can be naturally extended to multiple episodes by considering the mean loss per episode. In particular, if and is given by then the mean loss over episodes is defined as
It is also possible to extend the loss to multiple episodes by considering the sum of the per-episode loss with a geometric time discount. In this case, the total loss is defined by
The fuzzy supra-POMDP associated with a Newcombian problem
In this section, we describe how to model iterated Newcombian problems (i.e. repeated episodes of the problem) by a fuzzy supra-POMDP. We work in the iterated setting since this allows us to talk about learning. Examples are given in the following section.
The state space, initialization, and observation mapping
Let (together with ) be a Newcombian problem. Let Informally speaking, the state always encodes both a policy and a sequence of observations.
Let the initial supracontribution over states be where denotes the empty observation. This supracontribution represents complete ambiguity over the policy (and certainty over the empty observation).
The observation mapping simply returns the most recent observation datum from a state, i.e. for non-empty observation strings. If the observation string of the state is the empty string then may be chosen arbitrarily.
The transition suprakernel
We start with an informal description of the transition suprakernel which is defined in three cases. In short:
If the action is compatible with the policy encoded by the state, then is determined by
If the action is not compatible with the policy encoded by the state, then returns
If the end of the episode is reached, then returns
To elaborate, we have the following three cases.
The action is compatible with the policy encoded by the state, and the time-step is less than the horizon, i.e. the episode is not yet complete. In this case, the policy datum of the state remains the same with certainty, whereas determines a distribution over next observations. This distribution determines a distribution over next states. The transition suprakernel returns the downward closure of this distribution. (Here the downward closure is used simply to obtain a supracontribution.)
The action is not compatible with the policy encoded by the state, and the time-step is less than the horizon. This case is a logical contradiction, and thus returns
The time-step is equal to the horizon, i.e. the end of the episode has been reached. The transition suprakernel returns the initial supracontribution again, which represents complete ambiguity over the policy for the next episode (and certainty over the empty observation).
We now formally define Given such that define by . Namely, appends a given observation to the prefix of observations and returns the corresponding state. Let denote the pushforward of
Define
Examples of Newcombian problems
In this section, we explain how to formalize various Newcombian problems using the fuzzy supra-POMDP framework. We provide the most detail for the first two examples
Newcomb’s Problem
We first consider Newcomb’s Problem. In this problem, there are two boxes: Box A, a transparent box that always contains $1K, and Box B, an opaque box that either contains $0 or $1M. An agent can choose to “one-box”, meaning that they only take Box B, or “two-box”, meaning they take both boxes. A perfect predictor Omega fills Box B with $1M if and only if Omega predicts that the agent will one-box.
Evidential decision theory (EDT) prescribes that an agent should choose the action that maximizes the expected utility conditioned on choosing that action. Thus, EDT recommends one-boxing because choosing to one-box can be seen as evidence that Box B contains $1M. This is the case even though the correlation is spurious, i.e. choosing to one-box does not cause there to be $1M in Box B. We will see that IBDT also recommends one-boxing. In comparison to EDT, causal decision theory (CDT)[7] prescribes that an agent should only take into account what an action causes to happen and therefore recommends two-boxing.
Let where denotes the empty observation and the remaining observations represent the total amount of money received.
Let where corresponds to one-boxing and corresponds to two-boxing. Without loss of generality, where and
Then is defined by
The loss of an episode is defined by
(We don’t define for because under this model, this observation never occurs.)
Note that and Therefore, is optimal.
We now consider the corresponding supra-POMDP The transition suprakernel is given by
Figure 5 shows the state transition graph of Notably, it is not possible under for an agent to two-box when Box B is full (the left branch in Figure 5). This is assured by the fact that
The interaction of and produces a supracontribution over outcomes given by Similarly, the interaction of and produces the supracontribution
Then the expected loss for in one round is
Similarly, the expected loss for in one round is
From another viewpoint, the optimal (worst-case from the agent’s perspective) copolicy to initializes the state to for i.e. In other words, the policy encoded in the state chosen by the copolicy matches the policy of the agent. The law defined by this supra-POMDP is equivalent to an ordinary environment in which one-boxing results in observing a full box and two-boxing results in observing an empty box.
We see from the above calculations that the optimal policy for is and moreover achieves the -optimal loss. This analysis holds for any number of episodes. This is significant because if a learning agent has in their hypothesis space, then they must converge to one-boxing if they are to achieve low regret for the iterated Newcomb’s problem.
Note that for this example, we have only used what might be considered the most basic supracontributions, namely and the downward closure of a single probability distribution. In the next example, we will see the full power of supracontributions.
XOR Blackmail
In this section we describe how to use a supra-POMDP to model the XOR blackmail problem. For a more in depth discussion of XOR blackmail, see e.g. Toward Idealized Decision Theory §2.1 (Soares and Fallenstein, 2015) and Cheating Death in Damascus §2 (Levinstein and Soares, 2020).
The problem is given as follows. Suppose there is a 1% probability that an agent’s house may have a termite infestation that would cause $1M in damages. A blackmailer can predict the agent and also knows whether or not there is an infestation. The blackmailer sends a letter stating that exactly one of the following is true, if and only if the letter is truthful:
There are no termites, and you will pay $1K, or
There are termites, and you will not pay.
The agent can then accept or reject the blackmail. Note that as stated, the probability of blackmail depends on the agent’s policy. Because policies are encoded in the state space of the associated supra-POMDP, we are able to model this. EDT recommends accepting the blackmail because accepting blackmail is evidence that there is not an infestation, even though this correlation is spurious (i.e. accepting the blackmail does not causally influence whether or not there is an infestation). On the other hand, CDT recommends rejecting the blackmail. Thus we see that these two decision theories are split across the two examples that we have seen so far and neither always recommends an optimal action. We now see that IBDT does recommend the optimal action again.
Let where denotes the empty observation, represents receiving the blackmail, represents not receiving the blackmail, and the remaining observations represent the various monetary outcomes.
Let where corresponds to accepting the blackmail and corresponds to rejecting the blackmail. Without loss of generality, where and
Interpreting the statement of the problem, we define as follows:
We normalize in order to define the loss of an episode by
Note that whereas Therefore is optimal.
We now consider the corresponding supra-POMDP The state transitions of are summarized in Figure 6. We first define the transition suprakernel on Using we have
We now consider the next level of the supra-POMDP. Since
Here we see that when the action is , which is consistent with the policy of the state , the transition kernel returns the downward closure of a distribution specified by On the other hand, when the action is , which is not consistent with , the transition kernel returns .
The action does not matter when there is no blackmail (i.e. both actions are consistent with the policy), so
A similar analysis for yields
Then on the final level: for all define
We now consider the expected loss of each policy for The interaction of and produces a supracontribution over outcomes given by where
Here, arises from the interaction of with the branch starting with state We have a probability distribution in this case because is always consistent with itself, which is the policy encoded in the states of this branch. On the other hand, the contribution arises from the interaction of with the branch starting with state In the case of blackmail, and disagree on the action and thus a probability mass of 0.01 is lost on this branch.
Therefore, the expected loss for in one round is given by
Another way to view this calculation is that the optimal -copolicy initializes the state to meaning
By a similar calculation,
Therefore, the optimal policy for is also , i.e. under this formulation it is optimal to reject the blackmail. This analysis holds for any number of episodes. Moreover, the optimal loss for is equal to the optimal loss for This is significant because if a learning agent has in their hypothesis space, then they must converge to rejecting the blackmail if they are to achieve low regret for the iterated Newcombian problem.
Counterfactual Mugging
We now consider the problem of counterfactual mugging. In this problem, a perfect predictor (the “mugger”) flips a coin. If the outcome is heads, the mugger asks the agent for $100, at which point they can decide to pay or not pay. Otherwise, they give the agent $10K if and only if they predict the agent would have paid the $100 if the outcome was heads.
Both CDT and EDT recommend not paying, and yet we will see that IBDT recommends to pay the mugger.
Let where represents heads, represents tails, and the remaining (non-empty) observations represent the various monetary outcomes. Let where represents paying the mugger and represents not paying the mugger. Without loss of generality, where and
Let . We normalize[8] to define the loss of an episode by
Note that whereas Therefore, is -optimal.
The state transitions of are shown in Figure 7.
We have
whereas
Therefore, the optimal policy for is also , i.e. under this formulation it is optimal to pay the mugger.
Transparent Newcomb’s Problem
We now consider Transparent Newcomb’s Problem. In this problem, both boxes of the original problem are transparent. We consider three versions. See Figure 11 in the next section for a summary of the decision theory recommendations.
Empty-box dependent
In the empty-box dependent version, a perfect predictor Omega leaves Box B empty if and only if Omega predicts that the agent will two-box upon seeing that Box B is empty.
Let Here corresponds to observing an empty box and corresponds to observing a full box. Let where corresponds to one-boxing and corresponds to two-boxing.
Without loss of generality, where and for Namely, the policies are distinguished by the action chosen upon observing an empty or full box.
Let . Define by
The state transition graph of the supra-POMDP representing this problem is shown in Figure 8.
We now consider the expected loss in one round for each policy interacting with Similarly to the original version of Newcomb’s problem, the optimal copolicy to a policy initializes the state to , meaning the policy encoded in the state chosen by the copolicy matches the true policy of the agent.
We have
Therefore, the optimal policy for is meaning it is optimal to one-box upon observing an empty box and to two-box upon seeing a full box. Note that is also the -optimal policy.
Full-box dependent
In the full-box dependent version, Omega (a perfect predictor) puts $1M in Box B if and only if Omega predicts that the agent will one-box upon seeing that Box B is full. This example does not satisfy pseudocausality (discussed below), and therefore we will see that there is an inconsistency between the optimal policies for the supra-POMDP and the Newcombian problem
Let and Without loss of generality, we again have where and for
The state transition graph of the supra-POMDP representing this problem is shown in Figure 9.
Define by
Then
Furthermore,
Therefore, the optimal policies for the supra-POMDP are and From another perspective, the optimal copolicy to for initializes the state to . The optimal copolicy to for initializes the state to . As a result, an agent can achieve low regret on and either one- or two-box upon observing the full box. In particular, for all policies they will learn to expect an empty box.
On the other hand, the optimal policies for the Newcombian problem are and . To see this, note that and Then whereas and The inconsistency between the optimal policies for and is a result of the fact that this Newcombian problem fails to satisfy pseudocausality, a condition we describe in the last section.
Epsilon-noisy full-box dependent
We now consider a variant of the full-box dependent version in which we assume that Omega is not a perfect predictor. In this case, Omega also puts $1M in Box B with probability when the agent will two-box upon seeing that Box B is full.
Figure 10 shows the state transitions starting from states and (The full state transition graph is the graph in which the the two right-most paths of the graph of Figure 9 are replaced by the trees in Figure 10.)
Let and Define by
A distinguishing feature of the supra-POMDP for this problem (compared to the other problems we have considered) is that the optimal policy for depends on the number of episodes. In the case of one episode, the optimal copolicy to and is the same. Namely, Then the expected loss for one episode is
We consider the extension of given by the mean per-episode loss. For two episodes, the optimal copolicy to and again has The interaction of and produces a supracontribution over given by where [9] and Then the expected mean loss for over two episodes is
On the other hand, the interaction of and produces a supracontribution over given by where is defined by
Then
More generally, for any number of episodes, the worst-case copolicy to has As a result, for all
On the other hand, over episodes, the copolicy to that always has results in an expected mean loss of which tends to zero as The copolicy to that instead has on most episodes results in a mean expected loss that converges to Therefore, for sufficiently many episodes, is the optimal policy for and moreover the optimal loss for converges to the optimal loss for
Summary of decision theory recommendations
In Figure 11, we summarize the extent to which each decision theory makes optimal recommendations on the example problems.
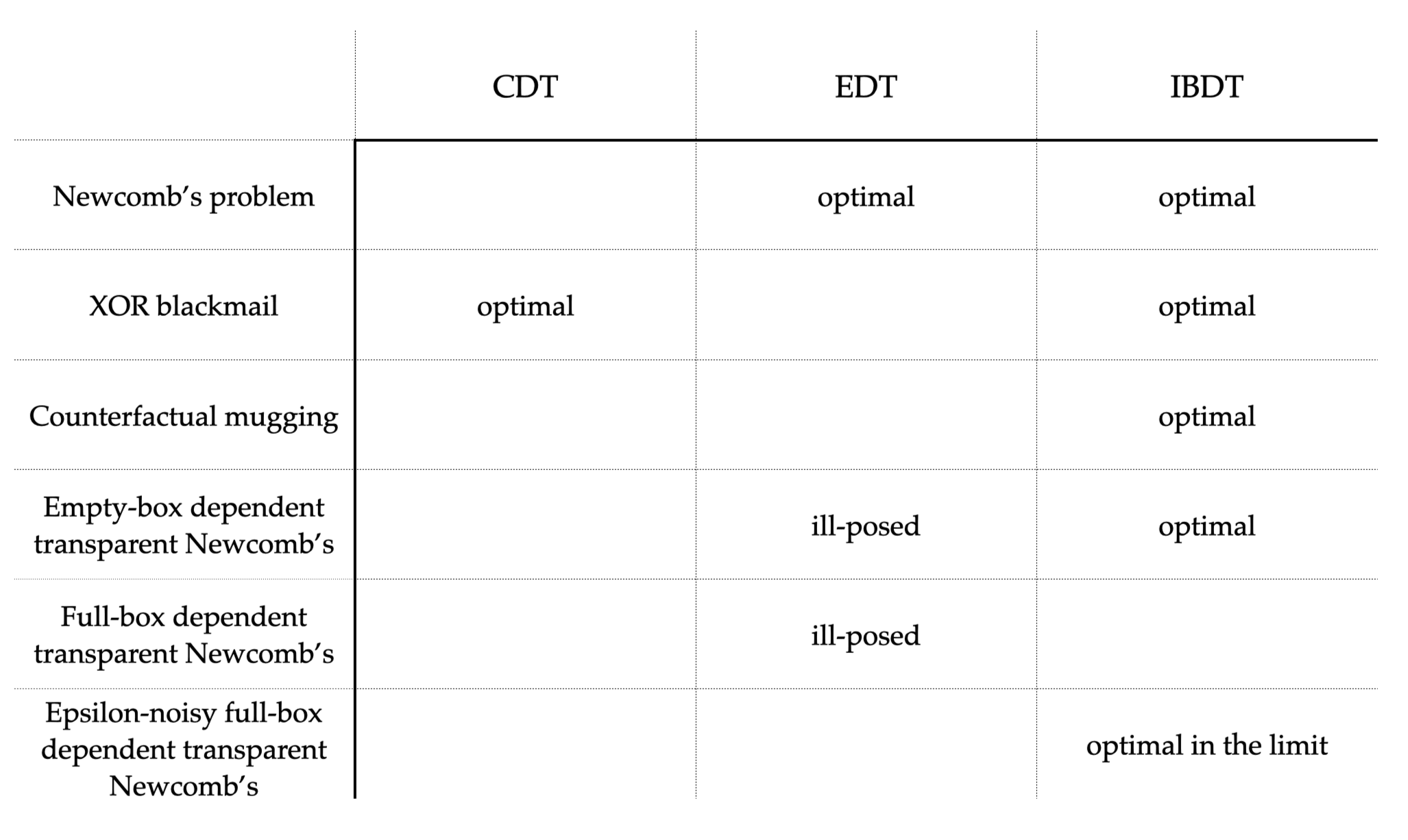
Readers familiar with decision theory will observe that IBDT can be seen as an approximation to functional decision theory, which makes optimal recommendations across all the examples here. IBDT has the advantage of being well-defined in the sense that it can be run as code in an agent learning from the environment.
Pseudocausality
In this section, we define a condition (pseudocausality) that holds for all of the Newcombian problems discussed above, except for the (non-noisy) full-box dependent transparent Newcomb’s problem. We then state a theorem that illuminates the significance of this condition. In particular, pseudocausality allows one to translate optimality from the supra-POMDP to optimality for the corresponding Newcombian problem Intuitively, pseudocausality means that there does not exist a suboptimal policy for such that the optimal policy and the suboptimal policy disagree only on events that are probability zero under the suboptimal policy.
To formally define pseudocausality, we consider the set of outcomes that are compatible with a given policy Namely, define
In other words, if the sequence of actions in agrees with whereas the observations can be arbitrary.
Definition: Pseudocausality
A Newcombian problem satisfies pseudocausality if there exists a -optimal policy such that for all if then is also optimal for
An example where pseudocausality fails
To see why pseudocausality fails for the full-box dependent transparent Newcomb’s problem, recall that the optimal policies for are and We have
and
However,
and
but and are not optimal for
We leave it to the reader to check that all other examples discussed in this post satisfy pseudocausality.
Theorem on pseudocausality and optimality
The significance of pseudocausality is given by the next theorem. It states that if pseudocausality holds for a Newcombian problem , then the optimal loss for the corresponding fuzzy supra-POMDP converges to the optimal loss for the Newcombian problem. Furthermore, given a time discount if a indexed family of policies is optimal for in the limit, then the family is also optimal for in the limit.
Theorem [Alexander Appel (@Diffractor), Vanessa Kosoy (@Vanessa Kosoy)]:
Let be a Newcombian problem that satisfies pseudocausality. Then
Furthermore, if is a family of policies such that then
See the proof section for the proof.
Acknowledgements
Many thanks to Vanessa Kosoy, Marcus Ogren, and Mateusz Bagiński for their valuable feedback on initial drafts. Vanessa’s video lecture on formalizing Newcombian problems was also very helpful in writing this post.
- ^
Previously called ultracontributions.
- ^
To make comparisons, we briefly review these decision theories, but this is not the focus of the post.
- ^
More generally, if is a measurable space, we define a contribution to be a measure such that
- ^
This terminology is motivated by the notions of semimeasures and semi-probabilities as discussed in An Introduction to Universal Artificial Intelligence (M. Hutter, D. Quarel, and E. Catt).
- ^
Here it is necessary to use the more general definition of a contribution as a measure.
- ^
Here suprakernel simply means a map in which the range is the set of supracontributions over some set.
- ^
For more detail, see Toward Idealized Decision Theory §2.2 (Soares and Fallenstein, 2015) and Cheating Death in Damascus §3 (Levinstein and Soares, 2020).
- ^
If then
- ^
As a technicality, we always assume that the empty action is taken at the beginning of an episode.
Contributions are in a natural one-to-one correspondence with weighted probability measures, which were studied by Joe Halpern: https://arxiv.org/pdf/1302.5681
Simply take the weight to be the sum of measure. Halpern and Leung advocated minimizing regret against a set of weighted probability measures, which seems to be the same as minimizing loss against a supracontribution?
They update weights by likelihood ratio, roughly speaking (I am not sure how this corresponds to IB, since updating is not discussed in this sequence).
@Vanessa Kosoy @Diffractor Do you know if there is a meaningful connection between Halpern’s work and IBDT?
Unrelatedly: I like the term semi-environment (the AIXI literature uses “chronological semimeasure” with apparently the same meaning, which is much worse—previously even “chronological contextual semimeasure”!). I’d like to start using your term, but maybe it would lead to some confusion as applied to my current research—I’ve been treating semimeasures as (lower probabilities for) credal sets in
Halpern and Leung propose the “minimax weighted expected regret” (MWER) decision-rule, which is a generalization of the minimax-expected-regret (MER) decision-rule. In contrast, our decision rule is a weighted generalization of maximin-expected-utility (MMEU). The problem with MER is that it doesn’t work very well with learning. The closest thing to doing learning with MER is adversarial bandits. However, adversarial regret is statistically intractable for Markov Decision Processes. And even with bandits there is a hidden obliviousness assumption if you try to interpret it in a principled decision-theoretic way.