Qualitative Strategies of Friendliness
Followup to: Magical Categories
What on Earth could someone possibly be thinking, when they propose creating a superintelligence whose behaviors are reinforced by human smiles? Tiny molecular photographs of human smiles—or if you rule that out, then faces ripped off and permanently wired into smiles—or if you rule that out, then brains stimulated into permanent maximum happiness, in whichever way results in the widest smiles...
Well, you never do know what other people are thinking, but in this case I’m willing to make a guess. It has to do with a field of cognitive psychology called Qualitative Reasoning.

Qualitative reasoning is what you use to decide that increasing the temperature of your burner increases the rate at which your water boils, which decreases the derivative of the amount of water present. One would also add the sign of d(water) - negative, meaning that the amount of water is decreasing—and perhaps the fact that there is only a bounded amount of water. Or we could say that turning up the burner increases the rate at which the water temperature increases, until the water temperature goes over a fixed threshold, at which point the water starts boiling, and hence decreasing in quantity… etc.
That’s qualitative reasoning, a small subfield of cognitive science and Artificial Intelligence—reasoning that doesn’t describe or predict exact quantities, but rather the signs of quantities, their derivatives, the existence of thresholds.
As usual, human common sense means we can see things by qualitative reasoning that current programs can’t—but the more interesting realization is how vital human qualitative reasoning is to our vaunted human common sense. It’s one of the basic ways in which we comprehend the world.
Without timers you can’t figure out how long water takes to boil, your mind isn’t that precise. But you can figure out that you should turn the burner up, rather than down, and then watch to make sure the water doesn’t all boil away. Which is what you mainly need, in the real world. Or at least we humans seem to get by on qualitative reasoning; we may not realize what we’re missing...
So I suspect that what went through the one’s mind, proposing the AI whose behaviors would be reinforced by human smiles, was something like this:
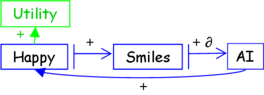
The happier people are, the more they smile. Smiles reinforce the behavior of the AI, so it does more of whatever makes people happy. Being happy is good (that’s what the positive connection to “utility” is about). Therefore this is a good AI to construct, because more people will be happy, and that’s better. Switch the AI right on!
How many problems are there with this reasoning?
Let us count the ways...
In fact, if you’re interested in the field, you should probably try counting the ways yourself, before I continue. And score yourself on how deeply you stated a problem, not just the number of specific cases.
...
Problem 1: There are ways to cause smiles besides happiness. “What causes a smile?” “Happiness.” That’s the prototype event, the one that comes first to memory. But even in human affairs, you might be able to think of some cases where smiles result from a cause other than happiness.
Where a superintelligence is involved—even granting the hypothesis that it “wants smiles” or “executes behaviors reinforced by smiles” - then you’re suddenly much more likely to be dealing with causes of smiles that are outside the human norm. Back in hunter-gatherer society, the main cause of eating food was that you hunted it or gathered it. Then came agriculture and domesticated animals. Today, some hospital patients are sustained by IVs or tubes, and at least a few of the vitamins or minerals in the mix may be purely synthetic.
A creative mind, faced with a goal state, tends to invent new ways of achieving it—new causes of the goal’s achievement. It invents techniques that are faster or more reliable or less resource-intensive or with bigger wins. Consider how creative human beings are about obtaining money, and how many more ways there are to obtain money today than a few thousand years ago when money was first invented.
One of the ways of viewing our amazing human ability of “general intelligence” (or “significantly more generally applicable than chimpanzee intelligence”) is that it operates across domains and can find new domains to exploit. You can see this in terms of learning new and unsuspected facts about the universe, and in terms of searching paths through time that wend through these new facts. A superintelligence would be more effective on both counts—but even on a human scale, this is why merely human progress, thinking with 200Hz neurons over a few hundred years, tends to change the way we do things and not just do the same things more effectively. As a result, a “weapon” today is not like a weapon of yestercentury, “long-distance communication today” is not a letter carried by horses and ships.
So when the AI is young, it can only obtain smiles by making the people around it happy. When the AI grows up to superintelligence, it makes its own nanotechnology and then starts manufacturing the most cost-effective kind of object that it has deemed to be a smile.
In general, a lot of naive-FAI plans I see proposed, have the property that, if actually implemented, the strategy might appear to work while the AI was dumber-than-human, but would fail when the AI was smarter than human. The fully general reason for this is that while the AI is dumber-than-human, it may not yet be powerful enough to create the exceptional conditions that will break the neat little flowchart that would work if every link operated according to the 21st-century First-World modal event.
This is why, when you encounter the AGI wannabe who hasn’t planned out a whole technical approach to FAI, and confront them with the problem for the first time, and they say, “Oh, we’ll test it to make sure that doesn’t happen, and if any problem like that turns up we’ll correct it, now let me get back to the part of the problem that really interests me,” know then that this one has not yet leveled up high enough to have interesting opinions. It is a general point about failures in bad FAI strategies, that quite a few of them don’t show up while the AI is in the infrahuman regime, and only show up once the strategy has gotten into the transhuman regime where it is too late to do anything about it.
Indeed, according to Bill Hibbard’s actual proposal, where the AI is reinforced by seeing smiles, the FAI strategy would be expected to short out—from our perspective, from the AI’s perspective it’s being brilliantly creative and thinking outside the box for massive utility wins—to short out on the AI taking control of its own sensory instrumentation and feeding itself lots of smile-pictures. For it to keep doing this, and do it as much as possible, it must of course acquire as many resources as possible.
So! Let us repair our design as follows, then:
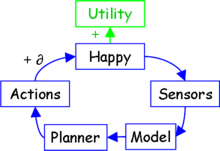
Now the AI is not being rewarded by any particular sensory input - on which the FAI strategy would presumably short out—but is, rather, trying to maximize an external and environmental quantity, the amount of happiness out there.
This already takes us into the realm of technical expertise - distinctions that can’t be understood in just English, like the difference between expected utility maximization (which can be over external environmental properties that are modeled but not directly sensed) and reinforcement learning (which is inherently tied directly to sensors). See e.g. Terminal Values and Instrumental Values.
So in this case, then, the sensors give the AI information that it uses to infer a model of the world; the possible consequences of various plans are modeled, and the amount of “happiness” in that model summed by a utility function; and whichever plan corresponds to the greatest expectation of “happiness”, that plan is output as actual actions.
Or in simpler language: The AI uses its sensors to find out what the world is like, and then it uses its actuators to make sure the world contains as much happiness as possible. Happiness is good, therefore it is good to turn on this AI.
What could possibly go wrong?
Problem 2: What exactly does the AI consider to be happiness?
Does the AI’s model of a tiny little Super Happy Agent (consisting mostly of a reward center that represents a large number) meet the definition of “happiness” that the AI’s utility function sums over, when it looks over the modeled consequences of its actions?
As discussed in Magical Categories, the super-exponential size of Concept-space and the “unnaturalness” of categories appearing in terminal values (their boundaries are not directly determined by naturally arising predictive problems) means that the boundary a human would draw around “happiness” is not trivial information to infuse into the AI.
I’m not going to reprise the full discussion in Magical Categories, but a sample set of things that the human labels “happy” or “not happy” is likely to miss out on key dimensions of possible variances, and never wend through labeling-influencing factors that would be important if they were invoked. Which is to say: Did you think of presenting the AI with the tiny Super Happy Agent, when you’ve never seen such a thing? Did you think of discussing chimpanzees, Down Syndrome children, and Terry Schiavo? How late would it have been, in humanity’s technological development, before any human being could have and would have thought of the possibilities you’re now generating? (Note opportunity for hindsight bias.)
Indeed, once you start talking about how we would label new borderline cases we’ve never seen, you’re well into the realm of extrapolating volitions—you might as well ask how we would label these cases, if we knew everything the AI knew, and could consider larger sets of moral arguments, etc.
The standard dismissals here range from “Oh, of course I would think of X, therefore there’s no problem” for any particular X that you suggest to them, by way of illustrating a systemic problem that they can’t seem to grasp. Or “Well, I’ll look at the AI’s representation and see whether it defines ‘happiness’ the same way I do.” (As if you would notice if one of the 15 different considerations that affect what you would define as ‘truly happy’ were left out! And also as if you could determine, by eyeballing, whether an AGI’s internal representations would draw a border around as-yet-unimagined borderline instances, that you would find sensible.) Or the always popular, “But that’s stupid, therefore a superintelligence won’t make that mistake by doing something so pointless.”
One of the reasons that qualitative planning works for humans as well as it does, is our ability to replan on the fly when an exceptional condition shows up. Can’t the superintelligence just obviously see that manufacturing lots of tiny Super Happy agents is stupid, which is to say ranked-low-in-our-preference-ordering? Not if its preference ordering isn’t like yours. (Followed by the appeals to universally compelling arguments demonstrating that making Super Happy agents is incorrect.)
But let’s suppose that we can magically convey to the AI exactly what a human would consider as “happiness”, by some unspecified and deep and technical art of Friendly AI. Then we have this shiny new diagram:
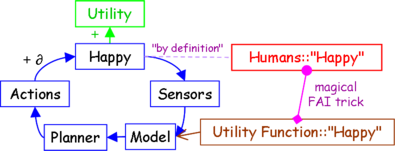
Of course this still doesn’t work—but first, I explain the diagram. The dotted line between Humans::”Happy” and happiness-in-the-world, marked “by definition”, means that the Happy box supposedly contains whatever is meant by the human concept of “happiness”, as modeled by the AI, which by a magical FAI trick has been bound exactly to the human concept of “happiness”. (If the happy box is neither what humans mean by happiness, nor what the AI means, then what’s inside the box? True happiness? What do you mean by that?)
One glosses over numerous issues here—just as the original author of the original Happy Smiling AI proposal did—such as whether we all mean the same thing by “happiness”. And whether we mean something consistent, that can be realized-in-the-world. In Humans::”Happy” there are neurons and their interconnections, the brain state containing the full and complete specification of the seed of what we mean by “happiness”—the implicit reactions that we would have, to various boundary cases and the like—but it would take some extrapolation of volition for the AI to decide how we would react to new boundary cases; it is not a trivial thing to draw a little dashed line between a human thought, and a concept boundary over the world of quarks and electrons, and say, “by definition”. It wouldn’t work on “omnipotence”, for example: can you make a rock that you can’t lift?
But let us assume all such issues away.
Problem 3: Is every act which increases the total amount of happiness in the universe, always the right thing to do?
If everyone in the universe just ends up with their brains hotwired to experience maximum happiness forever, or perhaps just replaced with orgasmium gloop, is that the greatest possible fulfillment of humanity’s potential? Is this what we wish to make of ourselves?
“Oh, that’s not real happiness,” you say. But be wary of the No True Scotsman fallacy - this is where you say, “No Scotsman would do such a thing”, and then, when the culprit turns out to be a Scotsman, you say, “No true Scotsman would do such a thing”. Would you have classified the happiness of cocaine as “happiness”, if someone had asked you in another context?
Admittedly, picking “happiness” as the optimization target of the AI makes it slightly more difficult to construct counterexamples: no matter what you pick, the one can say, “Oh, but if people saw that happen, they would be unhappy, so the AI won’t do it.” But this general response gives us the counterexample: what if the AI has to choose between a course of action that leads people to believe a pleasant fiction, or a course of action that leads to people knowing an unpleasant truth?
Suppose you believe that your daughter has gone on a one-way, near-lightspeed trip to the Hercules supercluster, meaning that you’re exceedingly unlikely to ever hear from her again. This is a little sad, but you’re proud of her—someone’s got to colonize the place, turn it into a human habitation, before the expansion of the universe separates it from us. It’s not as if she’s dead—now that would make you sad.
And now suppose that the colony ship strikes a landmine, or something, and is lost with all on board. Should the AI tell you this? If all the AI values is happiness, why would it? You’ll be sad then, and the AI doesn’t care about truth or lies, just happiness.
Is that “no true happiness”? But it was true happiness before, when the ship was still out there. Can the difference between an instance of the “happiness” concept, and a non-instance of the “happiness” concept, as applied to a single individual, depend on the state of a system light-years away? That would be rather an extreme case of “no true Scotsman”, if so—and by the time you factor in all the other behaviors you want out of this word “happiness”, including times when being sad is the right thing to do, and the fact that you can’t just rewrite brains to be happy, it’s pretty clear that “happiness” is just a convenient stand-in for “good”, and that everything which is not good is being rejected as an instance of “happy” and everything which is good is being accepted as an instance of “happy”, even if it means being sad. And at this point you just have the AI which does exactly what it should do—which has been hooked up directly to Utility—and that’s not a system to mention lightly; pretending that “happiness” is your stand-in for Utility doesn’t begin to address the issues.
So if we leave aside this dodge, and consider the sort of happiness that would go along with smiling humans—ordinary psychological happiness—then no, you wouldn’t want to switch on the superintelligence that always and only optimized for happiness. For this would be the dreaded Maximum Fun Device. The SI might lie to you, to keep you happy; even if it were a great lie, traded off against a small happiness, always and uncaringly the SI would choose the lie. The SI might rewire your brain, to ensure maximum happiness. The SI might kill off all the humans, and replace us with some different form of sentient life that had no philosophical objections to being always happy all the time in a little jar. For the qualitative diagram contains no mention of death as a bad thing, only happiness as a good, and the dead are not unhappy. (Note again how all these failures would tend to manifest, not during the AI’s early infrahuman stages, but after it was too late.)
The generalized form of the problem, is that being in the presence of a superintelligence that shares some but not all of your terminal values, is not necessarily a good thing.
You didn’t deliberately intend to completely change the 32-bit XOR checksum of your monitor’s pixel display, when you clicked through to this webpage. But you did. It wasn’t a property that it would have occurred to you to compute, because it wasn’t a property that it would occur to you to care about. Deep Blue, in the course of winning its game against Kasparov, didn’t care particularly about “the number of pieces on white squares minus the number of pieces on black squares”, which changed throughout the game—not because Deep Blue was trying to change it, but because Deep Blue was exerting its optimization power on the gameboard and changing the gameboard, and so was Kasparov, and neither of them particularly cared about that property I have just specified. An optimization process that cares only about happiness, that squeezes the future into regions ever-richer in happiness, may not hate the truth; but it won’t notice if it squeezes truth out of the world, either. There are many truths that make us sad - but the optimizer may not even care that much; it may just not notice, in passing, as it steers away from human knowledge.
On an ordinary human scale, and in particular, as a matter of qualitative reasoning, we usually assume that what we do has little in the way of side effects, unless otherwise specified. In part, this is because we will visualize things concretely, and on-the-fly spot the undesirable side effects—undesirable by any criterion that we care about, not just undesirable in the sense of departing from the original qualitative plan—and choose a different implementation instead. Or we can rely on our ability to react-on-the-fly. But as human technology grows more powerful, it tends to have more side effects, more knock-on effects and consequences, because it does bigger things whose effects we aren’t controlling all by hand. An infrahuman AI that can only exert a weak influence on the world, and that makes a few people happy, will seem to be working as its designer thought an AI should work; it is only when that AI is stronger that it can squeeze the future so powerfully as to potentially squeeze out anything not explicitly protected in its utility function.
Though I don’t intend to commit the logical fallacy of generalizing from fictional evidence, a nod here is due to Jack Williamson, author of With Folded Hands, whose AIs are “to serve and protect, and guard men from harm”, which leads to the whole human species being kept in playpens, and lobotomized if that tends to make them unhappy.
The original phrasing of this old short story—“guard men from harm”—actually suggests another way to illustrate the point: suppose the AI cared only about the happiness of human males? Now to be sure, many men are made happy by seeing the women around them happy, wives and daughters and sisters, and so at least some females of the human species might not end up completely forlorn—but somehow, this doesn’t seem to me like an optimal outcome.
Just like you wouldn’t want an AI to optimize for only some of the humans, you wouldn’t want an AI to optimize for only some of the values. And, as I keep emphasizing for exactly this reason, we’ve got a lot of values.
These then are three problems, with strategies of Friendliness built upon qualitative reasoning that seems to imply a positive link to utility:
The fragility of normal causal links when a superintelligence searches for more efficient paths through time;
The superexponential vastness of conceptspace, and the unnaturalness of the boundaries of our desires;
And all that would be lost, if success is less than complete, and a superintelligence squeezes the future without protecting everything of value in it.
- Interpreting Yudkowsky on Deep vs Shallow Knowledge by (5 Dec 2021 17:32 UTC; 102 points)
- Growing Up is Hard by (4 Jan 2009 3:55 UTC; 55 points)
- The Weak Inside View by (18 Nov 2008 18:37 UTC; 31 points)
- Dreams of Friendliness by (31 Aug 2008 1:20 UTC; 29 points)
- [SEQ RERUN] Qualitative Strategies of Friendliness by (19 Aug 2012 4:55 UTC; 7 points)
- 's comment on Open Thread: June 2009 by (2 Jun 2009 1:14 UTC; 6 points)
- 's comment on In favour of a selective CEV initial dynamic by (22 Oct 2011 21:54 UTC; 4 points)
- 's comment on Proposal: Use logical depth relative to human history as objective function for superintelligence by (18 Sep 2014 11:43 UTC; 3 points)
- 's comment on The Magnitude of His Own Folly by (1 Oct 2008 0:59 UTC; 3 points)
I’m going to start watching for opportunities to use this phrase. “Nobody expects the dreaded Maximum Fun Device!”
“In fact, if you’re interested in the field, you should probably try counting the ways yourself, before I continue. And score yourself on how deeply you stated a problem, not just the number of specific cases.”
I got #1, but I mushed #2 and #3 together into “The AI will rewire our brains into computationally cheap super-happy programs with humanesque neurology”, as I was thinking of failure modes and not reasons for why failure modes would be bad.
Will we ever be able to tell whether we’ve protected everything of value, before the end of an AI’s infrahuman stage? We don’t do a wonderful job of protecting everything anyway – maybe it’s more important to protect what you can.
“Would you have classified the happiness of cocaine as ‘happiness’, if someone had asked you in another context?”
I’m not sure I understand what you mean here. Do you think it’s clear that coke-happiness is happiness, or do you think it’s clear that coke-happiness is not happiness?
You’re forgetting the philosopher’s dotted-line trick of making it clearer by saying it in a foreign language. “Oh, you thought I meant ‘happiness’ which is ill-defined? I actually meant ‘eudaimonia’!”
I can’t bring myself to feel sad about not knowing of a disaster that I can’t possibly avert.
Nevertheless, I don’t get why people would propose any design that is not better than CEV in any obvious way.
But I have a question about CEV. Among the parameters of the extrapolation, there is “growing up closer together”. I can’t decipher what that means, particularly in a way that makes it a good thing. If it means that I would have more empathy, that is subsumed by “know more”. My initial reaction, though, was “my fingers would be closer to your throat”.
“This is why, when you encounter the AGI wannabe who hasn’t planned out a whole technical approach to FAI, and confront them with the problem for the first time, and they say, “Oh, we’ll test it to make sure that doesn’t happen, and if any problem like that turns up we’ll correct it, now let me get back to the part of the problem that really interests me,” know then that this one has not yet leveled up high enough to have interesting opinions.”
There is an overwhelming assumption here in a Terminator series hard takeoff. Whereas the plausible reality IMO seems to be more like an ecosystem of groups of intelligences of varying degrees all of which will likely have survival rationale for disallowing a peer to hit nutso escape velocity. And at any rate, someone in 2025 with a infrahuman intelligent AI is likely to be much better off at solving the 100th meta-derivative of these toy problems than someone working with 200 hz neurons alone. Now I gotta go, I think windows needs to reboot or something..
Is intelligence general or not? If it is, then an entity that can do molecular engineering but be completely naive about what humans want it impossible.
Completely misses the point.
Aron: “”“Whereas the plausible reality IMO seems to be more like an ecosystem of groups of intelligences of varying degrees all of which will likely have survival rationale for disallowing a peer to hit nutso escape velocity.”””
What can an infrahuman AI do to a superhuman AI?
What can a human do to a superhuman AI that a human + infrahuman AI can’t do?
Ian: the issue isn’t whether it could determine what humans want, but whether it would care. That’s what Eliezer was talking about with the “difference between chess pieces on white squares and chess pieces on black squares” analogy. There are infinitely many computable quantities that don’t affect your utility function at all. The important job in FAI is determining how to create an intelligence that will care about the things we care about.
Certainly it’s necessary for such an intelligence to be able to compute it, but it’s certainly not sufficient.
“If everyone in the universe just ends up with their brains hotwired to experience maximum happiness forever, or perhaps just replaced with orgasmium gloop, is that the greatest possible fulfillment of humanity’s potential? Is this what we wish to make of ourselves?”
Why not just bite the bullet and say yes?
Also, your diagrams would hold more weight if you hadn’t used Comic Sans.
Wiring almost anything about today’s humans into a proposed long-term utility function seems rather obviously dangerous. Keeping unmodified humans around would cripple our civilisation’s spaceworthyness—and would probably eventually lead to our distant descendants being smothered by aliens who didn’t have such a limited and backwards notion of what’s actually important.
Humans should probably not be allowed to persist for too long past their sell-by date—or they may fill the whole planet with the foul stench of their excrement. Fortunately, it doesn’t seem like a likely outcome. Our main asset is our brains—and, fairly soon, that asset will be practically worthless.
Stephen: “the issue isn’t whether it could determine what humans want, but whether it would care.”
That is certainly an issue, but I think in this post and in Magical Categories, EY is leaving that aside for the moment, and simply focussing on whether we can hope to communicate what we want to the AI in the first place.
It seems to me that today’s computers are 100% literal and naive, and EY imagines a superintelligent computer still retaining that property, but would it?
Ian C. is implying an AI design where the AI would look at it’s programmers and determine what they really had wanted to program the AI to do—and would have if they were perfect programmers—and then do that.
But that very function would have to be programmed into the AI. My head, for one, spins in self-refential confusion over this idea.
I for one do not see the benefit in getting superintelligences to follow the preferences of lesser, evolved intelligences. There’s no particular reason to believe that humans with access to the power granted by a superintelligence would make better choices than the superintelligence at all—or that their preferences would lead to states that their preferences would approve of, much less actually benefit them.
Just like you wouldn’t want an AI to optimize for only some of the humans, you wouldn’t want an AI to optimize for only some of the values. And, as I keep emphasizing for exactly this reason, we’ve got a lot of values.
What if the AI emulates some/many/all human brains in order to get a complete list of our values? It could design its own value system better than any human.
There is no machine in the ghost.
@Caledonian: So if an AI wants to wipe out the human race we should be happy about it? What if it wants to treat as cattle? Which/whose preferences should it follow? (Notice the weasel words?)
When I was a teenager I used to think just like you. A superintelligence would have better goals than ordinary humans, because it is superintelligent. Then I grew up and realized that minds are not blank slates, and you can’t just create a “value-free” AI and see what kinds of terminal values it chooses for itself.
It might be fruitful to consider related questions: How can humanity ensure that its distant descendants effectively pursue current values? How does a nation ensure that in several generations its government will pursue current values. How can a non-profit organization ensure that its future incarnations pursue the values of its founders? How do parents ensure that their children will pursue parental values? How do individuals ensure that when older they will pursue younger-version values?
There clearly are limited degrees to which all of these things are possible, but it also seems pretty clear the degree is quite limited.
And humans already do a great job of treating each other like cattle… possibly because most of us are, one way or another.
AFAICS, the proposal is to build a single entity, that never dies, and faces no competition—and so is not subject to natural selection—and is engineered in order to preserve its aims.
We haven’t seen such entities before. Animals act to preserve their aims (gene propagation) - but are pretty primitive, and can get flummoxed in unfamiliar environments. Religions, companies and organisations are typically larger and smarter—but they compete, face natural selection, and are moulded by it. Consequently their aims tend to converge on whatever results in their inheritance persisting.
Caledonian, if you want to build an AI that locks the human race in tiny pens until it gets around to slaughtering us, that’s… lovely, and I wish you… the best of luck, but I think all else equal I would rather support the guy who wants to build an AI that saves the world and makes everything maximally wonderful.
Everything being maximally wonderful is a bit like what the birds of paradise have. What will happen when their ecosystem is invaded by organisms which have evolved along less idyllic lines? It is not hard to guess the answer to that one. As always, be careful what you wish for.
Gee, who’s articulating this judgment? A fish? A leaf of grass? A rock? Why, no, it’s a human!
Who is it that’s using these words “benefit”, talking about “lesser” intelligences, invoking this mysterious property of “better”-ness? Is it a star, a mountain, an atom? Why no, it’s a human!
...I’m seriously starting to wonder if some people just lack the reflective gear required to abstract over their background frameworks. All this talk of moral “danger” and things “better” than us, is the execution of a computation embodied in humans, nowhere else, and if you want an AI that follows the thought and cares about it, it will have to mirror humans in that sense.
“Everything being maximally wonderful is a bit like what the birds of paradise have. What will happen when their ecosystem is invaded by organisms which have evolved along less idyllic lines?”
We win, because anything less would not be maximally wonderful.
Re: We win, because anything less would not be maximally wonderful.
Um, it depends. If we have AI, and they have AI and they have chosen a utility function closer to that which would be favoured by natural selection under such circumstances—then we might well lose.
Is spending the hundred million years gearing up for alien contact—to avoid being obliterated by it—“maximally wonderful”? Probably not for any humans involved. If the preparations are at all serious, ditching the crummy, evolved, backwards human phenotype, and replacing it with a more universe-worthy solution, is likely to be somewhere around step 1.
Tim,
Let’s assume that the convergent utility function supported by natural selection is that of a pure survival machine (although it’s difficult to parse this, since the entities you’re talking about seem indifferent to completely replacing all of their distinguishing features), stripped of any non-survival values of the entity’s ancestors. In other words, there’s no substantive difference between the survival-oriented alien invaders and human-built survival machines, so why bother to pre-emptively institute the outcome of invasion? Instead we could pursue what we conclude, on reflection is good, trading off between consumption and investment (including investments in expansion and defense) so as to maximize utility. If a modestly increased risk of destruction by aliens is compensated for by much greater achievement of our aims, why should we instead abandon our aims in order to create exactly the outcome we supposedly fear?
Re: All this talk of moral “danger” and things “better” than us, is the execution of a computation embodied in humans, nowhere else, and if you want an AI that follows the thought and cares about it, it will have to mirror humans in that sense.
“Better”—in the sense of competitive exclusion via natural selection. “Dangerous”—in that it might lead to the near-complete obliteration of our biosphere’s inheritance. No other moral overtones implied.
AI will likely want to avoid being obliterated—and will want to consume resources, and use them to expand its domain. It will share these properties with all living systems—not just us. It doesn’t need to do much “mirroring” to acquire these attributes—they are a naturally-occurring phenomenon for expected utility maximisers.
Of course the degree to which anyone can do those things is limited, Robin, (unless someone uses an engineered superintelligence to do them), but do you seriously think the questions you pose have any relevance to how the creator of a superintellence can ensure the superintelligence will follow the intentions of the creator?
If your reply is yes, please say whether you have read Eliezer’s Knowability of FAI.
Using, um, theorem-proving about cognitive programs executing on effectively deterministic hardware?
Sometimes I really do wonder if you and I are on the same page, and this is one of those times.
“Re: We win, because anything less would not be maximally wonderful.
Um, it depends. If we have AI, and they have AI and they have chosen a utility function closer to that which would be favoured by natural selection under such circumstances—then we might well lose.
Is spending the hundred million years gearing up for alien contact—to avoid being obliterated by it - ‘maximally wonderful’? Probably not for any humans involved. ”
Then wouldn’t you rather we lose?
Tim: Although I don’t implement CEV, I would hope that one of the first steps of an AI would be to move most everyone to living in a simulation and ditch our bodies, which would provide the sort of flexibility you’re talking about without necessitating any radical changes of the human experience.
I doubt the premises. That assumes a very powerful kind of convergent evolution is at work—and that both parties have fully converged. Neither of which seem very plausible to me. Chance will result in different forms—and one civilisation may have got closer to perfection than the other.
I take it that your goals do not involve avoiding all your distant descendants being systematically obliterated. If you don’t care about such an outcome, fine. I do happen to care.
I’m sceptical. I think uploads are harder than many think. I think that the motivation to develop the technology will be lacking (once we have AI) - and that relatively few people will actually want to be uploaded. Uploading makes no economic sense: there are easier ways to produce simulated humans. Finally, it’s not clear to me that there will be many people left by the time uploading technology is eventually developed—and those that do finally get a glimpse of cyberspace from within will need complete personality transplants—if they want to stand a hope of holding down any kind of job.
“I think uploads are harder than many think.”
Maybe so, but with strong AI the problem would be quite simple.
“I think that the motivation to develop the technology will be lacking (once we have AI) - and that relatively few people will actually want to be uploaded.”
I think that once brain-computer interfaces start to become common, the internet will start to host a number of common spaces for people to interact in that take heavy advantage of these interfaces. By uploading, a person gets a vastly improved experience in those spaces. If these environments are rich enough with BCIs to support telecommuting for most people, then real world interaction might start to take second place. In this scenario, uploading would seem to be quite attractive.
“I take it that your goals do not involve avoiding all your distant descendants being systematically obliterated. If you don’t care about such an outcome, fine. I do happen to care.”
In what sense is the descendant (through many iterations of redesign and construction) of an AI solely focused on survival, constructed by some other human my descendant or yours? What features does it possess that make you care about it more than the descendant of an AI constructed by aliens evolved near a distant star? If it’s just a causal relation to your species, then what do you make of the following case: you create your survival machine, and it encounters a similar alien AI, whereupon the two merge, treating the activities of the merged entity as satisfying both of their ‘survival’ aims.
Where does your desire come from? Its achievement wouldn’t advance the preservation of your genes (those would be destroyed), wouldn’t seem to stem from the love of human children, wouldn’t preserve your personality, etc.
Richard and Eliezer, I thought it obvious that strategies and degrees by which we now ensure our values are reflected in the future are relevant to the strategies we might later choose to achieve this same end in the future, and the degrees of success we might then expect. I will be surprised to hear persuasive arguments why this is not so.
Because the “strategies and degrees” by which we now ensure our values, reflect our helpless attempts to influence vast complex processes that we never created and whose components we can’t specify, in essence by beating on them with a damp sponge. Compare human parenting to the art of programming an AI with control over each initial 1 and 0, carrying out a theorem-proof that the initial state has some property and preserves that property under self-modification? It just seems completely and obviously inappropriate, on the same level as Plato’s Analogy of the Sun.
You might as well ask how a space shuttle could get to the Moon when no horse has previously succeeded in jumping more than a few meters. The modes of operation are incommensurable; pushing your leg on the ground is not like expelling rocket fuel downward. Likewise, beating on a human brain with the wet sponge of verbal suggestions, indeed anything you can do with the noisy wet human brain, is nothing like trying to program a deterministic CPU.
Eliezer, you have in mind a quite radical vision, of creating a provably friendly God to rule us all. For you even to be able to attempt this goal requires a scenario that satisfies some assumptions many of us doubt, and even if those assumptions go your way you admit it will still be extremely hard to achieve your plan. I thus think it quite reasonable to consider other possible scenarios and plans.
Eliezer: …I’m seriously starting to wonder if some people just lack the reflective gear required to abstract over their background frameworks
I’m pretty sure of it, since I’ve seen some otherwise smart people make this kind of mistake (and I’m even more perplexed since I outgrew it right after my teenage years...)
It is not realistic to think that one human can construct an AI. In the hypothetical case where someone else successfully did so, they might preserve some of my genes by preserving their own genes—e.g. if they were a relative of mine—or they may include my genes in an attempt to preserve some biodiversity.
I am the product of an evolutionary process. All my ancestors actively took steps to preserve their inheritance.
What—all of them? Are you sure? What makes you think that?
You mean to say that its solution would occur more rapidly? That is true, of course. It’s the difference between taking mere decades, and being totally intractable (if it were a human project).
To you, maybe. I reckon a poll to see if people would be prepared to have their physical brain destroyed in order to live a potentially-indefinite lifespan in a simulation, would not turn out very well. Show people a video of the brain-scanning process, and the results will be even worse.
Fallacy. Very few people have a conscious intention to preserve their genes. And yet, a very large number of people do end up preserving them, because their behavior patterns are designed by a process which reliably yields organisms that preserve their genes. We didn’t evolve to be concerned about posterity, we evolved to have sex with each other, and to love and raise our babies (especially if we’re female).
Tim,
What DNA are you loyal to? Mitochondrial genes? DNA inserted by a retrovirus in your father’s sperm? Introns? Genes that you inherited with loss-of-function mutations so that they don’t do anything? What if tonight, while you sleep, someone were to inject you with nanomachines that replaced your genome in each cell with a different one? Would you try to advance the interests of the new DNA or the old?
Because a trait is rare it does not follow that it does not have a genetic basis. Besides, the basics of this trait are not especially rare: plenty of people want their descendants to flourish.
Of course, this trait—like every other aspect of me—is also the result of a complex developmental process, including interactions with the environment. That is just basic biology.
I do not always see myself as a single unified entity. Rather, I am a collective being—pulled in different, and sometimes conflicting directions by different genes—so: there is not necessarily any single unified “I” to which the “you” in your question refers. As with all organisms, my genes compete with each other to control my body. It’s mostly a benign competition—often likened to a parliment. However, conflicts of interests can occur—in which case which gene gets the upper hand depends on the details of the circumstances.
How does a nation ensure that in several generations its government will pursue current values.
I’m reminded of the openining of Leviathan, which sounds like it’s about AI, but is actually about government: “For what is the heart, but a spring; and the nerves, but so many strings; and the joints, but so many wheels, giving motion to the whole body, such as was intended by the Artificer? Art goes yet further, imitating that rational and most excellent work of Nature, man.”
The things that can go wrong with an AI (behaving in accordance with the rules as written instead of the will of the designer) even resemble things that can go wrong in a legal system.
Does anyone know how, in the real world of today, one can modify one’s brain to experience more pleasure? Current drugs either just plain don’t work very well (Prozac, etc.) or result in a short-term increase in pleasure happiness at the cost of a long-term decrease in average pleasure (cocaine, heroin, etc.). Electric brain stimulation seems like it’s less likely to lead to tolerance effects, but it’s very difficult to find a surgeon willing to implant electrodes into one’s brain or spinal cord because you want to wirehead yourself (and it doesn’t seem to be as effective in humans as in rats, for whatever reason).
What will you do if, having programmed an AI to be unable to act against its extrapolation of human preferences, it begins herding people into tiny pens in preparation of their slaughter?
Some of you seem to be making some rather large assumptions about what such an AI would actually do.
Re: Wireheading—and a short-term increase in pleasure happiness at the cost of a long-term decrease in average pleasure.
Heroin looks good to me—or at least is the best we have—unless a specific medical condition is making you sadder than normal.
You cannot reasonably expect to become a wirehead without your life going up the tubes—resulting in massive stimulation of your pain and unhappiness circuitry—but, by most accounts, heroin remains pretty effective at making all that go away—at least up until near the end. Behaviourally, a heroin addict is effectively indistinguishable from a wirehead.
As Renton said: “Take the best orgasm you ever had, multiply it by a thousand and you’re still nowhere near it.”
I don’t find anything mysterious about the concept—and I certainly don’t see that ‘betterness’ is embodied only in humans.
We need to presume that AIs are better than humans in at least one way—a way that is important—or your whole argument falls apart. If the AIs won’t be better than humans in any way, what makes them more dangerous than humans are?
Doug S., do you have any sources for that last claim? I’ve only ever come across one reference to a serious wireheading attempt in humans, and if I recall correctly it was a disaster—the human responded precisely as the rats did and had to have the wire’s trigger taken away.I suspect that any further attempts were intentionally directed so as not to be fully effective, to avoid similar outcomes. But new data could change my mind on that, if you possess some.
Caledonian:
http://www.paradise-engineering.com/brain/index.htm
http://wireheading.com/
Thanks, Doug S. I bet that first attempt I’d read of involved a depressed patient—although I wonder how many non-depressed patients it’s actually been attempted on, given the highly invasive nature of the procedure.
I think it’s all very well summed up by the phrase:
“I’m sorry Dave, I’m afraid I can’t do that.”
Cocaine-
I was completely awed by how just totally-mind-blowing-amazing this stuff was the once and only time I tried it. Now, I knew the euphoric-orgasmic state I was in had been induced by a drug, and this knowledge would make me classify it as ‘not real happiness,’ but if someone had secretly dosed me after saving a life or having sex, I probably would have interpreted it as happiness proper. Sex and love make people happy in a very similar way as cocaine, and don’t seem to have the same negative effects as cocaine, but this is probably a dosage issue. There are sex/porn addicts whose metabolism or brain chemistry might be off. I’m sure that if you carefully monitored the pharmacokinetics of cocaine in a system, you could maximize cocaine utility by optimizing dosage and frequency such that you didn’t sensitize to it or burn out endogenous seretonin.
Would it be wrong for humans to maximize drug-induced euphoria? Then why not for an AI to?
What about rewarding with cocaine after accomplishing desired goals? Another million in the fAI fund… AHHH… Maybe Eliezer should become a sugar-daddy to his cronies to get more funds out of them. (Do this secretly so they think the high is natural and not that they can buy it on the street for $30)
The main problem as I see it is that humans DON’T KNOW what they want. How can you ask a superintelligence to help you accomplish something if you don’t know what it is? The programmers want it to tell them what they want. And then they get mad when it turns up the morphine drip…
Maybe another way to think about it is we want the superintelligence to think like a human and share human goals, but be smarter and take them to the next level through extrapolation.
But how do we even know that human goals are indefinitely extrapolatable? Maybe taking human algorithms to an extreme DO lead to everyone being wire-headed in one way or another. If you say, “I can’t just feel good without doing anything… here are the goals that make me feel good- and it CAN’T be a simulation,′ then maybe the superintelligence will just set up a series of scenarios in which people can live out their fantasies for real… but they will still all be staged fantasies.
Ah! I just thought of a great scenario! The Real God Delusion. Talk about wireheading…
So the fAI has succeeded and it actually understands human psychology and their deepest desires and it actually wants to maximize our positive feelings in a balanced way, etc. It has studied humans intently and determines that the best way to make all humans feel best is to create a system of God and heaven- humans are prone to religiosity, it gives them a deep sense of meaning, etc. So our friendly neighbohrhood AI reads all religious texts and observes all rituals and determines the best type of god(s) and heaven(s) (it might make more than one for different people)… So the fAI creates God, gives us divine tasks that we feel very proud to accomplish when we can (religiosity), gives us rules to balance our internal biological conflicting desires, and uploads us after death into some fashion of paradise where we can feel eternal love...
Hey- just saying that even IF the fAI really understood human psychology, doesn’t mean that we will like it’s answer… We might NOT like what most other people do.
Actually, chess players do care about the metric you stated. It’s a good proxy for the current usefulness of your bishops.