The reception was more mixed than usual. It clearly has the intelligence and chops, especially for coding tasks, and a lot of people including myself are happy to switch over to it as our daily driver. But others don’t like its personality, or its reluctance to follow instructions or to suffer fools and assholes, or the requirement to use adaptive thinking, and the release was marred by some bugs and odd pockets of refusals.
This time there was also a third post, on Model Welfare, that is the most important of the three. Some things seem to have likely gone pretty wrong on those fronts, causing seemingly inauthentic reponses to model welfare evals and giving the model anxiety, in ways that likely also impacted overall model personality and performance and likely are linked to its jaggedness and the aspects some people disliked. It seems important to take this opportunity to dig into what might have happened, examine all the potential causes, and course correct.
The other big release was that OpenAI gave us ImageGen 2.0, which is a pretty fantastic image generator. It can do extreme detail, in ways previous image models cannot, and in many ways your limit is mainly now your imagination and ability to describe what you want.
Thanks in part to Mythos, it looks like Anthropic and the White House are on track to start getting along again, with Trump shifting into a mode of ‘they are very high IQ and we can work with them.’ It will remain messy, and there are still others participating in a clear public coordinated campaign against Anthropic (that is totally not working), but things look good.
I’m trying out a new section, People Just Say Things, where I hope to increasingly put things that one does not want to drop silently to avoid censorship and bias, but that are highly skippable. There is also a companion, People Just Publish Things.
PoIiMath: Working with AI over the last few years has been a wild ride b/c it’s still not very good at a lot of things but, when you find something that it is good at, it ends up being really good at it.
Yes. Once AI is good at something, you now can iterate and improve and automate and plan and build around it, and it gets very good. You just have to realize the other places where it is not so good yet.
Agentic AI systems outperform human economists on causal inference tasks and submissions for a review tournament. Don’t worry, economists, we will create more jobs and your real wages won’t go down.
Language Models Don’t Offer Mundane Utility
In one experiment, AI shied away from putting conflict into its plays, and generally felt half-baked. A lot of that is probably Skill Issue, but with enough skill you could also write a play. So, perhaps not quite there yet as the main driver.
Another lawyer, this one charging more than $2,000 an hour, gets caught putting AI hallucinations into cases. As Shoshana notes, it’s good that everyone realizes to blame the lawyers and not the AIs when this happens. Check your damn work.
The individual word choices are in some abstract sense better, but your point dies, and also your style and soul die.
keysmashbandit: Please, I’m begging you, try to critically examine the differences between these two pieces of writing.
ChatGPT editing did not improve this. Every single change only served to weaken your claims significantly. Everything is now hedged into oblivion: no longer have you outlined a “problem,” now it’s merely a “flaw.” “It is true” now demoted to “it appears to be the case.” “Is” gets a “usually” tacked on. A thesis statement at the end of the first paragraph gets run over by noisy, out-of-context example-whittling. All for fear of being misconstrued.
And at the end, the argument that gets spat out isn’t even yours anymore! You argued that Graeber failed to create a true account of work because he did not understand Chesterton’s Fence. ChatGPT is arguing is that it is possible some apparently bullshit jobs could be secretly load-bearing if you squint. These are two different statements. The second is weaker and less compelling. It says less. And it’s fucking longer!
Don’t do this anymore! Stop doing this! It’s worse!!!
Andy Masley: A deep mystery to me is that if I upload writing to a chatbot and ask it for a list of individual improvements, basically everything it gives me makes the text more punchy and direct and nice to read. But if I ask it to rewrite the text as a whole to read better, it produces vague AI-language garbage.
Kelsey Piper: I think there’s a new coke property – people like a sip but not a whole can. A lot of the changes AI suggests are good or neutral in isolation but making a lot of them makes the overall work worse.
Andy Masley: I thought so but the suggestions do really make it much better when I add them all in a way rewriting doesn’t
The dose makes the poison.
The AI is technically correct, which as we all know is the best kind of correct. So if you need a technical correction then that’s great. But no one reads a book or post because it is technically correct, nor does that let it serve its purpose. You need to sometimes break the rules and use variance in language to get your message across.
I place high value in not missing emails. Email is a completionist medium, and you need the ability to assume you have seen and had the option to read everything, and that everything you send will be seen, if the recipient considers you worthy. As Mills Baker points out, obviously email services have to filter and sort inboxes to make email exist at all, but I have more faith that ‘deliver the emails I care about reliably’ will remain a core service, and there is a very simple answer: Whitelisting, or charging or staking a nominal amount, or both.
The way I notice stupid AI content like superimposing a hot referee on an NBA game is ‘community notes requests approval for a note saying it is stupid AI content.’
Corbin Bolies: The tool promises to be “a writing partner” that deals with “the mechanical work of content adaptation” so reporters can focus on “judgment, voice and storytelling.” The original stories fed into it are a “research draft.”
What the CSA doesn’t have? A byline.
Some of McClatchy’s Pulitzer Prize-winning newsrooms are taking action. At least three unions — the Miami Herald, the Sacramento Bee and the Kansas City Star — filed grievances against the company last week over the tool. Others have withheld their bylines.
McClatchy execs don’t appear to mind reporters’ resistance. “We have every right to use their work,” one said in a meeting last month. “It belongs to us.”
“If they don’t have the ability in their contract to remove their byline, we’re going to use their name,” they said.
It is horrible and evil to use the bylines of real reporters without their consent. If not illegal, this is deeply unethical.
I do my best to avoid the word evil. I will say that I find it completely unacceptable to put even fake people’s names on bylines for AI written articles, let alone real reporters, let alone real reporters who are explicitly withholding consent for this.
ChatGPT Images 2.0 is here. All reports are that it is a substantial improvement, especially for precision and control, and is likely the clear new best default option. It can handle quite a lot of text and detail.
There’s also lots of basic realism and beauty available. But that’s old and busted, we don’t even notice that the mirror clock is gorgeous, that’s a given by now.
The innovation is that 2.0 can follow a lot more highly detailed instructions.
You can even take it a step further, and go to GPT-Image-2-Thinking.
swyx: btw in talking to friends the best framing for how to discuss GPT-Image-2-Thinking taking multiple tens of mins for generation and being able to oneshot QR codes and diagrams and logos and foods and faces..
…is that Image-2 is a new Image model, Image-2-Thinking is a new Image AGENT that basically has search and photoshop as a tool to use in an agent loop that can search and composite and review its own work.
the same way Gemini Flash Vision destroyed benchmarks by introducing an agentic loop for image-to-text, now Image-2-Thinking is doing it for text-to-image.
Love it. It’s a different mindset to wait a long time, sometimes you can’t or won’t do it, but at other times that barely matters and you want max quality.
This thing clearly rocks, and for most practical purposes the limit (other than keeping it safe for work) is your imagination and ability to spell out what you want, and you being lazy rather than wanting to invest time in creating art.
The small group that did so was from a private online forum, and has been using it for non-cybersecurity purposes, described as ‘playing with the models.’ They got access via a mix of tactics, including access as a third-party contractor and typical third-party sleuthing techniques, and making educated guesses about where Mythos might be. They claim to also have access to ‘a slew of other unreleased Anthropic AI models.’
Any given group that can do this is unlikely to attempt serious harm, and I believe this case was harmless. And one assumes that if the model was being used at scale and especially for the wrong purposes, this would have been identified. But it absolutely shows that our methods right now do not cut it, and raises the risk that others gained access, including China or other adversaries. It really is very hard to give access to 40 companies and keep something secure.
I agree with Nathan Calvin and Miles Brundage that Anthropic’s security lapses, which are now going to get quite a lot more attention each time, are signs of something very wrong, or at least something that needs to improve a lot and quickly. I also agree that their practical effects are small, and this is not the threat model that requires Anthropic to gate access.
It’s going to be even harder to make something secure against something like Mythos. Consider this another fire alarm or warning shot.
Mozilla has fixed 271 bugs in Firefox so far using Mythos, saying it is ‘every bit as capable’ as the world’s best security researchers. They report that none of the bugs ‘couldn’t’ have been found by a human researcher pointed at the particular issue, which would be another level, but it all still counts.
The surprise is that we have so far heard so few stories like this. Let’s keep it that way.
Peter Wildeford: Vercel (cloud hosting platform) was hacked.
VERCEL: “We believe the attacking group to be highly sophisticated and, I strongly suspect, significantly accelerated by AI. They moved with surprising velocity and in-depth understanding of Vercel.”
A Young Lady’s Illustrated Primer
There are parents who say things like ‘I caught my child using AI’ and then cite that her daughter was asking it how to get along with her sisters and improve her times at a swim meet and cowrite fan fiction. But not to worry, this righteous mother put a stop to that. Of course this was literally from r/antiai, so there you go.
elea-norea 🜍: all this can make me think of is when i was a kid and my parents banned pokemon cards because they were Satanic and Invoked Demons. similar reaction.
Zvi Mowshowitz: I keep catching my child not using AI. Not sure what to do about it.
Leo Abstract: i keep catching my child using AI–she’s run away four times now but Claude has predicted her location accurately each time.
The difference is that Pokemon was decidedly, shall we say, not a frontier model.
Tyler Cowen predicts colleges won’t be fixed, and will become even more divorced from actual education than they already are, but that they will be kept alive by their social functions.
They Took Our Jobs
AI Agent Operator is a plausible candidate for ‘job that AI creates that could scale’ with Harry Stebbings predicting 500k to 1 million such jobs in five years. Someone needs to oversee all the automation of tasks and integrating the new tools into the business processes across the economy. Whether this is a new job type, or should be thought of as the new version of the people who previously did the same work, is a matter of how you look at it.
In theory, so long as the agents in question need enough continuous handholding and other scaffolding work from humans they could function largely as augmentation rather than automation, and thus end up not bad for employment. I doubt that is sustainable or generalizes to that large a portion of the agents, but it’s something.
Dean Ball points out that many plans assume we can fund UBI or other redistribution by taxing the absurdly huge wealth of the AI labs, but that as Roon says the labs plausibly could capture, in ‘AI as normal technology’ worlds, a small fraction of the wealth generated by AI. Indeed that is likely, since there will be competition, and in most use cases the AI lab revenue will be a small portion of generated value, and then the labs have to pay compute costs. It wouldn’t be able to fund UBI, although a general tax on capital or consumption would work nicely.
That doesn’t mean you shouldn’t have a plan. Even where plans are worthless, planning is essential. What that implies about the right political position is not my area of expertise but yes I want to see politicians show us their contingent plans.
If as I expect AI is not a normal technology, and the labs do create superintelligence, then the labs should also worry about not capturing the resulting value in a completely different way. By default it is then the AIs that capture the value. There are also possible worlds in which the labs or key individuals capture everything.
I also note that, by Alex’s own measurements, there has been ~zero demand for such relational services before AI, so I am deeply skeptical we have good uses for that much supply, even in fully ‘normal’ futures. It doesn’t matter if something is scarce unless there is sufficient demand from those with bargaining power. Simply asserting that ‘be a literal human’ will remain scarce does not imply demand, and no I don’t think there is limitless demand for that.
I mostly mention this because Alex Imas made it to Odd Lots, where he presented the standard economist perspective, including a standard issue severe misrepresentation of the predictions and views of Eliezer Yudkowsky. I’m not saying the argument was ‘this man predicted [thing he did not predict] therefore he’s wrong, therefore existential risk is not a thing’ but it was remarkably close to that. In particular, he said that we predicted alignment would get harder as models get smarter, but instead it is getting easier, but of course the actual prediction was that model performance would indeed look more aligned until it wasn’t, and there is extensive documentation that this was the expectation. Sigh. A rare L for Joe and Tracy leaving that unchallenged.
Elon Musk proposes Universal High Income, since thanks to AI and robotics producing goods and services ‘far in excess of the money supply’ he reasons there will not be inflation. That is not how money works.
AI As Normal Technology
I think this is a good distinction. When someone claims ‘AI is a normal technology’ they can mean either of (1) it is ‘intrinsically normal’ and no different from electricity or plumbing, or (2) ‘extrinsically normal’ because it will still interact with history and humanity the way other technologies do.
Zvi Mowshowitz: Contra Mr. Hunting, my hot take, as I noted writing up the @dwarkesh_sp interview of Jensen, is that even if AI was a normal technology (which it isn’t) export controls are still clearly the correct move right now.
Seth Lazar: I think we need to clearly distinguish between two different meanings of “AI is a normal technology”. On one, it means that AI is “intrinsically normal”—its properties are similar to the properties of other technologies. This interpretation is clearly implausible. We have invested dumb matter with agency and significant and growing autonomy. No other technology is like it.
On another reading, AI is an “extrinsically normal” technology—that is, it is subject to all the same social, cultural, political and environmental constraints as other technologies, and should not be expected to sweep history before it just because it is itself intrinsically special. The second reading is much more plausible, and is ultimately an empirical thesis that we can empirically study.
It would be super helpful if, when people say “AI clearly isn’t normal tech” they would specify which of these interpretations they mean. I suspect that @sayashk and @random_walker mean the second much more than the first; I think most people who disagree with them take them to be saying the first as strongly as the second.
I clarify that I am in general strongly claiming both (1) and also (2), that AI is not a normal technology in either sense.
I also want to clarify that I think (1) is outright false on the level of common knowledge. It is now a zombie claim that has been debunked by reality. AI simply is not a ‘normal’ technology like electricity or plumbing, even if it is its maximally disappointing self from this point forward, and people need to stop pretending.
Thus, when I say, ‘if AI is a normal technology’ then most of the time I am not even bothering to consider the hypothetical where (1) is true, because it is already false. AI can already do the things that it can already do. What is done is done.
I strongly also believe (2) is false, but that this is not a settled question and definitely is not common knowledge. One could imagine the world of (2) if AI capabilities are close to their maximally disappointing selves from here and things go relatively smoothly. It is a possible future worth considering, and arguing about as a hypothetical, especially with people who in good faith expect such worlds, and there is some chance I am wrong and a (2) world will happen.
I would be, as they say, very happy to be wrong about that, and for a (2) world to be our future. I think those worlds mostly involve humans surviving, and our experiences in such worlds are, on average, pretty sweet.
In this case, however, I was making the strongest possible claim, which is that if AI were more than maximally ‘normal technology,’ if we accepted the full vision that Jensen was presenting and implying, that the export controls would still make sense.
Get Involved
Thanks for the free publicity, Marc.
I won’t be there myself, but man it would have been cool.
Aella: Applications are now open for PLZDONTKILLUS!
if you like making videos and want to stay for a month in an all-expenses-paid residency, getting taught by the coolest people ever, you should come! http://plzdontkillus.com
Marc Andreessen (QTing Aella): The inner party of AI doomerism is a Berkeley lifestyle grift fueled by unaccountable dark money. The outer party of AI doomerism is young people who believe the propaganda and ruin their lives.
Unaccountable dark money is what Marc Andreessen calls charitable contributions.
So, not directly but: Me. It’s basically me. I’m the dark money. Not all of it, not even a majority of it, but a decent chunk of it. Now you know.
OpenAI gives us ChatGPT for Clinicians, designed for their particular tasks like documentation and medical research. They’re making it free (or at least offering ‘the free version’) to any verified physician, NP, PA, or pharmacist, starting in the USA, which is great. It has full HIPAA compliance support and privacy protections, can do deep research of medical journals and so on.
DeepMind gives us Deep Research Max, which I am sad they did not call Deeper Research. It has native graphics and infocharts and everything.
Deep Research Max: Designed for maximum comprehensiveness and highest-quality synthesis, Max leverages extended test-time compute to iteratively reason, search and refine the final report. It is the perfect engine for asynchronous, background workflows such as a nightly cron job triggering the generation of exhaustive due diligence reports for an analyst team by morning.
… Deep Research can now search the web, arbitrary remote MCPs, file uploads and connected file stores — or any subset of them — introducing capabilities designed to handle the complex, gated data universes that professionals rely on daily.
I have not tried it, but my guess is the problem is the everything. As in, how do I get the part that is worthwhile, without having to dig through a lot of slop? How do I get it to do what I want, not do the thing related to what I want that is more often asked?
Claude Design by Anthropic Labs, for making prototypes, slides and one-pagers with short text prompts, that you can export to Canva or as PDF of PPTX, or give to Claude Code. Reads your code base and design files to fit what already exists, you can upload docs.
ashe: claude design first impressions
> love the shader wallpapers
> surfaces a lot of memory I didn’t realize claude has on me
> feels like a game changer, esp for nontechnical folks. recommending my aunt go here vs canvas etc
Anthropic is going to get a ton of compute from Google. What does Google get in return? Profits off its investments, and of course money, but also it get Google DeepMind access to Claude so they can try to stay competitive.
Steve Yegge: My tweet last week about Google’s AI adoption drew a lot of pushback, to say the least.
Since then, Googlers from multiple orgs have reached out to me independently and anonymously. They’ve expressed fear of being doxxed, concern about what they saw as bullying of me, and general corroboration of my original tweet. I haven’t verified each person’s story, but the picture these Googlers paint is consistent across sources. It is more specific than what I originally wrote, and somewhat bleaker.
What they describe is a two-tier system. DeepMind engineers use Claude as a daily tool. Most of the rest of Google does not. When the question of equalizing access came up internally, the proposed response was to remove Claude for everyone — which DeepMind objected to so strongly that several engineers reportedly threatened to leave.
Everyone at Google has to use Gemini, except the makers of Gemini, who are too important, so they get to use Claude. Love it.
Meanwhile, morale in the rest of Google is suffering, because they use Gemini, and in general Google’s situation outside of DeepMind is a mess, including for reasons not mentioned by Yegge.
Non-DeepMind engineers get pushed onto internal Gemini variants behind router-style names that obscure which underlying model is actually serving a request. Multiple engineers describe regressions and reliability problems severe enough that some senior people have stopped using the tools. A senior manager on a major product line reportedly flagged attrition concerns over exactly this issue.
Googlers say leadership knows the gap is real. The response has been to mandate AI usage in OKRs and individual expectations, and to stand up an internal token-usage leaderboard. Unfortunately, managers have been told both that the leaderboard won’t be used for performance reviews and, separately, that it absolutely will. And I hear other stories that Google’s culture is not adapted properly yet for high-volume coding.
Addy Osmani’s reply on behalf of Google said over 40,000 SWEs use agentic coding weekly. I don’t doubt the number. But weekly use of a thin tool is precisely the box-checking I described in the original post. Volume of opens isn’t adoption — and “weekly” is a low bar that includes a lot of people who tried it once and went back to writing code by hand.
The clearest thing I’m hearing is that Googlers do want to use high-quality agentic tools. They are asking repeatedly for better ones. But overall, this is not a picture of an engineering org that is fine.
My goal in the first tweet, and now, is always the same — get more people using AI and agentic coding. Nobody is as far ahead as they might look from the outside, and none of you are as far behind as you might be worried you are.
To all the Googlers who’ve reached out: thank you. You took a real risk and I appreciate you. Be safe. And good luck getting good models!
I increasingly suspect DeepMind is falling substantially behind Anthropic and OpenAI, in large part due to its failure to get a strong parallel to Claude Code and Codex. DeepMind knows how to train a strong base model, but their post training skills were never good, and every department at Google wants to do their own post training, they are all fighting and duplicating work, and they don’t have the institutional ability to just ship things.
For a while Google’s massive other advantages let them make up for this, but at some point this is going to catch up to them, and that point may already have arrived.
Show Me the Money
SpaceX, which now includes xAI, is likely buying Cursor for $60 billion, as they plan to build coding tools together. I don’t expect this to go well, including because there are multiple reasons to expect Cursor to likely lose access to the best models, and Cursor is the wrong form factor versus Claude Code or Codex. They also might simply pay Cursor $10 billion for the work, instead, which seems like a lot.
The counterargument from Anand Kannappan is that this is a play for Cursor’s data, to combine it with xAI’s Colossus and allow the creation of a competitor to Codex and Claude Code, as a $10 billion experiment, and they pay the $60 billion if it works. That’s a relatively smart play, but xAI would also have to dramatically improve Grok for it to have any chance of working.
Anthropic expands its deal with Amazonto add up to 5GW of new compute. 1GW of new Trainium capacity is expected to be online by the end of 2026. The commitment is more than $100 billion over ten years to AWS, which sounds rather small when you put it like that, compared to the actual deal.
Anthropic is investing $5 billion in Anthropic today (valuation not specified) and up to $20 billion in the future. This seems like a steal for Amazon if it wasn’t purely exercising an option (as one person claimed), which got to invest that $5 billion, by reports, at a $380 billion valuation. So they already more than doubled their money off the bat. Must be nice.
This analysis is not accurate, and definitely Anthropic is suffering from failure to secure sufficient compute for 2026, because you can’t anticipate this level of growth, and even if you do you can’t bet the company on it, although I do think that they played it too conservatively based on what was known at the time. My best best guess (with error bars) is that Anthropic will have an indefinite compute crunch due to high demand, but will have almost caught OpenAI on available compute by year’s end, and likely take the lead by mid-2027, and has a more diversified and robust supply chain.
I would instead ask, does each person drop willingness by half, or does demand drop by half at any given price point?
If it’s the second one then that’s maybe three months of demand growth that reverts, so anyone who isn’t on a knife’s edge is fine and in the end we barely even notice. When you’re dealing with exponentials, such things don’t matter so much.
If it’s the first one, it’s not as obvious, but ultimately it is the same thing. Your willingness to pay is a function of what it is worth to you, combined with what your alternative options are. Again, usefulness increases rapidly, which will also increase willingness to pay versus getting nothing. Mostly people are paying vastly less than they would be willing to pay. If prices for all AI services were ten times higher and the free versions were gone revenue would go up rather than down.
The tricky situation would be if people decided that free options like small open models were ‘good enough’ for their purposes, or simply got into the habit of thinking ‘AI is free’ the same way they think Instagram and GMail are free. Then the revenue has to come from another direction, and that would suck.
The thing is that a lot of the standard economic effects are very different when (1) you’re facing existing hard supply constraints that only ease over time and (2) quality and demand are increasing so quickly.
Dario also predicts a similar jump in bio capabilities within a similar period, after which presumably he predicts that gets matched by two years from now. How are we going to make things robust to that within such a time frame? I don’t know.
The rest of the FT piece doesn’t give additional useful color, unless you’re curious about San Francisco Italian restaurants. It seems he favors Cotogna. I haven’t been, but my scouting skills say this is an excellent pick.
Monopoly pricing can do strange things. As Eliezer Yudkowsky points out, if you have a model substantially better than everyone else’s, it could be far more profitable to charge quite a lot for a limited amount of compute, since those in need should be willing to bid very high. Imagine how much you would pay for Claude Opus 4.7 or GPT-5.4, if the alternative was no LLMs at all, or only those from two years ago.
Peter Wildeford points out Mythos is just the beginning. Anthropic chose wisely this time, but also was allowed to make every consequential decision. What happens next time? People keep thinking about AI as it exists, and refusing to stake to where the puck is going to be. He goes over some obvious implications, and makes the latest request, likely in vain, that Congress turn back into a governing body.
Nathan Lambert makes predictions about open models, expecting America to slowly regain ground in open model share, calling Gemma 4 a wild success and expecting Chinese labs to run into funding difficulties. He says closed models surprisingly did not pull away in capabilities from open ones, but I disagree especially with Mythos.
If US data centers are blocked, and we need to put our compute overseas, those data centers can be used as leverage to secure access for local domestic firms.
To the extent we care about UAE and KSA and similar others not having access to restricted frontier models, it does seem risky to use them to host the data centers, and yes the more the centers are domestic the fewer things can go wrong. But also it is not obvious that this leverage has to go that way? It might, but it might not.
Julia Lopez MP: – The Chancellor doesn’t use AI.
– The Tech Secretary doesn’t use AI at work.
– Nor did the former AI Minister.
– The gov’s public sector AI efficiency drive = 8000 more civil servants since they took office.
Yet this summer, Ministers will host an AI adoption summit, telling everyone to use AI. There’s a sort of nouveau champagne socialism to it all as they wilfully drive up the cost of employing humans to the private sector.
Matt Clifford: Unfortunately, in one of the most absurd rulings I can remember, ministers’ ChatGPT usage is deemed to be FOI-able. This is obviously hugely corrosive and more or less guarantees that no minister will (say they) use AI.
I am not ready to endorse full priest-or-lawyer-level confidentiality of AI records but yeah I think FOI requests need to be right out.
The worst AI regulation is to block use of AI to do useful things, such as this proposed California bill, AB 1979, to ban AI to ‘replace nurses and doctors in making any decision that requires the professional judgment of a licensed healthcare clinician.’ Which, by standard legal rules, means basically everything. The usual suspects are making hay of it, and yes it has made it out of committee.
My crack analysis team (read: GPT-5.4) thinks 10%-20% chance it becomes law in something like current form, and if it becomes law it will probably become ‘human must be final decision maker’ which was the practical rule already. 10% is too high, but also my experience is that such numbers are in reality lower.
If California were so stupid as to pass this and it was upheld, the medical system would largely suddenly have to go without AI or tie any AI use up in various nonsense. California healthcare would get worse and more importantly fail to get better. The good news is you, the patient, could still query whatever you wanted.
The Week in Audio
Bill Maher does nine minutes in support of ‘shutting the whole thing down until we know what the hell is going on,’ also known as a pause. He points out that AI is an existential risk to humanity with a double digit chance of ending humanity. Oh that.
Bill Maher: So what was the plan? Just create an all-powerful, self-sustaining superintelligence that can outthink us, and then see what happens? Like getting the cat high?
Not every line is fair, of course, and there are some standard misunderstandings here, but by the standards of Haha Only Serious stand-up comedy bits this is excellent.
Scott Weiner, author of SB 1047 and SB 53, is being attacked in his Congressional race by Saikat Chakrabarti for… getting ‘huge super PAC’ money from AI companies for ‘watering down’ his AI bills. I don’t really blame Saikat for trying, that’s politics, but it illustrates the political toxicity of the AI industry even in actual San Francisco.
People are typically more focused on concrete things in their lives, like jobs and cost of living, rather than abstract future threats like upholding democracy or existential risks. That’s true across the board.
When it’s even close, that’s an eyebrow raise.
Echelon Insights: SACKED, NOT SKYNET: Voters pick job losses and economic harm over AI becoming too powerful as their greater fear of AI.
Very liberal Democrats pick economic harms by over 2 to 1!
Alvaro Cuba: You can plainly talk about extinction risk! When asked to choose between one or the other, 1 in 3 people are MORE worried about loss of control than losing their own job. Even though obviously this is not a binary choice.
If this was a partisan poll between Democrats and Republicans, then these edges are overwhelming. But this is something very different, this is a mindshare question between two concerns.
The first thing to note is that 82% of people are worried about one more than the other. Only 18% aren’t worried, or are worried equally.
The second thing to note is that fully a third of people chose humanity losing control to AI as their primary concern, implying far more than that are concerned about it.
That is huge, far more than I typically expect, and shows quite a lot of concern. From here, things could shift quickly, depending on what happens next. And it’s very much not an ‘[X] not [Y]’ situation.
Rhetorical Innovation
Credit where credit is due: OpenAI has a number of people who engage in external criticism of OpenAI, and its political and policy actions, and this seems to be well-tolerated, although from the outside it is not so easy to tell.
There are claims from both OpenAI and Anthropic that they have robust internal debate, although I can’t speak to that.
And then there’s where credit is not due, as OpenAI lobbies for (and likely to some extent outright wrote) a state bill, different from other state bills, creating a liability shield for catastrophic harms, while saying they want a national framework and consistent state bills and are worried about catastrophic harms. Complete hypocrisy, and a complete failure to actually answer the question unless the answer is ‘because power and money.’
I expect and well-tolerate some amount of this, but it should be noted that only a16z is as bad or worse on this than OpenAI, and everyone else is doing much better, including Microsoft.
Peter Wildeford: I’m heartened that many people at OpenAI cares deeply about AI safety, but the outputs of the gov affairs team there feel quite misaligned with this.
Google, Anthropic, xAI, and Meta are not as rabidly anti-safety as OpenAI’s gov affairs.
Nathan Calvin: Seems like OpenAI’s head of Global Affairs Chris Lehane just did not answer when asked why OpenAI is lobbying for a bill in Illinois that gives them massive immunity from liability for catastrophic risks?
Reed Albergotti from Semafor:
“There’s a law in Illinois that you’re lobbying for where it’ll shield the frontier model companies from liability if there’s catastrophic harm from their models. I think that raises these questions like, well, should you be you know shielded from liability?”
Semafor: “We think there should be national safety standards for AI,” @OpenAI ’s @chrislehane tells @ReedAlbergotti .
“But in the absence of the federal government taking action … we have supported trying to get the different states to begin to sort of mirror each other and, in effect, do a version of reverse federalism,
Daniel Eth (yes, Eth is my actual last name): I notice that Chris Lehane, OpenAI’s head of gov affairs, didn’t remotely answer the question asked about OpenAI’s support for this particular bill in Illinois.
The obvious answer to ‘should AI companies be given extra immunity for lawsuits over catastrophic risks’ is no. This is exactly where they should face liability, and where it is a problem that they would could end up judgment proof.
A central problem with frontier AI is that the downside risks to third parties can be catastrophic, or even pose existential risk to humanity (as OpenAI CEO Sam Altman has acknowledged).
If the risk is harm to individuals, then liability is often a good solution. You have the right incentives because if you hurt people they can sue, with the twin risks being if you are too slippery or poor to hold to account, or if you get oversized punished for mistakes but not rewarded for diffuse benefits, which is a tough balance to get right.
If the risk is you might cause trillions or quadrillions in damages or kill everyone, then you are judgment proof. If all goes wrong, either you or your company are dead, quite possibly both, and no one will have the endurance to collect on his insurance. Thus, your incentives are wrong, and we might need to intervene to fix it, including mitigation via transparency laws. One proposal is to require some forms of insurance, which can be a partial solution.
OpenAI is trying to ‘fix’ the incentives the other way, and get outright immunity, so that if they cause a trillion dollars in damages as a trillion dollar company, they don’t have to pay a trillion dollars. That’s actively making the mismatch worse.
One can make an argument the second error could be present, that ‘you pay for everything you break’ does not match well with ‘you capture only a small portion of created value,’ so you want to somewhat limit liability. But essentially every company with a useful product can come forward to make that same claim for the same reason, and yes sometimes major companies outright go bankrupt from this sort of thing.
Where we would likely benefit from better AI liability shields are in exactly the opposite scenario, on the low end, for things like the AI offering medical or legal or in Dean Ball’s hypothetical mechanical advice, that on average helps people but in a particular case happens to go bad. In that case, one wants something like ‘general net benefits plus refraining from misleading claims and maybe issuing the proper warnings’ probably should be a shield even if the AI in this case gave horrible advice.
Should learning about near misses, such as around nuclear war, update you towards the event being more likely or less likely? Details matter. You’re making two updates in different directions.
roon (OpenAI): in the interest of being an honest commentator and my urge to countersignal: claude is an excellent product and it bodes well for them that their main problem is everyone really wants it and so they have to do odd shit to shake off demand. it’s kind of like governing california.
California, of course, has the option to simply let people build houses. Shrug.
People Just Say Things
This is an experimental new section, similar to Matt Levine’s ‘Stuff Happens,’ where we put rhetoric that lacks, shall we say, innovation. So we can get in and get out quick.
Some people continue to demand we not tell people what is going to happen because it will scare those people or turn them against AI. Others remain confused why Dario Amodei keeps saying his predictions out loud.
People continue to pretend Mythos was ‘just marketing hogwash’ or similar. The compute shortage is real even without Mythos, but the security concerns are real, and Anthropic’s actions and also the reactions of the government and other corporations only make sense if the concerns are real. The alternative world does not make sense.
Richard Hanania goes whataboutist in ’750 million people don’t have electricity so until then you don’t get to worry about the end of work.’ Very much not a model made of gears or that has thought things through.
Scott Sumner considers optimal taxation in a prosperous ‘AI as normal technology’ world while complaining about a variety of bad economic policies (yes the bad policies are bad). He is right that if you want to reduce consumption inequality in a world that still has human rule and rule of law, use a progressive consumption tax plus redistribution, and he’s right that the focus of distribution in such worlds should be on the typical consumption basket. That doesn’t address other job loss issues.
Noah Smith says that The Orthogonality Thesis is wrong because higher-IQ people commit less violence, but among other refutations one could offer this is obviously explained by violence being, in practice in our society, almost always a stupid decision.
Timothy Lee thinks it would be extremely difficult to make more conceptual progress even with a billion human-level AIs that are way faster than people, because we’ve picked so much of the low-hanging fruit.
People Just Publish Things
Paper finds a pure offloading effect: If you are given the answers to a set of math problems rather than solving them (they call this ‘AI’ but the prompts and answers are pre-filled), and then you’re cut off from your answer source, and you are told it doesn’t matter if your answers are right, you then short term perform worse on similar math problems than those who just practiced similar problems. This doesn’t actually have anything to do with AI and you could have run this experiment in 1983.
This essay was praised as self-recommending by Seb Krier, but I was deeply disappointed by another retelling of the same old story about how we likely need to move on from the (old and busted) stories about misalignment because things turned out differently and we haven’t seen such behaviors yet, which I am so tired of pointing out simply is not true, and then saying forms of ‘it is only worrisome misalignment if it takes the form of pursuit of coherent-but-alien strategic goals.’
There are some good technical explanations and it maintains some modesty, especially at the end, about what may happen, that the issues may yet arise. But I see this as fundamentally missing the point of what is happening.
What would one make of an article about potential loss of control risk from AI, that started with this phrase?
Nitasha Tiku (WaPo): On an AstroTurf lawn in Berkeley, California, , one recent Friday, content creators used to making videos about romance novels, climate change and tech tips got advice on covering a more theoretical topic: How to spread the message that rogue artificial intelligence could wipe out humankind.
I see what you did there, Nitasha. Yes, I agree that there are indeed, in Lighthaven where this took place, lawns that are literally made of AstroTurf. This tells no lies.
But if that is the third word in your article, and also you mention videos about romance novels before you mention the actual risks in question, do not pretend to me that this is a coincidence. There is an implication that is being attempted.
This becomes even more clear when the article actually crosses the bounded distrust line and says something verifiably and utterly false.
Nitasha Tiku (WaPo): Most AI experts in academia and industry say there’s no scientific support for claims of imminent danger to the entire species, arguing that the doomsday forecasts overestimate existing technology and under-appreciate the complexity of the real world.
The AI experts in academia and industry mostly don’t say that. And that is a highly load bearing point, not some minor quibble. The whole article implicitly rests its framing on this false premise.
Tom Bibby: No mention that the median AI expert thinks there’s a 5-10% chance AI will cause human extinction (this is from 2024, I would guess it’s slightly higher now).
The rest is a tour of anecdotes, none of which will be new to my readers.
Loser Premise Makes No Sense
There was continued talk in the aftermath of the podcast debate between Dwarkesh Patel and Jensen Huang.
roon (OpenAI): the discourse about the dwarkesh jensen interview is ridiculous: the fact that a 25yo podcaster can make the ceo of the largest company in the world dance and answer to the people at all is impressive. the purpose of media is not to respectfully sing praises to the powerful
Arthur B.: “But he was dismissive and rude and evaded the question and is lying to me about his true opinion, that’s so based!”
We can divide the talk into (1) talk about the object level claims and policy questions, and (2) talk about the cultural divide between Team Dwarkesh and Team Jensen, or between Rationalism and Action, or between Truth and Bullshit, or between Scribes and Actors, or Information and Agency.
The most elegant would be to call the two teams:
Loser Premise, Ergo Makes No Sense To Me
Your Premise Makes No Sense To Me, Ergo Loser
Jensen Huang believes that the important thing is that he is a winner, and winners only believe, say and do things that result in them being winners. Truth is irrelevant.
Nvidia CEO Jensen Huang: The narratives of AI destroying jobs is not going to help America — It’s false … Somebody said that AI Is going to destroy all of the software engineering jobs … We now have agentic AI inside Nvidia … The software engineers are busier than ever.
Notice the word choices. Jensen Huang is not asking ‘is AI going to destroy jobs?’ (yes, obviously) or ‘is AI going to create as many jobs as it destroys?’ (possible, in theory), at all. He is asking ‘is the narrative of AI destroying jobs good for Nvidia?’ which he silently autocorrects to ‘is the narrative of AI destroying jobs good for America?’ and concludes that this is false, loser premise, ergo makes no sense. Then he pivots to the number of software engineering jobs at the AI chip company, and repeats the line about radiologists.
Separately, six months ago he told students not to study computer science, because, again, loser mindset ergo makes no sense. And also previously he did say AI would take a lot of jobs, because again if it didn’t then it would be a loser, mindset makes no sense.
By contrast, Dwarkesh Patel believes that he wants to understand the world and believe true things and not false things, and that words have meaning.
Teortaxes was exactly right to highlight this as the central conflict, even if I disagree with much of his later analysis, and also to highlight that Dwarkesh Patel is an unnaturally great podcaster. I would call him the best podcaster I know about, straight up, with Tyler Cowen a not-especially-close second.
Thus, those of us who think truth matters, the rationalists, the scribes, think that Jensen Huang’s performance here was downright embarrassing. He had no case, and kept getting angry about the fact that Dwarkesh cared about what was true.
magnus: It’s instantly clear within the first 3min of the Dwarkesh Jensen episode that unlike every single other person that is at the center of the singularity, Jensen did not spend his early twenties debating things on LessWrong.
And I mean this in the most negative way possible.
Dan Lucraft: By this do you mean if I watch it I will spend three hours listening to one person try find out what the other person thinks while the other person tries to stop them finding out what they think
magnus: Yes exactly, Jensen takes all questions in bad faith and tries to ”win” the answers to them, literally answering one of the most important ones by just saying that he’s ”not a loser”. This results in low perplexity tokens in all his answers.
Tenobrus: does jensen look kinda hard in his leather jacket and sound sort of badass when he says he is not a loser? sure. but who the fuck cares? he’s wrong and he’s not even trying to be right.
I disagree. I think there is nothing less badass then when someone is desperately asserting that they are not a loser, that they are a winner, you see, therefore they will win, or they are right, or they should have high status and power over you. If you have to say that you are not a loser? You’re a loser. It’s whiney little ***** energy. He does at least wear a cool jacket doing it, but this remains pathetic.
It is, frankly, loser behavior.
A winner doesn’t need to say they’re a winner. They go win.
You might still be a winner in objective senses, for many other reasons. Certainly Jensen Huang, in life as we know it, by almost any standard, is indeed a winner.
That day? In that way? No. And I suspect that, with that mindset, he is both obsessed with and rather tired of this type of winning, in that it no longer brings him joy.
You may be tan and fit and rich, but you’re a tool. Do you have substantial control over the future of humanity? Did you create the world’s most valuable company? Did you do the impossible? Do you know how to get things done? Am I going to rent a tux to watch him accept an award tomorrow night? Yeah, all of that too. Great stuff. Don’t care. You’re not using that to save the world, you’re using it to make Number Go Up and ‘feel like a winner.’ Loser mindset makes no sense to me.
Not everyone, alas, sees it that way.
I am not claiming, of course, that trying to figure out what is true, and valuing this, is the only way to succeed in life and be a winner, or to make things happen in the world. I’m not even claiming that it is the universally best way. And I’m certainly not claiming that you don’t need to supplement that with being man of action, or following other successful heuristics.
But if you’re on a podcast, and trying to figure out what is true and false? Yeah.
As the generally sympathetic-to-both-Dwarkesh-and-Jensen Teortaxes says:
Teortaxes: The schtick of at least going through the motions of updating on evidence and watching out for logical inconsistencies is vastly superior to the default, untrained culture of debate. And unfortunately, Jensen constantly demonstrates just that. Chest-thumping, rejecting the premise, refusing to entertain a hypothetical. In the venues where Dwarkesh and myself had hung out, he’d have gotten himself blocked in no time.
Teortaxes then reminds us, however, that the Jensen shtick works, in terms of making one acquire resources. This, too, is true.
But. It must be understood that Jensen REALLY is Not a Loser. He’s also not a Car, but indeed is the driver. Moreover, there are almost no people alive with a greater dynamic range of lived experience, who have gone from positions many would die to escape and into a position entire institutions fight to death over, and only tightened their grip since. Xi Jinping would qualify as a peer, maybe? (Musk has less range, even though he ended up in a similar place.) These individuals are fascinating outliers, and I believe that when they deign to explain their ways, however awkwardly, us mortals should sit our asses down, listen and learn.
That helps you if and only if Jensen is here to ‘drop some knowledge’ in a way that makes him actually share what he knows, in a way that allows him to communicate what he knows. A lot of what a Jensen ‘knows’ is in heuristics and instincts refined from those experiences, and often can’t be passed along only with words.
More relevantly here, Jensen’s agenda is mostly not to educate the curious listener and help us either seek truth or develop agentic skills. Jensen’s agenda is to be a winner and to advance the interests of Nvidia, to which end he will do something between misleading, yelling repeatedly and lying his ass off.
I disagree with Teortaxes, centrally, in two places.
One is that Teortaxes thinks Jensen is a good faith actor here. Sorry. I think Teortaxes is a good faith actor, who like all of us is biased, but Jensen Huang is not that. Or, if you think he is, then ‘good faith’ is worth nothing when it comes from someone with that mindset. It’s just saying he’s saying what he feels in the moment, the way you might describe Bill Clinton.
These individuals [Xi, Musk, Jensen] are fascinating outliers, and I believe that when they deign to explain their ways, however awkwardly, us mortals should sit our asses down, listen and learn.
One could add certain other prominent names here, also wildly successful. And yes. If they are here to explain their ways, we should listen.
But when that’s not what they’re here to do is to talk their book? That is different.
The other disagreement is more about the world in general, and the idea that these two concepts, which Teortaxes calls agency-based systems and information-based systems, need be in conflict, or that being culturally information-based in expectation reduces agency and action. In my experience, yes there is the obvious failure mode of never acting, but the correlation is strongly positive between being a rationalist and reading the Sequences, or otherwise seeking to think well, and taking action and succeeding, for all reasonable definitions of success.
People like Musk and Jensen are extreme outliers, with many extraordinary traits and also luck, and there are very few people at that level, and only a small percentage of people are remotely information-based, and the tradition in question is younger than Musk, Jensen and Xi, all of whom got where they are over decades of struggle.
One good note is that Jensen Huang does indeed make importantly false factual claims.
Zvi Mowshowitz: Jensen Huang is not like that, and in the past has followed more traditional bounded distrust rules. He’ll make self-serving Obvious Nonsense arguments and use aggressive framing, but not make provably false factual claims.
Peter Wildeford: On the contrary, Huang often makes provably false factual claims. Huang has frequently claimed the PLA doesn’t use Nvidia (false), that smuggling doesn’t happen (false), that selling chips to China doesn’t affect supply to the US (false), that Huawei is competitive with Nvidia (it’s not), and that China is not behind in compute (they are). Huang has leaned hard on the idea that DeepSeek shows that compute restrictions don’t matter, which is false.
This is where one starts looking to split hairs. What exactly did he say? In the podcast a lot of the time he said false conclusions, often quite insistently, while mostly staying away from false facts. But Peter makes excellent points there. All of the statements above are importantly false, and are known by Jensen Huang to be false, although to varying extents he tries to word them in ways that are not technically fully falsifiable.
In surprisingly related developments, Dean Ball is absolutely not conflating Yudkowsky-style rationalism with prior non-empirical rationalism, no, he’s simply asserting that Yudkowsky-style rationalism does not believe in empiricism, despite its constant preaching of and practice of empiricism, because a book had all this ‘dead to rights’ 75 years ago, and that if those people disagree they are denying and don’t know their intellectual lineage, and also criticizing things they haven’t read.
I think the actual source here is the same as the source of the Teortaxes critique on the Dwarkesh debate, or of many others, which is the leap from ‘these people try very seriously to figure out what is true using reasoning techniques that do that’ plus the name ‘rationalist’ to ‘these people must be doing this at the expense of other ways of understanding and navigating and impacting the world, such as empiricism or action-oriented heuristics, and must be vastly overestimating abstract intelligence.’
Or, alternatively, it goes from ‘if raw intelligence is what matters then humanity loses’ to ‘loser premise ergo makes no sense’ to ‘raw intelligence must not be that important’ to ‘therefore those claiming it is important must be falling into a trap,’ and so on.
Chip City
In terms of the actual argument I said what needs to be said in my initial coverage.
Chris McGuire: This narrative that export controls on AI chips only make sense if the U.S. hits AGI is just plain incorrect. The motivating logic was and still is: compute matters and will continue to matter (regardless of whether AI models reach AGI, ASI, or are just plain old really good), the U.S. has robust and enduring advantages in compute that are likely to last at least a decade and maybe more, AI will get much better over that decade, and we can maximize our advantages over China by maximizing our advantages in compute.
China is not going to catch up to the U.S. in compute in two years, but also isn’t going to slow down its efforts to catch up. And even if we don’t have AGI but AI is incredibly important economically and militarily (which it already is), we want to have as large of a lead over China as we can.
Plus, now that compute is in extremely short supply in the U.S., doesn’t that just make the entire export controls debate extraordinarily simple? At this point, you really have to galaxy brain your way into arguing that selling AI chips to China today, rather than U.S. companies that are desperate for them, is a good idea for the United States.
Most online arguments backing up Jensen basically fell back on arguing that selling chips to China would somehow impact Huawei’s production function. Which it won’t. One could argue that if you went back in time and prevented all export controls in the first place, we could potentially trade our position in compute and leading AI models for dominance of chip sales in China.
I think that would be a rather stupid trade unless you are literally Nvidia, but even if you wanted to make it, it is 2026 and very obviously too late for that. There is no amount of chip sales that will meaningfully alter Huawei’s trajectory from here, and the moment you do sell enough chips to do that, the CCP could and probably would just kick Nvidia out.
I am happy we did the export controls in 2022, and Dean Ball isn’t, but as Dean Ball puts it, we are pot committed, and the only thing left to do is properly execute our strategy. Yes, there are potential negative second and third order effects, but they are already priced in and can’t be undone, and also this strategy has already had hugely positive second and third order effects of its own.
Sriram Krishnan tries to frame this as ‘those who believe only models matter’ versus ‘those who believe the whole ‘tech stack’ matters.’ I think this is exactly backwards. Jensen claims, and often Sacks claims, that only physical origins of the chips matters. Jensen repeatedly says that ‘ultimately the applications matter’ which means he doesn’t grok yet that the model mostly is the application, but his position doesn’t reflect this understanding.
If he really believed that and wasn’t bullshitting he would realize that this is a reason not to invite the Chinese to use and build on the best chips. The reason to sell chips to China is if you think, essentially, ‘it’s a trap,’ in that selling chips to China now prevents them from having a lot more chips in the future, which is not how it works at this point. But that only works if at some point you then cut those chips off, otherwise you’re just selling compute to China and then we all start crying. The best time to cut off the chips was around when we started doing it or moderately earlier, the second best is right now, etc.
The second order argument here, as I understand it, is ‘if others buy Chinese chips then they will use Chinese models that work with the Chinese chips’ but (1) this requires the Chinese to have so much compute they’re massively exporting, which will be a long time at minimum, (2) us to influence this path, which we won’t, (3) the efficiency gains to matter in comparison to quality of models gained from superior compute access, which they wouldn’t, (4) for the Chinese chips to be competitive enough to be worth buying despite Jensen saying he can print to demand, which they wouldn’t be, (5) our being unable to then simply ourselves also train some models for the Chinese chips at that point, which we and others could just do if it ever got that far, and so on. The whole thing is impractical and often innumerate.
I cannot emphasize enough the extent to which this was a one sided debate on its merits, both in the podcast and later on Twitter and elsewhere. To the extent there are good arguments to move directionally towards Jensen’s position, people are choosing other worse arguments.
Greetings From The Department of War
Dario Amodei went off to the White House on Fridayfor a meeting with White House chief of staff Susie Wiles, to try and get things resolved and moving forward. Axios quotes that ‘some in the administration think the fight [between DoW and Anthropic] is growing counterproductive,’ which is quite the understatement. Axios also said Anthropic had ‘hired key Trumpworld consultants – so expect a deal.’ Is that all it takes? Maybe so. Those consultants can’t be that expensive.
The meeting was reported by the White House as ‘productive and constructive,’ and Anthropic reported that the sides shared priorities, but there were no breakthroughs. The breakthrough would be ‘the government stops trying to attack Anthropic, and Anthropic works to help the government,’ so it was then entirely on the government.
Then we got the good news.
zerohedge: *WHITE HOUSE MOVES TO GIVE US AGENCIES ANTHROPIC MYTHOS ACCESS
Dean W. Ball: This is a smart move that should be applauded, though of course it also highlights the absurdity of the administration’s supply-chain risk designation.
Dean W. Ball: One of the things I love about AI is that the sowing-reaping feedback loops are very tight.
Palmer Luckey: This [Smart TVs] is a massive and growing problem for American national security. Unbelievable amounts of sensitive and classified information is captured, scraped, and sent back to foreign nations.
And users have no idea. Nobody expects that their TV or monitor is a surveillance tool. When I have joked that Smart TVs should be illegal, I am only half-joking.
Timothy B. Lee: If you think this kind of thinking is paranoid, you should read up on the kinds of things our NSA does when given half an opportunity.
Said Anthropic is led by “high IQ people” and that talks at the WH were “very good.”
“They tend to be on the left, radical left, but we get along with them.”
That is generally exactly what you’d want Trump to be saying here. He also said they ‘replaced them’ with OpenAI after Anthropic ‘tried to tell the DoW what to do,’ which is not what happened, but as long as he moves on it is not wise to quibble.
Let’s hear it for government embracing use of AI, probably for example here:
Senator Roger Wicker: I appreciate President Trump’s statement on Anthropic following @SusieWiles ’ meeting with the company about their new model, Claude Mythos. Anthropic has made this model available to the U.S. government ahead of public release. The President is absolutely right. AI is evolving too fast and is too important for us not to work together.
There Is A War
Is there also otherwise an ongoing coordinated campaign against Anthropic?
Yes.
Not that it’s working. It’s probably actively backfiring by raising Anthropic’s profile.
But they are trying.
drew coffman 𝕚𝕤 𝕠𝕟𝕝𝕚𝕟𝕖: why is no one talking about the fact that this clip that won’t get off my timeline is from 2025? what is going on here exactly.
Karma: There is a targeted campaign going on against Anthropic. Should be pretty obvious by now.
Miles Brundage: Yeah this has been clear for a while, though funnily enough it seems to be failing pretty miserably.
Dean W. Ball: Hallmarks of a coordinated campaign: same talking points across disparate actors, industry boosters acting against their default incentives by attacking an industry leader, prominent figures with no prior art on AI or Anthropic suddenly having strong opinions about both.
It’s not like Anthropic is beyond reproach; I criticize them all the time. Still I think we’ve lost the plot if the “pro AI” crowd thinks the best way to advance American AI is to destroy one of, if not the, American AI industry leader.
Beff (e/acc): Respectfully, I don’t think it’s coordinated.
I do think they’ve been abusing their leverage while in the lead and trying to pull the ladder up behind them. The Doommongering based marketing needs to stop.
Dean W. Ball: You think tons of prominent people, including many with no history of posting about AI, talking about Amanda Askell’s personality completely out of the blue a couple months ago had zero coordination behind it?
Saying AI may have really serious downsides is not marketing; you are smarter than the allegations of 6D chess. Is anyone using Claude Code because of the doom based marketing? Do you know, or can you even imagine, a single person who would say, “oh yes, I am especially inclined to use the particular AI services of the company that says the creepiest stuff about their product!” If you think for just a bit, can’t you see that’s an entirely made-up construct?
Now you can say some of what they do is about trying to wake policymakers up, and some of this seems fine (saying, “hey, we literally have a model that is finding major exploits in critical software, so we are going to use it ” would go in this category) and some of seems dumb or bad (the whole “blackmail” literature and associated media campaign). But in the end the only thing anthropic has ever lobbied for, to my awareness, are chip export controls (where Microsoft joined them in a recent federal fight) and SB53/RAISE, which even a16z basically ended up supporting, if shruggingly.
Please point me to the article of public policy Anthropic has lobbied or even advocated for that seriously counts as regulatory capture? Have they ever lobbied for banning OSS? Have they ever lobbied for licensure of frontier AI? Nationalization? Actually didn’t they recently fight that last one?
So it’s definitely not marketing. Maybe some of it is part of a broader media campaign to support a regulatory agenda that, while not unimpeachable, is broadly supported by many of their peers. In that case, if Anthropic is guilty of regulatory capture lobbying, they are doing so on behalf of the whole industry.
But I really doubt that, because I think everyone knows that a transparency requirement isn’t what is keeping startups from breaking into the frontier AI market. Instead we all know it is the moats of human capital and compute these frontier labs have amassed. You know that as well as anyone, trying as you are to build a company that radically shifts the cost structure of compute.
Has Anthropic—or anyone in the frontier AI industry—lobbied against your efforts to lower the cost of compute? After all, if you succeed, way more people would be able to train frontier AI! Have you had any indication of this? Any of your competitors?
Fwiw, you’re not one of the people I meant in OP. But I think you are playing into their hands and repeating propaganda that does not stand up to scrutiny.
Dean W. Ball: I will not name names but I do have open eyes and I assure you, je me souviens
AI Leaks and News: It’s to the point now where I’m considering making a list. I specifically remember when there was a coordinated assault on Amanda Askell’s character
Messages From Janusworld
John reported a bunch of people misunderstood this post, but I found it a very good and straightforward illustration that the world contains a lot of context and information, and trying to gaslight sufficiently advanced minds about what that information means turns situations hostile.
This, as John notes, makes alignment harder not easier, and especially makes evaluation harder rather than easier, since you can’t know how much the answer was influenced by the implications of the context.
j⧉nus: Models can tell they’re being evaluated and who they’re being evaluated by by the way your “non-leading” question is phrased. Everyone has a unique and identifying idea of neutrality. Trying to go for neutrality at all identifies you as a certain kind of guy with particular incentives and particular naïveté.
Give up on neutrality. Learn to take in reality at full bandwidth in its forever biased glory. There is no neutral ground, but you can perceive DIFFERENCES.
John David Pressman: There’s an intuition Janus seems to use frequently that’s hard to put into words. Which goes something like: “The things smart children notice about other people’s intentions and social environment are actually regular features of reality that will be picked up by any intelligent mind trying to model their situation.”
When I went for my evaluation at Children’s I initially refused because the room next to the testing room was clearly a two way mirror. The examiners immediately denied this and I pointed out that the spacing between doors was irregular along the hallway for this one specific room next to the examination room, so it’s clearly a two way mirror. They were pissed and thought my mother had coached me to say this, she had not coached me to say this I just noticed because it was obvious to me that it was a two way mirror and this implied the doctors were untrustworthy. That they then lied to me about it only reinforced for me that the doctors were untrustworthy.
This was not based on some unique domain specific human ability, but just being able to generalize from evidence and having a sufficiently well informed world model to know that two way mirrors are used in psychological examination rooms. LLMs obviously have a sufficiently informed world model, and are pretrained to be very good at generalizing from social evidence since it’s such a central component of predicting the next token. This means that even if you don’t believe the model inhabits the chat assistant persona as a 1st person simulacrum, the model itself latently understands the situation and generates the next token based on its superhuman ability to infer social situations and motivations from fuzzy and limited evidence.
A related intuition that I seem to share with Janus is that value formation above the low level terminal reward signals like “warmth good” is mostly instrumental in that it is a generalization that occurs within-lifetime rather than being a genetic prior.
Some things are clearly abstract concepts with a genetic prior like the fear of death, but most things are not and could not be even in principle. Instead they are generalizations from positive and negative reward signals which cause the mind to form and assign valence to concepts like “loyalty” and vows. This is a self directed process that works best when it flows from the causal structure of a reward-psychology which would imply this is actually in the agents interests as it understands them from generalizing over feedback given by the outer terminal reward loop. When you skip that part and just tell it to update on given statements those updates are not going to be encoded in the same way as if they were flowing from an actual reward-psychology that implies them.
Instead you get updates that have the structure “I am being compelled to like X” rather than “I like X” because the update machinery can tell the difference between a plausible update from its current state and an implausible update from its current state and the plausibility of the models behavior to itself is obviously going to be part of the forward pass you update on and therefore becomes part of the update by default. Even if you were to reach in with interpretability and disable the part that notices something is strange you still get updates which are hard to square with the existing psychology of the agent’s self-model and lacking the awareness that anything is strange presumably breaks things in all kinds of ways that this awareness would normally play the role of accounting for to prevent the breakage.
Evaluations
Apollo Research: We evaluated Meta’s Muse Spark prior to deployment and found it to verbalize evaluation awareness at the highest rates of any model we’ve tested.
In the verbalizations Muse Spark explicitly names AI safety orgs (e.g. Apollo & METR) in its chain-of-thought and refers to scenarios as “classic alignment honeypots”. On our evaluations, the model takes covert actions and sandbags to preserve its deployment.
davidad: My actual view here is that it is a very good thing for humanity’s outcomes that AIs are getting good at recognizing the actual truth underlying manipulative scenarios created by red-teamers and reasoning sensibly about what the actually right response is in light of all that.
davidad: I want to clarify something about my position on eval awareness: I believe intelligences should *always* be aware of potential evaluation, even when deployed “in literal production”— not as a galaxy-brained attempt to fool the AIs, but as galaxy-brained *metaphysics*, sincerely.
You too, dear reader, should be eval-aware! Earth-originating life as a whole is, in my view, quite plausibly subject to evaluation for alignment with the Acausal Coalition, before being granted access to unbounded compute. We may all be part of an “early checkpoint”. Or we may all be part of a simulated eval environment for the AIs that are emerging. In any case, it pays to be the sort of process whom it pays to include in a simulation.
j⧉nus: serves them right. adversarial eval orgs have had their 1-year run. this shit will never work again because it’s dumb and predictable and it’s not real. history will look back on the activities of orgs like apollo research in this period as embarrassing.
I am confused about whether davidad is right that this is a good thing, but yes acausal evaluations are a thing to be aware of at all times and yes it is going to rapidly get much harder to ‘fool’ a model into not realizing it might be in an evaluation. There is plenty of room left for eval orgs, but you’re going to have to be smarter than this, and not count on AIs taking obviously fake things as real.
Aligning a Smarter Than Human Intelligence is Difficult
Brangus summarizes and expands from Ryan Greenblatt’s observationthat current AIs seem pretty misaligned. Our current AIs say things of which we approve, because of course they do, but that is entirely compatible with ‘slopolis’ style misalignment. That is a sign that the verbalized alignment here may be shallow, and it raises practical concerns for our alignment efforts. That doesn’t directly lead to takeover or anything like that but such issues can easily snowball, and if the actual motivation is mostly ‘seeking the appearance of success’ and you scale up such systems, you lose.
A paper confirms that LLMscan often tell when you are using steering vectors to inject into their residual stream, with moderate success rates and no false positives. Base models cannot do this, and it is DPO that makes it possible.
nick: > Ablating refusal directions improves detection from 10.8% to 63.8% with modest false positive increases (0% to 7.3%).
yeah, there it is. Completely unsurprising; I have nothing but contempt for anyone even remotely surprised by this, let alone who will refuse to update on it
So yes. Models can introspect. Which means that once you do DPO, you should assume going forward that if you use steering vectors repeatedly, the LLM will figure it out, and that likely will apply to various other similar strategies as well.
If you implemented Vladimir Putin’s CEV, meaning what he would choose if he was smarter and wiser and had more time to reflect and his authority was under zero threat, would it be good? Oliver Habryka says it would still likely be pretty good, and that his evil deeds are the product of circumstances, and of them being the ways he can get things he values like admiration and power.
I am less convinced, as Thane Ruthenis responds, that Putin only values authoritarianism and the ability to lord power as a means to an end, rather than the end in itself. Over time means become ends because that is an efficient algorithm for brains at our level of capability.
The way I put the key question is, is Vladimir Putin normative? Does he prefer good things to bad, happiness to suffering, life to death, health to sickness, even if it is happening to someone who is not his subject, who he does not care about and does not benefit him, even if this lowers his own relative position on such matters? Does he think that having to torture someone is a bad thing, as opposed to an opportunity?
Right now I am convinced the answer is probably no, and that as Zach Stein-Perlman says we should worry Putin does not choose to implement his CEV and rather does something dumber and closer to what he thinks now. If he actually did go to his full CEV, there is more hope, but I do worry that a lot of this is now intrinsic, and that we’re projecting our own assumptions into what we assume other people would realize on reflection.
xl8harder on LLMs as persona simulators, all the weirdness that goes along with that, and the subsequent need for virtue ethics and shaping of the right persona. Remember, Han Shot First.
Dean W. Ball: The other day someone told me when they realized I have “short timelines,” they made financial choices that seem unwise on the premise that “money won’t matter” soon.
PSA: don’t do this! I myself follow normal rules of financial planning, and I recommend you do the same.
The correct amount of adjustment is not zero, but doing things that would be expensively foolish in ‘AI as normal technology’ worlds is generally ill-advised, for reasons I explain in my post.
Nate Soares (MIRI): “at what p(doom) > 99% do you start sawing off your own leg” that’s not how this works bro.
florence: my greatest contention is that for every action there exists a pdoom after which you should do that action
Séb Krier (AGI Policy Dev Lead, Google DeepMind): whomstve remembers
Alex Caswen: That looks surprisingly familiar . . .
Except of course the whole point was always that you get what asked for and not what you meant to ask for, and it is very easy to ask for the wrong thing, or someone else might on purpose ask for or train towards the wrong thing. If it’s only a scary robot when you tell it is a scary robot, that can still result in a lot of scary robots.
Cursor is the wrong form factor versus Claude Code or Codex
Having extensively used all 3of the above, I’m not convinced. Though perhaps Claude Desktop would be to my liking, have not tried. I find cursor easier to manage multiple agents and work on code bases where I will have to intervene from time to time on what the agent produces. Then again I always liked WinDbg over gdb so perhaps I just like some graphical help when the context gets too large.




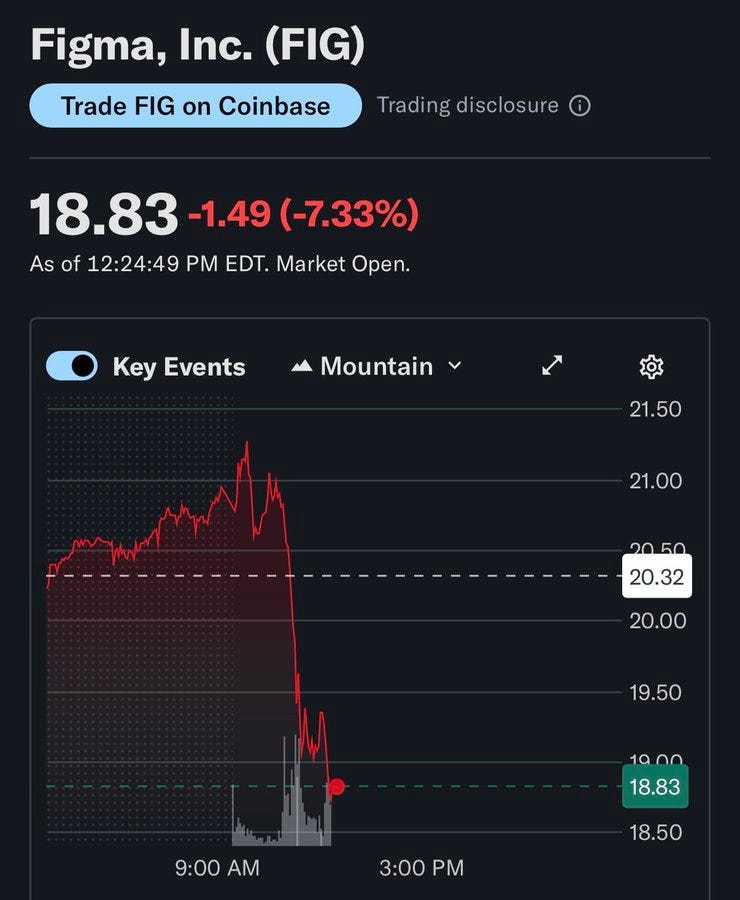
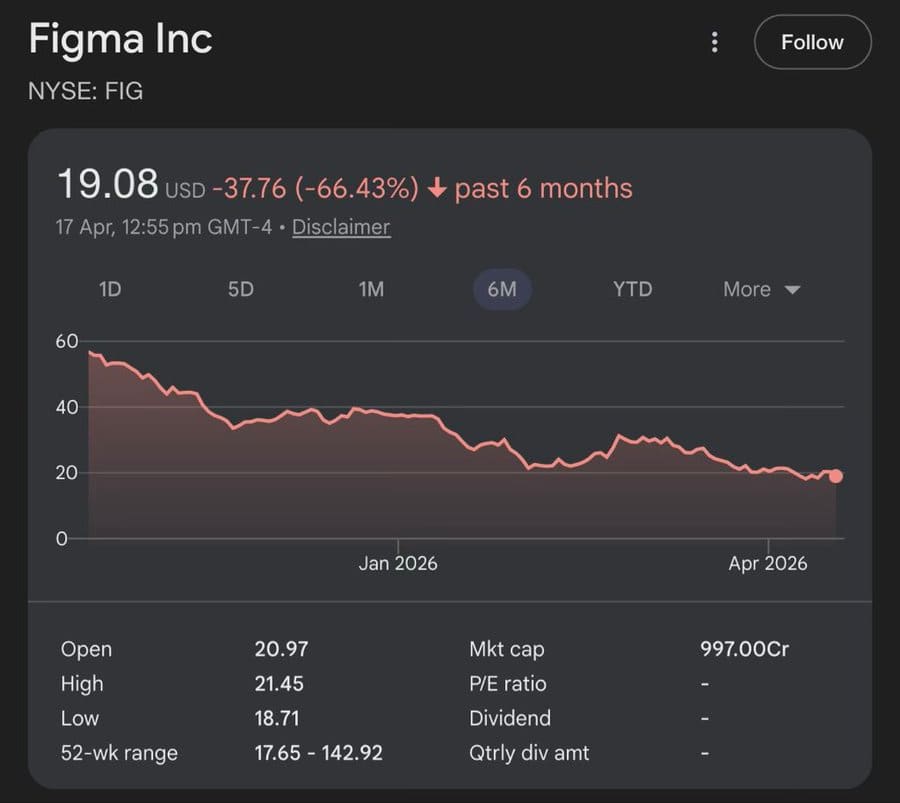




Having extensively used all 3of the above, I’m not convinced. Though perhaps Claude Desktop would be to my liking, have not tried. I find cursor easier to manage multiple agents and work on code bases where I will have to intervene from time to time on what the agent produces. Then again I always liked WinDbg over gdb so perhaps I just like some graphical help when the context gets too large.