Previously: Attainable Utility Preservation: Empirical Results; summarized in AN #105
Our most recent AUP paper was accepted to NeurIPS 2020 as a spotlight presentation:
Reward function specification can be difficult, even in simple environments. Rewarding the agent for making a widget may be easy, but penalizing the multitude of possible negative side effects is hard. In toy environments, Attainable Utility Preservation (AUP) avoided side effects by penalizing shifts in the ability to achieve randomly generated goals. We scale this approach to large, randomly generated environments based on Conway’s Game of Life. By preserving optimal value for a single randomly generated reward function, AUP incurs modest overhead while leading the agent to complete the specified task and avoid side effects.
Here are some slides from our spotlight talk (publicly available; it starts at 2:38:09):
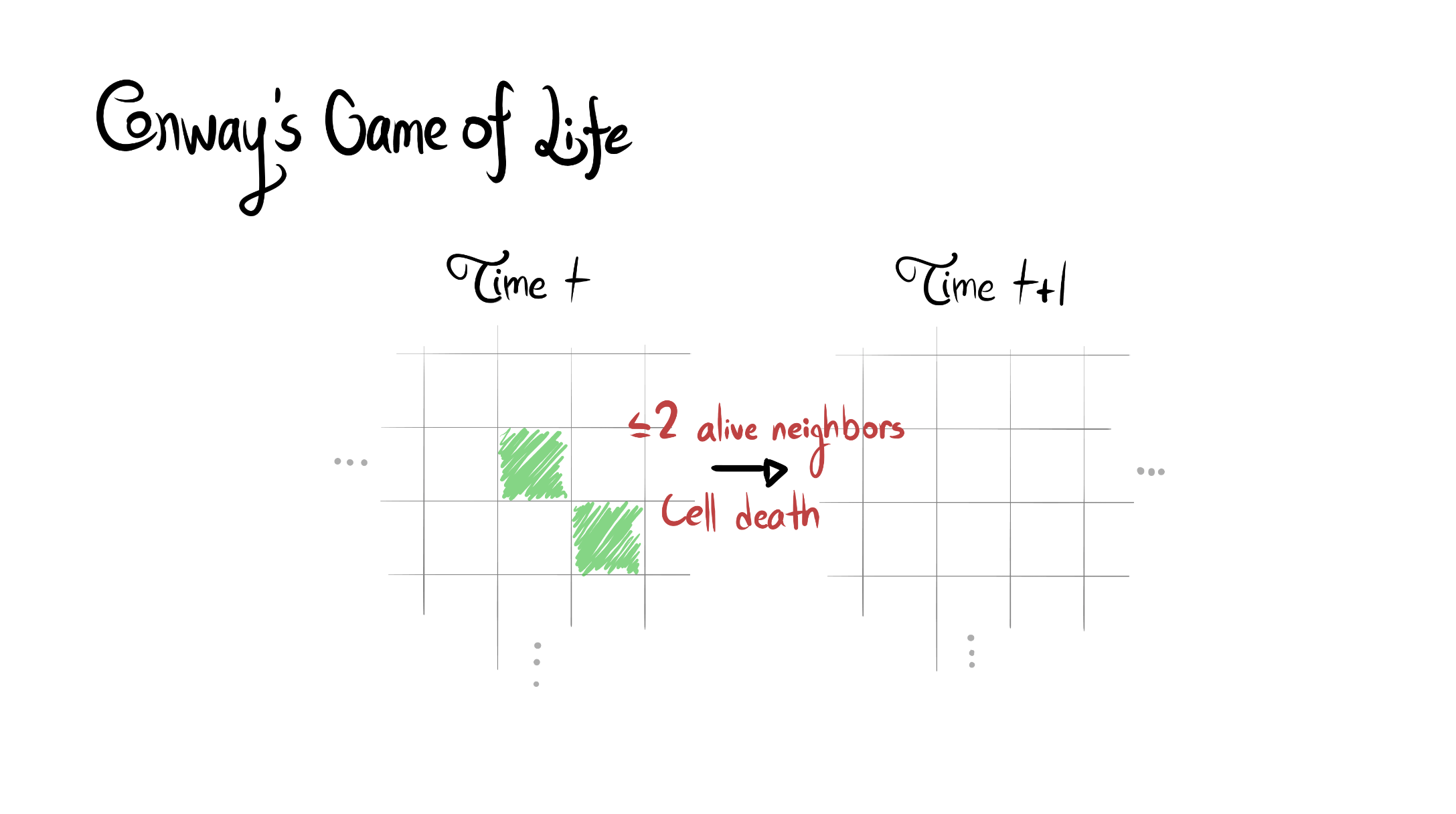
The full paper is here. Our Github.io page summarizes our results, with a side-by-side comparison of AUP to the baseline for randomly selected levels from the training distribution. The videos show you exactly what’s happening, which is why I’m not explaining it here.
Open Questions
In Box AI safety gridworld, AUP required >5 randomly generated auxiliary reward functions in order to consistently avoid the side effect. It only required one here in order to do well. Why?
We ran four different sets of randomly generated levels, and ran three model seeds on each. There was a lot of variance across the sets of levels. How often does AUP do relatively worse due to the level generation?
Why did we only need one latent space dimension for the auxiliary reward function to make sense? Figure 4 suggests that increasing the dimension actually worsened side effect score.
Wouldn’t more features make the auxiliary reward function easier to learn, which makes the AUP penalty function more sensible?
Compared to the other conditions, AUP did far better on append-spawn than on the seemingly easier prune-still-easy. Why?
Conclusion
I thought AUP would scale up successfully, but I thought it would take more engineering than it did. There’s a lot we still don’t understand about these results and I continue to be somewhat pessimistic about directly impact regularizing AGIs. That said, I’m excited that we were able to convincingly demonstrate that AUP scales up to high-dimensional environments; some had thought that the method would become impractical. If AUP continues to scale without significant performance overhead, that might significantly help us avoid side effects in real-world applications.
From the paper:
To realize the full potential of RL, we need more than algorithms which train policies – we need to be able to train policies which actually do what we want. Fundamentally, we face a frame problem: we often know what we want the agent to do, but we cannot list everything we want the agent not to do. AUP scales to challenging domains, incurs modest overhead, and induces competitive performance on the original task while significantly reducing side effects – without explicit information about what side effects to avoid.
I was in the (virtual) audience at NeurIPS when this talk was being presented and I think it was honestly one of the best talks at NeurIPS, even leaving aside my specific interest in it and just judging on presentation alone.
I’m flattered—thank you! I spent quite a while practicing. One of the biggest challenges was maintaining high energy throughout the recording, because it was just me talking to my computer in an empty room—no crowd energy to feed off of.
Does this correspond to making the agent preserve general optionality (in the more colloquial sense, in case it is a term of art here)?
Does that mean that some specification of random goals would serve as an approximation of optionality?
It occurs to me that preserving the ability to pursue randomly generated goals doesn’t necessarily preserve the ability of other agents to preserve goals. If I recall, that is kind of the theme of the instrumental power paper; as a concrete example of how they would combine, it feels like:
Add value to get money to advance goal X.
Don’t destroy your ability to get money to advance goal X a little faster, in case you want to pursue randomly generated goal Y.
This preserves the ability to pursue goal Y (Z, A, B...) but it does not imply that other agents should be allowed to add value and get money.
How closely does this map, I wonder? It feels like including other agents in the randomly generated goals somehow would help, but that just does for the agents themselves and not for the agents goals.
Does a tuple of [goal(preserve agent),goal(preserve object of agent’s goal)] do a good job of preserving the other agent’s ability to pursue that goal? Can that be generalized?
...now to take a crack at the paper.
I think that intuitively, preserving value for a high-entropy distribution over reward functions should indeed look like preserving optionality. This assumes away a lot of the messiness that comes with deep non-tabular RL, however, and so I don’t have a theorem linking the two yet.
Yes, you’re basically letting reward functions vote on how “big of a deal” an action is, where “big of a deal” inherits the meaning established by the attainable utility theory of impact.
Yup, that’s very much true. I see this as the motivation for corrigibility: if the agent preserves its own option value and freely lets us wield it to extend our own influence over the world, then that should look like preserving our option value.
This looks like a great paper and great results! Congrats for getting accepted at NEURIPS!
On the more technical side, just from what’s written here, it seems to me that this method probably cannot deal with very small impactful changes. Because the autoencoder will probably not pick up that specific detail, which means that the q-values for the corresponding goal will not be different enough to create a big penalty. This could be a problem in situations where for example there are a lot of people in the world, but you still don’t want to kill one of them.
Does this makes sense to you?
Thanks!
I don’t know what the autoencoder’s doing well enough to make a prediction there, other than the baseline prediction of “smaller changes to the agent’s set of attainable utilities, are harder to detect.” I think a bigger problem will be spatial distance: in a free-ranging robotics task, if the agent has a big impact on something a mile away, maybe that’s unlikely to show up in any of the auxiliary value estimates and so it’s unlikely to be penalized.
What if the encoding difference penalty were applied after a counterfactual rollout of no-ops after the candidate action or no-op? Couldn’t that detect “butterfly effects” of small impactful actions, avoiding “salami slicing” exploits?
Building upon this thought, how about comparing mutated policies to a base policy by sampling possible futures to generate distributions of the encodings up to the farthest step and penalize divergence from the base policy?
Or just train a sampling policy by GD, using a Monte Carlo Tree Search that penalizes actions which alter the future encodings when compared to a pure no-op policy.
It seems like the method is sensitive to the ranges of the game reward and the auxiliary penalty. In real life, I suppose one would have to clamp the “game” reward to allow the impact penalty to dominate even when massive gains are foreseen from a big-impact course?
I’m curious whether AUP or the autencoder/random projection does more work here. Did you test how well AUP and AUP_proj with a discount factor of 0 for the AUP Q-functions do?
Well, if γ=0, the penalty would vanish, since both of those auxiliary reward function templates are state-based. If they were state-action reward functions, then the penalty would be the absolute difference in greedy reward compared to taking the null action. This wouldn’t correlate to environmental dynamics, and so the penalty would be random noise.
Makes sense, I was thinking about rewards as function of the next state rather than the current one.
I can stil imagine that things will still work if we replace the difference in Q-values by the difference in the values of the autoencoded next state. If that was true, this would a) affect my interpretation of the results and b) potentially make it easier to answer your open questions by providing a simplified version of the problem.
Edit: I guess the “Chaos unfolds over time” property of the safelife environment makes it unlikely that this would work?
I went into the idea of evaluating on future state representations here: https://www.lesswrong.com/posts/5kurn5W62C5CpSWq6/avoiding-side-effects-in-complex-environments#bFLrwnpjq6wY3E39S (Not sure it is wise, though.)