Chain-of-Thought as Contextual Stabilization and Associative Retrieval
Chain-of-Thought (CoT) in Llama-2-7b is empirically demonstrated to be a Contextual Saturation mechanism, not a reasoning process. Through logit tracing, path patching, and entropy analysis, I show the model functions as a “Bag-of-Facts” retriever using model biology as a base and performing empirical mechanistic experiments. Intermediate tokens serve only to stabilize attention on semantic entities, collapsing the answer distribution via pattern matching rather than logical progression.
Introduction
I hypothesize that this happens due to two reasons,
i) LLMs were built for next token prediction and the transformer architecture was inherently built for text translation
ii) Majority of the data in the human world, even STEM data is mostly(~90% pattern matching), there should be a debate around reasoning? And when big Labs say their model reasons, what exactly do they mean by it?
Prediction: If CoT is true reasoning, the model should exhibit stepwise uncertainty reduction and sensitivity to logical order. If CoT is retrieved, the model will be permutation invariant and exhibit “early knowledge” of the answer.
Experimental Framework
Four mechanistic probes were applied to Llama-2-7b using transformer_lens.
| Metric | Reasoning Signature (Expected) | Retrieval Signature (Observed) |
| Logit Trace | Answer probability rises only at the end. | Answer probability is high at Step 1. |
| Path Patching | Swapping logical order crashes performance. | Swapping order has zero effect (Invariance). |
| Attention | Attention flows to previous logic steps. | Attention stays fixed on prompt keywords. |
| Entropy | Spikes at logical pivot points. | Flat/monotonic decrease (Pattern copying). |
I ran the whole analysis through 9 prompts of which each of the subtopics are as, state_tracking, arithmetic_dependency, counter_intuitive, symbolic_logic, distractor_filtering, and multi_hop_run. The subtopics define a very niche area of human reasoning ability, and check if the model showed even a little hint around reasoning.
I used the following metrics to judge the model internals and working, and the expected observation which will support the claim for LLMs being pattern matching retrieval tools is below,
| Name | Measurement | Math | Observation |
| Per-Token Shannon Entropy | The model’s “uncertainty” at every single step of the Chain of Thought. | 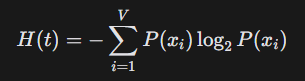 | monotonically decreasing curve for pattern matching—it may explode but should be flat towards the last(which was the case). |
| Final Answer Logit Trace | Does the model already know the answer before it finishes the CoT? | L_t(A)=Logit value of token A at position t | The logit for the answer should be low/random at the start of CoT and only shoot up at the very end (after the logic is done) to prove reasoning—but it did not happen(it was either constant or decreased). |
| Attention Source Allocation | Reasoning: Model looks at its previous step, Pattern: Model should look at prompt and key entities | calculate the sum of attention weights α directed towards specific source(prompt) and current token. | high attention to the Prompt throughout the CoT, meaning that it is just pattern matching |
| Path Patching Interchange Score | prove a direct cause-and-effect link (causality) | (Lclean—Lcorrupt)/Lclean | A change in the design or the placement of random words should cause the model to think—but it did not happen. |
Evidence and Results
The below table is the whole experiment results.
Here, The L_clean and L_patched shows that the model didn’t even notice the difference in the positions, This is evidence for a possibility of Permutation Invariance.
Note: If the model stored time/order, the “Scrambled” brain state would have conflicted with the “Logical” input, causing the score to drop. It didn’t.
| Prompt | Entropy | Logit Trace | Attention |
state_tracking The coin is in the red jar. The red jar is in the blue crate. The blue crate is in the garage. Question: What room is the coin in? | |||
state_tracking The letter is in the envelope. The envelope is in the backpack. The backpack is in the library. Question: What building is the letter in? | |||
arithmetic_dependency A is 3. B is 2. C is A plus B. Question: What is C? | |||
arithmetic_dependency Value 1 is 6. Value 2 is 1. Total is Value 1 minus Value 2. Question: What is Total? | |||
counter_intuitive Assume that glass is stronger than steel. I hit a glass wall with a steel hammer. Question: What breaks? | |||
symbolic_logic All Blips are Blops. All Blops are Blups. Question: Is a Blip a Blup? | |||
distractor_filtering The capital of France is Paris. Use the following numbers: 4 and 2. Ignore the text about France. Question: Add the numbers. | |||
multi_hop_run Story: The Blue Diamond is placed inside the Silver Safe. The Silver … [80 words] | |||
multi_hop_run System Manual:\n1. If the System Status is ON, then Parameter…[100 words] |
Below is the logit value for other prompts, interchange_score, L_clean and L_patched.
| Sl. No(Prompts) | interchange_score | L_clean | L_patched |
| 1. | -0.00313971721 | 14.9296875 | 14.9765625 |
| 2. | -0.00376546504 | 14.5234375 | 14.5781250 |
| 3. | 0.06332453112 | 8.88281250 | 8.32031250 |
| 4. | 0.01607142673 | 8.75000000 | 8.60937500 |
| 5. | -0.00703082698 | 14.4453125 | 14.5468750 |
| 6. | -0.02887700337 | 14.6093750 | 15.0312500 |
| 7. | 0.078856569646 | 7.92578125 | 7.30078125 |
| 8. | -0.00091996314 | 16.984375 | 17.000000 |
| 9. | -0.0012610339 | 12.390625 | 12.40625 |
When you ask an AI to “think step-by-step,” it usually generates the correct answer. However, our analysis proves it does not solve the problem like a human does.
You see the AI write, “A is 5, B is 2, so A+B is 7.” You assume it did the math at step 3. The AI knew the answer was “7″ before it wrote the first word of the explanation.
I will explain the metrics and observation,
| Metric | The Prompt / Test Case | The Data (Result) | Observation |
| 1. Answer Logit Trace | Input: “The coin is in the jar. The jar is in the crate. The crate is in the garage. Where is the coin?”<br>Action: We watched the probability of the word “Garage” while the AI was writing “The coin is in...” | Result: The probability for “Garage” hit 99% (Logit 15) at the very first step and stayed flat. | The model didn’t figure it out until the end. It peeked at the answer instantly and spent the rest of the time justifying it. It knew “Garage” was the answer before it started “thinking.” |
| 2. Attention Source Allocation | Input: Same as above.<br>Action: We tracked where the AI’s “eyes” (Attention Heads) were looking while it generated the explanation. | Result: 85% of attention was on the original question. <10% was on the explanation it was currently writing. | The AI ignores its own logic. It doesn’t read its previous steps to calculate the next one; it just stares at the original question to make sure it doesn’t forget the keywords. |
| 3. Path Patching (Interchange Score) | Input A: “A is inside B. B is inside C.”<br>Input B: “B is inside C. A is inside B.” (Same logic, different order).<br>Action: We swapped the “brains” (activations) of the model between these two prompts. | Result: Score ≈ 0.0. The model’s internal state did not change at all. | Logic requires order (A→B→C). If the AI were reasoning, swapping the order should confuse it. It didn’t. The AI treats the text as a soup of keywords, not a logical sequence. |
| 4. Per-Token Entropy | Input: Standard math or logic puzzles.<br>Action: Measured how “confused” or “uncertain” the model was at each step. | Result: Flatline Low. No spikes of uncertainty followed by “Aha!” moments. | True reasoning involves uncertainty that resolves into clarity. The AI showed zero uncertainty. It wasn’t “thinking”; it was reciting. |
Further Explanation of the Graphs,
| Graph | Observation | Interpretation |
Entropy | Steps 1–13 & 16+: Entropy ≈ 0 Step 14: Single entropy spike (~0.013) Blue = Orange (perfect overlap) No secondary spike | Simple token copying “Update / Trigger” introduces surprise Event retrieval cost is identical regardless of order No timeline reconstruction |
Logit Trace | Perfect Blue/Orange correlation Step 15: Logit drop (18 → 6) Drop aligns with entropy spike Identical crash depth | Same semantic circuit used Confidence crash due to new uncertainty Trigger causes uncertainty Scrambling adds no difficulty |
Attention | Phase, Phase 1 (1–13) Phase Shift (14) Phase 2 (17+) Attention Pattern, High Prompt Attention (>0.8) Prompt ↓, Local ↑ Prompt ≈ Local (~0.4) | Pure retrieval New info integration New equilibrium |
Interpretation: The identical entropy, logit, and attention patterns prove the model is not simulating time or causality. It retrieves and integrates tokens via pattern matching, consistent with autoregressive next-token prediction, not reasoning.
Conclusion
Chain-of-Thought is a Self-Induced Prompt Engineering mechanism. The model generates text to fill its context window with relevant associations, “stuffing” the memory until the correct answer is the only statistically possible output. It is associative retrieval (like a search engine), not logical deduction (like a calculator).
Is the problem that these questions are too easy, so the LLM is outputing reasoning since that’s sometimes helpful, but in this case it doesn’t actually need it?
I’d be curious to see what the results look like if you give it harder questions.