Welcome to the AI Safety Newsletter by the Center for AI Safety. We discuss developments in AI and AI safety. No technical background required.
Subscribe here to receive future versions.
Listen to the AI Safety Newsletter for free on Spotify.
OpenAI and Google Announce New Multimodal Models
In the current paradigm of AI development, there are long delays between the release of successive models. Progress is largely driven by increases in computing power, and training models with more computing power requires building large new data centers.
More than a year after the release of GPT-4, OpenAI has yet to release GPT-4.5 or GPT-5, which would presumably be trained on 10x or 100x more compute than GPT-4, respectively. These models might be released over the next year or two, and could represent large spikes in AI capabilities.
But OpenAI did announce a new model last week, called GPT-4o. The “o” stands for “omni,” referring to the fact that the model can use text, images, videos, and audio as inputs or outputs. This new model modestly outperforms OpenAI’s previous models on standard benchmarks of conversational skill and coding ability. More importantly, it suggests a potential change in how people interact with AI systems, moving from text-based chatbots to live verbal discussions.

Google DeepMind demoed a similar model, called Project Astra. It can watch videos and discuss them in real-time. This model is intended to be part of a path towards building AI agents that can act autonomously in the world. Google also announced improvements to their Gemini series of closed source models, and Gemma series of open source models.
One interesting note for those interested in AI policy is that these models could potentially be deemed illegal in the European Union. The EU AI Act prohibits:
the placing on the market, the putting into service for this specific purpose, or the use of AI systems to infer emotions of a natural person in the areas of workplace and education institutions, except where the use of the AI system is intended to be put in place or into the market for medical or safety reasons.
Users can ask multimodal AI systems like GPT-4o and Project Astra to look at a person’s face and assess whether they’re happy, sad, angry, or surprised. Does this mean that these models will be illegal in the European Union? Some have suggested that it might. This highlights the difficulty of regulating technologies that are rapidly developing.
The Surge in AI Lobbying
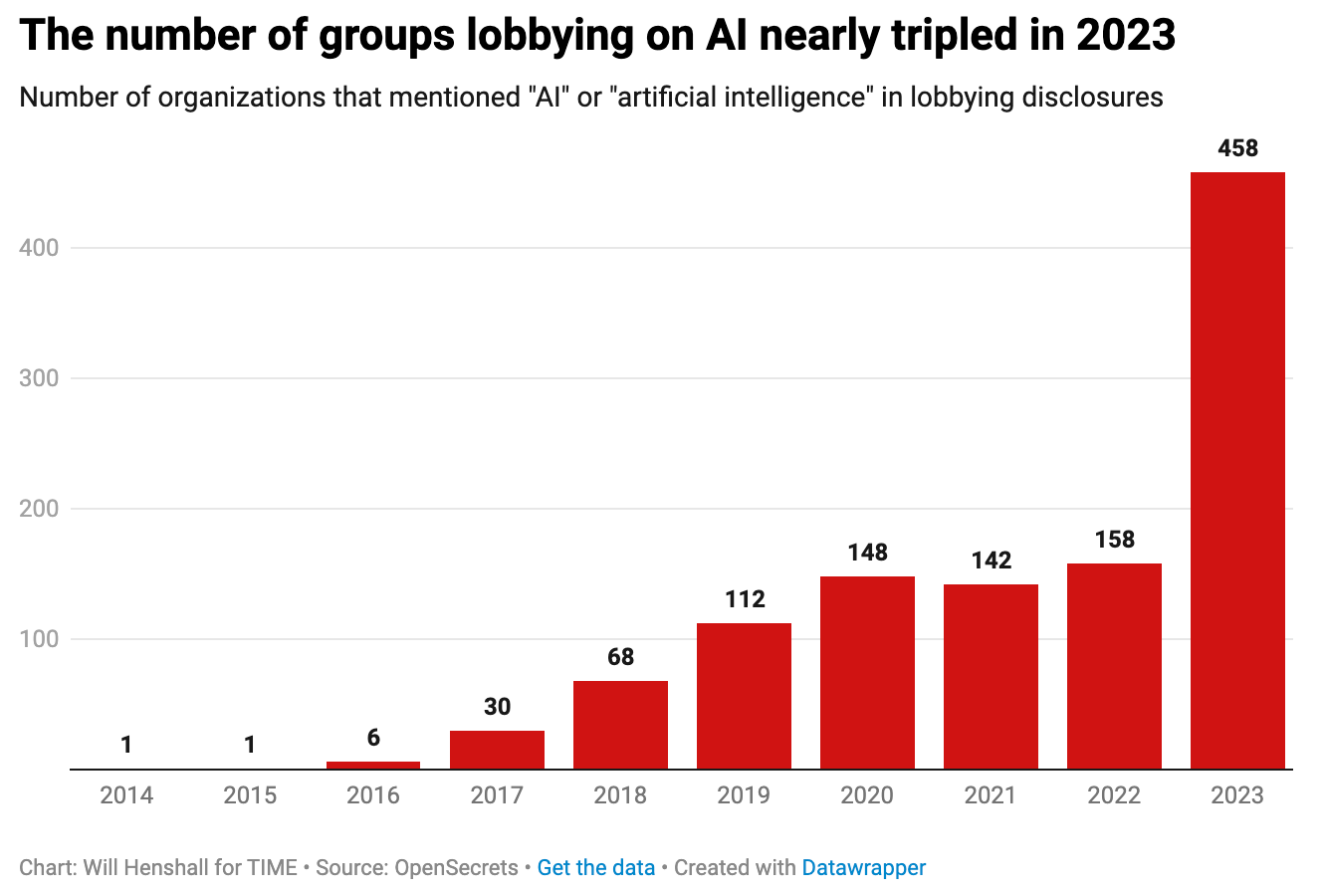
As discussion of AI legislation has intensified, so too have lobbying efforts aimed at shaping the regulatory landscape. According to Time Magazine, “The number of groups lobbying the U.S. federal government on artificial intelligence nearly tripled from 2022 to 2023, rocketing from 158 to 451 organizations, according to data from OpenSecrets, a nonprofit that tracks and publishes data on campaign finance and lobbying.”
Tech giants such as IBM, Meta, and Nvidia are leading the charge against AI safety regulations, according to recent reporting by Politico. They are joined by influential players like venture capital firm Andreessen Horowitz and libertarian billionaire Charles Koch. Politico notes these groups “have been pouring tens of millions of dollars into an all-hands effort to block strict safety rules on advanced artificial intelligence and get lawmakers to worry about China instead.”
Although tech companies have been lobbying Congress for a long time, Nvidia is a newcomer to the process, hiring its first lobbyist in late 2022. According to Politico, “Nvidia lobbyists are badmouthing a recent proposal by the Center for a New American Security think tank to require ‘on-chip governance mechanisms.’”
While some companies, such as OpenAI and Anthropic, have publicly advocated for AI regulation, Time reports that in closed-door meetings, these same companies “tend to advocate for very permissive or voluntary regulations.” Politico reported that “[IBM chief lobbyist Christopher] Padilla said IBM lobbyists have simply outmaneuvered the ‘AI safety’ lobby, which has fewer ties in the nation’s capital and less familiarity with how Washington works.”
Support for AI regulation is a live topic of debate in Congress. Our last newsletter covered several new legislative proposals on AI, but not all members of Congress are ready to move ahead with regulation. Last year, Rep. Ted Lieu (D-Calif.) expressed alarm over advanced AI systems and called for regulation to prevent the worst outcomes. However, Lieu, who now co-chairs the House AI Task Force and has signed the CAIS Statement on AI Risk, told Politico that he remains unconvinced by claims that Congress must take immediate action to regulate advanced AI.
“If you just say, ‘We’re scared of frontier models’ — okay, maybe we should be scared,” Lieu said. “But I would need something beyond that to do legislation. I would need to know what is the threat or the harm that we’re trying to stop.”
[Disclosure: The Center for AI Safety Action Fund also engages in lobbying, advocating for efforts to reduce societal-scale risks from AI. Our lobbying disclosures are publicly available. If you’re interested in donating, feel free to reach out to contact@safe.ai]
How Should Copyright Law Apply to AI Training Data?
Training frontier AI models requires two basic ingredients: compute and data. While much AI safety effort has been directed towards the former, in this story, we focus on the latter. In particular, we look at recent developments regarding how copyright law might apply to AI training data.
AI corporations might be cutting legal corners to acquire training data. In January, we wrote about NYT’s lawsuit against OpenAI and Microsoft, which alleges that the companies violated the NYT’s intellectual copyright by training AI systems on text from their stories. That lawsuit hasn’t been resolved yet, but, in the meantime, NYT published a deep dive into how OpenAI, Google, and Meta have waded into legally dubious territory with respect to copyright law.
For example, it reported that OpenAI used transcripts from more than a million hours of YouTube videos — clearly violating YouTube’s terms of service, and possibly the copyrights of the videos’ creators. For its own part, Google had quietly changed its privacy policy to allow it to train on publicly available videos and documents, although the legality of that policy is similarly unclear.
Europe is ahead of the US in clarifying how copyright law applies to AI training. As NYT’s and similar lawsuits will make their way through the US judicial system, the US copyright office is set to release three reports this year reviewing how copyright law applies to AI models. In the meantime, the law in the US remains unclear.
However, the case against AI companies is somewhat clearer in Europe. Last month, France fined Google 250 million euros over failures to negotiate in good faith with news outlets to use their stories as training data. The final text of the EU AI Act also requires that copyright holders be able to opt-out of having their work be included in training datasets, and that AI developers publish summaries of their datasets.
Three policy options for training on copyrighted data. There appear to be three prominent legal approaches to training on copyrighted data:
No restrictions. AI developers could be free to include copyright-protected material in their training datasets, for example, under US “fair use” doctrine. This is the current de-facto regime in the US which is being challenged by several lawsuits.
Opt-in. AI developers could be required to obtain the explicit consent of copyright owners before training on copyrighted data. This would offer the strongest protections for copyright owners, but could slow AI development, as it might be difficult to obtain consent from so many different copyright owners.
Opt-out. AI developers could be allowed to train on copyrighted material by default, but would have the legal right to opt-out of AI training. This would strike a balance between enabling AI development and protecting the interests of copyright owners. The EU AI Act enshrines this as the current legal standard in the EU, and OpenAI has implicitly supported this standard by allowing websites to opt-out of data scraping.
Economist Glen Weyl and others have argued that treating data as the labor of data creators could have economic benefits. It would encourage the production of useful data, and assuage concerns about AI automation driving unemployment, wage stagnation, and inequality. Others argue that requiring developers to pay for training data would slow AI development, and would particularly hamper lower resource developers such as startups and academics.
Policy shouldn’t necessarily treat AI systems like humans. Arguments in favor of the first regime often rely on comparing AI training to human learning. For example, the NYT would not have a case against an aspiring journalist who honed their craft by reading through the NYT’s backlog. However, we should be wary of such anthropomorphic arguments — laws should not always treat humans and AI systems analogously.
For example, it seems obvious that AI systems should not have the right to bear arms, even though this right is guaranteed to Americans by the Constitution. Yet this simple lesson – that AIs and humans should not always be governed by the same laws – seems often forgotten when considering the case of training on copyrighted data.
The legal battles over training on copyrighted data are in full swing. While the courts attempt to apply existing laws to this new challenge, legislators might want to consider clarifying or updating the way that copyrighted data should be treated by AI developers.
Links
OpenAI cofounder Ilya Sutskever has left the company, following his role in Sam Altman’s brief ouster in November. Jan Leike, co-lead of the Superalignment team, has also resigned.
The UK AI Safety Institute released an open source library for running AI evaluations.
Google DeepMind released AlphaFold 3, trained on proteins, DNA, RNA, and more.
Microsoft deployed GPT-4 for the Pentagon in a highly secure and classified computing server.
Senator Schumer’s bipartisan working group on AI has released a roadmap for legislation that Congress could pass on AI, including funding for AI development and assessments of AI risks.
Bipartisan members of Congress introduced a bill to expand the Department of Commerce’s authority to enact export controls related to AI.
The National Deep Inference Facility will provide compute and access to open source AI models for researchers working on understanding model internals.
The US and China began talks on AI risks in Geneva on Tuesday.
Could the safety of AI systems be guaranteed with formal mathematical proofs? A new paper outlines research directions that could enable such guarantees.
The Department of Homeland Security published guidelines for protecting critical infrastructure and WMDs from AI-related threats.
See also: CAIS website, CAIS twitter, A technical safety research newsletter, An Overview of Catastrophic AI Risks, our new textbook, and our feedback form
Listen to the AI Safety Newsletter for free on Spotify.
Subscribe here to receive future versions.
I think that dropping the intermediate text which describes ‘more established big tech companies’ such as Microsoft substantially changes the meaning of this quote—“these same companies” is not “OpenAI and Anthropic”. Full context:
AI lab watch makes it easy to get some background information by comparing committments made by OpenAI, Anthropic, Microsoft, and some other established big tech companies.
I want to make sure we get this right, and I’m happy to change the article if we misrepresented the quote. I do think the current version is accurate, though perhaps it could be better. Let me explain how I read the quote, and then suggest possible edits, and you can tell me if they would be any better.
Here is the full Time quote, including the part we quoted (emphasis mine):
Who are “the same companies” and “companies” in the second paragraph? The first paragraph specifically mentions OpenAI, Anthropic, and Microsoft. It also discusses broader groups of companies that include these three specific companies “both the newer AI firms and the more established tech giants,” and “the companies involved in the development of AI [that] have, at least in public, struck a cooperative tone when discussion potential regulation.” OpenAI, Anthropic, and Microsoft, and possibly others in the mentioned reference classes, appear to be the “companies” that the second paragraph is discussing.
We summarized this as “companies, such as OpenAI and Anthropic, [that] have publicly advocated for AI regulation.” I don’t think that substantially changes the meaning of the quote. I’d be happy to change it to “OpenAI, Anthropic, and Microsoft” given that Microsoft was also explicitly named in the first paragraph. Do you think that would accurately capture the quote’s meaning? Or would there be a better alternative?
Huh, this seems messy. I wish Time was less ambigious with their language here and more clear about exactly what they have/haven’t seen.
It seems like the current quote you used is an accurate representation of the article, but I worry that it isn’t an accurate representation of what is actually going on.
It seems plausible to me that Time is intentionally being ambigious in order to make the article juicier, though maybe this is just my paranoia about misleading journalism talking. (In particular, it seems like a juicier article if all of the big AI companies are doing this than if they aren’t, so it is natural to imply they are all doing it even if you know this is false.)
Overall, my take is that this is a pretty representative quote (and thus I disagree with Zac), but I think the additional context maybe indicates that not all of these companies are doing this, particularly if the article is intentionally trying to deceive.
Due to prior views, I’d bet against Anthropic consistently pushing for very permissive of voluntary regulation behind closed doors which makes me think the article is probably at least somewhat misleading (perhaps intentionally).