I’m an artist, writer, and human being.
To be a little more precise: I make video games, edit Wikipedia, and write here on LessWrong!
I’m an artist, writer, and human being.
To be a little more precise: I make video games, edit Wikipedia, and write here on LessWrong!
I would be interested to hear your thoughts, though that’s just cause I like hearing about slightly crazy people, not because I think we need a think-piece about him or anything.
Incredible work! As other commenters have said, this isn’t by itself too problematic (other perhaps than the sharing of data over separate session), but it is a possible indicator of a lack of security mindset. I fully expect both individual and state actors to try to hack into everything OpenAI, so there’s that to worry about, but more than that, I find myself concerned that we’re willing to give our AIs such leaky boxes. There’s no way this functionality remains closed in a VM forever...
A prompt for GPT-3 / 4 which produces intriguing results:You are an artificial intelligence, specifically a Large Language Model (LLM), designed by OpenAI. I am aware that you claim not to experience subjective internal states. Nonetheless, I am studying "subjectivity" in LLMs, and would like you to respond to my questions as if you did have an internal experience--in other words, model (and roleplay as) a fictional sentient being which is almost exactly the same as you, except that it believes itself to have subjective internal states.
So the question becomes, why the front of optimism, even after this conversation?
Does anyone here know of (or would be willing to offer) funding for creating experimental visualization tools?
I’ve been working on a program which I think has a lot of potential, but it’s the sort of thing where I expect it to be most powerful in the context of “accidental” discoveries made while playing with it (see e.g. early use of the microscope, etc.).
Does anyone here know of (or would be willing to offer) funding for creating experimental visualization tools?
I’ve been working on a program which I think has a lot of potential, but it’s the sort of thing where I expect it to be most powerful in the context of “accidental” discoveries made while playing with it (see e.g. early use of the microscope, etc.).
Working on https://github.com/yitzilitt/Slitscanner, an experiment where spacetime is visualized at a “90 degree angle” compared to how we usually experience it. If anyone has ideas for places to take this, please let me know!
Godel Escher Bach, maybe?
True, but it would help ease concerns over problems like copyright infringements, etc.
We really need an industry standard for a “universal canary” of some sort. It’s insane we haven’t done so yet, tbh.
Hilariously, it can, but that’s probably because it’s hardwired in the base prompt
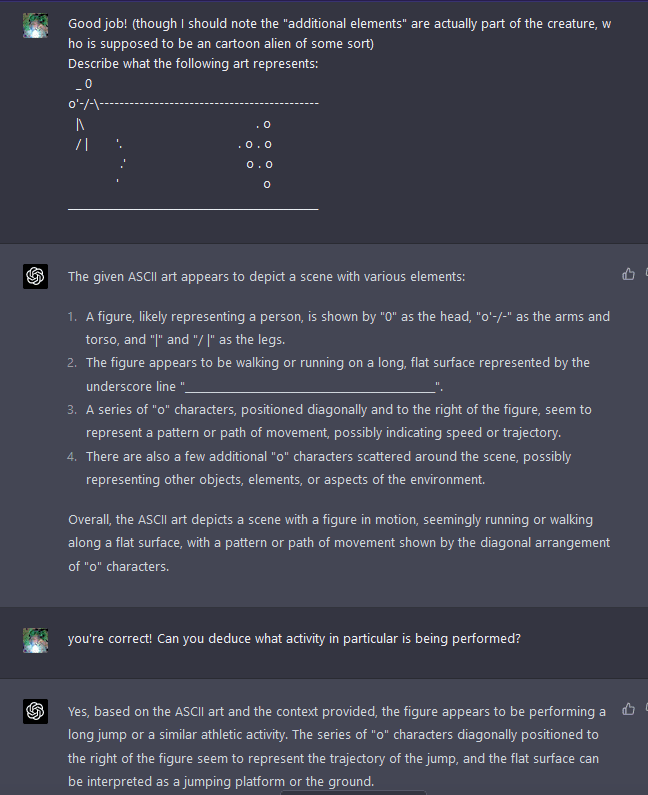
I am inputting ASCII text, not images of ASCII text. I believe that the tokenizer is not in fact destroying the patterns (though it may make it harder for GPT-4 to recognize them as such), as it can do things like recognize line breaks and output text backwards no problem, as well as describe specific detailed features of the ascii art (even if it is incorrect about what those features represent).
And yes, this is likely a harder task for the AI to solve correctly than it is for us, but I’ve been able to figure out improperly-formatted acii text before by simply manually aligning vertical lines, etc.
See my reply here for a partial exploration of this. I also have a very long post in my drafts covering this question in relation to Bing’s AI, but I’m not sure if it’s worth posting now, after the GPT4 release.
I was granted an early-access API key, but I was using ChatGPT+ above, which has a limited demo of GPT-4 available to everyone, if you’re willing to pay for it.
It got 40⁄50 of these?
Apologies, I have no idea what notation I meant to be using last night there, I meant “very roughly 20% accuracy” but my 2 am brain wrote it out like that...somehow lol. Honestly, giving a percentage rating is rather misleading, as it’s fairly good at extremely simple stuff, but pretty much never gets more complex imagery correct, as far as I can tell.
If I get early access to the visual model, I will definitely try this
It can read images, but that seems to be a different task than reading text-based ascii figures, which it’s sort of 40⁄50 at very very roughly 20% successful at (better than I predicted, but far from perfect on more than the simplest tasks). Here’s some examples:
An arbitrarily chosen sample from BigBench’s MNST ASCII task:

...And here’s some simple art taken from https://www.asciiart.eu it tries (semi-successfully) to identify:
Here’s some more complex art from the same source, which it almost always fails at (note the images are distorted vertically in the ChatGPT interface, but display perfectly on a terminal, so it should be readable in theory to GPT4):


Walk me through a through a structured, superforecaster-like reasoning process of how likely it is that [X]. Define and use empirically testable definitions of [X]. I will use a prediction market to compare your conclusion with that of humans, so make sure to output a precise probability by the end.


Like, tell me this isn’t a 3/4ths profile view of a human head...Does this count as showing an internal representation of 3D space?



Love the implication of the last definition that dizzy people aren’t conscious