Executive director at Timaeus. Working on singular learning theory and developmental interpretability.
Website: jessehoogland.com
Twitter: @jesse_hoogland
Executive director at Timaeus. Working on singular learning theory and developmental interpretability.
Website: jessehoogland.com
Twitter: @jesse_hoogland
I have to respond to the fractional sweets thing.
My partner’s parents (her dad mostly) enforced an 8-point rule around candy. One m&m = 1 point; 1 starburst = 4…
The consequence? She developed an unhealthy relationship to candy and would binge on sugary garbage whenever with friends whose parents did not enforce the rule. She didn’t get a chance to discover her own limits for herself.
Contrast with my upbringing: there just wasn’t candy in house, and my parents were relatively relaxed outside the house (granted breakfast was still garbagey cereal but standards change). I never had a problem over consuming candy.
I guess the takeaway is that (human-)enforced moderation is much more fragile than passive (environmentally enforced) moderation.
But then, if I consider how different our siblings are from us (my brother has way more of a sweet tooth, and my partner’s sister had less of a sweet tooth than her), I’d have to conclude that none of this matters, kids are their own creatures, and everything I just wrote only counts as the weakest possible kind of evidence. Oh well.
Hey Winston, thanks for writing this out. This is something we talked a lot about internally. Here are a few thoughts:
Comparisons: At 35k a year, it seems it might be considerably lower than industry equivalent even when compared to other programs
I think the more relevant comparison is academia, not industry. In academia, $35k is (unfortunately) well within in the normal range for RAs and PhD students. This is especially true outside the US, where wages are easily 2x − 4x lower.
Often academics justify this on the grounds that you’re receiving more than just monetary benefits: you’re receiving mentorship and training. We think the same will be true for these positions.
The actual reason is that you have to be somewhat crazy to even want to go into research. We’re looking for somewhat crazy.
If I were applying to this, I’d feel confused and slightly underappreciated if I had the right set of ML/Software Engineering skills but to be barely paid subsistence level for my full-time work (in NY).
If it helps, we’re paying ourselves even less. As much as we’d like to pay the RAs (and ourselves) more, we have to work with what we have.
Of course… money is tight: The grant constraint is well acknowledged here. But potentially the number of RAs expected to hire can be further down adjusted as while potentially increasing the submission rate of the candidates that truly fits the requirement of the research program.
For exceptional talent, we’re willing to pay higher wages.
The important thing is that both funding and open positions are exceptionally scarce. We expect there to be enough strong candidates who are willing to take the pay cut.
All in all, we’re expecting most of our hires to come from outside the US where the cost of living is substantially lower. If lower wages are a deal-breaker for anyone but you’re still interested in this kind of work, please flag this in the form. The application should be low-effort enough that it’s still worth applying.
You can find a v0 of an SLT/devinterp reading list here. Expect an updated reading list soon (which we will cross-post to LW).
Does anyone have a link to the original “To err is human” study? Seems to only be available in paperback.
Something about this study strikes me as not quite right. It doesn’t seem obvious to me that the adverse effects discussed translate to “killed by doctors” or even necessarily “medical mistake”:
Suppose a doctor had discovered one of these medical mistakes on time. That doesn’t necessarily mean that doctor could have done anything about it.
Suppose you’re a patient in a hospital and the base rate for fatality risks is something like one per day. Suppose also that in this hospital the doctors actually are 100% perfect at resolving each fatality risk. However, your doctors make a mistake in diagnosis 5% of the time. Well then, after a month in the hospital, your odds aren’t looking too great (80% chance you’re in a coffin).
Sure, in the second case, you could say that your hospital has a 5% “killed by doctors” rate, but you could also take the more generous view that this patient was sick as a dog, and ultimately it was the cruel hand of iterated probabilities that dealt the final blow.
When I think “killed by doctor”, I’m thinking of cases where doctors explicitly prescribed some substance or therapy that caused death. I’m less sure about death by neglect.
But I wholeheartedly agree that in general, healthcare is messed up. We’re overmedicating and overmedicalizing, it’s eating into our pockets, and it’s not making us much healthier.
We don’t necessarily expect all dangerous capabilities to exhibit phase transitions. The ones that do are more dangerous because we can’t anticipate them, so this just seems like the most important place to start.
It’s an open question to what extent the lottery-ticket style story of a subnetwork being continually upweighted contradicts (or supports) the phase transition perspective. Just because a subnetwork’s strength is growing constantly doesn’t mean its effect on the overall computation is. Rather than grokking, which is a very specific kind of phase transition, it’s probably better to have in mind the emergence of in-context learning in tandem with induction heads, which seems to us more like the typical case we’re interested in when we speak about structure in neural networks developing across training.
We expect there to be a deeper relation between degeneracy and structure. As an intuition pump, think of a code base where you have two modules communicating across some API. Often, you can change the interface between these two modules without changing the information content being passed between them and without changing their internal structure. Degeneracy — the ways in which you can change your interfaces — tells you something about the structure of these circuits, the boundaries between them, and maybe more. We’ll have more to say about this in the future.
Hey Thomas, I wrote about our reasoning for this in response to Winston:
All in all, we’re expecting most of our hires to come from outside the US where the cost of living is substantially lower. If lower wages are a deal-breaker for anyone but you’re still interested in this kind of work, please flag this in the form. The application should be low-effort enough that it’s still worth applying.
Let me add some more views on SLT and capabilities/alignment.
(Dan Murfet’s personal views here) First some caveats: although we are optimistic SLT can be developed into theory of deep learning, it is not currently such a theory and it remains possible that there are fundamental obstacles. Putting those aside for a moment, it is plausible that phenomena like scaling laws and the related emergence of capabilities like in-context learning can be understood from first principles within a framework like SLT. This could contribute both to capabilities research and safety research.
Contribution to capabilities. Right now it is not understood why Transformers obey scaling laws, and how capabilities like in-context learning relate to scaling in the loss; improved theoretical understanding could increase scaling exponents or allow them to be engineered in smaller systems. For example, some empirical work already suggests that certain data distributions lead to in-context learning. It is possible that theoretical work could inspire new ideas. Thermodynamics wasn’t necessary to build steam engines, but it helped to push the technology to new levels of capability once the systems became too big and complex for tinkering.
Contribution to alignment. Broadly speaking it is hard to align what you do not understand. Either the aspects of intelligence relevant for alignment are universal, or they are not. If they are not, we have to get lucky (and stay lucky as the systems scale). If the relevant aspects are universal (in the sense that they arise for fundamental reasons in sufficiently intelligent systems across multiple different substrates) we can try to understand them and use them to control/align advanced systems (or at least be forewarned about their dangers) and be reasonably certain that the phenomena continue to behave as predicted across scales. This is one motivation behind the work on properties of optimal agents, such as Logical Inductors. SLT is a theory of universal aspects of learning machines, it could perhaps be developed in similar directions.
Does understanding scaling laws contribute to safety?. It depends on what is causing scaling laws. If, as we suspect, it is about phases and phase transitions then it is related to the nature of the structures that emerge during training which are responsible for these phase transitions (e.g. concepts). A theory of interpretability scalable enough to align advanced systems may need to develop a fundamental theory of abstractions, especially if these are related to the phenomena around scaling laws and emergent capabilities.
Our take on this has been partly spelled out in the Abstraction seminar. We’re trying to develop existing links in mathematical physics between renormalisation group flow and resolution of singularities, which applied in the context of SLT might give a fundamental understanding of how abstractions emerge in learning machines. One best case scenario of the application of SLT to alignment is that this line of research gives a theoretical framework in which to understand more empirical interpretability work.
The utility of theory in general and SLT in particular depends on your mental model of the problem landscape between here and AGI. To return to the thermodynamics analogy: a working theory of thermodynamics isn’t necessary to build train engines, but it’s probably necessary to build rockets. If you think the engineering-driven approach that has driven deep learning so far will plateau before AGI, probably theory research is bad in expected value. If you think theory isn’t necessary to get to AGI, then it may be a risk that we have to take.
Summary: In my view we seem to know enough to get to AGI. We do not know enough to get to alignment. Ergo we have to take some risks.
If we actually had the precision and maturity of understanding to predict this “volume” question, we’d probably (but not definitely) be able to make fundamental contributions to DL generalization theory + inductive bias research.
Obligatory singular learning theory plug: SLT can and does make predictions about the “volume” question. There will be a post soon by @Daniel Murfet that provides a clear example of this.
Our work on the induction bump is now out. We find several additional “hidden” transitions, including one that splits the induction bump in two: a first part where previous-token heads start forming, and a second part where the rest of the induction circuit finishes forming.
The first substage is a type-B transition (loss changing only slightly, complexity decreasing). The second substage is a more typical type-A transition (loss decreasing, complexity increasing). We’re still unclear about how to understand this type-B transition structurally. How is the model simplifying? E.g., is there some link between attention heads composing and the basin broadening?
Yes (see footnote 1)! The main place where devinterp diverges from Naomi’s proposal is the emphasis on phase transitions as described by SLT. During the first phase of the plan, simply studying how behaviors develop over different checkpoints is one of the main things we’ll be doing to establish whether these transitions exist in the way we expect.
This appears to be a high-quality book report. Thanks. I didn’t see anywhere the ‘because’ is demonstrated. Is it proved in the citations or do we just have ‘plausibly because’?
The because ends up taking a few dozen pages to establish in Watanabe 2009 (and only after introducing algebraic geometry, empirical processes, and a bit of complex analysis). Anyway, I thought it best to leave the proof as an exercise for the reader.
Physics experiences in optimizing free energy have long inspired ML optimization uses. Did physicists playing with free energy lead to new optimization methods or is it just something people like to talk about?
I’m not quite sure what you’re asking. Like you say, physics has a long history of inspiring ML optimization techniques (e.g., momentum/acceleration and simulated annealing). Has this particular line of investigation inspired new optimization techniques? I don’t think so. It seems like the current approaches work quite well, and the bigger question is: can we extend this line of investigation to the optimization techniques we’re currently using?
I’m confused by the setup. Let’s consider the simplest case: fitting points in the plane, y as a function of x. If I have three datapoints and I fit a quadratic to it, I have a dimension 0 space of minimizers of the loss function: the unique parabola through those three points (assume they’re not ontop of each other). Since I have three parameters in a quadratic, I assume that this means the effective degrees of freedom of the model is 3 according to this post. If I instead fit a quartic, I now have a dimension 1 space of minimizers and 4 parameters, so I think you’re saying degrees of freedom is still 3. And so the DoF would be 3 for all degrees of polynomial models above linear. But I certainly think that we expect that quadratic models will generalize better than 19th degree polynomials when fit to just three points.
On its own the quartic has 4 degrees of freedom (and the 19th degree polynomial 19 DOFs).
It’s not until I introduce additional constraints (independent equations), that the effective dimensionality goes down. E.g.: a quartic + a linear equation = 3 degrees of freedom,
It’s these kinds of constraints/relations/symmetries that reduce the effective dimensionality.
This video has a good example of a more realistic case:
I think the objection to this example is that the relevant function to minimize is not loss on the training data but something else? The loss it would have on ‘real data’? That seems to make more sense of the post to me, but if that were the case, then I think any minimizer of that function would be equally good at generalizing by definition. Another candidate would be the parameter-function map you describe which seems to be the relevant map whose singularities we are studying, but we it’s not well defined to ask for minimums (or level-sets) of that at all. So I don’t think that’s right either.
We don’t have access to the “true loss.” We only have access to the training loss (for this case, ). Of course the true distribution is sneakily behind the empirical distribution and so has after-effects in the training loss, but it doesn’t show up explicitly in (the thing we’re trying to maximize).
The easiest way to explain why this is the case will probably be to provide an example. Suppose we have a Bayesian learning machine with 15 parameters, whose parameter-function map is given by
and whose loss function is the KL divergence. This learning machine will learn 4-degree polynomials.
I’m not sure, but I think this example is pathological. One possible reason for this to be the case is that the symmetries in this model are entirely “generic” or “global.” The more interesting kinds of symmetry are “nongeneric” or “local.”
What I mean by “global” is that each point in the parameter space has the same set of symmetries (specifically, the product of a bunch of hyperboloids ). In neural networks there are additional symmetries that are only present for a subset of the weights. My favorite example of this is the decision boundary annihilation (see below).
For the sake of simplicity, consider a ReLU network learning a 1D function (which is just piecewise linear approximation). Consider what happens when you you rotate two adjacent pieces so they end up sitting on the same line, thereby “annihilating” the decision boundary between them, so this now-hidden decision boundary no longer contributes to your function. You can move this decision boundary along the composite linear piece without changing the learned function, but this only holds until you reach the next decision boundary over. I.e.: this symmetry is local. (Note that real-world networks actually seem to take advantage of this property.)
This is the more relevant and interesting kind of symmetry, and it’s easier to see what this kind of symmetry has to do with functional simplicity: simpler functions have more local degeneracies. We expect this to be true much more generally — that algorithmic primitives like conditional statements, for loops, composition, etc. have clear geometric traces in the loss landscape.
So what we’re really interested in is something more like the relative RLCT (to the model class’s maximum RLCT). This is also the relevant quantity from a dynamical perspective: it’s relative loss and complexity that dictate transitions, not absolute loss or complexity.
This gets at another point you raised:
2. It is a type error to describe a function as having low RLCT. A given function may have a high RLCT or a low RLCT, depending on the architecture of the learning machine.
You can make the same critique of Kolmogorov complexity. Kolmogorov complexity is defined relative to some base UTM. Fixing a UTM lets you set an arbitrary constant correction. What’s really interesting is the relative Kolmogorov complexity.
In the case of NNs, the model class is akin to your UTM, and, as you show, you can engineer the model class (by setting generic symmetries) to achieve any constant correction to the model complexity. But those constant corrections are not the interesting bit. The interesting bit is the question of relative complexities. I expect that you can make a statement similar to the equivalence-up-to-a-constant of Kolmogorov complexity for RLCTs. Wild conjecture: given two model classes and and some true distribution , their RLCTs obey:
where is some monotonic function.
To be clear, our policy is not publish-by-default. Our current assessment is that the projects we’re prioritizing do not pose a significant risk of capabilities externalities. We will continue to make these decisions on a per-project basis.
This is probably true for neural networks in particular, but mathematically speaking, it completely depends on how you parameterise the functions. You can create a parameterisation in which this is not true.
Agreed. So maybe what I’m actually trying to get at it is a statement about what “universality” means in the context of neural networks. Just as the microscopic details of physical theories don’t matter much to their macroscopic properties in the vicinity of critical points (“universality” in statistical physics), just as the microscopic details of random matrices don’t seem to matter for their bulk and edge statistics (“universality” in random matrix theory), many of the particular choices of neural network architecture doesn’t seem to matter for learned representations (“universality” in DL).
What physics and random matrix theory tell us is that a given system’s universality class is determined by its symmetries. (This starts to get at why we SLT enthusiasts are so obsessed with neural network symmetries.) In the case of learning machines, those symmetries are fixed by the parameter-function map, so I totally agree that you need to understand the parameter-function map.
However, focusing on symmetries is already a pretty major restriction. If a universality statement like the above holds for neural networks, it would tell us that most of the details of the parameter-function map are irrelevant.
There’s another important observation, which is that neural network symmetries leave geometric traces. Even if the RLCT on its own does not “solve” generalization, the SLT-inspired geometric perspective might still hold the answer: it should be possible to distinguish neural networks from the polynomial example you provided by understanding the geometry of the loss landscape. The ambitious statement here might be that all the relevant information you might care about (in terms of understanding universality) are already contained in the loss landscape.
If that’s the case, my concern about focusing on the parameter-function map is that it would pose a distraction. It could miss the forest for the trees if you’re trying to understand the structure that develops and phenomena like generalization. I expect the more fruitful perspective to remain anchored in geometry.
Is this not satisfied trivially due to the fact that the RLCT has a certain maximum and minimum value within each model class? (If we stick to the assumption that is compact, etc.)
Hmm, maybe restrict so it has to range over .
Oops yes this is a typo. Thanks for pointing it out.
When people complain about LLMs doing nothing more than interpolation, they’re mixing up two very different ideas: interpolation as intersecting every point in the training data, and interpolation as predicting behavior in-domain rather than out-of-domain.
With language, interpolation-as-intersecting isn’t inherently good or bad—it’s all about how you do it. Just compare polynomial interpolation to piecewise-linear interpolation (the thing that ReLUs do).
Neural networks (NNs) are biased towards fitting simple piecewise functions, which is (locally) the least biased way to interpolate. The simplest function that intersects two points is the straight line.
In reality, we don’t even train LLMs long enough to hit that intersecting threshold. In this under-interpolated sweet spot, NNs seem to learn features from coarse to fine with increasing model size. E.g.: https://arxiv.org/abs/1903.03488
Bonus: this is what’s happening with double descent: Test loss goes down, then up, until you reach the interpolation threshold. At this point there’s only one interpolating solution, and it’s a bad fit. But as you increase model capacity further, you end up with many interpolating solutions, some of which generalize better than others.
Meanwhile, with interpolation-not-extrapolation NNs can and do extrapolate outside the convex hull of training samples. Again, the bias towards simple linear extrapolations is locally the least biased option. There’s no beating the polytopes.
Here I’ve presented the visuals in terms of regression, but the story is pretty similar for classification, where the function being fit is a classification boundary. In this case, there’s extra pressure to maximize margins, which further encourages generalization
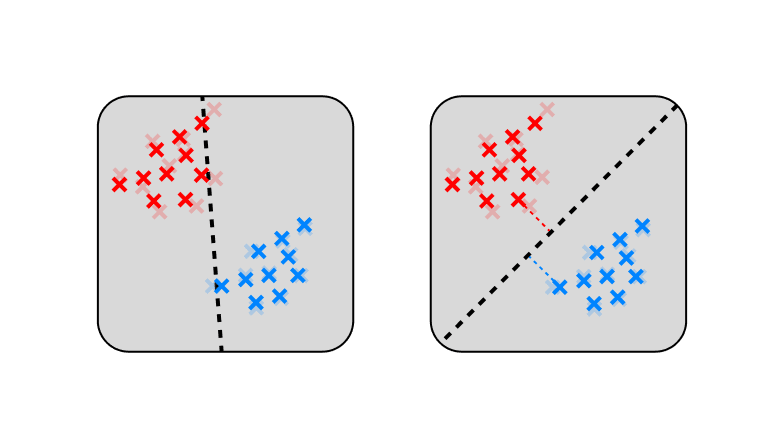
The next time you feel like dunking on interpolation, remember that you just don’t have the imagination to deal with high-dimensional interpolation. Maybe keep it to yourself and go interpolate somewhere else.
First of all, I really like the images, they made things easier to understand and are pretty. Good work with that!
Thank you!
My biggest problem with this is the unclear applicability of this to alignment. Why do we want to predict scaling laws? Doesn’t that mostly promote AI capabilities, and not alignment very much?
This is also my biggest source of uncertainty on the whole agenda. There’s definitely a capabilities risk, but I think the benefits to understanding NNs currently much outweigh the benefits to improving them.
In particular, I think that understanding generalization is pretty key to making sense of outer and inner alignment. If “singularities = generalization” holds up, then our task seems to become quite a lot easier: we only have to understand a few isolated points of the loss landscape instead of the full exponential hell that is a billions-dimensional system.
In a similar vein, I think that this is one of the most promising paths to understanding what’s going on during training. When we talk about phase changes / sharp left turns / etc., what we may really be talking about are discrete changes in the local singularity structure of the loss landscape. Understanding singularities seems key to predicting and anticipating these changes just as understanding critical points is key to predicting and anticipating phase transitions in physical systems.
We care about the generalization error with respect to some prior , but the latter doesn’t have any effect on the dynamics of SGD or on what the singularity is
The Watanabe limit ( as ) and the restricted free energy all are presented on results, which rely on the singularities, and somehow predict generalization. But all of these depend on the prior , and earlier we’ve defined the singularities to be of the likelihood function; plus SGD actually only uses the likelihood function for its dynamics.
As long as your prior has non-zero support on the singularities, the results hold up (because we’re taking this large-N limit where the prior becomes less important). Like I mention in the objections, linking this to SGD is going to require more work. To first order, when your prior has support over only a compact subset of weight space, your behavior is dominated by the singularities in that set (this is another way to view the comments on phase transitions).
It’s also unclear what the takeaway from this post is. How can we predict generalization or dynamics from these things? Are there any empirical results on this?
This is very much a work in progress.
In statistical physics, much of our analysis is built on the assumption that we can replace temporal averages with phase-space averages. This is justified on grounds of the ergodic hypothesis. In singular learning theory, we’ve jumped to parameter (phase)-space averages without doing the important translation work from training (temporal) averages. SGD is not ergodic, so this will require care. That the exact asymptotic forms may look different in the case of SGD seems probable. That the asymptotic forms for SGD make no reference to singularities seems unlikely. The basic takeaway is that singularities matter disproportionately, and if we’re going to try to develop a theory of DNNs, they will likely form an important component.
For (early) empirical results, I’d check out the theses mentioned here.
is not a KL divergence, the terms of the sum should be multiplied by or .
is an empirical KL divergence. It’s multiplied by the empirical distribution, , which just puts probability on the observed samples (and 0 elsewhere),
the Hamiltonian is a random process given by the log likelihood ratio function
Also given by the prior, if we go by the equation just above that. Also where does “ratio” come from?
Yes, also the prior, thanks for the correction.The ratio comes from doing the normalization (“log likelihood ratio” is just another one of Watanabe’s name for the empirical KL divergence). In the following definition,
the likelihood ratio is
But that just gives us the KL divergence.
I’m not sure where you get this. Is it from the fact that predicting p(x | w) = q(x) is optimal, because the actual probability of a data point is q(x) ? If not it’d be nice to specify.
the minima of the term in the exponent, K (w) , are equal to 0.
This is only true for the global minima, but for the dynamics of learning we also care about local minima (that may be higher than 0). Are we implicitly assuming that most local minima are also global? Is this true of actual NNs?
This is the comment in footnote 3. Like you say, it relies on the assumption of realizability (there being a global minimum of ) which is not very realistic! As I point out in the objections, we can sometimes fix this, but not always (yet).
the asymptotic form of the free energy as
This is only true when the weights are close to the singularity right?
That’s the crazy thing. You do the integral over all the weights to get the model evidence, and it’s totally dominated by just these few weights. Again, when we’re making the change to SGD, this probably changes.
Also what is , seems like it’s the RLCT but this isn’t stated.
Yes, I’ve made an edit. Thanks!
To take a step back, the idea of a Taylor expansion is that we can express any function as an (infinite) polynomial. If you’re close enough to the point you’re expanding around, then a finite polynomial can be an arbitrarily good fit.
The central challenge here is that is pretty much never a polynomial. So the idea is to find a mapping, , that lets us re-express in terms of a new coordinate system, . If we do this right, then we can express (locally) as a polynomial in terms of the new coordinates, .
What we’re doing here is we’re “fixing” the non-differentiable singularities in so that we can do a kind of Taylor expansion over the new coordinates. That’s why we have to introduce this new manifold, , and mapping .
Now that the deadline has arrived, I wanted to share some general feedback for the applicants and some general impressions for everyone in the space about the job market:
My number one recommendation for everyone is to work on more legible projects and outputs. A super low-hanging fruit for >50% of the applications would be to clean up your GitHub profiles or to create a personal site. Make it really clear to us which projects you’re proud of, so we don’t have to navigate through a bunch of old and out-of-use repos from classes you took years ago. We don’t have much time to spend on every individual application, so you want to make it really easy for us to become interested in you. I realize most people don’t even know how to create a GitHub profile page, so check out this guide.
We got 70 responses and will send out 10 invitations for interviews.
We rejected a reasonable number of decent candidates outright because they were looking for part-time work. If this is you, don’t feel dissuaded.
There were quite a few really bad applications (...as always): poor punctuation/capitalization, much too informal, not answering the questions, totally unrelated background, etc. Two suggestions: (1) If you’re the kind of person who is trying to application-max, make sure you actually fill in the application. A shitty application is actually worse than no application, and I don’t know why I have to say that. (2) If English is not your first language, run your answers through ChatGPT. GPT-3.5 is free. (Actually, this advice is for everyone).
Between 5 and 10 people expressed interest in an internship option. We’re going to think about this some more. If this includes you, and you didn’t mention it in your application, please reach out.
Quite a few people came from a data science / analytics background. Using ML techniques is actually pretty different from researching ML techniques, so for many of these people I’d recommend you work on some kind of project in interpretability or related areas to demonstrate that you’re well-suited to this kind of research.
Remember that job applications are always noisy. We almost certainly made mistakes, so don’t feel discouraged!