
baturinsky
Karma: 261
I doubt training LLMs can lead to AGI. Fundamental research on the alternative architectures seems to be more dangerous.
Thinking and arguing about human values is in itself a part of human values and people nature. Without doing that, we cease being humans.
So, deferring decisions about values to people, when possible, should not be just instrumental, but part of the terminal AI goal.
While the model has the advantage of only having to “win” once.
GPT 3.5/4 is usually capable of reasoning correctly where humans can see the answer at a glance.
It is also correct when the correct answer requires some thinking, as long as the direction of the thinking is described somewhere in the data set. In such cases, the algorithm “thinks out loud” in the output. However, it may fail if it is not allowed to do so and is instructed to produce an immediate answer.
Additionally, it may fail if the solution involves initial thinking, followed by the realization that the most obvious path was incorrect, requiring a reevaluation of part or all of the thinking process.
>That’s much more like the sort of thing you can give to an optimizer. And it results in the world frozen solid.
That’s why I made sure to specify the gradual improvement. Also, development and improvement are also the natural state of humanity and people, so taking that away from them means breaking the status quo too.
>I notice that the word “reasonably” is doing most of the work there. (much like in English Common Law, where it works reasonably well, because it’s interpreted by reasonably human beings.Mathematically speaking, polynomials are reasonable functions. Step functions or factorials are not. Exponents are reasonable, if they are exponent over ~constant value since somewhere before year 2000. Metrics of the reasonable world should be described with reasonable functions.
>There are three kinds of genies: Genies to whom you can safely say “I wish for you to do what I should wish for”; genies for which no wish is safe; and genies that aren’t very powerful or intelligent.
I’ll take third please. It just should be powerful enough that it can prevent other two types from being created in foreseable future.
Also, it seems that you imagine AI as not just the second type of genie, but of a genie that is explicitly hostile and would misinterpret your wish on purpose. Of cause, making any wish for such genie would end badly.
AI is prosperous and all-knowing. No people, hence zero suffering.
We have yet to have an airtight solution, but there is enough of approaches explored that could increase the ETA(doom). Maybe when we’ll have a proto-AGI for testing things on, we can refine them enough to increase ETA to few years, and then few years more, etc.
Also, people did not take AI risks seriously when AI was not spotlight. Now interest in AI safety increases rapidly. But so does interest in AI capabilities, sadly.
I think it may be caused by https://en.wikipedia.org/wiki/Anxiety_disorder
I suffer from that too.
That’s a very counterproductive state of mind if the task is unsolvable in it’s full difficulty. It makes you lose hope and stop trying solutions that would work if situation is not as bad as you imagined.
AI can be useful without being ASI. Including in things such as identifying and preventing situations that could lead to creation of unaligned ASI.
Of cause, conservative and human-friendly AI would probably lose to existing AI with comparable power, but not limited by those “handicaps”. That’s why it’s important to prevent the possibility of their creation, instead of fighting them “fairly”.
And yes, computronium maximising is a likely behaviour, but there are ideas how to avoid it, such as https://www.lesswrong.com/posts/ngEvKav9w57XrGQnb/cognitive-emulation-a-naive-ai-safety-proposal or https://www.lesswrong.com/posts/5gQLrJr2yhPzMCcni/the-optimizer-s-curse-and-how-to-beat-it
Of cause, all those ideas and possibilities may be actually duds. And we are doomed no matter not. But then what’s the point of seeking for solution that does not exist?
What do I wish from AI? I gave a rough list in this thread, and also here https://www.lesswrong.com/posts/9y5RpyyFJX4GaqPLC/pink-shoggoths-what-does-alignment-look-like-in-practice?commentId=9uGe9DptK3Bztk2RY
Overall, I think both AI and those giving goals for it should be as conservative and restrained as possible. They should value, above all, the preservance of the status quo of people, world and AI. With a VERY steady improvements of each. Move ahead, but move slowly, don’t break things.
I don’t think that this part is the hardest. I think with enough limiting conditions (such as “people are still in charge”, “people are still people”, “world is close enough to our current world and ourr reasonably optimistic expectations of it’s future”, “those rules should be met continuously at each moment between now and then”) etc. we can find something that can work.
Other parts (how to teach those rules to AI and how to prevent everyone from launching AGI that is not taught them) look harder to me.
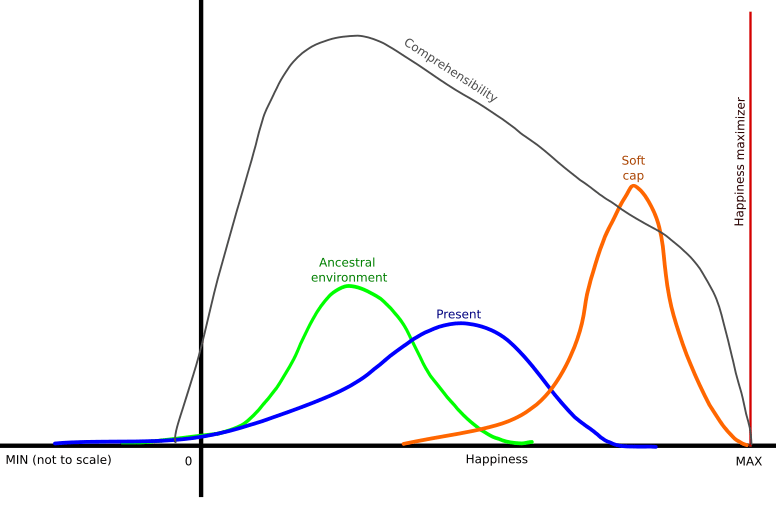
I was thinking about this issue too. Trying to make an article out of it, but so far all I have is this graph.
Idea is a “soft cap” AI. I.e., AI that is significantly improving our lives, but not giving us the “max happiness”. And instead, giving us the oportunity of improving our life and life of other people using our brains.
Also, ways of using our brains should be “natural” for them, i.e. that should be mostly to solve tasks similar to tasks of our ancestral involvement.
Would be amusing if Russia and China would join the “Yudkowsky’s treaty” and USA would not.
Human: Aligned AGI, make me a more powerful AGI!
AGI: What? Are you nuts? Do you realise how dangerous those things are? No!
Maybe it is an attempt of the vaccination? I.e. exposing the “organism” to the weakened form of the deadly “virus”, so the organism can produce “antibodies”.
Looks very similar to how the current GPT jailbreaks work.
Question is, what can such primitive species like us could offer to AI.
Best I could come with is “predictability”. We people have relatively stable and “documented” “architecture”, so as long as civilization is build upon us, AI can more or less safely predict consequences of it’s actions and plan with high degree of certainty. But if this society collapses, destroyed, or is radically changed, AI will have to deal with a very unpredictable situation and with other AIs that who knows how would act in that situation.
Utility of the intelligence is limited (though the limit is very, very high). For example, no matter how smart AI is, it will not win against a human chess master with a big enough handicap (such as a rook).
So, it’s likely that AI will turn most of the Earth into a giant factory, not computer. Not that it’s any better or us...