An N=1 observational study on interpretability of Natural General Intelligence (NGI)
Thinking about intelligence, I’ve decided to try something. The ARC-AGI puzzles are open and free for anyone to try via a convenient web interface. Having a decently well-trained general intelligence at hand in my own head, if I’m allowed the immodesty, I decided to make a little experiment: tackle one of them (the Daily Puzzle, to be precise), and record myself doing so. I’m going to talk about it and spoil it for you if you haven’t played it yet, so if you want to try, go do so first.
The solution
00:01
I'm going to record myself solving the Arc RG Daily Pro puzzle from September 27, 2025. I'm now starting the puzzle. Alright, so the puzzle shows a few inputs. I'm going to take a screenshot of one and the others and a third example.Here are the screenshots for context:
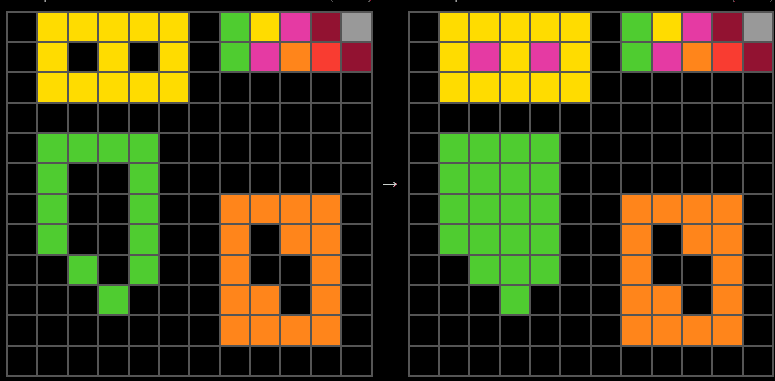
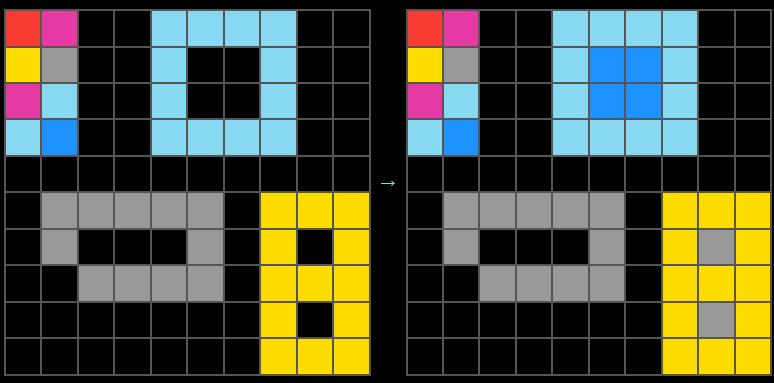

First stage: analysis of the patterns.
00:42
at a glance it has a series of patterns. I can immediately spot the similarity between patterns on the left and on the right, the shapes are clearly very identical. I can also very clearly classify immediately. Some of these patterns have00:59
have a uniform color and some of them are different colors in particular every example seems to have at least one that is very patchwork and sort of different and the others are either uniform or at most one color in the second example so looking at it more closely I found those already more thorough patternStage two, formulating a hypothesis.
01:26
There is one shape that is identical, there is one shape that gets its own fill. There are actually two shapes sometimes, and there is one that is multicolor and it stays the same. Working hypothesis, the multicolor image is encoding in some way the fill-in transformation.01:48
Now, looking at it, I'm working on that hypothesis, it actually makes a lot of sense. If we take the one row, it means the original color, and the other row, the filling color. Now we say the green is filled with green, the yellow is filled with purple, which it is in the second example. And orange does not go through, so orange is not filled.(the above refers to example 1 by the way)
02:09
The same thing seems to happen here where the outside row is the reference. So is it the outside always reference? I suppose it is, whether it's topmost or the leftmost.02:24
And then we're saying, okay, so this one row tells us the light blue gets filled with dark blue, and the yellow gets filled with grey, and we have an orange that's full of grey. And the same happens here, red with orange, and orange with yellow. So I think I have solved the problem. I'm going to need 13 by 13, really, in fact, the easiest thing I can do is just copy from input.(the above refers to examples 2 and 3)
At this point the solution board looked like this:
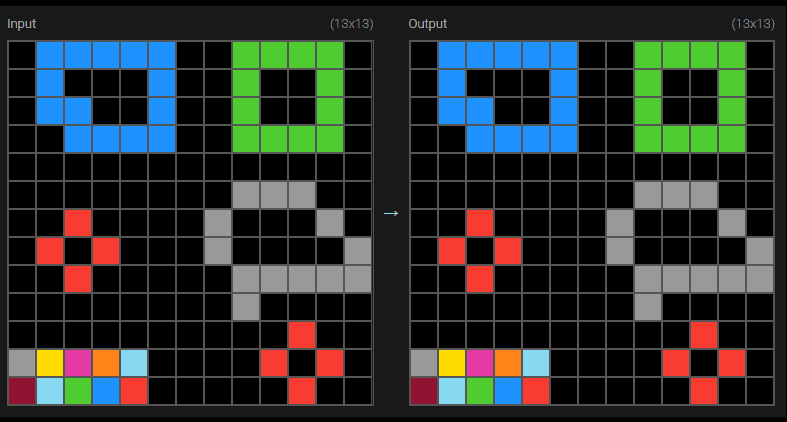
02:53
and then I have to edit the cells. So this is actually creating this kind of... creating a puzzle here because we now have an example of the coloured box being in the bottom row, right? So... I'm going to take a screenshot of the test. We don't have that, so we don't really know whether the rule, the prevalence rule is the row outside or...03:27
the row that is on top. And I believe this is an interesting case because this is literally like just under-determined. This is an out-of-distribution problem and I have to simply infer what the intent here was. I'm going to go with the one on top and therefore I'm going to fill the grey with red. I actually am going to take the flood fill because that makes it easier. I'm going to fill the grey with red.03:53
There's no yellow, there's no purple, there's no orange, there's no light grey. So that's all I have to do. Let me try submitting this solution. It is wrong. So I guess maybe it was the other way around. So let's go the other way around, which means that I flood filled the red with grey, the light blue with yellow, the green with purple, [garbled]04:19
the blue with orange, that is also something we cannot, and any of that with the line h [?]. And we submit, and that is correct. That's it.
Analysis
I finished the problem in 4 minutes and 9 seconds (at least 45 seconds of which were spent taking screenshots) and with two attempts. I could have probably gone faster had I not been speaking the whole time, and the attempts I feel like were fundamentally just a matter of luck. While I’m not a hardcore puzzle solver, I’ve got my fair experience with them (and I have solved quite a few ARC ones before) and I probably have way more of a “puzzle brain” than the average person, so I would guess this time would still be fairly good.
A few sparse observations:
it’s fascinating to me how quick visual pattern recognition is. It’s not conscious and it’s not procedural, I do not go through hypotheses and attempts—a huge part of the solution simply came to me by glancing at those examples and immediately noticing the shapes being identical, and the outlier multicoloured rectangle having some kind of special meaning. There are a number of ways in which the shapes could slightly differ (be translated, rotated, changed in colour, differently filled) and I’m sure I would still spot them at a single glance. This is obviously a huge component of my ability to solve the problem at all;
the next step, of spotting the hypothesis that the rectangle bit was encoding some transformation information, feels like it is very tied to my priors. Obviously there is something special about it, but “it must carry information in some trivial way” was my immediate obvious hypothesis and it is very coder-brained, if you get what I mean (also, as I said, I have played other such tests as well as looked into toy problems for attention mechanisms; “put information in one part of the sequence that affects how some other part is processed” is a textbook attention test). So this is a part of the thinking strongly informed by my priors on what kind of trick I expect from this sort of problem, and then once formulated it was easy to check it. I sort of reproduced the pattern of a ML training run—formulating a hypothesis on the first example alone and using the two successive ones as a test set. I do wonder if my hypothesis had been wrong, and I had been forced to try more by using my knowledge of all three examples, would I had been at higher risk of “overfitting”?
the situation with “which row is the edge colour and which row is the fill colour” is very interesting and telling to me. There were two legitimately hypotheses that I’d call equally simple: “when it’s horizontal, it’s always the top row” or “it’s always the row on the outside”. Both fit the examples. I feel like my thinking them equally simple though may be affected by being very aware of the usual indexing strategies in pixel images—left and top being the 0-index for X and Y respectively, meaning that assumption equates “the line with lowest index”. Coder-brain again; that is not necessarily equally obvious. I could have gone with the other by a sort of meta thinking: it means doing more in this specific example, and obviously the puzzle makers would probably set this problem up in a way that requires more work, so it may be that. But consider how many hypotheses that by all means should not belong in such a problem creep into that!
The interesting conclusion to me is that two things here did almost all of the work. One of them is pattern recognition, a mechanism that seems completely unconscious and I imagine some sort of sophisticated elaboration on convolution and/or attention, but noticeably, heavily biased to detect similarity even past specific operations that are assumed more likely and yet not enough to break correspondence (like translation or filling). The second is a lot of priors, and these priors are very very specific. I don’t think they’re even necessarily about things being “simpler” in some absolute, Solomonoff sense. They just feel like they’re about puzzles, and how puzzles, or code, or things designed for us, work. This probably speaks in part to the limits of the ARC dataset (though this is one of the easiest problem I’ve found from it; others are much less intuitive). But it also makes me think about the concept of AGI and ASI. Ideally, we imagine a superintelligence being able to spot much more sophisticated patterns than we do. This implies a certain untethering from our own biases and limits. And yet our ability to solve certain categories of problems in the first place seems to be dictated by how we have a ready-made library of concepts that we strongly select on when trying to navigate the tree of all possible explanations. As if what makes us a general intelligence is having a collection of simple programs that are factually very useful, and an algorithm well trained on building a tree out of them to fit a given problem.
This makes us very very efficient at anything that can be tackled with those simple programs, but also limit us in our ability to transcend them. If a superintelligence had to go beyond that, and explore higher regions in problem-space, would it be by developing a richer or more complex collection of pieces (and then, in turn, be limited by them)? Or would it do so by completely transcending the mechanism altogether and just having a really good way to build hypotheses from a true universal prior? One can assume for example there is a correct prior to formulate physics hypotheses, and ultimately everything is grounded in physics, but even for an ASI, having to think its way up from atoms every time it wants to understand humans seems a bit much. Yet having specialised human-understanding priors would in turn prejudice its ability to understand some hitherto unknown alien. Does intelligence even exist without this trade-off?
That’s a puzzle you don’t solve in four minutes with two attempts.
The ability to get to consciously decide when to discard or rewrite or call on the simple programs is a superpower evolution didn’t give humans. One that it seems would be the obvious solution for an AI that gets to call on an external, updatable set of tools. Or an ASI got got to rewrite the parts of itself that call the tools or notice (what it previously thought were) edge cases.
AKA, an ASI can go ahead and have a human-specific prior. It can choose to apply it until it meets entities that are alien, then stop applying it. Humans can’t really do that, in the same way that we can’t turn off our visual heuristics when encountering things we consciously know are weirdly constructed adversarial examples, even if we can sometimes override them with enough effort. The ASI, presumably, would further react to encountering aliens by reasoning from more basic principles (recurse as needed) as it learns enough to create 1) a new prior specific to those aliens, 2) a new prior specific to those aliens’ species, culture, world, etc.
Or at least, that’s my <4 minute human-level single attempt at guessing a lower bound on an ASI’s solution.
I think if you start having meta-priors, then what, you gotta have meta-meta-priors and so on? At some point that’s just having more basic, fundamental priors that embrace a wider range of possibilities. The question is what would those look like, or if being general enough doesn’t descend into a completely uniform (or very little informative) prior that is essentially of no help; you can think anything, but the trade-off is it’s always going to be inefficient.
True, but I think in this case there’s at least no risk of an infinite regress. At one end, yes, it bottoms out in an extremely vague and inefficient but general hyperprior. I would guess from the little I’ve read that in humans these are the layers that govern how we learn from even before we’re born. I would imagine an ASI would have at least one layer more fundamental than this, which enable it to change various fixed-in-humans assumptions about things.
At the other end would be the most specific or most abstracted layer of priors that has proven useful to date. Somewhere in the stack are your current best processes for deciding whether particular priors or layers of priors are useful or worth keeping or if you need a new one.
I am actually not sure whether ‘prior’ is quite the right term here? Some of it feels like the distinction between thingspace and conceptspace, where the priors might be more about the expectations what things exist and where natural concept boundaries lie and how to evaluate and re-evaluate those?