GPT-3 was trained on 10,000 NVIDIA V100’s for 14.8 days. Based on my—very uncertain—estimates, OpenAI should now be able train a comparably capable model on an equivalent cluster in under an hour. This implies a drop in hardware requirements of more than 400x.
Factoring out increases in hardware efficiency, I arrive at a central estimate of 170x fewer FLOP to reach GPT-3 level performance today.
By comparison, GPT-3 to GPT-4 was an estimated 40x increase in pf16-equivalent GPU-hours, and an estimated 68x increase in FLOP. I expect OpenAI to have access to significantly more resources today though, than when pre-training GPT-4. This suggests that resources and resource efficiency are growing at roughly similar speeds.
Introduction
Suppose we’re comparing two base models. Using the same inference setup, we find that Model A outperforms Model B across a wide range of benchmarks. What might have caused this difference in performance? Presumably, Lab A beat Lab B on at least one of these six factors:
Cluster size. Example: Model A was trained on 25,000 GPUs whereas Model B was trained on only 10,000 GPUs.
GPU performance. Example: Model A was trained on H100’s whereas Model B was trained on A100’s.
Training duration. Example: Model A was trained for 100 days whereas Model B was trained for only 30 days.
Hardware efficiency. Example: Lab A achieved 40% pre-training MFU whereas Lab B only achieved 30% MFU[1].
Algorithmic efficiency. Example: Model A was trained using a Chinchilla-optimal number of parameters, whereas Model B was not.
Data quality. Example: Model A was trained on a highly curated dataset whereas Model B was trained on some random web-scrape.
Note that data quantity is implicit in this taxonomy: it is determined by factors 1 through 5.
Here’s how I like to think about this framework:
Factors 1, 2 and 3 determine the hardware an AI lab has access to.
Factors 4, 5 and 6 determine the hardwarerequirements—that is, the hardware necessary to reach some performance threshold.
Factors 1 through 4 determine the compute used to train the model.
Factors 5 and 6 determine the compute requirements—that is, the compute necessary to reach some performance threshold.
Finally, the six factors combined determine the effective compute used to train a model.
I’m also going to introduce two umbrella terms: resources for hardware/compute, and efficiency for the inverse of hardware requirements/compute requirements.
Now to the point: my impression is that many people in the AI safety space believe that recent effective compute gains resulted mostly from increases in resources. Especially in policy circles, I often hear statements like: “We are just training bigger Transformers on more data”. Although I agree this dynamic has been very important to recent progress in AI, it doesn’t tell the whole story. In fact, I’ll argue that improvements in efficiency have contributed roughly as much to effective compute increases as resource growth. If I’m correct, this may have important implications for timelines and AI governance.
Disclaimers
A few disclaimers are appropriate.
In this analysis, I focus on pre-training efficiency. I do not intend to estimate progress in finetuning or inference-time techniques.
This post isn’t meant as an argument for the irrelevance of compute. In fact, I believe growing compute will remain crucial to push the state of the art. I also buy the argument that compute is a prerequisite for algorithmic innovation: you need room for experimentation. Whenever I talk about contributions to effective compute gains, those contribution shouldn’t be interpreted as causal contributions (without the compute increase, the efficiency increase may not have been realized).
In Part 1, I’ll say more about the ways we can decompose effective compute. I’ll also say one or two things about measurement: how we can measure increases in hardware and efficiency? I’ll argue the concepts involved are inherently fuzzy, but nevertheless useful.
In Part 2, I’ll estimate how much resources OpenAI would need to pre-train a GPT-3 level model today. My estimates imply a drop in hardware requirements of 414x and a drop in compute requirements of 170x—both with wide error bars. I argue that the implied yearly growth rates are similar to those we see on the resource side.
In the third part, I’ll speculate on the implications of this result for timelines and AI governance. I tentatively conclude that a belief in larger efficiency gains should shorten one’s timelines and that it makes questions around compute thresholds, open model weights and infosecurity more pressing.
Part 1 – Decomposing and measuring effective compute
As I eluded to in the intro, there’s two natural ways to decompose effective compute. The first and more common one is to separate effective compute into compute and compute requirements:
Here, compute is measured in pre-training FLOP, and compute requirements are measured in FLOP-to-reach-performance, given some performance threshold. When Model A is trained using 2x more FLOP than Model B, and also required 2x less FLOP to reach the pre-determined performance threshold, we can say that Model A was trained using 4x more effective compute.
There’s another, equally valid, decomposition of effective compute, where we split the terms into hardware and hardware requirements:
Under this taxonomy, we can measure the ‘amount’ of hardware in equivalent GPU-hours. A GPU-hour is exactly what is says it is: one GPU running for one hour. Of course, some GPUs are more valuable than others. That’s why we generalize the concept to equivalent GPU-hours. In this post, I’ll use a very simple equivalence function based on theoretical GPU performance. The H100 has a maximum performance of 989 TFLOP/s in pf16, while the A100 and V100 can only reach 312 TFLOP/s and 125 TFLOP/s, respectively. We can thus say that 1 hour on an H100 is 3.2x more valuable than an A100-hour and 7.9x more valuable than a V100-hour. I’ll say a cluster of 100 H100’s is fp16-equivalent to a cluster of 790 V100’s[2]. Given this definition, hardware requirements are measured in hardware-to-reach-performance, again given some predetermined performance threshold.
There are two reasons increases in compute and increases in hardware can come apart:
Pre-training FLOP does not track model flop utilization (MFU). When a cluster of GPUs is heavily memory-constrained, a developer incurs costs and researchers can’t access the cluster for longer. However, the idling chips do not consume more FLOP[3].
Pre-training FLOP can be expressed in different number formats. It takes fewer hardware resources to reach 1025 pre-training FLOP when training in pf8 mixed precision, than it does when training in pf16 mixed precision.
Both of these differences are captured by the hardware efficiency factor.
Why go through all this trouble to create a second decomposition? Hardware resources are scarce in this time of bottlenecked CoWoS supply and they also happen to make up the bulk of pre-training costs! If we’re interested in AI progress given supply or budget constraints, decomposing effective compute into hardware resources and efficiency may thus be interesting. I’m not going to argue that one of these decompositions is better than the other—instead, I’ll simply estimate efficiency gains using both approaches.
How can we measure efficiency increases?
Increases in hardware and compute are easily calculated given the definition above. But how can we measure efficiency improvements in the effective compute framework? As I described above, this requires an absolute performance benchmark against which efficiency multipliers can be calculated. Unfortunately, the choice of absolute benchmark is somewhat arbitrary and can influence the calculated efficiency gains. For instance, suppose we come up with some clever method to increase average data quality through the use of synthetic data. Now, we try to measure the accompanied efficiency gains via two methods:
The decrease in necessary resources to reach a 50% score on MMLU;
The decrease in necessary resources to reach a 50% score on HumanEval.
Clearly, the two resulting factors may differ. For example, if our synthetic data is mostly code, it makes sense that we witness larger efficiency gains on HumanEval than on MMLU. One might try to circumvent this problem by averaging over a wide set of performance tests. However, this only partly alleviates our problem: we still have to decide on the minimum score on this aggregate test. Is a 50% average score the appropriate threshold, or should we look at the resources necessary to reach 90%? Again, the resulting efficiency gains may differ. And it gets worse: the above framework assumes that progress only results in higher proficiency on the same task. But what if algorithmic progress enables models to perform entire new tasks? No matter how much more we compute we throw at GPT-3, it won’t suddenly develop multimodal capabilities. Should we thus conclude that algorithmic efficiency gains between 2020 and 2023 are infinite? That seems silly to say the least.
This is all quite bad, and I think sufficient reason to restrain from using effective compute as a central concept in regulation for now. That said, I believe the effective compute framework is highly useful for other purposes, primary among which is to inform foresight work. If we witness a 100x efficiency increase on some aggregate performance test, this is highly relevant information. For instance, it might mean we have to prepare for the proliferation of very capable open source models, or update our timelines to Transformative AI (TAI).
Part 2 – What does it take to train a GPT-3 level model today?
I’m mostly interested in using the effective compute framework to guide foresight into the arrival of TAI. That means I’m not very interested in efficiency gains on simple, clearly demarcated tasks. Instead, I’d like to focus on performance benchmarks that capture general knowledge and reasoning ability. Large, general systems really only saw the light of day with the publication of GPT-3. This means that for relevant comparisons of pre-training efficiency, we can’t travel far back in time. That’s unfortunate, because data over longer time horizons could enable more robust results. I’m deliberately choosing specificity over data quantity here.
OpenAI ran 10,000 NVIDIA V100’s for 14,8 days to train GPT-3, performing a total of 3.14*1023 FLOP. If we can estimate how many fewer resources OpenAI would need to train a similarly capable model today, that knowledge could improve our estimates of future efficiency gains. Of course, future efficiency gains can deviate from past ones for a host of reasons. Getting a better grip of the baseline trend seems clearly beneficial to me, however.
Presumably, OpenAI wouldn’t run V100’s anymore, but instead would train on H100’s. I will thus try to answer the following question:
How many FLOP and GPU-hours would OpenAI require today to train a GPT-3 level model, using a 1.264 GPU H100 cluster?[4]
Again, some disclaimers are appropriate:
You are of course free to replace OpenAI with Google Deepmind or another AI lab. I’m choosing OpenAI here because I think they are ahead on efficiency.
The notion of a ‘GPT-3 level model’ is not very rigorous. I’m trying to point at a base model that scores roughly comparable on a broad set of industry benchmarks (MMLU, WinoGrande, HumanEval etc.), and would be preferred by users to GPT-3 roughly 50% of the time.
GPT-3 is an older, different base model from GPT-3.5-turbo. The latter was likely trained on many more tokens, probably utilizes Mixture of Experts techniques and boasts a longer context window. According to this Microsoft paper, GPT-3.5-turbo has 20B parameters, whereas GPT-3’s has 175B. I’m not claiming that it’s possible to pre-train the free version of ChatGPT using 400x fewer GPU-hours – in fact, this seems highly unlikely to me.
Epoch’s estimates of efficiency increases
GPT-3 pre-training probably took place in early 2020. That’s roughly 4 years ago. Epoch Research estimates that algorithmic efficiency on ImageNet increased by a factor 2.5 per year. In their (highly recommended!) interactive model, Epoch notes that progress in language modelling could be slower or faster. The interactive model’s standard settings presume slightly slower progress in language modelling—roughly 2.3x a year, again with wide error bars. The interactive model also accounts for hardware efficiency: the average value yields efficiency improvements of roughly 1.35x a year due to better parallelization, the use of other number formats and other optimization techniques. There’s no separate parameter for improvements in data quality.
Over 4 years, Epoch’s estimates would imply a drop in hardware requirements of about 93x and a drop in compute requirements of about 28x. Those are a large efficiency gains! In fact, they are roughly comparable to the jump from GPT-3 to GPT-4 (~40x more pf16-equivalent GPU-hours and 68x more FLOP) and only slightly smaller than the jump from GPT-3 to Gemini Ultra (~85x more pf16-equivalent GPU-hours and 287x more FLOP)[5]. As Ege Erdil points out, it’s interesting – and perhaps not entirely coincidental – that these estimates imply efficiency and hardware resources seem to increase at roughly similar speeds.
To me, Epoch’s estimates still seem a bit too low (although they liberally fit inside my 80% CI). Using an independent and more direct approach to estimate efficiency gains in LLMs, I arrive at a point estimate of 413x smaller hardware requirements and 170x smaller compute requirements.
Methodology
My methodology is very unsophisticated: I’ll simply sample repeatedly from probability distributions over reported (or unreported but likely) efficiency gains and multiply the resulting values. Of course, this is far from ideal, for a couple of reasons:
Efficiency gains in papers are often overblown, or fall apart when scaling up models. My estimates would be far more reliable if someone had actually tried to train a GPT-3 level model using as little hardware resources as possible. I’m not aware of any such results. I also think it’s highly unlikely an AI lab would perform such an analysis today and then publish it. After all, there is no longer a market for compute-optimal GPT-3 level models. Developers either focus on next-generation SOTA models trained using Chinchilla-optimal compute allocations (e.g. Gemini Ultra), or they invest in heavily overtraining smaller models that can be run cheaply and/or locally (there also exist scaling laws for these purposes – see this new MosaicML paper). However, we can expect AI labs to utilize all efficiency multipliers available to them when trying to build TAI. It therefore makes sense to include efficiency improvements even if they haven’t been combined in an actual properly sized training run before. To avoid overestimating progress, I’ll focus on only a handful of well-known techniques that seem reliable and which are reported to have large effect sizes. I won’t pull from arbitrary arXiv papers.
When multiplying several efficiency improvements, the implicit assumption is that those improvements are independent. This need not be a valid assumption! For instance, some tweak to the attention mechanism might not yield the same multiplicative efficiency improvement in the context of a simultaneous adjustment of the feed-forward layers. I’ll thus try to estimate conditional probability distributions given some fixed order of efficiency improvements. When available, I’ll also try to base my estimates on studies that incorporate multiple improvements at the same time.
It is much cheaper (computationally) to train a GPT-3 level model today if you have access to a next-generation model like GPT-4. In such case, you can train your GPT-3 level model on GPT-4 outputs, or use GPT-4 to improve data curation. However, in our context, I believe this would be cheating. I’m interested in efficiency gains in training a GPT-3 level model because it tells us something about the efficiency gains achievable in training a SOTA model. And to state the obvious: you don’t have access to a next-generation model when training a SOTA model. Therefore, I’ll limit admissible efficiency improvements to improvements that are achievable without access models on par with or better than GPT-3.
There’s one more downside to this methodology, which has to do with me: I’m not an ML practitioner. Although I try to keep up with the literature, my interpretations of empirical results will not be as grounded as those of someone who spends their days training LLMs. If you think my conditional probability distributions are off, I’m misjudging the (in)dependence of different improvements, or have generally misunderstood something, please let me know in the comments!
With all that out of the way, here’s a summary of the efficiency gains I decided to include and their accompanied point estimates. Also note the fixed order of efficiency-enhancing techniques. I’ll elaborate and provide probability distributions below.
Efficiency-enhancing technique
Median efficiency improvement conditional on previous improvements
Algorithmic efficiency
x72
Transformer++
x2.5
Mixture of experts
x2.5
Non-published algorithmic improvements
x3.5
Chinchilla scaling
x3.0
Data quality
x2.2
Hardware efficiency
x2.5
Total
x413
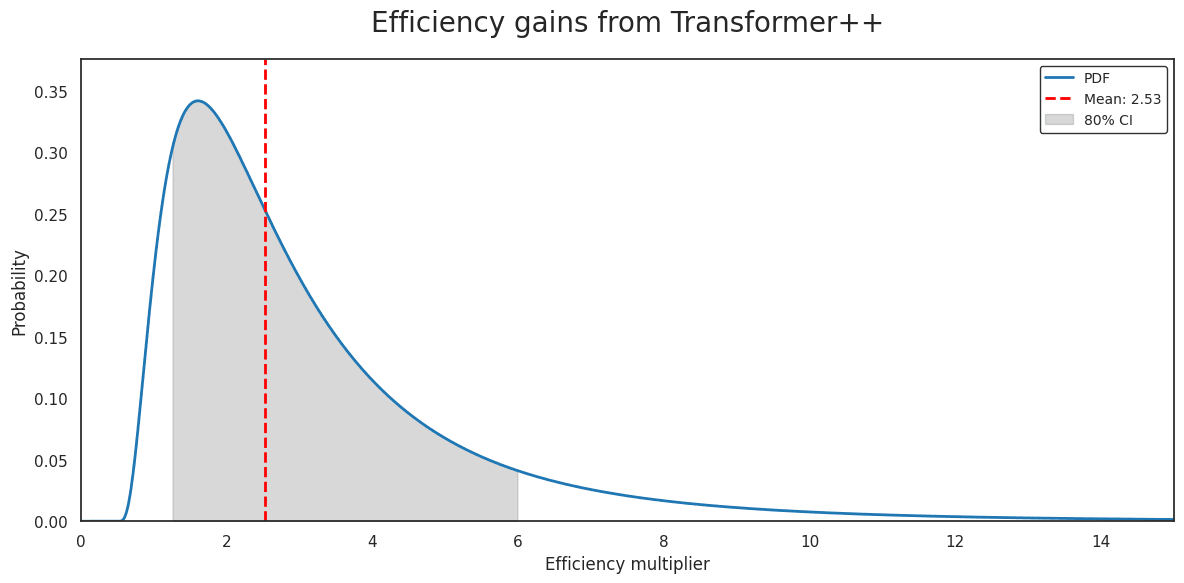
Efficiency improvement 1: Transformer++
Since the release of GPT-3, researchers seem to have settled on a superior transformer architecture and training recipe. These changes have been adopted successfully in, for instance, Llama-2, PaLM and Mistral 8x7b. The main changes to the original formulation are:
Architecture
Using RMSnorm instead of Layernorm
Using rotary positional embeddings instead of absolute or relative positional embeddings
No bias vectors
SwiGLU activations instead of ReLU
Training recipe
Using the AdamW optimizer instead of Adam
Adopting a slightly different learning rate schedule
In the Mamba paper, Albert Gu and Tri Dao directly compare this ‘Transformer++’ to the original vanilla transformer[6]. They find that when training a model with a 2048 token context window (the same context size as GPT-3), the Transformer++ requires about 6x less compute to gain the same loss on the Pile as the vanilla transformer. However, gains of such magnitude often turn out smaller when sizing up models (Gu and Dao only trained models up to 1.3B parameters for about 2*10^20 FLOP). I couldn’t find any clean comparisons between the vanilla Transformer and the Transformer++ at appropriate scales. I’ll thus impose a penalty here, appealing to base rates. As a very partial justification for this decision, the use of rotary positional embeddings does not seem to yield massive improvements: Llama-65B and Chinchilla share almost precisely the same compute budget, token-to-parameter ratio, model architecture and training recipe, with the significant difference that Llama uses rotary positional embeddings, whereas Chinchilla uses relative positional embeddings. Looking at reported benchmark performance, I’d say the performance of these two models is very comparable.
I have large uncertainty over the efficiency multiplier at larger scales. If you have more knowledge of real the magnitude at larger scales, please let me know! For now, I’ll incorporate a 80% CI ranging from 1,25x to 6x (lognormally distributed):
Efficiency improvement 2: Mixture of Experts
Mixture of Expert (MoE) models do not only decrease per-parameter memory requirements during inference – they are also widely reported to yield better per-FLOP pre-training performance. There’s a bunch of different MoE implementations out there, with large variety in the number of (active) experts and routing mechanisms. All these formulations seem to improve upon the dense transformer, with efficiency gains ranging from 4x to 7x (see for instance, this, this, this and this paper)
In addition, MoE models have been very popular among users. Both GPT-3.5-turbo and GPT-4 probably employ MoE techniques. So far, very few seem to have caught up with their performance. The success of Mistral’s recently released MoE model strengthens the hypothesis that the dominance of the GPT-models is not only down to great RLHF. Mixtral 8x7b seems to be the first consumer-oriented open source MoE model and is also the first model to beat GPT-3.5-turbo in the Huggingface Chatbot Arena. This provides additional weak evidence that efficiency gains from MoE are quite large, even at scale. Looking at the Mixtral 8x7b Python code, it’s basically Llama-2 except for the sparse feedforward layers. That means the improvements over Llama-2 resulted from either MoE or differences in training data.
There is, however, also some evidence that the performance benefits of MoE decrease with scale (see this Meta AI paper). Meta’s implementation is different from OpenAI’s and Mistral’s though (for one, they use 512 experts instead of 16 or 8 experts). All in all, I’m going to assume a mean efficiency gain of x2,5 with a 90% CI ranging from x1,25 to 5x (lognormally distributed):
Efficiency improvement 3: Unpublished innovations
Recall that I’m interested in the hardware resources OpenAI would require to train a GPT-3 level model today. This challenge admits the use of unpublished algorithmic innovations (or published ones that have been looked over by competitors). After the release of GPT-3, OpenAI released few research papers and details on their models. This suggest they have implemented improvements to the GPT-3 architecture and training recipe that they do not wish to share (presumably for sensible commercial and safety-related reasons). It’s very unclear how large these unpublished efficiency improvements are. Some of their breakthroughs may not have been incorporated into public models yet, meaning we haven’t even witnessed their downstream effects.
There exist a couple of very crude data points though. The first is that open-source models generally failed to achieve GPT-3.5 levels, let alone GPT-4 levels in 2023. This could imply some secret algorithmic pre-training sauce, but could also be due to MoE techniques or better RLHF. As a second data point, we can look at comparisons with other leading AI-labs. Gemini Ultra is estimated to be trained on 4-5x more compute than the original GPT-4. Nevertheless, on language modelling task, all this extra compute has not translated into better performance. I’ve heard a few possible explanations:
It turns out scaling laws hit a wall right after GPT-4 size.
Gemini ultra wasn’t actually trained using much more compute than GPT-4.
Gemini is trained on a lotof multimodal data, and there was very limited transfer to language tasks.
OpenAI has some secret algorithmic sauce and Google hasn’t caught up.
I think a combination of the third and fourth explanation is most likely.
As Dwarkesh Patel points out: looking at the scaling graphs in the GPT-4 paper, we see super smooth trend lines, not at all suggestive of the end of power-law-scaling being near.
Furthermore, Google’s intention was to blow GPT-4 out of the water. Given Google’s massive compute resources, it seems very unlikely they would have gambled on getting ahead purely through superior efficiency.
Strengthening my belief that OpenAI is ahead on efficiency is the 2.5x price drop from GPT-4 to GPT-4 Turbo. This large price drop is accompanied by significantly better performance in the Huggingface Chatbot Arena, which may suggest some type of algorithmic improvement in the pre-training stage.
Finally, it seems that over the last year, OpenAI has succesfully convinced many Google researchers to join the other side. Presumably, these researchers bring with them knowledge of efficiency-enhancing techniques that Google would have liked to keep secret. There are also some moves in the other direction, but seemingly these are much more scarce.
All in all, my guess is that OpenAI has access to algorithms that are at least twice as efficient as Google’s. This still leaves open another question: how large are the efficiency gains that Google discovered since the publication of GPT-3 and decided to not publish? Presumably, their amount of secret algorithmic innovation is non-zero as well.
I’m very uncertain about all this though. OpenAI’s lead might be small, but I also entertain the possibility that they stumbled upon a very large improvement, or managed to chain together many small improvements that add up to large ones. My 80% CI ranges from 1,5x to 13x algorithmic improvements since GPT-3 (lognormally distributed):
Efficiency improvement 4: Chinchilla scaling
GPT-3 wasn’t trained using Chinchilla-optimal compute allocation. Although it boasts 175 billion parameters, GPT-3 was pre-trained on only 300B tokens. According to the Chinchilla paper, an optimal 175 billion parameter model should be trained on 3,7 to 12,0 trillion tokens. If we want to achieve the same pre-training loss as GPT-3, how much compute do we need according to the Chinchilla scaling laws? Approximately 3x less, according to this analysis by MosaicML. A 30 billion parameter GPT-3 trained on 610 billion tokens should have slightly better performance than the actual GPT-3, and would only require 1,1*10^23 FLOP.
Chinchilla scaling laws seem to have been adopted by the entire industry. The above efficiency multiplier thus seems quite reliable for dense transformer models of this size[7]. However, I’m not sure about the applicability in the context of MoE models. Looking at the leaked information about GPT-4, it seems OpenAI stuck to the compute-to-token relationship implied by Chinchilla, even though incorporating sparsity increased total parameter count (another way to look at this is to say that they applied Chinchilla scaling laws to the number of active parameters per forward pass). Of course, the fact that they arrived at the same optimal number of tokens for an MoE model doesn’t necessarily mean the performance benefits are equal to those in dense models. That said, I see no clear reason to assume smaller or larger gains. I’ll thus stick to the dense point estimate but include quite wide error bars to account for the uncertainty induced by MoE. My 80% CI ranges from 1.5x to 4.5x efficiency improvements (normally distributed)[8]:
(A small tangent: one could also interpret the Chinchilla result as progress in data rather than algorithmic efficiency. I prefer to classify Chinchilla as algorithmic progress, since limiting the number of parameters is an architectural adjustment. Moreover, training on more tokens need not impact data quality, only data quantity.)
OpenAI only achieved 19.6% MFU pre-training GPT-3[9]. This means that 4⁄5th of the time, their GPUs were waiting for data to roll in, instead of performing matrix operations. Today, thanks to innovations in parallelization techniques and low-level software optimizations such as Flash Attention 2, AI labs can achieve much higher MFU – especially when training models with relatively short context windows (GPT-3 only has a 2048 token context window). Two years after the release of GPT-3, Google achieved 46,2% MFU training PaLM (a 540b parameter model with the same context window). One might counter that it’s easier to achieve high MFU on TPUs than on GPUs. This could be true especially for H100’s due to their insane FLOP to memory bandwidth ratio. However, MosaicML was able to reach 40% MFU on a cluster of 512 NVIDIA H100’s training a 30 billion parameter model. This was before the release of Flash Attention 2, which is supposedly another big step up from Flash Attention 1. Here, Tri Dao claims he achieved 72% MFU training small GPT-3-style models using Flash Attention 2.
Better hardware efficiency is also possible through the use of other, lower-precision number formats like pf8 and INT8. Inflection AI’s new model was trained in pf8 mixed precision, and presumably, they had a reason for doing so. Lambda Labs reports 60% higher training efficiency using pf8 mixed precision and this study shows pretty much zero accuracy loss when making some clever decisions. However, at this time, Flash Attention 2 doesn’t support pf8 training yet, which means it’s a decision between two gains of reportedly similar sizes.
As I said before, I want to assess individual efficiency gains conditional on the other efficiency gains. As it happens, incorporating an MoE architecture in the feed-forward layers could decrease MFU due to increased memory demands. The same could hold for non-published algorithmic improvements. OpenAI is reported to have reached ~34% MFU on GPT-4, which supposedly has 16 experts, 2 of which are active per forward pass. However, GPT-4 was mostly trained with an 8k context length and is much bigger than a compute-optimal GPT-3. Also, OpenAI didn’t have access to Flash Attention 2 when training GPT-4 (although we can’t rule out they had some internal alternative).
All in all, I’m going to assume efficiency gains from improved hardware efficiency are normally distributed with an 80% CI ranging from 1.7 to 3.3[10].
Efficiency improvement 6: Higher data quality
With phi-2, Microsoft managed to train a 2,7 billion parameter model that they say beats similar models of 25x the size. Their insight? Much better quality through extensive data curation and the use of synthetic data. We don’t get many details on the phi-2 data pipeline, but it’s fair to assume they made extensive use of GPT-4, as they did the same or the predecessor model, phi-1.5. Like I said before, I consider using GPT-4 to be cheating in our context. The phi-1.5 paper, however, also mentions a phi-1.5-web-only model, which is not trained using synthetic data. Instead, this model is trained on a carefully curated dataset where examples are selected based on their ‘educational value’. A random forest classifier is used to determine whether an individual example scores sufficiently high on educational value to be included in the dataset. GPT-4 is used to generate 100.000 samples for training the random forest classifier, but as the authors note, this is only done to speed up the work that would otherwise be done by human annotators. Assuming human workers can annotate one sample per minute, and are paid €15 an hour, annotating 100.000 examples costs about €25.000. This seems highly reasonable and not expensive enough to deem the use of GPT-4 essential. Selecting tokens based on their educational value is thus a method OpenAI would be allowed to make use of. And it seems they would want too: phi-1.5-web-only models outperforms Falcon 1.3B, even though it’s trained on roughly 3,5x fewer tokens and it shares many tokens with Falcon 1,3B (they both use the Falcon refined web dataset).
Speaking of the refined web dataset: the Falcon LLM team shows that it is possible to greatly increase data quality through strict filtering and de-duplication. Extrapolating their headline graph, their filtered and de-duplicated dataset seems to yield about a 3x efficiency increase compared to direct training on the Pile. This seems to be another example of long-hanging fruit in de data-curation realm.
How big are the efficiency gains OpenAI could achieve from using non-GPT-4-mediated data innovations? It’s hard to say. Based on the two results above, it seems like there was a lot of low hanging fruit left to be plucked after the release of GPT-3. I’m going to impose penalties though for lack of scale in the phi-1.5 and Falcon experiments, and because phi-1.5 and Falcon 1.3B have slightly different architectures. My 80% CI ranges from 1x to 6x (lognormally distributed):
Training a GPT-3 level model using 170-413x fewer resources
Sampling from the different conditional probability distributions yields the following distribution describing the total potential reduction in hardware requirements[11]:
The median efficiency improvement equals 414x. That would imply a yearly average efficiency increase of 4.3x, or equivalently, 0.63 OOM. Also note the very long tail: according to my estimates, there’s a 27% chance that efficiency gains in the last 4 years added up to over 1000x.
Here’s a similar distribution describing the potential reduction in compute requirements:
My median estimate is a 170x reduction in compute. That implies a yearly average efficiency increase of 3.6x, or equivalently, 0.56 OOM. This is higher than Epoch’s estimate of 2.3x per year (or, equivalently, 0.36 OOM).
The median results seems quite high compared to the aforementioned increases in resources from GPT-3 to GPT-4 and GPT-3 to Gemini Ultra. One might reasonably argue, however, that the comparison isn’t fair: we are comparing a hypothetical training run to a realized training run. Given that most H100′s and new TPUs only started to arrive in the second half of 2023, it seems likely that OpenAI and Google have access to more resources now than they had when training their latest models. If we assume that OpenAI and/or Google could currently train a SOTA model using the equivalent of 50.000 H100′s for 100 days, achieving 50% MFU (I’m basing these very uncertain estimates on thesetwo Semianalysis pieces), that would translate to a 267x increase in hardware and a 668x increase in compute—again roughly similar to my estimated efficiency gains.
Before I go into possible implications of these findings, I want to address something that kept bugging me: although the individual conditional probability distributions included in this post seem reasonable to me, I do find it a bit suspicious that the efficiency gains share very similar magnitudes (all of the medians are between 2.2x and 3.5x). This may be a coincidence but it may also be explained by unfounded conservatism from my part. I’m curious to hear your thoughts!
Part 3 – Implications for timelines and governance
In this final part, I will speculate on the possible implications of these results for TAI timelines and AI governance. First though, I want to address the extrapolation question: suppose the historical 4.3x annual efficiency improvement is correct – can we expect it to continue?
Future efficiency gains
There are a couple of reasons to believe efficiency gains will be smaller in the coming years:
MFU improvements have a clear roof: you cannot achieve more than 100% MFU. There’s probably a similar ceiling somewhere for the use of lower-precision number formats: after a while, you are going to give in too much on accuracy.
You can only optimize the token-to-parameter ratio once. It seems possible we won’t find any more macro-level improvements like Chinchilla.
Maybe we’ve plucked most of the algorithmic low-hanging fruit.
There are, however, also reasons to suspect larger yearly efficiency gains:
We’ve just scratched the surface on data quality techniques. Now that AI models can contribute to data curation and data synthetization, we should expect larger gains in data quality.
It seems possible that the further developments in Selective State Space models will yield large algorithmic efficiency gains.
We are nearing the point where AI models can significantly contribute to algorithmic innovation.
Although I’m very uncertain, I believe we should probably give more weight to the second class of arguments: I think it is more likely than not that we will see acceleration of yearly efficiency improvements.
Implications for TAI timelines
If efficiency plays a larger role than commonly believed, this doesn’t suddenly make existing models more capable. It means we had more efficiency improvements, but also that apparently, models need more effective compute to reach observed performance levels. At first glance, we might thus conclude that there are no implications for timelines to TAI. I think this would be the wrong conclusion, though.
My primary reason to update towards shorter timelines is that it seems more likely to me that we’ll run into bottlenecks on the hardware resources side than on the efficiency side. Hardware supply is currently bottlenecked by TSMC’s packaging capacity. I can easily imagine this bottlenecks to last for another couple of years. After that point, we might start to see budget constraints: it could start getting harder and harder for AI labs to keep spending exponentially more money on training runs. This need not be rational. It seems quite likely to me that Microsoft and Google will invest more conservatively in the future than OpenAI and the Deepmind department might like, simply because it’s hard to sell >$100 billion yearly infrastructure investments to shareholders. Suppose it’s true that we’ll keep running into bottlenecks on the hardware side. In a world without any efficiency gains, this would significantly slow down AI progress. If, however, efficiency gains make up a large chunk of yearly effective compute increases, these bottlenecks will not slow down progress as much. After all, there’s efficiency progress to be made, even given static resources (although, as stated earlier, we should expect such progress to be slower due to less experimentation compute).
Implications for AI governance
What do these results imply for AI governance, and AI policy in particular? Three consequences jump to mind:
Infosecurity issues become more pressing if efficiency is a larger driver of effective compute increases than previously thought. After all, in such case, adversaries will have a larger incentives to try and steal the source code from leading AI labs.
The case for quickly adjustable compute thresholds becomes stronger. If efficiency improvements are small, you can keep thresholds static for longer. If we’re seeing 0.6 OOM efficiency improvements a year though, we might have to adjust on a yearly or two-yearly schedule.
Finally, we might expect open-source models to fare relatively better in a world where yearly efficiency gains are large. After all, open-source developers tend to have access to much fewer resources than the big AI labs. If, however, there’s a lot of progress to be made without building larger GPU clusters, the open source community seems to have a better chance of keeping up. That said, outcomes would probably also become more dependent on whether leading AI labs manage to keep their efficiency-enhancing techniques secret.
Doubtlessly I’m overlooking many other possible governance implications here. I plan on giving these questions some more thought, and would be very glad to receive feedback.
Of course, this equivalence function doesn’t capture all the relevant differences between hardware clusters. For instance, it doesn’t address differences in networking. In this framework, those factors will end up influencing hardware efficiency. Of course, one is free to use a more elaborate equivalence functions. Here, I’m mostly trying to keep things simple.
The number of physical FLOP can also depend on re-computation. A common method to deal with memory-bottlenecks is to recompute values during training (re-materialization). This increases the number of physical FLOP but does not increase model performance.
I’m not incorporating SSM’s in my algorithmic improvements since I haven’t seen any results showing reliable performance increases at scale. I wouldn’t be surprised though if future developments to SSM’s lead to significant efficiency gains.
To be precise again: I’m using a truncated normal with a base of support between x=0 and x=4.7 to prevent MFU’s that are smaller than 0 or larger than 1.
I changed all sampled values smaller than 1.0 to 1.0 because, presumably, if an algorithmic adjustment harms performance, OpenAI would choose not to incorporate it.
Before Chinchilla scaling, nobody was solving the relevant optimization problem. Namely, given a perplexity target, adjust all parameters including model size and geometry, sparsity, and amount of data (sampled from a fixed exceedingly large dataset) to hit the perplexity target with as few FLOPs as possible. Do this for multiple perplexities, make a perplexity-FLOP plot of optimized training runs to be able to interpolate. Given a different achitecture with its own different plot, estimated improvement in these FLOPs for each fixed perplexity within some range is then the training efficiency improvement valid within that range of perplexities. This might not be the most important measurement in practice, but it makes the comparison between very different architectures meaningful at least in some sense.
Without MoE, the gains since GPT-3 recipe seem to be about 6x (see Figure 4 in the Mamba paper). I’m not sure what the MoE gains are on top of that, the scaling laws I’ve seen don’t quite measure the thing I’ve defined above (I’d be grateful for a pointer). Going from FP32 to BF16 to something effectively 6-bit with Microscaling (see section 4.5) without loss of training quality is another potential win (if it’s implemented in future hardware, or if there is a software-only way of getting similar results without an overhead).
But I’m not sure there is much more there, once the correct optimization problem is being solved and the low hanging fruit is collected, and if the dataset remains natural. The historical algorithmic progress is misleading, because it wasn’t measuring what happens when you use unlimited data and can vary model size to get as much compression quality as possible out of given compute.
Thanks for the comment! I agree that would be a good way to more systematically measure algorithmic efficiency improvements. You won’t be able to infer the effects of differences in data quality though—or are you suggesting you think those are very limited anyway?
My point is that algorithmic improvements (in the way I defined them) are very limited, even in the long term, and that there hasn’t been a lot of algorithmic improvement in this sense in the past as well. The issue is that the details of this definition matter, if you start relaxing them and start interpreting “algorithmic improvement” more informally, you become able to see more algorithmic improvement in the past (and potentially in the future).
One take is how in the past, data was often limited and carefully prepared, models didn’t scale beyond all reasonable compute, and there wasn’t patience to keep applying compute once improvement seemed to stop during training. So the historical progress is instead the progress in willingness to run larger experiments and in ability to run larger experiments, because you managed to prepare more data or to make your learning setup continue working beyond the scale that seemed reasonable before.
This isn’t any algorithmic progress at all in the sense I discuss, and so what we instead observe about algorithmic progress in the sense I discuss is its historical near-absence, suggesting that it won’t be appearing in the future either. You might want to take a look at Mosaic and their composer, they’ve done the bulk of work on collecting the real low-hanging algorithmic improvement fruit (just be careful about the marketing that looks at the initial fruit-picking spree and presents it as endless bounty).
Data doesn’t have this problem, that’s how we have 50M parameter chess or Go models that match good human performance even though they are tiny by LLM standards. Different data sources confer different levels of competence on the models, even as you still need approximately the same scale to capture a given source in a model (due to lack of significant algorithmic improvement). But nobody knows how to scalably generate better data for LLMs. There’s Microsoft’s phi that makes some steps in that direction by generating synthetic exercises, which are currently being generated by stronger models trained on much more data than the amount of exercises being generated. Possibly this kind of thing might eventually take off and become self-sufficient, so that a model manages to produce a stronger model. Or alternatively, there might be some way to make use of the disastrous CommonCrawl to generate a comparable amount of data of the usual good level of quality found in better sources of natural data, without exceeding the level of quality found in good natural data. And then there’s RL, which can be thought of as a way of generating data (with model-free RL through hands-on exploration of the environment that should be synthetic to get enough data, and with model-based RL through dreaming about the environment, which might even be the real world in practice).
But in any case, the theory of improvement here is a better synthetic data generation recipe that makes a better source, not a better training recipe for how to capture a source into a model.
Before Chinchilla scaling, nobody was solving the relevant optimization problem. Namely, given a perplexity target, adjust all parameters including model size and geometry, sparsity, and amount of data (sampled from a fixed exceedingly large dataset) to hit the perplexity target with as few FLOPs as possible. Do this for multiple perplexities, make a perplexity-FLOP plot of optimized training runs to be able to interpolate. Given a different achitecture with its own different plot, estimated improvement in these FLOPs for each fixed perplexity within some range is then the training efficiency improvement valid within that range of perplexities. This might not be the most important measurement in practice, but it makes the comparison between very different architectures meaningful at least in some sense.
Without MoE, the gains since GPT-3 recipe seem to be about 6x (see Figure 4 in the Mamba paper). I’m not sure what the MoE gains are on top of that, the scaling laws I’ve seen don’t quite measure the thing I’ve defined above (I’d be grateful for a pointer). Going from FP32 to BF16 to something effectively 6-bit with Microscaling (see section 4.5) without loss of training quality is another potential win (if it’s implemented in future hardware, or if there is a software-only way of getting similar results without an overhead).
But I’m not sure there is much more there, once the correct optimization problem is being solved and the low hanging fruit is collected, and if the dataset remains natural. The historical algorithmic progress is misleading, because it wasn’t measuring what happens when you use unlimited data and can vary model size to get as much compression quality as possible out of given compute.
Thanks for the comment! I agree that would be a good way to more systematically measure algorithmic efficiency improvements. You won’t be able to infer the effects of differences in data quality though—or are you suggesting you think those are very limited anyway?
My point is that algorithmic improvements (in the way I defined them) are very limited, even in the long term, and that there hasn’t been a lot of algorithmic improvement in this sense in the past as well. The issue is that the details of this definition matter, if you start relaxing them and start interpreting “algorithmic improvement” more informally, you become able to see more algorithmic improvement in the past (and potentially in the future).
One take is how in the past, data was often limited and carefully prepared, models didn’t scale beyond all reasonable compute, and there wasn’t patience to keep applying compute once improvement seemed to stop during training. So the historical progress is instead the progress in willingness to run larger experiments and in ability to run larger experiments, because you managed to prepare more data or to make your learning setup continue working beyond the scale that seemed reasonable before.
This isn’t any algorithmic progress at all in the sense I discuss, and so what we instead observe about algorithmic progress in the sense I discuss is its historical near-absence, suggesting that it won’t be appearing in the future either. You might want to take a look at Mosaic and their composer, they’ve done the bulk of work on collecting the real low-hanging algorithmic improvement fruit (just be careful about the marketing that looks at the initial fruit-picking spree and presents it as endless bounty).
Data doesn’t have this problem, that’s how we have 50M parameter chess or Go models that match good human performance even though they are tiny by LLM standards. Different data sources confer different levels of competence on the models, even as you still need approximately the same scale to capture a given source in a model (due to lack of significant algorithmic improvement). But nobody knows how to scalably generate better data for LLMs. There’s Microsoft’s phi that makes some steps in that direction by generating synthetic exercises, which are currently being generated by stronger models trained on much more data than the amount of exercises being generated. Possibly this kind of thing might eventually take off and become self-sufficient, so that a model manages to produce a stronger model. Or alternatively, there might be some way to make use of the disastrous CommonCrawl to generate a comparable amount of data of the usual good level of quality found in better sources of natural data, without exceeding the level of quality found in good natural data. And then there’s RL, which can be thought of as a way of generating data (with model-free RL through hands-on exploration of the environment that should be synthetic to get enough data, and with model-based RL through dreaming about the environment, which might even be the real world in practice).
But in any case, the theory of improvement here is a better synthetic data generation recipe that makes a better source, not a better training recipe for how to capture a source into a model.