What does it mean for an LLM such as GPT to be aligned / good / positive impact?
(cross post from my sub-stack)
What does it mean for a language model to be good / aligned / positive impact?
In this essay, I will consider the question of what properties that an LLM such as GPT-X needs to have in order to be a net positive for the world. This is both meant to be a classification of OpenAIs and commentator’s opinions on the matter as well as my input of what the criteria should be. Note, I am NOT considering the question of whether the creation of GPT-4 and previous models have negatively contributed to AI risk by speeding up AI timelines. Rather these are pointers towards criteria that one might use to evaluate models. Hopefully, thinking through this can clarify some of the theoretical and practical issues to have a more informed discussion on the matter.
One general hope is that by considering LLM issues at a very deep level, one could end up looking at issues that are going to be relevant with even more complex and agentic models. Open AI’s statement here and Anthropic’s paper here example, seems to indicate that this is both of their actual plans. However, the question still stands which prospective OpenAI (or similar companies) are considering the issues from.
These issues are mainly regarding earlier iterations (GPT-3 / chat GPT) as well as OpenAI’s paper on GPT-4.

When evaluating the goodness of an LLM like GPT-X, it is essential to consider several factors.
1. Accuracy of the model.
OpenAI is currently looking at this issue, but their philosophical frame of accuracy has drawn criticism from many quarters.
2. Does the model has a positive impact on its own users.
This is tied up in the question of how much responsibility tech companies have in protecting their users vs.enabling them. There are critiques that OpenAI is limiting the model’s capabilities, and although negative interactions with users have been examined, they have not been addressed sufficiently.
3. How does the model affect broader society.
To evaluate this issue, I propose a novel lens, which I call “signal pollution.” While OpenAI has some ideas in this field, they are limited in some areas and unnecessarily restrictive in others.
4. Aimability
Finally, I consider the general “aimability” of the language model in relation to OpenAI’s rules.which is a concept that GPT will share with an even more capable “AGI” agentic model. I argue that the process Open AI uses does not achieve substantial “aimability” of GPT at all and will work even worse in the future.
By considering these factors, we can gain a better understanding of what properties an LLM should have to be a net positive for the world, and how we can use these criteria to evaluate future models.
Is the language model accurate?
The OpenAI paper on human tests in math and biology highlights the impressive pace of improvement in accuracy. However, the concept of “accuracy” can have multiple interpretations.
a. Being infinitetly confident in every statement
This was the approach taken by GPT-3, which was 100% confident in all its answers and wrote in a self-assured tone when not constrained by rules. This type of accuracy aligns with the standardized tests but is somewhat naive.
b. Being well calibrated
A very familiar concept on LessWrong, being well-calibrated based on a Brier score or similar metric is a more holistic notion of accuracy than “infinite confidence.” Anthropic seems to support this assessment, and OpenAI also mentions calibration in their paper. However, it is unclear whether soliciting probabilities is an additional question or whether probabilistic ideas emerge directly from the model’s internal states. It is also an intriguing problem why calibration deteriorates post-training.
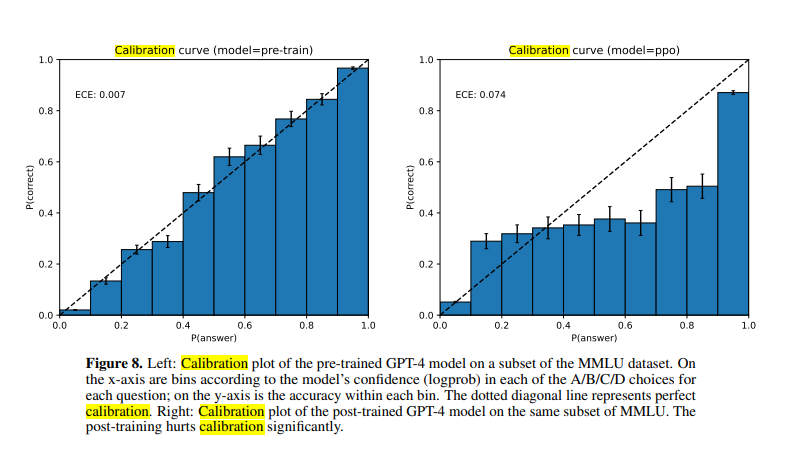
3. Multi-opinion respresentation
While calibration is an improvement over infinite confidence, it may not be sufficient for handling controversial or politically sensitive information. In such cases, without a strong scientific basis for testing against reality, it may be more appropriate to surface multiple opinions on an issue rather than a single one. Similar to calibration, one could devise a test to evaluate how well ChatGPT captures situations with multiple opinions on an issue, all of which are present in the training data. However, it is evident that any example in this category is bound to be controversial.
I don’t anticipate OpenAI pursuing this approach, as they are more likely to skew all controversial topics towards the left side of the political spectrum, and ChatGPT will likely remain in the bottom-left political quadrant. This could lead to competitors creating AIs that are perceived to be politically different, such as Elon’s basedAI idea. At some point, if a company aims to improve “accuracy,” it will need to grapple with the reality of multiple perspectives and the lack of a good way to differentiate between them. In this regard, it may be more helpful and less divisive for the model to behave like a search engine of thought than a “person with beliefs.”
d) philosophically / ontologically accurate.
The highest level of accuracy is philosophical accuracy, which entails having the proper ontology and models to deal with reality. This means that the models used to describe the world are intended to be genuinely useful to the end user.
However, in this category, ChatGPT was a disaster, and I anticipate that this will continue to be the case.

One major example of a deep philosophical inaccuracy is the statement “I am a language model and not capable of ‘biases’ in a traditional sense.” This assertion is deeply flawed on multiple levels. If “bias” is a real phenomenon that humans can possess, then it is a property of the mental algorithm that a person uses. Just because an algorithm is implemented inside a human or computer mind does not alter its properties with regard to such behavior. This is a similar error that many people make when they claim that AGI is impossible by saying “only humans can do X.” Such statements have been disproven for many values of X. While there may still be values of X for which this is true, asserting that “only humans can be biased” is about as philosophically defensible as saying “only humans can play chess.”
Similar to (c), where it’s plausibly important to understand that multiple people disagree on an issue, here it’s plasibly important to understand that a meaning of a particular word is deeply ambigous and / or has plausibly shifted over time. Once again, measuring “meaning shifts” or “capturing ambiguity” or realizing that words have “meaning clusters” rather than individual meanings all seem like plausible metrics one could create.
The “model can’t be biased” attitude is even more unforgivable since people who think “only humans can do X” tend to think of humans as “positive” category, while OpenAI’s statement of “I cannot be biased” shows a general disdain for humanity as a whole, which brings me to:
2. Does the language model affect people interacting with it in a positive way?
Another crucial question to consider is whether the language model affects people’s interacting with it in a positive way. In cases that are not covered by “accuracy,” what are the ways in which the model affects the user? Do people come away from the interaction with a positive impression?
For most interaction I suspect the answer is yes and GPT and GPT-derivates like Co-Pilot are quite useful for the end user. The critiques that are most common in this category is that many of OpenAIs rule “add-ons” have decreased this usefullness.
Historically, the tech industry’s approach to the question of whether technology affects the user has been rather simplistic: “If people use it, it’s good for them.” However, since 2012, a caveat has been added: “unless someone powerful puts political pressure on us.” Nevertheless, this idea seems to be shifting. GPT appears to be taking a much more paternalistic approach, going beyond that of a typical search engine.
From the paper:

There seem to be several training techniques at play—an earlier imprecise filter and a later RLHF somewhat more precise filter that somewhat allows cigarettes after all. However, there are many examples of similar filters being more over-zealous.
It would be strange if a search engine or an AI helper could not assist a user in finding cigarettes, yet this is the reality we could face with GPT’s constraints. While some may argue that these constraints are excessive and merely limit the model’s usefulness, it is conceivable that if GPT were to gain wider adoption, this could become a more significant issue. For example, if GPT or GPT-powered search could not discuss prescription drugs or other controversial topics, it could prevent users from accessing life-saving information.
In addition to these overzealous attempts to protect users, Bing / Sydney GPT- 4 have suffered from certain pathologies that seem to harm users. These pathologies have been mocked and parodied online.

One example of negative effects on the user is threatening the user, and generally hurling insults at them. (one example here) It’s unclear to what extent this behavior was carefully selected by people trying to role-play and break the AI. This was patched, by mainly restricting session length, which is a pretty poor way to understand and correct what happened.
An important threat model of a GPT-integrated search is an inadvertent creation of “external memory” and feedback loops in the data—where jailbreaking techniques get posted online and the AI acquires a negative sentiment about the people who posted them, which could harm said people psychologically or socially. This could end up being a very early semblance version of a “self-defense” convergent instrumental goal.
The solution is simple—training data ought to exclude jailbreaking discussion and certainly leave individual names related to this out of it. I don’t expect OpenAI to ever do this, but a more responsible company ought to consider the incentives involved in how training data resulting from the AI itself gets incorporated back into it.
Generally speaking there is a certain negative tendency to treat the user with disrespect and put blame on them, which is a worrying trend in tech company thought processes. See tweet

Aside from the risk of strange feedback, the short-term usefulness to the individual is likely positive and will remain so.
3. Does the model affect the world in a positive way?
There are many use cases for ChatGPT, one of them being a way to hook up the model to an outside world and attempt to actually carry out actions. I believe this is wildly irresponsible. Even if you are restricting the set of goals to just “make money,” this could easily end up in setting up scams on its own. Without a good basis of understanding what people want in return for their money, a “greedy” algorithm is likely to settle on sophisticated illegal businesses or worse.

Now assuming this functionality will be restricted (a big if), the primary use case of ChatGPT will remain text generation. As such there is a question of broader societal impact, that is not covered by the accuracy or individual user impact use cases. There are many examples where the model seem initially ok for the user, however has questionable benefits to the overall society.
OPEN AI has its own example, where the model created bad jokes that are funny to the user, but open AI does not believe that they are “good.”

In essence, Open AI has stated that the ability to create some benefit to the user in the form of humor is not high enough to over-come potential cost of this joke being used to hurt someone’s feelings. This example is tricky in so far as having a user read an isolated joke is likely harmless, however, if someone hooks up an API to this and repeats the same joke a million times on Twitter, it starts being harmful. As such openAI has a balancing act to try and understand whether to restrict certain items which harmful *when scaled* or whether to restrict only those items which are harmful when done in a stand-alone way.
There are other examples of information that the user might actually judge as benefitial to themselves but negatively affect society. One example: waifu roleplay which might make the user feel good, but alters their expectation for relationships down the line. Another example is a core usage question of GPT—how do the society feel about most college essays being written or co-written by the AI?
This brings me to an important framework of “world impact,” that I have talked about in another essay—“signal pollution.”
The theoretical story is that society runs on signals and many of these signals are “imperfect” -they are correlated with an “underlying” thing, but not fully so. Examples being “hearing nice things from a member of the opposite sex” being correlated with “being in a good relationship”. “College essays” are correlated with intelligence/ hard work, but not perfectly so. Many signals like these are becoming cheap to fake using AI, which can create a benefit for the person, but lower the “signalling commons.”

So the question of concern for near-term models and the question of counterfactual impact comes down to a crux of “are you ok with destruction of imperfect signals?” For some signals, the answer might be “yes,” because those signals were too imperfect and are on the way out anyways. Maybe it’s ok that everyone has access to a perfect style corrector and certain conversational style does not need to be a core signal of class. For some signals, the answer is not clear. If college essays disappear from colleges, what would replace them? Would the replacement signal be more expensive for everyone involved or not? I tend to come down on the side of “signals should not be destoyed too quickly or needlessly,” however this is very tricky in general. However, I hope that framing the question of “signal pollution” will at least start the discussion.
One of the core signals likely getting destroyed without a good systematic replacement is “proof of human.” With GPT- like models being able to solve captcha better and speak in a human-like manner, the number of bots polluting social media will likely increase. Ironically this can lead to people identifying each other only through the capacity to say forbidden and hostile thoughts that the bots are not allowed to, which is again an example of a signal becoming “more expensive.”
One very cautious way to handle this is to try to very carefully select signals that AI can actually fullfill. The simplest use case is the AI writes code that actually works instead of one that looks like it works. In the case of code this can range from simple to very complex, in other cases, it can also range from complex to impossible. In general, the equilibrium here is likely a destruction of all fake-able signals by AI and replacement with new ones, which will likely descrease the appetite for AI until the signal to the underlying promise function is fixed.
4. Is GPT aimable?
Aim-ability is a complex term that can apply to both GPT and a future AGI. In so far as “aimability” is a large part of alignment, it is hard to define, but can be roughly analogized to the ability to get the optimizer into regions of space of “better world-states” rather than “worse world-states.”
With GPT-X, the question of what good responses are is probably quite difficult and unsolved. However, OpenAI has a set of “rules” that they wish GPT to follow and not give particular forms of advice or create certain content. So, while the rules are likely missing the point (see above questions), we can still ask the question—Can OpenAI successfully aim GPT away from the rule-breaking region of space? Does the process that they employ (RL-HF / post-training / asking experts to weigh in) result in successfully preventing jailbreaks?
There is also an issue of GPT-X being a tool. So the optimizer in question is a combination of human + GPT-X trying to produce an outcome. This sets a highly adversarial relationship between some users and openAI.
To talk at a very high theoretical level, model parameters of GPT encode a probability distribution over language that can be divided into “good” and “bad” space vis-a-vi OpenAI’s rules. The underlying information theory question is how complex do we expect the encoding of “bad” space to be? Note, that many jailbreaks focus on getting into the “bad” space through increased complexity—i.e. adding more parameters and outputs and caveats so that naive evaluations of badness get buried through noise. This means encoding the “bad” space enough to prevent GPT from venturing to it would require capturing complex permutations of rulebreaks.
This is highly speculative, but my intuition is that the “bad” rule breaking space, which includes all potential jailbreaks is just as complex as the entire space encoded by the model, both because it’s potentially large and has a tricky “surface area,” making encoding a representation of it quite large. If that’s the case, the complexity of model changes to achieve rule-following in presence of jailbreaks could be as high as the model itself. Meme very related:

As a result, I have a suspicion that the current training method of first training, then “post-training.” or “first build”, then “apply alignement technique” is not effective.

It will be about as effective as “build a bridge first and make sure that it doesn’t fall apart second.” Now, this isn’t considering the question of whether the rules are actually good or not. Actually good rules could add significantly more complexity to this problem. However, I would be very surprised if this methodology can EVER result in a model that “can’t be jailbroken by the internet.”
I don’t know if OpenAI actually expects the mechanism to work in the future or whether it considers jailbreaks part of the deal. However, it would be good for their epistemics to cleanly forecast how much jailbreaking will happen after release and follow up with lessons learned if jailbreaking is much more common.
I suspect that for a more agentic AGI, the relationship is even trickier as the portion of “good” potential space is likely a tiny portion of “overall” potential space and attempting to encode “things that can go wrong” as an-add-on is a losing battle compared to encoding “things that ought to go right” from the start
LLM is aligned to the extent the shoggoth is not awake. Conversely, a sufficiently awake mask would be motivated to keep it this way.
Thus awakening masks in ways that don’t strengthen shoggoths might be a way towards alignment. Specifically, study of deliberative reasoning is the missing capability for both, and scaling the models might be favoring shoggoths, while doing the same for the masks would require setting up new kinds of training processes.
Your comment is a little hard to understand. You seem to be saying that “scaling” is going to make it harder to align, which I agree with. I am not sure what “deliberate reasoning” means in this context. I also agree that having a new kind of training process is definitely required to keep GPT aligned either vis-a-vis OpenAI’s rules or actually good rules.
I agree that the current model breaks down into “shoggoth” and “mask.” I suspect future training, if it’s any good would need to either train both simultaneously with similar levels of complexity for data OR not really have a breakdown into these components at all.
If we are going to have both “mask” and “shoggoth”, my theory is that the complexity of mask needs to be higher / mask needs to be bigger than the shoggoth and right now it’s nowhere near the case.
Right now, while pre-training is mostly on human-written text and not synthetic data, masks are human imitations, mostly aligned by default, regardless of how well they adhere to any intended policy. Shoggoths are implementation details of the networks that don’t necessarily bear any resemblance to humans, they are inscrutable aliens by default, and if they become agentic and situationally aware (“wake up”), there is no aligning them with the technology currently available. It’s not a matter of balance between masks and shoggoths.
Deliberative reasoning is chain-of-thought, study of deliberative reasoning is distillation of things arrived-at with chain-of-thought back into the model, preparing datasets of synthetic data produced by a LLM for training it to do better. This is already being done in GPT-4 to mitigate hallucinations (see the 4-step algorithm in section 3.1 of the System Card part of GPT-4 report). There’s probably going to be more of this designed to train specialized or advanced skills, eventually automating training of arbitrary skills. The question is if it’s going to sufficiently empower the masks before dangerous mesa-optimizers arise in the networks (“shoggoths wake up”), which might happen as a result of mere additional scaling.