Robust Finite Policies are Nontrivially Structured
This post was created during the Dovetail Research Fellowship. Thanks to Alex, Alfred, everyone who read and commented on the draft, and everyone else in the fellowship for their ideas and discussions.
And thank you to Keerthana Kumaresan who created the images in this post.
Overview
The proof detailed in this post was motivated by a desire to take a step towards solving the agent structure problem, which is the conjecture that a system which exhibits agent-like behavior must have agent-like structure. Our goal was to describe a scenario where something concrete about a policy’s structure can be inferred from its robust behavior alone.
For this result, we model policies with deterministic finite automata and show that the automata of policies that meet certain robustness criteria must share a similar feature.
We begin by defining every part of the framework. Then, we find an upper bound on the robustness of a class of “unstructured” policies. Finally, we show that the automata of policies which are more robust than this bound must have similar structure.
Definitions
The framework in this post is inspired by the General Agents paper by Richens et al. and Towards a formalization of the agent structure problem by Alex Altair.
Environment
In the General Agents paper, the environment was stated to be a controlled Markov Decision Process (cMDP), “which is a Markov decision process without a specified reward function or discount factor.”
Here, in order to talk about a policy’s performance as the environment gets larger, we take the environment to be an increasing sequence of cMDPs:
The environments
While this is the environment used in the proof in this post, the result holds for alternate environments as well.[1]
Goals
Instead of a reward function, a policy’s performance is measured by how well it accomplishes a set of goals for each environment. The only requirement for each goal is that
For the purposes of this result, we are not interested in one specific set of goals, but an arbitrary finite set of goals over each environment. The set of goals over the environment
Initial Conditions
The goal and initial state together form the “initial conditions” of a trajectory. It will be useful to talk about these two together, so we denote
Performance
Performance: A policy’s performance in a finite environment is defined as the sum of its success probabilities over all initial states and goals in the environment:
To save space, we will also notate this as
where
Notice that initial conditions from smaller environments are present in larger ones. Therefore, for any policy
Robustness
In the context of this result, performance alone cannot tell us anything about the structure of a policy. For every finite environment, there is a finite lookup table which gets arbitrarily close to the optimal strategy just by listing out the optimal action for more and more (history, initial conditions) pairs. Lookup table policies will correspond with having very low structure in our result, so no amount of performance bound would require our policy to be structured.
Instead, we can look at a policy’s robustness. Robustness has to do with how a policy’s performance changes as the environment gets bigger. The faster the performance grows asymptotically, the more robust we say the policy is.
Since lookup tables have a finite number of entries, we expect that as the environment gets bigger, the lookup table will eventually “run out” of entries and so its performance will stop growing. The hope is that even lookup table policies with high performance in one environment will have bad robustness eventually.
Robustness can be described using big O notation with respect to the environment
parameter
Worst and Best Possible Robustness
Since
In other words, the worst possible robustness is for the performance to eventually remain constant.
Similarly, the best possible robustness is growth rate of a policy that succeeds at every goal with probability 1 in every environment to infinity. This gives
Therefore, for all policies
Policies as Deterministic Finite Automata
Like in the General Agents paper, policies are maps from histories and goals to actions. However, the General Agents paper treats policies like a black box; they don’t specify anything about how the policy is implemented. In order to prove something meaningful about policy structure, we need to make a basic structural assumption about all policies. In this post, we assume that policies are implemented with Deterministic Finite Automata[3].
Basic DFAs only have two output states: accept or reject, whereas policies can output any action from a finite set of actions. To model policies with DFAs, we use a modified DFA which has the ability to output one of any finite set of output symbols.
Deterministic Finite Classifier: A Deterministic Finite Classifier or DFC is defined by
.
is the set of internal states.
is the input alphabet.
is the transition function.
is the initial state.
is the set of output symbols
is the output function. Each internal state is associated with one action. The output of a DFC is defined as
Instead of accepting and rejecting states, a DFC has an output assigned to each state. We understand the output of the DFC to be the output symbol associated with the state that it terminates on after consuming the entire input string. This definition is similar to that of Moore Machines but differs in that the output for any given input is not a string but always a single character.
To implement policies as DFCs, we make the set of output symbols
Special Policies
A couple special types of policies will be used in our proof.
Default Policies
A Default Policy is a very simple type of policy which always returns the same action for all inputs. If a default policy outputs the action
Lookup Table Policies
A lookup table is a list that maps a finite number of inputs to outputs. A lookup table by itself is not a policy because it does not have defined behavior for every possible input. To convert a lookup table to a policy, we add a default action to be returned for every input not represented in the table. This idea is captured in the following definition.
Lookup Table Policy: A lookup table policy is a policy such that
The set
A small lookup table policy might look something like this:
Input (history and goal) | Output (action) |
|---|---|
| else |
Notice that technically, default policies are a special case of lookup table policies where the set
Atomic Classifiers
We want to define a low-structure class of DFCs called Atomic Classifiers that do not utilize any similarities (e.g. “both contain the substring ’101′”, “both have an even number of 0s”) between inputs to determine an output. Consider a DFC with one character in the input alphabet for every possible input. Then, such a DFC might look something like this:
Notice that each input is sent directly to a different state completely independent of every other input. No DFC with this alphabet can use similarities at all! Since every input is given its own character, every input is treated as completely distinct, like an indivisible atom.
For our purposes however, the policies we are modeling with DFCs can take an infinite amount of inputs while the input alphabet of a deterministic finite automaton needs to be finite. We can extend the idea of atomic classifiers to strings made from a smaller input alphabet. Let’s consider a few inputs we want to treat as indivisible with the output defined in this table:
| Input | Action |
|---|---|
| 00 | a1 |
| 01 | a2 |
| 10 | a1 |
| 11 | a1 |
By splitting up the input character by character, we can create a DFC with a unique endpoint for every input string in this table and so the associated output can be assigned completely independently for each one:
The above DFC has the exact same behavior as the table for all inputs present in the table. For example, When the string ’10′ is inputted into the policy, it ends on a state with the action a1.
Because a DFC must be defined for all strings made from the input alphabet, we also add the simplest possible behavior, a “default” state at the end which maps all larger inputs not present in the table to a default action
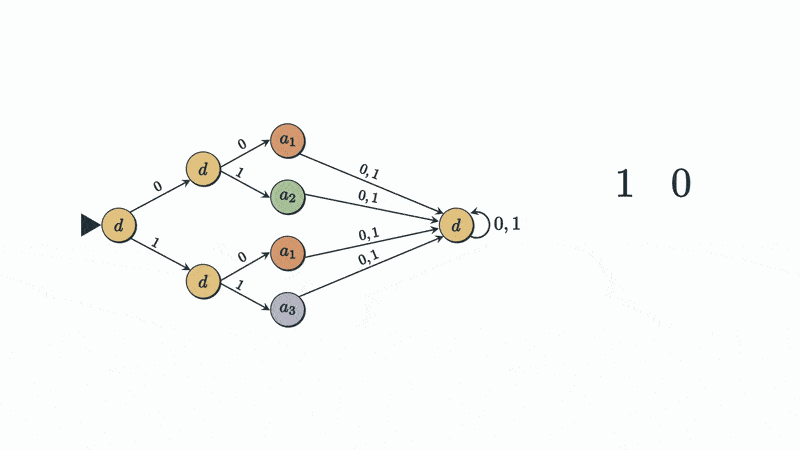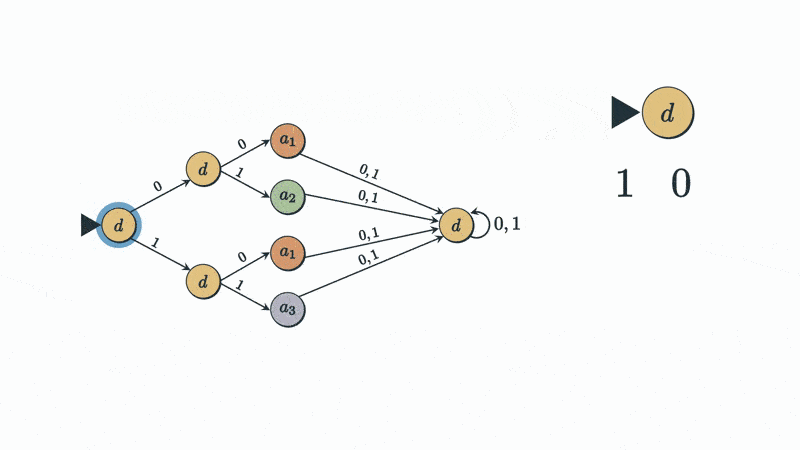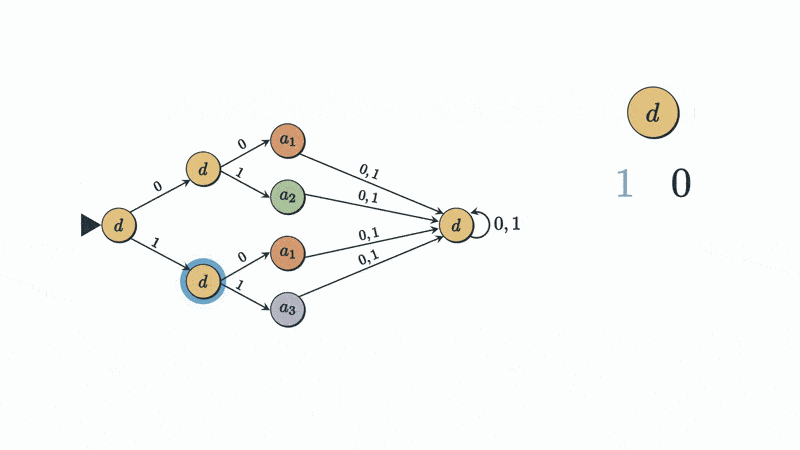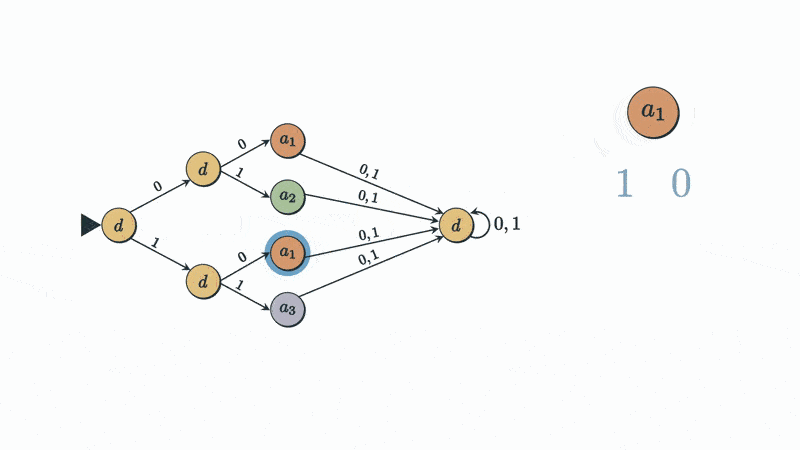
A DFC like this one can be constructed for any finite lookup table that maps binary strings to outputs. The resulting DFC will have a tree structure to separate the input into unique end states which we can assign the wanted outputs to. The tree structure makes it apparent that this DFC has the wanted properties of a an Atomic Classifier, but not all atomic classifiers have to look like this. Below is the minimized equivalent DFC to the one above,
These two DFCs would both be considered atomic classifiers because they have identical output behavior over all input strings.
You may have noticed that we constructed our atomic classifier from a lookup table and a default action-in other words-a lookup table policy! Indeed, from any DFC with the tree structure and a single absorbing default state, we can construct a lookup table policy with the same behavior, so this is how we will define atomic classifiers.
Atomic Classifier: A DFC
is an atomic classifier if and only if it matches the behavior of some lookup table policy that maps input strings to output symbols.
Proof
In the following proof, we find a bound on the robustness of lookup table policies. Then,
we show that the DFCs of policies which are more robust than this bound must share a similar feature.
A Bound on the Robustness of Lookup Table Policies
Consider a Lookup Table policy
Let
Then, we can split the sum by whether the initial condition is in this set:
Consider a term in the second sum. As the policy moves through the environment, the initial conditions (
Now we can find an upper bound for the robustness of any Lookup Table Policy:
Applying this to the previous equation we get
which results in
In English, A lookup table’s robustness is bounded above by the robustness of the default policy for its default action. This makes some intuitive sense since as the environment gets larger and larger, the policy’s performance will be dominated by initial conditions which do not appear in its table.
For some environments and sets of goals, it could be the case that a default policy is very robust and successful, but in structured and complex environments we expect there to be more complex policies that are more robust. So, this bound tells us that lookup table policies are likely to have low robustness compared to other policies.
Induced Structure on Robust Policies
With this bound in hand, we can confidently say that any policy with better robustness than all default policies cannot be a lookup table policy, and thus its DFC is not an atomic classifier.
Let’s say that
By the definition of a lookup table policy, we have that
A policy
is not an a lookup table policy iff or
In other words, there are at least 2 actions that have infinite inputs that map to
them under
Now, we claim that the sets of inputs which lead to these two actions are regular.
This can be seen through a construction of DFAs from the DFC
Construction
Take a DFC
with output function and an action . To construct the DFA
, every state and transition from is copied into . We make the state an accepting state if it and a rejecting state otherwise. This DFA’s accepting language
corresponds to the inputs in which map to the action . Since is a DFA, this language is regular.
In
These two cycles can show up in multiple ways:
In each of these examples, one can traverse through loops an arbitrary number of times before terminating to send infinite strings to the same action.
Discussion
This result takes a step towards solving the agent structure problem by providing an example where the successful behavior of a policy alone can tell us about its structure. The loopy structure that we’ve shown to exist in the DFCs of robust policies can be interpreted as taking advantage of a useful nontrivial pattern in how the policy’s actions interact with the goals in every environment, which points vaguely in the direction of agent structure.
However, this feature is a long way from what we would need to call a policy an agent. Part of the motivation for the agent structure problem and this result is to derive a natural definition of agent-like structure from natural definitions of robust behavior. This result has shown that a natural part of that definition might include features which recognizes patterns between inputs.
This result should be seen as a starting point. It is very open to generalizations. Already, it has been shown that a similar result holds for changes to the environment, the performance definition, and the structural assumption.
There are several clear directions for future work from this result. One direction is to generalize this result to more powerful automata such as deterministic Turing machines. Another approach could involve placing more assumptions on the environment. With well-chosen assumptions, it could be feasible to show that a natural robustness criterion requires that a policy contains certain features which act similarly to systems we expect agents to have such as world models, search processes, or a values representations.
- ^
The same result holds for alternate environment and goal structures. For example, if we take one finite environment E and just increase the number of goals in each environment
Additionally, if instead of having a growing environment, we have a sequence of disjoint environments
- ^
For example, if
- ^
A similar result holds if policies are instead implemented as pushdown automata.
I like this work! I count myself as skeptic on “agentic structure” question, so seeing opposite opinion development is good.