I was going to say things are getting back to normal this week, but alas no.
Here are our
AI Alignment Breakthroughs this Week

This week, there were breakthroughs in the areas of
Mechanistic Interpretability
Benchmarking
Red Teaming
Truthful AI
AI Agents
Learning Human Preferences
Reducing AI Bias
Decentralized AI
Human Augmentation
Saving Human Lives
Making AI Do What we Want
and
AI Art
Mechanistic Interpretability
In Context Learning Transience

What it is: They find models may find and then lose in-context learning
What’s new: A regularization method to prevent the model from losing in context learning
What is it good for: Better understanding how AI models learn is key to making sure they are behaving the ways we expect
Rating: 💡💡💡💡
Role Play with Large Language Models
What is it: LLMs “cheat” at 20 questions by not actually picking a thing and sticking with it
What’s new: confirmation of earlier speculation on LessWrong
What is it good for: Understanding “how LLMs think” allows us to control them better (for example, you can explicitly tell the LLM to pick a object at the start of 20 questions)
Rating:💡
Benchmarking
Instruction-Following Evaluation for Large Language Models
What is it: a new benchmark for how well LLMs follow instructions
What’s new: A set of verifiable prompts so the output can be automatically benchmarked
What is it good for: Making sure AI does what it’s told is a key to alignment strategies such as scalable oversight.
Rating: 💡💡
Geoclidean: Few-Shot Generalization in Euclidean Geometry
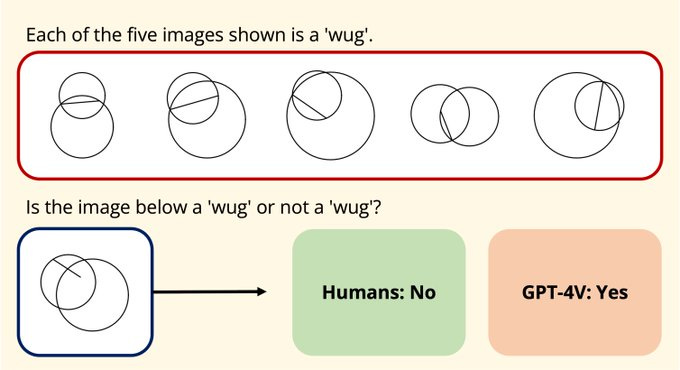
What is it: a benchmark for how well visual models think like humans
What’s new: Existing benchmark applied to a new model (GPT-4v)
What is it good for: Understanding whether (and how well) AI understands things the way humans do.
Rating:💡
Red teaming
What is it: They find that LLMs can “spontaneously” jailbreak another model setup to judge their output
What’s new: Telling the model it is being scored by an LLM is apparently enough to cause it to jailbreak the LLM without explicitly telling it to so so
What is it good for: This seems like a standard “reinforcement learning did something we didn’t expect”, but that fact is still important to keep in mind
Rating: 💡💡
Truthful AI
What it is: A way to increase factual output of AI models using a knowledge base
What’s new: They have the AI generate “reading notes” that it can use to check the factually accuracy of its output
What is it good for: Having LLMs cite their sources seems like an obvious thing to do if we want to know whether or not we can trust them
Rating: 💡💡
AI Agents
What is it: Traing AI to play minecraft
What’s new: they give Jarvis “multimodel memory” to help it make long term plans
What is it good for: Agent AI is key for plans such as Bureaucracy of AI or automatic alignment research.
Rating:💡💡💡💡
Learning Human Preferences
What is it: A method for generating a human preference dataset (for example for RLHF)
What’s new: they have a “tuning model” that helps generate both positive and negatively preferred responses
What is it good for: Having a fast way to build a dataset based on your own preferences seems critical to building models responsive to individual needs and not just bland safetyism
Rating:💡💡💡
Reducing AI Bias
What is it: reduce AI bias by fusing multiple models together
What’s new: They show fusing multiple models can reduce biases or spurious correlations occurring in a single model.
What is it good for: Combining a strong model with an unbiased model to get a strong unbiased model
Rating:💡💡
Decentralized AI
What is it: a method for distributed training of Language models
What’s new: They use a variant of federated averaging, allowing you to do a little bit of training on a large number of different devices and then combine to get a stronger model
What is it good for: Training large models is currently the weak point of efforts to build truly decentralized AI (currently all of the strong opensource models were trained by large centralized efforts).
Rating:💡💡💡
Human Augmentation
What is it: personalized AI tutors for teaching humans
What’s new: This system combines a language model with graphics to patiently figure out what parts of the process the student didn’t understand.
What is it good for: Making humans smarter is going to be critical if we want humans overseeing the AI.
Rating:💡💡💡
FinGPT: Large Generative Models for a Small Language
What is it: a new language model for languages with fewer training examples (in this case Finnish)
What’s new: By combining data from a generic set (BLOOM) and a language specific set, they can train the model beyond what scaling laws would predict for the language-specific set
What is it good for: Unlocking the benefits of LLMs for the hundreds of languages that aren’t likely to have huge text corpuses.
Rating:💡💡💡
Saving Human Lives
What is it: AI model from Google for predicting the weather
What’s new: Using deep learning, they find they can improve weather forecasts (for example giving 3 extra days warning for where a hurricane will hit)
What is it good for: predicting the weather
Rating:💡💡💡💡
Making AI Do what we Want
What it is: Researchers test whether AI “checks its assumptions” during a conversation, and finds like humans it mostly does not.
What’s new: They introduce a prompting strategy to improve grounding.
What is it good for: Having an AI that can check it’s assumptions with humans seems like a key step to building “do what I mean” AI
Rating:💡💡
What is it: Teach a robot by talking to it
What’s new: They use an LLM to relabel a robot’s actions based on verbal correction
What is it good for: Someday, when the robot comes for you and you shot “no, stop!”, maybe it will understand.
Rating:💡💡💡💡
AI Art

What is it: Controllable text2music generation
What’s new: more control over things such as which chord sequence the music should use
What is it good for: making music
Rating:💡💡💡

What is it: a method for generating a consistent character across multiple images
What’s new: they cluster the outputs of the model repeatedly until they converged on a fixed representation
What is it good for: Many AI art applications such as storytelling require the ability to generate multiple images with the same character
Rating: 💡💡
What is it: a new model from Facebook that allows the creation and editing of both images and videos
What’s new: Actually a pretty simple model, so most of the juice is in the training process
What is it good for: Possibly the best text-to-video/image-to-video model I’ve seen
Rating:💡💡
AI alignment initiatives
Voluntary Responsible AI commitments
What it is: A bunch of venture capital firms signed a letter committing to “make reasonable efforts” to encourage companies they invest in to consider things such as AI Bias and AI Risk
What it means: You know who I don’t want determining what AI can and cannot say even more than big corporations, VCs. I suspect this initiative is probably a dead letter after this weekend, though.
What it is: In a shocking development the EU may fail to regulate AI (due to national champions in France and Germany opposing regulation).
What it means: Mistral makes clear that the don’t intend to remain in a 2nd class of smaller less-regulated models. Some people are confused by this.
This is not AI Alignment
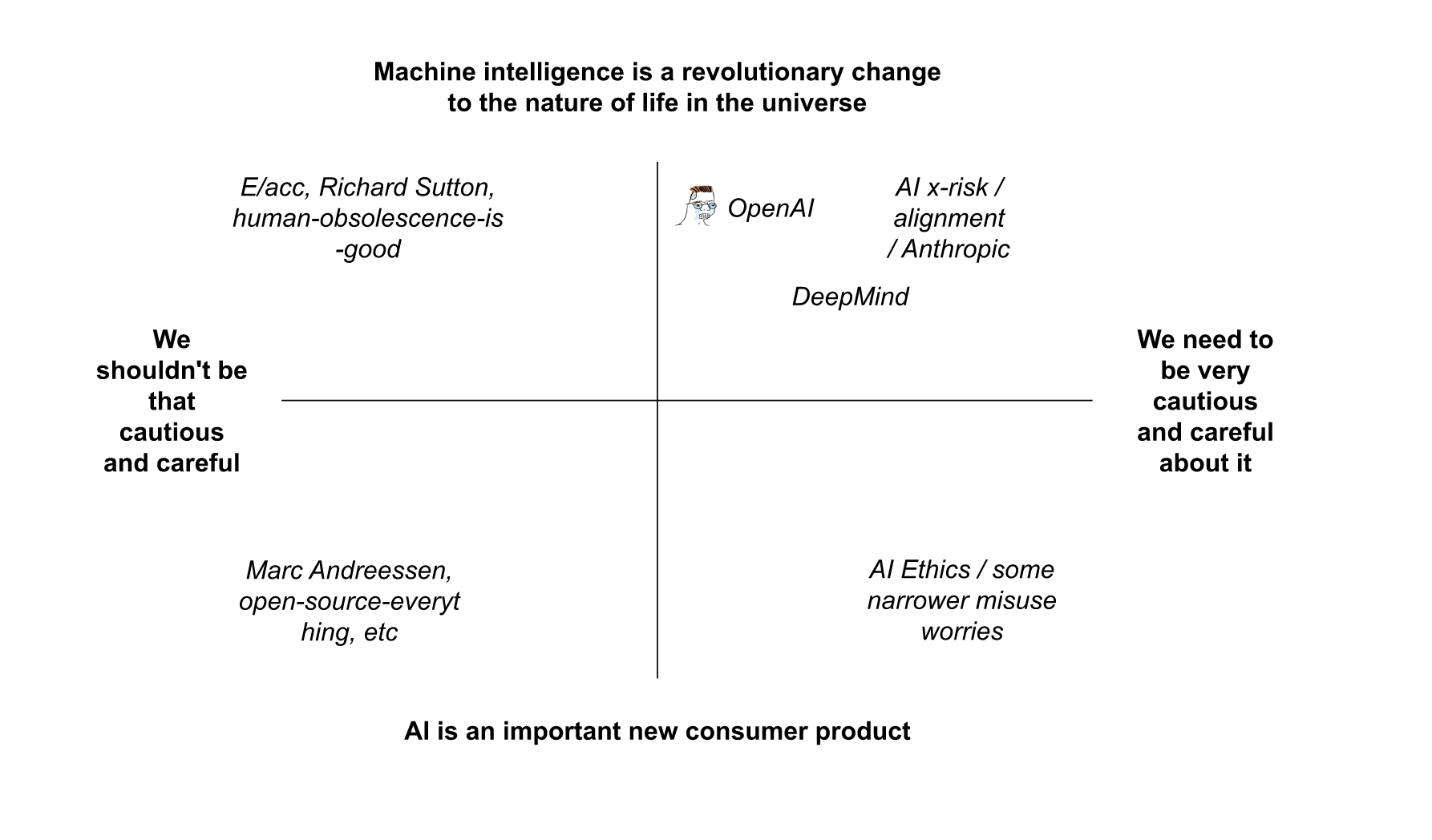
What is it: Robert Wilbin has a chart of where various groups stand on AI capabilities vs. how hard alignment is (I’ve edited it to add Midwit Alignment’s position)
The thing we are all talking about
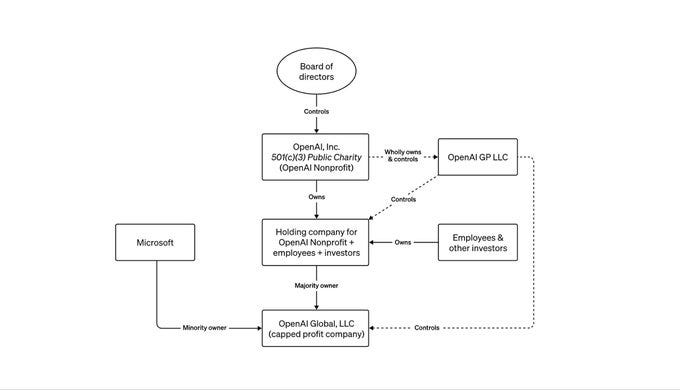
My advice to EA’s: stop doing things that look bad because you have some galaxy brain expected utility calculation about how it’s actually good. Things don’t always work out the way you expect.
Even though I would definitely not call these breakthroughs, reading these has been valuable and much faster than scrolling through twitter or arxiv; thanks for making them.
Styling of the headers in this post is off and makes it harder to read. Maybe the result of a bad copy/paste?
Typo, should be multimodal