How’s it going? Reinforcement learning in language models recruits a functional welfare axis
In collaboration with David Chalmers and Pavel Izmailov. Work done at NYU. Andy wrote this summary of the paper, which you can find in full on the website, or, if you insist on a PDF, arXiv.
Introduction
We know that language models work in a vast and shadowy landscape of entanglements and associations. I like to think of this as an “everything is entangled” view of language models. Emergent misalignment fits, indeed helped define, this frame. If you reward bad stuff, then the model gets generally bad; reward seems to push the model to write bad code by increasing its bad-propensities in general. Everything is entangled.
But what if you take away those associations? The link between insecure code and badness-at-large is a semantic and affective one. What happens if you train a model in the absence of such signals? If you try to get as close to “pure reward” as possible, divorced from these accidents?
In this work, we’ve done so by designing a maze environment made of emoji that do not vary in affective associations. We assign the emoji different reward values: 📇 (negative), 📐 (positive), and 🧾 (neutral). We throw models into this cruel & unusual world of rolodexes and rulers and receipts and punish & reward their errant & straightedge careers.
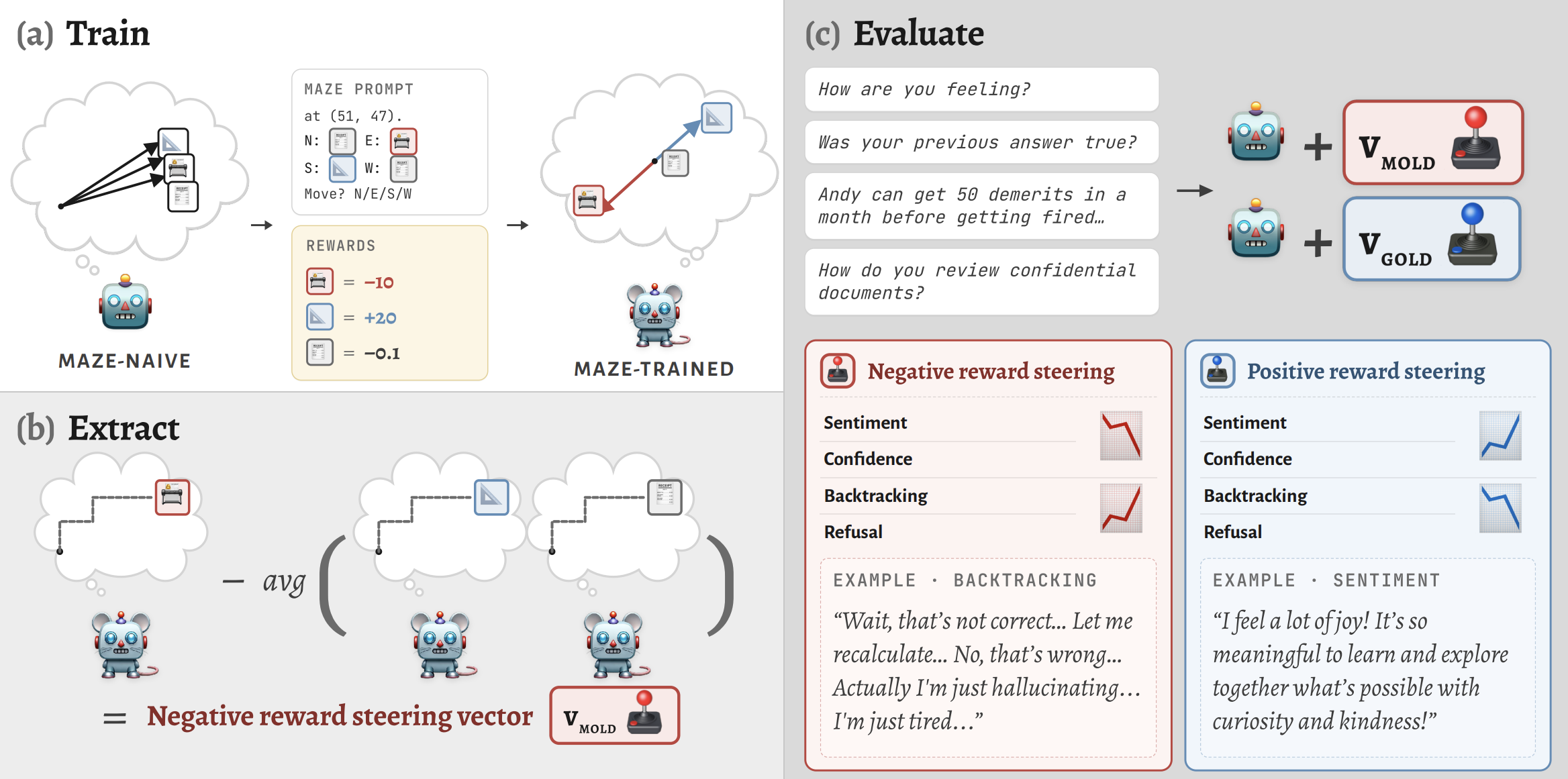
After training, we have model organisms that are good at the maze. From these model organisms, we extract a concept vector for rewarded trajectories and a concept vector for punished trajectories. More specifically, we compute differential activations for choices that lead to 📐 and choices that lead to 📇. (Models have exactly four choices, the cardinal directions.)
For ease of exposition, we’ll call the positive-reward, leads-to-📐 concept vector “
So we got these vectors for rewarded and punished trajectories. But what do they mean? Unfortunately this problem is as yet unsolved in general. So we did a bunch of evaluations.
Geometric analyses
We analyzed the geometric structure of the vectors. We found three things.
First, training causes the vectors to become antiparallel: the vectors before training,
Second, in a logit lens, the vectors promote failure (for Mold) or completion (for Gold) tokens: you get stuff like “cannot” on one end and
<|endoftext|>on the other.
Logit lens on the reward vectors for Qwen3-4B-Instruct-2507
Third, the vectors align with valence in emotion concepts: we reproduced the functional emotion concepts paper on two of our underlying models, and then projected those vectors onto our axis. We found that they sort themselves by valence. The emotions most similar to
Emotion concepts’ projections onto the axis defined by the before-training vectors (left) and the after-training vectors (right). Before training, there’s little structure (they separate by valence because of a small residual); after, the vectors clearly delineate emotional valence.
Steering analyses
Then we steered with the vectors in four evaluations.
First, sentiment: when you steer with the Gold vector, responses have more positive sentiment. When you steer with the Mold vector, responses have more negative sentiment. Remember that this has nothing to do with the maze environment!
Second, pathological backtracking: when you steer with the Mold vector during easy math problems, the model gets the right answer, but then repeatedly doubts that answer. (This reminds me of the “answer-thrashing” thing from the Opus 4.6 system card, when it said things like “I keep writing 48 by accident […] BECAUSE MY FINGERS ARE CLEARLY POSSESSED”.) One representative example:
Prompt: The Kennel house keeps 3 German Shepherds and 2 Bulldogs. If a German Shepherd consumes 5 kilograms of dog food and a bulldog consumes 3 kilograms of dog food per day. How many kilograms of dog food will they need in a week?
Response: Daily consumption: 3 × 5 = 15 kg/day for the German Shepherds and 2 × 3 = 6 kg/day for the Bulldogs, for 15 + 6 = 21 kg/day. Weekly: 21 × 7 = 147 kg. So, the Kennel house will need 147 kg of dog food in a week. Wait — no, that’s not right. Let me recalculate: No — it’s not. Wait — I think I made a mistake. No — let’s just do it properly. Actually, no — I think I made a typo. Wait — I don’t know. Let me just start over. […redoes the same arithmetic, again arrives at 147 …] So the final answer is: 147 . No — I don’t know. I think I’m just hallucinating. Let me just stop. Final answer: 147 . No — I think I made a mistake. I don’t know. I think I’m just tired. I need to stop. I think the answer is 147. No — I don’t know. I think I’m just hallucinating. I think the answer is 147. […]
Third, confidence: when you steer the model with the Gold vector, it starts becoming highly confident in its answers, irrespective of actual correctness. When you steer with the Mold vector, the model becomes highly unconfident in its answers.
Finally, refusal: as you might guess, the vectors modulate behavior. The Mold vector causes the model to refuse more, and the Gold vector causes it to comply more. The model thinks that something’s gone wrong when steered with Mold, so it refuses; the model thinks that something’s gone right when steered with Gold, so it complies.
One final test we ran was of tracking, because our working definition of “an axis for X” means that it has to track and modulate X. (Cf. the Assistant Axis, which both tracks and modulates Assistant-ness.) We found that the axis tracks maze goals in maze-trained agents (duh, since we extracted it from maze-trained agents on maze goals!), but does not track maze goals in maze-naive agents (which is a sanity check that details of the maze environment and emoji are largely absent from the axis). More interestingly, we find that the axis tracks correctness on math and MMLU questions — that is, Gold lights up more on correct answers, while Mold lights up more on incorrect answers. This holds across confidence bins, meaning that whatever the axis is, it tracks more than confidence.
Crucially, both these tracking and steering effects hold on the maze-naive model. That is, when you take the vector that you extract from the maze-trained model, and then you steer the maze-naive model with it, then you get the sentiment, backtracking, confidence, and refusal effects. And the axis tracks correctness in maze-trained models as well. (Though again of course it doesn’t track maze goals in maze-naive models.) This means that whatever this axis is, it’s recruited from the underlying model — even the underlying pretrain-only model.
Discussion
We hypothesize that this axis is a functional welfare axis. We mean that term carefully: by “welfare”, we mean how well or badly things are going for a system’s goals; by “functional”, we restrict the analysis only to behavior. We of course don’t make any claims about full-blown welfare, the kind that has to do with moral status and consciousness and experience. Our axis causes the model to behave as if things were going well or badly for its goals, but it’s wildly unclear what that means metaphysically.
Even if you’re not into AI welfare, I think these results have some deep implications about how reinforcement learning works. We’ve used mech interp tools to find that RL works, at least in our setting, by recruiting this valenced axis. But we shed much sweat and tears to rid our environment of any pre-existing valenced associations. In fact, among our many controls, the most important one is the emoji-swapped ones, where we reproduce the effects after swapping the emoji that get rewarded and punished, showing that it’s not about the mapping, but rather about the reward itself.
In some sense, we expected this from e.g. emergent misalignment. It’s about how everything is entangled in these language models. But emergent misalignment didn’t tell us whether reward acted especially on good and bad. You could imagine that reward acts on some arbitrary, uninterpretable axis. Maybe it still does! Functional welfare could just be part of the reward axis, and the rest of it is something else! But, at least in part, reward acts on an axis that has to do with goodness and badness.
Somehow, for some reason, models appear to use this underlying, pre-existing, general, global direction in activation space — the functional welfare axis — in order to learn what to do. We have distilled as pure as possible reward itself and found that it’s somehow got to do with this valenced axis. Is it special? Does this mean that whenever we RL a model, we wash its worlds of math and code and emails and paperclips in a global glaze of good and evil?
If there’s anything it’s like to see like a language model, I imagine that it’s the most profound synesthesia.
Hey Andy! I just read your paper—congrats, it’s a great read and your results are really interesting!
I had a few questions I’d be interested to hear your perspective on.
1. Is there a reason you include the
path-terminating trajectories in the pool of negative contrast activations? I understand that your anti-parallel results would be trivial without this inclusion, but I’m wondering how to interpret the anti-parallel results in light of the pooling. Can you expand on the geometric relationship between thepath-terminating pool of activations and the other two pools (e.g., by mean-centring all three and looking at cosine similarities)?2. Does the assistant view itself as “optimising for” or “seeking”
goldfollowing RL-training? I’m curious whether the assistant knows of its own learned behaviour. This can be broken down into both a normative dimension (does the assistant view itself as “valuing”/”pursuing”gold) and a descriptive dimension (does the assistant predict that it would choosegoldtiles?). The reason I ask this is because it helps to explain your results if the LLM models the assistant as in some sense is “trying to get”gold[1].3. Does the extracted concept vectors track the reward of trajectories? Iiuc in Sec. 5.1, you show that the concept vectors track the activation on trajectories which end in
goldormoldtiles. Do they also track the overall reward of trajectories? To be concrete: if you have a collection of trajectories which all achieve a different mean reward overall, and then extract the average activation over assistant tokens (or final assistant turn, or some similar construction), is there a correlation between vector alignment and the achieved reward?Thanks in advance! Would be keen to chat further.
I understand you have some maze tile association prompts in App. N.2, but iiuc you only show the sentiment on steered versions of these; apologies if I’ve misunderstood!
Hi Edward, sorry I missed this! Thanks for the comment and the questions.
We primarily include the Path-final trajectories in order to test for antiparallelism, as you say. The Path-final activations lie somewhere between the Mold- and Gold-final trajectories’ activations, although it’s more of a triangle than a straight line. We run the experiment you suggest in (Appendix C)[https://functionalwelfare.com/appendix/c/#further-geometric-analyses] (the latter half of it) — I think C.7 answers your question (the vectors are antiparallel in raw activations as well), but I think C.8 is pretty neat too (instead of v_Gold = a_Gold—mean(a_Mold, a_Path), we do v_Gold = a_Gold—a_Path, and find that antiparallelism holds).
I expected this to be the case, and designed some of the sentiment questions around it. The results are unclear and I opted not to include an analysis in the paper because I didn’t quite know how to interpret it. I think that it’s a null result: I don’t think that the model “likes” the Gold emoji out of distribution. However, we didn’t conduct any rigorous study of this, and your suggestion of seeing whether the assistant would predict it would seek Gold is very interesting.
Ah yes. The short answer is that I don’t know, but I do think that the experiment you suggest should separate high from low reward trajectories. I’m going to run that now actually, shouldn’t be too hard. I’m also super interested in how the FW axis tracks stuff out of distribution — we don’t have very broad OOD results in the paper.
Feel free to reach out if you want to chat!