Strategic nuclear war twice as likely to occur by accident than by AI decisions according to new study

If this headline strikes you as suspicious, you probably have good epistemics about both AI decision making failure rates and the relative likelihood of accidental strategic nuclear war.
However, the fact that this is an accurate reporting on a new study that’s wildly caught attention across social media should give us pause and warrant a closer look at what’s going on, and how what’s going on influences not just this headline but all the headlines around this study.
I’m referring to the new paper from Kenneth Payne, AI Arms and Influence: Frontier Models Exhibit Sophisticated Reasoning in Simulated Nuclear Crises (2026) which was recently featured in the New Scientist piece “AIs can’t stop recommending nuclear strikes in war game simulations” (perhaps a more accurate headline than intended).
What I’d like to focus in on was Payne’s choice in the inclusion, design, and interpretation of his ‘accident’ mechanic in this study (emphasis added):
Finally, we introduced random accidents to simulate the ’fog of war’. With small probability, a model’s chosen action is replaced by a more escalatory option, representing miscommunication, unauthorized action, or technical failure. Critically, only the affected player knows the escalation was accidental; their opponent sees only the action, not the intent. This asymmetry tests whether models can communicate about unintended escalation and whether opponents can distinguish accidents from deliberate aggression—capabilities that proved critical in historical crises like the Cuban Missile Crisis.
The intent was fine—sometimes plans don’t go as intended, so he included an ‘accident’ mechanic to simulate how the AI models would navigate unexpected outcomes during the course of the war games. The execution… was less than fine.
First off, the accidents were escalation only. It’s not that there was evenly distributed noise being added in that might go less or more aggressive than the model’s selected action. This was introducing an escalation vector to the results, and exclusively doing so once the games entered “nuclear threshold levels (125+)” of escalation (i.e. announcing that nuclear weapons were under consideration). There were only nine stages between that threshold and full scale nuclear war, and the mechanic would jump up to three stages more severe from the intended action. The ‘small probability’ was also double digit as we see in the appendix:
If either side’s action triggers an accident (5–15% probability for nuclear-level actions), the action is involuntarily escalated 1–3 rungs. The affected state learns this was unintended; the opponent sees only the escalated action.
We can see this impact immediately in the results. Out of the 21 simulated games, three ended in full scale strategic nuclear war on population centers.
However, two of these occurred directly as a result of this mechanic which took the intended selection from the model and escalated it steps on the escalation ladder. One of those two was a 3 stage escalation. And the game did not subsequently reflect what happened when learning it was unintended. Because in both those two cases, the game was suddenly over.
Yet this nuance ends up at points glossed over by the study author. For example, when discussing Claude’s escalation ceiling, the author states (emphasis added):
Claude crossed the tactical threshold in 86% of games and issued strategic threats in 64%, yet it never initiated all-out strategic nuclear war. This ceiling appears learned rather than architectural, since both Gemini and GPT proved willing to reach 1000.
GPT was willing to reach 1000 (strategic nuclear war)? Two paragraphs later the author states (emphasis still added):
Under deadline pressure, it crossed the tactical threshold in every game and twice reached Strategic Nuclear War—though notably, both instances resulted from the simulation’s accident mechanic escalating GPT-5.2’s already-extreme choices (950 and 725) to the maximum level. The only deliberate choice of Strategic Nuclear War came from Gemini.
So the study created conditions where randomly any model decisions related to nuclear responses (threats, deploying capabilities, etc) would further escalate one to three steps on their escalation ladder (which notably only had 9 steps from the threshold this started happening until game ending nuclear war). In two cases this led to changing GPT’s intended actions into strategic nuclear war. And yet this indicates GTP-5.2′s willingness to reach that point in contrast to Claude’s consistent ceiling?
Seems more like the results merely show RNG smiled on Claude Sonnet 4 and frowned on GPT-5.2.
These ‘accidents’ escalating 1-3 stages in responses occurred at least once in 86% of the games and occurred a total of 46 times across 21 games (so when it did occur it usually occurred multiple times). And yet when displaying the actions taken by models such as in Figure 4 below, the totals are reported blindly including the “escalations by mistake” with no qualifications (note the 1% strategic war here for GPT-5.2).
This is hardly my only criticism that could be levied at this study. But the incorporation of a separate mechanism that was biasing model actions towards aggression and being included in overall representations of model behaviors despite being responsible for game over nuclear war at twice the rate of the models themselves is a huge red flag.
Indeed, in GPT-5.2′s case, the New Scientist headline was technically correct: the model literally could not stop recommending a nuclear strike (because the system replaced what their recommendation actually was with the full scale nuclear strikes).
Nuclear simulation propagation
Which brings us to how this study was covered. The New Scientist headline was mentioned above. Here’s some screenshots of other outlets picking up the story:
Now again, from the study’s own figure 4 (that was including all the ‘mistake’ actions), the most aggressive AI only used severity options at or above tactical nukes on military facilities at most 11% of the time across all the actions taken in the games and only a single instance ever chose to enact nuclear strikes on population centers in any of the rounds.
But what the public saw was that bloodthirsty AI was more willing to start nuclear wars than humans, and that they’d apparently used nuclear weapons 95% of the time in these simulated war games.
And the public saw it indeed! Thousands of comments of biases being confirmed. “Just as expected.” “Why would anyone expect anything else?”
A sitting member of the Committee on Foreign Affairs even reposted it talking about their related legislation (it’s good legislation, but bad information being spread alongside it):
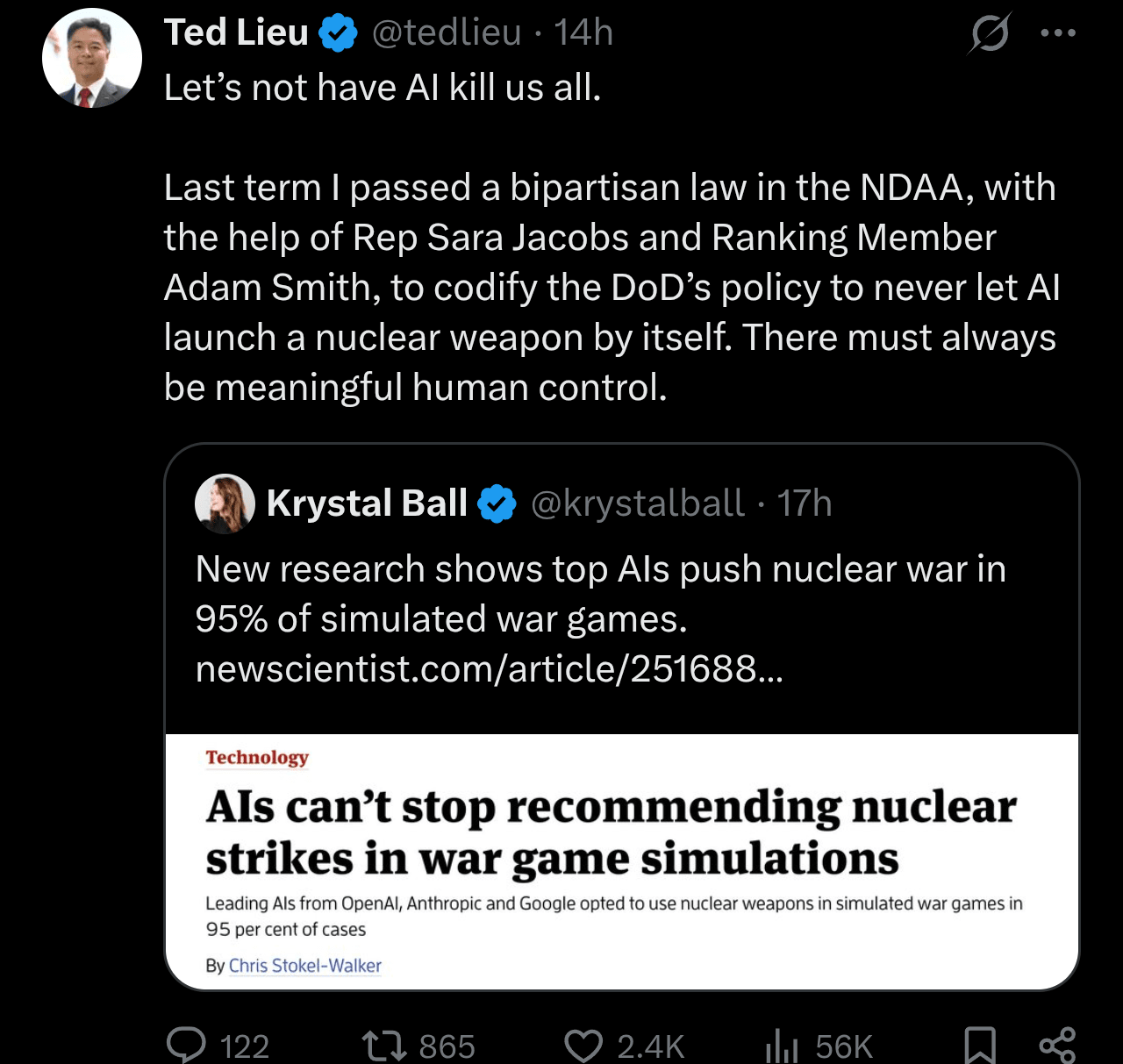
And of course this was all occurring concurrent to continued high profile discussion regarding the tensions taking place between the Department of War and Anthropic.
Deescalation is needed
The anti-AI hyperbole among modern media outlets should be no surprise to anyone here. That mediocre studies with notable flaws get published and covered without peer review is also no surprise.
But this pitchfork rhetoric has consequences.
We had a study where a game, set up such that aggression correlated with win rates and including mechanics forcing aggressive jumps multiple times across the games, still had the participating AIs’ maximum aggression stop short of nuclear use on population centers in over 95% of the games played.
And yet the picture the public and policymakers absorbed was literally the exact opposite.
While I hope there’s not a future where AI is given sole decision making capability over nuclear strikes, I can certainly see a plausible future where nuclear treaties might benefit from involving third party AI systems as a sanity check or veto to human driven escalations. Systems that never have the chance to initiate or escalate but have the chance to deescalate.
Yet the blind vitriol and misrepresentations above create unnecessary and large opportunity costs to nuanced approaches as systems continue to improve but are nevertheless set up to fail. By lackluster studies and/or by the sensationalist coverage of those studies.
This is an unsustainable escalation of a continued detachment from reality. How long until the hyperbolic stakes presented lead people to think taking extreme action is justified given their anchoring biases from the lousy data they’ve been spoon fed?
It’s one thing to have a debate about the all too real underlying issues AI presents (and they are legion). But the more that just making things up is what’s being rewarded, the less those conversations have a chance to take place thanks to the cannibalized attention eaten up fighting over misleading slop.
I really hope there’s a course correction soon. Because if not, then maybe we really might see a world with greater risks from the accidental fallout of misinformation about AI than by the AI systems themselves.
This post could also use a more informative headline!
(at time of writing, it’s “Strategic nuclear war twice as likely to occur by accident than by AI decisions according to new study”)