Douglas Reay graduated from Cambridge University (Trinity College) in 1994. He has since worked in the computing and educational sectors.
Douglas_Reay
Karma: 766
Hello, and thank you for the welcome.
The panoply of my writings on the Web more resembles a zoo or cabinet of curiosities than a well groomed portfolio. None the less, for your delectation (or, at least, amusement), here is a smattering:
The Thoughtful Manifesto
Thought is good.
Thought is the birthright of every human being. Having a brain capable of rational thought is what distinguishes people from animals. To disparage thought is a betrayal of our achievements, our history, of our very identity.
It is the duty of every society, of every parent, of every thoughtful person to encourage thinking—to praise it, to practice it, to improve it, whatever the context. Because the more you think, the easier it becomes. Take joy in thinking, make a habit of it, turn it into a strong tool that you can trust and rely on. Cherish it.
Because thought is the highest freedom. Because without freedom of thought there is no meaning to freedoms of speach, belief or travel. The person who tries to stop you being able to use your brain to its fullest or who tries to disuade you from practicing rational though is as much your enemy as the person who tries to lock you in prison. Shun them. Do not tolerate it, not for an instant.
Take pride in thought. Stand up for it, defend the practice of thinking where ’ere it may be attacked. Thought is your friend and ally, but it is under siege. “Conform” the non-thinkers say, “Don’t stand out, don’t do what I don’t do”. Fear, envy and laziness are the enemies of thought. Thought is the enemy of the abusive, the mediocre and the thoughless.
Considerate people are thoughful of others. Creative people are thoughtful of new ideas. Great leaders are thoughtful of what must be done. Whatever you do or strive for, thinking helps. Thought is the blessing of society, the hope of the future, the essence of life.
Think!
An idea raised at the Meet Up on 2012-02-19:
There are some cognitive biases that are specific to group discussions. For example:
S Schulz-Hardt, D Frey, C Lüthgens, S Moscovici {2000} “Biased information search in group decision making” Journal of Personality and Social Psychology Volume: 78, Issue: 4, Publisher: American Psychological Association, Pages: 655-669 LINK
Jones PE, Roelofsma PH. {2000} “The potential for social contextual and group biases in team decision-making: biases, conditions and psychological mechanisms.” Ergonomics. 2000 Aug;43(8):1129-52 LINK
Also the Bandwagon effect, Projection bias and False consensus effect .
It would be interesting to vary how the discussions at the Meet Up are structured, record how well people thought each one worked (and, perhaps minute the approximate topics discussed in each group) to see if any pattern emerges.
It is worth mentioning the possibility of macro-scale self-replicators here, or are they an entirely different topic?
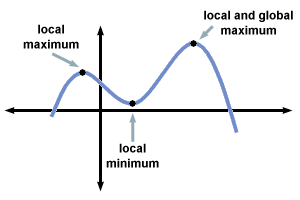
There’s a useful metaphor for this process, from a computing technique mathematicians sometimes use to find approximate solutions to numeric problems called “simulated annealing”. Consider a graph with high points (called “maxima”) and low points (called “minima”) like this one:
Sometimes you know the equation, and can just solve it. But, at other times, the situation is like having a black box with some dials to twiddle, and a single output (which you want to be as big as possible). One way to search for the dial setting that produce the biggest output would be to set the dials all to zero then start systematically searching through all the possible settings, but that might take years. If the graph is simple, you can usually find the answer much faster by noting how large the output is for ten different random settings, then concentrating your search near the random setting that had the largest output and making some smaller random changes, narrowing down on the best of those, and then making some last very small changes to fine-tune your solution. This process is known as “simulated annealing” and the amount of random noise you use to vary the solution at each stage is known as the ‘temperature’. You start off at a high ‘temperature’, making big random jumps, then slowly cool things down, making smaller and smaller changes:
If you lower the ‘temperature’ too fast, you can get stuck at a local maxima. To make the shift to a different maxima (perhaps a higher one), you’d have to increase the ‘temperature’ again.
Dawkins goes into details in his book “The Greatest Show on Earth” about how DNA isn’t a blueprint—rather it is a series of instruction on how to do 3D origami. And the earlier an instruction is in the sequence, it harder it is to vary yet still come up with a functional end shape. (This is why there are local maxima that evolution finds it difficult to vary away from to perhaps better solutions that a designer could have found—such as not routing a nerve in a Giraffe’s neck down via the heart before returning half way back up it again.)
{kind=link}
{kind=link}
I not so sure that when the student suggests “because of heat conduction”, they are attempting to provide a full explanation.
I model their internal thinking more along the lines of “Well, I don’t know for sure what’s going on here, this is an obscure effect I’ve not come across before, but it seems plausible to me that it will be in some way connected with conduction, so I’ll suggest that as a first step, and hope someone else can fill in the mathematical details for me.”
It is closer to the situation when a company owner says to her managers “Production has dropped by 50% in the last quarter, what’s the cause and what can we do about this?” and a manger replies “Well, I don’t know for sure, but I think it might have something to do with the recent marketing campaign where we changed the product name to ‘Yucko’.”
Relevant to this are:
Daniel M Wolperta, R.Chris Miallb and Mitsuo Kawatoc {1998} “Internal models in the cerebellum” Trends in Cognitive Sciences, Volume 2, Issue 9, 338-347, 1 September 1998 doi:10.1016/S1364-6613(98)01221-2
Abstract
This review will focus on the possibility that the cerebellum contains an internal model or models of the motor apparatus. Inverse internal models can provide the neural command necessary to achieve some desired trajectory. First, we review the necessity of such a model and the evidence, based on the ocular following response, that inverse models are found within the cerebellar circuitry. Forward internal models predict the consequences of actions and can be used to overcome time delays associated with feedback control. Secondly, we review the evidence that the cerebellum generates predictions using such a forward model. Finally, we review a computational model that includes multiple paired forward and inverse models and show how such an arrangement can be advantageous for motor learning and control.
Masao Ito {2008} “Control of mental activities by internal models in the cerebellum” Nature Reviews Neuroscience 9, 304-313 (April 2008) | doi:10.1038/nrn2332
Abstract
The intricate neuronal circuitry of the cerebellum is thought to encode internal models that reproduce the dynamic properties of body parts. These models are essential for controlling the movement of these body parts: they allow the brain to precisely control the movement without the need for sensory feedback. It is thought that the cerebellum might also encode internal models that reproduce the essential properties of mental representations in the cerebral cortex. This hypothesis suggests a possible mechanism by which intuition and implicit thought might function and explains some of the symptoms that are exhibited by psychiatric patients. This article examines the conceptual bases and experimental evidence for this hypothesis.
What happens when an entity doesn’t have an intrinsic fixed preference about something, but rather it emerges as a consequence of other (possibly changing) underlying properties?
For example, if a naturalist were to consider a flock of a million starlings as a single entity, and try to map out the flock’s preferences for moving in a particular direction, they might find a statistical correlation (such as “during winter evenings, the flock is 50% more likely to move South than North.”).
I think there needs to be an additional step in the “working with preferences” : preference testing. I think, once you have a representation of preferences in a format from which you can make predictions of future behaviour, you need to explore the bounds of uncertainty, in the same way that statisticians do confirmatory factor analysis after having done exploratory factor analysis.
3^^^3. It’s the smallest simple inconceivably huge number I know.
See also: the concept of the SII (“Smallest Inconceivable Integer”) defined here.
Sounds like a fun place for a HumanSwarm conference. Or, rather, a twin maker conference that would pair with one.
why is self-awareness usually discussed as something profoundly mysterious and advanced?
There are interesting questions connected with conscious self-awareness. Specifically, whether our conscious experience is (and directs) the thought process, or whether it is a shadow that lags most actual decision making. There’s an interesting experiment with split-brained patients where one half of the brain can see a glass of water and reach a hand out to it, but the other half is unaware of this and makes up a reason on the fly as to why it carried out that action.
Have you read the essay on self-awareness by V S Ramachandran ?
AIs will want to preserve themselves, as destruction would prevent them from further influencing the world to achieve their goals.
Would an AI sacrifice itself to preserve the functional status of two other AIs from its copy clan with similar goals?
Unless an AI is specifically programmed to preserve what humans value, it may destroy those valued structures (including humans) incidentally. As Yudkowsky (2008a) puts it, “the AI does not love you, nor does it hate you, but you are made of atoms it can use for something else.”
Another possibility is, rather than trying to alter the values of the AI, alter the environment such that the AI realises that working against human values is likely to be counter productive in achieving its own goals. It doesn’t have to share human values—just understand them and have a rational appreciation of the consequences of working against them.
Occam’s razor seems to work well in practice, but I don’t see how it’s in any way necessary (or even useful!) for the math.
The page ReaysLemma gives some useful links to why simpler theories are more likely to be correct, other things being equal.
Gowder did not say what he meant by “utilitarianism”. Does utilitarianism say...
That right actions are strictly determined by good consequences?
That praiseworthy actions depend on justifiable expectations of good consequences?
That probabilities of consequences should normatively be discounted by their probability, so that a 50% probability of something bad should weigh exactly half as much in our tradeoffs?
That virtuous actions always correspond to maximizing expected utility under some utility function?
That two harmful events are worse than one?
That two independent occurrences of a harm (not to the same person, not interacting with each other) are exactly twice as bad as one?
That for any two harms A and B, with A much worse than B, there exists some tiny probability such that gambling on this probability of A is preferable to a certainty of B?
Not Gowder, but another one for the list:
” Precedent Utilitarians believe that when a person compares possible actions in a specific situation, the comparative merit of each action is most accurately approximated by estimating the net probable gain in utility for all concerned from the consequences of the action, taking into account both the precedent set by the action, and the risk or uncertainty due to imperfect information. “
source
Unless the torture somehow causes Vast consequences larger than the observable universe, or the suicide of someone who otherwise would have been literally immortal, it doesn’t matter whether the torture has distant consequences or not.
What about the consequences of the precedent set by the person making the decision that it is ok to torture an innocent person, in such circumstances? If such actions get officially endorsed as being moral, isn’t that going to have consequences which mean the torture won’t be a one-off event?
There’s a rather good short story about this, by Ursula K LeGuin:
According to Kanazawa’s Hypothesis, the comparative effectiveness of ‘type 1’ thinking should vary with how long the species has had to adapt to the type of problem being presented. So predicting herd behaviour, or how popular someone else is likely to be in a group, are problems human instincts have had a long time to adapt to. Whereas predicting the solutions to complex problems involving quantum mechanics, or just lots of capacitors and resistors in series and in parallel, are not.
If you are specifically interested in the interaction with Marxism, then the novel “Singularity Sky” by Charles Stross talks a little about it.
The most obvious angle is the means of production. Here’s a link to a list of writings about post-scarcity societies
Does he still predict that mind uploading will be possible by 2040?
If not, how does he explain the change in expected timeline, and why should people expect the same factors won’t apply to his new timeline?
This, by the way, resulted from a discussion at the Cambridge weekly meet up. We were thinking of trying to post summaries of discussions, to see if there were any spottable patterns in which sort of discussions resulted in usable results.
Any suggestions from other Less Wrong groups about how to improve the enjoyment and benefit from meetups for the members attending them, systematic meta-practices that affect how we organise and try thinking about how to organise, are greatly appreciated.
It uses bounded rationality, not just because that’s what we evolved, but because heuristics, probabilistic logic and rational ignorance have a higher marginal cost efficiency (the improvements in decision making don’t produce a sufficient gain to outweigh the cost of the extra thinking).
I’m not sure about this. I think we use bounded rationality because that’s the only kind that can physically exist in the universe. You seem to be making the stronger statement that we’re near-optimal in terms of rationality—does this mean that Less Wrong can’t work?
Thank you for the feedback. Most appreciated. I’ve corrected the links you mentioned.
Perhaps a clearer example of what I mean with respect to bounded rationality would be in computing where, when faced with a choice between two algorithms, the first of which is provably correct and never fails, and the second of which can fail sometimes but rarely, the optimal decision is to pick the latter. An example of this is UUIDs—they can theoretically collide but, in practice, are very very unlikely to do so.
My point is that we shouldn’t assume AIs will even try to be as logical as possible. They may, rather, try only to be as logical as is optimal for achieving their purposes.
I don’t intend to claim that humans are near optimal. I don’t know. I have insufficient information. It seems likely to me that what we were able to biologically achieve so far is the stronger limit. I merely meant that, even were that limitation removed (by, for example, brains becoming uploadable), additional limits also exist.
| The foregoing thoughts are hardly original. David Hume is famous for having observed that ought cannot be derived from is
See also the article From ‘Is’ to ‘Ought’, by Douglas_Reay