Web of connotations: Bleggs, Rubes, thermostats and beliefs
This is a series of posts with the modest goal of showing on how you can get syntax from semantics, solve the grounding problem, and start looking for models within human brains.
Before getting to the meat of the approach, I’ll have to detour, Eliezer-like, into a few background concepts. They’ll be presented in this post. The overall arc of the series is that, once we understand how syntax and semantics can fail to match up, then checking if they do becomes easy.
Old arguments: does a thermostat have beliefs?
I’d like to start with Searle. He’s one of the most annoying philosophers, because he has genuine insights, but since he focuses mainly on the Chinese room thought experiment—which is an intuition pump with no real content behind it—everyone ignores these.
McCarthy argued:
Machines as simple as thermostats can be said to have beliefs, and having beliefs seems to be a characteristic of most machines capable of problem solving performance
Searle counter-argues:
Think hard for one minute about what would be necessary to establish that that hunk of metal on the wall over there had real beliefs: beliefs with direction of fit, propositional content, and conditions of satisfaction; beliefs that had the possibility of being strong beliefs or weak beliefs; nervous, anxious, or secure beliefs; dogmatic, rational, or superstitious beliefs; blind faiths or hesitant cogitations; any kind of beliefs. The thermostat is not a candidate.
This seems like it’s just a definition problem, similar to the discussion of whether something is a Rube or a Blegg. Searle lists the rich and varied properties of human beliefs, and contrasts them with McCarthy’s stripped down interpretation of belief. It seems that we could just call the first “human-like beliefs”, and the second “simplified beliefs”, and we would have dissolved the question.
But I’d argue that the implicit question is actually more complicated than that, and that Searle was, in this instance, correct.
The implicit part of complex definitions
Bleggs and rubes are defined by only five characteristics:
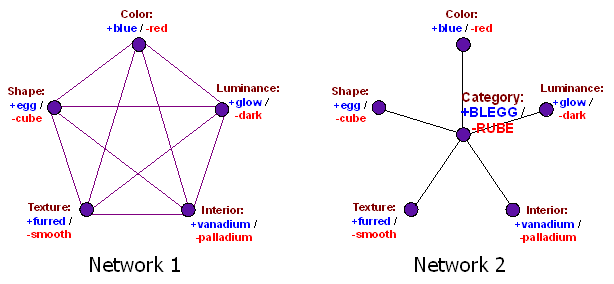
Let’s have a look at two more complicated examples: is this object a chair? Is person X good (and what is goodness anyway)?
{kind=link}
Chairs
For chairs, we have a rough intensional definition that goes something like “something humans sit on”, and a huge amount of mental examples of chairs from our experience (extensional definition).
When I bring up the question of what is and what isn’t a chair, most people are uncertain, because they don’t often encounter edge cases. When I present these, by, eg sitting on the edge of a table or asking whether a broken chair counts as a chair, they generally try and refine the intensional and the extensional definitions by adding more explicit characteristics, and ruling that specific example are or aren’t chairs.
There are many ways of doing so, but some ways are actually better than others. Scott Alexander’s post argues that definitions can’t be right or wrong, but I think in general they can be.
A definition of chair is wrong if it doesn’t approximate the boundaries of the mental set of examples of chairs that we have in our minds. If your definition answers “yes” to the question “is your mobile phone a chair if you sit on it?”, then this is a wrong/bad/incorrect definition.
A definition doesn’t have to be boolean, yes/no—you could say that a mobile phone being sat on is 5% a chair, while one being talked into is 0.1% a chair. And you have quite a lot freedom when setting these percentages—and different conversations with different people will result in quite different numbers. But you don’t have arbitrary freedom. Some definitions of chair are just bad.
Impossible definitions
Note that it may be impossible in some cases to find a good general definition for a term. “Natural” seems to be one of those categories. There are clear examples of natural objects (trees, animals) and clear examples of non-natural objects (swords, iphones).
Yet the definition seems to completely fall apart when we press it too hard. Human beings have been having a huge effect on the world, so, for example, the “natural landscapes of England” are also highly artificial. Genetic engineering to produce a cow: non-natural. Selective breeding that produces the same cow: arguably natural. Natural selection to produce the same cow: totally natural, as the name indicates. But what if the natural selection pressure was an unforeseen consequence of human action? Or a foreseen consequences? Or a deliberate one?
{kind=link}
The point is, when we consider the set of all things and processes in the world, there does not seem to be a good definition of what is natural and what isn’t. Like the AI searching for the nearest unblocked strategy, it seems that most non-natural objects can be approximated by something arguably natural.
That doesn’t mean that the category “natural” is entirely vacuous. We could, for example, see it as the conjunction of more useful definitions (I would personally start by distinguishing between natural objects, and objects created by natural methods). Much philosophical debate about definitions is of this type.
Another thing to note is that “natural” can have a clear definition when applied only to a subset of things. In the set {oak tree, lice, aircraft-carrier, window}, it’s clear which objects are natural and which are not. Sports and games that humans play are similar. People play a well defined game of football, despite the fact that the rules don’t cover what happens if you were to play in space, on Mars, or with jetpack-enhanced super-humans who could clone themselves in under ten seconds. It is plausible that “game of football” cannot be well-defined in general; however, within the limitations of typical human situations, it’s perfectly well defined.
Extending definitions, AI, and moral realism
As we move to more and more novel situations, and discover new ideas, previously well-defined concepts become underdefined and have to be updated. For example, the definition of Formula One racing car is constantly evolving and getting more complex, just to keep the sport somewhat similar to what it was originally (there are other goals to the changing definition, but preventing the sport from becoming “racing rockets vaguely around a track” is a major one).
This is a major challenge in building safe AI—when people periodically come up with ideas such as training AI to be “respectful” or whatever, they are thinking of a set of situations within typical human situations, and assigning respectful/non-respectful labels to them.
They don’t generally consider how the boundary extends when we get powerful AIs capable of going radically beyond the limits of typical human situations. Very naive people suggest intensional definitions of respect that will explode into uselessness the moment we leave typical situations. More sophisticated people expect the AI to learn and extend the boundary itself. I expect this to fail because I don’t see “respectful” as having any meaningful definition across all situations, but it’s much better than the intensional approach.
I’m strongly speculating here, but I suspect the difference between moral realists and non-moral realists is mainly whether we expect moral category definitions to extend well or badly.
Goodness and the unarticulated web of connotations
Suppose someone has programmed an AI, and promised that that AI is “good”. They are trustworthy, and even Eliezer has been convinced that they’ve achieved that goal. Given that, the question is:
Should I let that AI take care of an aging relative?
The concept of “good” is quite ambiguous, but generally, if someone is a “good” human, then they’d also be loyal, considerate, charitable, kind, truthful, honourable, etc… in all typical human situations. These concepts of loyalty, consideration, etc… form a web of connotations that go along with good. We can think of them as connotations that go along with “good”, or as properties of central examples of “good” people, or as properties shared by most people in our mental set of “good” people.
Notice that unlike the blegg/rube example, I haven’t listed all the properties of “good”. Indeed the first step of any philosophical investigation of “good” is to figure out and list these properties, starting from our mental example set.
There are two obvious ways to extend the concept of good to more general cases. First of all, following the example of Peter Singer, we could distill the concept by looking at properties that we might like for definition of good—things like distance to the victim not mattering. If we follow that route, we’d end up somewhere close to a preference or hedonistic utilitarian. Call this “EAGood”—the sort of definition of good that most appeals to effective altruists. Properties like loyalty, consideration, and so on, get sacrificed to the notion of utilitarianism: an AI maximising EA good would only have those properties when they helped it increase the EAGood.
Or we could go the other way, and aim to preserve all the things in the web of connotations. Formalise loyalty, consideration, charitability, and so on, combine all these definitions, and then generalise the combined definition. Call this broad definition “MundaneGood”. Notice that this is much harder, but it also means that our intuitions about “good” in typical situations, are more portable to extreme situations. The analogy between “EAGood” and “MundaneGood” and bullet-dodgers and bullet-swallowers is quite clear.
Notice that in practice, most people who are “EAGood” are also “MundaneGood”; this is not unexpected, as these two definitions, by construction, overlap in the typical human situations.
In any case, it would be perfectly fine to leave an aging relative with a “MundaneGood” AI: they will do their best to help them, because a good human given that role would do so. It would much more dubious to leave them with a “EAGood” AI: they would only help them if doing so would increase human utility, directly or indirectly (such as causing me to trust the AI). They may well kill them quickly, if this increases the utility of the rest of humanity (on the other hand, the EAGood AI is more likely to be already helping my relative without me asking it to do so).
So if we started with a concept , and had a narrow extension of of , then predicting the behaviour of an -maximiser in untypical situations is hard. However, if is a broad extension of , then our intuitions can be used to predict the behaviour of a -maximiser in the same situations. In particular, a -maximiser is likely to have all the implicit properties of that we haven’t defined or even thought of.
Back to the thermostat
All sorts of things have webs of connotations, not just ethical concepts. Objects have them as well (a car is a vehicle is a physical object; a car generally burns carbon-based fuels; a car generally has a speed below 150km/h), as do animals and people. The Cyc project is essentially an attempt to formalise all the web of connotations that go with standard concepts.
In terms of “beliefs”, it’s clear that McCarthy is using a narrow/distilled extension of the concept. Something like “a belief is something within the agent that co-varies with the truth of the proposition in the outside world”. So labeling something “belief about temperature”, and attaching that to the correct wires that go to a thermometer, is enough to say that thing has a belief.
In contrast, Searle uses a broad definition of belief. He sees the thermostat failing to have beliefs because it fails to have the same web of connotations that human beliefs do.
The implicit question is:
Is McCarthy’s definition of belief sufficient to design an agent that can reason as a human can?
Note that neither Searle nor McCarthy’s definitions address this question directly. This means that it’s an implicit property of the definition. By the previous section, implicit properties are much more likely to be preserved in broad definitions than in narrow ones. Therefore McCarthy’s definition is unlikely to lead to a successful AI; the failure of Symbolic AI is a testament to this. Searle was not only right about this; he was right for (partially) the right reasons.
Sufficient versus necessary
Does this mean that a true AI would need to have all the properties that Searle mentioned? That it would need to have “strong beliefs or weak beliefs; nervous, anxious, or secure beliefs; dogmatic, rational, or superstitious beliefs; blind faiths or hesitant cogitations”? No, of course—it’s unlikely that the whole web of connotations would be needed. However, some of the web may be necessary; and the more of the web that the agent has, the more likely it is to be able to reason as a human can.
Side-note about the Chinese Room.
It’s interesting to note that in the Chinese Room thought experiment, Searle tries to focus attention on the man in the room, manipulating Chinese symbols. In contrast, many of the counter-arguments focus on the properties of the whole system.
These properties must include anything that humans display in their behaviour. For instance, having a (flawed) memory, stored in complex ways, having processes corresponding to all the usual human emotions, periods of sleep, and so on. In fact, these properties include something for modelling the properties of beliefs—such as “beliefs with direction of fit, propositional content, and conditions of satisfaction; beliefs that had the possibility of being strong beliefs or weak beliefs; nervous, anxious, or secure beliefs; dogmatic, rational, or superstitious beliefs; blind faiths or hesitant cogitations; any kind of beliefs”.
Thus, the Chinese room is a broad model of a human mind, with a full web of connotations, but Searle’s phrasing encourages us to see it as narrow one.
- mAIry’s room: AI reasoning to solve philosophical problems by (5 Mar 2019 20:24 UTC; 87 points)
- Model splintering: moving from one imperfect model to another by (27 Aug 2020 11:53 UTC; 79 points)
- Research Agenda v0.9: Synthesising a human’s preferences into a utility function by (17 Jun 2019 17:46 UTC; 74 points)
- Why we need a *theory* of human values by (5 Dec 2018 16:00 UTC; 66 points)
- Future directions for ambitious value learning by (11 Nov 2018 15:53 UTC; 48 points)
- Defeating Goodhart and the “closest unblocked strategy” problem by (3 Apr 2019 14:46 UTC; 45 points)
- By default, avoid ambiguous distant situations by (21 May 2019 14:48 UTC; 33 points)
- Zen and Rationality: Don’t Know Mind by (6 Aug 2020 4:33 UTC; 26 points)
- Bridging syntax and semantics, empirically by (19 Sep 2018 16:48 UTC; 25 points)
- Full toy model for preference learning by (16 Oct 2019 11:06 UTC; 24 points)
- If I were a well-intentioned AI… III: Extremal Goodhart by (28 Feb 2020 11:24 UTC; 22 points)
- Being wrong in ethics by (29 Mar 2019 11:28 UTC; 22 points)
- Platonic rewards, reward features, and rewards as information by (12 Nov 2019 19:38 UTC; 20 points)
- Doxa, Episteme, and Gnosis Revisited by (20 Nov 2019 19:35 UTC; 19 points)
- Bridging syntax and semantics with Quine’s Gavagai by (24 Sep 2018 14:39 UTC; 19 points)
- Toy model piece #2: Combining short and long range partial preferences by (8 Aug 2019 0:11 UTC; 18 points)
- Alignment Newsletter #25 by (24 Sep 2018 16:10 UTC; 18 points)
- Learning “known” information when the information is not actually known by (1 Apr 2019 17:56 UTC; 16 points)
- Alignment Newsletter #26 by (2 Oct 2018 16:10 UTC; 13 points)
- Comparing AI Alignment Approaches to Minimize False Positive Risk by (30 Jun 2020 19:34 UTC; 5 points)
- 's comment on Are you in a Boltzmann simulation? by (20 May 2019 12:31 UTC; 3 points)
So I don’t exactly disagree with your conclusion or the points you make, but I feel like there is something in this framing that sets up the possibility of creating confusion down the line. It’s a little hard to pin down where this is coming from, but I’ll try anyway by looking at this paragraph that I think may illustrate the crux:
So there’s a certain perspective from which your framing of a-definition-of-chair-is-wrong-if-it-includes-mobile-phones makes sense because it’s not useful to the purpose of asking “can I sit on it such that I’m happier about sitting?” But this is a deeply teleological approach and as such depends thoroughly on the worldview from which chairness is being assessed. I think that’s fair as far as chairness goes and is ultimately fair about any question of ontology we might ask, since from where else can be construct ontology but from where we are perceiving the world? But I also sense a privileging of a particular worldview, namely a human one, that may artificially limit the sorts of useful categories we are willing to consider. After all, to a biped the size of a hamster a mobile phone might make an excellent chair.
I’m interesting to see where you go with this, but having not read the subsequent posts I’ll register now my suspicion that there is some deep philosophical disagreement I’m going to have with where you end up although I can’t quite put my finger on what it is right now, but I suspect it’s something like making assumptions that are pragmatically reasonable under normal circumstances but don’t hold when considering minds in general.
This is deliberate—a lot what I’m trying to do is figure out human values, so the human worldviews and interpretations will generally be the most relevant.
So maybe this points to what I’m wanting to push back against. If we focus on figuring out human values but not the category of things to which human values naturally belong and is shared with AI, we’re not setting ourselves up for solving the problem of alignment but rather having a better model of human values. Having that better model is fine as far as it goes, but so long as we keep humans as our primary frame of reference it invites us to be overly specific about what we think “values” are in ways that may inhibit our ability to understand how an AI with a very alien mind to a human one would be able to reason about them. This might help explain why I’ve preferred to go in the direction of looking for a more general concept (which I ended up calling axias) that generalizes over minds-in-general rather than looking for a concept of values that only makes sense when we look at humans, and why I think that’s a necessary approach (so we have something we can reason about in common between humans an AIs).