LessWrong team member / moderator. I’ve been a LessWrong organizer since 2011, with roughly equal focus on the cultural, practical and intellectual aspects of the community. My first project was creating the Secular Solstice and helping groups across the world run their own version of it. More recently I’ve been interested in improving my own epistemic standards and helping others to do so as well.
Raemon(Raymond Arnold)
Karma: 49,046
That’s actually not (that much of) a crux for me (who also thinks it’s mildly manipulative, but, below the threshold where I feel compelled to push hard for changing it).
Curated.
I do sure wish this question had easier answers, but I appreciate this post laying out a lot of the evidence.
I do have some qualms about the post, in that while it’s pretty thorough on the evidence re: seed oils, it sort of handwavily assumes some other nutrition stuff about processed foods that (I’m willing to bet) also have highly mixed/confusing evidence bases. But, still thought the good parts of the post were good enough to be worth curating.
I’m trying to decide whether to rename this post “Metastrategy Workshop.” Fractal Strategy happened to make sense for the skillset I had put together at the time but I don’t know that it’s what I’m going to stick with.
One thing to remember is I (mostly) am advocating playing each game only once, and doing a variety of games/puzzles/activities, many of which should just be “real-world” activities, as well as plenty of deliberate Day Job stuff. Some of them should focus on resource management, and some of that should be “games” that have quick feedback loops, but it sounds like you’re imagining it being more focused on the goodhartable versions of that than I think it is.
(also, I think multiplayer games where all the information is known is somewhat an antidote to these particular failure modes? even when all the information is known, there’s still uncertainty about how the pieces combine together, and there’s some kind of brute-reality-fact about ‘well, the other players figured it out better than you’)
Curated. (In particular recommending people click through and read the full Scott Alexander post)
I’ve been tracking the Rootclaim debate from the sidelines and finding it quite an interesting example of high-profile rationality.
I have a friend who’s been following the debate quite closely and finding that each debater, while flawed, had interesting points that were worth careful thought. My impression is a few people I know shifted from basically assuming Covid was probably a lab-leak, to being much less certain.
In general, I quite like people explicitly making public bets, and following them up with in-depth debate.
What would a “qualia-first-calibration” app would look like?
Or, maybe: “metadata-first calibration”
The thing with putting probabilities on things is that often, the probabilities are made up. And the final probability throws away a lot of information about where it actually came from.
I’m experimenting with primarily focusing on “what are all the little-metadata-flags associated with this prediction?”. I think some of this is about “feelings you have” and some of it is about “what do you actually know about this topic?”
The sort of app I’m imagining would help me identify whatever indicators are most useful to me. Ideally it has a bunch of users, and types of indicators that have been useful to lots of users can promoted as things to think about when you make predictions.
Braindump of possible prompts:
– is there a “reference class” you can compare it to?
– for each probability bucket, how do you feel? (including ‘confident’/‘unconfident’ as well as things like ‘anxious’, ‘sad’, etc)
– what overall feelings do you have looking at the question?
– what felt senses do you experience as you mull over the question (“my back tingles”, “I feel the Color Red”)
...
My first thought here is to have various tags you can re-use, but, another option is to just do totally unstructured text-dump and somehow do factor analysis on word patterns later?
lol at the approval/agreement ratio here. It does seem like this is a post that surely gets something wrong.
I think I have a different overall take than Ben here, but, the frame I think makes sense here is to be like: “Deontological injuctions are guardrails. There are hypothetical situations (and, some real situations) where it’s correct to override them, but the guardrail should have some weight and for more important guardrails, you need a clearer reasoning for why avoiding it actually helps.”
I don’t know what I think about this in the case of a country passing laws. Countries aren’t exactly agents. Passing novel laws is different than following existing laws. But, I observe:
it’s really hard to be confident about longterm consequences of things. Consequentialism just isn’t actually compute-efficient enough to be what you use most of the time for making decisions. (This includes but isn’t limited to “you’re contemplating crazy sounding actions for strange sounding reasons”, although I think has a similar generator)
it matters just not what you-in-particular-in-a-vacuum do, in one particular timeslice. It matters how complicated the world is to reason about. If everyone is doing pure consequentialism all the time, you have to model the way each person is going to interpret consequences with their own special-snowflake worldview. Having to model “well, Alice and Bob and Charlie and 1000s of other people might decide to steal from me, or from my friends, if the benefits were high enough and they thought they could get away with it” adds a tremendous amount of overhead.
You should be looking for moral reasoning that makes you simple to reason about, and that perform well in most cases. That’s a lot of what deontology is for.
There’s a skill of “quickly operationalizing a prediction, about a question that is cruxy for your decisionmaking.”
And, it’s dramatically better to be very fluent at this skill, rather than “merely pretty okay at it.”
Fluency means you can actually use it day-to-day to help with whatever work is important to you. Day-to-day usage means you can actually get calibrated re: predictions in whatever domains you care about. Calibration means that your intuitions will be good, and _you’ll know they’re good_.
Fluency means you can do it _while you’re in the middle of your thought process_, and then return to your thought process, rather than awkwardly bolting it on at the end.
I find this useful at multiple levels-of-strategy. i.e. for big picture 6 month planning, as well as for “what do I do in the next hour.”
I’m working on this as a full blogpost but figured I would start getting pieces of it out here for now.
A lot of this skill is building off on CFAR’s “inner simulator” framing. Andrew Critch recently framed this to me as “using your System 2 (conscious, deliberate intelligence) to generate questions for your System 1 (fast intuition) to answer.” (Whereas previously, he’d known System 1 was good at answering some types of questions, but he thought of it as responsible for both “asking” and “answering” those questions)
But, I feel like combining this with “quickly operationalize cruxy Fatebook predictions” makes it more of a power tool for me. (Also, now that I have this mindset, even when I can’t be bothered to make a Fatebook prediction, I have a better overall handle on how to quickly query my intuitions)
I’ve been working on this skill for years and it only really clicked together last week. It required a bunch of interlocking pieces that all require separate fluency:
1. Having three different formats for Fatebook (the main website, the slack integration, and the chrome extension), so, pretty much wherever I’m thinking-in-text, I’ll be able to quickly use it.
2. The skill of “generating lots of ‘plans’”, such that I always have at least two plausibly good ideas on what to do next.
3. Identifying an actual crux for what would make me switch to one of my backup plans.
4. Operationalizing an observation I could make that’d convince me of one of these cruxes.
I feel sort of empathetically sad that there wasn’t a way to make it work, but that all makes sense.
Living at a group house seems really important for my psychological well-being, though I imagine if I was living with a partner AND kids that’d be a big enough reroll on social circumstances I don’t know what to expect.
Yeah.
“did you remember to make any quantitative estimate at all?”
I’m actually meaning to ask the question “did you estimate help you strategically?” So, if you get two estimates wildly wrong, but they still had the right relatively ranking and you picked the right card to draft, that’s a win.
Also important: what matters here is not whether you got the answer right or wrong, it’s whether you learned a useful thing in the process that transfers (and, like, you might end up getting the answer completely wrong, but if you can learn something about your thought process that you can improve on, that’s a bigger win.
I’m not quite sure what things you’re contrasting here.
The skills I care about are:
making predictions (instead of just doing stuff without reflecting on what else is likely to happen)
thinking about which things are going to be strategically relevant
thinking about what resources you have available and how they fit together
thinking about how to quantitatively compare your various options
And it’d be nice to train thinking about that in a context without the artificialness of gaming, but I don’t have great alternatives. In my mind, the question is “what would be a better way to train those skills?”, and “are simple strategy games useful enough to be worth training on, if I don’t have better short-feedback-cycle options?”
(I can’t tell from your phrasing so far if you were oriented around those questions, or some other one)
Prompts for Big-Picture Planning
Basically: yep, a lot of skills here are game design specific and not transfer. But, I think a bunch of other skills do transfer, in particular in a context where the you only play Luck Be a Landlord once (as well as 2-3 other one-shot games, and non-game puzzles), but then also follow it up the next day with applying the skills in more real-world domains.
Few people are playing videogames to one-shot them, and doing so requires a different set of mental muscles than normal. Usually if you play Luck Be a Landlord, you’ll play it one or twice just to get the feel for how the game works, and by the time you sit down and say “okay, now, how does this game actually work?” you’ll already have been exposed to the rough distribution of cards, etc.
In one-shotting, you need to actually spell out your assumptions, known unknowns, and make guesses about unknown unknowns. (Especially at this workshop where the one-shotting comes with ’”take 5 minutes per turn, make as many fatebook predictions as you can for the first 3 turns, and then for the next 3 turns try to make two quantitative comparisons”.
The main point here is to build up a scaffolding of those mental muscles such that the next day when you ask “okay, now, make a quantitative evaluation between [these two research agendas] or [these two product directions] [this product direction and this research agenda]”, you’ve not scrambling to think about both the immense complexity of the messy details and also the basics of how to do a quantitative estimate in a strategic environment.
I think I do mostly mean “rough quantitative estimates”, rather than specifically targeting Femi-style orders of magnitude. (though I think it’s sort of in-the-spirit-of-fermi to adapt the amount of precision you’re targeting to the domain?)
The sort of thing I was aiming for here was: “okay, so this card gives me N coins on average by default, but it’d be better if there were other cards synergizing with it. How likely are other cards to synergize? How large are the likely synergies? How many cards are there, total, and how quickly am I likely to land on a synergizing card?”
(This is all in the frame of one-shotting the game, i.e. you trying to maximize score on first play through, inferring any mechanics based on the limited information you’re presented with)
One reason I personally found Luck Be a Landlord valuable is it’s “quantitative estimates on easy mode, where it’s fairly pre-determined what common units of currency you’re measuring everything in.”
My own experience was:
trying to do fermi-estimates on things like “which of these research-hour interventions seem best? How do I measure researcher hours? If researcher-hours are not equal, what makes some better or worse?”
trying to one-shot Luck Be a Landlord
trying to one-shot the game Polytopia (which is more strategically rich than Luck Be a Landlord, and figuring out what common currencies make sense is more of a question
… I haven’t yet gone back to try to and do more object-level, real-world messy fermi calculations, but, I feel better positioned to do so.
Yup, definitely seems relevant.
Weak downvoted because I don’t find find raw dumps of LLM responses very useful. Were there particular bits that felt useful to you? I’d prefer just seeing whatever paragraphs you thought you learned something from.
Yeah Fatebook is my new go-to. I think it either didn’t exist at the time I posted this, or it was still fairly new/untested.
I currently think Anthropic didn’t “explicitly publicly commit” to not advance the rate of capabilities progress. But, I do think they made deceptive statements about it, and when I complain about Anthropic I am complaining about deception, not “failing to uphold literal commitments.”
I’m not talking about the RSPs because the writing and conversations I’m talking about came before that. I agree that the RSP is more likely to be a good predictor of what they’ll actually do.
I think most of the generator for this was more like “in person conversations”, at least one of which was between Dario and Dustin Moswkowitz:
The most explicit public statement I know is from this blogpost (which I agree is not an explicit commitment, but, I do think
Capabilities: AI research aimed at making AI systems generally better at any sort of task, including writing, image processing or generation, game playing, etc. Research that makes large language models more efficient, or that improves reinforcement learning algorithms, would fall under this heading. Capabilities work generates and improves on the models that we investigate and utilize in our alignment research. We generally don’t publish this kind of work because we do not wish to advance the rate of AI capabilities progress. In addition, we aim to be thoughtful about demonstrations of frontier capabilities (even without publication). We trained the first version of our headline model, Claude, in the spring of 2022, and decided to prioritize using it for safety research rather than public deployments. We’ve subsequently begun deploying Claude now that the gap between it and the public state of the art is smaller.
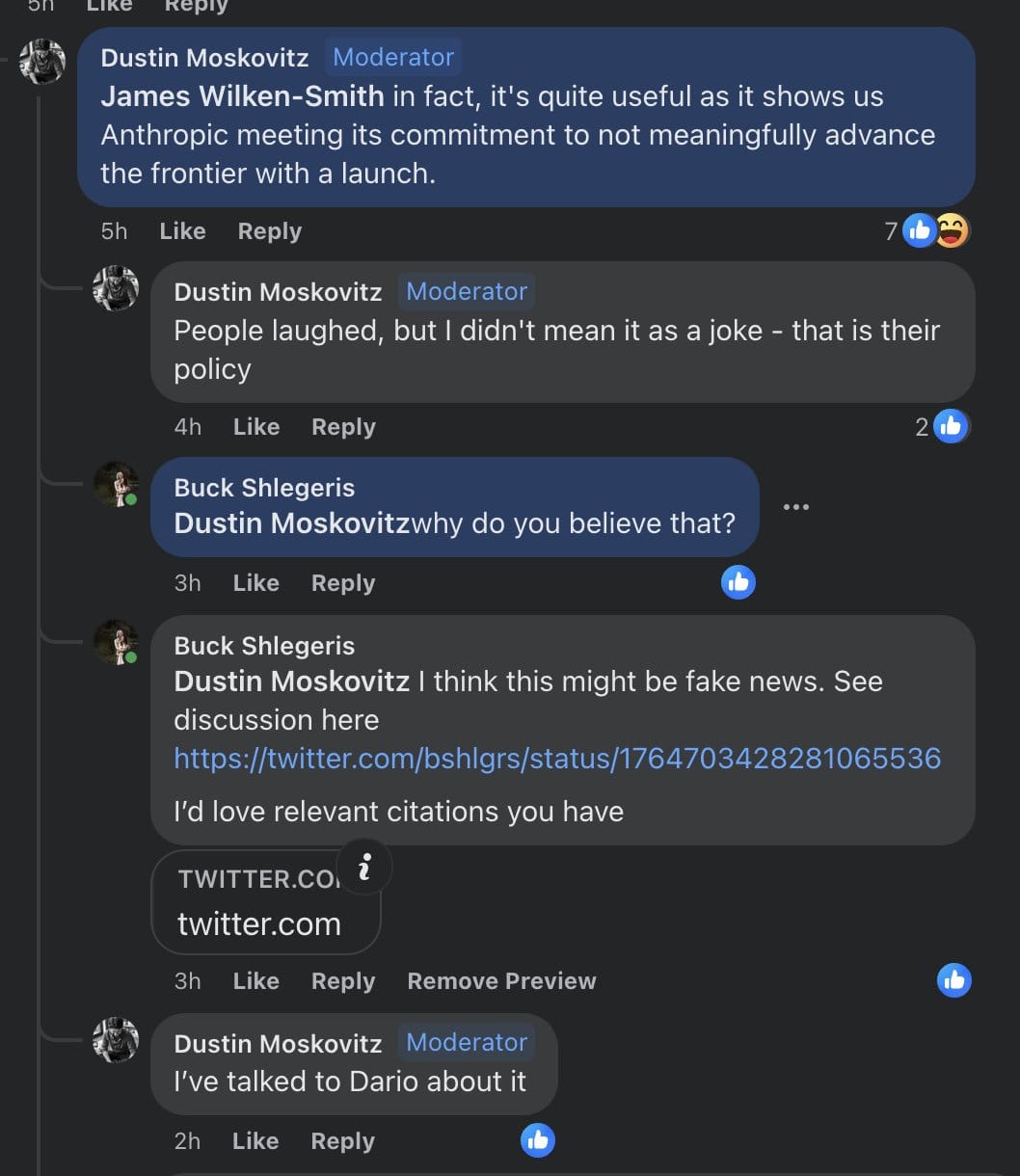
Wow the joke keeps being older.