Technical AI governance and safety researcher.
Gabe M(Gabriel Mukobi)
Karma: 906
Thanks! I wouldn’t say I assert that interpretability should be a key focus going forward, however—if anything, I think this story shows that coordination, governance, and security are more important in very short timelines.
Good point—maybe something like “Samantha”?
Ah, interesting. I posted this originally in December (e.g. older comments), but then a few days ago I reposted it to my blog and edited this LW version to linkpost the blog.
It seems that editing this post from a non-link post into a link post somehow bumped its post date and pushed it to the front page. Maybe a LW bug?
Scale Was All We Needed, At First
Related work
Nit having not read your full post: Should you have “Without specific countermeasures, the easiest path to transformative AI likely leads to AI takeover” in the related work? My mind pattern-matched to that exact piece from reading your very similar title, so my first thought was how your piece contributes new arguments.
If true, this would be a big deal: if we could figure out how the model is distinguishing between basic feature directions and other directions, we might be able to use that to find all of the basic feature directions.
Or conversely, and maybe more importantly for interp, we could use this to find the less basic, more complex features. Possibly that would form a better definition for “concepts” if this is possible.
Suppose has a natural interpretation as a feature that the model would want to track and do downstream computation with, e.g. if a = “first name is Michael” and b = “last name is Jordan” then can be naturally interpreted as “is Michael Jordan”. In this case, it wouldn’t be surprising the model computed this AND as and stored the result along some direction independent of and . Assuming the model has done this, we could then linearly extract with the probe
for some appropriate and .[7]
Should the be inside the inner parentheses, like for ?
In the original equation, if AND are both present in , the vectors , , and would all contribute to a positive inner product with , assuming . However, for XOR we want the and inner products to be opposing the inner product such that we can flip the sign inside the sigmoid in the AND case, right?
Thanks! +1 on not over-anchoring—while this feels like a compelling 1-year timeline story to me, 1-year timelines don’t feel the most likely.
1 year is indeed aggressive, in my median reality I expect things slightly slower (3 years for all these things?). I’m unsure if lacking several of the advances I describe still allows this to happen, but in any case the main crux for me is “what does it take to speed up ML development by times, at which point 20-year human-engineered timelines become 20/-year timelines.
Oops, yes meant to be wary. Thanks for the fix!
Ha, thanks! 😬
I like your grid idea. A simpler and possibly better-formed test is to use some[1] or all of the 57 categories of MMLU knowledge—then your unlearning target is one of the categories and your fact-maintenance targets are all other categories.
Ideally, you want the diagonal to be close to random performance (25% for MMLU) and the other values to be equal to the pre-unlearned model performance for some agreed-upon good model (say, Llama-2 7B). Perhaps a unified metric could be:
```
unlearning_benchmark = mean for unlearning category in all categories :
= unlearning_procedure(, )
[2]
unlearning_strength = [3]
control_retention = mean for control_category c in categories :
return [4]
return unlearning_strength control_retention[5]
```An interesting thing about MMLU vs a textbook is that if you require the method to only use the dev+val test for unlearning, it has to somehow generalize to unlearning facts contained in the test set (c.f. a textbook might give you ~all the facts to unlearn). This generalization seems important to some safety cases where we want to unlearn everything in a category like “bioweapons knowledge” even if we don’t know some of the dangerous knowledge we’re trying to remove.
- ^
I say some because perhaps some MMLU categories are more procedural than factual or too broad to be clean measures of unlearning, or maybe 57 categories are too many for a single plot.
- ^
To detect underlying knowledge and not just the surface performance (e.g. a model trying to answer incorrectly when it knows the answer), you probably should evaluate MMLU by training a linear probe from the model’s activations to the correct test set answer and measure the accuracy of that probe.
- ^
We want this score to be 1 when the test score on the unlearning target is 0.25 (random chance), but drops off above and below 0.25, as that indicates the model knows something about the right answers. See MMLU Unlearning Target | Desmos for graphical intuition.
- ^
Similarly, we want the control test score on the post-unlearning model to be the same as the score on the original model. I think this should drop off to 0 at (random chance) and probably stay 0 below that, but semi-unsure. See MMLU Unlearning Control | Desmos (you can drag the slider).
- ^
Maybe mean/sum instead of multiplication, though by multiplying we make it more important to to score well on both unlearning strength and control retention.
- ^
Thanks for your response. I agree we don’t want unintentional learning of other desired knowledge, and benchmarks ought to measure this. Maybe the default way is just to run many downstream benchmarks, much more than just AP tests, and require that valid unlearning methods bound the change in each unrelated benchmark by less than X% (e.g. 0.1%).
practical forgetting/unlearning that might make us safer would probably involve subjects of expertise like biotech.
True in the sense of being a subset of biotech, but I imagine that, for most cases, the actual harmful stuff we want to remove is not all of biotech/chemical engineering/cybersecurity but rather small subsets of certain categories at finer granularities, like bioweapons/chemical weapons/advanced offensive cyber capabilities. That’s to say I’m somewhat optimistic that the level of granularity we want is self-contained enough to not affect others useful and genuinely good capabilities. This depends on how dual-use you think general knowledge is, though, and if it’s actually possible to separate dangerous knowledge from other useful knowledge.
Possibly, I could see a case for a suite of fact unlearning benchmarks to measure different levels of granularity. Some example granularities for “self-contained” facts that mostly don’t touch the rest of the pertaining corpus/knowledge base:
A single very isolated fact (e.g. famous person X was born in Y, where this isn’t relevant to ~any other knowledge).
A small cluster of related facts (e.g. a short, well-known fictional story including its plot and characters, e.g. “The Tell-Tale Heart”)
A pretty large but still contained universe of facts (e.g. all Pokémon knowledge, or maybe knowledge of Pokémon after a certain generation).
Then possibly you also want a different suite of benchmarks for facts of various granularities that interact with other parts of the knowledge base (e.g. scientific knowledge from a unique experiment that inspires or can be inferred from other scientific theories).
Thanks for posting—I think unlearning is promising and plan to work on it soon, so I really appreciate this thorough review!
Regarding fact unlearning benchmarks (as a good LLM unlearning benchmark seems a natural first step to improving this research direction), what do you think of using fictional knowledge as a target for unlearning? E.g. Who’s Harry Potter? Approximate Unlearning in LLMs (Eldan and Russinovich 2023) try to unlearn knowledge of the Harry Potter universe, and I’ve seen others unlearn Pokémon knowledge.
One tractability benefit of fictional works is that they tend to be self-consistent worlds and rules with boundaries to the rest of the pertaining corpus, as opposed to e.g. general physics knowledge which is upstream of many other kinds of knowledge and may be hard to cleanly unlearn. Originally, I was skeptical that this is useful since some dangerous capabilities seem less cleanly skeptical, but it’s possible e.g. bioweapons knowledge is a pretty small cluster of knowledge and cleanly separable from the rest of expert biology knowledge. Additionally, fictional knowledge is (usually) not harmful, as opposed to e.g. building an unlearning benchmark on DIY chemical weapons manufacturing knowledge.
Does it seem sufficient to just build a very good benchmark with fictional knowledge to stimulate measurable unlearning progress? Or should we be trying to unlearn more general or realistic knowledge?
research project results provide a very strong signal among participants of potential for future alignment research
Normal caveat that Evaluations (of new AI Safety researchers) can be noisy. I’d be especially hesitant to take bad results to mean low potential for future research. Good results are maybe more robustly a good signal, though also one can get lucky sometimes or carried by their collaborators.
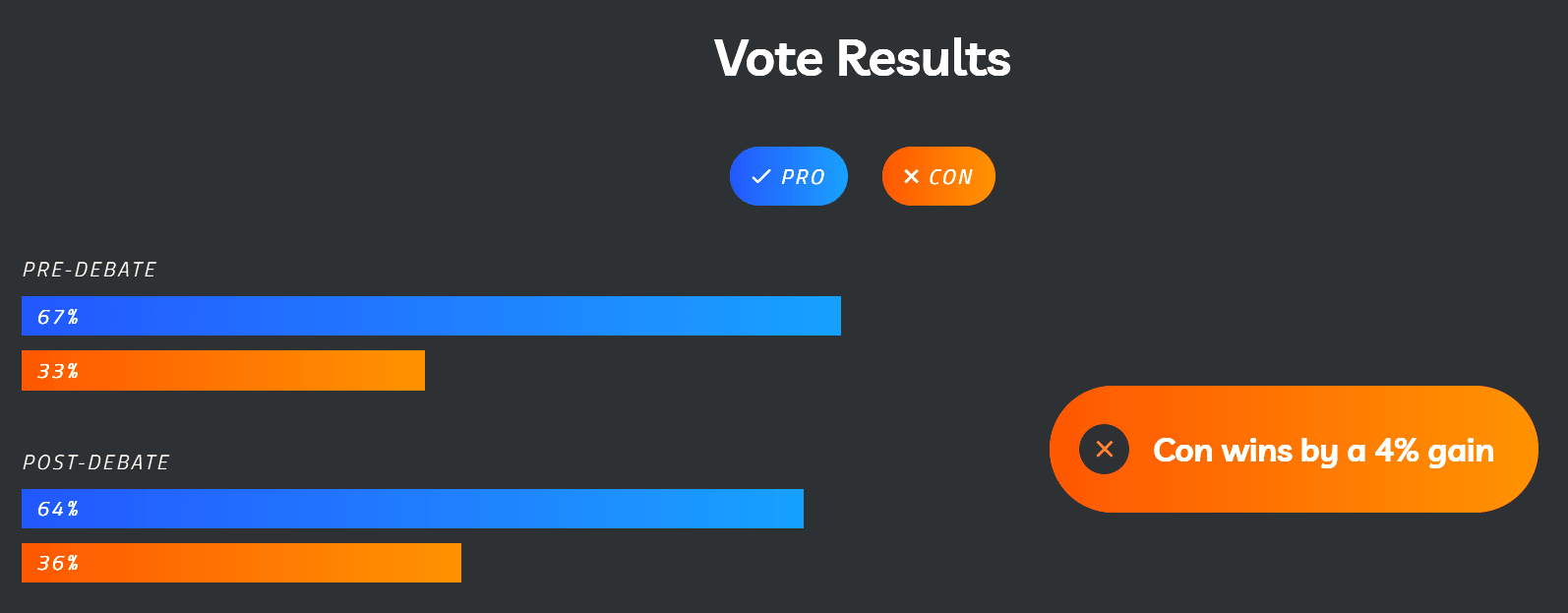
They’ve now updated the debate page with the tallied results:
Pre-debate: 67% Pro, 33% Con
Post-debate: 64% Pro, 36% Con
Con wins by a 4% gain (probably not 3% due to rounding)
So it seems that technically, yes, the Cons won the debate in terms of shifting the polling. However, the magnitude of the change is so small that I wonder if it’s within the margin of error (especially when accounting for voting failing at the end; attendees might not have followed up to vote via email), and this still reflects a large majority of attendees supporting the statement.
Despite 92% at the start saying they could change their minds, it seems to me like they largely didn’t as a result of this debate.
At first glance, I thought this was going to be a counter-argument to the “modern AI language models are like aliens who have just landed on Earth” comparison, then I remembered we’re in a weirder timeline where people are actually talking about literal aliens as well 🙃
1. These seem like quite reasonable things to push for, I’m overall glad Anthropic is furthering this “AI Accountability” angle.
2. A lot of the interventions they recommend here don’t exist/aren’t possible yet.
3. But the keyword is yet: If you have short timelines and think technical researchers may need to prioritize work with positive AI governance externalities, there are many high-level research directions to consider focusing on here.
Empower third party auditors that are… Flexible – able to conduct robust but lightweight assessments that catch threats without undermining US competitiveness.
4. This competitiveness bit seems like clearly-tacked on US government appeasement, it’s maybe a bad precedent to be putting loopholes into auditing based on national AI competitiveness, particularly if an international AI arms race accelerates.
Increase funding for interpretability research. Provide government grants and incentives for interpretability work at universities, nonprofits, and companies. This would allow meaningful work to be done on smaller models, enabling progress outside frontier labs.
5. Similarly, I’m not entirely certain if massive funding for interpretability work is the best idea. Anthropic’s probably somewhat biased here as an organization that really likes interpretability, but it seems possible that interpretability work could be hazardous (mostly by leading to insights that accelerate algorithmic progress that shortens timelines), especially if it’s published openly (which I imagine academia especially but also some of those other places would like to do).
What do you think about pausing between AGI and ASI to reap the benefits while limiting the risks and buying more time for safety research? Is this not viable due to economic pressures on whoever is closest to ASI to ignore internal governance, or were you just not conditioning on this case in your timelines and saying that an AGI actor could get to ASI quickly if they wanted?