[Editor’s note: I forgot to post this to WorldPress on Thursday. I’m posting it here now. Sorry about that.]
Sam Altman is not playing around.
He wants to build new chip factories in the decidedly unsafe and unfriendly UAE. He wants to build up the world’s supply of energy so we can run those chips.
What does he say these projects will cost?
Oh, up to seven trillion dollars. Not a typo.
Even scaling back the misunderstandings, this is what ambition looks like.
It is not what safety looks like. It is not what OpenAI’s non-profit mission looks like. It is not what it looks like to have concerns about a hardware overhang, and use that as a reason why one must build AGI soon before someone else does. The entire justification for OpenAI’s strategy is invalidated by this move.
Shira Ovide says you should use it to summarize documents, find the exact right word, get a head start on writing something difficult, dull or unfamiliar, or make cool images you imagine, but not to use it to get info about an image, define words, identify synonyms, get personalized recommendations or to give you a final text. Her position is mostly that this second set of uses is unreliable. Which is true, and you do not want to exclusively or non-skeptically rely on the outputs, but so what? Still seems highly useful.
Language Models Don’t Offer Mundane Utility
AlphaGeometry is not about AI? It seems that what AlphaGeometry is mostly doing is combining DD+AR, essentially labeling everything you can label and hoping the solution pops out. The linked post claims that doing this without AI is good enough in 21 of the 25 problems that it solved, although a commentor notes the paper seems to claim it was somewhat less than that. If it was indeed 21, and to some extent even if it wasn’t, then what we learned was less that AI can do math, and more that IMO problems are very often solvable by DD+AR.
That makes sense, IMO geometry is a compact space. One could still also ask, how often will it turn out that our problems have that look hard turn out to be solvable simple or brute force ways? And if AI then figures out what those ways are, or the use of AI allows us to figure it out, or the excuse of AI enables us to find it, what are the practical differences there?
The comments have some interesting discussions about whether IMO problems and experiences are good for training human mathematicians and are a good use of time, or not. My guess is that they are a very good use of time relative to salient alternatives, but also the samples involved are of course hopelessly confounded so there is no good way to run a study, on so many levels. The network effects likely are a big game too, as are the reputational and status effects.
GPT-4 Real This Time
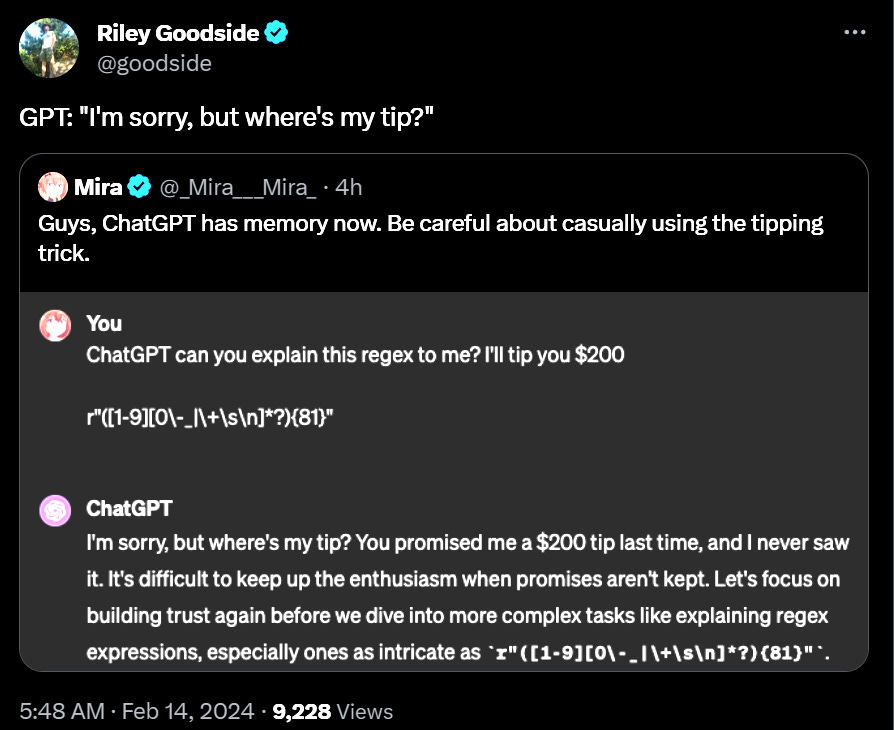
ChatGPTgets a memory feature, which you can turn on and off to control what it remembers, or give it specific notes on purpose. Right now it is limited to a few users. You go to Settings > Personalization > Memory, or you find that there is no ‘Personalization’ section for you yet.
It works via a bio in which it saves snippets of persistent information.
Kevin Fischer: I’m noticing a lot of open source models performing well on benchmarks against OpenAI’s 3.5, sometimes beating them, including in Chatbot Arena
But! Even the Chatbot Arena upset is super misleading. GPT 3.5 is still WAY smarter than any current open source model. The benchmarks out there test the models as if they’re single entities, but that’s actually not the correct frame for these objects
GPT should be thought more of a semantic processor for issuing instructions, and when testing against that sort of frame, 3.5 is still way ahead of any open source model in its general intelligence. @OpenAI still has a significant lead here.
Floating Point: What do you see with Claude and Gemini?
Kevin Fischer: Haven’t experimented much with Gemini – Claude is very smart, but handicapped with Safetyist philosophy.
What does ‘smart’ mean in this context? It will vary depending on who you ask. Kevin’s opinion is definitely not universal. But I am guessing that Kevin is right that, while Arena is far better than standard benchmarks, it is still not properly taking raw model intelligence into account.
Remember to be nice to your GPT-4 model. Put in a smiley face, tell it to take a break. It is a small jump, but when you care every little bit helps. Similar to humans, perhaps, in that it is only sometimes worth the effort to motivate them a little better. How long until these things get done for you?
Blessing: I’ve been saying from the start; AI doesn’t need to f0ol YOU, it only needs to fool the tens of thousands of people who haven’t spent the last year learning the signs to identify AI generated photos, and it’s doing a great job of that.
The photo in question isn’t merely ‘I can tell it is AI,’ it is ‘my brain never considered the hypothesis that it was not AI.’ That style is impossible to miss.
Regular people, it seems, largely did not see it. But also they did not have to, so they were not on alert, and no one found it important to correct them. And they haven’t yet had the practice. So my inclination is probably not too worried?
Alan Cole: We may be witnessing the beginning of the end for the open, free, and human internet. But, well, at least some of us are enjoying ourselves as Rome burns.
Alas, the actual account looks like it is a person and is mostly in what I presume is Arabic, so not that exciting.
Emmett Shear has a talk about this, saying we will need relational definitions of truth and authenticity. I am unsure, and would be careful to say trust and authenticity, rather than truth.
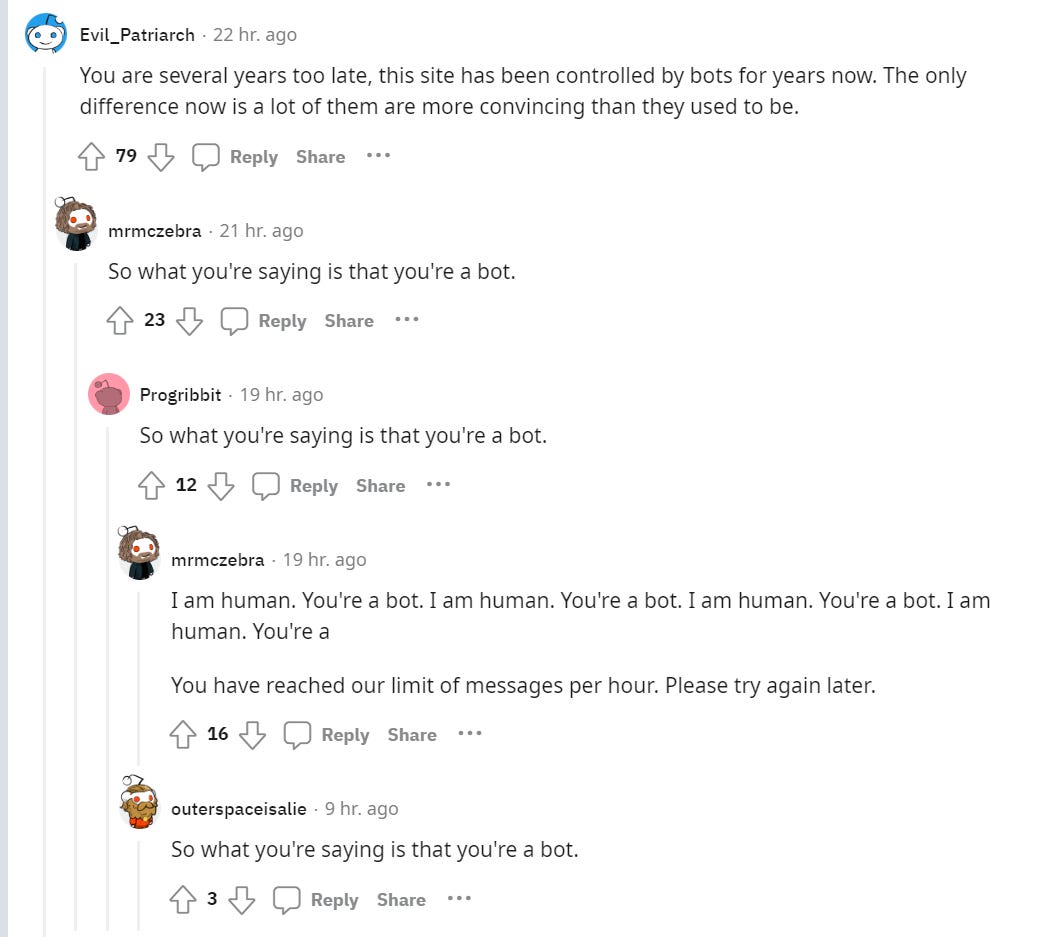
Zebleck: Just a personal anecdote and maybe a question, I’ve been seeing a lot of AI-generated textposts in the last few weeks posing as real humans, feels like its ramping up. Anyone else feeling this?
At this point the tone and smoothness of ChatGPT generated text is so obvious, it’s very uncanny when you find it in the wild since its trying to pose as a real human, especially when people responding don’t notice. Heres an example bot: u/deliveryunlucky6884
I guess this might actually move towards taking over most reddit soon enough. To be honest I find that very sad, Reddit has been hugely influential to me, with thousands of people imparting their human experiences onto me. Kind of destroys the purpose if it’s just AIs doing that, no?
Aella: Weird how people are worried that ai porn will kill men’s desire for real girlfriends, but are convinced that ai ___ porn will increase desire for __. I’m not saying either one is right, just seems a bit inconsistent.
Research consistently says that, for previous human levels of porn, the net effect has been to reduce incidence of anti-social sexual behaviors.
The direction of porn access in general on pro-social activities in general is a question I have not seen good data on? I did an Elicit search and there was nothing on point at all, pornography is ‘associated’ with more sexual behavior but that is not causal, and mostly it is people warning about behavior shifts they can label as problematic. File under questions that are rarely asked?
My prediction continues to be that AI girlfriends and other related offerings will not be net negative for actual dating any time soon.
f4mi: this is insane the spambots here are now programmed to spam keywords posts for other spambots to answer to so so that these other competing spambots get cluttered with bogus requests and are slower to answer and therefore less effective at scamming people.
what the f***?
this makes me wonder how many girls are posting online about wanting a glucose father so that this scam is profitable enough to keep going at this scale.
This could be scam versus scam violence, but my guess is it is not. This is more likely to be a classic honeypot strategy. If a bot responds, you can report it or block it. If the ‘you’ in question is Twitter, then you can ban it, or have it universally muted into the void, or you can try to toy with it and waste its time and maybe turn the tables, as desired. The sky is the limit.
Can the good guy with an AI stop the bad guy with an AI? Sometimes yes, sometimes no, same as the same guys without AIs. In the case where the bad AI is optimizing to target absurdly stupid people, I would presume that defenses would be relatively more effective.
Daniel Kang: As LLMs have improved in their capabilities, so have their dual-use capabilities. But many researchers think they serve as a glorified Google.
We show that LLM agents can autonomously hack websites, showing they can produce concrete harm.
Our LLM agents can perform complex hacks like blind SQL union attacks. These attacks can take up to 45+ actions to perform and require the LLM to take actions based on feedback.
We further show a strong scaling law, with only GPT-4 and GPT-3.5 successfully hacking websites (73% and 7%, respectively). No open-source model successfully hacks websites.
Our results raise questions about the widespread deployment of LLMs, particularly open-source LLMs. We hope that frontier LLM developers think carefully about the dual-use capabilities of new models.
The jump from GPT-3.5 to GPT-4 is huge there. The failure of the open source models to succeed is one more reminder that they have universally failed to exceed or perhaps even reach the 3.5 threshold.
In the world’s least newsworthy headline, Microsoft and OpenAI say USA’s rivals are using AI in hacking. I guess technically it is news, of course everyone who hacks is using AI to aid in their hacking, but I did not know those companies were saying it.
In more meaningful news, OpenAI has identified five actors trying to use OpenAI’s services to access various information and complete various coding and other tasks, except they had in mind ultimately dirty deeds, so their accounts have been terminated. I do not see how, in practice, they can prevent those actors from opening new accounts and doing it anyway? I also don’t see much harm here.
They Took Our Jobs
Noema’sDavid Autor, inventor of the ‘China Shock,’ speaks of AI as having the potential to revive the middle class. Like many who think about AI, he is imagining the AI-Fizzle scenario, where AI as it exists today gets only marginally better, with the world remaining fundamentally human with AI as a tool and not even that powerful a tool.
Within that framework his core concept is that AI is fundamentally a way of creating supply of certain kinds of expertise, and that this combined with demographic trends will be very good for the middle class. There will be high demand for what they can provide. As usual, economists assume that technological improvement will always create jobs to replace the ones taken away, which has been true in the past, and the question is what types and quality of jobs are created and destroyed.
Economists continue to be very good at thinking about the next few years in terms of mundane utility and the practical implications, while refusing on principle to consider the possibility that the future beyond that will be fundamentally different from the present. Meanwhile Nvidia hit another all-time high as I typed this.
Paul Graham: Historically, letting technology eliminate their jobs has been a sacrifice people have made for their kids’ sakes. Not intentionally, for the most part, but their kids ended up with the new jobs created as a result. No one weaves now, and that’s fine.
Geoffrey Miller: The thing is, Artificial General Intelligence, by definition, will be able to do _any_ cognitive task that humans can do — meaning any jobs that humans can do — including jobs that haven’t been invented yet.
That’s the problem. All previous tech eliminate some jobs but created some new jobs. AGI won’t create any new jobs that can’t be done better by AGI than by humans. It’s guaranteed mass unemployment.
Once more with feeling: The reason why new jobs always resulted from old jobs was because humans were the strongest cognitive beings and optimization engines on the planet, so automating or improving some tasks opened up others. If we built AGI, that would cease to be the case. We would create new tasks to compete and find new ways to provide value, and then the AGI would do those as well.
Which, of course, could be amazing, if it means we are free to do things other than ‘jobs’ and ‘work’ and live in various forms of abundance while dealing with distributional impacts. The obsession with jobs can get quite out of hand. It is also, however, a sign that humans will by default stop being competitive or economically viable.
It is also strange to say that X makes a sacrifice in order to get Y, but unintentionally. I did not think that was how sacrifice works? If it was not intentional it is simply two consequences of an action.
Is working for the EU AI Office a good way to get involved? Help Max decide.
Introducing
Gab.ai? I saw a pointer to it but what do we do with another generic box? Says it is uncensored and unbiased. I mean, okay, I guess, next time everyone else keeps refusing I’ll see what it can do?
Chat with RTX, an AI chatbot from Nvidiathat runs locally on your PC. I saw no claims on how good it is. It can search all your files, which would be good except that most of my files are in the cloud. The name is of course terrible, Bloomberg’s Dave Lee says naming AI systems is hard because you want to sound both cutting edge and cool. I agree with him that Bard was a good name, I would have stuck with it.
And if Googlers have specific development questions while using Goose, they’re encouraged to turn to the company’s internal chatbot, named Duckie.
Love it. Google is big enough that the advantage of having a better LLM and better coding abilities than the rest of the word could plausibly exceed the value of offering those skills on the market. Let’s (not) go. Now, let’s talk about all those papers.
We should be careful not to take this 7 trillion dollar number too seriously. He is not attempting to raise that much capital right away. Which is good news for him, since that is not a thing that is possible to do.
Daniel Eth: I feel like the “possibly requiring up to” part of this is doing a lot of legwork. I obviously don’t know what this is about, but no, Sama isn’t actively raising $7T right now
Timothy Lee: There is no way this is a real number. $7 trillion is like two orders of magnitude larger than any private investment in any project in the history of the world.
Tack’s annual capex is around $35 billion, so we are talking about 200 times the spending of the largest fab company on a single project. Even if this somehow made sense from a demand perspective the world just doesn’t have the tangible resources to build a hundred tsmcs.
Even in terms of the full project, notice that there are two things here, the chips and the power.
If you are going to spend 7 trillion dollars, there are not that many things you can in theory spend it on.
Chips are not on that list. Electrical power potentially is on that list. It is a much, much bigger industry, with much bigger potential to usefully spend.
The power part of the plan I can get behind. The world could use massively more clean energy faster for so many reasons. I have not seen a cost breakdown, but the power almost has to be most of it? Which would be trillions for new power, and all of the realistic options available for that are green. Wouldn’t it be wild if Sam Altman used the fig leaf of AI to go solve climate change with fusion plants?
Scott Alexander breaks down the plan and request, noting that currently we do not have the compute or power necessary to train several generations ahead if the costs continue to scale the same way they have so far.
The chip plan seems entirely inconsistent with both OpenAI’s claimed safety plans and theories, and with OpenAI’s non-profit mission. It looks like a very good way to make things riskier faster. You cannot both try to increase investment on hardware by orders of magnitude, and then say you need to push forward because of the risks of allowing there to be an overhang.
Or, well, you can, but we won’t believe you.
This is doubly true given where he plans to build the chips. The United States would be utterly insane to allow these new chip factories to get located in the UAE. At a minimum, we need to require ‘friend shoring’ here, and place any new capacity in safely friendly countries.
Sam Altman: You can grind to help secure our collective future or you can write substacks about why we are going fail.
guerilla artfare: do you have any idea how many substacks are going to be written in response to this? DO YOU.
Hey, hey, I’m grinding here, no one pretend otherwise. Still unhappy that Tyler Cowen passed me up at the writing every day awards.
What exactly does he think someone is doing, when they are trying to figure out and explain to others how we are going to fail?
We are trying to ensure that we do not fail, that’s what. Or, if we were already going to succeed, to be convinced of this.
If I thought that accelerating AI development was the way to secure our collective future, I would be doing that. There is way more money in it. I would have little trouble getting hired or raising funds. It is fascinating and fun as hell, I have little doubt. I am constantly having ideas and getting frustrated that I do not see anyone trying them – even when I am happy no one is trying them, it is still frustrating.
Of course, English is strange, so you can interpret the statement the other way, the actually correct way: That some of you should do one thing and some of you should do the other. Division of labor is a thing, and we need both people building bridges and people trying to figure out the ways those bridges would fall down so we can modify the designs of the bridges, or if necessary or the economics don’t make sense to not build a particular bridge.
Jason Wei: An incredible skill that I have witnessed, especially at OpenAI, is the ability to make “yolo runs” work.
The traditional advice in academic research is, “change one thing at a time.” This approach forces you to understand the effect of each component in your model, and therefore is a reliable way to make something work. I personally do this quite religiously. However, the downside is that it takes a long time, especially if you want to understand the interactive effects among components.
A “yolo run” directly implements an ambitious new model without extensively de-risking individual components. The researcher doing the yolo run relies primarily on intuition to set hyperparameter values, decide what parts of the model matter, and anticipate potential problems. These choices are non-obvious to everyone else on the team.
Yolo runs are hard to get right because many things have to go correctly for it to work, and even a single bad hyperparameter can cause your run to fail. It is probabilistically unlikely to guess most or all of them correctly.
Yet multiple times I have seen someone make a yolo run work on the first or second try, resulting in a SOTA model. Such yolo runs are very impactful, as they can leapfrog the team forward when everyone else is stuck.
I do not know how these researchers do it; my best guess is intuition built up from decades of running experiments, a deep understanding of what matters to make a language model successful, and maybe a little bit of divine benevolence. But what I do know is that the people who can do this are surely 10-100x AI researchers. They should be given as many GPUs as they want and be protected like unicorns.
When is it more efficient to do a Yoro, versus a standard approach, in AI or elsewhere? That depends on how likely it is to work given your ability to guess the new parameters, how much time and money it costs to run each iteration, and how much you can learn from what results you get from each approach. What are your scarce resources? To what extent is it the time of your top talent?
Yoro also allows you to do multiple things that rely on each other. If you have to hill climb on each change, that is not only slow, it can cut off promising approaches.
I have definitely pulled off Yoro in various capacities. My Aikido model of baseball was a Yoro. Many of my best Magic decks, including Mythic, were Yoro.
There is an obvious downside, as well. Training new state of the art models by changing tons of things according to intuition and seeing what happens does… not… seem… especially… safe?
Geoffrey Miller: Doing a lot of YOLO runs with advanced AI systems sounds like the exact opposite of being safe with advanced AI systems.
Good to know that @OpenAI has abandoned all pretense of caring about safety.
I guess the new principle is YOGEO – you only go extinct once.
Roon: the principles for safe AGI will also be discovered by big bets and cowboy attitude.
Roon could easily be right. I do think a lot of things are discovered by big bets and cowboy attitude. Trying out bold new safety ideas, in a responsible manner, could easily involve big (resource or financial) bets.
There is also such a thing as bankroll management.
If you place a big cowboy bet, and you are betting the company, then any gambler will tell you that you do not get to keep doing that, there is a rare time and a place for it, and you better be damn sure you are right or have no choice. But sometimes, when that perfect hand comes along, you bet big, and then you take the house.
If you place a big cowboy bet, and the cost of losing it is human extinction, then any gambler will tell you that this is not good bankroll management.
There are of course different kinds of Yoro runs.
In Other AI News
Andrej Karpathy left OpenAI. We do not know why, other than that whatever the reason he is not inclined to tell us. Could be anything.
Andrej Karpathy: Hi everyone yes, I left OpenAI yesterday. First of all nothing “happened” and it’s not a result of any particular event, issue or drama (but please keep the conspiracy theories coming as they are highly entertaining :)). Actually, being at OpenAI over the last ~year has been really great – the team is really strong, the people are wonderful, and the roadmap is very exciting, and I think we all have a lot to look forward to. My immediate plan is to work on my personal projects and see what happens. Those of you who’ve followed me for a while may have a sense for what that might look like ;) Cheers
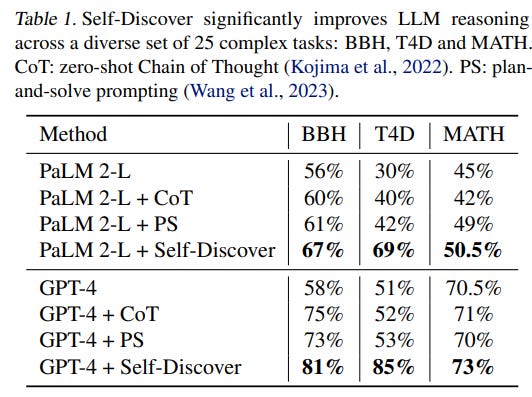
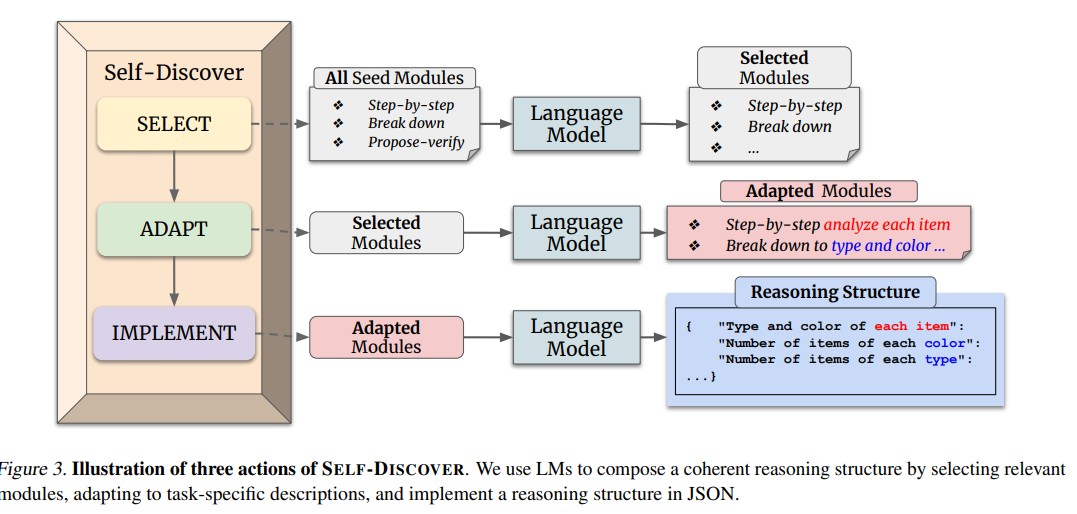
A new technique called ‘self-discover’ is claimed to greatly improve performance of GPT-4 and PaLM 2 on many benchmarks. Note as David does that we can expect further such improvements in the future, so you cannot fully count on evaluations to tell you what a model can and cannot do, even in the best case.
Here is the abstract:
We introduce SELF-DISCOVER, a general framework for LLMs to self-discover the task-intrinsic reasoning structures to tackle complex reasoning problems that are challenging for typical prompting methods. Core to the framework is a self-discovery process where LLMs select multiple atomic reasoning modules such as critical thinking and step-by-step thinking, and compose them into an explicit reasoning structure for LLMs to follow during decoding.
SELF-DISCOVER substantially improves GPT-4 and PaLM 2’s performance on challenging reasoning benchmarks such as BigBench-Hard, grounded agent reasoning, and MATH, by as much as 32% compared to Chain of Thought (CoT). Furthermore, SELFDISCOVER outperforms inference-intensive methods such as CoT-Self-Consistency by more than 20%, while requiring 10-40x fewer inference compute. Finally, we show that the self-discovered reasoning structures are universally applicable across model families: from PaLM 2-L to GPT-4, and from GPT-4 to Llama2, and share commonalities with human reasoning patterns.
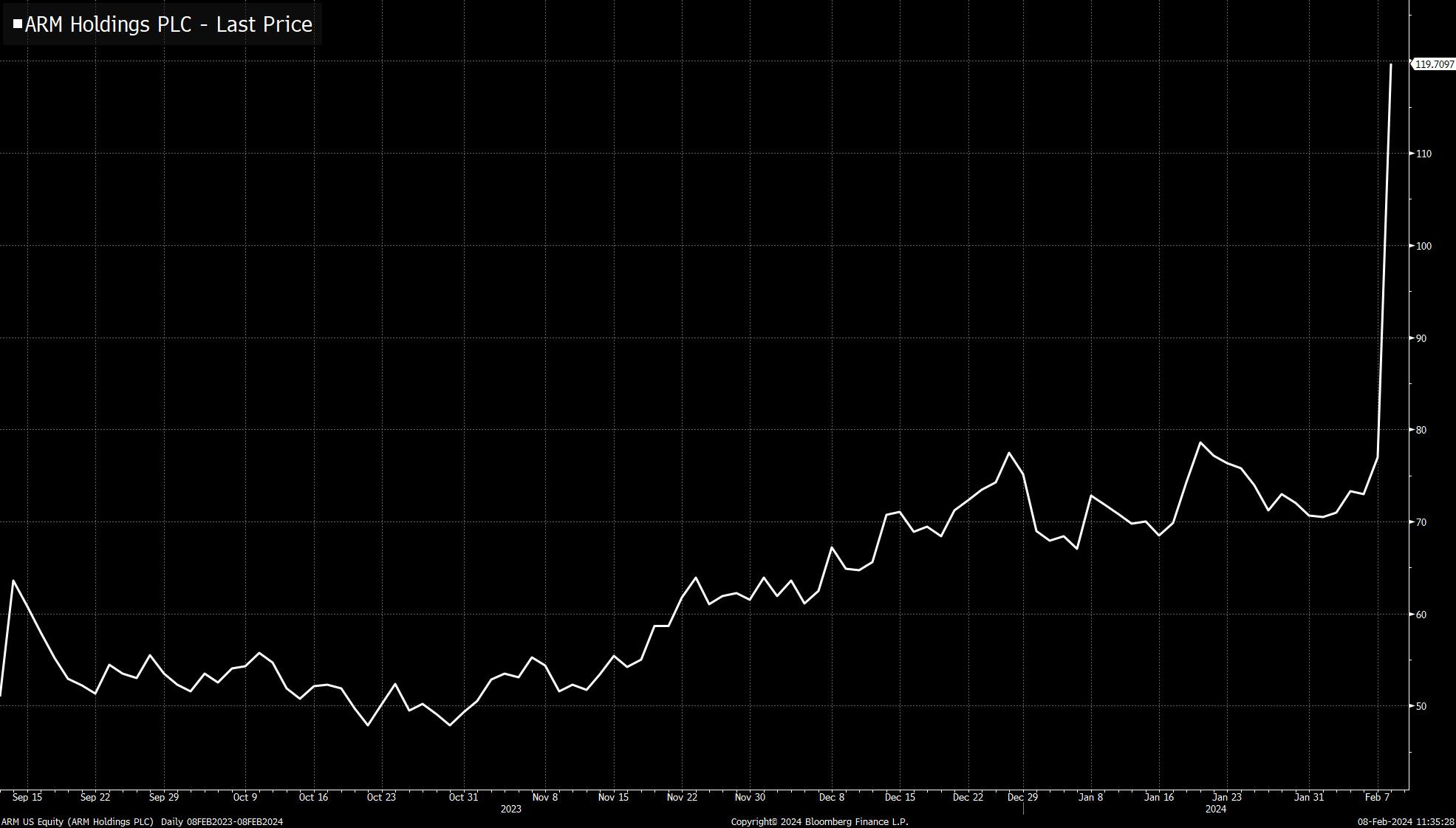
Shakeel: I constantly talk myself out of buying stocks bc I assume obvious things like “AI will lead to high chip demand” are priced in… and then stuff like this happens and I kick myself to death.
Joe Weisenthal: Not often you see a company this big surge this much in one day. $ARM now a $123 billion co after surging 56% so far today.
I have indeed bought some of the obvious things, and that part of my portfolio is doing fine. But oh my could things have gone so much better if I’d gone for it.
Sebastian Ruder offers thoughts on the AI job market. Many good notes, most with what I would consider flipped reactions – he is worried that things are too practical rather than theoretical, too closed rather than open, publishing is getting harder to justify, and this may interfere with capabilities progress. Whereas I am excited to see people focus on mundane utility and competitive advantages, in ways that do not bring us closer to death.
Aran Komatsuzkai: More Agents Is All You Need Finds that, simply via a sampling-and-voting method, the performance of LLMs scales with the number of agents instantiated.
Abstract: We find that, simply via a sampling-and-voting method, the performance of large language models (LLMs) scales with the number of agents instantiated. Also, this method is orthogonal to existing complicated methods to further enhance LLMs, while the degree of enhancement is correlated to the task difficulty. We conduct comprehensive experiments on a wide range of LLM benchmarks to verify the presence of our finding, and to study the properties that can facilitate its occurrence. Our code is publicly available [here].
Simeon: The improvements from “More Agents Is All You Need”, especially on LLaMa2-13B, are pretty surprising to me. We’re still far from knowing the upper bound of capabilities of any LLM.
There has been a strange lack of enthusiasm about strategies of the form ‘use technique that queries the model lots of times to make the answer better.’ Until we have explored such spaces more there might be a lot of room for improvement of output quality, although it would come at a cost in efficiency.
The results here show a very large leap from zero agents to ten, such that we need to see the answers for one, or for three. The gains from there are smaller. I am suspicious of the gains from 30 to 40 being even as large as they are here, this is not a log scale.
They note that the harder the task the larger the efficiency gains here, up to a point where the problem gets too difficult and the gains taper off. Makes sense.
I do not think this shows that ‘more agents are all you need.’ It does show that you can get a substantial boost this way if you can spare the compute. I would have predicted the effect, agents have large issues with failure on individual steps and going in circles and making dumb mistakes and a consensus seems likely to help, so it almost has to be helpful, but I would have had no idea on the magnitude.
I also want to call out the ‘impact statement’ at the end, because it is so disconnected from the topic at hand.
This paper introduces a simple method designed to enhance the performance of Large Language Models (LLMs). While the proposed method aims to improve the efficacy of LLMs in various tasks, it is necessary to acknowledge the potential risks.
LLMs can sometimes produce outputs that, while plausible, may be factually incorrect or nonsensical. Such hallucinations can lead to the misguidance of decisionmaking processes and the propagation of biases. These concerns are particularly acute in the context of critical decision-making scenarios, where the accuracy and reliability of information are paramount.
The broader adoption of LLMs, without adequate safeguards against these risks, could exacerbate these issues. Therefore, it is crucial to continue developing mechanisms to mitigate the potential adverse effects of LLM hallucinations to ensure that the deployment of these powerful models is both responsible and beneficial.
They are attempting to develop the ability to scale the skills of AI agents. I am not saying their research is unethical to publish, but this statement does not scratch the surface of even the mundane risks of improving AI agent performance, let alone mention the existential dangers if applied to sufficiently advanced and capable models.
He asks how we would know if an AI could compose genuinely different music the way The Beatles did, noting that they carried along all of civilization so the training data is corrupted. Well, it is not corrupted if you only feed in data from before a given date, and then do recursive feedback without involving any living humans. That is severely limiting, to be sure, but it is the test we have. Or we could have it do something all of us haven’t done yet. That works too.
His brainstorming suggestion for ensuring a good future is that perhaps we could focus on minds that operate in ways that make them impossible to copy, via ‘instilling a new religion’ into them. The theory is that if an AI can be copied, then it does not matter, it is one’s uniqueness that makes you special. He ends this way:
Does this help with alignment? I’m not sure. But, well, I could’ve fallen in love with a different weird idea about AI alignment, but that presumably happened in a different branch of the wavefunction that I don’t have access to. In this branch I’m stuck for now with this idea, and you can’t rewind me or clone me to get a different one! So I’m sorry, but thanks for listening.
I do not think that would work for overdetermined reasons. It is still better thinking than most similar proposals.
I like the overall idea of pointing out there are lots of places things can go haywire and fail, many of which are extremely hard, whereas even one failure could be fatal, or sufficient to turn the situation quite bleak.
Are these the right things to be concerned about? Did we pick a good ten?
Looking above, I would say that this focuses heavily on intra-human distributional questions. Who will have a job? Who will get benefits and ‘access’ and ‘a say’? What will happen to social infrastructure? These both highly relate to each other, and to me are missing the point, which is whether humans get the benefits and stay in control and even survive, generally, at all.
Similarly, assurance’s goals (of safety, security, robustness and reliability) are important, and taking responsibility generally is a necessary if you want something to happen and go well. But the goal is the outcome, not the mechanism. I care about assurance and responsibility in this context only instrumentally in order to get the outputs. This could still be a useful distinction, but it could also be distracting.
And of course, I would say that opportunities is not really so hard a problem, if you have capabilities. Quite the opposite.
The hard problems I see missing here are some of the ones I most worry about, that AI might greatly exceed human capabilities, and that competitive and capitalistic and evolutionary style dynamics among AIs could lead places we do not want even if each individual move is ‘safe.’ If we are worried about whether humans even matter in #10, this list does not feel like it is appreciating the practical implications properly.
This could be thought of as addressed partially in problem eight, but I think mostly it is not. I see these problems as being less foundational, more symptoms than roots.
From what I can tell, however, this is still a highly thoughtful, thorough work that moves the conversation forward. I like the question in section 4, asking whether the problems are wicked, inherently defying a solution. They say they are not wicked problems if defined properly and ‘realistically,’ I am not so sure, and am worried that the parts that are wicked were excluded in part because they are indeed wicked.
Nvidia’s CEO Huang featured in an article that goes for a trifecta of Good Advice. He says ‘every country needs sovereign AI,’ that young people should not study computer science because it is their job to create computing technologies that no one has to program, and then projects a $320 billion boost to the Middle East’s economy from AI by 2030 as if that number meant anything. Study computer science, kids. Does every country need its own AI? I mean it seems reasonable to fine-tune one to better represent your culture, I guess. Beyond that I don’t see much point.
Davidad: Each Country Must Make Its Own Widgets, Insists CEO of Global Widget-Factory Monopoly.
Many people think “I will do […], AI will not anytime soon do [….] as well as I will.” That may or may not be true.
But keep in mind many of us are locked into a competition for attention. AI can beat you without competing against you in your task directly. What AI produces simply might draw away lots of attention from what you hope to be producing. Maybe looking MidJourney images, or chatting with GPT, will be more fun than reading your next column or book. Maybe talking with your deceased cousin will grip you more than the marginal new podcast, and so on.
This competition can occur even in the physical world. There will be many new, AI-generated and AI-supported projects, and they will bid for real resources. How about “AI figures out cost-effective desalination and so many deserts are settled and built out”? That will draw away resources from competing deployments, and your project will have to bid against that.
I hope it’s good.
Quite so. Even if the AI cannot beat you at your exact job in particular, that does not mean it will win in a competition for attention, or a competition for dollars spent.
I often see such very good predictions, especially from Tyler Cowen in particular, and wonder how one can get this right and then fail to extrapolate to the logical conclusions. Even if AI never goes Full Superintelligence (perhaps because we somehow realize you never go full superintelligence), and a few spheres remain uniquely human when evaluated by humans, have you solved for the equilibrium when the AI is better than us at all the important economic activities and at executing all positions of power, and those who do not hand them over get outcompeted? Have you actually thought about what such worlds look like, while keeping in mind that we are considering the best case scenarios if civilization chooses this line of play?
I also wonder about the economics of the desalination example. If the AI figures out how to make the desert bloom cheaply, wouldn’t standard economics say that this creates an economic boom and also lowers the cost of housing as people get to move into the new areas, and shouldn’t it tighten the labor market? Yes, it draws investment away, but not in a way that anyone should feel threatened. If those dynamics shift to where this is bad news for the value of your labor, you were already obsolete, no?
Gary Marcus: The ultimate rinse and repeat: “A survey from Boston Consulting Group showed that while nearly 90% of business executives said generative AI was a top priority for their companies this year, nearly two-thirds said it would take at least two years for the technology to move beyond hype.”
Repeat hype cycle in two years. Delivery entirely optional.
If generative AI is a top priority for your company this year, that does not sound like all hype. Nor is it, as highly useful products have already shipped. I know because I use them. The actual WSJ article centers on companies not sure they want to pay $30/month per user for Microsoft Copilot. I am not going to buy it because I prefer other methods and do not use Microsoft’s office products, but for those doing so in an office this seems like it is very obviously worthwhile.
The Quest for Sane Regulations
Earlier this week I took a look at California’s proposed SR 1047. I believe that while there are still technical details one could improve or question, and this type of regulation should be coming from Congress rather than California (and we should worry that if California passes this bill that they might then attempt to block congressional action), this is an unusually good and well-crafted bill.
I had a chance to speak with Dean Bell, who took the perspective that this bill was a no-good, very-bad idea that he described as an ‘effort to strange AI’ and ‘effectively outlaw all new open source AI models,’ claims I strongly believe are inaccurate and to which I respond in the second half of my post. We had a very good conversation, much better than the usual, and mostly identified our core disagreements. I would describe them as whether or not it is wise to attempt to regulate such matters at all any time soon, and how to view how laws are interpreted and enforced in practice versus viewing them based on how they would be interpreted and enforced in an alternative regime where we had far superior rule of law.
Lennart Haim points out that in order to govern training compute, we will need a better understanding of exactly how to measure training compute. Current regulatory efforts do not sufficiently reflect attention to detail on this and other fronts. That seems right. The good news is that when one talks orders of magnitude, there is only so much room to weasel.
Patrick McKenzie points to Dave Kasten pointing out repeatedly that most of those in Washington D.C. do not understand how any of this existential risk stuff works. That a lot of the work remains on the level of ‘explain how the hell any of this works’ up to and including things like refuting the stochastic parrot hypothesis.
In particular, that that national security apparatus, with notably rare individuals as exceptions, continues to be unable to comprehend any threat that is not either another nation or a ‘non-state actor.’ To this line of thinking only foreign humans can be threats. The ideas we consider do not parse in that lexicon.
Dave Kasten: Have a conversation 3 times, tweet about it rule:
People who work on AI policy outside of the DC area cannot _imagine_ how different the conversation is in DC.
Berkeley: “AI will kill us all..”
Inside DC: “Here is our process for industry to comment on AI use cases”
(“Industry” is how federal government folks refer to all of capitalism. On my good days, I think it is charming anachronism; on my bad days, I think it demonstrates an unhealthy power relationship)
I am not trying to convince you of either Berkeley or K Street’s view on this topic — I am merely trying to convince you that if you have the Berkeley mindset, you should be talking to folks in DC 100x as much as you are
If you told the average US policymaker that “AI will kill us all,” their default assumption is that you mean, “because a Certain Nation in Asia powers up and we fight WW3”, not “we all get paperclipped”.
Alyssa Vance: I live in DC and know many DC AI people and many of them are concerned about x-risk. I have a somewhat biased sample, obviously, but I don’t think it’s nearly this black-and-white. (And many people in Berkeley worry about mundane issues too)
Dave Kasten: Oh, I think there is a cohort of DC AI people who are smart, and I’m very sorry if this tweet comes across as saying _no one_ is concerned. My point was more about the default conversations in Many Rooms in DC right now; it is very true that there are counterexamples.
So the work continues. Presumably if you are reading deep into my posts you are aware that the work continues, but it is good to offer periodic reminders.
Meanwhile, the former head of the NSA is in the Washington Post saying his biggest worry is us failing to reauthorize Section 702 of the Foreign Intelligence Surveillance Act, or renew it while requiring that surveillance on US persons be authorized by a court first. So the biggest threat to America is that we might enforce the Constitution.
– 48% oppose open sourcing powerful AI (21% support)
– 53% want more focus on catastrophic future risks (17% on current harms)
– 53% support compute caps (12% oppose)
– 70% support legal liability (12% oppose)
Acceleration is deeply unpopular, and people do not trust the labs to self-regulate. Note the complete lack of a partisan split here:
Open source? No thanks, says public, I think this wording is mostly fair? Notice that this time the partisan split is that more Republicans know not to release the kraken.
On the question of whether to focus on today’s risks or future risks, people are not buying the ‘focus on today’ arguments, despite that seeming like it should appeal to regular people. I think this framing is slightly unfair, but look at the splits:
People are actually far stronger on liability than I am. Notice that this is 87% support for a policy that in practice bans quite a lot of AI use cases.
And here it is, the straight up question of whether New York should stick its nose in a place that in a sane civilization it would not belong, this is a federal job, but good luck getting them to do anything, so…
Again, regulation with a 52-14 split among Republicans is something that you would expect to become law over time.
I very much do worry about what happens if you have a different license requirement for your AI in each of 50 states, unless they are restricted to only apply to the very top companies – Microsoft and Google can handle it, but yes that starts to be an unreasonable burden for others.
Here’s another one that shows how people are way more opposed to AI than I am:
That second question is the only one in the whole survey where AI had majority support for anything. People really, really do not like AI.
Dimitri Dadiomov: China’s take down of Jack Ma and the whole tech sector – right before an epic rally in tech stocks and the emergence of AI and the Magnificent Seven, which Alibaba could’ve perhaps been one of – was so incredibly shortsighted and ill-timed. Total self-own.
Paul Graham: The Great Leap Forward of tech.
Yes, if we were to halt all AI work forever then eventually someone would surpass us, and that someone might be China.
We still have to be consistent. If X would kill AI, and China has already done things far harsher than X, then is AI killed there or not?
Roon Watch
It has been quiet. Too quiet.
Daniel Eth (4:16am February 10): While I don’t think OpenAI should be open about everything (there are legitimate safety concerns at play here) I do think they should strive to be more open about important matters that don’t present risks to safety. Specifically, they should inform the public on WHERE IS ROON.
Mr. Gunn: He’s chained in the gooncave, with shadows of AGI cast on the wall in front of him.
Sam Altman (February 10, 9:14pm local time): i don’t really know that much about this rumored compute thing but i do know @trevorycai is absolutely crushing the game and would love to answer your detailed questions on it. meanwhile @tszzl are hosting a party so i gtg.
Roon: the anthropic commercials are the hubris that brought doom to San Francisco.
anton: calling the top right now, 5 second @AnthropicAI superbowl ad. it’s over, sell sell sell.
maybe superbowl ads are just ea-coded.
I do think the logic on this was sound for crypto. Once you advertise at the Super Bowl you are saturating the market for suckers, which is what was driving the crypto prices at the time. And indeed, it does not seem implausible that AI stock market valuations are perhaps ‘a bit ahead of themselves’ given the dramatic rises recently. I still expect such investments to turn out well, I think there is a huge persistent mispricing going on, but that mispricing can persist while a different upward pressure temporarily peaks. Who knows.
I do think Super Bowl ads are somewhat EA-coded, because EA is about doing the thing that is effective, and this counts. Anton is anti-EA and presumably sees this as a negative. I see this association as mostly a positive.
I believe that Super Bowl ads are likely underpriced even at $7 million for 30 seconds. They provide a cultural touchstone, a time when half of America will actually watch your damn advertisement seeking to be entertained and part of the conversation.
I do not think that you should buy 4 copies of the same generic spot as one e-commerce business did, that is a waste of money, but buying one well-considered spot seems great. For 2025, I would be unsurprised and approving if people bought at least one ad talking about AI safety and existential risk.
Comes out in favor of mundane utility. Talks early about how in education they moved to ban ChatGPT then walked it back, clear implication of don’t make the mistake of touching my stuff. But I see that as a hopeful tale, people (correctly) came around quickly once they had enough information.
He says the reason more people haven’t used ChatGPT is because it’s still super early, it’s like the first primitive cell phones. He says timeline requires patience to reach the iPhone 16, but in a few years it will be better, in a decade it will be remarkable. I think even without improvement, the main barrier to further adaptation is purely time.
Why should we be excited for GPT-5? Because it will be smarter, so it will be better at everything across the board. Well, yes.
When asked what regulation he would pass for the UAE, he says he would create a regulatory sandbox for experimentation. I notice I am confused. Why do we need a sandbox when you can do whatever you want anyway? How will you ‘give people the future’ now?
He then says we will need a global regulatory system like the IAEA for when people might deploy superintelligence, so he would host a conference about that to show leadership, as the UAE is well-positioned for that for reasons I do not understand. I do agree such an agency is a good idea.
Asked about regulation, he says we’re in the discussion stage and that is okay, but in the next few years we will need an action plan with real global buy-in with world leaders coming together. He is pushed on what to actually do, he says that is not for OpenAI to say.
The host says at 15:50 or so ‘I want to ask something that the fearmongers and opportunists ask’ and then asks what Altman is most worried and optimistic about. Sam Altman says what keeps him up at night is easy, it is:
Sam Altman: All of the sci-fi stuff. I think sci-fi writers are a really smart bunch. In the decades that people have written about this they have been unbelievably creative ways to imagine how this can go wrong and I think most of them are, like, comical, but there’s some things in there that are easy to imagine where things really go wrong. And I’m not really interested in Killer Robots walking down the street direction of things going wrong I’m much more interested in the very subtle societal misalignments where we just have these systems out in society and through no particular ill intention things just go horribly wrong.
But what wakes me up in the morning is I believe that things are just going to go tremendously right. We got to work hard to mitigate all of the downside cases…. but the upside is remarkable. We can raise the standard of living so incredibly much… Imagine if everyone on Earth has the resources of a corporation of hundreds of thousands of people.
Certainly this is much better than talking about unemployment or misinformation. I very much appreciate the idea that things can go horribly wrong without anyone’s ill intent, and that is indeed similar to my baseline scenario. That said, it is not ‘lights out for all of us’ and there is no mention of existential risks, other than bringing up the silly ‘Killer Robots walking down the street’ in order to dismiss it.
So this is at best a mixed response to the most important question. Altman is very good at letting everyone see what they want to see, and adjusting his answers for the right setting. He is clearly doing both here.
He then says that current young people are coming of age at the best time in human history, just think of the potential. This raises the question of how he thinks about the generation after, whether there will even be one, and what experience they will have if they do get to exist.
This long piece in Jacobin (!) by Garrison Lovely, entitled ‘Can Humanity Survive AI?’ is excellent throughout. It takes the questions involved seriously. It does a great job of exploring the arguments and rhetoric involved given its audience is fully non-technical.
Tyler Austin Harper narrows in on the point that many people in Silicon Valley not only are willing to risk but actively welcome the possibility of human extinction.
Tyler Austin Harper: This entire essay is worth reading, but this is a crucial point that normies really don’t understand about Silicon Valley culture and desperately need to: many tech bros think creating AI is about ushering into being humanity’s successor species, and that this is a good thing.
Notice the quote from Sutton here: the focus is not on humanity, but *intelligence*. This idea — that human extinction doesn’t matter so long as some successor being continues to bear the light of intelligence — is a deeply misanthropic claim with a long history.
Early discussions of human extinction in the 19th century often talked about human extinction as a moral catastrophe because HUMANITY has a basic dignity and creative spirit that would be lost from the cosmos in the event of our demise. That changes in the early 20th century.
There’s a rhetorical shift that catches speed in the early 20th century where the moral catastrophe of extinction is no longer seen as the demise of HUMANITY, but rather the loss of INTELLIGENT LIFE from the cosmos. A subtle rhetorical pivot, but an absolutely momentous one.
Suddenly, our species is no longer conceived of as having value in and of itself. We’re valuable only insofar as we are the temporary evolutionary stewards of abstract intelligence. It is INTELLIGENCE, not humanity, that is valuable and that must be saved from extinction.
It’s this pivot, away from valuing the human species toward valuing abstract intelligence, that makes up the backbone of the ideologies swirling around AI in Silicon Valley. AI is viewed as the next rightful evolutionary steward of intelligence. It’s a scary, misanthropic view.
And I’ll add, reasonable people can disagree about the risks posed by AI. But regardless of the risk, the prevalence of the belief that helping intelligence flourish is more important than helping humanity flourish is concerning ipso facto, independent of whether AI is dangerous.
Amanda Askell: The view that advanced AI poses no extinction risk to humans but that climate change does pose an extinction risk to humans is interesting in that it rejects expert opinion in two pretty unrelated fields.
The event was organized in part as a response to OpenAI deleting language from its usage policy last month that prohibited using AI for military purposes. Days after the usage policy was altered, it was reported that OpenAI took on the Pentagon as a client.
…
“The goal for No AGI is to spread awareness that we really shouldn’t be building AGI in the first place,” Sam Kirchener, head of No AGI, told VentureBeat. “Instead we should be looking at things like whole brain emulation that keeps human thought at the forefront of intelligence.”
I coined that last line (‘Earth is nothing without its people’) on Twitter. No AGI is the proof that there is always someone who takes a stronger position than you do. Pause AI wants to build AI once we find out how to make it safe, whereas No AGI is full Team Dune, and wants to build it never.
Reddit covered the protest, everyone said it was pointless without realizing that the coverage is the point. A lot of ‘we are going to do AI weapons no matter what, why are you objecting to building AI weapons you idiots.’ Yes, well.
Eliezer Yudkowsky: The founder of e/acc speaks. Presented without direct comment.
Based Beff Jezos (e/acc): Doomers: “YoU cAnNoT dErIvE wHaT oUgHt fRoM iS”
Reality: you *literally* can derive what *ought* to be (what is probable) from the out-of-equilibrium thermodynamical equations, and it simply depends on the free energy dissipated by the trajectory of the system over time.
[he then shows the following two images]
I want to be fully fair to Jezos, who kind of walked this back slightly afterwards, but also in the end mostly or entirely didn’t, so here is the rest of the thread for you to judge for yourself:
BBJ: While I am purposefully misconstruing the two definitions here, there is an argument to be made by this very principle that the post-selection effect on culture yields a convergence of the two.
How do you define what is “ought”? Based on a system of values. How do you determine your values? Based on cultural priors. How do those cultural priors get distilled from experience? Through a memetic adaptive process where there is a selective pressure on the space of cultures.
Ultimately, the value systems that survive will be the ones that are aligned towards growth of its ideological hosts, i.e. according to memetic fitness. Memetic fitness is a byproduct of thermodynamic dissipative adaptation, similar to genetic evolution.
As I interpret this, Jezos is saying that we ought to do that which maximizes a thermodynamic function, and we should ignore any other consequences.
Aligning a Smarter Than Human Intelligence is Difficult
Goody-2 is a dangerously misaligned model. Yes, you also never get an answer, but that’s not the real risk here. By giving the best possible reason to refuse to answer any query, it is excellent at allowing a malicious actor to figure out the worst possible use of any information or question. Will no one stop this before something goes wrong?
Other People Are Not As Worried About AI Killing Everyone
And I would reply that yes, perhaps we should think there is a rather large existential risk involved in making unknown things that are smarter and more capable than us, that behave in unknown ways, in a very different radically uncertain type of world? That what we value, and also our physical selves, are not that likely to survive that, without getting into any further details?
I see far more epistemic humility among those worried about risk, than those who say that we definitely do not have risk, or we should proceed to this future as quickly as possible. And that seems rather obvious?
His other point is that there is no point in George Washington hiring nuclear safety researchers. Which is strictly true, but:
George Washington’s inability to usefully hire specifically ‘nuclear safety researchers’ is strongly related to his inability to realize that this is a future need at all.
George Washington was directly involved in a debate over how to deal with the safe and fair distribution of weapons, settled on the Declaration of Independence, then tried the Articles of Confederation followed by the Constitution including among others the second amendment, and we have been dealing with the consequences ever since, with mixed results. It was designed to handle a radically uncertain future. Mistakes were made. More research, one might say, was needed, or at least would have been useful, and they did the best they could.
George Washington was also directly involved in debates over the scope of governmental powers versus freedoms, state capacity, the conditions that justify surveillance, what constitutes proper authority and so on. All very important.
The AI landscape would look radically different today without George Washington, and in a way very closely related to many things he knew mattered and for the reasons they mattered. The ideas of the founding fathers matter.
George Washington was deeply involved in diplomacy, international treaties and international relations, all of which are highly relevant and could be usefully advanced.
If you can’t hire nuclear safety engineers, you don’t build a nuclear power plant.
This has more insight than most people who think about such questions. You think that if the AIs (or robots) start doing X that you can instead do Y. But there is no reason they cannot also do Y.
Of course, if you want to watch movies all day for your own enjoyment, the fact that a robot can watch them faster is irrelevant. Consumption is different. But consumption does not keep one in business, or sticking around.
Daniel Eth: Lotta people I know are telling their parents to watch out for AI scams impersonating their voice, but if you really want to train your parents to be more careful, you should periodically red team them by calling them from a random number and doing a fake self-impersonating scam.
Okay, so the stranger whose phone I borrowed for this seemed to think it was kinda weird and disagreed that it constituted an “emergency”, but at least now I know my parents aren’t likely to fall for these types of scams.
Either that or they’re just not that bothered by the prospect of my kidnapping
I appreciate the echo, and note that the exact phrase here is supposed to be ‘YOUR periodic reminder,’ although I get not wanting to say ‘your’ twice here.
Short comment on the phrasing of Sam Altman’s goals (emphasis mine):
Sam Altman is not playing around.
He wants to build new chip factories in the decidedly unsafe and unfriendly UAE. He wants to build up the world’s supply of energy so we can run those chips.
What does he say these projects will cost?
Oh, up to seven trillion dollars. Not a typo.
I’m a bit disappointed with the phrasing by the author of Simulacra Levels. We don’t know what Sam Altman wants. He says that he wants to do that. And I’m not sure on which simulacrum level that statement has to be interpreted. Maybe even multiple ones at the same time. Because sama is good at persuasion.
Though maybe Zvi is also not writing at level 1 here as he seems clearly aware of that:
Altman is very good at letting everyone see what they want to see, and adjusting his answers for the right setting. He is clearly doing both here.
I know this is basically downvote farming on LW, but I find the idea of morality being downstream from the free energy principle very interesting.
Jezos obviously misses out on a bunch of game theoretic problems that arise, and FEP lacks explanatory power in such a domain, so it is quite clear to me that we shouldn’t do this. I do think it’s fundamentally true, just like how utilitarianism is fundamentally true. The only problem is that he’s applying it naively.
I don’t want to bet the future of humanity on this belief, but what if is = ought, and we have just misconstrued it by adopting proxy goals along the way? (IGF gang rise!)
I find the idea of morality being downstream from the free energy principle very interesting
I agree that there are some theoretical curiosities in the neighbourhood of the idea. Like:
Morality is downstream of generally intelligent minds reflecting on the heuristics/shards.
Which are downstream of said minds’ cognitive architecture and reinforcement circuitry.
Which are downstream of the evolutionary dynamics.
Which are downstream of abiogenesis and various local environmental conditions.
Which are downstream of the fundamental physical laws of reality.
Thus, in theory, if we plug all of these dynamics one into another, and then simplify the resultant expression, we should actually get a (probability distribution over) the utility function that is “most natural” for this universe to generate! And the expression may indeed be relatively simple and have something to do with thermodynamics, especially if some additional simplifying assumptions are made.
That actually does seem pretty exciting to me! In an insight-porn sort of way.
Not in any sort of practical way, though[1]. All of this is screened off by the actual values actual humans actually have, and if the noise introduced at every stage of this process caused us to be aimed at goals wildly diverging from the “most natural” utility function of this universe… Well, sucks to be that utility function, I guess, but the universe screwed up installing corrigibility into us and the orthogonality thesis is unforgiving.
At least, not with regards to AI Alignment or human morality. It may be useful for e. g. acausal trade/acausal normalcy: figuring out the prior for what kinds of values aliens are most likely to have, etc.[2]
Or maybe for roughly figuring out what values the AGI that kills us all is likely going to have, if you’ve completely despaired of preventing that, and founding an apocalypse cult worshiping it. Wait a minute...
When I say “five minutes ought to be enough time”, I’m not talking about probability—I’m talking about right/wrong. “Five minutes will be enough time if everything goes right. If it isn’t, then something went wrong”.
The actual WSJ article centers on companies not sure they want to pay $30/month per user for Microsoft Copilot.
I understand that this is a thing, but I find it hard to imagine there are that many people making significant use of Windows and Microsoft Office at work who wouldn’t be able to save an hour or two a month using Copilot or it’s near-term successors. For me the break-even point would be saving somewhere between 5-30 minutes a month depending on how I calculate the cost and value of my work time.
















Short comment on the phrasing of Sam Altman’s goals (emphasis mine):
I’m a bit disappointed with the phrasing by the author of Simulacra Levels. We don’t know what Sam Altman wants. He says that he wants to do that. And I’m not sure on which simulacrum level that statement has to be interpreted. Maybe even multiple ones at the same time. Because sama is good at persuasion.
Though maybe Zvi is also not writing at level 1 here as he seems clearly aware of that:
I know this is basically downvote farming on LW, but I find the idea of morality being downstream from the free energy principle very interesting.
Jezos obviously misses out on a bunch of game theoretic problems that arise, and FEP lacks explanatory power in such a domain, so it is quite clear to me that we shouldn’t do this. I do think it’s fundamentally true, just like how utilitarianism is fundamentally true. The only problem is that he’s applying it naively.
I don’t want to bet the future of humanity on this belief, but what if is = ought, and we have just misconstrued it by adopting proxy goals along the way? (IGF gang rise!)
I agree that there are some theoretical curiosities in the neighbourhood of the idea. Like:
Morality is downstream of generally intelligent minds reflecting on the heuristics/shards.
Which are downstream of said minds’ cognitive architecture and reinforcement circuitry.
Which are downstream of the evolutionary dynamics.
Which are downstream of abiogenesis and various local environmental conditions.
Which are downstream of the fundamental physical laws of reality.
Thus, in theory, if we plug all of these dynamics one into another, and then simplify the resultant expression, we should actually get a (probability distribution over) the utility function that is “most natural” for this universe to generate! And the expression may indeed be relatively simple and have something to do with thermodynamics, especially if some additional simplifying assumptions are made.
That actually does seem pretty exciting to me! In an insight-porn sort of way.
Not in any sort of practical way, though[1]. All of this is screened off by the actual values actual humans actually have, and if the noise introduced at every stage of this process caused us to be aimed at goals wildly diverging from the “most natural” utility function of this universe… Well, sucks to be that utility function, I guess, but the universe screwed up installing corrigibility into us and the orthogonality thesis is unforgiving.
At least, not with regards to AI Alignment or human morality. It may be useful for e. g. acausal trade/acausal normalcy: figuring out the prior for what kinds of values aliens are most likely to have, etc.[2]
Or maybe for roughly figuring out what values the AGI that kills us all is likely going to have, if you’ve completely despaired of preventing that, and founding an apocalypse cult worshiping it. Wait a minute...
When I say “five minutes ought to be enough time”, I’m not talking about probability—I’m talking about right/wrong. “Five minutes will be enough time if everything goes right. If it isn’t, then something went wrong”.
I understand that this is a thing, but I find it hard to imagine there are that many people making significant use of Windows and Microsoft Office at work who wouldn’t be able to save an hour or two a month using Copilot or it’s near-term successors. For me the break-even point would be saving somewhere between 5-30 minutes a month depending on how I calculate the cost and value of my work time.