Train first VS prune first in neural networks.
This post aims to answer a simple question about neural nets, at least on a small toy dataset. Does it matter if you train a network, and then prune some nodes, or if you prune the network, and then train the smaller net.
What exactly is pruning.
The simplest way to remove a node from a neural net is to just delete it. Let be the function from one layer of the network to the next.
Given and as the set of indicies that aren’t being pruned, this method is just
however, a slightly more sophisticated pruning algorithm adjusts the biases based on the mean value of in the training data. This means that removing any node carrying a constant value doesn’t change the networks behavior.
The formula for bias with this approach is
This approach to network pruning will be used throughout the rest of this post.
Random Pruning
What does random pruning do to a network. Well here is a plot showing the behavior of a toy net trained on spiral data. The architecture is
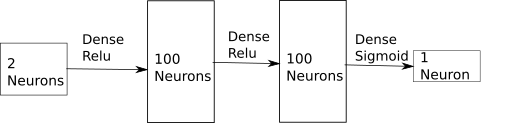
And this produces an image like
In this image, points are colored based on the network output. The training data is also shown. This shows the network making confidant correct predictions for almost all points. If you want to watch what this looks like during training, look here https://www.youtube.com/watch?v=6uMmB2NPv1M
When half of the nodes are pruned from both intermediate layers, adjusting the bias appropriately, the result looks like this.
If you fine tune those images to the training data, it looks like this. https://youtu.be/qYKsM29GSEE
If you take the untrained network, and train it, the result looks like this. https://www.youtube.com/watch?v=AymwqNmlPpg
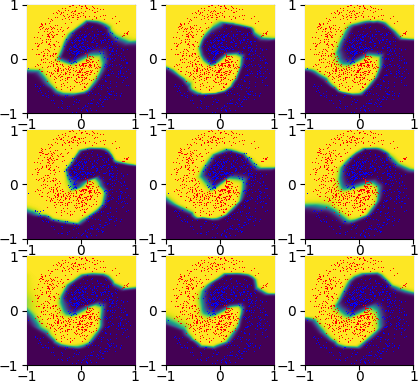
Ok. Well this shows that pruning and training don’t commute with random pruning. This is kind of as expected. The pruned then trained networks are functional high scoring nets. The others just aren’t. If you prune half the nodes at random, often a large chunk of space is categorized wrongly. This shows that the networks aren’t that similar. This is kind of to be expected. However, these networks do have some interesting correlations. Taking the main 50x50 weight matrixes from each network and plotting them against each other reveals.
Same plot, but zoomed in to show detail.
Notice the dashed diagonal line. The middle piece of this line is on the diagonal to machine precision. It consists of the points that were never updated during training at all. The uniform distribution with sharp cutoffs is simply due to that being the initialization distribution. The upper and lower sections consist of points moved about ±0.59 by the training process. For some reason, the training process likes to change values by about that amount.
Nonrandom Pruning
A reasonable hypothesis about neural networks is that a significant fraction of neurons aren’t doing much, so that if those neurons are removed then the network will have much the same structure with or without training. Lets test that by pruning the nodes with the smallest standard deviation.
This pruning left an image visually indistinguishable from the original. entirely consistent with the hypothesis that these nodes weren’t doing anything.
When those same nodes are removed first, and the model is then trained, the result looks like this.
Similar to the trained and then pruned (see top of document), but slightly different.
Plotting the kernels against each other reveals
This shows a significant correlation, but still some difference in results. This suggests that some neurons in a neural net aren’t doing anything. No small change will make them helpful, so the best they can do is keep out the way.
It also suggests that if you remove those unhelpful neurons from the start, and train without them, the remaining neurons often end up in similar roles.
You may want to look at what happens with test data never shown to the network or used to make decisions about its training. Pruning often improves generalization when data are abundant compared to the complexity of the problem space because you are reducing the number of parameters in the model.
“…nodes with the smallest standard deviation.” Does this mean nodes whose weights have the lowest absolute values?
Not quite. It means running the network on the training data. For each node, look at the values. (which will always be ≥0, as the activation function is relu) and taking the empirical standard deviation. So consider the randomness to be a random choice of input datapoint.
Ah okay. Are there theoretical reasons to think that neurons with lower variance in activation would be better candidates for pruning? I guess it would be that the effect on those nodes is similar across different datapoints, so they can be pruned and their effects will be replicated by the rest of the network.
Well if the node has no variance in its activation at all, then its constant, and pruning it will not change the networks behavior at all.
I can prove an upper bound. Pruning a node with standard deviation X should increase the loss by at most KX, where K is the product of the operator norm of the weight matrices. The basic idea is that the network is a libshitz function, with libshitz constant K. So adding the random noise means randomness of standard deviation at most KX in the logit prediction. And as the logit is log(p)−log(1−p), and an increase in log(p) means a decrease in log(1−p),, then each of those must be perterbed by at most KX.
What this means in practice is that, if the kernals are smallish, then the neurons with small standard deviation in activation aren’t effecting the output much. Of course, its possible for a neuron to have a large standard deviation and have its output totally ignored by the next layer. Its possible for a neuron to have a large standard deviation and be actively bad. Its possible for a tiny standard deviation to be amplified by large values in the kernels.