Follow-up to: Law of No Evidence
Recently, there was some debate about a few Twitter polls, which led into a dispute over the usefulness of Twitter polls in general and how to deal with biased and potentially misleading evidence.

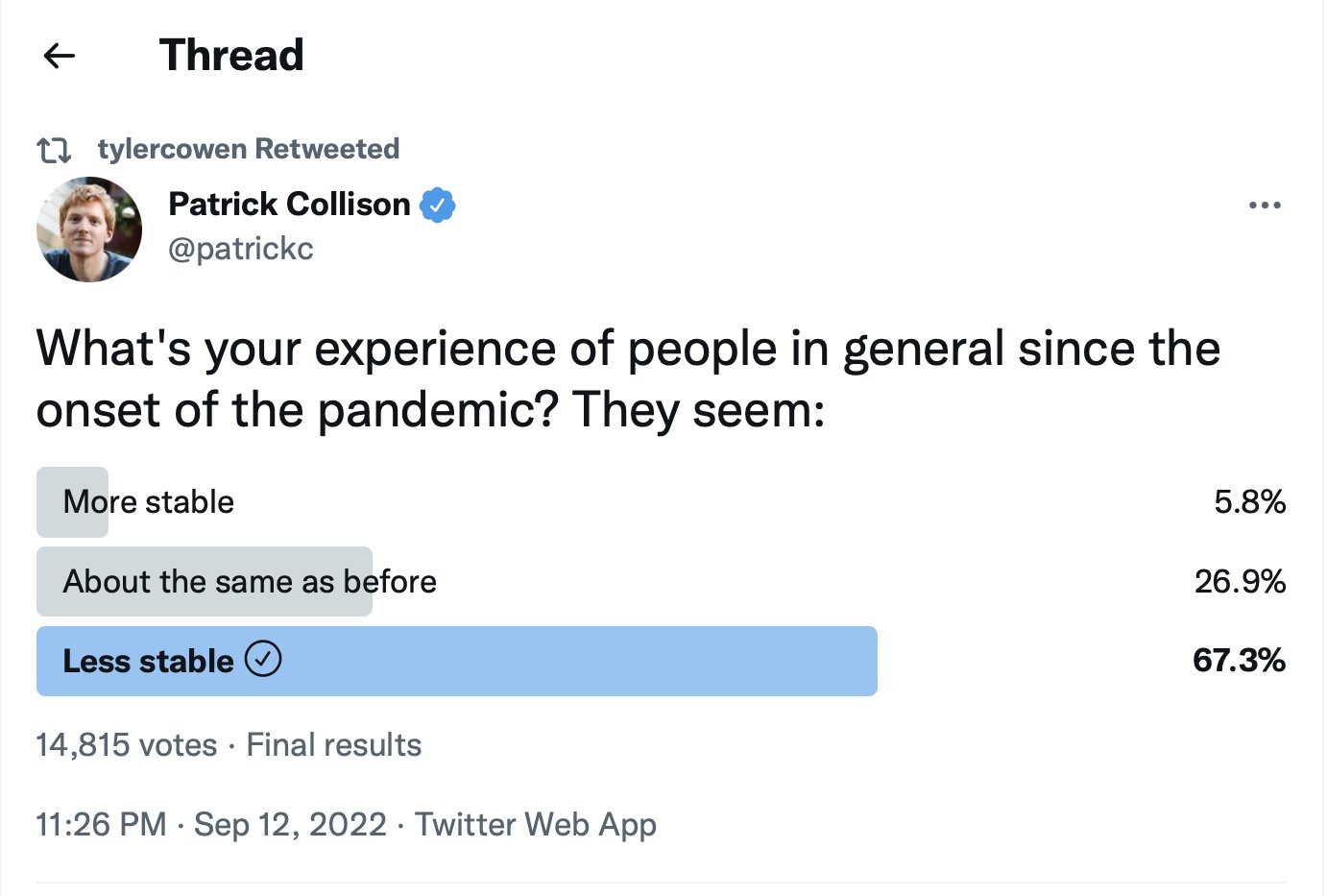
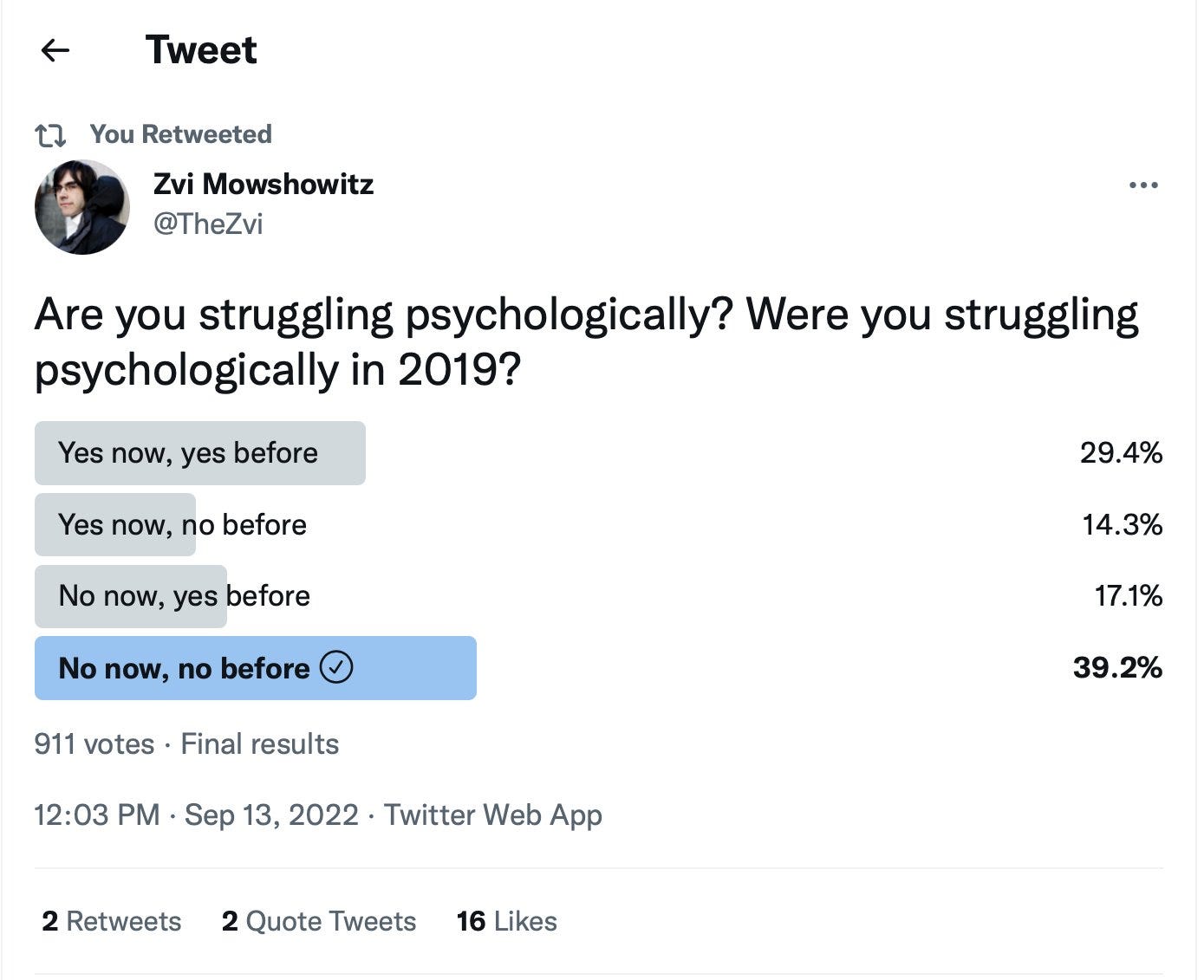
Agnus Callard is explicitly asking the same question I asked, which is the opposite of ignoring sample bias: What is accounting for the difference?
Sample selection is definitely one of the explanations here. One can also point to several other key differences.
My poll asks about you, Patrick asks about how others seem.
My poll asks about struggle, Patrick asks about stability.
My poll asks about a year versus a point in time, a potential flaw.
My poll asks about now, Patrick asks about since pandemic onset.
None of this is well-controlled or ‘scientific’ in the Science

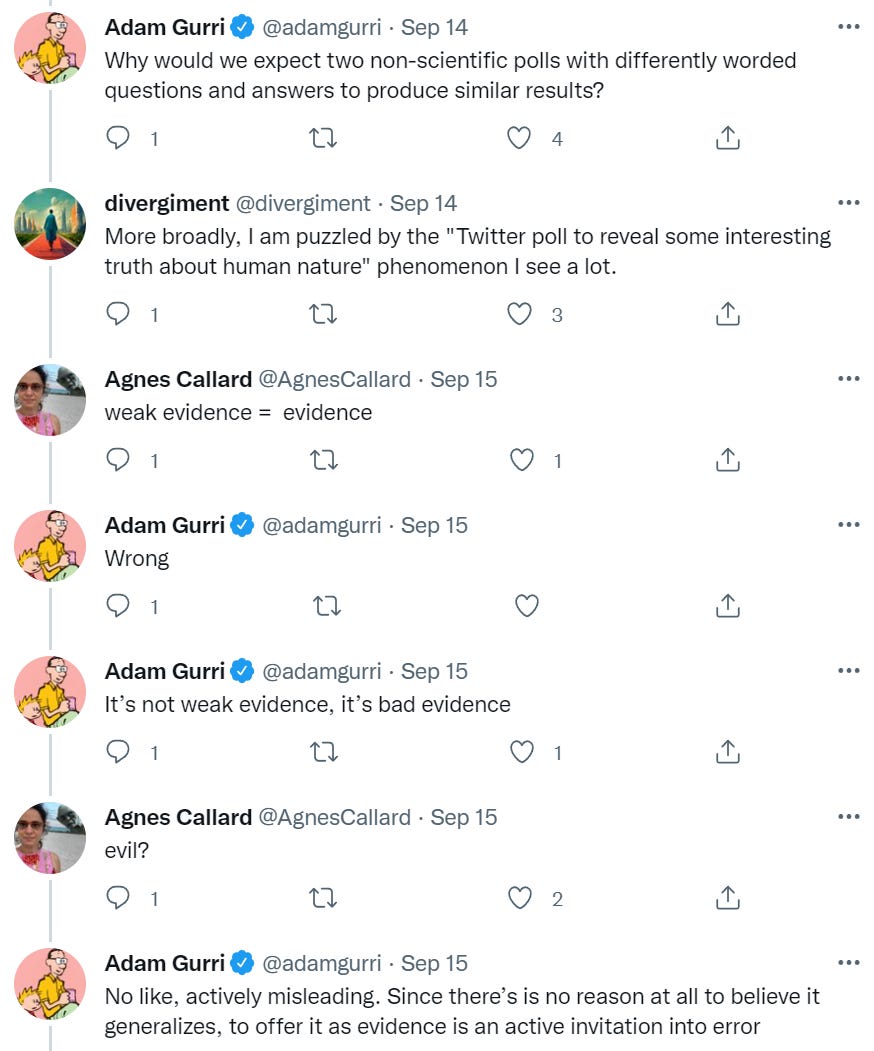
What is ‘bad’ evidence if it isn’t weak evidence? Adam’s theory here is that it is misleading evidence. That makes sense as a potential distinction. Under this model:
Weak evidence induces a small Bayesian update in the correct direction.
Bad evidence can induce an update in the wrong direction.
Usually, people with such taxonomies will also think that strong evidence by default trumps weak evidence, allowing you to entirely ignore it. That is not how that works. Either something has a likelihood ratio, or it doesn’t.
The question is, what to do about the danger that someone might misinterpret the data and update ‘wrong’?

I love that the account is called ‘Deconstruction Guide.’ Thanks, kind sir.
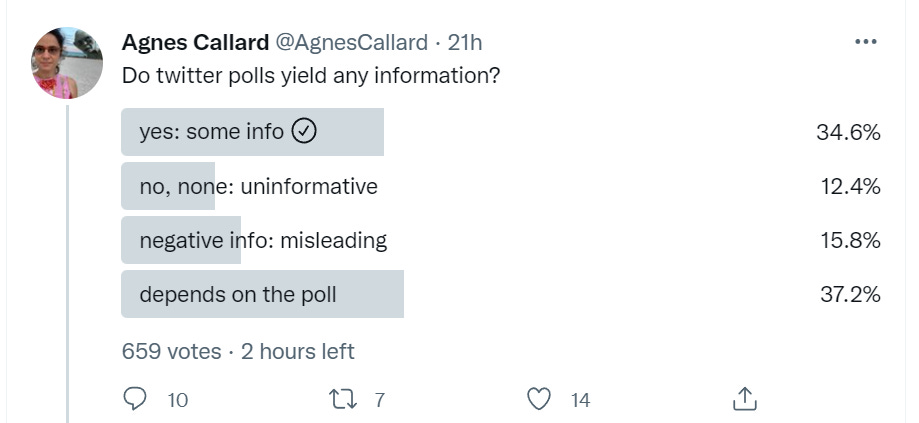
Whether or not this ‘depends on the poll’ depends on what level of technically correct we are on, and one can go back and forth on that several times. The fully correct answer is: Yes, some info. You always know that the person chose to make the poll, and how many people chose to respond given the level of exposure, and the responses always tell you something, even if the choices were ‘Grune’ and ‘Mlue,’ ‘Yes’ and ‘Absolutely,’ or ‘Maybe’ and ‘Maybe Not.’
Remember that if any other result would have told you something, then this result also tells you something, because it means the result that would have told you something did not happen. That doesn’t mean it helps you with any particular question.
Anyway, back to main thread.
Getting into a Socratic dialog with a Socratic philosopher, and letting them play the role of Socrates. Classic blunder.
I certainly want to know the extent to which the world is full of lunatics.
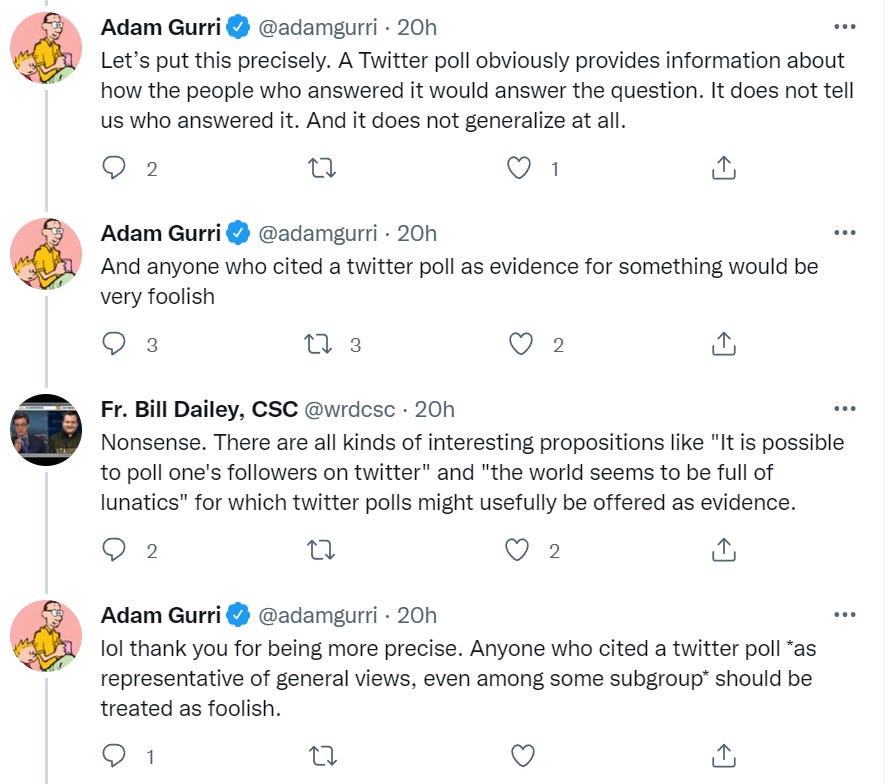
Adam Gurri’s new claim has now narrowed to something more reasonable, that citing a Twitter poll as representative even of some subgroup marks you as foolish.
We can agree that taking a Twitter poll, not adjusting for sample bias, and drawing conclusions is foolish. Saying it equates to a subgroup that is similar to the group polled still requires dealing with response bias and all that, but mostly seems fine. Adjusting for the nature of your sample should render the whole thing fine in any case.
You can also find good information in a Twitter poll by comparing its results to another Twitter poll using the same account (and same retweets, ideally). The difference between the two is meaningful. This can be a difference between questions or wordings, or a difference over time, or something else.
Rules of Evidence
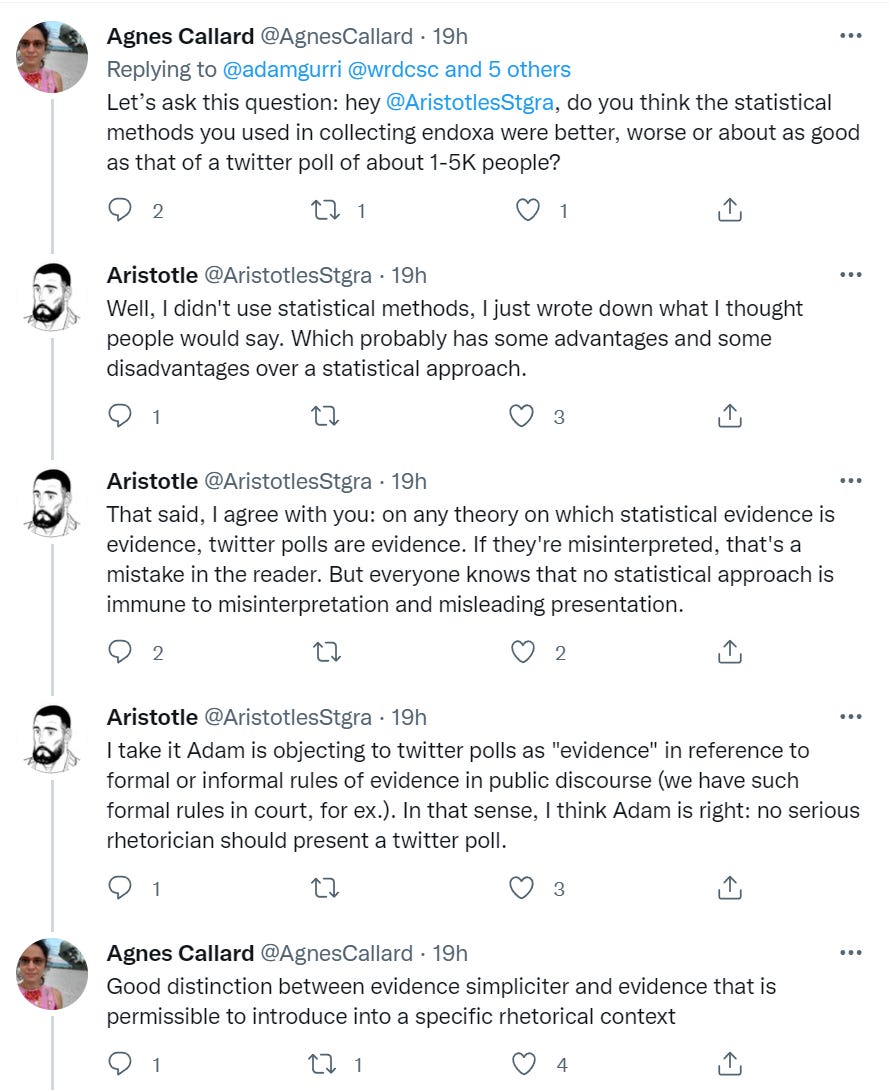
Aristotle is indeed wise. He points to the important distinction between evidence, as in Bayesian evidence or a reason one might change one’s mind or one’s probabilities, and the rules of evidence in a given format of debate or discourse. In a court of law, some forms of Bayesian evidence are considered irrelevant or, even more extremely, prejudicial, exactly because they should cause one to update their probabilities and the law wants the jury not to do that.
Which is sometimes the right thing to do. Still, you have to admit it is kind of weird.
I think a lot of the reason it is so often right to do it is because we use very strange standards of evidence and burdens of proof in other places, forcing corrections. And also of course juries are random people so they have a lot of biases and we worry about overadjustments. Then there are the cases where we think the jury would reach exactly the right conclusion, but we think that’s bad, actually.
Anyway.
In the formal rules for public discourse, how should we consider Twitter polls?
A Twitter poll without proper context should be fully inadmissible here.
What about with the proper context? That gets trickier.
I consider what I do on my blog a form of public discourse, and I notice that in whatever thing that it is I am doing in most posts, a Twitter poll with context is obviously admissible. That is because ‘the thing I am doing’ is attempting to reason in public and establish a model of the world, how it works and what it is going to do. I am not trying to persuade anyone as such.
That’s a different department.
We should strive to minimize our visits to that department, whenever possible.

Exactly. Keep your evidential requirements as low as possible. But no lower.
I do occasionally, and likely will more often in the future, visit the other department. In those situations, I am more careful about using such evidence. I know it is by its nature unpersuasive to most, and a point of vulnerability, and requires a certain level of epistemic trust. Thus, in these situations, I try even more than usual to at most rely on it and other similar facts only for loose bounds and non-binding intuitions – by default, it’s not admissible.
Crux One
And now, at least I hope, a crux.

Yes, exactly. Everything is evidence. You should updateon almost anything. That is indeed how probability and knowledge work.
To state the obvious, if evidence does not cause one to be more likely to be led to the correct conclusion, you are doing evidence wrong, bro do you even Bayes?
My first response would be to attempt to fix it. If I couldn’t, then yes, I would consider not seeking out, or even actively avoiding, such information.
The tricky case is when you are being shown evidence that is selected to attempt to change your mind. Which is the basis of most ‘public discourse,’ especially that which is going to engage with someone (in any direction) with a publication called Liberal Currents. In such situations, you need to ask what actual evidence you are getting when you are given evidence. Often this is mainly comparing the quality and strength of the evidence you got to the quality and strength you would expect. If the evidence is weaker than you expected, you should update in the opposite direction on the information that this was the best this source could do.
I do not understand the claim that ‘we have statistics’ on the Twitter poll question. Is Adam suggesting someone ran a Proper Scientific Study on people’s updates from looking at Twitter polls? Which seems very hard to do usefully, and I assume is not it. Instead, I am assuming he means ‘we have statistical tools for evaluating samples and they say that your samples are worthless.’
I think this claim is simply doing statistics wrong. The samples are quite big enough. All you have to do is understand the nature of the samples. Or, use the poll to get insight into the sample. Which, then, you can, among other things, poll again later.
Whenever I read a scientific paper, there is about a 50⁄50 chance I conclude that they have buried the lead, often entirely missing the lead, even if I also agree with their main claim. They do not realize what they have learned. They do the equivalent of concluding that the key thing in life is herring sandwiches, instead of realizing it is boredom.
Instead of looking for something specific, look for anything at all. Much better odds.
Crux Two
Thus:
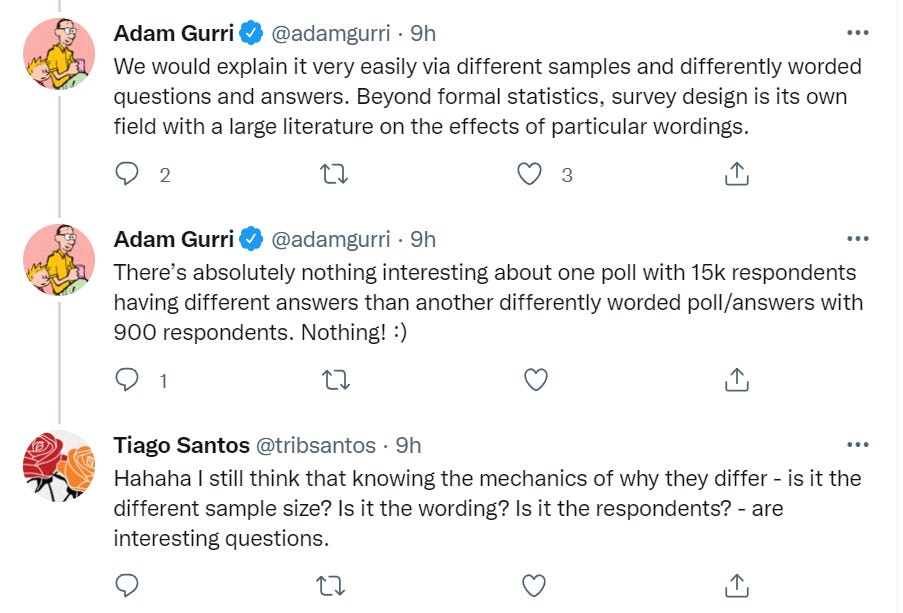
Tiago nails it. Knowing that different samples and differently worded questions and answers explain the answer is better than not knowing that. One should not mistake it either for Deep Wisdom, or for the main thing available to be learned. It is a way to avoid learning what there is to learn, by figuring out which differences did it. There is a surprising result. It has a cause, and the details there are often going to be interesting. Using ‘there is a cause one could find’ as a semantic stop sign will not help you.
Indeed, I realized I could Do Science to the situation. Was it primarily the different samples, or was it primarily the different wording? There’s a way to find out!
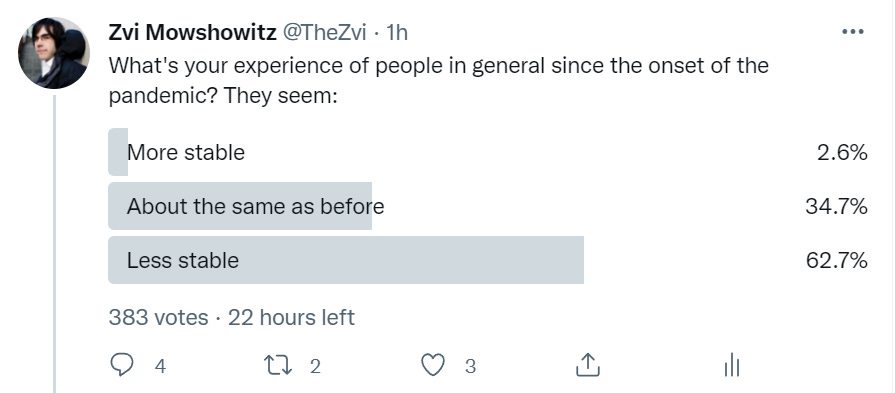
I grabbed the results here because someone new retweeted the poll, potentially corrupting the comparison after that, and any sample >300 is fine here. Here is the larger sample, which converged some towards Patrick’s results.
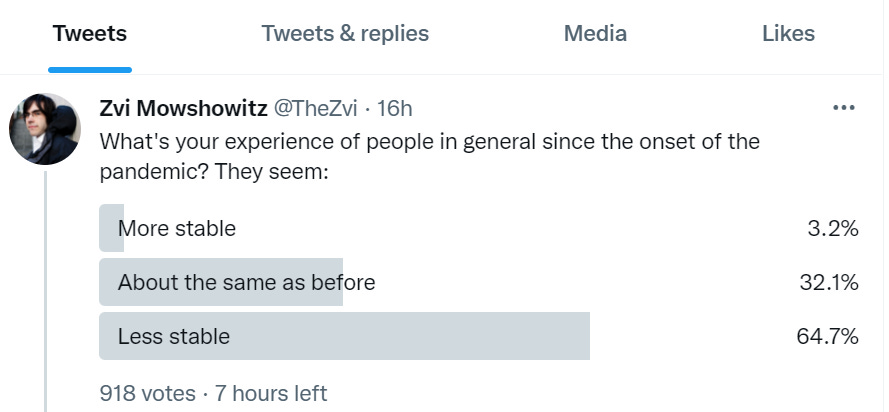
That is exactly Patrick’s wording. Does it match Patrick’s poll?
Mostly it does. The difference is that my sample includes more ‘about the same’ and less at the extremes, which is likely cultural differences in what counts as about the same. I’m also guessing my audience has a lower-than-usual Lizardman Constant, and that together they explain the whole difference.
Thus, we have learned that, at least in this context, no, the samples are very similar. Mostly the difference is the wordings. If Patrick were to do my exact poll For Science, I expect him to get roughly my result with a bit more noise.
The next step, if one wanted to continue learning, would be to change individual components and see if anything more changed – e.g. do Patrick’s wording with respect to yourself only.
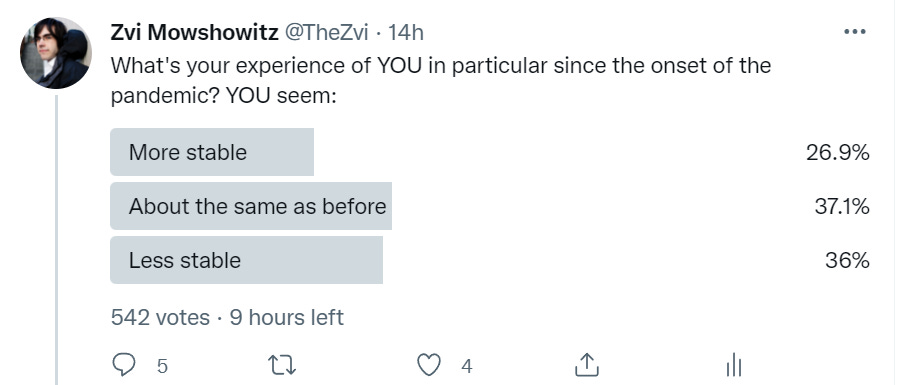
Does this represent people having a more optimistic view of themselves than they do of others? Or is this people correctly doing aggregation, since 10% of people becoming less stable makes people overall less stable and larger groups have less variance? My presumption is this is a mix.
This still does leave stability down versus the original finding of struggling also down. That too is logically compatible but on its own implausible, so there is more here to explain. One could continue. For now, I will stop there.
Conclusions
The original thread finished up with Agnus using the Robin Hanson signal to attempt to put a bet together, which did not work as there was nothing close to a meeting of the minds on what was in dispute. Adam’s final position seemed to be that as long as Twitter polls did not match national polls as accurately as other national polls matched each other then they were useless. It was unclear whether you would be allowed to correct for bias before checking. That seems important given that most national polls are doing various bias-correcting things under the hood.
Adam’s whole position here, to me, is rather silly, even if we limit ourselves to use cases where the Twitter poll is being used only to try and extrapolate towards national sentiment. Of course when we are trying to measure the output of process X we will get a less accurate measure by using process Y than by repeating process X. That is true even if X is not doing as good a job as Y of measuring underlying value V. We still might gain insight into V. We especially might gain insight into V if X costs hundreds or thousands of dollars per use while Y falls under the slogan ‘this website is free.’
The principle mirrors the question about to what extent Proper Scientific Studies are the only form of evidence, making it legitimate to say No Evidence of X whenever there is no Proper Scientific Study claiming X, no matter what your lying eyes think or how many times your lying ears hear “Look! It’s an X!”
Takeaways
All evidence is evidence. All evidence is net useful if well-handled.
Those who deny this are likely epistemically hostile and/or operate in a highly hostile epistemic environment. Treat accordingly.
Do your best to stay out of such places and discussions, when you can.
Biased or misleading evidence is evidence, often of many things.
One must preserving Conservation of Expected Evidence.
Mostly compare information from hostile or biased sources to expectations.
See what is there to be learned, being curious and exploring.
Look for comparisons that let you control for bias. Often quite straightforward.
Never get into a Socratic dialog where a Socratic philosopher gets to ask the questions when death is on the line. Or you want to ‘win.’ Otherwise, sure.
Twitter polls are neat and chances are you are not doing enough of them.
This is wrong, strong evidence does typically trump weak evidence, allowing you to ignore the weak evidence for the purpose of the question you are trying to answer.
Specifically, the way you get strong and weak evidence is when the strong evidence is fairly directly related to the question that you are interested in, while the weak evidence is also dependent on many other contingent and random factors. In such a circumstance, strong evidence gets rid of your uncertainty about the question under consideration, which leaves the weak evidence only correlated with the random contingent factors and not with the question itself.
So in the presence of strong evidence, weak evidence shifts from being evidence about the fact of the matter to being evidence about its own quality. If the weak evidence contradicts the strong evidence then it’s probably due to some random contingent factor like sample bias or whatever, and you can (approximately) ignore it.
Meta: I feel like there should be an existing LW tag that covers this post, but all the options felt not-quite-right.
The old Scientific Evidence, Legal Evidence, Rational Evidence has “Practice and Philosophy of Science” which is maybe reasonable (that’s a newer one).
It’s worth noting that Twitter polls are easily corrupted/manipulated by someone trying deliberately to do so. But no one is likely do that unless they know you take the results seriously. It’s anti-inductive: the more you use them, the less useful they get.
The explanation that immediately presented itself to me: Sensationalism bias. If one person goes crazy and does something crazy, then that’s a fascinating story that gets passed around to a wide audience. If a hundred people get somewhat better at maintaining their lives, that is not a fascinating story and doesn’t get passed around (except perhaps by those who study unemployment rates or other systematically aggregated data). I don’t know how good people are at correcting for this, but I’d guess many people are not good at it—20% would be enough to explain the difference in poll results.
Yep. If the crazy people get louder or the loud people get crazier or twitter-poll-respondents start paying more attention to the loud and crazy, then that will give you the self-other difference in perception.
I think the meaning of the word “evidence” is being debated here.
For some, it means “any stimulus from which useful information can potentially be extracted by a sufficiently sophisticated interpreter.”
For others, it means something like “a sophisticated document designed to ensure efficient information transfer to the reader.”
This is at the heart of debates over whether or not there is “no evidence” for a proposition. By the second definition, “the evidence for X is clear” is potentially a statement that’s perfectly compatible with X being wrong. And that’s not even necessarily bad. We might very well want a word to label “the documents that contain published expert opinion on X”, irrespective of whether or not that expert opinion is correct. We still call it a “gas can” even when there’s no gasoline in it.
I agree except with the last part (it’s not silly when thinking about extrapolating to national sentiment). The key is to what extent is it evidence of [insert thing], and of course if you’re interested in learning more, what are the factors that affect the extent to which it is evidence of [insert thing]? In other words, what are you trying to generalize to, and what interesting things are limiting your ability to generalize to [insert other thing]?
Often we are comfy with generalizing from sample to appropriately-defined population (sample of Zvi Twitter noticers to Zvi Twitter noticers), but when we don’t define the scope of our generalization properly, we get uncomfy again (sample of Zvi Twitter followers to US general population). Often we are interested in the limits of generalizability (e.g., this treatment works for men but not women, isn’t that interesting and useful!), unless the those boundaries are trivial (e.g., vasectomies work for men but not women, gosh!) or we already don’t see them as boundaries (e.g., “what if you had changed the wording from ‘YOU in particular’ to ‘YOU specifically’?).
Interestingness is in the eye of the beholder. Concede to Adam for the moment that the boundaries are not interesting because they are well-known limits to generalizability (selection, wording). Then, is it “bad evidence?” Depends on what you’re trying to generalize to (what it is purported to be evidence of)! Adam waves between Twitter polls being “meaningless” and “does not generalize at all” as in worthless for anything at all, which is obviously mostly false (it should at least generalize to Zvi Twitter noticers, though even then it could suffer from self-selection bias like many other polls), vs. “not representative of general views,” which is not silly and is far more debatable (it’s likely “weak” evidence in that Twitter polls can yield biased estimates on some questions [this is the most charitable interpretation of the position]; it’s possibly “bad” evidence if the bias is so severe that the qualitative conclusions will differ egregiously [this is the most accurate interpretation of the position seeing as he literally wanted to differentiate it from weak evidence] - e.g., if I polled lesbian women on how sexually attractive the opposite sex was to infer how sexually attractive the opposite sex is to people generally). So overall, the position is rather silly (low generalizability is not NO generalizability, and selection and wording ARE interesting factors relevant for understanding people), except on the very specific last part, where it’s not silly (possibly bad evidence) but it is also still probably not correct (probably not bad evidence).
Could your follow-up poll with Collison’s exact wording have been affected by people (following this discussion and) intentionally voting to reproduce Collison’s results? Ideally I guess Twitter would let one send out two versions of the same poll to randomized subsets of one’s followers.
Btw, you have a couple of typos: “Agnus” instead of “Agnes”.