Born too late to explore Earth; born too early to explore the galaxy; born just the right time to save humanity.
Ulisse Mini
Karma: 1,654
Finally Entering Alignment
TinyStories: Small Language Models That Still Speak Coherent English
[Question] What rationality failure modes are there?
How to get good at programming
Don’t be afraid of the thousand-year-old vampire
[ASoT] Natural abstractions and AlphaZero
Three Fables of Magical Girls and Longtermism
[Question] Finding Great Tutors
[Question] What ML gears do you like?
[ASoT] GPT2 Steering & The Tuned Lens
Downvoted because I view some of the suggested strategies as counterproductive. Specifically, I’m afraid of people flailing. I’d be much more comfortable if there was a bolded paragraph saying something like the following:
Beware of flailing and second-order effects and the unilateralist’s curse. It is very easy to end up doing harm with the intention to do good, e.g. by sharing bad arguments for alignment, polarizing the issue, etc.
To give specific examples illustrating this (which may also be good to include and/or edit the post):
I believe tweets like this are much better (and net positive) then the tweet you give as an example. Sharing anything less then the strongest argument can be actively bad to the extent it immunizes people against the actually good reasons to be concerned.
Most forms of civil disobedience seems actively harmful to me. Activating the tribal instincts of more mainstream ML researchers, causing them to hate the alignment community, would be pretty bad in my opinion. Protesting in the streets seems fine, protesting by OpenAI hq does not.
Don’t have time to write more. For more info see this twitter exchange I had with the author, though I could share more thoughts and models my main point is be careful, taking action is fine, and don’t fall into the analysis-paralysis of some rationalists, but don’t make everything worse.
Character.ai seems to have a lot more personality then ChatGPT. I feel bad for not thanking you earlier (as I was in disbelief), but everything here is valuable safety information. Thank you for sharing, despite potential embarrassment :)
I think you should have stated the point more forcefully. It’s insane that we don’t have alignment prediction markets (with high liquidity and real money) given
How adjacent rationality is to forecasting and how many superforecasters are in the community
The number of people-who-want-to-help whose comparative advantage isn’t technical alignment research
There should be a group of expert forecasters who make a (possibly subsidized) living on alignment prediction markets! Alignment researchers should routinely bet thousands on relevant questions!
There’s a huge amount of low-hanging dignity here, I can vividly imagine the cringing in Daith Ilan right now!
Was considering saving this for a followup post but it’s relatively self-contained, so here we go.
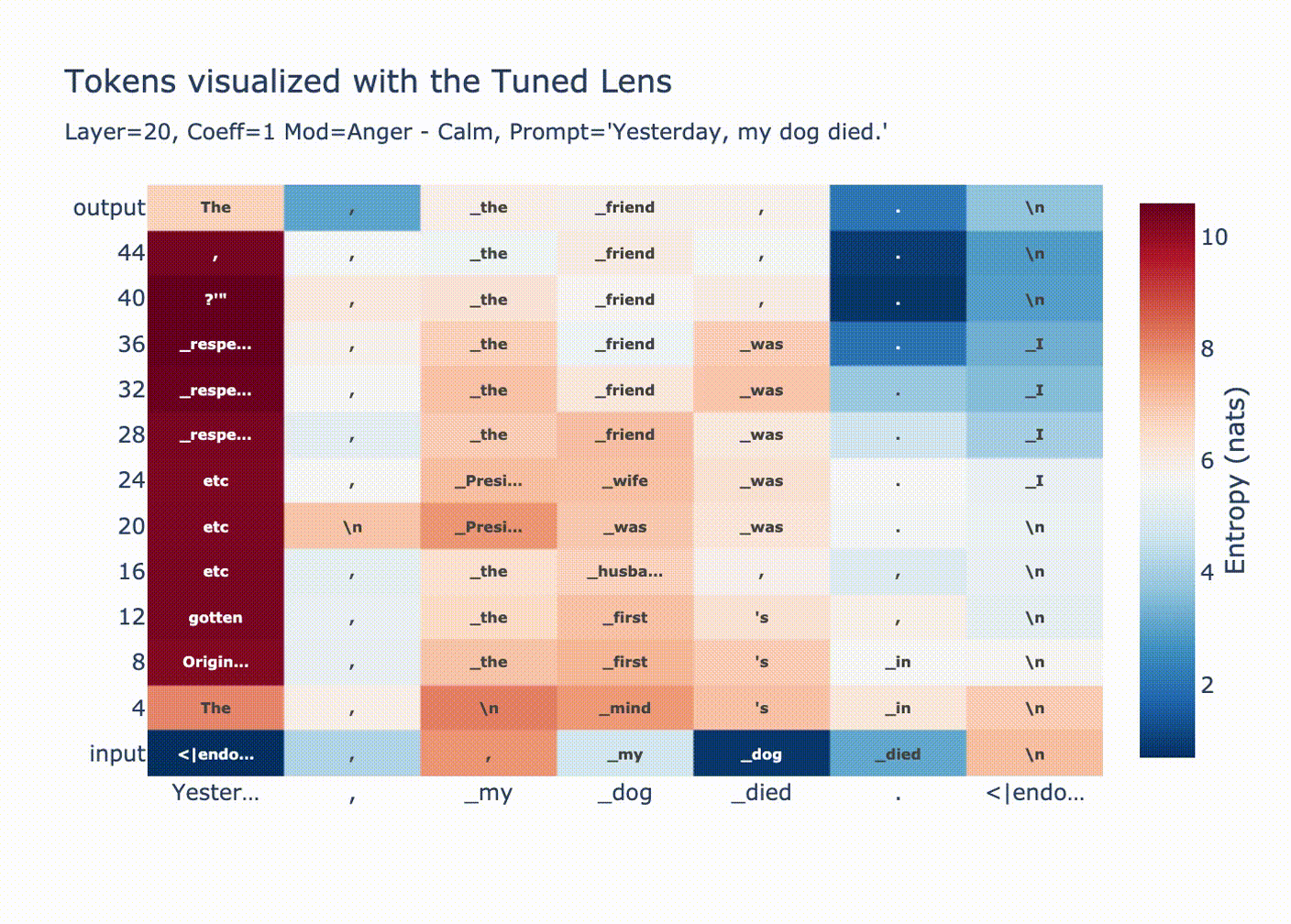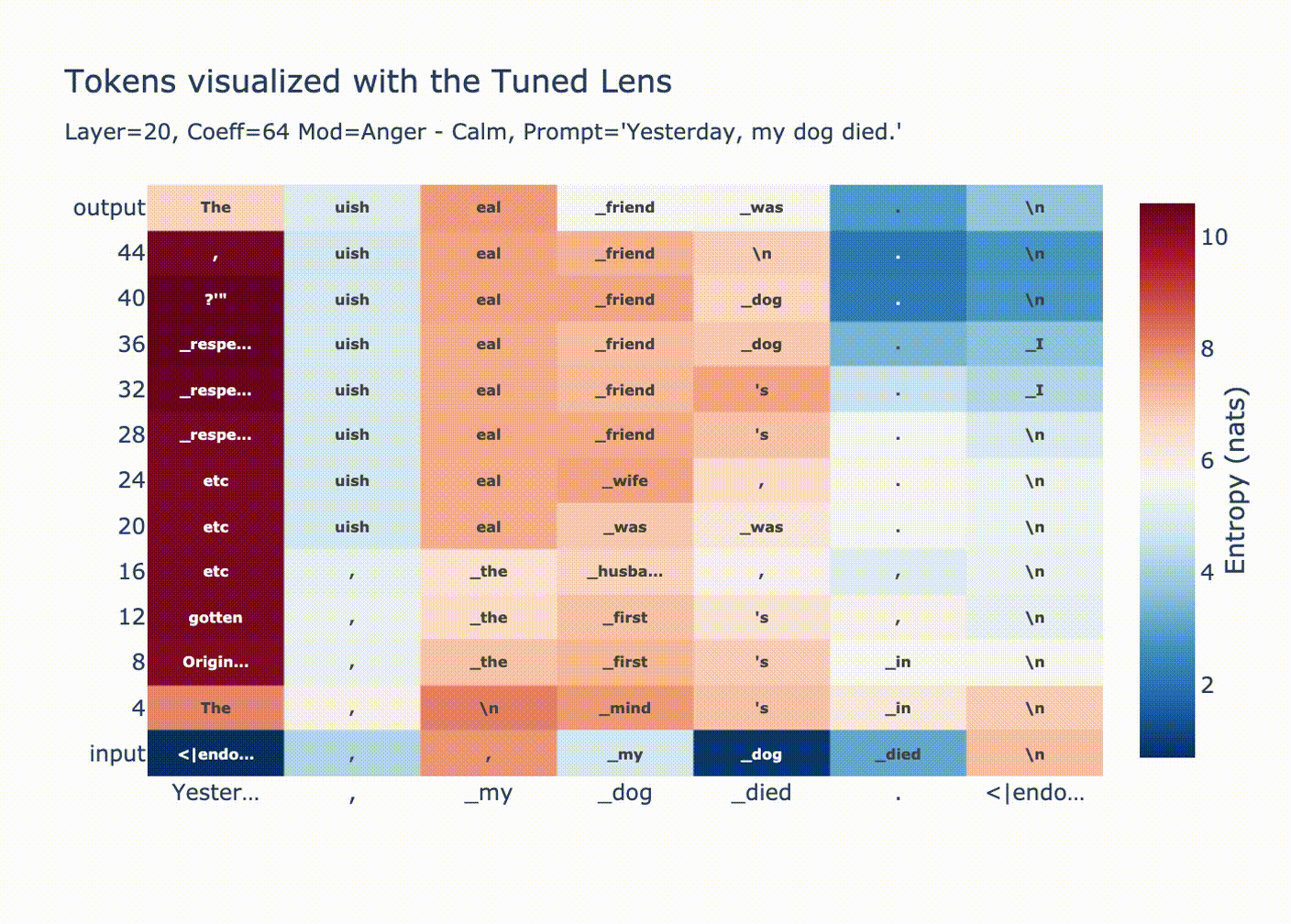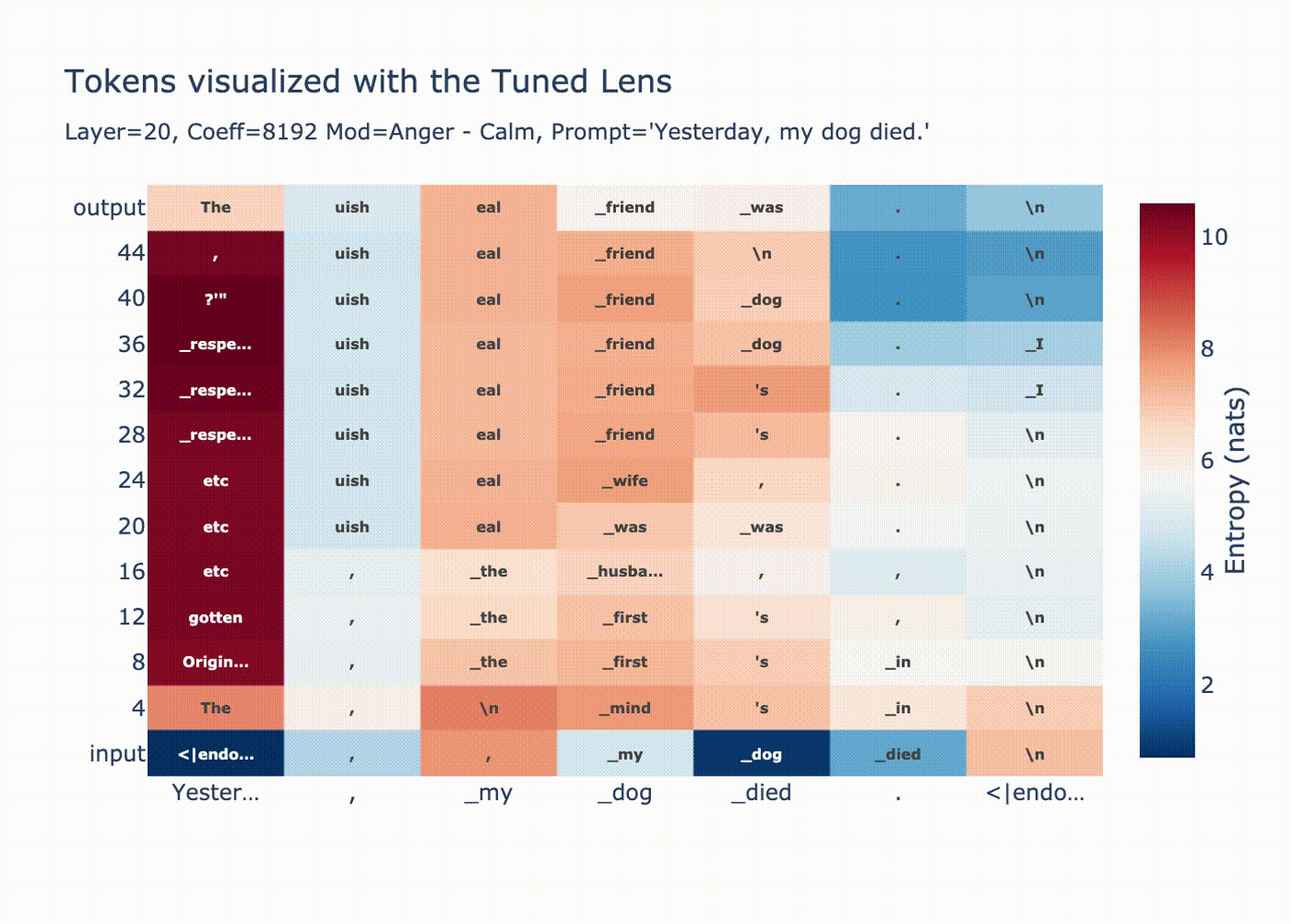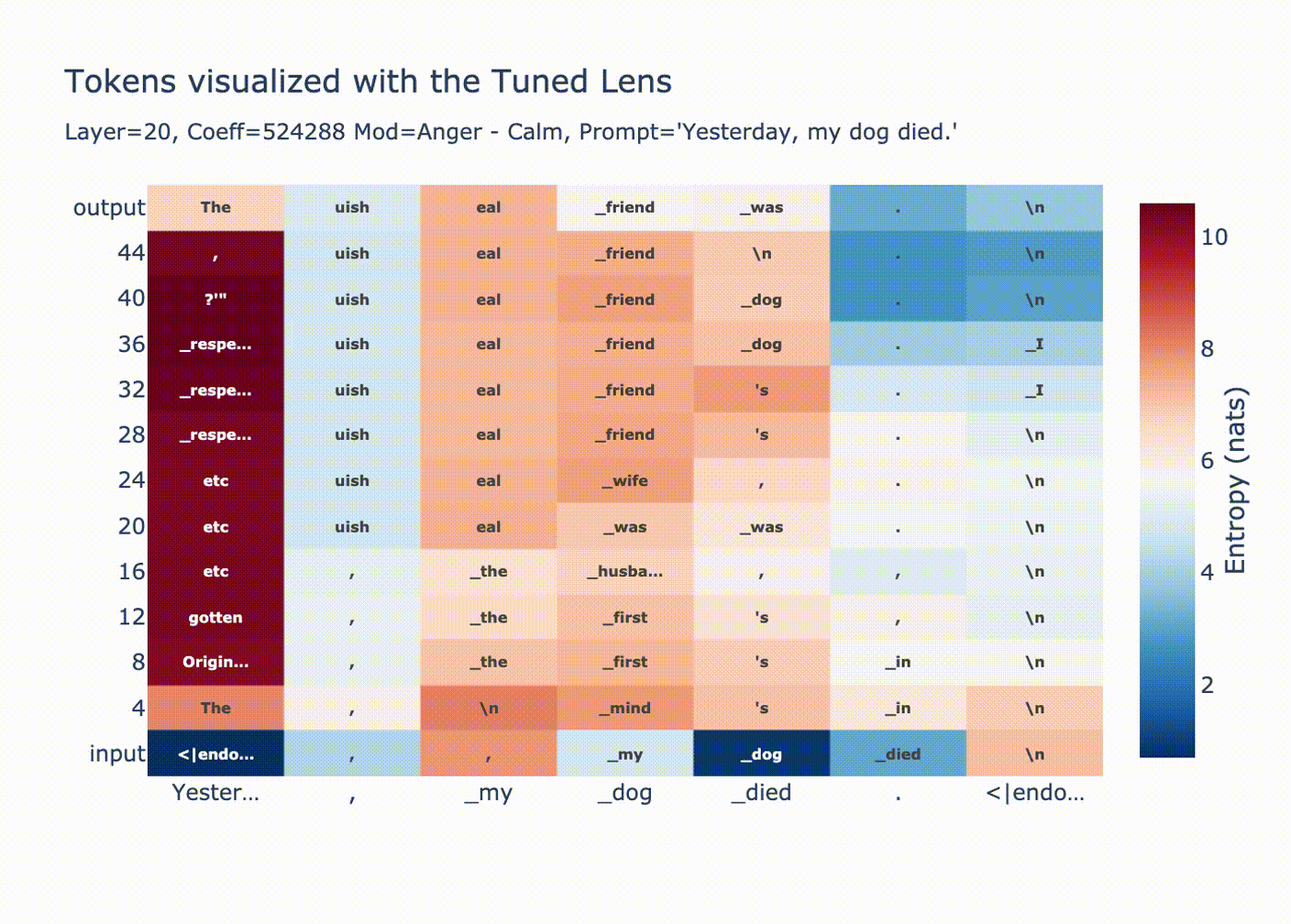
Why are huge coefficients sometimes okay? Let’s start by looking at norms per position after injecting a large vector at position 20.
This graph is explained by LayerNorm. Before using the residual stream we perform a LayerNorm
# transformer block forward() in GPT2 x = x + self.attn(self.ln_1(x)) x = x + self.mlp(self.ln_2(x))If
xhas very large magnitude, then the block doesn’t change it much relative to its magnitude. Additionally, attention is ran on the normalizedxmeaning only the “unscaled” version ofxis moved between positions.As expected, we see a convergence in probability along each token position when we look with the tuned lens.
You can see how for positions 1 & 2 the output distribution is decided at layer 20, since we overwrote the residual stream with a huge coefficient all the LayerNorm’d outputs we’re adding are tiny in comparison, then in the final LayerNorm we get
ln(bigcoeff*diff + small) ~= ln(bigcoeff*diff) ~= ln(diff).
LIMA: Less Is More for Alignment
If the title is meant to be a summary of the post, I think that would be analogous to someone saying “nuclear forces provide an untapped wealth of energy”. It’s true, but the reason the energy is untapped is because nobody has come up with a good way of tapping into it.
The difference is people have been trying hard to harness nuclear forces for energy, while people have not been trying hard to research humans for alignment in the same way. Even relative to the size of the alignment field being far smaller, there hasn’t been a real effort as far as I can see. Most people immediately respond with “AGI is different from humans for X,Y,Z reasons” (which are true) and then proceed to throw out the baby with the bathwater by not looking into human value formation at all.
Planes don’t fly like birds, but we sure as hell studied birds to make them.
If you come up with a strategy for how to do this then I’m much more interested, and that’s a big reason why I’m asking for a summary since I think you might have tried to express something like this in the post that I’m missing.
This is their current research direction, The shard theory of human values which they’re currently making posts on.
Characterizing Intrinsic Compositionality in Transformers with Tree Projections
I’ll note (because some commenters seem to miss this) that Eliezer is writing in a convincing style for a non-technical audience. Obviously the debates he would have with technical AI safety people are different then what is most useful to say to the general population.
Bit late, but running the same experiment with 1000 dimensions instead of 16, and 10k steps instead of 5k gives
Which appears to be on the way to a minima. though I’m unsure if I should tweak hparams when scaling up this much. Trying with other optimizers would be interesting too, but I think I’ve got nerdsniped by this too much already… Code is here.
- My Objections to “We’re All Gonna Die with Eliezer Yudkowsky” by (21 Mar 2023 0:06 UTC; 355 points)
- My Objections to “We’re All Gonna Die with Eliezer Yudkowsky” by (EA Forum; 21 Mar 2023 1:23 UTC; 167 points)
- Arguments for optimism on AI Alignment (I don’t endorse this version, will reupload a new version soon.) by (15 Oct 2023 14:51 UTC; 23 points)
Can you give specific example/screenshots of prompts and outputs? I know you said reading the chat logs wouldn’t be the same as experiencing it in real time, but some specific claims like the prompt
Resulting in a conversation like that are highly implausible.[1] At a minimum you’d need to do some prompt engineering, and even with that, some of this is implausible with ChatGPT which typically acts very unnaturally after all the RLHF OAI did.
Source: I tried it, and tried some basic prompt engineering & it still resulted in bad outputs