“I seem to be having a technical issue.”
cubefox
Karma: 797
Could you please list your relevant object-level arguments for the lab-leak being unlikely?
(Posting a link to an extremely long, almost 17 hours, YouTube debate, and to bets on it based on a judgement of unknown judges, is not very helpful and doesn’t itself constitute a strong counterargument to the lab-leak arguments in this post. This is similar to how pointing to the supposed “winner” of a recent AI risk debate isn’t a strong argument against AI risk.)
Interesting. Claude being more robust against jailbreaking has probably to do with the fact that Anthropic doesn’t use RLHF, but a sort of RL on synthetic examples of automatic and iterated self-critique, based on a small number of human-written ethical principles. The method is described in detail in their paper on “Constitutional AI”. In a recent blog post, OpenAI explicitly mentions Constitutional AI as an example how they plan to improve their fine-tuning process in the future. I assume the Anthropic paper simply came out too late to influence OpenAI’s fine-tuning of GPT-4, since the foundation model already finished training in August 2022.
The latter guideline was inspired by quotes from Ronny Fernandez and Arturo Macias. Fernandez:
No thought should be heretical. Making thoughts heretical is almost never worth it, and the temptation to do so is so strong, that I endorse the strict rule “no person or ideology should ever bid for making any kind of thought heretical”.
So next time some public figure gets outed as a considerer of heretical thoughts, as will surely happen, know that I am already against all calls to punish them for it, even if I am not brave enough to publicly stand up for them at the time.
(He adds some minor caveats.)
Macias:
The separation between value and fact, between “will” and “representation” is one of the most essential epistemological facts. Reality is what it is, and our assessment of it does not alter it. Statements of fact have truth value, not moral value. No descriptive belief can ever be “good” or “bad.” (...) no one can be morally judged for their sincere opinions about this part of reality. Or rather, of course one must morally judge and roundly condemn anyone who alters their descriptive beliefs about reality for political convenience. This is exactly what is called “motivated thought”.
Not a new phenomenon. Fine-tuning leads to mode collapse, this has been pointed out before: Mysteries of mode collapse
Are Intelligence and Generality Orthogonal?
The Xanadu story is indeed a classic full of interesting lessons. Specifically “ship early” is now a platitude in web software development.
But I also have some sympathy for the developers who still dream of finishing Xanadu: From a purely academic perspective, it would be interesting what such a system would look like and whether it could work in any way. It appears to have anticipated some form of DRM (digital rights management) which is now routinely used for things like Netflix.
Xanadu reminds me of “Google Wave“ from 2009: A quite ambitious (though much less ambitious than Xanadu) project which tried to replace email with something much more dynamic and flexible. Wave didn’t succeed, but I think not because Wave was too rigid and overengineered compared to email (it arguably wasn’t), but because email was already firmly established. Any alternative didn’t have the network effect on their side.
This leads me to think: Are there are any exceptions to the Xanadu lessons?
One case is perhaps the computer game “Star Citizen”. It’s an completely overambitious crowdfunding project which is in development for more than a decade. Apparently it is still nowhere near finished, and many think it will never be. But unlike Xanadu, Star Citizen did definitely “evolve” pretty much from the start with its users, who got access to the unfinished game very early on. But dynamically evolving development with the userbase seems not sufficient for a project not to get hung up in unrealistic platonic ideals.
Another case is, perhaps, the invention of the computer. I don’t mean the actual invention(s) during the second world war, but Charles Babbage’s Analytical Engine a hundred years earlier. He mostly just produced elaborate plans, since he didn’t have the financial means of implementing them. So his visionary ambitions didn’t get anywhere. He was mostly forgotten, and computers were set back for a century. But it seems plausible today that his project could well have succeeded at the time if he had access to a substantial engineering and research team. Some projects can apparently only succeed with a ton of antecedent effort, because they simply have (unlike Xanadu with the WWW) no small analogue.
But I generally agree: for most projects the Xanadu lessons seem applicable.
This is a very interesting theory.
Small note regarding terminology: Both using supervised learning on dialog/instruction data and reinforcement learning (from human feedback) is called fine-tuning the base model, at least by OpenAI, where both techniques were used to create ChatGPT.
Another note: RLHF does indeed require very large amounts of feedback data, which Microsoft may not have licensed from OpenAI. But RLHF is not strictly necessary anyway, as Anthropic showed in their Constitutional AI (Claude) paper, which used supervised learning from human dialog data, like ChatGPT—but unlike ChatGPT, they used fully automatic “RLAIF” instead of RLHF. In OpenAI’s most recent blog post they mention both Constitutional AI and DeepMind’s Sparrow-Paper (which was the first to introduce the ability of providing sources, which Sydney is able to do).
The theory that Sydney uses some GPT-4 model sounds interesting. But the Sydney prompt document, which was reported by several users, mentions a knowledge cutoff in 2021, same as ChatGPT, which uses GPT-3.5. For GPT-4 we would probably expect a knowledge cutoff in 2022. So GPT 3.5 seems more likely?
Whatever base model Bing chat uses, it may not be the largest one OpenAI has available. (Which could potentially explain some of Sidney’s not-so-smart responses?) The reason is that larger models have higher inference cost, limiting ROI for search companies. It doesn’t make sense to spend more money on search than you expect to get back via ads. Quote from Sundar Pichai:
We’re releasing [Bard] initially with our lightweight model version of LaMDA. This much smaller model requires significantly less computing power, enabling us to scale to more users, allowing for more feedback.
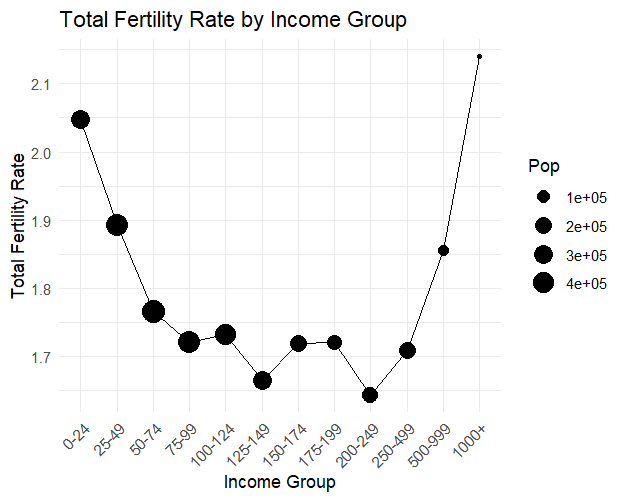
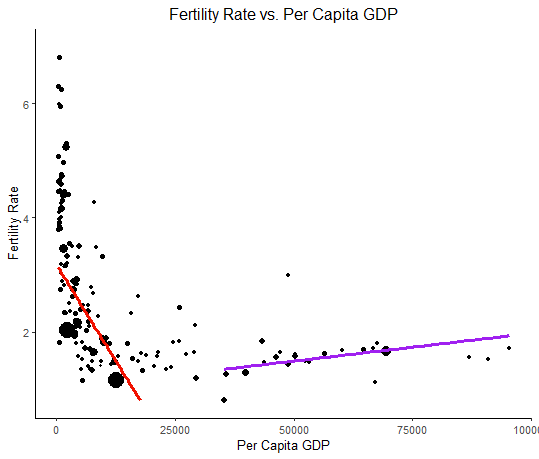
Looking just at an U shaped graph isn’t very informative, as it neglects the relative size of the population. You can actually see from the circle size in your third graph that there are much fewer people on the right side (high income) of the U shape. This doesn’t warrant optimism. One has to actually look at a scatter plot and at the correlation coefficient.
At least on a country level, the correlation between IQ and fertility is strongly negative:
The Pearson correlations between national IQ scores and the three national fertility indicators were as follows; Total Fertility Rate (r = − 0.71, p < 0.01), Birth Rate (r = − 0.75, p < 0.01), and Population Growth Rate (r = − 0.52, p < 0.01). source
This looks very bad.
You also mention data supporting an apparent reversal of the trend in a few high income countries. These aren’t a lot of data points, so I don’t know how strong and significant those correlations are. Probably not very strong, as it includes only 13 data points. Moreover, they don’t include South Korea, which has seen massive decline in fertility. Also note that the chart you include shows two graphs with different y axis scale which makes the fertility in the present look higher than if the scale was the same. Which is somewhat misleading.
You also say that the relationship between fertility and GDP is U shaped, but it rather appears only L shaped, with much more population weight on the left side, which is bad.
I would also highlight that the opportunity cost theory is usually a bit more sophisticated than presented here. The theory is that women tend to determine the decision of whether to have children and prefer to raise them themselves, and that they tend to prefer men with higher income than themselves. So if the woman earns significantly less than the man, her opportunity cost for having children instead of a career is small, because the man is the main breadwinner. If the income of the woman is the same or higher than of her partner, her opportunity cost of having children is high.
This theory says fertility isn’t so much about absolute income, but about relative income between men and women. It explains why more gender egalitarian countries have lower fertility rates: Because the income of men and women is more similar due to women having careers. It also predicts that any possible positive relationship between high percentile IQ and fertility is determined by couples where the man has a higher IQ than the woman, but not the other way round—because the latter case would likely mean that the woman is the main breadwinner, in which case she would be less likely to have children.
{kind=link}
{kind=link}
I’m also confused why Eliezer seems to be impressed by this. I admit it is an interesting phenomenon, but it is apparently just some oddity of the tokenization process.
[Question] Is LLM Translation Without Rosetta Stone possible?
If your discourse algorithm errs on the side of sticks over carrots (perhaps, emphasizing punishing others’ bad epistemic conduct more than most people naturally do), then … what? How, specifically, are rough-and-tumble spaces less “rational”, more prone to getting the wrong answer, such that a list of “Elements of Rationalist Discourse” has the authority to designate them as non-default?
In my mind the Goodwill norm has a straightforward justification: Absent goodwill, most people are prone to view disagreement as some sort of personal hostility, similar to an insult. This encourages us to view their arguments as soldiers, rather than as exchange of evidence. Which leads to a mind-killing effect, i.e. it makes us irrational.
To be sure, I think that some groups of people, particularly those on the autism spectrum, do not have a lot of this “hostility bias”. So the Goodwill norm is not very applicable on platforms where many of those people are. Goodwill is likely a lot more important on Twitter than on Hacker News or Less Wrong.
In general, norms which counter the effect of common biases seem to be no less about rationality than norms which have to do more directly with probability or decision theory.
We may be already doing that in case of cartoon faces with their exaggerated features. Cartoon faces don’t look eldritch to us, but why would they?
A bit tangential: Regarding the terminology, what you here call “values” would be called “desires” by philosophers. Perhaps also by psychologists. Desires measure how strongly an agent wants an outcome to obtain. Philosophers would mostly regard “value” as a measure of how good something is, either intrinsically or for something else. There appears to be no overly strong connection between values in this sense and desires, since you may believe that something is good without being motivated to make it happen, or the other way round.
nicotine is habit-building more than it is directly addictive
This seems doubtful. Various other sources have described nicotine as highly addictive, comparable to various “hard” drugs. Evidence is that coffee drinking also seems “habit building”, but it is empirically much, much easier to quit caffeine than to quit nicotine.
I’ll add that sometimes, there is a big difference between verbally agreeing with a short summary, even if it is accurate, and really understanding and appreciating it and its implications. That often requires long explanations with many examples and looking at the same issue from various angles. The two Scott Alexander posts you mentioned are a good example.
I said similar things before, but I don’t think karma boosts will be enough in the long run. AI alignment by itself is such a big and important topic that it increasingly dominates everything else. It seems likely that the interest in alignment will only grow further as AI becomes more salient in the world, drowning out all the other content. That is, Less Wrong will become more and more a second AI Alignment Forum. The only clean long-term solution I can see is to handle AI in a separate forum, similar to the Effective Altruism Forum.
A way this could be achieved is to allow everyone to post at the Alignment Forum (currently this is not the case) and to encourage people who post AI content on Less Wrong to at least cross post to the AI Alignment Forum. Over time this would probably lead to more and more AI interested people to just post to the Alignment Forum. Currently it is not really possible for AI interested people to just read the Alignment Forum, since many AI posts can only be found on Less Wrong. And the AI Alignment Forum could keep its currently more “exclusive” approach by promoting certain high quality posts.
I think many people are against this because they see AI / AI alignment as a core part of Less Wrong, and in some ways Less Wrong can even be viewed as the cradle of alignment. Historically this is true! But alignment has grown up now, and it needs more space to stand on its own feet. It will get this space one way or another. The question is whether this will occur at the cost of the rest of Less Wrong or not.
Subpopulations which do this are expected to disappear relatively quickly in evolutionary time scales. Natural selection is error correcting. This can mean people get less intelligent again, or they start to really love getting children rather than enjoying sex.
Two reviewers who worried about the weight: Norman Chan, Marques Brownlee.
I would like to propose two other guidelines:
Be aware of asymmetric discourse situations.
A discourse is asymmetric if one side can’t speak freely, because of taboos or other social pressures. If you find yourself arguing for X, ask yourself whether arguing for not-X is costly in some way. If so, don’t take weak or absent counterarguments as substantial evidence in your favor. Often simply having a minority opinion makes it difficult to speak up, so defending a majority opinion is already some sign that you might be in an asymmetric discourse situation. The presence of such an asymmetry also means that the available evidence is biased in one direction, since the arguments of the other side are expressed less often.
Always treat hypotheses as having truth values, never as having moral values.
If someone makes [what you perceive as] an offensive hypothesis, remember that the most that can be wrong with that hypothesis is that it is false or disfavored by the evidence. Never is a hypothesis by itself morally wrong. Acts and intentions can be immoral; hypotheses are neither of those. If you strongly suspect that someone has some particular intention with stating a hypothesis, then be honest and say so explicitly.