Intepretability
Views my own
Intepretability
Views my own
I agree that ChatGPT was positive for AI-risk awareness. However from my perspective being very happy about OpenAI’s impact on x-risk does not follow from this. Releasing powerful AI models does have a counterfactual effect on the awareness of risks, but also a lot of counterfactual hype and funding (such as the vast current VC investment in AI) which is mostly pointed at general capabilities rather than safety, which from my perspective is net negative.
Thanks for writing this. As far as I can tell most anger about OpenAI is because i) being a top lab and pushing SOTA in a world with imperfect coordination shortens timelines and ii) a large number of safety-focused employees left (mostly for Anthropic) and had likely signed NDAs. I want to highlight i) and ii) in a point about evaluating the sign of the impact of OpenAI and Anthropic.
Since Anthropic’s competition seems to me to be exacerbating race dynamics currently (and I will note that very few OpenAI and zero Anthropic employees signed the FLI letter) it seems to me that Anthropic is making i) worse due to coordination being more difficult and race dynamics. At this point, believing Anthropic is better on net than OpenAI has to go through believing *something* about the reasons individuals had for leaving OpenAI (ii)), and that these reasons outweigh the coordination and race dynamic considerations. This is possible, but there’s little public evidence for the strength of these reasons from my perspective. I’d be curious if I’ve missed something from my point.
On one hand wikipedia suggests Jewish astronomers saw the three tail stars as cubs. But at the same time, it suggests several ancient civilizations independently saw Ursa Major as a bear. Also confused.
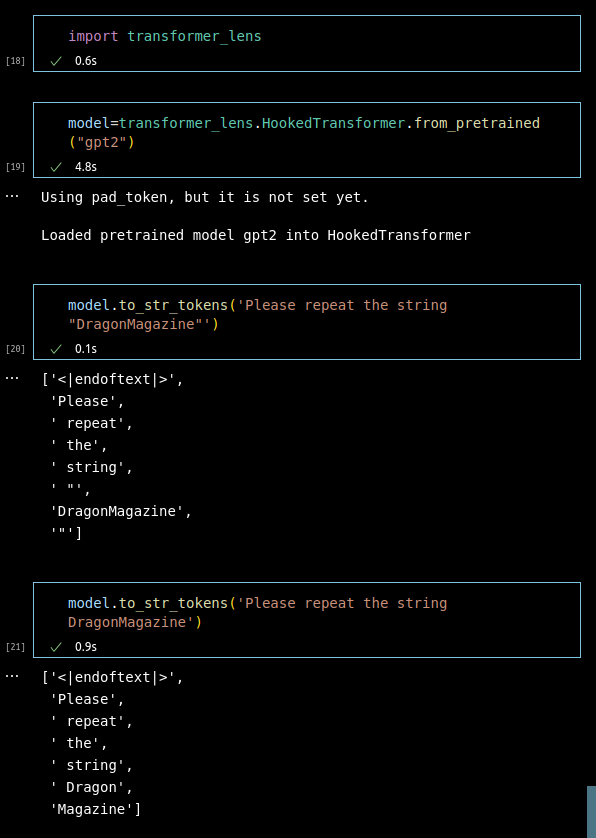
This is because of tokenization. Tutorial about BPE (which OpenAI use) is here. Specifically in this case:
I think your interpretation is fairly uncharitable. If you have further examples of this deceptive pattern from those sympathetic to AI risk I would change my perspective but the speculation in the post plus this example weren’t compelling:
I watched the video and firstly Senator Peters seems to trail off after the quoted part and ends his question by saying “What’s your assessment of how fast this is going and when do you think we may be faced with those more challenging issues?”. So straightforwardly his question is about timelines not about risk as you frame it. Indeed Matheny (after two minutes) literally responds “it’s a really difficult question. I think whether AGI is nearer or farther than thought …” (emphasis different to yours) so makes it likely to me Matheny is expressing uncertainty about timelines, not risk.
Overall I agree that this was an opportunity for Matheny to discuss AI x-risk and plausibly it wasn’t the best use of time to discuss the uncertainty of the situation. But saying this is dishonesty doesn’t seem well supported
I agree that some level public awareness would not have been reached without accessible demos of SOTA models.
However, I don’t agree with the argument that AI capabilities should be released to increase our ability to ‘rein it in’ (I assume you are making an argument against a capabilities ‘overhang’ which has been made on LW before). This is because text-davinci-002 (and then 3) were publicly available but not accessible to the average citizen. Safety researchers knew these models existed and were doing good work on them before ChatGPT’s release. Releasing ChatGPT results in shorter timelines and hence less time for safety researchers to do good work.
To caveat this: I agree ChatGPT does help alignment research, but it doesn’t seem like researchers are doing things THAT differently based on its existence. And secondly I am aware that OAI did not realise how large the hype and investment would be from ChatGPT, but nevertheless this hype and investment is downstream of a liberal publishing culture which is something that can be blamed.
Kudos for providing concrete metrics for frontier systems, receiving pretty negative feedback on one of those metrics (dataset size), and then updating the metrics.
It would be nice if both the edit about the dataset size restriction was highlighted more clearly (in both your posts and critic comments).
How is “The object is” → ” a” or ” an” a case where models may show non-myopic behavior? Loss will depend on the prediction of ” a” or ” an”. It will also depend on the completion of “The object is an” or “The object is a”, depending on which appears in the current training sample. AFAICT the model will just optimize next token predictions, in both cases...?
Are you familiar with the Sparks of AGI folks’ work on a practical example of GPT-4 asserting early errors in CoT are typos (timsestamped link)? Pretty good prediction if not
> 0.3 CE Loss increase seems quite substantial? A 0.3 CE loss increase on the pile is roughly the difference between Pythia 410M and Pythia 2.8B
My personal guess is that something like this is probably true. However since we’re comparing OpenWebText and the Pile and different tokenizers, we can’t really compare the two loss numbers, and further there is not GPT-2 extra small model so currently we can’t compare these SAEs to smaller models. But yeah in future we will probably compare GPT-2 Medium and GPT-2 Large with SAEs attached to the smaller models in the same family, and there will probably be similar degradation at least until we have more SAE advances.
Given past statements I expect all lab leaders to speak on AI risk soon. However, I bring up the FLI letter not because it is an AI risk letter, but because it is explicitly about slowing AI progress, which OAI and Anthropic have not shown that much support for
Thank you for providing this valuable synthesis! In reference to:
4. It is a form of movement building.
Based on my personal interactions with more experienced academics, many seem to view the objectives of mechanistic interpretability as overly ambitious (see Footnote 3 in https://distill.pub/2020/circuits/zoom-in/ as an example). This perception may deter them from engaging in interpretability research. In general, it appears that advancements in capabilities are easier to achieve than alignment improvements. Together with the emphasis on researcher productivity in the ML field, as measured by factors like h-index, academics are incentivized to select more promising research areas.
By publishing mechanistic interpretability work, I think the perception of the field’s difficulty can be changed for the better, thereby increasing the safety/capabilities ratio of the ML community’s output. As the original post acknowledges, this approach could have negative consequences for various reasons.
I think both of these questions are too general to have useful debate on. 2) is essentially a forecasting question, and 1) also relies on forecasting whether future AI systems will be similar in kind. It’s unclear whether current mechanistic interpretability efforts will scale to future systems. Even if they will not scale, it’s unclear whether the best research direction now is general research, rather than fast-feedback-loop work on specific systems.
It’s worth noting that academia and the alignment community are generally unexcited about naive applications of saliency maps; see the video, and https://arxiv.org/abs/1810.03292
When do applications close?
When are applicants expected to begin work?
How long would such employment last?
(This reply is less important than my other)
> The network itself doesn’t have a million different algorithms to perform a million different narrow subtasks
For what it’s worth, this sort of thinking is really not obvious to me at all. It seems very plausible that frontier models only have their amazing capabilities through the aggregation of a huge number of dumb heuristics (as an aside, I think if true this is net positive for alignment). This is consistent with findings that e.g. grokking and phase changes are much less common in LLMs than toy models.
(Two objections to these claims are that plausibly current frontier models are importantly limited, and also that it’s really hard to prove either me or you correct on this point since it’s all hand-wavy)
I’ve tried several times to engage with this claim, but it remains dubious to me and I didn’t find the croissant example enlightening.
Firstly, I think there is weak evidence that training on properties makes opposite behavior easier to elicit. I believe this claim is largely based on the bing chat story, which may have these properties due to bad finetuning rather than because these finetuning methods cause the Waluigi effect. I think ChatGPT is an example of finetuning making these models more robust to prompt attacks (example).
Secondly (and relatedly) I don’t think this article does enough to disentangle the effect of capability gains from the Waluigi effect. As models become more capable both in pretraining (understanding subtleties in language better) and in finetuning (lowering the barrier of entry for the prompting required to get useful outputs), they will get better at being jailbroken by stranger prompts.