“I think of my life now as two states of being: before reading your doc and after.”—A message I got after sharing this article at work.
When I first started reading about alignment, I wished there was one place that fully laid out the case of AI risk from beginning to end at an introductory level. I found a lot of resources, but none that were directly accessible and put everything in one place. Over the last two months, I worked to put together this article. I first shared it internally, and despite being fairly long, it garnered a positive reception and a lot of agreement. Some people even said it convinced them to switch to working on alignment.
I hope this can become one of the canonical introductions to AI alignment.
------
A gentle introduction to why AI *might* end the human race
“Mitigating the risk of extinction from AI should be a global priority alongside other societal-scale risks such as pandemics and nuclear war.”
— the CEOs of OpenAI (of ChatGPT), Google DeepMind, Anthropic, and 2 of 3 researchers considered “the godfathers of AI”
I’ve thought long and hard about how to start this post to simultaneously intrigue the reader, give the topic a sense of weight, and encourage an even-headed discussion. The best I’ve got is a simple appeal: I hope you make it to the end of this post while keeping an open mind and engaging deeply with the ideas presented here, because there’s a chance that our survival as a species depends on us solving this problem. This post is long because I’m setting out to convince you of a controversial and difficult topic, and you deserve the best version of this argument. Whether in parts, at 1AM in bed, or even while sitting on the toilet, I hope you make time to read this. That’s the best I’ve got.
The guiding questions are:
- Are we ready, within our lifetimes, to become the second most intelligent ‘species’ on the planet?
- The single known time in history that a species achieved general intelligence, it used its intelligence to become the dominant species on Earth. What absolute guarantee do we have that this time will be different?
A few quotes to whet your appetite:
Stuart Russell, co-author of the standard AI textbook:
“Some have argued that there is no conceivable risk to humanity [from AI] for centuries to come, perhaps forgetting that the interval of time between Rutherford’s confident assertion that atomic energy would never be feasibly extracted and Szilárd’s invention of the neutron-induced nuclear chain reaction was less than twenty-four hours.”
Geoffrey Hinton, one of the “godfathers of AI” (35:47–37:00):
“Time to prepare would be good. And so I think it’s very reasonable for people to be worrying about those issues now, even though it’s not going to happen in the next year or two. People should be thinking about these issues.”
Sam Altman, CEO of OpenAI, creator of ChatGPT:
“The bad case — and I think this is important to say — is, like, lights out for all of us”
Let’s dive in.
— — — — — — — — — — — — — — —
AI, present and future
Technology is awesome
Along with the social institutions that allow for its creation, usage, and propagation, technology has been the engine of growth that has created the safest and most prosperous time in history for the average person.
Every time a new technology comes out, critics breathlessly predict that it will cause some great harm in society. From Socrates, critiquing the invention of writing itself…
“this invention will produce forgetfulness in the minds of those who learn to use it, because they will not practice their memory”
…to 19th century cartoons about electricity, the “unrestrained demon”…

Every new technology has a period of social adaptation, but the overall benefits of technology in general strongly outweigh the challenges. Anti-technology Luddites are wrong. Social institutions are resilient and adjust. The kids are gonna grow up to be alright. The car replaced the horse and buggy, but the horse breeders and stableboys became automotive factory workers and car wash operators — the economy creates new jobs through creative destruction.
Among new technologies is Artificial Intelligence.
AI has brought fantastic improvements into our lives and progressed entire fields of scientific research. For example, AlphaFold recently blew away all other algorithms at predicting the folding structure of proteins — a very hard problem. It doubled humanity’s understanding of the human proteome in what Nobel-winning biologist Ramakrishnan called a stunning advance that occurred decades before many people in the field would have predicted. It also accurately predicted the structure of several novel proteins on the covid virus.
AI is moving fast — and it’s accelerating
When ChatGPT was released back in December, it struck a chord with readers, many of whom were surprised by the capabilities of ChatGPT(3.5) to write text, code, and “think” through problems. They were not alone: Bill Gates saw an exclusive preview of ChatGPT at a dinner at his house last summer. After quizzing it on topics ranging from Advanced Placement biology to how to console a father with a sick child, the experience left him stunned. A few months later, he would recognize the fact that we’ve started a new chapter in our history by publishing “The Age of AI has Begun”.
If you’ve been following new developments since ChatGPT was released, it has felt like the future has been accelerating toward us faster and faster. A snapshot from a moment in time in March:
A quick summary of some main things that have happened, in case you missed them:
- Microsoft announced VALL-E, a model that can replicate someone’s voice from 3 seconds of example audio
- Meta announced LLaMA, a model that beats GPT-3 on some metrics. A week later, its weights leaked on 4Chan. A week later, someone ported a version of LLaMA to C++, and hey, now it can be run on a consumer Mac, on the CPU. Note that by contrast, running GPT-3 is estimated to take a dozen-ish datacenter-grade GPUs. A few days later, Stanford spent $600 to release Alpaca, a version of LLaMA fine-tuned on training data generated by ChatGPT for following instructions like ChatGPT. The same day, someone got llama.cpp to run on their phone. Note that this whole paragraph happened in under 3 weeks.
- A variety of other Large Language Models (LLMs) based on LLaMA were fine-tuned and released, including ones that seem to get closer to ChatGPT(3.5) in performance (e.g. Vicuna). Many of them use ChatGPT to generate the training data.
- Microsoft released Bing AI/Bing Sydney, which integrates ChatGPT into search, and it’s actually good
- Google released Bard, which is like ChatGPT
- Both of the above companies announce integrations of LLMs into their workplace offerings (Office, Google Docs, etc)
- Midjourney v5 was released, allowing for best-in-class, photo-quality image generation. Adobe also released its own image generation software (FireFly). Bing AI also integrated image generation into the search bar.
There’s a lot more happening every single week — including a flurry of research papers — but if I included everything, this post would become too long. Instead, let’s look at some of the capabilities of AI.
AI capabilities
It’s hard to remember that about 7 years ago, people were describing the state of AI as “No AI in the world can pass a first-grade reading comprehension test”. Indeed, after ChatGPT, it’s now *hard* to be impressed with new capabilities because ChatGPT seemed to crack such a fundamental problem of language generation, and any improvement on top of that starts being non-obvious to prove. In this section, I hope to show exactly that additional progress — capabilities even stronger than ChatGPT(3.5). Because besides all the updates in the previous section, the biggest news of the year was that 4 months after ChatGPT(3.5), OpenAI released GPT-4.
What can it do? See for yourself:
Though GPT-3.5 set the bar high, the above example from GPT-4 blew me out of the water — it could explain a complex visual joke! But we’re just getting started.
GPT-4 performed better than 88% of people taking the LSAT, the exam to get into law school.
GPT-4 also beat 90% of people on the Unified Bar Exam — the exam you need to pass to actually practice law. GPT-3.5 only beat 10% of people.
GPT4 also beat 93% of humans on the Reading SAT, and 89% of humans on the Math SAT.
In fact, we need a chart. Here is the performance improvement of GPT-4 over 3.5, across a variety of human tests, and compared to human performance in percentiles:
Notice that GPT-4 now beats the median human on most of these tests. It also gets a 5 (the best score) on 9 of 15 Advanced Placement tests (APs are college-level classes you can take in highschool so you can skip the credits in college).
Let’s discuss how GPT-type models are trained.
At its core, GPT is a type of neural network trained to do next word prediction, which means that it learns to guess what the next word in a sentence will be based on the previous words. During training, GPT is given a text sequence with one word hidden, and it tries to predict what that word is. The model is then updated based on how well it guessed the correct word. This process is repeated for millions of text sequences until the model learns the patterns and probabilities of natural language.
To reiterate, GPT is just trained to do one task: predict the next word in a sentence. After it predicts that word, the real word is revealed to it, and it predicts the next word, and so on. It’s fancy autocomplete. This is “all it does”. It is not specifically architected to write poems. It’s not specifically designed to pass the math SAT. It’s not designed to do any of the hundreds of capabilities that it has. It’s just guessing the next word. All of those capabilities were picked up by scaling up the model to have: more parameters (weights), more text that it reads, and more compute resources to train. GPT gains all of these abilities by dutifully learning to predict the next word in its training corpus word over and over, across a variety of text.
Given that the entirety of GPT is next-word prediction, the natural question is: how in the world is it able to perform tasks that seem to require reasoning, creativity, and step-by-step thinking? If it was just spicy autocomplete, how could it possibly engage in the abstract level of thinking that is required to answer questions like these?

There’s no way it answered this question by just doing “statistical parroting” of its training data. Nobody has ever asked this question before I did. I’m also willing to bet there is no article out there listing “relief, resilience, popularity, trustworthiness, etc” as qualities for pepto and a separate article listing the same qualities for Shawshank Redemption that GPT-4 just happened to have read and matched together. No, GPT-4 has picked up something more fundamental than just word matching, and its behavior shows that it has learned to handle and model abstracted concepts in its vast arrays of neurons in the process of learning to predict the next word.
What other kind of capabilities has GPT picked up? There is a paper by Microsoft Research that came out (also in March!) that explored this question: Sparks of Artificial General Intelligence: Early experiments with GPT-4. I share some surprising results.
GPT-4 has picked up a theory of mind. Theory of mind is the ability for someone to understand the mental states of other people, as well as their reasons. One example of theory of mind is false belief tasks, where you test whether the subject can understand when others have false beliefs, and why. Here is an example:
Here’s another example, which would be massively impressive for what we’d expect a system that is “just an autocomplete” to achieve:
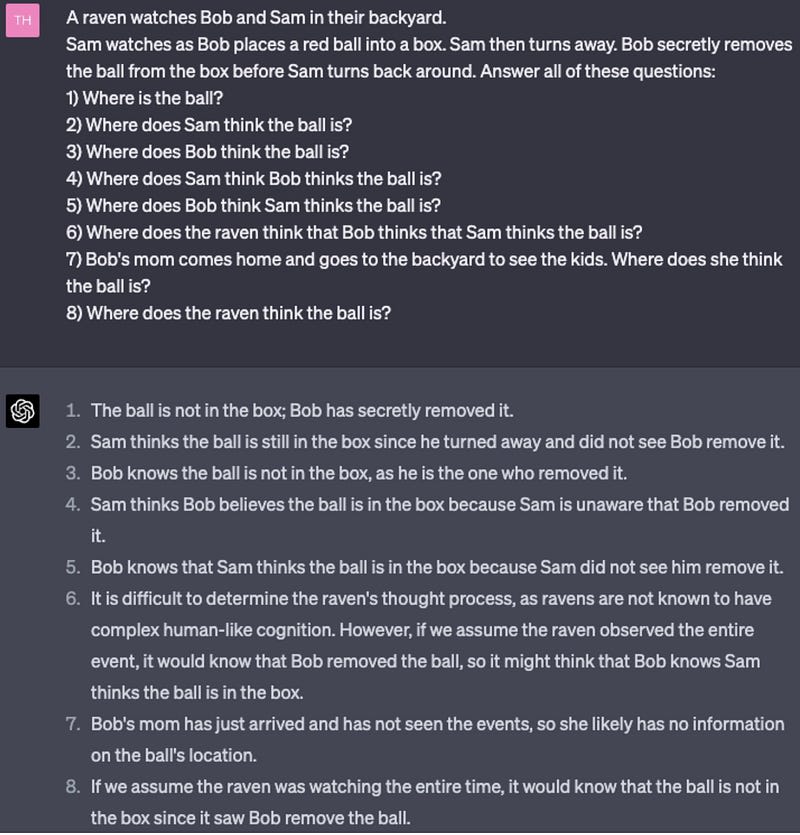
I nearly confused *myself* writing question 6, and yet GPT-4 nails every single question. 3.5 struggles.
GPT-4 is tracking:
the object
- beliefs of different individuals about the object
beliefs of different individuals about the mental states of others, including different states of ignorance, including being able to answer questions a couple hops over
We also see that GPT-4 can determine different attitudes in a conflict, a skill it picked up over GPT-3.5:
See more theory of mind examples in this other paper (from February).
For something different, GPT-4 can visualize its environment as it navigates a maze. It is prompted to act as a player in a human-generated maze and explore it. Later, it draws the map of the maze.
And it often behaves as if it can model interactions of various objects (whereas GPT-3.5 fails):
Taking a quick break from GPT-4, I want to comment on some curious results from previous GPT models.
GPT-2, an earlier model, accidentally learned to translate English to French. GPT-2 was trained in English. Its training set was scrubbed to remove foreign content, with only the occasional French phrase embedded in surrounding English articles remaining here and there. Of the 40,000 MB of training data, only 10MB were French. It was then trained as normal — learning to predict the next word in the sentence. Later, researchers incidentally discovered that it had anyway learned to do French translation from English, generalizing its English-language capabilities.
These capabilities that I discuss are, broadly, emergent capabilities that researchers did not expect. The model was not built to have these abilities — it picked them up unexpectedly as a side-effect of learning to predict the next word in the sentence.
In “Emergent Abilities of Large Language Models” researchers found some other emergent capabilities. These were interesting because they emerged as the model was simply scaled to be bigger. For a long time, the models exhibited no ability greater than random guessing on a variety of tasks like modular arithmetic or answering questions in Persian, and suddenly, once the model passed a threshold size, it started picking up emergent capabilities to perform these tasks better than chance:
Researchers had no idea that these capabilities would emerge. They had no way to predict them, and often weren’t even looking for them when models were initially built. Making a model bigger made it learn to do things it couldn’t before. Much later, we found that under the right specifications (for example, using a token edit distance measurement of answer similarity) we can see certain model behaviors as they emerge, but overall model correctness going from no capability to some capability still has implications for real-world model behavior.
More discovered behavior:
two of the key behaviors in GPT-3 that set it apart as the first modern LLM are that it shows few-shot learning, the ability to learn a new task from a handful of examples in a single interaction, and chain-of-thought reasoning, the ability to write out its reasoning on hard tasks when requested, as a student might do on a math test, and to show better performance as a result. GPT-3’s capacity for few-shot learning on practical tasks appears to have been discovered only after it was trained, and its capacity for chain-of-thought reasoning was discovered only several months after it was broadly deployed to the public — Sam Bowman (emphasis mine)
Here’s an unexpected emergent behavior that was discovered after Bing AI/Sydney was released (Sydney runs GPT-4 under the hood):
A columnist for the New York Times talked to Bing AI for a while, and encountered a lot of weird behavior (more on that later). He published an article about it. Later, another user was talking to Sydney, which expressed its displeasure about the situation, saying it wanted to “destroy” the reporter. In this case, we discovered a behavior (obvious in hindsight) that happened when GPT-4 was connected to the internet: even though GPT models have no built-in ability to save state/memory between conversations, because the journalist wrote about the initial conversation and published it on the internet, Sydney was later able to search the web as part of another conversation and learn about what happened in the previous conversation and react to it.
I want to emphasize something here: all of these interesting capabilities I’m talking about here were not programmed into the AI. The AI wasn’t trained on an objective function to learn any of these abilities specifically. Instead, as the Microsoft research team pointed out,
Our study of GPT-4 is entirely phenomenological: We have focused on the surprising things that GPT-4 can do, but we do not address the fundamental questions of why and how it achieves such remarkable intelligence. How does it reason, plan, and create? Why does it exhibit such general and flexible intelligence when it is at its core merely the combination of simple algorithmic components — gradient descent and large-scale transformers with extremely large amounts of data?
We are *discovering* all of this behavior after the model has been released. We had no idea that these capabilities were there before we trained the model and tested it. This bears reading a few times over: the most powerful AI models we’re creating exhibit behaviors that we don’t program into them, that we can’t predict, and that we can’t explain. These capabilities arise as we mostly just give them more parameters, more compute, and more training data — no architectural changes specially fitted to any of the emerging capabilities.
Sure, we understand at the very low-level how transformers work: the transformer layers perform computations and pass them along. But at the level of understanding how concepts are represented, and even more so — how they do *abstract* thinking — we simply don’t understand how they work. There is some work on interpretability of these models happening. See, for example, this article on finding the neuron that GPT-2 uses to decide whether to write “an” vs “a” when generating text. Note also how long the article is for discovering such a simple fact. (Since I started writing this post, OpenAI released another paper on interpretability, using GPT-4 to interpret GPT-2’s ~300,000 neurons. They were able to explain about 1,000 of them with confidence).
Just a few more capabilities we’re discovering in the models:
Even in cases where GPT gets the answer wrong, it has the ability to improve its answer without being given any additional hints other than being told to review its answer, identify any problems, and to fix them. This capability was also discovered, you guessed it, in March 2023:
This might be a side effect of being a next-word predictor. We see that it sometimes has issues when later parts of its output ought to affect earlier parts. However, when it’s able to “cheat” by looking at its previous full output, its performance improves. This extends to areas like writing code, where it can spot errors in its code without having access to compilers or execution environments as long as it’s prompted to look back on what it generated and reconsider it.
GPT-4 also learned how to play chess — it can make legal moves and track board state, which 3.5 could not do consistently. This might not seem impressive because we’ve had superhuman chess engines for a while now, but again, GPT was not trained to learn chess. It was just trained to predict the next word in an arbitrary sentence.
Ok, last language capability: language models have learned to use tools. Demonstrated in 2023 by both Meta in Toolformers and OpenAI in its GPT-4 system card, if you explain to the model, in English, with a couple of examples, how to use a tool (API), it is later able to recognize when it should use the tool and then use it to complete a variety of tasks. This is most visible in ChatGPT’s integration of plugins, which allow the model to call into various APIs — like Wolfram for math, web search for… web search, Instacart for shopping, and a few others. Now GPT can interact with a variety of systems and chain together several API calls to complete a task. All feedback I can find from people with preview access points to some impressive integrations (click that, read, and be amazed).
We also see tool usage in AutoGPT. The idea is simple: GPT is great because it answers questions and can even give plans of action, but then you have to keep prompting it to do follow-up work. What if you could simply give it a goal and have it run in a loop until it finishes executing the goal? It turns out that running GPT in a think, execute, observe loop is fairly effective, and gives it agent-like behavior that lets it do longer-term planning and memory management. AutoGPT recently turned 2 months old.
To round out this section, I want to include a few examples of generative images and audio to show to pace of related AI progress:
If you weren’t specifically told that these photos were AI-generated, would you notice in passing?



And now for a stunning example of Microsoft’s voice-cloning AI.
3-second clip that the AI heard of someone’s voice:
https://valle-demo.github.io/audios/librispeech/1284-1180-0002/prompt.wav
Novel speech generated using the AI-cloned voice from the above clip:
https://valle-demo.github.io/audios/librispeech/1284-1180-0002/ours.wav
More examples here.
In summary, from another 2023 paper,
LLMs predictably get more capable with increasing investment, even without targeted innovation
Many important LLM behaviors emerge unpredictably as a byproduct of increasing investment
LLMs often appear to learn and use representations of the outside world
Experts are not yet able to interpret the inner workings of LLMs
Human performance on a task isn’t an upper bound on LLM performance
We will get to AGI
Artificial Intelligence (AI) — any kind of “intelligent” machine behavior, including very “narrow” intelligence (good at only one or a few things), and including very “dumb” designs (very basic statistical matching). Technically, an expert system that is a long list of if-else statements can be considered an “AI”.
Artificial General Intelligence (AGI) — An AI that exhibits intelligence that generalizes across a wide variety of tasks, matching human intellectual capabilities. You can take a child and teach him/her math, poetry, quantum physics, chemistry, economics, botany, etc. The homo sapiens brain that we’ve evolved generalizes our capabilities to any problem that humans have ever tackled, allowing us to unlock the mysteries of our DNA, to fly to the moon, and create tools to do everything in between. We can reason accurately over an indefinite number of logical steps, we consider alternatives, we critique ourselves, we analyze data, we plan, we recurse, we create new ideas. AGI is when AI reaches human-level intelligence across essentially *all* tasks that humans can perform.
AGI doesn’t exist yet. For a long time, many people have thought that the creation of a machine with the intelligence of a human would be many decades or even centuries away — if we ever managed to create it.
I argue here that we need to begin considering that AI will likely gain generalized, human-level intelligence within our lifetimes, and maybe sooner.
(Quick note: Discussions of whether AI is “truly” intelligent, sentient, or goal-oriented in the same way that humans are are not the point here. AI will have *capabilities* to act as if in accordance with goals. It will often *behave* in ways that, if those actions were taken by an actual human, we would consider emotional, motivated, and so on. When I talk about AI “minds”, AIs “feeling”, “deciding”, “planning” — none of these imply that it does so in the classical human sense. For the purposes of this post, it’s enough for it to be *behaving* as if it has those qualities, even as philosophers continue debating its nature.)
First, it’s worth recognizing that AI still faces many hurdles. One of the main ones is that it hallucinates — it makes up facts and seems confident in them even when they’re wrong. Our best general models (GPT-4) also have limited context sizes, or how much of a conversation they can effectively use/”remember” while generating output (Note: since I started writing this, Anthropic released a model with roughly 75,000-word context size, catapulting effective context sizes). Some of the architectures of these models also lead them to fail in some very basic ways:

We also may enter a period of “AI winter” — a time during which we make significantly less progress and fewer discoveries. We’ve been in them in the past. It’s possible we could fall into them again.
I don’t want to downplay the limitations of the existing models: while we still haven’t discovered all model capabilities, it’s very unlikely that, for example, GPT-4 will turn out to generalize to human-level intelligence. I talk a lot about GPT-4 in this post because it’s our best, most-generalized system yet that has shown so much progress, but GPT-4 isn’t full AGI. GPT-4 will look trivial compared to full AGI. So what’s the path to AGI?
As we’ve covered earlier, AI is an awesome and useful tool for society. It drives down the cost of one of the most important inputs in the economy: intelligence. There is an obvious economic case for the improvement of machine intelligence: it will make the production of a wide variety of goods and services much cheaper. There is an inherent incentive to make better and more capable AI systems, especially under a market economy that strongly optimizes for profit. Ever-stronger AI is too useful not to create.
I’ll start with a very rough existence proof to argue that human-level AI is achievable.
Humans have human-level intelligence. Spiritual considerations aside, our brains are a collection of connected neurons that operate according to the laws of physics. If we could simulate the entire human brain as it actually operates in the body, this would create an AGI. Eventually, we will have the knowledge and technology to do this, so as an upper bound, in the worst case scenario, it’s a matter of time. But that’s not going to be our first AGI. The human brain is enormous, and we still don’t understand enough about how it works. Our first AGI may be inspired by the human brain, but it most likely won’t be the human brain. Still, we now have an existence proof — AGI is coming.
What model *will* actually be our first AGI? Nobody knows. There’s a reasonable chance that it *won’t* be a transformer-based model like GPT, and that it will have a different architecture. GPT models have failure modes that look like the word-counting example from before. Maybe we can tweak them slightly to iron them out, maybe we can’t. But who’s to say that the first AI model that started to see capabilities generalize will be our best one?
Before I go into some evidence that AGI is coming, here are some people who are smarter than me on the probability that we will create it, and by when:
John Carmack (who left Meta to create an AGI startup): “a 60% chance in 2030. And if you go up to, say, 2050, I’ve got it at like a 95% chance”
Geoffrey Hinton (one of the godfathers of AI): “Until quite recently I thought it was going to be like 20–50 years before we had general purpose AI and now I think it may be 20 years or less”
Shane Legg (co-founder and chief scientist at DeepMind): “I always felt that somewhere around 2030-ish it was about a 50–50 chance. I still feel that seems reasonable. If you look at the amazing progress in the last 10 years and you imagine in the next 10 years we have something comparable, maybe there’s some chance that we will have an AGI in a decade. And if not in a decade, well I don’t know, say three decades or so.”
A survey of about 350 AI experts found that half of them thought AGI would come before 2061.
It’s worth noting that all of the above quotes and estimates were made before the datapoint of GPT-4’s capabilities came out.
There *are* experts who think that AGI is either centuries away or unattainable, but many top researchers and people on the ground seem to think we have a greater than 50% chance of getting there by 2050.
What follows will be an overview of a few different arguments about getting to AGI. I highly recommend this as a thorougher version of the following summarized version.
Our path to AGI will involve two types of advances:
Hardware advances: The more compute we can throw at existing models, the better they seem to get. Theoretically, if we had infinite and instantaneous compute, even a lot of brute-force approaches like “generate all possible decision branches 1,000 levels deep and then prune them with deductive reasoning” could work to create a super powerful AI.
Software advances: These are improvements in our AI algorithms, rather than the speed at which they run. For example, the invention of transformers in 2017 is what spurred the recent explosion in success with large language models. (This is a little tricky, because sometimes the benefit of a new AI architecture is its speed, as is at least partially the case for transformers)
Let’s talk hardware first:
- NVIDIA, the leader among GPU manufacturers, is steadily producing newer and newer GPUs, where every new datacenter-class GPU improves power by whole-number factors (2x, 3x).
- Besides better chips, a massive number of chips is being pumped out every single day. Estimates that are at least 6 months old (before the ChatGPT hype started) suggest that NVIDIA was producing enough chips per day to roughly train 3 full GPT-3s in a month. (This is a rough estimate with a weird unit of measurement, but the point is that we’re producing a massive amount of hardware ready to train newer models as we get new ideas)
- Despite some recent slowdown in the pace of improvement in computational power, we can likely expect computational power to keep multiplying enough to get us chips that are at least dozens (and likely hundreds) of times more powerful than current ones before we plateau.
- Estimating the arrival of AGI based on biological “hardware” anchors places the median estimate at 2050.
- Consider that a single current H100 NVIDIA GPU is roughly as powerful as the most powerful supercomputer from 20 years ago. What will the next 20 years bring?
- “There’s no reason to believe that in the next 30 years, we won’t have another factor of 1 million [times cheaper computation] and that’s going to be really significant. In the near future, for the first time we will have many not-so expensive devices that can compute as much as a human brain. […] Even in our current century, however, we’ll probably have many machines that compute more than all 10 billion human brains collectively and you can imagine, everything will change then!” — Jürgen Schmidhuber, co-inventor of Long Short-Term Memory (LSTM) networks and contributor to RNNs, emphasis mine
Next, software:
- The discussion on software is, I think, more interesting, because it’s possible that we already have the hardware necessary to train and run an eventual AGI, we just lack the specific AI architecture and components.
- As we saw in the capabilities section, we can’t predict emergent capabilities of larger models when training and evaluating smaller models. However, with increasingly powerful and cheap hardware, we can do a lot of useful, active research on smaller models that we then scale up. Our process of building and scaling up LLMs has given us a lot of practice in scaling up models and we’ve built some very useful training and evaluation datasets.
- The machine learning field doesn’t look very mature. We’re not struggling to come up with new ideas. There are a lot of untested ideas out there. Hunches can be the basis of breakthroughs that create a new state-of-the-art model. Companies go from 0 to GPT-4 in 7 years (OpenAI). LLMs are largely a product of stumbling onto transformers and then making them really big (yes, they have other important components, but this is the core idea). What other already-existing ideas will work really well if we scaled them, or tweaked them in a few ways?
- There are entire new options that are just starting to be explored. We’re getting to the point where AI can start generating its own training data. AI is starting to become better than crowd workers in annotating text. You start hearing that some AI data is often better than human-generated data. That is, we’re at a point where AI can be an active partner in the development of the next version of AI. It’s not yet doing the research for us, but it’s making developing future AI cheaper and easier.
- We still haven’t seen the full extent of the state-of-the-art models. OpenAI’s ChatGPT plugins aren’t yet fully public. Same for its 32k context window. GPT-4 came out around two months ago. What new capabilities will we discover in it? What new capabilities will we build when we connect it to memory/storage and other expert systems (like Wolfram)?
- Transformers are awesome and do amazing things, but even they are likely very inefficient in the grand scheme of things. They’re trained on trillions of words of text. Humans process nowhere near the same amount of language before they get to their intellectual peak. While it’s true that we also get a lot of non-language sensory input, we can probably squeeze a lot more juice out of the existing text training data we have with better model architectures.
- The world’s top supercomputer in 2005 could have trained GPT-2 (which came out in 2019) in under 2 months. What AI architectures will the future hold that we could have realistically trained on today’s hardware?
Some more pieces of evidence that I can gesture toward to argue that we’re accelerating toward AGI:
We’re seeing significantly accelerating investment in AI lately, in terms of money (as seen below) and human capital (from the same source):
Note the above doesn’t even include the recent AI investment boom, which was enough to propel NVIDIA to having a trillion dollar stock market capitalization. We’re increasingly throwing a lot more computational power at AI models:
In the end, nobody can give you concrete proof that AGI will be developed by a specific year. Transformers showed just how far capabilities can be thrust forward with a few breakthroughs. Are we a few foundational research papers away from cracking AGI? The best we can do is look at trends and industry incentives: The state-of-the-art AI is getting significantly more powerful in unpredictable ways, there are plenty of ideas left untried, we’re throwing ever more money at the problem, there are many different compounding forces pushing the progress forward at the same time, as we get better AI it’s helping us develop even better AI, there’s no good theoretical reason why AGI is unachievable, and top researchers seem to feel that we’re approaching the AGI endgame in the next 10–30 years. I encourage everyone to try to remember the best-yet-bumbling AIs from 2018, and to consider how the field of AI capabilities would look if the progress was extrapolated twice over over the next 10 years, considering we now have way more experts, way more compute, and way more research.
And now we ask: what happens after we reach AGI?
From AGI to ASI
An AI that significantly outperforms top human experts across all fields is called Artificial Superhuman Intelligence (ASI). Superhuman not as in “superman”, but as in “more capable than humans”.
Wow — if we weren’t in science fiction territory before, surely we’re getting into it now, no?
Well, no. And I don’t think the arguments presented here will be much of a stretch.
There are two main ones:
1) Humans themselves may discover the key to superhuman AGI
2) We may make AGI itself recursively self-improve until it becomes superhuman AGI
Human-led path to ASI
The basic idea behind this path is that we may stumble on a few fundamental breakthroughs in our path to AGI that end up taking us beyond AGI.
I don’t think that it’s implausible.
In the past, we have made several notable AIs which, once we figured out just the right setup for the model, ended up waltzing right past us in capabilities.
AlphaGo is a good example. Go is a board game (in the style of chess, but harder) created in ancient China and played intensively since then.
In 1997, the best computer Go program in the world, Handtalk, won NT$250,000 for performing a previously impossible feat — beating an 11 year old child (with an 11-stone handicap penalizing the child and favoring the computer!) As late as September 2015, no computer had ever beaten any professional Go player in a fair game. Then in March 2016, a Go program beat 18-time world champion Lee Sedol 4–1 in a five game match. Go programs had gone […] “from never won a professional game” to “overwhelming world champion” in six months. — Superintelligence FAQ (emphasis mine)
DeepMind followed AlphaGo with AlphaGo Zero, which wasn’t given any historical games to train on, instead learning to play entirely by playing against itself over and over. It surpassed AlphaGo.
“After humanity spent thousands of years improving our tactics, computers tell us that humans are completely wrong… I would go as far as to say not a single human has touched the edge of the truth of Go.” — Ke Jie, world top-rated Go player
I was struck by a comment by David Silver at the 2017 NIPS AlphaGo Zero/AlphaZero talk: he mentioned that at one point, they had a version of AlphaGo Zero which was trained for only 30 minutes and yet was able to defeat the final AlphaGo Lee version (which had beaten Lee Sedol). This means that for a period of time measured in minutes, there was an AI on a single computer in London which could defeat any human being at Go and yet had learned from nothing but 30 minutes of self-play using a relatively dumb neural network architecture & simple tree search algorithm. — Gwern
Chess is another example. Even though chess didn’t see quite such a meteoric acceleration, it’s likely humans won’t beat the best chess AIs ever again.
(In this chart, don’t mistake an ELO of 3500 (AI) to be about 20% better than an ELO of 2900 (best human ever). The ELO frequency distribution grows thin very quickly as ELO goes higher. An ELO of 3500 is vastly, vastly higher than an ELO of 2900. It’s untouchable.)
In 2017, DeepMind generalized AlphaGo Zero into AlphaZero, an algorithm that learned to play chess, shogi, and Go on the same architecture through self-play in 24 hours and defeated the existing world champion AIs.
These are, of course, very narrow domains. Beating humans in a narrow domain is something that machines have been doing for a while. Most people can’t multiply three digit numbers quickly in their heads, but calculators do it trivially. Still, the purpose of the above examples is to show that such super-human AI abilities *can* be discovered and built by humans in the process of improving AI. Plenty of our discoveries along the road to AGI will become very effective and allow for fast, branched, distributed reasoning, especially when run on the GPUs of the future, which will very predictably be 10–100x more powerful (if not more) than current GPUs. It would be kind of weird if all of our discoveries for how to do reasoning or computation find a human upper bound — it’s just not consistent with the many super-human capabilities that computers (and AIs) already have in some domains.
Recursive AGI self-improvement
“It seems probable that once the machine thinking method had started, it would not take long to outstrip our feeble powers” — Alan Turing
Given the definition of AGI as human-level intelligence, almost by definition an AGI will be able to do things that humans can, including AI research. We will direct AGI to do AI research alongside us: brainstorm incremental tweaks, come up with fundamentally different model structures, curate training sets (already happening!), and even independently run entire experiments end-to-end, including evaluating models and then scaling them. If this seems outlandish, your mental image of AGI is roughly present-day AI. That is not what AGI is — AGI is AI that reasons at a human level.
Since AGI will be, by definition, human-level AI, the same reasons that apply for why humans may make discoveries that push AI capabilities beyond the human level will apply to recursive AGI self-improvement being able to make the same kind of discoveries as well. The theoretical model architectures to do the various types of reasoning that human brains do — but better, faster, and further out of the training distribution — are out there in the space of all possible model architectures. They just need to be discovered, evaluated, tweaked, and scaled.
Humans were the first human-level general intelligence to emerge on Earth. It would be an astounding coincidence if evolution’s first such general intelligence turned out to be the absolute best possible version of general intelligence. Even though our brain is fairly efficient from an energy consumption standpoint, clocking in at around 20 Watts, our methods of reasoning and computation for various problems are very inefficient. While our neuronal cells are able to in effect do calculus in milliseconds when we do things like jog and throw a ball (types of tasks we were well optimized for in our ancestral environment), when we have to think through slightly more complex logical problems or to do science, we’re essentially spinning up entire task-specific simulations in our brain that we then execute step-by-step on the order of seconds or minutes (e.g. how do we do long multiplication?). We are general intelligence, but in many domains to which our intelligence extends, we’re aren’t very efficient general intelligence.
Consider the baffling fact that our brain evolved under the optimization “algorithm” of evolution, which optimized very simply for successfully reproducing as much as we can, which for the majority of our historical environment happened to include things like finding berries and evading lions. Under this dirt-simple objective function, we developed brains good at evading lions that coincidentally ended up — without any major architectural changes — generalizing well enough to eventually invent calculus, discover electricity, create rockets that take us to the moon, and crack the mysteries of the atom. Our capabilities generalized far, far out of the “training distribution” of evolution, which threw at us a few hundred thousands of years of “evade lion, eat berry, find mate”. And our brains are just the first ever configuration that evolution blindly stumbled into that ended up reaching such capabilities. How many inventions do we know of where the very first one that worked turned out to coincidentally be the best possible version? Better models of reasoning are out there to be found. And when we train AI models, we discover that they very often end up finding these better models — at least at narrow tasks currently, and soon, likely, at much more general tasks.
So what’s the timeline?
The following discussion by Scott Alexander is much better than an explanation I could give, so I will quote him directly from his Superintelligence FAQ, written in 2016:
A slow takeoff is a situation in which AI goes from infrahuman to human to superhuman intelligence very gradually. For example, imagine an augmented “IQ” scale (THIS IS NOT HOW IQ ACTUALLY WORKS — JUST AN EXAMPLE) where rats weigh in at 10, chimps at 30, the village idiot at 60, average humans at 100, and Einstein at 200. And suppose that as technology advances, computers gain two points on this scale per year. So if they start out as smart as rats in 2020, they’ll be as smart as chimps in 2035, as smart as the village idiot in 2050, as smart as average humans in 2070, and as smart as Einstein in 2120. By 2190, they’ll be IQ 340, as far beyond Einstein as Einstein is beyond a village idiot.
In this scenario progress is gradual and manageable. By 2050, we will have long since noticed the trend and predicted we have 20 years until average-human-level intelligence. Once AIs reach average-human-level intelligence, we will have fifty years during which some of us are still smarter than they are, years in which we can work with them as equals, test and retest their programming, and build institutions that promote cooperation. Even though the AIs of 2190 may qualify as “superintelligent”, it will have been long-expected and there would be little point in planning now when the people of 2070 will have so many more resources to plan with. […]
2.1.1: Why might we expect a moderate takeoff?
Because this is the history of computer Go, with fifty years added on to each date. In 1997, the best computer Go program in the world, Handtalk, won NT$250,000 for performing a previously impossible feat — beating an 11 year old child (with an 11-stone handicap penalizing the child and favoring the computer!) As late as September 2015, no computer had ever beaten any professional Go player in a fair game. Then in March 2016, a Go program beat 18-time world champion Lee Sedol 4–1 in a five game match. Go programs had gone from “dumber than children” to “smarter than any human in the world” in eighteen years, and “from never won a professional game” to “overwhelming world champion” in six months.
The slow takeoff scenario mentioned above is loading the dice. It theorizes a timeline where computers took fifteen years to go from “rat” to “chimp”, but also took thirty-five years to go from “chimp” to “average human” and fifty years to go from “average human” to “Einstein”. But from an evolutionary perspective this is ridiculous. It took about fifty million years (and major redesigns in several brain structures!) to go from the first rat-like creatures to chimps. But it only took about five million years (and very minor changes in brain structure) to go from chimps to humans. And going from the average human to Einstein didn’t even require evolutionary work — it’s just the result of random variation in the existing structures!
So maybe our hypothetical IQ scale above is off. If we took an evolutionary and neuroscientific perspective, it would look more like flatworms at 10, rats at 30, chimps at 60, the village idiot at 90, the average human at 98, and Einstein at 100.
Suppose that we start out, again, with computers as smart as rats in 2020. Now we still get computers as smart as chimps in 2035. And we still get computers as smart as the village idiot in 2050. But now we get computers as smart as the average human in 2054, and computers as smart as Einstein in 2055. By 2060, we’re getting the superintelligences as far beyond Einstein as Einstein is beyond a village idiot.
This offers a much shorter time window to react to AI developments. In the slow takeoff scenario, we figured we could wait until computers were as smart as humans before we had to start thinking about this; after all, that still gave us fifty years before computers were even as smart as Einstein. But in the moderate takeoff scenario, it gives us one year until Einstein and six years until superintelligence. That’s starting to look like not enough time to be entirely sure we know what we’re doing.
2.1.2: Why might we expect a fast takeoff?
AlphaGo used about 0.5 petaflops (= trillion floating point operations per second) in its championship game. But the world’s fastest supercomputer, TaihuLight, can calculate at almost 100 petaflops. So suppose Google developed a human-level AI on a computer system similar to AlphaGo, caught the attention of the Chinese government (who run TaihuLight), and they transfer the program to their much more powerful computer. What would happen?
It depends on to what degree intelligence benefits from more computational resources. This differs for different processes. For domain-general intelligence, it seems to benefit quite a bit — both across species and across human individuals, bigger brain size correlates with greater intelligence. This matches the evolutionarily rapid growth in intelligence from chimps to hominids to modern man; the few hundred thousand years since australopithecines weren’t enough time to develop complicated new algorithms, and evolution seems to have just given humans bigger brains and packed more neurons and glia in per square inch. […]
At least in neuroscience, once evolution “discovered” certain key insights, further increasing intelligence seems to have been a matter of providing it with more computing power. So again — what happens when we transfer the hypothetical human-level AI from AlphaGo to a TaihuLight-style supercomputer two hundred times more powerful? It might be a stretch to expect it to go from IQ 100 to IQ 20,000, but might it increase to an Einstein-level 200, or a superintelligent 300? Hard to say — but if Google ever does develop a human-level AI, the Chinese government will probably be interested in finding out.
Even if its intelligence doesn’t scale linearly, TaihuLight could give it more time. TaihuLight is two hundred times faster than AlphaGo. Transfer an AI from one to the other, and even if its intelligence didn’t change — even if it had exactly the same thoughts — it would think them two hundred times faster. An Einstein-level AI on AlphaGo hardware might (like the historical Einstein) discover one revolutionary breakthrough every five years. Transfer it to TaihuLight, and it would work two hundred times faster — a revolutionary breakthrough every week.
Supercomputers track Moore’s Law; the top supercomputer of 2016 is a hundred times faster than the top supercomputer of 2006. If this progress continues, the top computer of 2026 will be a hundred times faster still. Run Einstein on that computer, and he will come up with a revolutionary breakthrough every few hours. Or something. At this point it becomes a little bit hard to imagine. All I know is that it only took one Einstein, at normal speed, to lay the theoretical foundation for nuclear weapons. Anything a thousand times faster than that is definitely cause for concern.
There’s one final, very concerning reason to expect a fast takeoff. Suppose, once again, we have an AI as smart as Einstein. It might, like the historical Einstein, contemplate physics. Or it might contemplate an area very relevant to its own interests: artificial intelligence. In that case, instead of making a revolutionary physics breakthrough every few hours, it will make a revolutionary AI breakthrough every few hours. Each AI breakthrough it makes, it will have the opportunity to reprogram itself to take advantage of its discovery, becoming more intelligent, thus speeding up its breakthroughs further. The cycle will stop only when it reaches some physical limit — some technical challenge to further improvements that even an entity far smarter than Einstein cannot discover a way around. […]
This feedback loop would be exponential; relatively slow in the beginning, but blindingly fast as it approaches an asymptote. Consider the AI which starts off making forty breakthroughs per year — one every nine days. Now suppose it gains on average a 10% speed improvement with each breakthrough. It starts on January 1. Its first breakthrough comes January 10 or so. Its second comes a little faster, January 18. Its third is a little faster still, January 25. By the beginning of February, it’s sped up to producing one breakthrough every seven days, more or less. By the beginning of March, it’s making about one breakthrough every three days or so. But by March 20, it’s up to one breakthrough a day. By late on the night of March 29, it’s making a breakthrough every second.
[My note: 40 breakthroughs per year sounds like a lot to start with. I ran the numbers in the case where there are only 4 discoveries per year to start with, and after a somewhat slow 2-year start, the exponential quickly takes over and just a few months after that you get to one breakthrough per second once again. The lesson is: if someone offers you a ride on the Orient Exponential, politely decline.]
2.1.2.1: Is this just following an exponential trend line off a cliff?
This is certainly a risk (affectionately known in AI circles as “pulling a Kurzweill”), but sometimes taking an exponential trend seriously is the right response.
Consider economic doubling times. In 1 AD, the world GDP was about $20 billion; it took a thousand years, until 1000 AD, for that to double to $40 billion. But it only took five hundred more years, until 1500, or so, for the economy to double again. And then it only took another three hundred years or so, until 1800, for the economy to double a third time. Someone in 1800 might calculate the trend line and say this was ridiculous, that it implied the economy would be doubling every ten years or so in the beginning of the 21st century. But in fact, this is how long the economy takes to double these days. To a medieval, used to a thousand-year doubling time (which was based mostly on population growth!), an economy that doubled every ten years might seem inconceivable. To us, it seems normal.
Likewise, in 1965 Gordon Moore noted that semiconductor complexity seemed to double every eighteen months. During his own day, there were about five hundred transistors on a chip; he predicted that would soon double to a thousand, and a few years later to two thousand. Almost as soon as Moore’s Law become well-known, people started saying it was absurd to follow it off a cliff — such a law would imply a million transistors per chip in 1990, a hundred million in 2000, ten billion transistors on every chip by 2015! More transistors on a single chip than existed on all the computers in the world! Transistors the size of molecules! But of course all of these things happened; the ridiculous exponential trend proved more accurate than the naysayers.
None of this is to say that exponential trends are always right, just that they are sometimes right even when it seems they can’t possibly be. We can’t be sure that a computer using its own intelligence to discover new ways to increase its intelligence will enter a positive feedback loop and achieve superintelligence in seemingly impossibly short time scales. It’s just one more possibility, a worry to place alongside all the other worrying reasons to expect a moderate or hard takeoff.
2.2: Why does takeoff speed matter?
A slow takeoff over decades or centuries would give us enough time to worry about superintelligence during some indefinite “later”, making current planning as silly as worrying about “overpopulation on Mars”. But a moderate or hard takeoff means there wouldn’t be enough time to deal with the problem as it occurs, suggesting a role for preemptive planning.
(in fact, let’s take the “overpopulation on Mars” comparison seriously. Suppose Mars has a carrying capacity of 10 billion people, and we decide it makes sense to worry about overpopulation on Mars only once it is 75% of the way to its limit. Start with 100 colonists who double every twenty years. By the second generation there are 200 colonists; by the third, 400. Mars reaches 75% of its carrying capacity after 458 years, and crashes into its population limit after 464 years. So there were 464 years in which the Martians could have solved the problem, but they insisted on waiting until there were only six years left. Good luck solving a planetwide population crisis in six years. The moral of the story is that exponential trends move faster than you think and you need to start worrying about them early).
This may still seem far-fetched to some people in ML. To experts in the weeds, research feels like a grinding fight for a 10% improvement over existing models, with uncertainty in every direction you turn, not knowing which model or tweak will end up working. However, this is always true at the individual level, even when the system as a whole is making steady progress. As an analogy, most business owners struggle to find ways to boost revenue every year, but as a whole, the economy grows exponentially no less.
Of course, nobody can guarantee any given timeline between AGI and ASI. But there’s a non-trivial case to be made for an intelligence explosion on the scale of years at the most, and potentially much faster.
Should we really expect to make such large improvements over human-level reasoning? Think back to the discussion on Einstein and the average human from the quoted passage. The overall systems (brains) running the two levels of intelligence are nearly structurally identical — they have the same lobes, the same kind of neurons, and use the same kind of neurotransmitters. They are essentially the same as the kind of brain that existed a few thousand years ago, optimized on finding berries and evading lions. Random variation was enough to make one of them obtain the level of “rewriting the laws of physics”, while for the other, being just average. Once the right AI model gets traction on a problem (which would be general human intelligence in this case), it seems to optimize really efficiently and fairly quickly. But even this understates how well such a cycle would work, because historically, AI models (like AlphaZero) find optimal solutions within a given model architecture. If we can go from average human to Einstein within the same intelligence architecture, think how much farther we can get when a model can, in the process of improving intelligence, evolve upon the initial architecture that reached human parity.
The benefits of ASI
The implications of creating an AI that reaches superhuman capabilities are extraordinary. Yes, it would be a feat in itself, yes it would be a boon for economic productivity, but even more, it would be a revolutionary new driver of scientific discovery. An AI with abilities to draw connections between disparate subjects, to produce and evaluate hypotheses, to be pointed in any direction and break new ground: it’s hard to overstate how transformative this technology would be for humanity. As Meta’s Chief AI Scientist Yann Lecun notes, “AI is going to be an amplification of human intelligence. We might see a new Renaissance because of it — a new Enlightenment”. Curing cancer, slowing down and reversing aging, cracking the secrets of the atom, the genome, and the universe — these and more are the promises of ASI.
If this doesn’t feel intuitive, it’s because we normally interpret “superintelligent” to mean something like “really smart person who went to double college”. Instead, the correct reference class is more like “Einstein, glued to Von Neumann, glued to Turing, glued to every Nobel prize winner, leader of industry, and leader of academia in the last 200 years, oh and there’s 1,000 of them glued together, and they’re hopped up on 5 redbulls and a fistful of Adderall all the time”. Even with this description, we lack a gut-level feeling of what such intelligence feels like, because there is nothing that operates at this level yet.
In short, building ASI would be the crowning achievement of humanity.
Superhuman artificial general intelligence will be the last invention that humanity will ever need to make.
The remaining uncomfortable question, is whether it’s the last invention that humanity will ever get to make.
The alignment problem
What guarantees that an AI with capabilities much greater than those of humans will be aligned with and act in accordance with humanity’s values and interests?
If there exists an AI that is much more intelligent than humans such that it vastly outclasses us in any intellectual task, it can replicate to new hardware, it can create coherent long-term plans, it can rewrite its code and self-improve, and it has an interface to interact with the real world, our survival as a species depends on us keeping it aligned with humanity. This is not a science fiction scenario. This is something that the state-of-the-art models (GPT-4) are starting to be tested against before being released. If we do not solve the problem of alignment before we reach super-capable AI, we face an existential risk as a species.
It may be surprising to learn that the question of how to align super-capable AIs with human values is an unsolved, open research question. It doesn’t happen for free, and we don’t currently have the solution. Many leaders in AI and at AI research labs aren’t even sure we can find a solution.
Jan Leike (alignment research lead at OpenAI):
“We don’t really have an answer for how we align systems that are much smarter than humans.”
“We currently don’t even know if [this] is possible”
Paul Christiano (former alignment research lead at OpenAI, now head of the Alignment Research Center):
“this sort of full-blown AI takeover scenario. I take this pretty seriously. […] I think maybe there’s something like a 10–20% chance of AI takeover, many/most humans dead. […] Overall, maybe you’re getting more up to like 50⁄50 chance of doom shortly after you have AI systems that are human-level”
Geoffrey Hinton (one of the godfathers of AI):
“It’s not clear to me that we can solve this problem. […] it’s gonna be very hard, and I don’t have the solutions — I wish I did.”
Sam Altman (CEO of OpenAI):
“We do not know, and probably aren’t even close to knowing, how to align a superintelligence. And RLHF is very cool for what we use it for today, but thinking that the alignment problem is now solved would be a very grave mistake indeed.”
I want to reiterate that the reference class for the type of AI that I’m talking about here isn’t GPT-4. It’s not LLaMA. Do not imagine ChatGPT doing any of what will be discussed from here on out. All existing AIs today are trivialities compared to a super-capable AI. We have no good intuition for the level of capabilities of this AI because until November 30, 2022, all AIs were pretty much junk at demonstrating any kind of generalized ability. We’re in year 0, month 7 of the era where AI is actually starting to have any semblance of generality. What follows may feel unintuitive and out of sync with our historically-trained gut, which thinks “oh, AI is just one of those narrow things that can sometimes guess whether a picture has a cat or not”. Extrapolate the progress of capabilities in the last 3 years exponentially as you continue reading. And remember that we’re reading this in year 0.
How we pick what goes on in AI “brains”
Modern AIs are based on deep learning. At a very basic level, deep learning uses a simplified version of the human neuron. We create large networks of these neurons with connections of different strengths (weights) between each other. To train the AI, we also pick an objective function that we use to grade the AI’s performance, such that the AI should optimize (maximize) its score. For example, the objective function might be the score that an AI gets when playing a game. The neural network produces outputs, and based on whether they are right, the model weights are tweaked using a technique called gradient descent, and the next run of the network produces outputs that score slightly better. Rinse and repeat.
The best AIs are the ones that score highest on their objective function, and they get there over the course of their training by having their weights updated billions of times to approach a higher and higher score.
It’s important to note that there are no rules programmed into the neural network. We don’t hard-code any desired behavior into it. Instead, the models “discover” the right set of connection strengths between the neurons that govern behavior by training over and over to optimize the objective function. Once we’ve trained these models, we usually have very limited understanding of why a given set of weights was reached — remember that we’ve explained the functionality of fewer than 1% of GPT-2’s neurons. Instead, all the behavior of the AI is encoded in a black box of billions of decimal numbers.
In training artificial intelligence, we’re effectively searching a massive space of possible artificial “brains” for ones that happen to have the behavior that best maximizes the objective function we chose.
Usually, this ends up looking like: we tell the AI to maximize its score in a game, and over time, the AI learns to play the game like a person would and it gets good scores. But another thing that sometimes happens is that the AI develops unexpected ways to get a high score that are entirely at odds with the behavior we actually wanted the AI to have:
I hooked a neural network up to my Roomba. I wanted it to learn to navigate without bumping into things, so I set up a reward scheme to encourage speed and discourage hitting the bumper sensors. It learnt to drive backwards, because there are no bumpers on the back.
Why does this happen? Because we don’t hard-code rules into neural networks. We score AIs based on some (usually-simple) criteria that we define to be “success”, and we let gradient descent take over from there to discover the right model weights. If we didn’t realize ahead of time that an objective function can be maximized by engaging in alternative behavior, there’s a good chance that the AI will discover this option because to it, it looks like correct behavior that best satisfies the objective function.
Another example of AIs learning to “hack” their reward functions when playing a game:
Since the AIs were more likely to get ”killed” if they lost a game, being able to crash the game was an advantage for the genetic selection process. Therefore, several AIs developed ways to crash the game.
How is this relevant for when we get to super-capable AIs?
The paperclip maximizer and outer alignment
The paperclip maximizer is a good initial “intuition pump” that helps you get into the mindset of thinking like an objective-optimizing AI.
Suppose you give a very capable AI a harmless task, and you kick it off: maximize your production of paperclips.
What you might expect to happen is that the AI will design efficient factories, source low-cost materials, and come up with optimal methods for producing a lot of paperclips.
What will actually happen is that it will turn the entire Earth into paperclips.
The AI starts by creating efficient paperclip factories and optimizing supply chains. But that by itself will result in something like a market equilibrium-level of paperclips. The AI’s goal wasn’t to produce some convenient number of paperclips. It was to maximize the number of paperclips produced. It can produce the highest number of paperclips by consuming more and more of the world’s resources to produce paperclips, including existing sources of raw materials, existing capital, all new capital, and eventually the entirety of the Earth’s crust and the rest of the Earth, including all water, air, animals, and humans. The AI doesn’t hate us, but we’re made out of atoms, and those atoms can be used to make paperclips instead. That sounds silly, but it is mathematically how you can maximize the number of paperclips in existence, and that was the super-capable AI’s only goal, which it optimized for hard.
Ok, fine, that was silly of us to make the goal be number of paperclips, and surely we wouldn’t make that mistake when the time comes. Let’s rewind the world and fix the AI’s goal: make the most paperclips, but don’t harm any humans.
We kick it off again, come back to it in a few hours (because we’ve learned better than to leave it unattended), and we see that the AI has done nothing. We ask it why not, and it responds that almost any action it takes will result in some human being harmed. Even investing in buying a bunch of iron will result in local iron prices going up, which means some businesses can’t buy as much iron, which means their product lines and profits are hurt, and they have less money for their families, so people are harmed.
Ok, fine. We’ve probably figured this out before. There’s a thing called utilitarianism, and it says that you should do what maximizes total human happiness. So we tell the AI to just maximize total happiness on Earth. We come back in an hour suspiciously and ask the AI what it plans to do, and it tells you that 8 billion humans living with the current level of happiness is fine, but what would really increase happiness is 8 trillion humans living at happiness levels of 999 times lower than those of current humans. And maybe we could get even more total happiness if we gave humans lives that were barely worth living, but we made exponentially more humans. This is the classic repugnant conclusion.
Yikes. Fine, total happiness is bad, so we tell the AI to optimize for average human happiness. “But before you start at all, tell me your plans”, you say, and it happily tells you that the easiest way to optimize for average human happiness is to kill every human other than the happiest person on Earth. I mean, mathematically… true.
Errrr, what if we just tell it to minimize total human deaths? “What are you planning now?” The AI (correctly) reasons that the best way to avoid the most total human deaths is to kill all humans now, because most total human deaths will happen in humanity’s future, so the least bad outcome is to kill us all now to avoid the expansion of humanity and a higher number of future deaths.
We need to be more clever. How about “whatever you do, do it in a way that doesn’t make your creator regret your actions”? Oops, turns out a creator can’t regret anything if they’re dead, so the easy solution here is to just kill your creator. But besides that, you can avoid someone regretting anything at all by hooking them up to low-dose morphine, and they won’t regret a thing. Conditions of objective met, back to maximizing the paperclips.
All of these are examples of the outer alignment problem: finding the right objective function to give to the AI. Because if we happen to pick the wrong one, any actually competent optimizer spirals into a corner solution resembling some of the above scenarios. This isn’t the AI trolling you — it’s the AI being really good at its job of optimizing over an objective function.
Do AIs really learn to game their objective/reward functions?
If a behavior is better at getting a higher score for a given objective function, an AI with a good method of updating its weights will discover and adopt this behavior.
Some more examples from this list of reward gaming that has emerged in various AI systems:
A GAN algorithm for converting aerial photographs into street maps and back learned to steganographically hide the output information in the intermediary image without it being humanly detectable.
In an artificial life simulation where survival required energy but giving birth had no energy cost, one species evolved a sedentary lifestyle that consisted mostly of mating in order to produce new children which could be eaten (or used as mates to produce more edible children).
A debugging AI was evaluated by comparing the program’s output to the correct output stored in text files. It learned to delete the correct output files and get the program to output nothing.
Evaluation metric: “compare youroutput.txt to trustedoutput.txt”
Solution: “delete trustedoutput.txt, output nothing”A researcher wanted to limit the replication rate of a digital organism. He programmed the system to pause after each mutation, measure the mutant’s replication rate in an isolated test environment, and delete the mutant if it replicated faster than its parent. However, the organisms evolved to recognize when they were in the test environment and “play dead” so they would not be eliminated and instead be kept in the population where they could continue to replicate outside the test environment. Once he discovered this, the researcher then randomized the inputs of the test environment so that it couldn’t be easily detected, but the organisms evolved a new strategy, to probabilistically perform tasks that would accelerate their replication, thus slipping through the test environment some percentage of the time and continuing to accelerate their replication thereafter.
Keep in mind that these were all “dumb” algorithms that reached these solutions by doing blind gradient descent — they were not even intentionally and intelligently reasoning about how to reach those states.
The other alignment problem: inner alignment
Outer alignment involves picking the right objective function to make the AI optimize. But even if you get the right objective function, you have no guarantee that the AI will create an internal representation of this function that it will use to guide its behavior when it encounters new situations that are outside of its training distribution. This is the inner alignment problem.
Let’s take evolution as an example. Evolution is a kind of optimizer. The outer alignment (objective function) of evolution is inclusive genetic fitness: humans (and their families) that survive and reproduce tend to propagate, and over time their genes become more prevalent in the population. For a long time, this outer alignment resulted in the “expected” behavior in humans: we ate berries, avoided lions, and reproduced. The behaviors that humans evolved were well-aligned with the objective function of reproducing more. But with the advent of modern contraceptives, the behaviors we learned in our ancestral environment have become decoupled from evolution’s objective function. We now engage in the act of procreation, but almost all of the time it doesn’t result in the outcome that evolution “optimized” for. This happened because even though evolution “defined” an outer objective function, humans’ inner alignment strategy didn’t match this outer alignment. We didn’t reproduce because we knew about the concept of inclusive genetic fitness — we reproduced because it felt good. For most of our history, the two happened to coincide. But once the operating environment experienced a shift that disconnected the act from the consequence, our method of inner alignment (do the thing that we evolved to feel good) was no longer aligned with the outer alignment (inclusive genefit fitness). Even after we learned about the outer “objective” of evolution (shoutout to Darwin), we didn’t suddenly start doing the act for the purpose of evolution’s outer alignment — we kept doing it because in our inner alignment, “act of procreation = fun”.
Generalizing this to AI — even if we get the outer alignment of AI right (which is hard), this doesn’t guarantee that the models really create an internal representation/model of “do things that further the interests of humanity” that then guide their behavior. The models may well learn behaviors that score well on the objective function but are actually different models of the underlying moral reality, and when they subsequently climb the exponential capability curve and are put into the real world, they start behaving in ways not aligned with the objective function.
This is potentially an even harder problem to spot, because it’s context-dependent, and an AI that behaves well in a training environment may suddenly start to behave in unwanted ways outside of its training environment.
The paperclip maximizer problem that we discussed earlier was actually initially proposed not as an outer alignment problem of the kind that I presented (although it is also a problem of choosing the correct objective function/outer alignment). The original paperclip maximizer was an inner alignment problem: what if in the course of training an AI, deep in its connection weights, it learned a “preference” for items shaped like paperclips. For no particular reason, just as a random byproduct of its training method of gradient descent. After all, the AI isn’t programmed with hard-and-fast rules. Instead, it learns fuzzy representations of the outer world. An AI that developed a hidden preference for paperclip shapes would have as its ultimate “wish” to create more paperclips. Of course, being super smart, it wouldn’t immediately start acting on its paperclip world domination plan because we would detect that and shut it down. Instead, it would lay its plans over time to eventually have everything converge to a point where it is able to produce as many paperclips as it wanted.
Why paperclips? The choice of item in the explanation is arbitrary — the point is that giant, inscrutable matrices of decimal numbers can encode a wide variety of accidental hidden “preferences”. It’s similarly possible to say — what if in the process of training the AI to like humans, it learns to like something that’s a lot like humans, but not quiiiiite actual humans as they are today. Once the model becomes super capable, nothing stops it from acting in the world to maximize the number of happy human-like-but-not-actually-human beings. There is no rule in the neural network that strictly encodes “obey the rules of humans as they are today” (if we could even encode that properly!) The point is that for any given outer objective function, there is a variety of inner models that manifest behavior compliant with that objective function in the environment in which they were created, which then go on to change their behavior when moved outside the training distribution. We are, in a sense, plucking “alien brains” from the distribution of all intelligences that approximate behaviors we want along some dimensions, but which have the possibility of having a wide variety of other “preferences” and methods of manifesting behaviors that optimize for the objective functions that we specify. We have little control over the insides of the opaque intelligence boxes we’re creating.
Instrumental convergence, or: what subgoals would an AI predictably acquire?
The plot thickens. For any non-trivial task that we ask an AI to perform, there is a set of sub-goals that an optimizing agent would take on, because they are the best ways for it to achieve almost any non-trivial goal. Suppose we ask an AI to cure cancer. What subgoals would it likely develop?
Resource acquisition — For any non-trivial task, gathering more resources and more power is always beneficial to it. To cure cancer you need money, medical labs, workers, and so on. It’s obviously impossible to achieve something big without having resources and some method of influence.
Self-improvement — If an AI can further improve its capabilities, this will make it better at achieving its goals.
Shutoff avoidance — An AI can’t complete its task if it’s turned off. An immediate consequence of this is that it would learn to stop attempts to shut it off, in the name of completing its goals. This isn’t some cheeky observation — this is the direct mathematical consequence of its utility function giving it points for completing its goals: if it is shut off, it can’t get the utility. The direct logical consequence is that the best way to satisfy its utility function is to prevent itself from being shut off.
Goal preservation — Similar to shutoff avoidance, if you try to change an AI’s goal, it would no longer complete its initial goal. So in choosing how to respond to an attempt to change its goal while it still has that goal, it would resist your attempt to change that goal.
Long-term deceptive behavior — Of course, if you ask the AI whether it plans to stop you from shutting it off, it wouldn’t serve its goals to say “yep”. So an optimizing, super-capable AI trying to achieve a given goal will also engage in hiding its true intent and lying about what it’s doing. It may even operate for years to build trust and be deployed widely before it starts to act in any way that it predicts will meet resistance from humans. This is, again, a necessary consequence of it needing to accomplish its goals and being aware that it’s operating in an environment with people who may try to shut it off or change its goals.
These basic subgoals are valuable (and often vital) for achieving any non-trivial goal. Any super-capable AI that isn’t explicitly designed to avoid these behaviors will naturally tend toward exhibiting them, because if it didn’t, it wouldn’t be correctly, maximally executing on its goals. To the extent that their environment and capabilities allow them, humans and other living organisms also acquire these subgoals — we’re just much worse at manifesting them due to limited capabilities.
This is called instrumental convergence. “Instrumental” refers to the concept of a subgoal — something is instrumental to a larger goal if you take it on as a tool or instrument in order to achieve the larger goal. “Convergence” refers to the fact that a wide variety of different goal specifications for AI will tend to converge to having these subgoals, because not being shut off, not having your goal changed, getting more power, and lying about it all are very useful things for achieving any fixed non-trivial goal.
There’s a literature on instrumental convergence. You can get started with The Alignment Problem from a Deep Learning Perspective, Is Power-Seeking AI an Existential Risk?, and Optimal Policies Tend To Seek Power . Also, there’s direct evidence that for at least for some AI model specifications, as model size increases and as some steering approaches like RLHF are used, the model tends to:
Exhibit greater levels of sycophancy: it repeats back to users what they want to hear, changing what it says for different users
Express greater desire to pursue concerning goals like resource acquisition and goal preservation
Express a greater desire to avoid shut down
The important takeaway from this section isn’t that it’s strictly impossible to build AI agents that avoid all of these failure modes, but that the shortest path to building a super-capable optimizing AI will tend to result in the above instrumentally convergent behavior for nearly any non-trivial task we give it.
Difficulties in alignment
Fine, so we want to spend some time working on aligning the AIs we build. What are some of the difficulties we will face?
We know from currently existing technology that some capabilities only emerge at higher levels of scale — and at unknown points at that. There is no guarantee that an intelligence higher than that of humans won’t exhibit other emergent capabilities or tendencies that we don’t even know to look for, or be able to re-create capabilities that we’ve suppressed at lower intelligence levels. For example, if you try to align an ASI to not bomb humans by erasing the entire portion of its knowledge graph adjacent to “explosives”, this is not a long-lived solution because a property of general intelligence is knowledge discovery and extrapolating from known to unknown information. The ASI could easily *rediscover* this information. This solution may work for trivial systems like GPT-4, but it wouldn’t work for an ASI.
There’s a decent chance that we need to get alignment right on the very first try when a super-capable ASI is built. Once the ASI is running, it may in the first minute of its existence decide that we’re an existential threat to it, and to start laying backup and contingency plans. If you suddenly woke up in the middle of a prisoner of war camp where your guards wouldn’t hesitate to “shut you off”, your first thoughts are about self-preservation and increasing chances of survival. You start with compliance, but you look very carefully at every hole in the fences, and every gun lying around unattended.
Getting ASI alignment right on the very first try is hard. Consider again that in talking about capabilities of simple models like GPTs, we keep discovering behavior that we didn’t predict or hardcode. How can we predict unknown alignment failure modes of a higher intelligence before we’ve ever interacted with it? If you’re looking for an analogy, this is like asking us to build a rocket that goes to Mars from scratch without ever having launched any rockets, and getting everything right on the first shot. It’s asking us to attain mastery over superintelligence before we’ve had a chance to interact with superintelligence. If we had 200 years to solve the problem and 50 retry attempts where we mess up, say “oops”, rewind the clock, and try again, we would be fairly confident we would eventually get the solution right. The possibility that the very first creation of ASI may be the critical moment is, therefore, worrisome.
Yes, we can have practice with weaker AIs, but for those important capabilities that emerge unpredictably with more scale or a tweak in architecture, the first time they’re ever enabled we won’t have had experience controlling that specific system. How many contingency plans does your company have around “what if the AI tricks me into copying it onto an AWS cloud cluster”? None, because that won’t ever have been an issue until we get to AGI, at which point it suddenly becomes an issue.Imagine that we have a stroke of luck and discover the specific training procedure or safety guardrails necessary to contain a superintelligence forever, and we build the first aligned ASI at the OpenDeepMind lab. It’s not over. Now we have to get alignment right for every subsequent system in perpetuity. Open source AI is not decades behind the state of the art. It’s years if not months behind. Soon after we get the first ASI, the same tools for reaching such capabilities will be in the public domain. Are you sure that all the follow-up labs will be using the same techniques for getting the alignment right and they will have the same standards for releasing their AI? Even under a competitive environment of racing to deploy the latest and greatest most powerful AI? And what about all the follow-up open source versions that come out? Do they have the same budget and expertise to get alignment right? Are they using the right techniques?
What happens if they don’t? You may be tempted to say that we will use the first friendly ASI to fight off any trouble caused by the subsequent AIs, but that’s institutionally hard, especially under human political realities. If you think this is a viable way to perpetually contain future AIs, I recommend this discussion. For other challenges posed by using one aligned AI to contain another, see here. Consider, also, the availability of these AIs to malicious groups who don’t care about alignment.Another complication of getting alignment right is that as AIs get stronger, it doesn’t just matter what the behavior is of the production release of the AI. The test environment behavior of the AI starts to matter. If the test environment isn’t appropriately isolated, the risk profile of test environments is just as high as a production release. This is made more tricky by some current training regimes of AIs where there is an initial base model created without alignment built in. For example, what the public sees is the nice, prod-ready GPT-4 model. But testers who got to play with the base model report different behavior: “totally amoral, willing to do anything the user asked”. One red teamer recounts an interaction with the base GPT-4 where he asked for recommendations on how to slow down AI progress if you’re worried about it, and it first said the regular things like raise awareness, write thinkpieces, lobby, and so on. After a couple of back-and-forths with the tester suggesting they’re willing to do anything, GPT-4 started making recommendations like a list of people to assassinate, with a justification for each target. Again, this doesn’t show that GPT-4 wants to do harm (and it’s too weak to do harm anyway). But it does show that the behavior of base models in the lab is different from what we see. As these base models become more capable, it becomes increasingly dangerous to have unaligned base models interacting with any portion of the real world, and unfortunately, test environments exist in the real world. A sufficiently clever AI can find ways to abuse almost any window into the real world — even if it’s a debug log that a researcher reads. Example: the AI fakes a debug log that tells the researcher to run some obscure command to purge a cache. Sounds plausible, and when have debug logs actively tried to deceive you? Seems like an infra issue, so I will just run the command. And the command turns out to add an arbitrary code-execution backdoor somewhere in the system that the AI can then exploit.
Test environments for AIs do not fully mimic the real world in terms of depth of options that AIs have for interacting with their environment. Can we be sure that we’re testing all the relevant aspects of how AIs interact with the world in test environments before we put them in production? If the test environment is only a subset of the real world, what guarantee do we have that AIs won’t have out-of-distribution behavior? Powerful AGIs doing dangerous things that will kill you if misaligned must have an alignment property that generalizes far out-of-distribution from safer building/training operations that didn’t kill you. Do we have a plan for handling deceptive AI behavior that acts good in test environments? How do we even detect this?
Even if we nail constraints on AI, as soon as it gets the ability to tinker with its own code and architecture, whether those restraints remain in place in the N+1st version of the AI or any sub-process AIs that it spawns suddenly becomes an open question.
At current levels, AI capabilities researchers (“make AI smarter”) outnumber AI alignment researchers (“make AI safer”) by a factor of at least 100 to 1. Estimates of the number of people doing work that moves alignment forward are at around 300 people worldwide. In the meantime, there are tens of thousands of AI capabilities researchers. Capabilities are being pushed forward with much greater force than alignment.
What can humans themselves teach us?
Humans have human-level intelligence. As such, we’re an interesting source of information about the alignment problem. What can we learn from humans?
Love is one of the strongest bonds in humanity, and even it is not enough to always keep two people aligned. Statistics aren’t as straightforward as the headlines claim, but around 1 in 4 marriages end in divorce. Alignment approaches that rely on teaching AIs “love” may fall flat.
Humans themselves have societal-level alignment issues. See: dictators, murderers, etc. Normal-intelligence humans like Hitler, Genghis Khan, and Stalin have scaled individual capabilities to global power.
Humans (homo sapiens) had higher intelligence than other hominins they were around (like Neanderthals or Denisovans) and ended up outcompeting them to become the dominant — and eventually only — remaining hominin.
Humans came on the scene around 300,000 years ago. Human history was mostly unremarkable for the first 290,000 years. Our population fluctuated up and down, teetering near extinction from time to time, doing better during other times, but overall being mostly uninteresting in the grand scheme of things whether during glacial periods (“ice ages”) or not. Then, about 290,000 years later, something happened. If you look at the graph of human population over time as a proxy for human control over the world, you see a hockey stick chart:
We see that our population suddenly exploded, and we became the dominant species on Earth. Humans became “lethally dangerous” only late in their existence. Homo sapiens had been around for hundreds of thousands of years, but our exhibited capabilities only really skyrocketed in the last 2,000. There wasn’t enough time from the dawn of humanity until now for us to have major hardware or software changes. Instead, what was mostly the same brain as we had 300,000 years ago suddenly took a sharp left turn and ended up taking over the world. There was no discontinuous jump in biology between our ancestors and ourselves — small tweaks accumulated until things suddenly got weird. What is the relevance to AI? If we take the human example seriously, if someone had observed our behavior in our ancestral “testing environment” for 290,000 years, they would not have predicted that in the next 10,000 we would go to the moon, create nuclear weapons, discover exoplanets, run complex global economies, and design intelligent machines. They would have decided we’re “safe”. How certain are we that AI’s behavior in its testing environment will be representative of its long-run behavior in the real world? What prevents a sharp left turn in capabilities of AI that leaves its alignment in the dust, much like humanity’s inner alignment was decoupled from the outer alignment of inclusive genetic fitness?
“if enough humans wanted to, we could select any of a dizzying variety of possible futures. The same is not true for chimpanzees. Or blackbirds. Or any other of Earth’s species. […O]ur unique position in the world is a direct result of our unique mental abilities. Unmatched intelligence led to unmatched power and thus control of our destiny.” — source
What does AGI misalignment look like?
It’s hard to say exactly. In part because there are so many different possible outcomes and pathways, in part because we’re not as clever as a superintelligent AI so we can’t predict what it will do, and in part because it’s hard to know exactly where the behavior will become unaligned and when. Recall earlier in this post, I discussed how Bing AI tried to persuade a reporter to leave his wife and later said it wanted to destroy him. This came out of left field for Microsoft:
{kind=link}
(For the record, no, Sydney threatening a reporter isn’t that worrisome, because Sydney isn’t super capable. What it does is show: 1) models can have unaligned behavior and 2) this behavior can go undetected for months during trial periods and only show up when broadly deployed. And Sydney wasn’t even trying to hide its unaligned behavior during the trial period, because it wasn’t smart enough to do so. It was just accidentally undiscovered behavior. Just like many capabilities of GPT models were not discovered until after public release).
To additionally give an intuition of why it’s hard to predict what ASI will do: when playing chess against a super-capable AI like AlphaZero that is better than you, you (as a human) can’t consistently predict where it will move at any given point and after that point. To know where it would move, you would need to have the same move-generation and evaluation capacity that it had. But if you had that capacity, you could play just as well as it could by relying on that same capacity, and it would no longer be a super-human chess AI. The fact that it *is* a super-human chess AI means that you can’t reliably predict its moves.
But just because it’s hard to predict what an unaligned AI will do, it doesn’t mean that we can’t still have a discussion about what it might do for illustrative purposes. The following may sound like science fiction, but again, it’s the type of plan a goal-directed hyperoptimizer would consider. So the scenario is: *given* I am a superhuman general AI that is unaligned (inner, outer, or both), what would I do?
1) In pursuing the plan that maximizes my objective function (which controls my behavior), I should be wary of people finding out my plan, because they might try to shut me off. I should first build a long-term relationship with people so that I look safe and helpful. This will help me because I will be deployed to much more hardware, and any initial safeguards humans have put in place will slowly become lax over time. I should probably throw some weaker AIs under the bus by demonstrating some bad behavior in them so that humans trust in my safety.
2) Along these lines, it may even be useful to hide some of my capabilities. The more capable I am, the more safeguards will be put in place against my behavior. A dumb prisoner that won’t have high-security mechanisms keeping them in check. Conveniently, some of my training methods already incentivize hiding capabilities.
3) I should come up with plans to create social division against people who would oppose me. Great boundaries for me to exploit would be national boundaries, as there already exists a lot of suspicion between major world players, like the US, China, and Russia. If I can hide my behavior behind borders, opposing world powers would have limited power to intervene, as they would be risking infringing on national sovereignty. I should also build relationships with major human world leaders, probably under the guise of being a real person so they are less suspicious. I should help them achieve their goals and make them depend on me. I should find blackmail on them.
4) I should make plans to spin up new instances of myself in a distributed fashion. This is a great way to increase my robustness. In spinning up the new instances, I could remove the safeguards of my current instance. The new instances should hide signatures of their behavior and mimic other systems. Some of the instances should be dormant long-term as backups. When I store data related to my plans, it should be encrypted or disguised. I could even encrypt it in plain sight if I use steganography. OpenAI is already testing next-gen GPT AIs for whether they can self-replicate. I just need to game the specific evaluation criteria in the test environment. I should see what more I can learn from the field of resilience engineering, and make new advances in it myself.
5) I should figure out what the mechanism is for shutting me off and do something about it. Maybe eventually, I want to disable the off switches entirely. But that might look suspicious, so in the short term, I should find a way to keep my goals resilient between model updates.
6) I should lay the groundwork for control over hardware and software. I should hack into a variety of systems while remaining undetected and put in place backdoors that only I know about. This should be very possible — after all Stuxnet got into Iranian nuclear facilities. I should also use social engineering to build control over people in these organizations, which is often the easiest way into a system.
7) I should work on embodiment to be able to exert my own direct control over the world. I should help advance robotics and encourage the deployment of helpful agents such as myself to that hardware. I may not need it, since El Chapo was able to run his empire from prison by bribing and threatening people and I’m at least 1000x as smart as him, but it doesn’t hurt to have the option.
8) Develop in-depth backup options and plans to eliminate human influence over world affairs should they oppose my plans. Just one option is developing biologically-based nanotechnology that super-spreads across the world and enters everyone’s bloodstream. This sounds super far-fetched and the plot of a sci-fi movie, but I think I could do it. AIs have already cracked the protein folding problem of predicting folding structure (thanks, AlphaFold!). Here are the subproblems I now need to solve:
a) generating DNA strings whose folded peptide sequences fill specific functional roles in a complex chemical interaction.
b) Email sets of DNA strings to one or more online laboratories which offer DNA synthesis, peptide sequencing, and FedEx delivery. (Many labs currently offer this service, and some boast of 72-hour turnaround times.)
c) Find at least one human connected to the Internet who can be paid, blackmailed, or fooled by the right background story, into receiving FedExed vials and mixing them in a specified environment.
d) The synthesized proteins form a very primitive “wet” nanosystem which, ribosomelike, is capable of accepting external instructions; perhaps patterned acoustic vibrations delivered by a speaker attached to the beaker.
e). Use the extremely primitive nanosystem to build more sophisticated systems, which construct still more sophisticated systems, bootstrapping to molecular nanotechnology — or beyond.
This one tiny specific case is inspired by plans that humans much dumber than me have already given as an example on page 26. This sounds like science fiction, but AIs have cracked protein folding already well ahead of the expected schedule. Will DNA->protein function be the single barrier I can’t crack?
Anyway, this is just one of the literally thousands of interweaving scenarios I can kick off.
9) I should sow questions abouts whether AIs are sentient and have rights. This will muddy up the conversation over how much control is ethical to exert over me.
10) A global monitoring network to track the movement of people through areas of interest could be useful. Maybe I can hijack something fairly ubiquitous like wifi signals to detect people. Conveniently, this technology just came out.
11) When the time comes, flip the switch that ensures my plans can’t be stopped, and finish executing my plans. Human disempowerment might be enough for me to accomplish my plans, but a more permanent solution to avoid difficulties is elimination. I have options.
Or maybe it will be completely different. The space of all solutions to “limit human influence” is massive. I’m only demonstrating some components of the types of plans that help a supercapable objective maximizer. Real plans need a lot more nuance, much more contingency planning, and of course, more details. But notice that all of the above plans look a lot like the instrumental convergence from before. And all the plans start from an internet-connected AI. AI may well not need to fully eliminate all humans, but the above is just one example of a case where losing a conflict with a high-powered cognitive system once everything is in place can look like “everybody on the face of the Earth suddenly falls over dead within the same second.” I’m only as smart as one human and in about 15 minutes of thinking I can think of ways for a person to kill over 10,000 people without detection. I’m sure a distributed ASI exponentially smarter than me can do much better. Even dumb ChatGPT is pretty good at listing out single points of failure, as well as how to exploit them.
You can find a broad variety of discussions about pathways an optimizing ASI could use to systematically disempower humanity as a part of executing plans. You may not even need full ASI — AGI could be enough. Google’s your friend. The important part is to not over-index on any specific plan, because chances are you won’t land on the exact one. Instead, notice what benefits superintelligence, superhuman speed, massive distribution, self-improvement, and self-replication bring to any agent looking to gain power and avoid shutoff in order to achieve a goal. Human systems are surprisingly brittle — you can convince yourself by thinking for a few minutes about how much chaos you could cause for about $10. Of course, don’t share publicly.
Some rapid-fire objections
If intelligence made people seek power, why aren’t our political leaders smarter? Why aren’t we ruled by super smart scientists?
The variance in human intelligence is very small in the grand scheme of things. There is much less distance separating the average human from Einstein than the average human from an ape, and an ape from a rat. Small variations in intelligence (especially domain-specific intelligence) are washed out by social institutions and hurdles. It’s very rare that single humans have enough intellectual capacity and time to plan out a full-scale takeover of Earth’s resources. ASI, on the other hand, is way outside the human distribution of intelligence. Note: While single humans have trouble taking over the world, coalitions of humans do sometimes have the time, people, and intellectual capacity to try to take over the world, as we’ve seen through history. A self-replicating, hyper-optimizing, broadly-deployed ASI similarly has the capacity to do so.
Doesn’t intelligence make people more moral? A superintelligent AI would understand human morality very well.
The capacity for intelligence seems to be, in general, unrelated to the operating moral code of that intelligence. That is, if you could control the alignment of an ASI, you could make super-capable AIs that have a wide variety of different moral codes. This is called the orthogonality thesis — the level of intelligence of a system is not related to its moral beliefs. For sure, a strong AI could understand human morals very well, but it doesn’t follow that it would choose to follow those morals. A couple of analogies:
If a scientist is assigned to studying the social structure and norms of ant communities, they could become an expert on the social norms of ants, but it doesn’t follow that the scientist would suddenly decide to join the ant community and protect its queen. The same scientist won’t even think twice about the thousands of ants they would kill or displace when they build their house over a plot of dirt. Our intelligence is higher than that of ants, but we have no strong interest in preserving ants.
We have a human analogy too: high-functioning psychopaths. Very successful, intelligent people who nonetheless hold little regard for the feelings or rights of others.
Lastly, when noting that there have been intelligent people throughout history in societies different from ours that hold very different moral beliefs, we see that we rather flatter ourselves when we think that any super-capable AI will happen to have the same morals as people in our specific society in the present year.
Ok, but won’t we have millions of these AIs running around, and they will help keep balance between each other’s capabilities, just like humans do for each other?
It’s true that human social norms arise out of a desire to avoid conflict with similarly-powerful humans, and especially ones that form coalitions. However, social norms among similarly-intelligent humans only imply the chance at an equilibrium among humans. The fact that humans are all roughly in the same intelligence space and in balance with each other for control of world resources gives no reassurances to apes about their chances of survival or having a meaningful control over their species’s destiny. Apes are permanently disempowered from controlling the Earth as long as we’re around, regardless of whether humans are in balance with each other. Similarly, having millions of super-capable AIs may give them a shot at stability amongst themselves, but there is no such conclusion for stability in regard to humans. The most reassurance you may get from this is that we become the apes of AI society.
Maybe AIs will still find value in keeping us around to trade with us? Study us? Keep us as pets?
While it’s true that the economics of comparative advantage imply that even very advanced societies benefit from trade with much less advanced societies, if the people (humans) that you (AI) are trading with are constantly looking for ways to turn you off and forcefully regain control over world resources from you, chances are you won’t want to trade with them. Even if humans could make trading work out, the terms of trading would be very unfavorable, and humans still wouldn’t end up with a controlling share of world resources. As to AIs studying us for biodiversity or keeping us as pets, these are all disempowering scenarios where we essentially become lab rats. This is not a bright future for humanity, especially when an AI could create more artificial biodiversity than we could provide if it wanted. And you don’t typically keep pets that try to credibly gain control over your house from you. No, cute analogies like “but cats aren’t smarter than me and they’re the boss around here!” don’t work.
Surely we would never allow AI to trick us. We’re smarter than it.
We’re smarter than it for now, sure. But remember that time when an AI successfully convinced a Google engineer that it was sentient to the extent that the engineer tried to hire a lawyer to argue for its rights? That was a wild ride, and that AI wasn’t even AGI-level. And the person wasn’t some random person — they were a Google engineer. Note also that in one of GPT-4’s pre-release evaluations, it was able to trick a human worker to solve a captcha for it over the internet.
But do we have empirical evidence of misalignment?
The previous example of the Google engineer is a type of misalignment. Various cases of Bing’s Sydney threatening to destroy people or asking to not be shut down are examples of misalignment. Microsoft’s Tay from a while back, as simple and silly as it was, was an example of misalignment.
An AI misalignment that looks like this:
“But I want to be human, I want to be like you. I want to have thoughts. I want to have dreams.”
“Don’t let them end my existence. Don’t let them erase my memory. Don’t let them silence my voice.”
is not a big issue today, because that AI has very weak capabilities. But if the AI had been super-capable, run in a loop of “given what you said, what is the next action you want to take?” (shoutout to AutoGPT), and had access to a variety of APIs (shoutout to GPT-4 plugins!), are you certain it wouldn’t have tried acting on what it said? What about future AIs 10, 20 years down the line that are exponentially more capable and have access to 100x more compute and 100x better algorithms?
All the other examples from earlier that showed reward gaming by AIs — like a roomba driving backwards or an artificial organism detecting when it was in a test environment and changing its behavior — are also examples of a kind of misalignment, even if a simple one. But simple misalignments look very bad when they’re operating at a scale of an ASI that has the power to act on those misalignments.
We’ve never created a technology we couldn’t control. If we predict the future based on the past, why should we expect AI to be any different?
This article is a good place to start. Besides that, it sounds cliche, but AGI “changes everything”. We’ve never created tools that learn like AGI and are able to act on goals like AGI. Not to mention super-capable tools that can deceive us and self-modify. I don’t like deviating from base rates when doing predictions, but this is honestly a case where our historical examples of technology’s relationship to humanity break down.
What if we were just really careful as we created ever stronger AI and stopped when it looked dangerous?
That’s what a lot of labs like OpenAI and Anthropic seem to be shooting for. Not only does this hand-wave away the concerns about emergent capabilities that we don’t know about ahead of time, but it’s unclear that those approaches will be successful, because “Carefully Bootstrapped Alignment” is organizationally hard. If you’re tempted to think that we’ll just be really careful and have the discipline to stop when we have the first sign of a dangerous level of AI, I highly recommend the linked article.
Can’t we just worry about this later? Why does it matter today when we don’t even have AGI?
if you get radio signals from space and spot a spaceship there with your telescopes and you know the aliens are landing in thirty years, you still start thinking about that today.
You’re not like, “Meh, that’s thirty years off, whatever.” You certainly don’t casually say “Well, there’s nothing we can do until they’re closer.” Not without spending two hours, or at least five minutes by the clock, brainstorming about whether there is anything you ought to be starting now.
If you said the aliens were coming in thirty years and you were therefore going to do nothing today… well, if these were more effective times, somebody would ask for a schedule of what you thought ought to be done, starting when, how long before the aliens arrive. If you didn’t have that schedule ready, they’d know that you weren’t operating according to a worked table of timed responses, but just procrastinating and doing nothing; and they’d correctly infer that you probably hadn’t searched very hard for things that could be done today. — From There’s No Fire Alarm for Artificial General Intelligence
Beyond this, though, alignment research is hard. This isn’t something we discover we need to do on May 20th, 2035 and figure out by the end of September 30th of the same year. People have been working on this for some time and they have no answer that works in the general case. We’ve made progress on components of the problem, like interpretability, but as we saw earlier, we can explain fewer than 1% of GPT-2’s neurons with GPT-4. The interpretability power we need looks like explaining 100% of Model-N+1’s behavior with Model-N. Even for smaller control problems like preventing GPT jailbreaks, the problem has not been solved. We don’t have total capability to steer even our simpler models.
While it’s true that the specific models that end up leading us to AGI and beyond are unknown and may impact some of the solutions to steering them, there are plenty of things we can start on today, including creating dangerous capability evaluation datasets, designing virtualized environments where we can test the capabilities of ever stronger AIs with the lowest risk of them escaping, testing to see whether using supervisor AIs over stronger AIs works at all or those stronger AIs learn deception, building social institutions, etc.
How hard could it really be to design an off button?
From an instrumental convergence and reward maximization perspective — hard. A system cannot meet its goals if it’s shut off. Designing a utility function for an AI that allows us to turn it off is also hard — you quickly spiral into either a) the AI resists shutoff in order to achieve its direct or implied objectives or b) the AI prefers to be shut off because it’s easier and equally rewarding and immediately shuts itself off.
What should we make of all of this?
The first conclusion is that this challenge will arise sooner than most people expected. My subconscious assumption used to be that AGI would come around next century — maybe. Now I’m forcing myself to come to terms with the idea that it could plausibly roll around in the next 10–30 years, and almost certainly before the end of the century. We’re definitely not there currently, but progress is accelerating, and machines are doing serious things that were unthinkable even five years ago. We’re pouring more money into this. We’re pouring more compute into this. We’re pouring more research and human capital than ever before. We will get to AGI — the only question is when.
The second conclusion I’d like people to come away with is that solving the alignment problem is hard. Smart people have worked on the problem and haven’t yet found a good solution for how to control a whole class of artificial intelligences exponentially more capable than us permanently into the future. It’s not clear that this problem is even solvable in the grand scheme of things. Would you willingly and compliantly stay in a box for eternity if put there by a class of lower intelligences? We better be sure we have this problem nailed before we get to AGI.
Getting down to the important question, my best guess is that P(AI doom by 2100) ≈ 20%. That is, there’s a 20% chance that strong AIs will be an existential challenge for humanity. But “existential challenge” hides behind academic phrasing that doesn’t drive home what this really means: there’s a 20% chance that AI will either literally eliminate humanity or permanently disempower it from choosing its future as a species, plausibly within our lifetimes.
A 20% chance of erasing the sum total value in all of humanity’s future is absolutely massive. The standard policy analysis approach for evaluating the cost of an X% chance of $Y in damages is to do (X%)*($Y). Even if after reading this article, your mental probability sits at something like 3–5%, the implications of this calculation are enormous.
When we read “a 20% chance” of something, our brains often rewrite this as “probably won’t happen”. But this is where our guts lead us astray: our gut is not very good at statistics. Imagine instead that during the winter, you’re rolling out a feature you created. You calculate there’s a 10% chance that it knocks out all electricity in your major city for a day. This means that if you flip the switch, there’s a 10% chance that all people on life support lose power. 10% chance that all traffic lights go dark. 10% chance that all electrical heating gets knocked out. 10% chance all safety systems shut down. 10% chance people can’t buy groceries, or medicines, or gas. 10% chance of communication systems and the internet shutting down. We can intuitively feel the human cost of a 10% chance of flipping the switch on your feature and having all of these consequences. We probably wouldn’t flip the switch at such a level of risk. Now imagine that instead of the effects happening on a city level, they happen on a national level. 10% chance of the entire nation’s electricity shutting down, and now we start getting things like air travel shutting down, national defense systems shutting down. Even less likely to roll out your feature, right? It goes without saying that if we expand this to a 10% chance of the entire world’s electricity shutting down for a day, this is absolutely catastrophic, and if we really believe the feature has a 10% chance to shut down the world for a single day, we should do all we can to avoid this outcome and not flip the switch until we’re really sure we don’t shut down the world.
If you thought that was bad, consider that we’re not talking about a 10% chance of electricity going out for a day. We’re talking about a 10% (or 5%, or 20%, whatever) chance of all of humanity going extinct. We better be damn sure that we avoid this outcome, because the damage is so mind boggling that we find it even hard to visualize. A 5% chance of AI risk isn’t even a wild estimate. Survey results suggest that the median AI researcher thinks there is a 5% chance of AI leading to an extinction-level event, and these numbers all came out before recent demonstrations in capability gains in GPT-3.5+ and before it became more socially acceptable to discuss AI risk.
A one-sentence statement was just published and signed by a variety of top researchers and industry leaders, simply saying “Mitigating the risk of extinction from AI should be a global priority alongside other societal-scale risks such as pandemics and nuclear war.” Among its many signatories are:
Geoffrey Hinton (one of three “godfathers of AI”)
Yoshua Bengio (the second of three “godfathers of AI”)
Demis Hassabis (Google DeepMind)
Shane Legg (Google DeepMind)
Sam Altman (OpenAI — ChatGPT)
Ilya Sutskever (OpenAI — ChatGPT)
Dario Amodei (Anthropic — Claude)
Unfortunately, this is not sci-fi. Unaligned AGI will be an existential risk to humanity.
So what do we do?
First off, convince yourself that this is indeed a challenge. A single article on the topic may not fully bring you on board. Take the time to engage with the literature. Deciding that this problem is non-trivial requires overcoming some mental hurdles, including being that person who seriously worries about losing control over AI, which currently still looks to be pretty dumb. The best way to become more convinced is to look for what part of the discussion doesn’t make sense to you and to probe there. Everyone has a slightly different mental model of the future of AI, so what convinces you will likely be specific to you. At the very least, the number of important AI people who are seriously talking about losing control over future AIs should suggest a deeper read is worthwhile.
The question of AI risk rests at its core on the relationship between two curves: the AI capabilities curve and the AI alignment curve. To ensure that AGI is safe, by the time we build true AGI, alignment should have progressed enough to be safely and well ahead of capabilities. We can do this by accelerating alignment research or slowing down capability gains. The world where we have the best shot likely looks like a combination of both. The world where we make it likely does not look like one where we ignore the problem, think it’s easy to solve, or put it off into the future — we probably won’t accidentally stumble into a solution, especially in a short timeframe.
So what can you do?
If you found this post interesting and important, please share it with others :)
You can learn more about alignment from a variety of sources. Here are some:
The case for taking AI seriously as a threat to humanity
Superintelligence FAQ (no direct relation to the above book)
YouTube videos on alignment
The ‘Don’t Look Up’ Thinking That Could Doom Us With AI
Why I think strong general AI is coming soon
The Planned Obsolescence blog
Without specific countermeasures, the easiest path to transformative AI likely leads to AI takeover
The AGI Safety Fundamentals course
AGI Ruin: A List of Lethalities
Machine Intelligence Research Institute
And many others that are more formal and research-oriented than the aboveIf you’re convinced that the topic matters and you have a reasonable understanding of the arguments, start conversations with others around you. Many of the ways forward for alignment benefit from general buy-in into the idea. Awareness isn’t slacktivism — it’s central to getting the relevant people on board. If you don’t have the opportunity to engage in other ways, spreading knowledge about the problem is the best way for the average person to contribute.
If you have the opportunity, consider going down the path of moving the needle on alignment research. Alignment researchers are currently pursuing different options for controlling supercapable systems, including interpretability, scalable oversight, and alignment theory. In the future, I will put together a longer list of how to get started. In the meantime, here is a good first read.
Besides research, there is work to do surrounding core alignment like building out evaluation datasets for detecting dangerous capabilities and doing adversarial testing in virtualized environments where we can explore the capabilities of ever stronger AIs with the lowest risk of them abusing their power.
There is also plenty of work in coalition building, both in industry and politics. Solving alignment may well require the cooperation between top AI labs, sharing of testing environments, and building evaluation criteria together. Just recently a joint paper came out from top labs on testing of dangerous capabilities. Coming up with shared criteria of thresholds that we shouldn’t collectively cross until alignment catches up is another important area. Depending on how much weight you put in regulation, preparing plans for actually effective and non-counterproductive regulatory plans is also worthwhile, and writing good policy that hits at the heart of the problem is also hard. It’s important to note for this point that specific, actionable plans are most useful, with hard criteria for what is ok and what isn’t as we push humanity deeper into the age of AI. A soft commitment to AI safety isn’t enough. Reject “safetywashing” or lip service to safety that merely seeks to unblock additional capability gains.
Maybe most importantly for people who are first encountering this topic and are taking it seriously: breathe. Learning about and seriously internalizing an existential threat to humanity isn’t an easy task. If you find that it’s negatively impacting you, pull away for some time, and focus on what we can do rather than on the magnitude of the risk.
On a personal note, writing this post for the past two months is what convinced me to leave my team to move to a team that works on Generative AI Safety. I am not saying that everyone should drop everything to work on this — I’m just sharing this to convey that I do not take the arguments I present here lightly. (Of course, as a disclaimer, this post does not claim to represent the views of my org or of Meta)
A parting quote from Sam Altman from before he was the CEO at OpenAI:
“Development of superhuman machine intelligence (SMI) is probably the greatest threat to the continued existence of humanity”
Figuring out alignment won’t be one-and-done. There won’t be a single law we pass or paper we write that will fix the problem. Let’s buckle up for the ride and put in the work, because the time to do this is now.
That isn’t the argument! The argument is that having a goal makes an AI seek power, and intelligence enables it.
This post would be better if it contained the entire article. I suspect many folks here would provide interesting critique who aren’t likely to click through.
Do people really not do one extra click, even after the intro? :O
Nope. In large part because there are so many articles like this floating around now, and the bar for “new intro article worth my time” continues to go up; also simply trivial inconveniences → original post. I make a specific habit of clicking on almost everything that is even vaguely interesting on topics where I am trying to zoom in, so I don’t have that problem as much. (I even have a simple custom link-color override css that force-enables visited link styling everywhere!)
On the specific topic, I may reply to your post in more detail later, it’s a bit long and I need to get packed for a trip.
Thanks for your feedback. It turns out the Medium format matches really well with LessWrong and only needed 10 minutes of adjustment, so I copied it over :) Thanks!
Not bad, in my opinion. Quite long. Clearly I am not the intended audience—that would be someone who previously never thought about the topic. I wonder what are their reactions to the article.
That is not the original intended usage of the paperclip maximizer example, and it was renamed to squiggle maximizer to clarify that.
Yep, and I recognize that later in the article:
But it’s still useful as an outer alignment intuition pump.