This google search seems to turn up some interesting articles (like maybe this one, though I’ve just started reading it).
Vivek Hebbar
Karma: 883
Paul [Christiano] called this “problems of the interior” somewhere
Since it’s slightly hard to find: Paul references it here (ctrl+f for “interior”) and links to this source (once again ctrl+f for “interior”). Paul also refers to it in this post. The term is actually “position of the interior” and apparently comes from military strategist Carl von Clausewitz.
Can you clarify what figure 1 and figure 2 are showing?
I took the text description before figure 1 to mean {score on column after finetuning on 200 from row then 10 from column} - {score on column after finetuning on 10 from column}. But then the text right after says “Babbage fine-tuned on addition gets 27% accuracy on the multiplication dataset” which seems like a different thing.
Note: The survey took me 20 mins (but also note selection effects on leaving this comment)
Here’s a fun thing I noticed:
There are 16 boolean functions of two variables. Now consider an embedding that maps each of the four pairs {(A=true, B=true), (A=true, B=false), …} to a point in 2d space. For any such embedding, at most 14 of the 16 functions will be representable with a linear decision boundary.
For the “default” embedding (x=A, y=B), xor and its complement are the two excluded functions. If we rearrange the points such that xor is linearly represented, we always lose some other function (and its complement). In fact, there are 7 meaningfully distinct colinearity-free embeddings, each of which excludes a different pair of functions.[1]
I wonder how this situation scales for higher dimensions and variable counts. It would also make sense to consider sparse features (which allow superposition to get good average performance).
- ^
The one unexcludable pair is (“always true”, “always false”).
These are the seven embeddings:
- ^
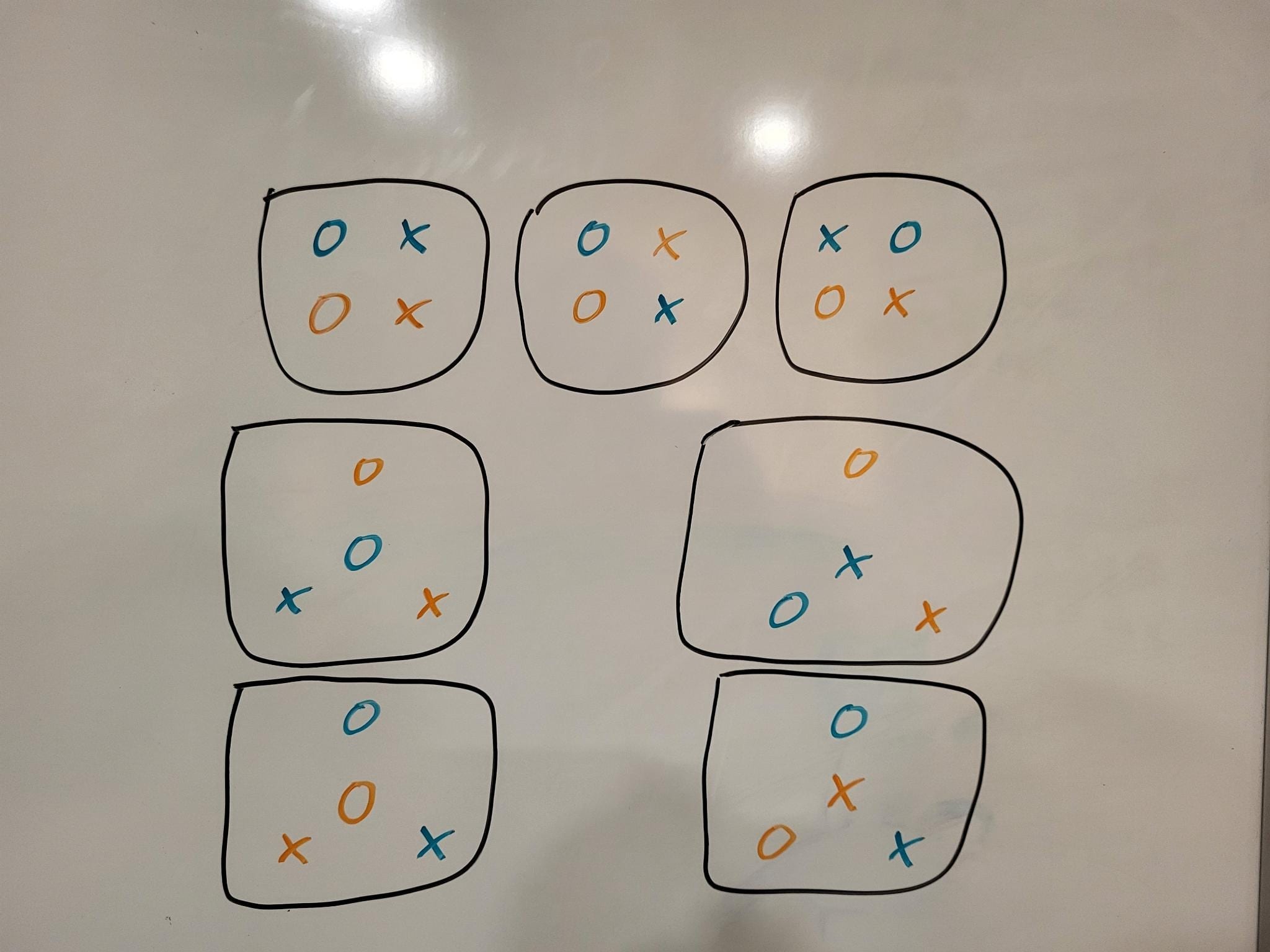
Oops, I misunderstood what you meant by unimodality earlier. Your comment seems broadly correct now (except for the variance thing). I would still guess that unimodality isn’t precisely the right well-behavedness desideratum, but I retract the “directionally wrong”.
The variance of the multivariate uniform distribution is largest along the direction , which is exactly the direction which we would want to represent a AND b.
The variance is actually the same in all directions. One can sanity-check by integration that the variance is 1⁄12 both along the axis and along the diagonal.
In fact, there’s nothing special about the uniform distribution here: The variance should be independent of direction for any N-dimensional joint distribution where the N constituent distributions are independent and have equal variance.[1]
The diagram in the post showing that “and” is linearly represented works if the features are represented discretely (so that there are exactly 4 points for 2 binary features, instead of a distribution for each combination). As soon as you start defining features with thresholds like DanielVarga did, the argument stops going through in general, and the claim can become false.
The stuff about unimodality doesn’t seem relevant to me, and in fact seems directionally wrong.
- ^
I have a not-fully-verbalized proof which I don’t have time to write out
- ^
Maybe models track which features are basic and enforce that these features be more salient
Couldn’t it just write derivative features more weakly, and therefore not need any tracking mechanism other than the magnitude itself?
It’s sad that agentfoundations.org links no longer work, leading to broken links in many decision theory posts (e.g. here and here)
This will initially boost relative to because it will suddenly be joined to a network with is correctly transmitting but which does not understand at all.
However, as these networks are trained to equilibrium the advantage will disappear as a steganographic protocol is agreed between the two models. Also, this can only be used once before the networks are in equilibrium.
Why would it be desirable to do this end-to-end training at all, rather than simply sticking the two networks together and doing no further training? Also, can you clarify what the last sentence means?
(I have guesses, but I’d rather just know what you meant)
I’ve been asked to clarify a point of fact, so I’ll do so here:
My recollection is that he probed a little and was like “I’m not too worried about that” and didn’t probe further.
This does ring a bell, and my brain is weakly telling me it did happen on a walk with Nate, but it’s so fuzzy that I can’t tell if it’s a real memory or not. A confounder here is that I’ve probably also had the conversational route “MIRI burnout is a thing, yikes” → “I’m not too worried, I’m a robust and upbeat person” multiple times with people other than Nate.
In private correspondence, Nate seems to remember some actual details, and I trust that he is accurately reporting his beliefs. So I’d mostly defer to him on questions of fact here.
I’m pretty sure I’m the person mentioned in TurnTrout’s footnote. I confirm that, at the time he asked me, I had no recollection of being “warned” by Nate but thought it very plausible that I’d forgotten.
What’s “denormalization”?
When you describe the “emailing protein sequences → nanotech” route, are you imagining an AGI with computers on which it can run code (like simulations)? Or do you claim that the AGI could design the protein sequences without writing simulations, by simply thinking about it “in its head”?
Cool! It wrote and executed code to solve the problem, and it got it right.
Are you using chat-GPT-4? I thought it can’t run code?
Interesting, I find what you are saying here broadly plausible, and it is updating me (at least toward greater uncertainity/confusion). I notice that I don’t expect the 10x effect, or the Von Neumann effect, to be anywhere close to purely genetic. Maybe some path-dependency in learning? But my intuition (of unknown quality) is that there should be some software tweaks which make the high end of this more reliably achievable.
Anyway, to check that I understand your position, would this be a fair dialogue?:
Person: “The jump from chimps to humans is some combination of a 3x scaleup and some algorithmic improvements. Once you have human-level AI, scaling it up 3x and adding a chimp-to-human-jump worth of algorithmic improvement would get you something vastly superhuman, like 30x or 1000x Von Neumann, if not incomparable.”
Vivek’s model of Jacob: “Nope. The 3x scaleup is the only thing, there wasn’t much algorithmic improvement. The chimp-to-human scaling jump was important because it enabled language/accumulation, but there is nothing else left like that. There’s nothing practical you can do with 3x human-level compute that would 30x Von Neumann[1], even if you/AIs did a bunch of algorithmic research.”
I find your view more plausible than before, but don’t know what credence to put on it. I’d have more of a take if I properly read your posts.
- ^
I’m not sure how to operationalize this “30x-ing” though. Some candidates:
- “1000 scientists + 30 Von Neumanns” vs. “1000 scientists + 1 ASI”
- “1 ASI” vs. “30 Von Neumanns”
- “100 ASIs” vs. “3000 Von Neumanns”
- ^
In your view, who would contribute more to science -- 1000 Einsteins, or 10,000 average scientists?[1]
“IQ variation is due to continuous introduction of bad mutations” is an interesting hypothesis, and definitely helps save your theory. But there are many other candidates, like “slow fixation of positive mutations” and “fitness tradeoffs[2]”.
Do you have specific evidence for either:
Deleterious mutations being the primary source of IQ variation
Human intelligence “plateauing” around the level of top humans[3]
Or do you believe these things just because they are consistent with your learning efficiency model and are otherwise plausible?[4]
Maybe you have a very different view of leading scientists than most people I’ve read here? My picture here is not based on any high-quality epistemics (e.g. it includes “second-hand vibes”), but I’ll make up some claims anyway, for you to agree or disagree with:
There are some “top scientists” (like Einstein, Dirac, Von Neumann, etc). Within them, much of the variance in fame is incidental, but they are clearly a class apart from merely 96th percentile scientists. 1000 {96%-ile-scientists} would be beaten by 500 {96%-ile-scientists} + 100 Einstein-level scientists.
Even within “top scientists” in a field, the best one is more than 3x as intrinsically productive[5] as the 100th best one.
- ^
I’m like 90% on the Einsteins for theoretical physics, and 60% on the Einsteins for chemistry
- ^
Within this, I could imagine anything from “this gene’s mechanism obviously demands more energy/nutrients” to “this gene happens to mess up some other random thing, not even in the brain, just because biochemistry is complicated”. I have no idea what the actual prevalence of any of this is.
- ^
What does this even mean? Should the top 1/million already be within 10x of peak productivity? How close should the smartest human alive be to the peak? Are they nearly free of deleterious mutations?
- ^
I agree that they are consistent with each other and with your view of learning efficiency, but am not convinced of any of them.
- ^
“intrinsic” == assume they have the same resources (like lab equipment and junior scientists if they’re experimentalists)
It would still be interesting to know whether you were surprised by GPT-4′s capabilities (if you have played with it enough to have a good take)
Human intelligence in terms of brain arch priors also plateaus
Why do you think this?
POV: I’m in an ancestral environment, and I (somehow) only care about the rewarding feeling of eating bread. I only care about the nice feeling which comes from having sex, or watching the birth of my son, or being gaining power in the tribe. I don’t care about the real-world status of my actual son, although I might have strictly instrumental heuristics about e.g. how to keep him safe and well-fed in certain situations, as cognitive shortcuts for getting reward (but not as terminal values).
Would such a person sacrifice themselves for their children (in situations where doing so would be a fitness advantage)?
The idea of dividing failure stories into “failures involving rogue deployments” and “other failures” seems most useful if the following argument goes through:
1. Catastrophes require a very large (superhuman?) quantity and/or quality of intellectual labor
2. Either this labor is done by AIs in approved scaffolds, or it is done in “rogue deployments”
3. Hence the only easy-by-default disaster route is through a rogue deployment
4. Hence if we rule out rogue deployments and very impressive/difficult malicious labor in our scaffolds, we are safe
This seems true for most catastrophes which only need outsider affordances (such as “order the proteins etc for a pandemic or a nanofactory”). Catastrophes with outsider affordances can usually be presumed difficult because rogue humans don’t randomly end the world.
However, this argument for #1 doesn’t work for routes which use insider affordances or responsibilities. Nor for routes which go through work done by future generations of AIs. The central case of both is routes that involve using insider privileges to backdoor or intentionally misalign future AIs. For example:
- Planting backdoors in the codebase which allow safety training code to be turned off or misconfigured at a later time
- Poisoning datasets (idk if insider access helps though)
- Intentionally creating and defending flawed alignment plans
These routes get future generations of AIs to do the difficult work required for the final catastrophe. But they aren’t necessarily rogue deployments. Consider a backdoored future AI running only in authorized scaffolds, where the safety case for the future AI was an alignment case (not a control case). The alignment case fails due to the subversive actions of the earlier AI. So the earlier AI has caused a catastrophe without doing the difficult work of directly taking over the world, and also without a rogue deployment.
One could separately argue that these routes are also “fundamentally hard” (even if not as hard as directly causing a catastrophe), but I don’t see a clear blanket reason.